이번에 들고온 논문은 이상 상황 검출에 대한 내용입니다. 오랜만에 산업 환경상의 이상 상황 검출 데이터 셋인 MVTec을 이용한 비지도 학습 기반의 이상 상황 검출 방법론을 들고 왔습니다. 해당 방법론에서 사용한 방법은 매우 간단합니다. 자기 자신(영상)의 일부를 잘라 다른 곳에 붙여, 붙인/안붙인 영상으로 이진 분류를 학습합니다. 그후 실제 이상 상황에서도 이상 부위에 집중하는 것을 보여줍니다. 이런 간단한 데이터 증강으로 Image-level/Pixel-level ROCAUC에서 SOTA를 달성하였습니다.

Intro
MVTec 데이터 셋은 산업환경에서 발생 가능한 실제 불량 영상들을 잘 구성된 환경에서 촬영한 영상과 불량 부위에 대한 위치 정보를 제공하는 데이터 셋입니다. 또한 산업 환경에서는 불량 발생이 매우 적으며, 발생하더라도 다양한 경위로 발생하기 때문에 다양한 형태를 가집니다. 그렇기에 모든 상황을 대비한 데이터 셋을 만들기에는 매우 비싼 비용이 듭니다. MVTec 데이터 셋은 이런 문제를 고려하여 데이터 셋의 목적 자체를 정상적인 상황만 이용하여 학습한 후, 이상 물체에 대해 분류 및 위치를 찾아내는 데이터 셋을 제작합니다. 이러한 사유로 데이터 셋은 학습 데이터에는 정상 상황, 평가 데이터에는 비정상과 정상 데이터를 포함하도록 구성됩니다.
MVTec 데이터 셋이 나온 후, 많은 비지도 방법론이 나왔습니다. 대부분 사전학습된 CNN을 이용한 특징 정보과 전통적인 비지도 기계학습 기법(K-means, GMM… etc)를 이용한 방법론들이 대다수 였습니다. 이런 조합으로 높은 성능을 보였으나 사전 학습된 CNN을 이용하기 때문에 MVTec 데이터 셋의 양상을 배우지 못하였기에 비효율적인 문제가 있습니다.
이번 리뷰 방법론인 CutPaste는 간단한 데이터 증강 방법을 이용하여 정상 영상만 존재하는 학습 데이테에서 비정상을 만들어 딥러닝 기반 이진 분류 모델에서 준 지도 학습이 가능하도록 합니다. 이를 통해 딥러닝 모델은 MVTec 데이터 셋의 양상을 학습 할 수 있도록 됨으로써, 아직 보지 못한 비정상 데이터 셋에서 불량 부위의 위치를 바라볼 수 있게 됩니다. 또한 저자는 CNN 모델들(ResNet, EfficientNet)만을 이용하여 SOTA를 달성함으로써 해당 방법론의 효과를 보여줍니다.
Method
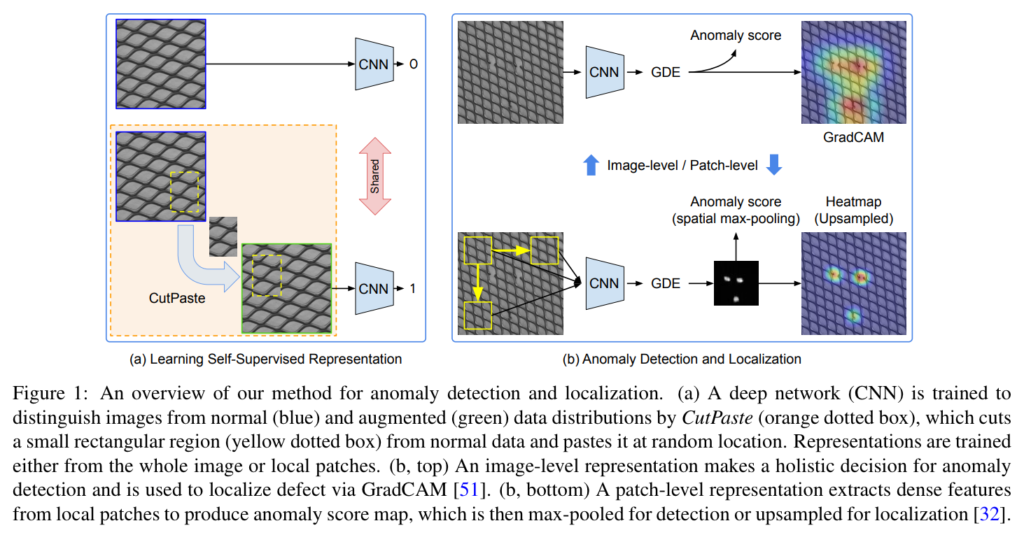
위에서 설명한 바와 같이 해당 방법론은 매우 간단한 데이터 증강을 이용하여 이상 부위를 찾아내는 방법을 사용합니다. Fig 1의 왼쪽 박스 하단을 보시면 영상의 일부를 잘라 다른 위치에 잘라 붙인 영상을 1(이상), 기존의 영상을 0(정상)로 구분하는 이진 CNN 모델을 학습합니다.(예시는 Fig 2. (E)-(f)에서 확인 가능합니다.) 학습된 모델은 영상 자체의 불량을 표현하는 Image-level anomaly score와 영상 픽셀 내 불량 위치를 표현하는 pixel-level anomaly score map을 출력함으로써 불량 여부를 판단합니다. (Image-level anomaly socre map을 생성하는데에 Grad-CAM, patch-aware anomaly score map을 이용합니다. 해당 내용들은 아래에서 자세히 다루도록 하겠습니다.)

Train
영상에 노이즈를 줌으로써 특징 추출기의 성능을 향상 시킨 방법론은 Cutout, CutMix 등으로 증명이 되었습니다. 또한 MVTec 데이터 셋에서도 영상에 fig 2의 (d) scar [1]와 같이 길쭉한 형태의 박스를 추가함으로써 이상 상황을 묘사한 방법도 존재합니다. 하지만 해당 방법론은 이전 방법론과 다르게 입력 영상의 일부를 잘라 붙이는 방법을 사용함으로써, 입력 영상의 특징에 대한 유사성을 가진 상태로 모사가 가능하여 모델이 학습하는데에 있어 노이즈를 줄이며 학습이 가능하다는 장점이 있습니다.
++ fig 2. (F) CutPaste (scar)는 (d) scar의 방법론의 효과를 착안하여 사각형으로 자르는 것이 아닌 한쪽 변의 비율을 줄인 사각형을 추가한 방법입니다.
또한 저자는 모델의 분별력을 보다 키우기 위해 [32]를 착안하여 정상, cutout, cutpaste, cutpaste-scar에 대한 정상/비정상 이진 분류 예측하도록하여 모델을 학습 시킵니다. (loss는 BCE loss를 사용합니다.)
Test
저자는 모델로부터 추론된 특징 값들을 축약하고 anomaly score를 추출하기 위해서 Kernel Density Estimator(KDE)를 이용하고자 합니다. 하지만 KDE는 정확도 향상을 위해서는 많은 학습 데이터가 필요하며 많은 계산량을 요구합니다. 저자는 이런 문제점을 해결하기위해 아래 수식과 같은 간단한 Gaussian density estimator(GDE)를 이용합니다.
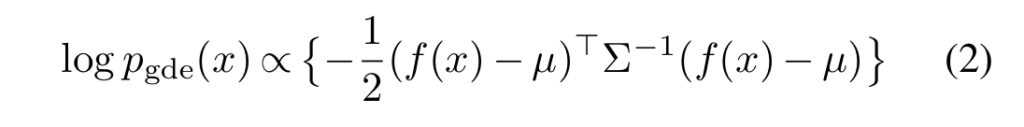
수식 2에 대해 좀 더 설명을 하자면, 테스트 영상 특징과 정상 영상 특징간의 마할라노비스 거리에 해당합니다. 이는 logscale gde와 비례하는 형태를 가진다고 합니다. 이를 통해 정상과 비정상 특징 정보에 대해 분산을 고려한 거리값을 계산함으로써 특징 분산을 고려한 이상 부위를 산정할 수 있게 됩니다.(f는 학습된 모델, 시그마(공분산)와 u(평균)는 정상 데이터의 특징으로부터 추론된 정보에 해당합니다.)
Localization
이상 부위를 예측하는 방법은 2가지 방법으로 구성됩니다. 하나는 모델의 gradient 정도를 계산함으로써 바라보는 시점을 시각화하는 Grad-CAM한 방법과 영상을 패치 단위로 쪼개 특징 값을 추론하고 수식 2를 적용하고 모든 패치를 모아 MaxPooling을 구하는 Patch heatmap이 있습니다. Image-level로 예측할 때는 전자를, pixel-level로 예측할 때는 local dense하게 볼 수 있는 후자의 방법을 이용하여 예측하였습니다. 도식화된 예제는 fig 1의 오른쪽 박스에서도 확인이 가능합니다.
Experiment

해당 방법의 효과는 fig 3의 정상, 비정상, CutPaste, CutPaste-scar의 t-SNE를 통해서도 확인 가능합니다. 간단한 데이터 증강을 이용한 학습 모델의 특징 정보들이 명확하게 군집화된 모습을 확인 가능합니다.
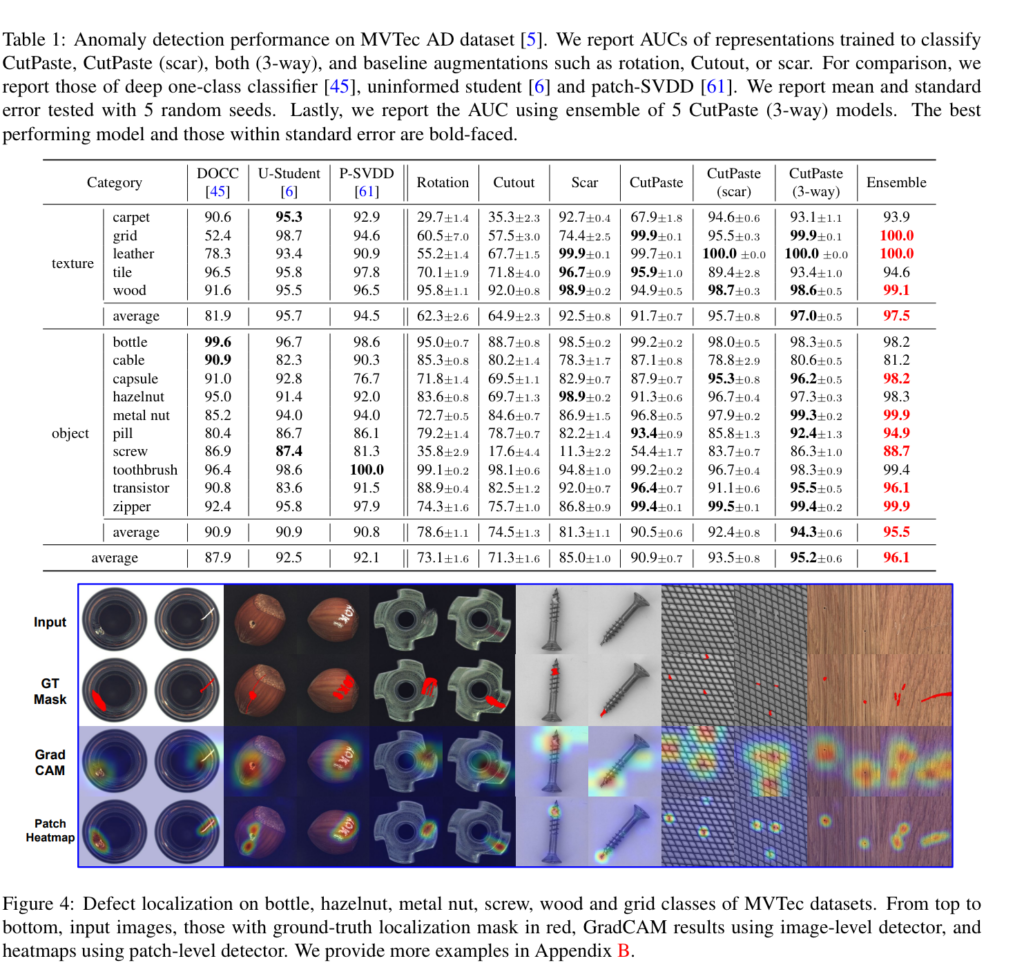
Table 1에서는 이전 SOTA 방법론들과 비교와 제안된 세팅에서의 Image-level ROCAUC를 볼 수 있습니다. 최종적으로 96.1로 SOTA를 달성한 것을 볼 수 있습니다. 성능 지표를 보면 몇가지 흥미로운 부분이 있습니다. texture는 fig 4의 오른쪽 그림과 같이 유사한 패턴을 가진 물체들로 구성됩니다. 또한 테스트 영상을 보면 스크래치, 물 흐림, 변색 등 사람이 눈으로 보기에도 어려운 영상들이 있었습니다. 하지만 해당 방법론은 자기 자신의 일부를 붙여 유사한 이상 상황을 생성하여 학습까지 하기에 feature extractor를 학습하지 않는 타 방법론보다 높은 성능을 보여주고 있습니다. 또다른 재밌는 부분은 pill, capsule입니다. 두 분류에서 포함된 불량 중 색의 변조, 글씨 불량, 색소 침작 등이 존재합니다. 해당 케이스들도 사람 눈으로 볼때 구분이 힘든 케이스에 해당합니다. 해당 케이스에서도 높은 성능을 보여주고 있습니다.
가장 흥미로운 케이스는 hazelnut, metalnut, screw에 해당합니다. 해당 분류에서는 고정된 각도가 아닌 서로 다른 각도에 존재하는 케이스로 위치 변화에 예민한 경우, 위치 변화를 이상 케이스로 구분할 수 있기에 어려운 케이스에 해당합니다. 하지만 이러한 케이스에도 동일하게 회전 변화가 포함된 정상 데이터를 변환 시키고, 또한 회전을 데이터 증가에 포함하여 학습이 가능하기 때문에 회전 불변성을 가져 높은 성능을 보여줍니다.
불량 위치에 대해서도 fig 4를 통해 잘 찾는 모습을 볼 수 있습니다.
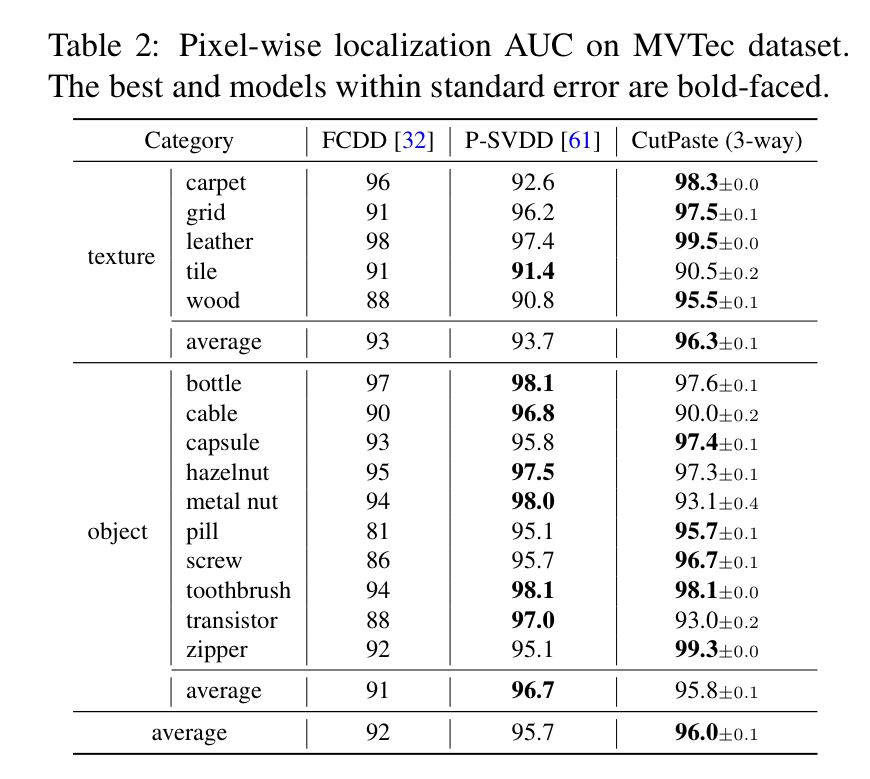
또한 Table 2를 통해서도 불량 위치(Pixel-level rocauc)의 성능을 확인 할 수 있습니다. 역시나 SOTA를 달성한 것을 볼 수 있습니다.
참고
[1] daisukelab. Spotting defects! — deep met- ric learning solution for mvtec anomaly detection dataset. https : / / medium . com / analytics – vidhya / spotting – defects – deep – metric – learning – solution – for – mvtec – anomaly – detection- dataset- c77691beb1eb. Accessed: 2020-11-12. 3, 5
[2] Philipp Liznerski, Lukas Ruff, Robert A Vandermeulen, Billy Joe Franks, Marius Kloft, and Klaus-Robert Muller. ¨ Explainable deep one-class classification. arXiv preprint arXiv:2007.01760, 2020. 2, 3, 4, 6, 7, 13
=============================================================
현재 진행 중인 중기청 과제에서 식물의 성장 정도 뿐만 아니라 식물의 질닐 검출하는 문제도 해결해야 했습니다. 하지만 산업 환경과는 다르게 식물의 질병을 인위적으로 확보하기가 매우 어렵기 때문에 역시나 데이터가 매우 부족한 상황에서 과제를 해결해야하는 상황이었습니다. 이러한 상황에서는 비지도 학습이 해결책이라고 생각하였고, 때마침 해당 논문을 발견하게 되었습니다. 비지도로만 해결하려고 했던 상황에서 데이터 증강을 이용하여 준지도 학습을 제안한 방법을 모티브로 새로운 아이디어가 떠올라 적용 중입니다. 추후 좋은 결과로 연구원님들에게 소개할 수 있으면 좋겠습니다.
결국엔 outlier exposure 기반 방법론들과 컨셉이 상당히 유사하네요. 해당 augmentation들도 결국엔 outlier로 작용할테니 말이죠. 이 때, augmentation을 어떻게 하면 좀 더 리얼리스틱하게 하느냐가 관건인거 같군요. 사람이 생각하는 것과 기계가 생각하는 “리얼리스틱” 의 정의가 다를수도 있다고 하는데 cut-paste가 사람인 제가 보기에는 가시적으로 좀 어색한 부분도 많다고 생각하는데 생각보다 잘 워킹하는게 신기하군요.