오늘 리뷰할 논문은 Transformer 입니다. 지난번 리뷰도 Transformer로 한 것 같은데, 지난번 리뷰가 Vision Transformer의 문제점에 대한 분석을 위주로 한 논문이었다면, 이번에는 일반적인 논문들처럼 새로운 구조로 제안된 Transformer 입니다.
이번 리뷰는 최대한 간결하게 작성해볼게요 흐흐..
Introduction
Transformer는 원래 NLP 분야에서 처음 등장하여 다른 RNN, LSTM 구조들보다 훨씬 좋은 성능을 보여주었습니다. 이렇게 좋은 모습을 보여주었으니, 비록 NLP에서 처음 등장하였지만 Vision 분야에도 접목해볼 수 있지 않을까라는 생각과 함께 Vision Transformer(ViT)가 제안됩니다.
하지만 저자는 NLP와 Vision domain 사이에서 큰 차이점들이 존재한다고 하는데 그 중 하나는 바로 scale입니다. language Transformer에서 처리하는 work token과는 달리, 시각적 요소들은 스케일의 다양성이 존재합니다. 이러한 스케일이 중요한 분야의 예시로는 보통 Object detection을 들 수 있겠죠?(작은 스케일의 물체를 더 잘 찾기 위해 다양한 방법론들이 제안되었던 것처럼요.
하지만 기존의 Transformer들은 NLP 방식들과 동일하게 고정된 스케일을 가지는 token을 활용하였으며, 이는 vision task에서는 적합하지 않은 방식이었던 것이죠.
또 다른 차이점으로는 resolution입니다. 여기서 resolution은 정보의 빈도?를 의미하는 것으로 보이는데, 문장 속 단어는 아무리 문장이 길더라도 한번에 몇십만개가 될 수 없지만, 영상은 각 픽셀별로 dense하게 정보들이 분포하고 있죠. 물론 픽셀을 단어로 보기에는 그 수가 너무 많으니, 패치 단위로 단어를 보고 있긴 합니다만… 결국 segmentation이나 depth estimation과 같이 pixel 단위로 dense한 값을 예측하는 task들은 고해상도의 영상을 처리해야합니다.
이 때 문제가 발생하는데 기존의 Transformer들은 처음부터 끝까지 고정된 크기에 패치 단위로 attention을 주고 layer를 태우기 때문에, 입력 영상의 해상도가 크면 클수록 연산량이 제곱으로 늘어나게 됩니다.
그래서 저자는 이러한 문제들을 해결하고자, hierarchical feature map을 설계하면서 동시에 영상 크기에 대해 linear한 연산 복잡도를 가지는 네트워크를 제안합니다.
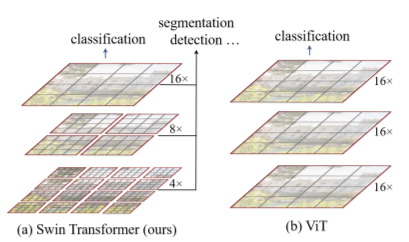
본격적으로 들어가기 앞서 해당 논문에 대해 요약을 하자면, 기존에 고정된 패치 단위가 아니라 transformer block을 타고 갈수록 점점 feature의 크기를 2배씩 줄여나가는 구조를 취하게 됩니다. 또한 원래라면 영상의 모든 패치들끼리 self-attention을 주고 받아야만 하는데, 저자는 shift하는 window partition을 통해 특정 구역 내 patch들끼리 attention을 주고 받도록 하여 연산량을 크게 줄였습니다.
Method
그럼 본격적으로 논문에서 제안하는 구조에 대해 알아봅시다.
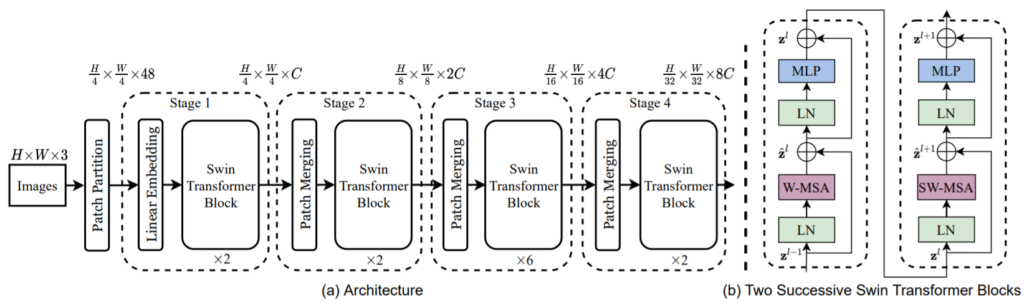
일단 그림2는 전체적인 구조와 Swin Transformer block의 내부 구조를 나타낸 것입니다. 입력 영상은 RGB 영상이므로 H \times W \times 3이라는 shape을 가지게 될 것이며, 기존 ViT와 다르게 4×4 kernel size, 4 stride를 통하여 4×4 패치로 자르게 됩니다.
이 때 각 4×4 패치 내부에 대하여 픽셀값에 해당하는 16개의 값들은 RGH 3채널에 기생?하여 48채널을 가지게 됩니다.(Patch Partition 부분). 그 다음에는 latent space로 투영시켜주기 위해 FC layer를 태우게 되고 모델의 크기 마다 투영된 임베딩 벡터의 크기가 달라지긴 하지만 default는 96이라고 생각하시면 될 것 같습니다.
이렇게 투영된 임베팅 벡터를 가지고 Swin Transformer block에 입력으로 넣어주게 됩니다. Swin Transformer block 내부 구조는 그림2의 b와 같은데, Layer normalization –> Window Multi head Self Attention –> Residual –> Layer normalization –> Multi Layer Perceptron의 구조를 띄고 있습니다. 2번째 블록에서 SW-MSA는 W-MSA에서 Shift가 붙은 것으로 밑에서 설명하겠습니다.
아무튼간에, 이렇게 각 Stage별로 Swin Transformer Block들이 구성되어 있으며 Stage를 통과할 떄마다 feature map의 크기는 절반씩 줄어들며 채널은 2배씩 커지는 모습입니다. 이러한 구조가 기존 CNN 네트워크에서 점점 Encoder 레이어를 타고 갈수록 feature map의 사이즈는 작아지고 채널은 깊어지는 부분이 많이 유사합니다.
Shifted Window based Self-Attention
저자는 Global Self Attention 대신, Shifted Window based Self-Attention을 제안합니다. 기존의 Global attention이 나쁘다는 것은 아니지만, 성능 향상 대비 연산량이 너무 크다는 것이 가장 큰 단점이었습니다. 때문에 보다 효율적으로 학습하기 위해서, 저자는 Local window 내에서만 Self-attention을 진행하도록 하였습니다.
각각의 윈도우는 non-overlapping한 특성으로 이루어져 있으며, 만약 해당 윈도우의 사이즈가 M x M에 입력 영상의 패치가 h x w 해상도를 가진다면 기존 ViT의 MSA와 Swin의 W-MSA 연산량은 다음과 같습니다.
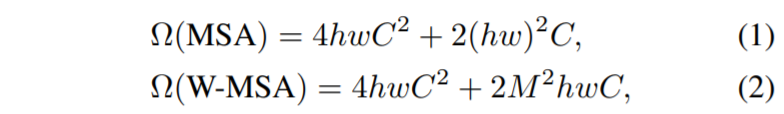
보시면 기존 MSA와 W-MSA의 차이는 (hw)^{2}, M^{2}*hw 의 차이네요. 입력 영상이 작아서 입력 영상의 패치 개수가 줄어들게 된다면 MSA와 W-MSA의 연산량 차이는 별로 나지 않겠지만, 고해상도 영상을 입력으로 사용하게 될 경우 기존 MSA는 h와 w가 동시에 늘어나는 반면, W-MSA는 고정된 M값을 사용하기에 M의 개수만 더 늘어나 연산량이 Linear하게 늘어납니다. 보통 M은 7 x 7 커널로 사용됩니다.
Shifted window partitioning in successive blocks
사실 Window 기반에 self-attention module은 윈도우들 간에 연결성이 부족하기 때문에 Global attention보다 attention 성능면에서 떨어질 수 있습니다. 그래서 저자는 self-attention을 수행하는 윈도우를 shift함으로써 각 패치들이 attention을 더 많이 주고 받을 수 있도록 하였습니다.
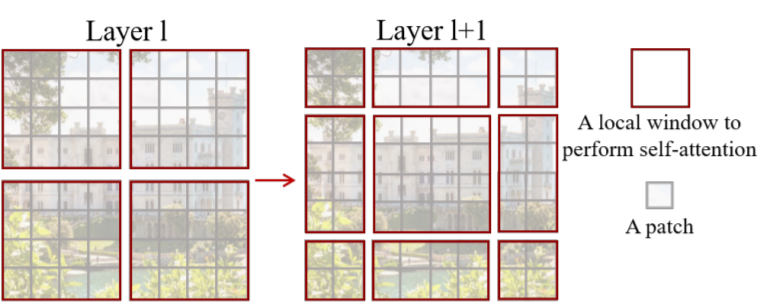
그림3은 Window attention과 Shifted window attention을 나타낸 그림입니다. 보시면 처음에는 좌상단 픽셀부터 8 x 8 구간으로 일반적인 window partitioning 기법을 적용합니다. 그후에 attention이 다 진행된 후 다음 모듈(SW-MSA)에서는 M/2, M/2 크기의 픽셀만큼 윈도우를 shift한 후 이동된 영역 내부끼리 Self-attention을 수행하게 됩니다.
대충 이러한 두 모듈의 연산 과정을 논문에서는 아래와 같이 표현하였습니다.

여기서 \hat{z}^{l}, z^{l}은 각각 (S)W-MSA 모듈과 MLP 모듈의 output feature들을 의미하며 l은 block의 순서를 의미합니다.
Efficient batch computation for shifted configuration
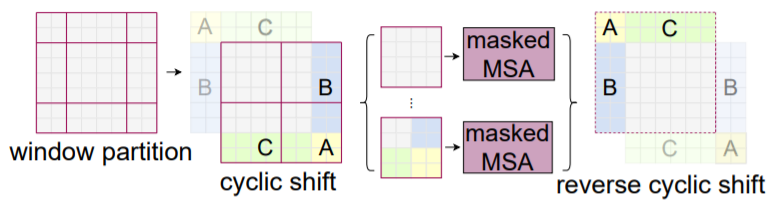
해당 부분은 shifted window partitioning을 할 때 발생하는 문제를 해결하고자 적용한 기법이라고 합니다. 사실 이 부분은 아무리 읽어도 무슨 말을 하는지 이해가 가지를 않아서… 설명을 드리기 애매하지만 논문에서 하는 말을 최대한 설명해보겠습니다.
우리가 그림3처럼 윈도우를 shift하여 self-attention을 계산할 때, feature 바운더리 부분을 벗어나게될 경우가 있을 것입니다. 이때 일반적인 방법으로는 feature map을 padding한 후 padding된 바깥 영역은 mask 처리하여 attention 계산에서 제외시킬 수 있는데, 이렇게 할 경우에는 일단 attention을 계산하는 윈도우 영역이 늘어나게 되어서 연산량이 증가한다고 하네요.
그래서 저자는 그림4와 같이 cyclic-shifting 방식을 통하여 기존의 window partitioning과 동일한 window 개수를 가질 수 있다..? 라고 하는데 저가 영어 이해를 잘 못하는건지.. 설명이 부족한건지 잘 모르겠네요ㅠ
Relative position bias
마지막으로 relative position bias에 대한 설명입니다. NLP 분야에서도 각 문장에서 단어가 어느 위치에 존재하느냐는 매우 중요한 문제입니다. 위치에 따라 어떻게 해석되는지 달라지기 때문이죠. 그래서 단어를 벡터화하여 임베딩 벡터로 만든 후, transformer에 입력으로 넣기 전에 positional encoding이라는 과정을 진행했었습니다.
이미지 역시 영상 내 위치(좌표)가 정말 중요하기 때문에 ViT도 똑같은 방식으로 positional encoding을 적용해주었는데, Swin에서는 이러한 기존 방식 말고 attention 과정 중 score를 계산할 때 position bias를 주도록 하였습니다.
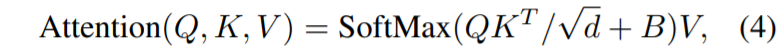
보시면 Q, K는 Query vector와 Key vector를, d는 Key vector의 길이를 의미하며 V는 Value vector를 의미합니다. 수식 4는 self-attention을 계산하는 과정을 의미하는데, 이때 B를 더해줌으로써 상대적인 위치 정보를 주게 되는 것입니다. 해당 정보는 [-M + 1, M – 1]의 범위 값을 가지고 있으며 이러한 relative position bias는 absolute position embedding보다 성능적인 면에서 더 좋다고 하네요.
Architecture Variants
실험 설명에 앞서 Swin 네트워크의 이름과 그에 따른 각 임베딩 벡터의 차원, 레이어의 개수 등에 대한 설명입니다.

Experiments
실험은 크게 ImageNet을 이용한 Classification, COCO Dataset을 이용한 Object Detection, 마지막으로 ADE20K 데이터 셋을 활용한 semantic segmentation 실험입니다.
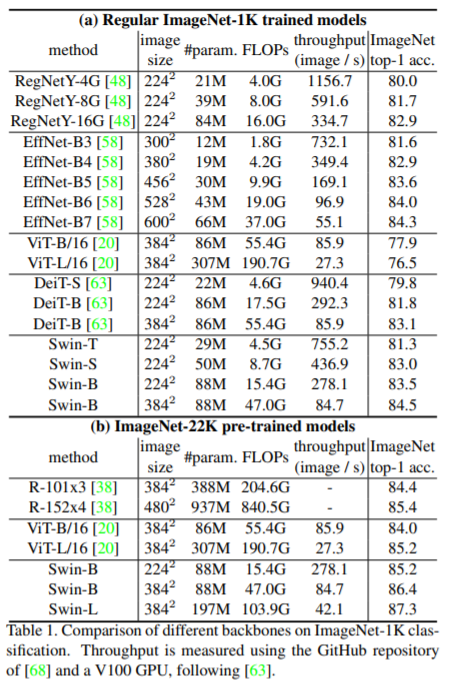
먼저 ImageNet 결과입니다. 위쪽에 RegNetY와 EfficientNet은 모두 CNN 기반 방법론들이며, ViT와 DeiT는 Transformer 방법론들입니다. ImageNet-1K 데이터셋으로 비교하였을 떄는 Swin이 SoTA는 합니다만 EffNet-B7과 비교하였을 때 모델의 크기가 제법 차이납니다. 하지만 또 입력 사이즈가 서로 달라서 EffNet과는 정확히 비교하기는 어려울 듯 하고, RegNetY 16G모델과 Swin-B(224)를 비교해볼 수 있는데, 성능 차이가 0.6밖에 차이나지 않는 모습입니다.
하지만 데이터셋을 크게 늘린 ImageNet-22K의 경우 Transformer답게 성능 차이가 크게 나는 것을 확인할 수 있는데 아쉽게도 CNN 기반의 방법론들과 비교를 하지는 않았네요.
아 그리고 ViT와 비교하였을 때 FLOP 값이 큰 차이가 나며 parameter 수도 모델이 깊을수록 큰 차이가 난다는 점을 통해서 기존 Global MSA에 비해 (S)W-MSA가 모델을 경량화 시켰으며 그럼에도 성능은 지지 않는 모습을 확실히 볼 수 있었습니다.
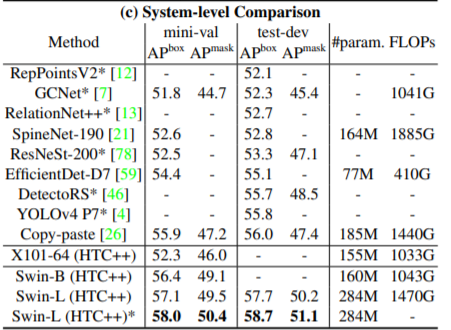
위에 표는 COCO Dataset에 대한 Detection 결과이며 상당히 좋은 모습을 보여주고 있습니다.
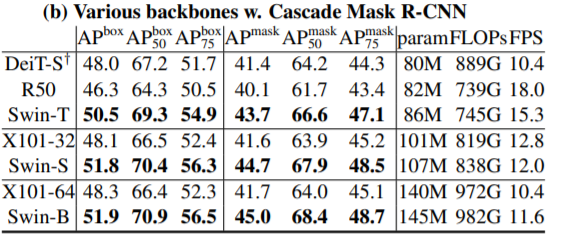
위에 표 결과도 Detection 결과인데, Swin이 같은 Transformer 백본인 Diet-S보다 더 좋은 검출 성능을 보이고 있습니다. 이는 object의 scale 차이를 얼마나 더 잘보는지가 중요한 detection task에서, 동일한 feature 크기를 사용하는 기존 Transformer 방법론들과 달리 계층적 구조를 가지는 Swin이 더 좋다는 것을 의미합니다.
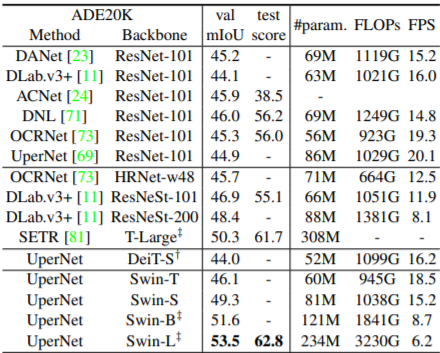
다음은 Segmentation에 대한 결과입니다. 아무래도 Transformer 방법론들은 Decoder 역시 Transformer를 쓰기는 아직 많이 힘들어서(연산량 문제로) UperNet의 Decoder를 사용한 것 같습니다. 결과는 다양한 방법론들과 비교하였을 때 가장 좋은 성능을 보입니다.
결론
해당 논문은 기존의 Transformer를 최대한 Vision Task에 맞춰서 풀고자 feature map의 구조도 계층적인 방식으로 바꾸고, Attention 방식도 Global에서 Window(local) 방식으로 변경하였습니다. 처음 논문을 읽었을 때는 Global한 attention을 주지 않는다면 굳이 Transformer를 왜쓰지…? CNN이랑 다를게 별로 없지 않나..? 라는 생각이 들었는데 다시 생각해보니 Transformer의 Global Attention과 Local한 CNN 특성을 적절히 중용한 방법이지 않나 생각합니다.
하지만 개인적으로 아쉬운 점은 Shifted window 과정이 생각보다 복잡하고 연산량을 줄인다는 목적이긴 하지만 그 과정 자체가 깔끔하지는 않아서 개인적으로 아쉬웠습니다. 저자들도 인정을 하는지 2달전에 CSwin이라는 새로운? Transformer 논문을 또 가져왔더군요. (아무래도 처음부터 완벽히 안만들고 Transformer 하나 가지고 이것저것 붙이면서 논문을 양산하는 것 같은데…) 다음에 시간되면 그쪽 논문도 리뷰해보도록 하겠습니다.
+ 그러고보니 이 논문 왜 정성적 결과는 없지…?