서론
안녕하세요 이번 리뷰는 멀티스펙트럴 보행자 인식에 관련된 논문입니다.
해당 논문을 리뷰하게된 배경은 YOLO 시리즈의 최신버전을 백본으로 활용하여 진행한 연구의 성능과 방법론이 어느정도 되는지 알아보고자 읽게되었습니다. 그 이유는, 최근 제가 리뷰를 진행했던 sota를 찍었던 논문에서도 YOLO 시리즈를 사용하고있었고, 실제로 YOLO 시리즈가 성능, 속도면에서 이점이 많으므로 과연 SOTA논문에 비해서 다른 YOLO인용 논문들은 어느정도의 성능을 보일지 궁금하여 리뷰하게 되었습니다.
우선 논문을 읽다보니 느낀게 저번에 SOTA 논문도 그렇고 이번에 읽은 논문도 그렇고 둘 다 Attention 기법을 활용하였다는 건데요. 아무래도 멀티스펙트럴의 특성상 두개의 서로다른 모달리티간의 갭차이가 존재하고, 해당 갭차이를 줄이는 방법에 대한 연구가 많은데 그런 과정에서 attention 기법이 많이 활용되는거 같습니다.
해당 논문은 YOLO시리즈를 인용한 멀티스펙트럴 논문중 최신 논문을 찾는 과정에서 발견 하였습니다. 그 중에서도 IF지수가 너무 낮지 않은 저널이나 컨퍼런스 위주로 서베이를 하였구요. 그 조건을 충족시키는거 같다고 판단되어 읽게되었습니다. 아무래도 이번에 구현해보고자 하는 논문이 YOLO 베이스라 과연 다른 YOLO베이스 멀티스펙트럴보행자 인식은 어떤식으로 네트워크 아키텍쳐를 설계를 하였는지 궁금하였습니다.
본론
논문 이야기 흐름의 구성을 짧게 요약해보겠습니다. 저는 개인적으로 잘 쓰여진 논문은 각각 소문단별로 한문단으로 요약이 가능하다고 생각합니다. 해당 논문은 전반적인 흐름이 매우 잘 짜여져있고, 특히나 방법론 설명부분에서는 엄청나게 디테일합니다. 최근에 읽은 논문중에서 가장 친절하게 방법론이 상세히 기술되어있다고 생각되어집니다. 그래서 1저자를 뒷조사 해봤더니 총인용지수가 6000정도 되는 중국분이네요.
조금 과장해서 방법론 부분에서는 해당 논문의 writing 기법을 레퍼런스 삼아도 될 거 같습니다. 그 이유는 표현적으로 고급스러운건 아니지만 모든 노테이션에 대한 설명이 빠짐없이 항상 일정한 위치에 나오고, 이해하기가 매우 쉽습니다. 글의 가독성이 좋아서 읽는사람이 편합니다. 그리고, implementation detail이 매우매우 상세하게 기술되어 있습니다. 개인적으로 이런 형식의 서술방법을 좋아하는데 아마도 의견차이가 있을거 같기는 하네요. 다만 단점으로는 각각의 피규어에 대한 주석이 좀 부실하고, LOSS항에 대한 설명이 빠진거같네요.
논문의 큰 흐름은 아래와 같습니다.
- 보행자인식 기술의 필요성
- CNN의 발달
- 기존 멀티스펙트럴 보행자 인식 방법론들의 한계
- 논문에서 제안하는 work 소개
- 실험결과
상당히 무난하게 흐름이 잘 잡힌거 같습니다. 그러나 writing을 참고하실 분들이 아니고서는 바로 방법론으로 가셔도 무난할거 같습니다. Related work도 그다지 읽어보시걸 추천드리고 싶지는 않습니다. 아무래도 한 두 문장으로 관련논문들을 설명하기도 어려울 뿐더러, 모든 RCV 연구원님들은 익숙한 흐름일거라 생각되기 때문입니다.
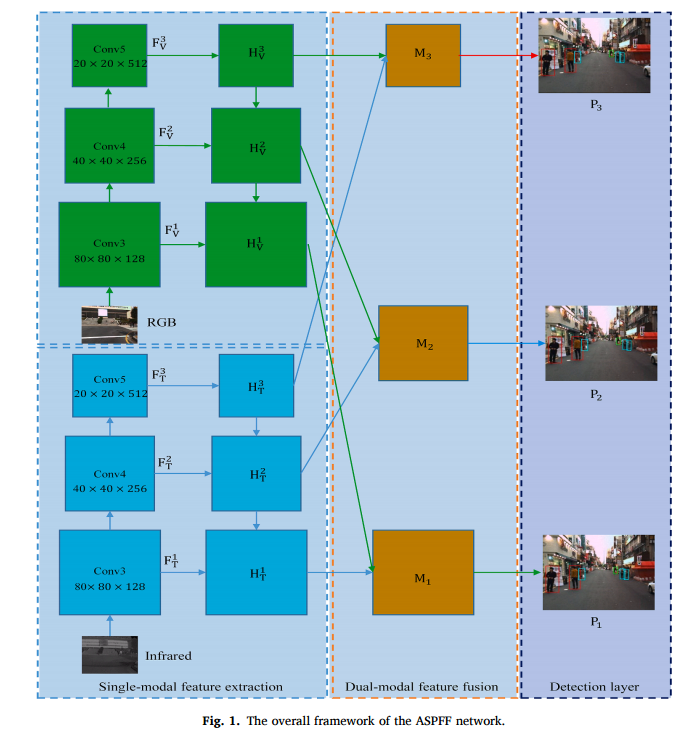
첫번째 피규어입니다. 만약 제가 저자라면, 그림이 좀 안 예쁜게 아쉽지만, 그래도 직관적으로 이해하는데 어려움은 없습니다. 높은 정확도와 real-time detection을 위해서 YOLO 5를 백본으로 사용하였고, 그렇기에 스케일이 다른 디텍션 레이어가 총 3개입니다. 그리고 각각의 디텍션 레이어는 Classification branch 와 regression branch를 갖습니다.
RGB와 Infrared 이미지는 각각 FPN구조로된 Conv layer를 거치고, Single-modal feature extraction 및 Dual-moal feature fusion방식을 활용하여 피쳐를 뽑아냅니다.

일반적인 attention기반의 멀티스펙트럴 보행자인식 연구에서는 위와 같이 Visible과 Thermal의 피쳐에 weight를 곱한 값의 합으로 나타내어집니다. 그러나 저자는 이는 너무 단순하다고 평하고, 좀 더 진보된 방법을 제안합니다. 자세한 설명은 뒤에서 하겠습니다.
결국엔 YOLO기반으로 네트워크를 설계하고, 어떤식으로 피쳐들을 합쳐서 멀티모달 피쳐를 잘 융합할지에 대한 연구입니다. 결과론적으로 SOTA방법론보다 좀 더 복잡한 Attention 방법론이라고 생각이 되어지는데, 성능은 복잡도에 비례하진 않나봅니다.
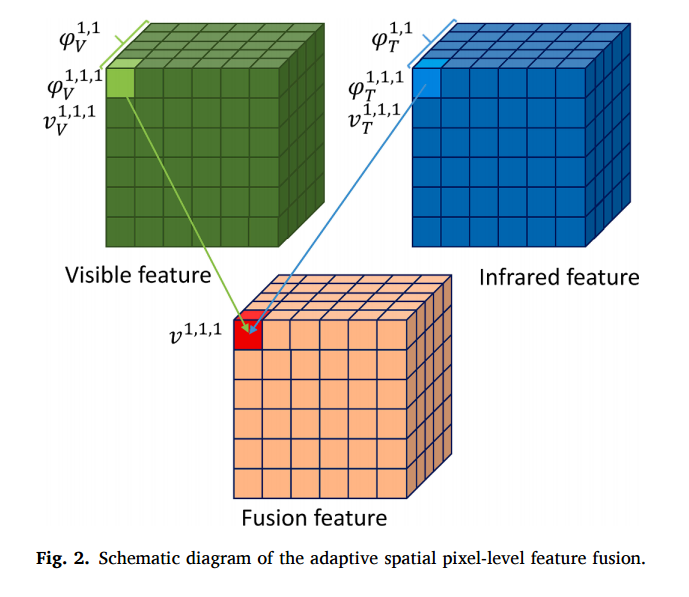
또한, Attention 기법에는 Spatial한 정보와 pixel-level에 대한 정보가 반영를 각각 반영하는 기법이 있습니다. 위의 그림이 그 원리이며, spatial한 정보에 따라서 파이^(1,1) 과 같이 weight 파라미터가 정해지며, 또한 각각의 픽셀에 따라서도 파이^(1,1,1,)과 같은 다른 weight 파라미터를 가집니다. 즉, 서로다른 두개의 weight 파라미터를 가지게 되는데요. 해당 논문에서는 첫번째 spatial 파라미터를 얻기위해 SAM이라고 불리는 모듈을 사용하였고, 두번째 pixel-level 파라미터를 위해서 PAM 모듈을 사용하였습니다. 뒤에서 더 자세히 설명하겠습니다.
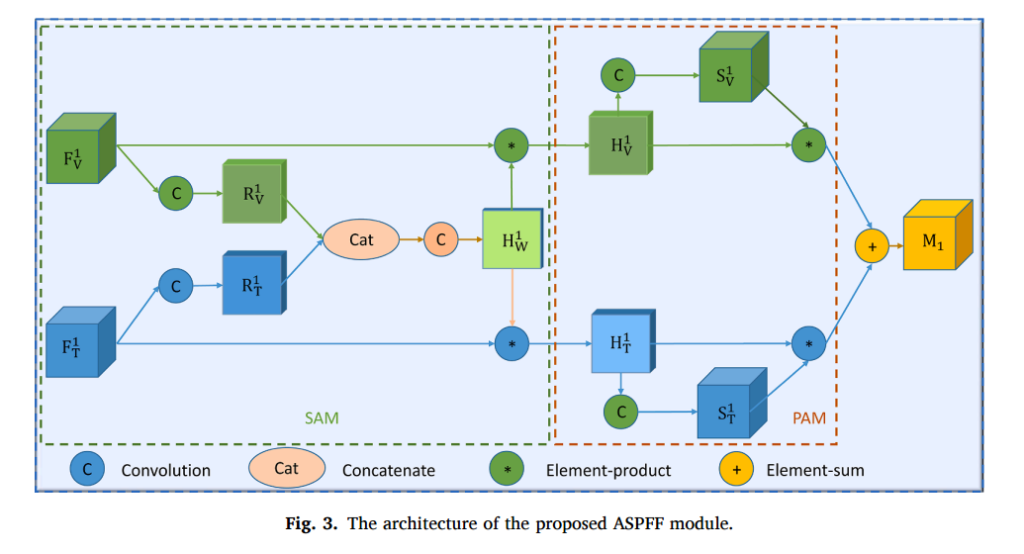
그리고 해당 Fusion Feature를 만드는 방법은 위와 같습니다. 저번 SOTA논문에 비해서 뭔가 더 복잡한건 느끼실 수 있으실 겁니다.
Notation을 모르면 이해하기 힘들기 때문에 수식과 같이 설명해드리겠습니다.

위에서 언급한것처럼 F는 Thermal이나 Visible에서 i번째 레이어의 피쳐맵입니다. 해당 아키텍쳐에서는 총 3개의 다른 스케일로부터 피쳐를 뽑아내므로 i는 {1, 2, 3}이 됩니다.

각각의 피쳐는 그림상에 C라고 표기된 Compound Conv 레이어를 통과합니다. (해당 Compound Conv 레이어는 3×3 필터에 128채널을 가지는 Conv layer와 1×1에 128 채널을 가지는 Conv 레이어 및 Batch Norm, Leaky ReLU이 묶여 잇는 형태입니다. ) 수식 (6)하고 (7) 에서의 phi는 해당 Compound Conv의 weight값을 의미합니다.
그렇게 구한 R 값은 Channel 에 stack하는 형식으로 Concatenate 되고, 1×1 Convolution이 태워집니다. 여기서 Compound Conv하고 그냥 1×1 conv 모두 그림상에는 C 라고 표기되어있는데 헷갈리지 않아야겠네요.

그렇게 구한 H값은 sigmoid를 한 후 앞의 피쳐와 곱해줍니다. 즉, attention을 주기위한 weight값으로 사용됩니다. H와 F 의 차원이 맞지 않느냐고 하실 수 있지만, 위의 수식에서 [1]과 [2]는 채널정보에서 vis에 대한 정보, thermal에 대한 정보를 의미합니다. 즉, 피쳐가 128 차원이라고 한다면, H는 256차원이 될것이고, H[1], H[2]는 각각 128차원씩 될 것 입니다.
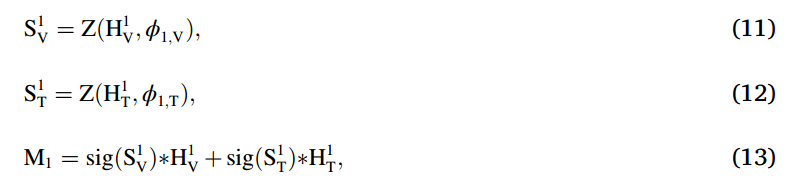
비슷한 과정을 거치면서 최종적으로 M을 얻어내며, 특이한점이라고 한다면 Attention을 주기위한 weight가 두번 사용된단점 입니다. 앞에서 쓰인 attention weight 는 공간정보를 반영해주고, 뒤에서는 pixel-level에 대한 정보를 반영해줍니다. 개인적으로 attention 기법에 대한 배경지식이 많이 없고 나이브한 방법만 봤어서 그런지 신박하단 생각이 드네요.
평가
평가는 카이스트셋에서만 진행하였고, 평가지표세팅은 MLPD와 같이 55픽셀이하는 버리고, 10^0~10^-2 구간에서의 MR기준으로 평가하였네요.
사용한 테스트셋은 아래와 같이 설명하네요.
As mentioned above, problematic labels can adversely affect the effectiveness of the algorithm and cause difficulties in interpretation. Therefore, in the ablation analysis, clean training and testing datasets were used to avoid the impact of labeling problems [25].
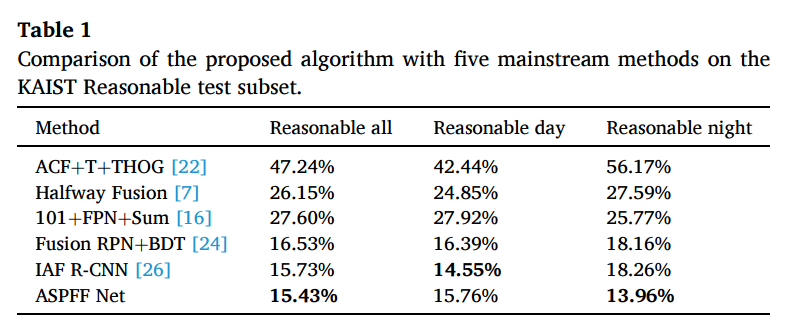
그래서 논문에서 제안하는 Attention기법을 사용하였을때 결과는 위와 같았구요.

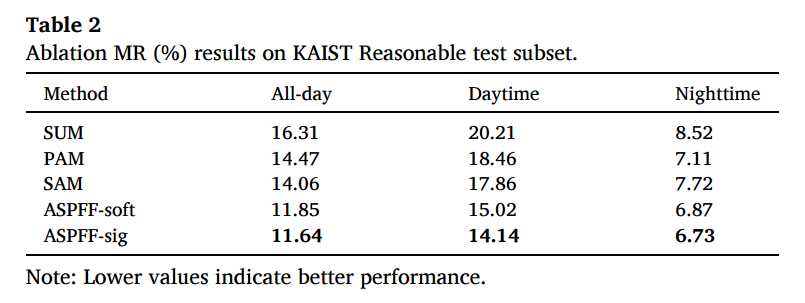
Ablation study에서는 각각의 방법론이 적용되었을때와 softmax를 sigmoid로 바꾸었을때의 성능차이를 리포팅합니다.

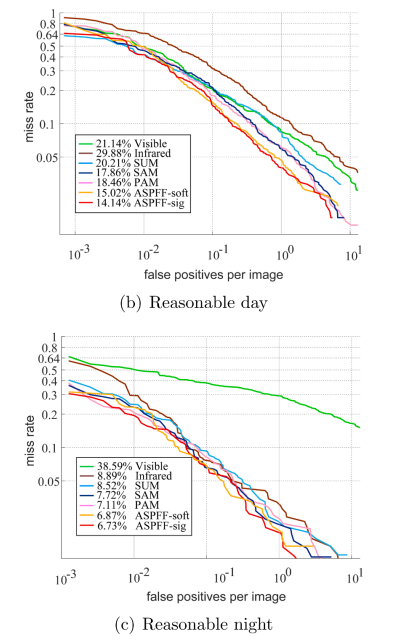
MR-FPPI 커브도 보여주고요.
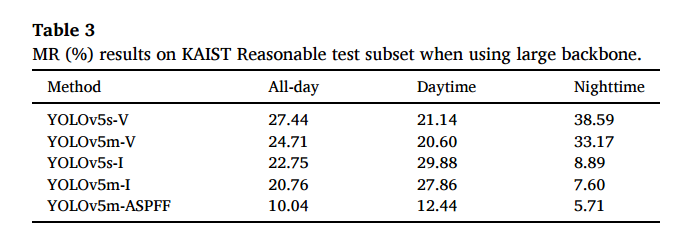
YOLO 백본의 네트워크 크기에 따른 성능차이도 리포팅합니다.

그리고 테스트셋의 특성에따라 나눈 서브셋에서의 성능도 리포팅합니다.
결론적으로 보면 실험이 많이 부실하네요. 왜냐면 해당 워크 자체에서 내세우는 주장이 speed-accuracy 간의 trade-off 관계를 balancing할 수 있는 attention 기법인데, 정작 speed에 관련된 리포팅은 없네요. YOLO를 사용한게 Real-time application이라고 하였는데 기존 방법론들과의 속도차이 리포팅이 없는게 큰 단점 같네요.
training 코드가 없어서 못했다고 하면 적어도 YOLO-m하고 YOLO-s 간의 속도차이 정도는 리포팅 해야하지 않았나 싶습니다. 여러모로 아쉬움이 남는 논문인데 일단 spatial&pixel-level의 attention기법을 동시에 적용하는 아이디어와 방법론부분 서술방식의 간결성 등… 배울점이 있었던 논문인거 같습니다.
해당분야에 정말 많은 분야가 있는것 같습니다. 이번 컴퓨터비전 수업에서 SOTA 복원하신다고 하셔서 매우 기대하고 있습니다. 마지막에 말씀하신 것처럼 속도차이가 없는게 아쉬운데, 말씀하신 것처럼 training 코드가 없어서는 아닌 것 같습니다. 왜냐면 MBNet과 AR-CNN 모두 속도를 리포팅하고 있으며, 저희도 이번에 그러한 속도를 포함해 논문을 작성했기 때문입니다. 그렇다면 속도를 포함하지 않은 이유는 아마도 속도가 느려서 그러지 않을까 생각합니다.
말씀하신 이유일수도 있고, 그 밖의 이유를 추정하자면 아마 Ablation study에서 사용한 subset같은 경우엔 속도를 리포팅 할 수 없었고, 뒤에 9개의 subset에서 평가한건 말씀하신대로 속도가 느리고, gpu, cpu등의 조건이 너무 달라서 fair comparison이 불가능했기 때문에 빼지 않았나 싶습니다.