본 페이퍼는 이번 방학 논문주제를 한전과 연계한 Anomaly Detection을 수행하자는 김형준 연구원의 이야기를 듣고 실제 ICRA에서 Anomaly Detection과 관련해 어떻게 논문이 작성됐는지 확인하기 위해 읽어보았습니다.
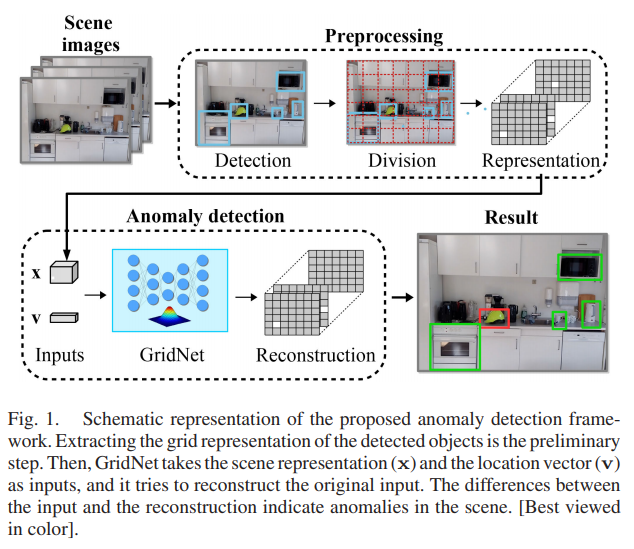
본 논문의 티저영상입니다. Scene 데이터가 들어오면 먼저 Detection을 수행하고, Detection 된 object의 센터를 구한이후 해당 이미지와 같은 크기의 grid matrix를 만들고 object center가 속한 영역은 1 그렇지 않은 영역은 0으로 나타내는 Scene grid representation을 만들게 됩니다. 그리고 이러한 Scene representation과 location vector를 이용해 Anomaly detection을 수행한다고 합니다. 이때, 저자가 제안하는 GridNet의 입력은 Scene grid representation과 location vector이며 raw image를 사용하지 않기 때문에 image-agnostic한 anomaly detection이라고 합니다. 이러한 내용을 아래 그림2와 같이 나타냈습니다.
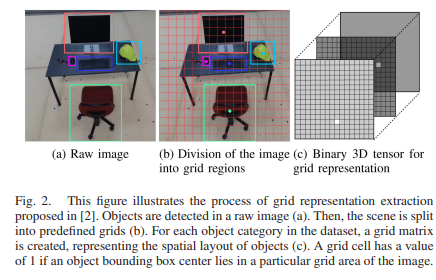
자 그러면 논문에 대해서 설명하기에 앞서 본 논문에서 정의내린 Anomaly object는 무엇일까요? 논문에서 저자는 ‘object that are out of the context of a scene’ 을 Anomaly object으로 정의합니다. 그러면 이러한 Anomaly object을 찾기위한 GridNet에 대한 아키텍처부터 확인하겠습니다.
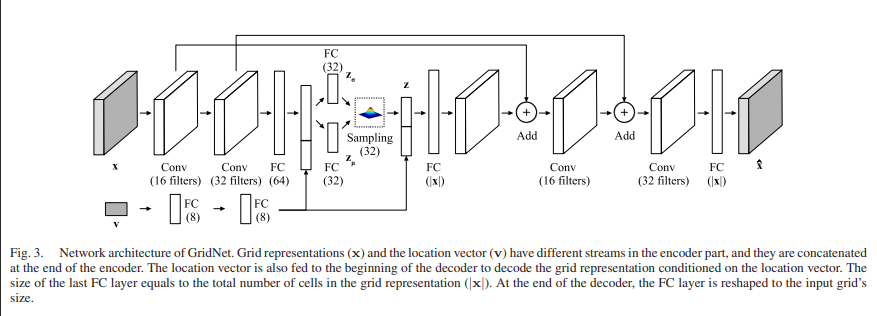
위에 그림은 본 논문에서 제안하는 GridNet의 아키텍처 입니다. 아키텍처는 3개로 나눌 수 있으며 Encoder, Sampler, Decoder로 나눌 수 있습니다.
잠깐 여기서 Anomaly Detection에 대해서 잘 모르시는 분들을 위해서 잠시 그림과 글을 가져오겠습니다. 해당 그림과 글은 이호성님의 블로그에서 가져왔습니다. (아시는분은 스킵하셔도 됩니다.)
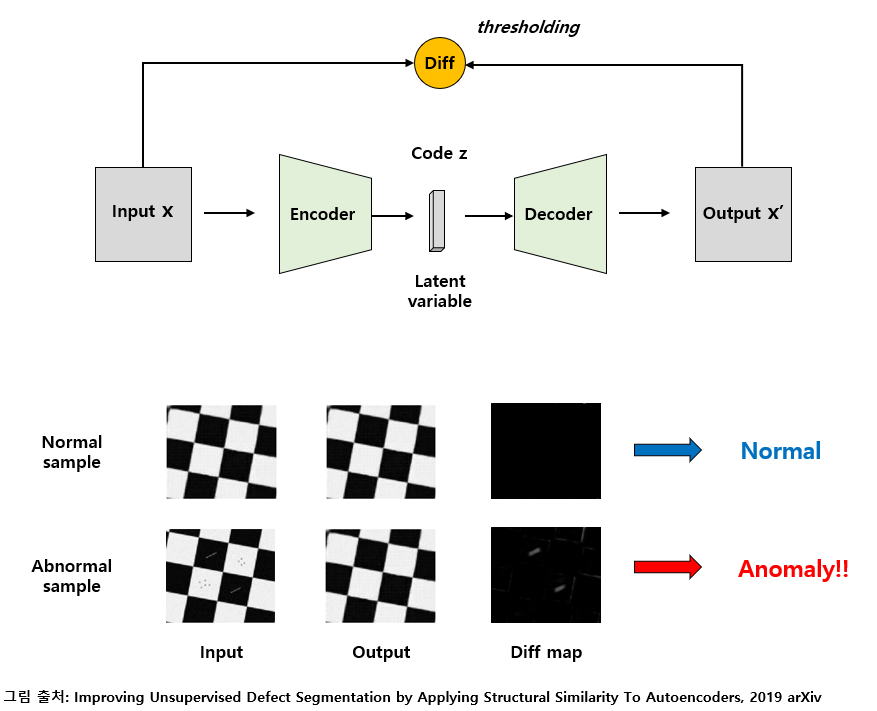
Autoencoder를 이용하면 데이터에 대한 labeling을 하지 않아도 데이터의 주성분이 되는 정상 영역의 특징들을 배울 수 있습니다. 이때, 학습된 autoencoder에 정상 sample을 넣어주면 위의 그림과 같이 잘 복원을 하므로 input과 output의 차이가 거의 발생하지 않는 반면, 비정상적인 sample을 넣으면 autoencoder는 정상 sample처럼 복원하기 때문에 input과 output의 차이를 구하는 과정에서 차이가 도드라지게 발생하므로 비정상 sample을 검출할 수 있습니다.
다만 Autoencoder의 code size (= latent variable의 dimension) 같은 hyper-parameter에 따라 전반적인 복원 성능이 좌우되기 때문에 양/불 판정 정확도가 Supervised Anomaly Detection에 비해 다소 불안정하다는 단점이 존재합니다. 또한 autoencoder에 넣어주는 input과 output의 차이를 어떻게 정의할 것인지(= 어떤 방식으로 difference map을 계산할지) 어느 loss function을 사용해 autoencoder를 학습시킬지 등 여러 가지 요인에 따라 성능이 크게 달라질 수 있습니다. 이렇듯 성능에 영향을 주는 요인이 많다는 약점이 존재하지만 별도의 Labeling 과정 없이 어느정도 성능을 낼 수 있다는 점에서 장단이 뚜렷한 방법론이라 할 수 있습니다.
하지만 Autoencoder를 이용하여 Unsupervised Anomaly Detection을 적용하여 Defect(결함)을 Segment 하는 대표적인 논문들에서는 Unsupervised 데이터 셋이 존재하지 않아서 실험의 편의를 위해 학습에 정상 sample들만 사용하는 Semi-Supervised Learning 방식을 이용하였으나, Autoencoder를 이용한 방법론은 Unsupervised Learning 방식이며 Unsupervised 데이터 셋에도 적용할 수 있습니다. Autoencoder 기반 Unsupervised Anomaly Detection을 다룬 논문들은 다음과 같습니다.
- Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
- Deep Autoencoding Models for Unsupervised Anomaly Segmentation in Brain MR Images
- MVTec AD – A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection
본 논문도 위와 같은 방법을 사용하는 것을 아키텍처 구조를 통해 확인하실 수 있습니다. 다시 해당 논문으로 돌아가 아키텍처의 3가지 모듈에 대해서 설명하자면 먼저 Encoder 입니다.

인코더의 경우 grid vector인 x와 location vector인 v를 입력으로 받습니다. 그리고 그에 대한 출력으로는 latent distribution의 평균과 분산이 되겠습니다. 그리고 이러한 인코더의 출력을 샘플러에서 파라미터로 받게되는데, 여기서 샘플러는 VAE(Auto-Encoding Variational Bayes) 논문에서 제안된 방법으로 zero-mean Gaussian에서 뽑히 노이즈를 평균과 분산을 더하고 곱해줘서 sampled latent representation인 z를 만드는 과정입니다. 이를 통해서 역전파가 가능하고 인코더도 학습이 가능합니다. 자세한 내용은 여기에서 확인하실 수 있으며 수식은 아래 (2) 와 같습니다.
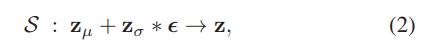
마지막으로 디코더는 이렇게 만들어진 latent representation z를 다시 Origianl input으로 Reconstruct하는 과정이며 수식은 다음과 같습니다.
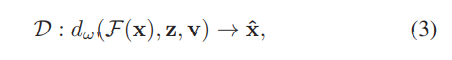
전체적인 구조는 이전의 연구들과 같지만, 저자가 이야기하는 핵심은 해당 논문에서 제안한 아키텍처는 raw image가 입력이 아닌 새롭게 정의한 grid vector와 location vector를 입력으로 한다는 점 입니다. 이와 같이 기존의 연구들과 입력이 다르기 때문에 저자는 Loss또한 새롭게 설계하여 제시하고 있으며, 이를 저자는 ‘Grid Loss’라고 명명하였습니다.
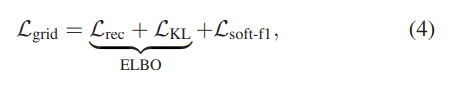
따라서 VAE에서 제안한 Loss에 새롭게 L_(soft-f1) loss term을 추가하였고 이를 저자는 Grid loss라고 이야기합니다. ELBO Loss의 경우 위에서 링크한 블로그에서 자세히 설명하고 있으므로 생략하고, 추가적으로 저자가 제안한 Loss에 대해서 확인하면 다음과 같습니다.

가장 먼저 저자는 입력으로 들어가는 Grid representations나 모델의 출력인 reconstructed grid representations나 모두 0과 1로 이뤄진 binary matrix라고 생각할 수 있습니다. 따라서 이 두 0과 1로 이뤄진 매트릭스를 통해서 다음수식 (8) 같이 TP,FP,FN을 구할 수 있습니다. 해당 수식에서 r은 row, c는 columns, o는 depth(channel)을 의미하며 σ는 sigmoid function을 의미합니다. T는 normalization을 위한 상수로 T = r*c*o로 나타낼 수 있습니다. 그러면 이렇게 구한 TP, FP, FN을 가지고 최종적으로 저자는 다음과 같이 L_(soft-f1) loss term을 설계합니다.

저자는 이러한 새로운 loss term을 설계한것도 contribution이라고 이야기하며, 이러한 Grid Loss는 reconstruction performance를 향상시켜준다고 합니다. 마지막 contribution은 데이터셋 입니다. 논문에서 저자는 실제촬영, 시뮬레이션, 모형 등으로 데이터셋을 제작하였습니다.

본 논문에서는 앞서 설명했듯 Anomaly object를 ‘object that are out of the context of a scene’라고 정의하였으므로, 해당 object의 빨간색으로 표기가 된것을 확인할 수 있습니다.
EXPERIMENTS AND RESULTS
본 논문에서는 다양한 베이스라인과 자신들의 GridNet에 대해서 자신들의 데이터셋을 평가한 결과를 나타내고 있습니다.
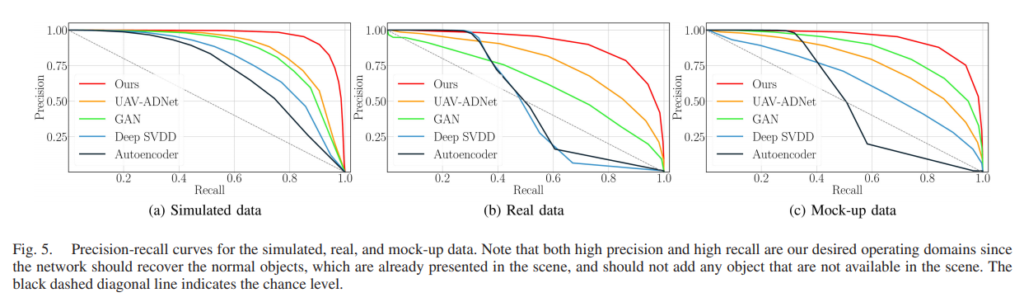
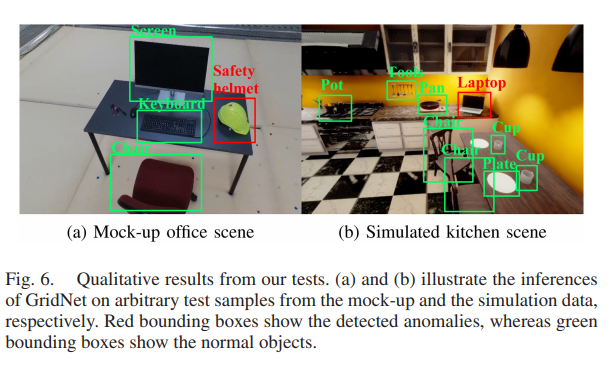
보시는것처럼 본인들의 방법이 가장 좋은 성능을 나타내며 실제 정성그림을 봐도 ‘object that are out of the context of a scene’ 로 보이는 것들을 찾고 있습니다. (신기하네요.., 오버피팅이 아닐지 의심됩니다만 다른 모델과의 비교가 있으니…)
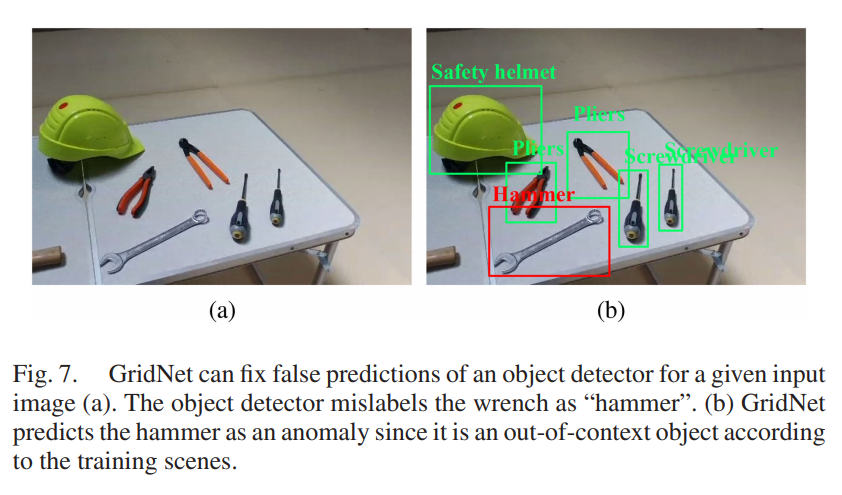
또 이러한 GridNet은 false prediction을 fix하는데도 영향을 미치며 이는 object detection의 성능향상을 이끌 수 있을 것이라고 저자는 이야기합니다.
결론
Anomaly Detection에 대해서 알 것 같다가도 논문을 읽으면서 점점 헷갈리는 것 같습니다. 다른 논문들을 읽어가며 점점더 감을 잡아야할 것 같고, 해당 논문을 통해서 새로운 데이터셋을 제작하고 해당 데이터셋을 통해 Contribution을 가져가며 동시에 ICRA에 억셉이 되려면 위의 저자와 같이 다양한 모델을 통한 비교는 필수적이며 동시에 데이터셋 뿐만 아니라 새로운 방법론도 제시해야할 것 같습니다.