[논문 Link]
논문에서 정의한 문제:
deep neural network optimization을 자동적으로 하지 못하는 이유는 무엇일까? 대부분의 학습이 학습의 상황(훈련된 모델 등)에 의존적이기 때문이다. 해당 연구는 일반화에 초점을 맞춘 새로운 시스템과 그 동기를 제안한다.
제안한 해결책:
learned hyperparameter optimizers(LHOPTs)를 제안하며, 기존의 hand-designed optimizer는 data-driven 속성을 지녔다고 언급한다. 제안하는 관리법은 tuning이 필요하지 않으며 turn이 필요한 다른 방법과 비교하였을 때 빠른 학습 속도와 높은 성능을 보였다. 논문에서 소개하는 optimizers는 모든 상황에 가장 좋은 선택은 아니지만, 일반화를 위한 새로운 접근이며, 일반화를 위한 연구들에 영감을 주기위한 논문이라고 한다.
related work:
해당 연구는 1)parameter updates를 위하여 neural networks를 사용하는 연구들과 2)Loss로 부터 직접 gradients를 결정하는 hypergradients라는 방법론으로 부터 영감을 받았다고 한다. 제안하는 방법은 1), 2)의 논문들을 포함하는 접근법이며, 두 논문들의 실험이 small datasets에서만 진행하였다면, 해당 논문에서 large scale일반화 할 수 있음을 보였다고 한다.
방법론:
3. Learning Hyperparameter Updates 가 가질 장점
학습을 기존의 parameter 업데이트를 위한 학습과 제안하는 hyperparameter update를 위한 학습 두가지를 비교할때 제안하는 방법이 갖는 두가지 특징이 있다. 첫째로 inner optimization task에서 분리될 수 있다. 즉, graident에 직접적으로 영향을 받지 않는다는 것인데, overfitting을 방지하고 우리의 policy(학습 정책)에 대한 유연성을(자유도)를 가질 수 있다고 한다. 물론 gradient에 직접적인 영향을 받지 않아 학습이 의도하지 않는 방향으로 갈 수 있다는 점은 주의해야 한다.
둘째로는 업데이트에 대한 자유도를 갖는다. 기존의 방식은 task가 업데이트 할 때마다 업데이트 하였다면 제안하는 방식은 task의 업데이트와 무관하게 필요할때 자유롭게 업데이트 될 수 있다는 점이다.
3.1 문제 설정
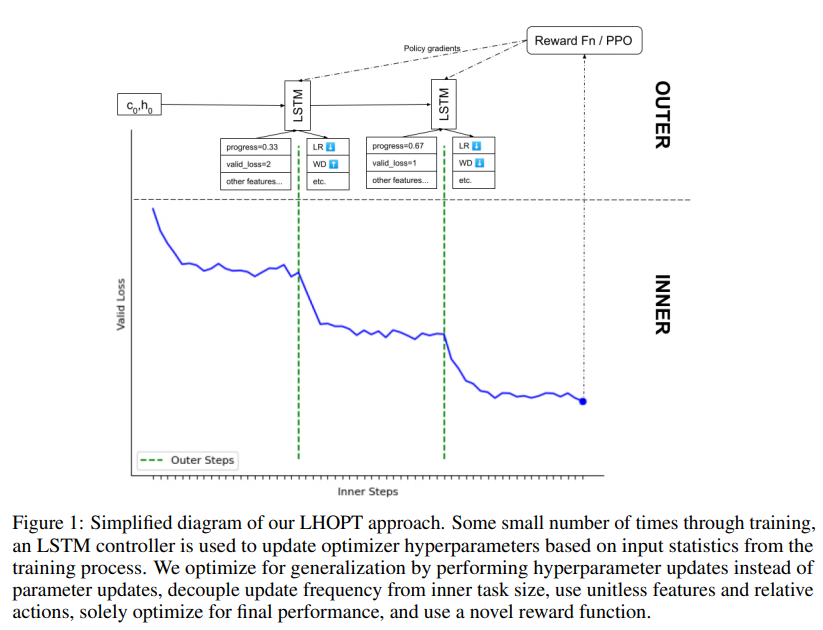
LHOPTs는 하나의 inner task에 적용하기 위해 디자인 되었다. 문제 해결을 위해 Inner step, outer step을 두가지로 구성하였는데, Inner step으로 생성된 feature의 정보를 policy network로 전달시키기 위해 outer step 을 구성하였으며 Outer step의 PPO algorithm이란 final loss를 reward로 하여 policy network의 upate weights를 정하는 알고리즘이다.
3.2 feature space
저자들은 inner optimization task에 집중하는 것이 아닌 일반화 된 policy 구성을 위하여 feature space를 디자인 하였다.
1. 좋은 일반화를 보장하기 위해, 모든 toy problem과 massive scale models이 모두 유사한 형태를 갖기를 원했다. (“unitless features”를 원했다)
이를 위하여 gradient, loss value와 같이 직접적인 내부 최적화 과정을 사용하지 않고, log-ratios, cosine similarities, averages of booleans (=CDF 특징) 와 같은 변환적 방식을 사용하였다고 한다.
다음으로 Reward Function과 Optimizer 와 같은 상세 내용은 다음 리뷰에 이어서 작성하겠습니다.