본 논문은 단일 이미지를 통해서 3D Object detection을 수행한 논문입니다. 본 논문을 설명하기 앞서 필요한 몇가지 개념들에 대해서 이야기하겠습니다.
기존 Convolution은 커널의 크기만큼 부분적으로 연산을 수행합니다. 따라서 기존 Convolution 연산은 local neural network로 말할 수 있는데, 우리는 local에서 연산을 수행하기 때문에 좁을 수 밖에 없는 receptive field를 넓히기 위해서 Convolution을 여러 층을 만들거나, Pooling layer를 사용하고 있습니다. 하지만 이러한 방식들은 연산량 대비 효율적이지 못하다는 단점이 있습니다. 그 유명한 Ross Girshick, Kaiming He 두분이 포함된 연구진은 이러한 문제를 해결하고자 non-local 한 연산 방식을 ‘Non-local Neural Networks’라는 논문에서 소개하고 있습니다. [PR 유트브 보기]
위에서 링크한 페이퍼 리뷰 링크에서 자세하게 설명하고 있으며, 간략히 요약하자면 논문에서는 Non-local Means Filter (NLM Filter)의 방법에서 convolution 연산시 패치(or 픽셀) 단위의 유사도가 포함된 새로운 non-local block 구조를 제안하고 있습니다.
여기서 NLM Filter란 기존에 연속적으로 촬영된 여러 프레임의 평균값을 이용해 각각 단일 이미지의 노이즈를 제거하는 기법이 있었는데, 해당 방법을 개선하여서 동일 이미지에서 비슷한 구간에 대해서 평균을 구해서 노이즈를 제거하는 필터 기법이라고 합니다.

우리 모두가 알고있는 위의 그림에서 p지점은 q1,q2와 같이 유사한 구조를 나타내기 때문에 이와같이 같은 이미지 내에서 유사한 구조를 갖는 패치(?)들의 평균을 구해서 노이즈를 제거하는 기법입니다.

이와 같은 컨셉에서 non-local neural networks에서도 같이 유사도(Similarity)를 구하는 텀을 추가하였습니다. 논문에서 유사도 방법에 따른 큰 차이는 없지만 그래도 유사도를 추가하는 방식이 효과적이였다고 합니다.
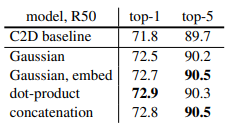
정리하면, 기존 Convolution neural networks의 방법에서 취했던 비효율적인 receptive field를 넓히는 방법의 개선 방안으로, Attention과 유사한 방식으로(해당 내용은 유튜브 영상참고) non-local block을 제안한 논문이였습니다.
Deformable Convolutional Networks
또다른 하나의 논문이 필요한데, 바로 Deformable Convolutional networks입니다. 해당 네트워크는 기존 anchor based Object Detection이 기하학적으로 일정한 패턴을 가정하고 있어서 복잡한 transformation에 유연하게 대처하기 어려운 한계를 극복하기 위한 방법입니다.

해당 그림이 핵심인데, 기존에는 일정 간격(grid)로 진행하는 일반적인 3×3 convolution(a)와는 다르게 grid에 offset을 추가하여서 (b),(c),(d) 처럼 다양한 패턴으로 변형을 일으키는 방식으로 convolution을 수행하는 것을 의미합니다.
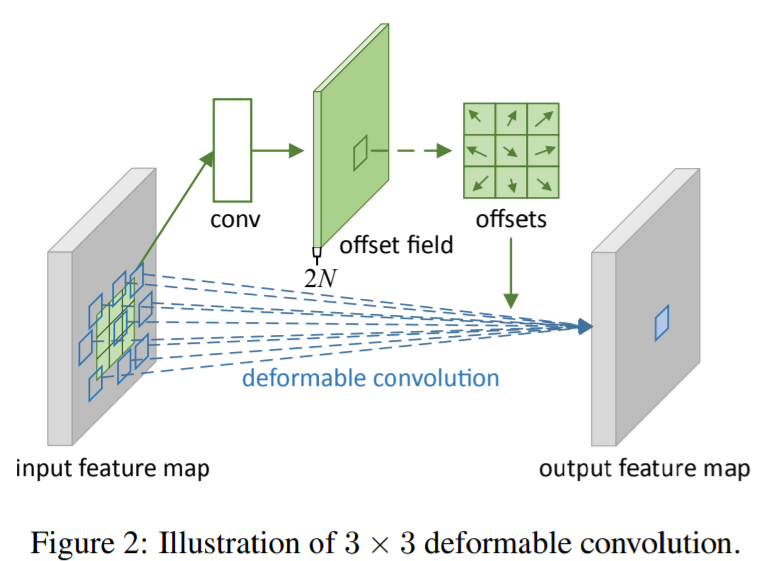
위의 그림과 같이 단순 일정한 간격의 3×3 큐브를 가지고 convolution을 하는게 아니라 offset을 구할 수 있는 네트워크를 통해서 기존 격자에서 offset을 반영하여 convolution을 수행하는 방법이라고 생각하시면 됩니다.
Introduction
자 다시 본론으로 돌아와서 그러면 해당 논문에서는 3D Object Detection을 수행합니다. 그리고 앞서 설명한 방법들을 적용하고, 개선하였습니다. 본 논문에서 이야기하는 Contribution은 다음과 같습니다.
- We propose a simple but very efficient monocular 3D single-stage object detection (M3DSSD) method. The M3DSSD achieves significantly better performance than the monocular 3D object detection methods on the KITTI dataset for car, pedestrian, and cyclist object class using one single model, in both 3D object detection and bird’s eye view tasks.
- We propose a novel asymmetric non-local attention block with multi-scale sampling for the depth-wise feature extraction, thereby improving the accuracy of the object depth estimation
- We propose a two-step feature alignment module to overcome the mismatching in the size of the receptive field and the size of the anchor, and the misalignment in the object center and the anchor center.
자세한 내용에 대해서는 뒤에서 설명하겠습니다.
Method
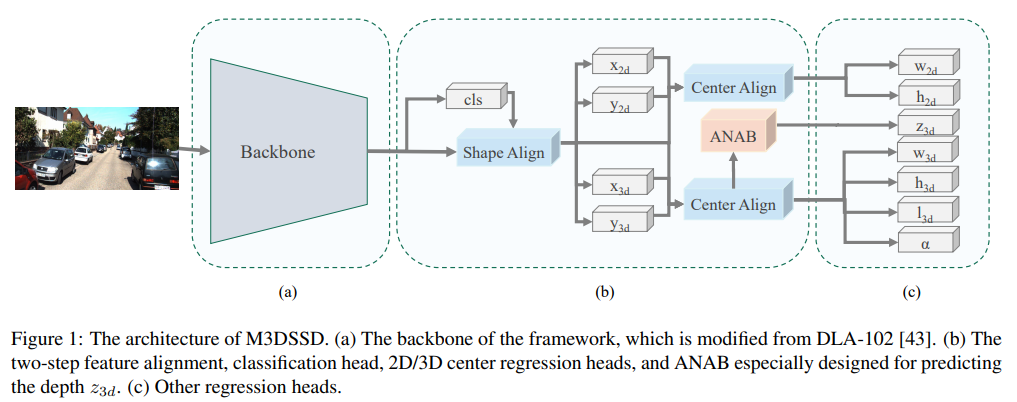
본 논문에서 제안하는 3D Object Detection 아키텍처는 위에 그림과 같습니다. 위에서 output은 2D의 outputs으로는 w,h 3D의 outputs으로는 z,w,h,l,a로 나눌 수 있습니다. 먼저 2D의 출력인 w,h는 모두가 아실거라고 생각하고, 3D 출력에 대해서 이야기드리면, z는 depth입니다. 논문에서는 더욱 정확한 depth값을 예측하기 위해서 receptive field를 효과적으로 넓힐 수 있는 Asymmetric Non-local Attention Block을 제안하고 있습니다(뒤에서 설명). 또한 anchor based methods가 겪는 feature mismatching문제를 해결하기 위한 alignment 모듈을 제안하고 있습니다. 이때 Deformable convolution을 적용했다고 합니다.(비슷하지만 조금 다르게)
Feature Alignment
저자는 Feature alignment 문제를 2가지로 이야기하고 있는데, 첫번째는 feature의 receptive field가 anchor의 shape(ratio and size)과 일치하지 않는 문제가 있다고 합니다. 두번째로는 feature map의 receptive field의 중심으로 고려되는 anchor의 중심은 실질적으로 object의 중심과 일치하지 않는 문제가 존재한다고 합니다. 이를 해결하기 위해서 서자는 shape alignment와 center alignment를 제안합니다.
Shape alignment
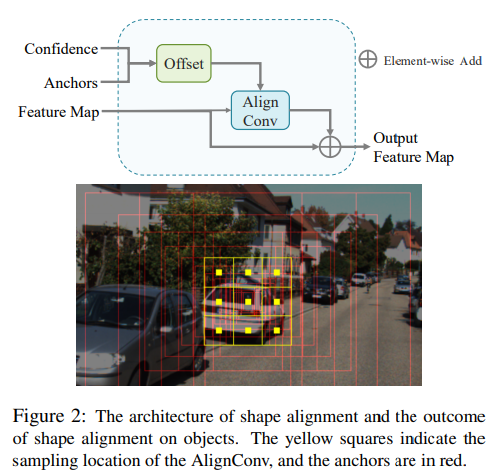
shape alignment는 일차적으로 backbone model을 통해 anchor들에 대한 confidence를 계산하고, 이를 통해 offset을 계상하여 해당 offset을 기반으로 deformable convolution과 동일하게 진행한다고 합니다. (차이점은 위에서 설명했듯 deformable은 이전 feature map으로 offset을 구했지만, 위에서는 confidence와 anchors를 통해서 offset을 구했다고 합니다.)
Center alignment
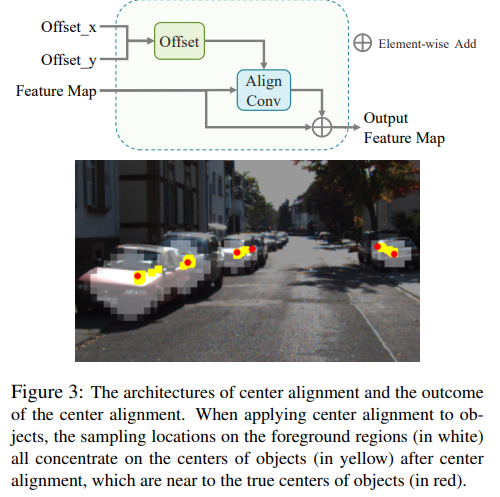
shape align 이후에 나온 featuremap을 통해서 2D/3D center regression을 수행하여 center에 대한 offset을 계산합니다. 그리고 예측된 offset을 이용해 center alignment의 center offset을 계산합니다. 위의 그림과 같이 기존 하얀색의 foreground regions에서 노란색의 center of object가 선정딘다고 합니다. 실제 빨간색이 GT라고 했을때 본인들의 방법을 통해서 실제 object center와 일치됨을 보여줍니다.
Asymmetric Non-local Attention Block
마지막으로 depth인 z의 정확도를 높이기 위해서 Asymmetric Non-local Attention Block을 제안합니다. 해당 리뷰 가장 초반부에 non-local Attention을 소개드렸고 수식은 다음과 같았습니다.
그리고 “Attention Is All You Need”라는 논문에서 이야기하는 attention function은 다음과 같습니다.
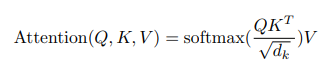
두 수식에서 비슷한점을 찾기 힘들수도 있지만 결국 f(x_i,x_j)와 softmax(QK^T/d_k)는 비슷한 역할을 하는 텀으로 볼 수 있고, 이러한 내용을 실제 non-local neural networks에서도 이야기하고 있습니다. (즉, Attention 기법에서도 receptive field가 넓은 이유와 실제 non-local에 대해서 receptive field가 넓은 이유가 비슷하다고 합니다.) 아무튼 이러한 컨셉을 착용하여서 본 논문에서는 non-local operation에 연산량이 많았던 문제들을 개선하는 새로운 방식을 제안합니다.
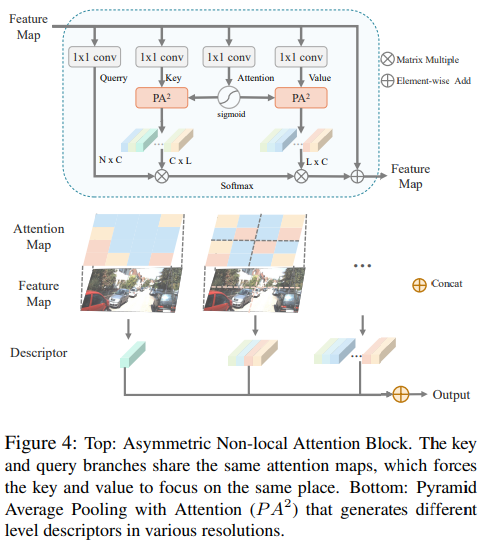
본 논문에서는 이러한 자신들의 방법이 훨씬 연산량이 적음을 논문에서 밝히고 있고 빅오로 나타내고 있습니다. (자세한내용은 클릭, 요약하면 O(N^2C)에서 O(NLC)로 줄였고 여기서 L은 무조건 N보다 작다고 합니다)
Experiments
해당 논문에서는 KITTI dataset에서 결과를 나타냈습니다.
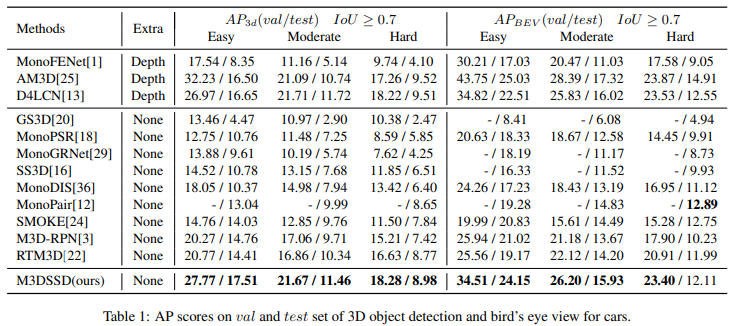
라이다 방법에 비하면 부족하지만, 그래도 단일 이미지 기반 3D Object detection에서 우수한 성능을 나타냈다고 합니다.
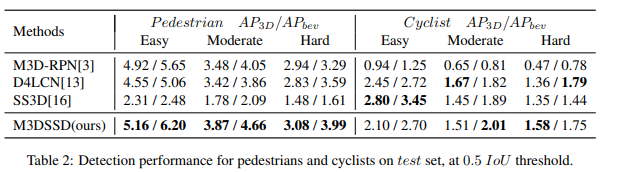
자동차뿐만 아니라 Pedestrian과 Cyclist에 대해서도 높은 성능을 나타냈습니다. (그래도 많이 낮네요..)
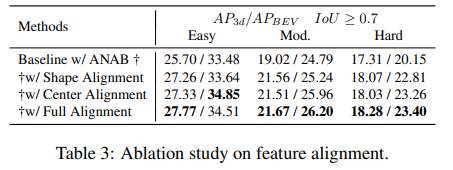
그리고 Ablation study도 진행하였습니다.
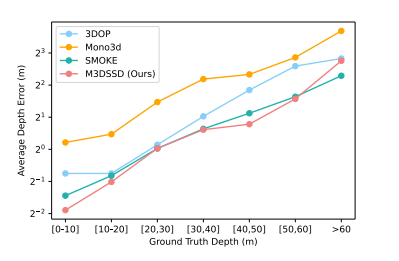
추가적으로 Depth estimation에 대한 error 도 기존대비 많이 낮췄다고 합니다.
그리고 앞서 말했던 Asymmetric non-local attention block에 대해서 연산량이 효율적이라고 이야기했으므로 이에 대해서도 다음과 같이 나타내고 있습니다.

원 Non-local 방법을 대체하였을때, 속도가 5.89ms에서 1.86ms로 줄어드는 것을 확인할 수 있습니다.
총평
본 논문을 통해 receptive field를 넓히기 위해서 non-local neural networks라는 방법도 알게됐고, attention과 비슷한 방식이며 실제 attention module을 추가로 적용할 수 있다는 방법도 알게됐습니다.
글 잘 읽었습니다.
본문 내용 중 “위에서 output은 2D의 outputs으로는 w,h 3D의 outputs으로는 z,w,h,l,a로 나눌 수 있습니다. 먼저 2D의 출력인 w,h는 모두가 아실거라고 생각하고, 3D 출력에 대해서 이야기드리면, z는 depth입니다.” 라는 내용이 있는데, 그럼 l, a는 무엇인가요?? 해당 부분은 설명 안하시고 넘어가셔서 괜히 궁금해지네요ㅋㅋ.
그리고 두번째로 Non-local Attention의 수식을 보여주며 transformer의 softmax(~~) 부분과 유사하다고 하셨는데, Non-local Attention에서 f와 g 함수가 어떠한 연산을 하는지에 대해서는 간략하게 설명을 적어주시면 transformer와 비교하였을 때 어떻게 유사한지에 대해서 보다 쉽게 이해할 수 있을 듯 합니다.
P.S.
“이를 해결하기 위해서 서자는 shape alignment와 center alignment를 제안합니다.” 부분과 “이를 통해 offset을 계상하여 해당 offset을 기반으로 deformable convolution과 동일하게 진행한다고 합니다.” 부분에 오타가 있습니다ㅎㅎ…