안녕하세요 이번에는 조금 신기한 주제로 X-review를 써보려고합니다. 그 주제는 바로 Grasping 인데요. 이는 로봇이 물체를 잡는 것을 뜻합니다. 물체를 잡기위해서는 해당 물체의 pose를 알아야하기에 6DoF pose Estimation과 관련이 높은데요. 여태까지 제가 해왔던 리뷰들이 6DoF Pose Estimation 쪽이 많았기 때문에 실제로 어떤식으로 활용되는지에 대한 궁금증에서 읽게된 논문입니다.
지난 몇달간 6DoF pose estimation 방법론에 대한 논문들을 많이 살펴보았지만, 실제로 로봇이 물체의 어떠한 위치를 집어야하는지에 대한 논문을 읽은적이 없었기 때문에 다소 어렵지만 신기한 개념이 많아서 재밌기도 했습니다.
좀 더 구체적으로 해당 논문을 고르게된 배경은 6DoF는 AR, bin picking, robotic arms, grasping 등등… 많은 적용분야가 있지만, 실제로 해당 분야들을 잘 아는건 아니라서, 구글 스칼라에 그 중 한개인 grasping을 검색하여 찾은 논문입니다. 몇몇의 논문들이 나왔는데 2020년 이후 논문들중에 citation이 어느정도있고, 제목이 마음에 들어 선택하였습니다.
그럼 저와 같이 흥미를 느끼신 연구원 분들을 위해서 본격적으로 리뷰 시작 하겠습니다.
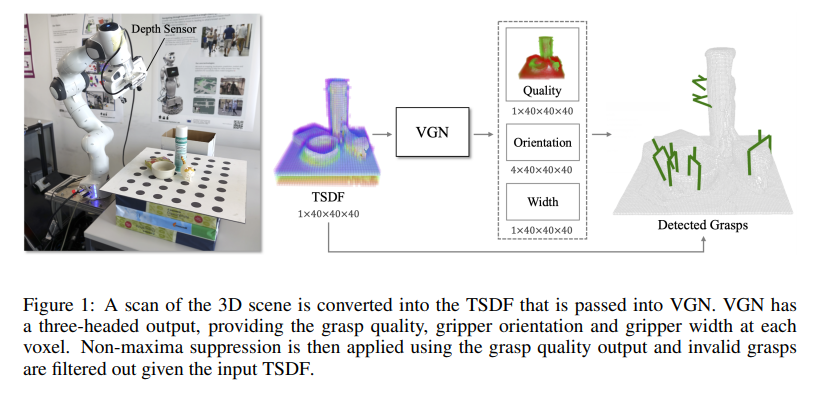
해당 논문에서는 로봇팔을 이용하여 물체를 잡아서 workspace 바깥으로 옮기는 task를 진행합니다. 좀 더 구체적으로 물체들이 있으면 어떠한 방법으로 grasp를 해야하는지에 대한 정보를 regression합니다. 평소에 제가 했던 리뷰들이 6 DoF에 대한 자세추정이 주된 쟁점이라면 이번 내용에서는 6DoF 자세추정 자체는 나이브하게 directly regression하는 방법을 사용하고 있습니다. 다만 그 외에 컨셉들이 다소 낯선 것들이 많았으며 신기 했습니다. 그를 위주로 리뷰를 해보겠습니다.
위의 그림의 예시를 보시면 왼쪽에 로봇팔이 있고, 그 오른쪽에 판위에 물건들이 놓여있습니다. 로봇팔에는 real-sensor가 달려있어 depth정보를 측정 가능하고 이를 이용하여 3D map을 만들 수 있습니다. 이 3D정보를 이용하여 30*30*30 크기의 workspace상에서의 물건들의 grasp하는 위치들을 알아내는 것이 주요 목표입니다. 그리고 그 알아낸 grasp 포인트들이 오른쪽 그림의 예시와 같습니다.
이 과정에서 처음 센서로 부터 얻은 3D정보는 Truncated Signed Distance Function(TSDF)을 통해 먼저 각각의 voxel마다의 truncated signed distance로 바뀝니다. 이 개념이 좀 난해한데 설명하자면 판위의 30*30*30의 workspace를 voxel화 하는데 이 때, voxel안의 각각의 cell 마다 nearest surface로의 distance를 포함하여 나타내는 방법이 바로 TSDF입니다. 즉, voxel화와 distance정보를 포함하는 representation 방법입니다. 해당 TSDF정보는 다시 Volumetic grasping network (VGN)을 거치며 피쳐맵을 뽑아내고, 해당 feature map을 이용하여 3가지 task를 동시에 수행합니다.
3가지 task를 위에서 부터 차례로 설명하자면, 먼저, quality 로 이는 0과 1사이의 확률을 의미합니다. 즉, grasping이 성공할 확률로 해당 값이 일정 threshold가 넘으면 성공했다고 간주합니다.
다음으로는, Orientation인데, 이는 gripper의 orientation을 의미합니다. gripper란 로봇팔에 붙어있는 손을 의미하는데 해당 로봇에서는 2개의 jaw를 가진 로봇팔이 사용되었습니다.
마지막으로, opening width를 구하는데 이는 로봇팔의 두개의 jaw가 벌어진 width를 의미합니다.
이렇게 총 3가지를 구하고 나면 최종적으로 grasps의 position이 나오게되고 위에서 보여지는 그림의 젤 오른쪽 detected grasps와 같습니다.
이 논문을 읽으면서 느낀게 6 DoF pose estimation만 하면 grasping task는 해결이 된다고 생각을 했는데 그게 아니라 생각보다 고려해야할 것이 상당히 많다는 것 입니다. 그런데 loss설계나 전체적인 컨셉은 6DoF pose estimation에서 주로 사용되는 개념들이 많이 들어있었습니다.
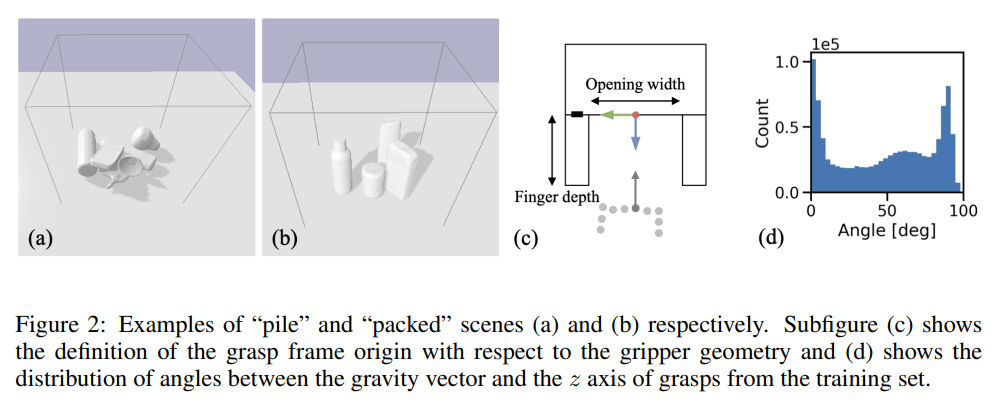
위의 그림을 보시면 (a)에는 물건들이 workspace상에 쌓여져있고 ,(b)에는 물건들이 정렬된상태로 있습니다. grasping을 해야할 때 고려해야하는 부분은 로봇을 위에서 아래로 집느냐, 옆에서 부터 집느냐를 생각해야합니다. (a)를 예로들면 위에서 아래로 집는게 유리하고, (b)에서는 옆에서부터 집는게 유리합니다.
이렇게 집는 방향에 따라서 다른물체와의 collision이 발생할 수 있기 때문에 기존 논문들에서 grasping을 할때에는 다른 물체와의 collision에 대해서 별도로 checking을 합니다. 그러는 과정에서 computation cost가 많이 발생하고, 이는 속도저하로 이어집니다. real-time operation이 매우 중요한 grasping task에서 해당 부분은 bottle neck으로 작용했습니다. 해당 논문에서는 하나의 workspace상에 3D 정보 전부를 받아서 사용하기 때문에 architecture 자체적으로 collision에 대해서 고려하게 된다고 가정합니다. 그리고 그 가정이 맞음을 실험적으로 입증하였습니다. 실험에서는 simulated된 환경과 real 환경에서 모두 진행하였는데 좀 더 자세히 뒤에서 소개하겠습니다.
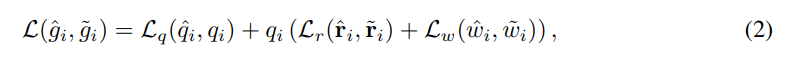
Loss 텀들은 생각보다 간단합니다. 총 3개로 이루어지는데 q r w는 각각 위에서 설명했듯이, quality, orientation, width에 대한 loss 항들 입니다. quality는 grasp할 확률을 의미하고, orientation은 gripper의 orientation, width는 gripper의 opening width를 의미합니다.
quality의 경우 binary cross-entropy loss를 사용하고, width와 orientation의 경우엔 mean squared error loss를 사용합니다. 사실 loss도 간단하고, orientation도 그냥 쿼터니안 형식으로 나타내고 regression만 하는 형태를 취합니다. 기존에 제가 리뷰했던 6DoF 방법론들은 directly 하게 regression하지 않고 PnP를 사용한다거나, 3D-2D correspondence, vector field등등… 다양한 개념들이 등장했습니다. 하지만 해당 로봇에서는 directly 하게 regression을 하는 것을 알 수 있습니다. 이는 아마도 computation time을 고려하여 내린 결정 같습니다. 물론 end-to-end라는 점에서도 이점을 가지고요.
이렇게 6 DoF pose를 구하는 방식이 간단한것을 보며 느끼는게 아직 robot에 성능이 좋은 네트워크를 싣는데는 한계가 있다고 생각이 듭니다. 음.. 무거운 모델을 넣으면 real-time으로 working하지 않기 때문에 이리 간단한 방법을 채택하지 않았을까요?
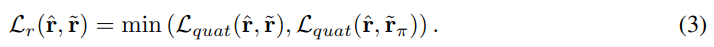
Loss중에 특이한점은 위의 수식인데요. 이것도 사실 기존에 제가 리뷰했던 ADD(s) 매트릭과 별반 다르지 않습니다. 개념과 원리는 비슷한데 활용처만 다른 느낌이네요. ADD(s)는 대칭인 object에서 모델이 제대로 추론을 했음에도 불구하고 penalized되는 현상을 막기위해 도입한 평가지표입니다.
이와 비슷하게 위의 수식도 gripper가 symmetric하기 때문에 도입한 loss입니다. 무슨 소리냐면, 2개의 jaw를 가지고있는 gripper는 180도 회전해도 같은 결과를 가집니다. 즉 정답값이 2개가 존재한다는 소리입니다. 그 2개중의 어떠한 정답값으로 prediction을 해도 모델이 올바르게 추론했다고 인지시켜주기 위해 180도 회전했을때의 결과도 구한 후에 min값을 취합니다.

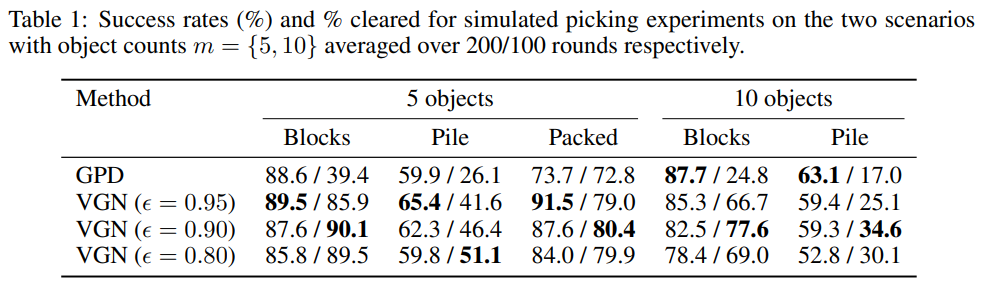

위의 내용들은 실험에 대한 내용들인데, python과 ROS의 RVIZ를 이용하여 시뮬레이션 테스트도 하였고, 실제 로봇에서도 실험을 하였습니다. 물체가 workspace상에서 놓여있는 방식에 따라 blocks, pile, packed로 나누었으며, workspace상에 몇가지의 종류의 object가 있는지에 따라서도 5개와 10개로 나누어서 실험을 하였습니다.
실제로 물체를 로봇을 잡는 실험을 하였을때는, 사람이 직접 물체를 넣으면 bias될 수 있기 때문에 박스를 이용하여 박스안에 물체를 넣어둔 후 흔들어서 물체를 뒤죽박죽 섞은 후 실험을 하였습니다.
개인적으로 이해하기 쉽게 잘 쓰여진 논문이라고 생각은 하지만, contribution이 좀 부족하고, 실험도 self-evaluation밖에 없다는 점이 좀 아쉬운거 같습니다. contribution은 real-time에서 가능했다, collision에 대한 별도의 checking없이 collision을 예방했다 정도 인거 같은데 사실상 설득력이 있진 않다고 생각합니다.
왜냐하면, real-time으로 robot을 구동시키기위해 어떠한 부분을 개선했다기보단 가장 나이브한 이미 존재하는 방법들을 가져다가 썼습니다. 또한, collision-free라고 표현을 하고있지만, 사실상 방법론 자체가 어떻게 collision-free를 만들 수 있는지에 대한 논리적인 이유가 부족했던거 같습니다. 그래서 실험적으로 보여주는데 이 또한 self-evaluation이라서 아무래도 설득력이 떨어지는게 사실인거 같습니다.
그럼에도 불구하고, 이해하기 쉽게 잘쓰여졌고 다양한 self-evaluation, 다양한 시뮬레이션 활용, 실제 로봇을 설계하고 implementation도 해보는 등 논문에서 다루는 컨텐츠가 풍부한거 같습니다. 잘 모르는 학회이긴 하지만… 아마 그래서 accept이 되지 않았나 싶습니다.
6DoF를 공부하면 아직 산업에 다양하게 적용하기에는 bottleneck들이 많다고 느낍니다. 어려운 task이다보니 computation이 문제가 되는 경우도 많고, end-to-end로 처리하기 힘든 이유도 있습니다. 그런 의미에서 해당 논문은 일단 real-time으로 working한걸 확인한건 사실이고, 컨텐츠가 훌륭하단 점에서는 읽어보기 추천할만 합니다.
흥미로운 주제라 저도 재밌게 읽었습니다.
읽으면서 궁금한 점이 생겼습니다.
1. 러닝 기반이 아닌 기존의 방법론은 어떻게 적용되는지
2. 기존 방법과는 어떤 차별성이 있는지 궁금합니다.
1. 본 논문에서 러닝기반이 아닌 기존의 two or more stage 기반의 방법론들에 대해서는 다루지 않습니다.
2. Collision checking을 과정을 생략하고, 쿼터니안 representation을 directly regression함으로써 computation time을 줄인데 있습니다.
1. Related work에서 다뤘을 거라고 예상하고 드린 질문 이였습니다.