근간이 되는 네트워크에 대해 알아보고자 ResNet 논문을 읽어보았습니다. 기본이 되는 논문들을 많이 읽어보고자 합니다.
Abstract
Nerual Network는 layer가 깊어질수록 학습이 어렵다. 본 논문은 기존 방법론보다 Layer가 깊지만 쉽게 학습할 수 있도록 Residual Learning Framework를 제시하였다. Layer Input을 참조하는 residual function을 재정의하는 방법을 통해, 학습은 더 쉬워지고 그와 동시에 더 깊은 깊이로부터 정확도를 얻을 수 있는 결과를 가져왔다.
Introduction
당시 Covolutional Neural Network의 Layer는 깊을수록 성능이 향상된다는 견해와 이를 뒷받침하는 연구들이 다수였다. 이를테면 Deep Network는 여러 level features를 조합하여 task를 수행하는데, 이 level features는 곧, Layer의 수이므로 네트워크가 deep할수록 많은 정보를 가질 수 있다.
그로인해 네트워크의 깊이는 깊을수록 학습이 잘 될것인지에 대한 의문이 따라오는데, 그에 대한 답변은 *Vanishing/Exploding Gradients 문제로 대신할 수 있다. 즉, 깊이가 깊을수록 학습이 잘 되기는 커녕 수렴을 방해하는 현상이 발생할 수 있으므로 네트워크가 깊을 수록 학습이 잘 되는 것은 아니라고 할 수 있다. 그러나 이 문제들은 normalized initialization 같은 여러 normalization 방법에 의해 해결되었다고 한다.
- 여기서 Vanishing/Exploding Gradients란, Network의 깊이가 깊을 때 역전파 과정 중 기울기가 0에 가까워질 때 학습이 잘 되지 않는 경우를 의미한다.
그러나 깊이가 깊어짐에 따라 발생하는 Degradation 이라는 또 다른 문제가 있다. 이는 네트워크의 depth 가 어느정도 이상 깊어지면 오히려 성능이 떨어진다는 문제로, overfitting과는 다른 문제다. 즉, Layer를 단순히 높게 쌓는다고 학습이 잘되는 것이 아니라는 처음 제기한 의문에 반기를 드는 문제점이 발생하는 것이다.
이에 대한 해결책으로는 Layer를 많이 쌓되, 깊게 쌓는 부분은 identity mapping으로 추가하는 방법이 있다. 이렇게 만든 깊은 네트워크는 얕은 네트워크보다 높은 training error를 발생시키면 안된다는 것을 보이지만, 이게 명쾌한 Solution이 될 수는 없다.
따라서 본 논문에서는 이 Degradation 문제를 해결하기 위해 Deep Residual Learning 제안하였다.
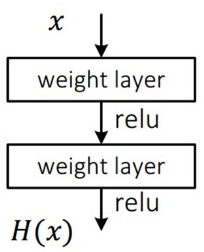
기존 Neural Network 에서는 [ 그림 1 ] 처럼 실제 mapping인 H(x) 를 최소화시키는 방향으로 학습을 하지만, 본 논문에서는 H(x) 를 곧바로 학습하기보다는 학습하기 더 쉽도록 F(x) = H(x) - x 의 Residual Mapping으로 재정의하여 학습시킨다. 이 때 x는 identity mapping이기 때문에, 참조하는 값이 없는 H(x) 보다 새롭게 정의한 F(x) 가 optimize하기 쉽다고 가정할 수 있다.
- 일례로 H(x) 가 x 인 경우( 즉, identity mapping ) residual 자체가 0이 되어버리므로 학습이 더 쉬울 것.
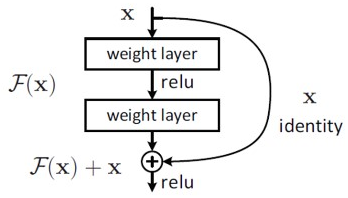
Shortcut Connections는 하나 이상의 계층을 건너 뛰는 연결로 [ 그림 2 ]의 곡선 화살표가 이 연결이라고 할 수 있다. 해당 방법론에서는 shortcut connections으로 identity mapping을 수행하기 때문에 단순히 출력값에 x 를 더하는 F(x) + x 로 표현된다. 간단하게 x만 더해주는 연산이므로 추가적인 파라미터도 필요 없고, 그와 동시에 복잡도도 증가하지 않으며 구현 역시 용이하다는 장점이 있다.
본 논문에서는 Degradation 문제와 성능 평가를 위해 ImageNet에 대한 포괄적인 실험을 진행했는데, 이를 통해 1) 학습은 더욱 쉽고, 2) *깊어질수록 accuracy가 높다는 것을 보였다.
- 단, 이 역시 깊이가 무작정 깊을 때를 의미하는 것은 아니다.
뿐만 아니라 본 논문에서는 CIFAT-10, 그리고 ImageNet 데이터셋 모두에 대해 성능이 좋음을 보여, 특정 데이터에 국한된 성능을 보인 것이 아니라는 것과 충분히 다양한 분야에 적용이 가능하다고 주장한다.
Deep Residual Learning
[1] Residual Learning
기존 Mapping을 앞서 언급한대로 $H(x)$라고 하자. 이 때 Multiple Nonlinear Layer가 복잡한 함수로 근사할 수 있다고 가정한다면, H(x) - x 같이 residual 함수로 근사하는 것이 가능하다고 가정할 수 있다. (단, input-output dimension은 같다고 가정.) 따라서 F(x) := H(x) - x 라고 할 수 있다. 여기서 F(x) 를 근사화하나, H(x) 를 근사화하나 수학적으로 보면 큰 차이가 없어보일 수 있으나, F(x) 를 학습하는게 훨씬 쉽다는 면에서 분명히 다르다.
요약 정리 하기
그러나 degradation 문제 관점에서 보았을 때, 이런 아이디어는 직관에 반하는 문제다. identity mapping의 layer를 추가한 더 깊은 모델은 최소한 더 얕은 모델에 비해 training error가 높아지지는 않을 것이라는 추측을 할 수 있다. 같은 맥락으로 여러개의 비선형 레이어를 겹쳐놓은 상황에 identity mappging을 학습하는 것 자체가 쉽지 않은 task 일 수 있으므로, 이런 identity mapping을 기본적으로 항상 수행하도록 하여 학습 난이도를 줄일 수 있다.
실제로 identity mapping이 최적일 가능성은 희박하지만, 이런 mapping을 추가하는 것 자체가 문제를 쉽게 해결하는데 도움이 될 수 있다. 이런 맥락에서 optimal function이 identity mapping에 가깝다면, 이미 identity mapping에 대한 정보가 있으므로 이를 reference하여 weight의 조정 폭을 더 쉽게 찾을 수 있다. 즉, 아예 새로운 function인 <strong>H(x)</strong> 를 레이어 마다 새로 조정하고 학습을 해야하는 것보다 훨씬 더 빠르고 안정적인 방법이라고 할 수 있다.
[2] Identity Mapping by Shortcuts
- Notation y = F(x,{W_i})+x
x : input, 혹은 identity mapping ( shortcut connections )
y : output vectors
F(x,{W_i}) : residual mapping
σ : ReLU
biases : 수식 간략화를 위해 생략
shortcut connection은 앞서 언급한대로 추가적인 파라미터도, 복잡도도 필요하지 않다는 장점이 있으며, 심지어 plain / residual network 를 fair 하게 비교했을 때, ResNet이 더 좋은 성능을 보였다.
y=F(x,{W_i})+W_sx추가로 input과 output dimension이 다를 경우 W_s 를 x 에 곱한 linear projection을 통해 dimension을 match 시킬 수 있다. 그러나 identity mapping을 사용했을 때, 충분히 좋은 성능을 보였기에 W_s 는 input-output의 dimension이 다를 때만 사용했다.
[3] Network Architectures
실험을 위해 Plain 네트워크와 본 논문에서 제안한 Residual 네트워크를 동일한 통제하에 비교했다.
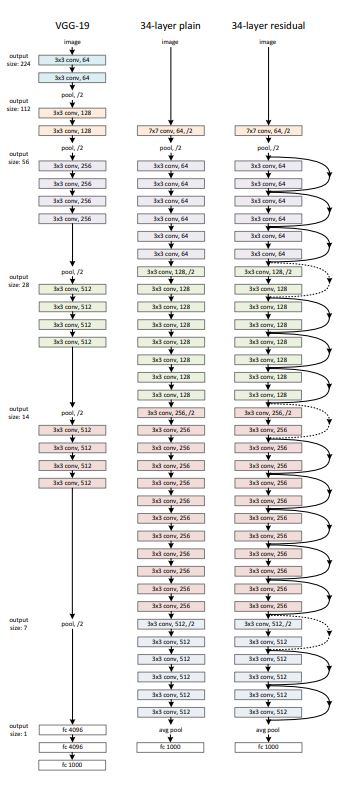
Plain Network
-
기본적인 CNN 모델로는 VGG 네트워크를 제한된 조건 하에 사용했다.
[조건] 3×3 filter를 사용하고, 다음 두 가지 rule을 제안
- 동일 output feature map size를 위해 layer는 같은 개수의 filter 사용
- feature map size가 절반으로 줄어들면, filter의 개수를 두 배로 증가시켜 layer마다 time complexity를 보존
- 별도의 pooling 없이, stride를 2로 설정하여 downsampling
- 네트워크의 마지막 단계 avgpooling을 통해 1000개의 class로 분류할 수 있도록 설계
⇒ 이 조건에 따라 본 모델은 VGG와 비교했을 때, 적은 파라미터 수와 복잡도를 가진다. Plain 모델의 FLOP이 VGG에 비해 더 낮음 (FLOP 란, 딥러닝에서 계산복잡도를 나타내는 척도)
Residual Network
input-output 간 dimension이 동일하면 identity mapping을 사용할 수 있고, 그렇지 않으면 다음 두 가지 옵션을 사용할 수 있다. (A) padding 후 identity mapping (B) Linear Projection을 활용한 ShortCut Connections
[4] Implement
- Scale Augmentation: 각 이미지는 224×224 randomly crop & Horizontal Flip
- Color Augmentation : AlexNet에서 사용된 방식
- Batch Normalization (BN) : Conv Layer와 Activation function 사이에
- Weights Initialization : Rectifier networks에서 사용된 방식
- SGD with a Mini Batch 256
- Learning Rate : 0.1에서부터 에러율의 변화가 없을 때 1/10씩 감소
- Iterations : 60 * 10^4
- Weight Decay : 0.0001
- Momentum : 0.9
- Dropout : 미사용
Experiments
[1] ImageNet Classification
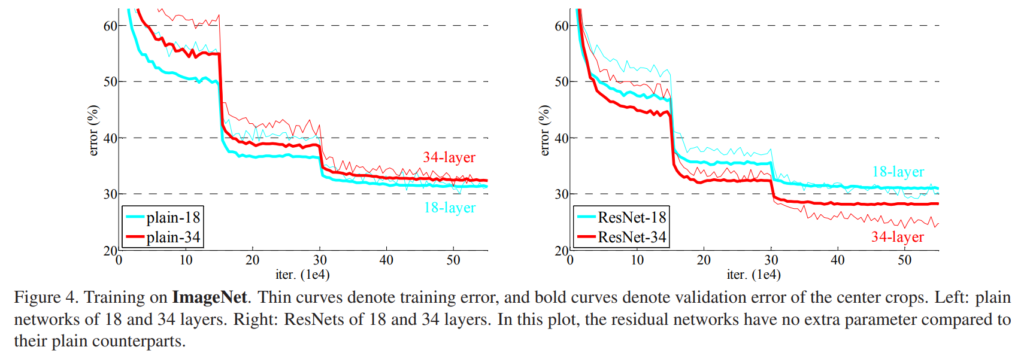
Plain Network는 깊을수록 Training Error가 증가하지만, ResNet은 더 떨어진다.
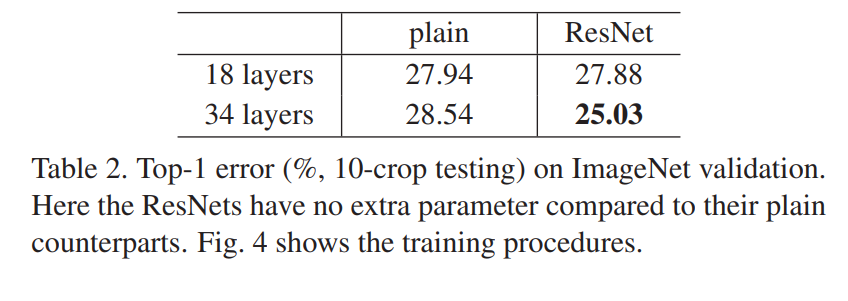
동일한 계산량을 가짐에도 불구하고 큰 성능 차이를 확인할 수 있다.
Plain Network는 BN과 함께 학습했기 때문에, Optimization이어려운 게 vanishing gradients의 문제로 볼 수는 없다고 한다. 게다가 본 논문에서는 Forward나 Backward propagated gradient들이 사라지지 않고 전달되는 것을 증명했다고 한다.
Identity vs Projection Shortcuts
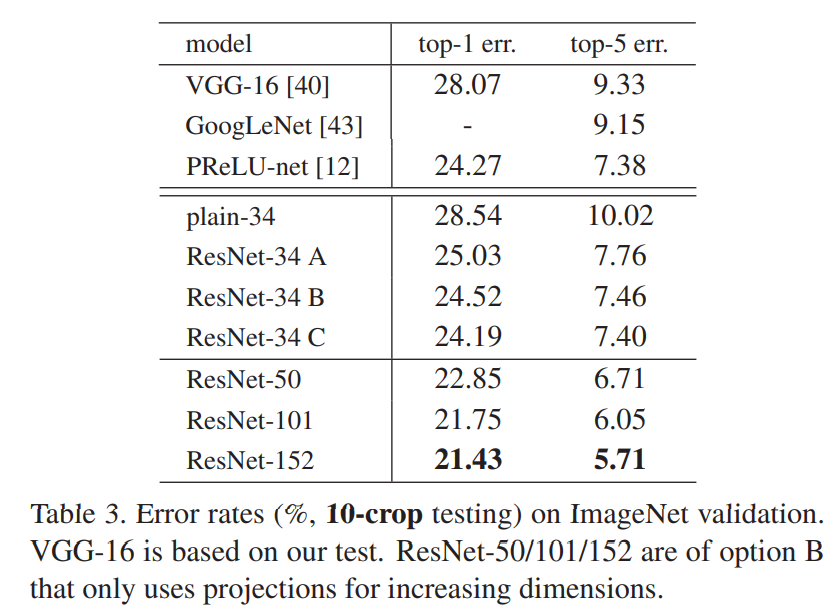
shortcut에 대한 성능을 비교하기 위해 (A), (B), (C)에 대한 실험 및 결과를 비교하였다. (A) zero-padding shortcuts (B) 차원을 늘려야하는 부분에 shortcut, 나머지는 identity (C) 모든 부분에 shortcut
⇒ 34 Layer에 한하여 C가 가장 성능이 좋다. 그러나 (A), (B), (C) 모두 Degradation 문제는 해결할 수 있고, Plain Network보다 성능이 좋다. 따라서 C 옵션은 메모리나 시간 복잡도 그리고 모델의 크기를 줄이고자 사용하지 않는다.
Deeper Bottleneck Architectures
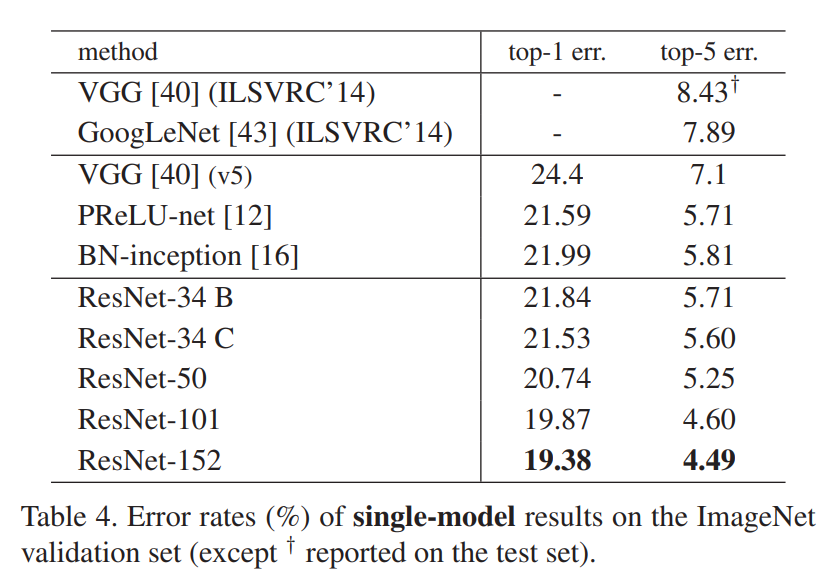
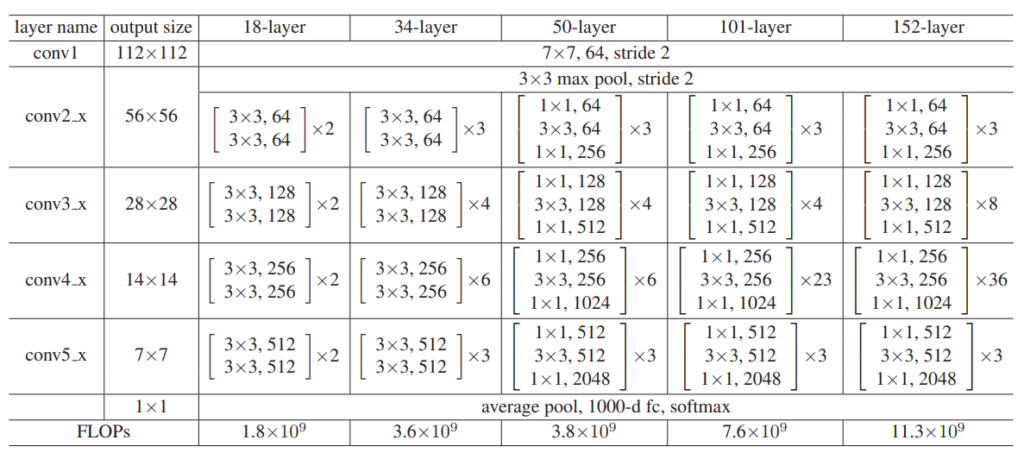
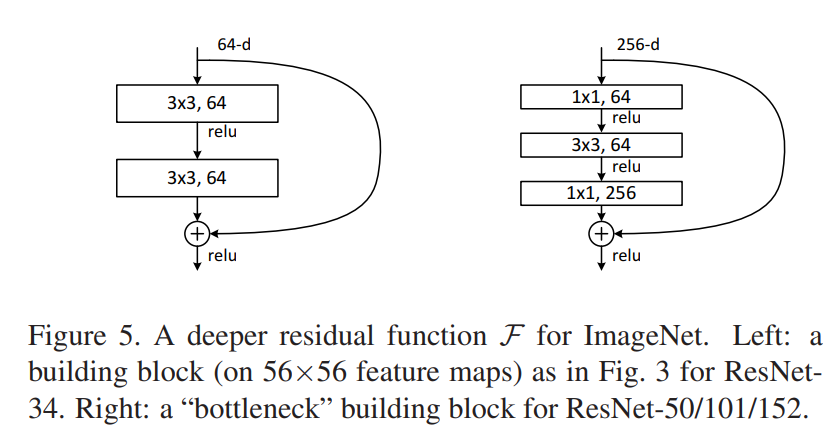
[그림 5] deep 한 네트워크를 위해 2개가 아닌 3개의 layer 사용
Depth가 50층 이상으로 깊어지면 계산량이 복잡해지기 마련이다. 따라서 50층 이상으로 깊어질 때에는 [그림 5] 의 오른쪽에 있는 Bottleneck Block으로 바꿔 사용한다. 계산량의 차이는 [표 1] 에서 확인 가능하다.
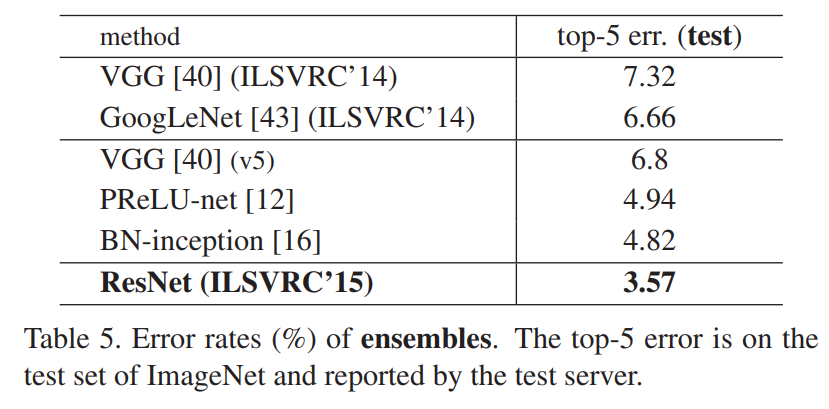
[표 5] Comparisons with State-of-the-art Methods : 6가지 모델의 앙상블로 가장 높은 성능.
“Degradation 이라는 또 다른 문제가 있다. 이는 네트워크의 depth 가 어느정도 이상 깊어지면 오히려 성능이 떨어진다는 문제로, overfitting과는 다른 문제다.” 이 부분에서 overfitting과 다른점이 무엇인가요? overfitting이 발생하면 degradation이 일어나는거 아닌가요?
안녕하세요 형준님, 질문 주셔서 감사합니다 🙂
저도 헷갈렸던 부분이라 질문 주신 내용에 대해서는 추후에 본문을 보충하여 작성하도록 하겠습니다.
overfitting 과 degradation 은 다른 문제입니다. 보통 train accuracy와 test accuracy 서로 다른 경향성을 보일 때 Overfitting이 발생했다고 판단합니다. 그러나 Degradation은 train, test 모두 accuracy가 높으나 성능이 좋지 않은 경우를 의미합니다. 즉, Layer가 어느정도 이상으로 깊어질수록 학습이 제대로 되지 않는 것이라고 할 수 있습니다.
답변이 도움이 되었기를 바라며 질문주신 내용에 대해서는 헷갈리지 않도록 본문을 잘 수정해두도록 하겠습니다. 감사합니다 🙂