

약 한달간 CVPR workshop 에서 열리는 ActivityNet Challenge 2021에 참여하게 되어 본격적으로 시작하기에 앞서 전년도 ActivityNet Challenge 2020에 대한 리뷰를 진행합니다. 제가 나가는 분야로는 Action Recognition 분야이기 때문에 이 분야의 전년도 공동 1위 팀에 대해 리뷰를 할 예정이며, 본 챌린지의 Temporal Action Localization 분야에 나가는 저희 연구실 내 다른 팀을 위해 해당 분야에 대한 정보도 참고할 수 있도록 추가하였습니다.
1. Overview
본 챌린지의 이름과 같게 이전 리뷰했던 데이터 셋인 ActivityNet이 주로 사용되는 챌린지이나, Action Recognition의 경우 Kinetics라는 10초 가량의 짧은 비디오로 구성된 데이터 셋을 사용합니다. 해당 데이터 셋의 경우 매년 챌린지를 거치며 총 class 수도 늘고 비디오 수도 늘었으며, 이번 챌린지에는 총 700 class와 대략 총 600,000개가 넘는 비디오로 구성된 Kinetics-700-2020 데이터 셋이 Action Recognition을 위해 사용됩니다. Action Recognition이란 말그대로 행동 인식을 의미하며, 특정 비디오에서 나타나는 행동을 분류하는 task 입니다. 이를 위해 비디오와 함께 행동에 대한 label이 제공되며 이를 Top-1 Accuracy, Top-5 Accuracy라는 지표를 통해 평가하게 됩니다. 또한, 이번 챌린지에 사용되는 Kinetics-700-2020이라는 데이터 셋은 Trimmed Action Recognition이라는 특징을 지니는데, Trimmed 란 잘 가공되어 한 비디오 내의 특정 행동 하나의 행동만이 표현된 것을 의미합니다. 이러한 점은 바로 다음 설명할 Temporal Action Localization task에서 사용되는 비디오와는 상반되는 점을 보입니다.
저희 연구실에서는 본 챌린지의 Action Recognition task 이외에도 Temporal Action Localization이라는 task에도 참가합니다. Temporal Action Localization task란 Untrimmed 비디오 내에서 특정 행동의 시간적인 위치를 찾아내고 그 행동이 어떤 것인지도 알아내는 task 입니다. 여기서 Untrimmed 란 비디오 내의 둘 이상의 행동이 나타나는 것을 의미합니다. 본 task는 ActivityNet 데이터 셋으로 진행되며, Action Recogntion과 비교를 위해 이미지 task에 빗대어 보았을 때, Action Recognition은 분류만이 필요하기에 이미지 Classification이라 한다면 Temporal Action Localization은 시간 축으로의 위치도 찾고 그 위치를 나타내는 행동의 분류도 필요하기에 이미지 Detection과 가깝습니다.
2. Results of Action Recognition in ActivityNet Challenge 2020
2020년도 ActivityNet Challenge의 Action Recognition 분야에서는 두 팀이 공동 1등을 달성하였습니다. 한 팀은 CUHK-Sensetime 이며, 다른 한 팀은 Google Cloud AI 입니다.
2.1 CUHK-Sensetime
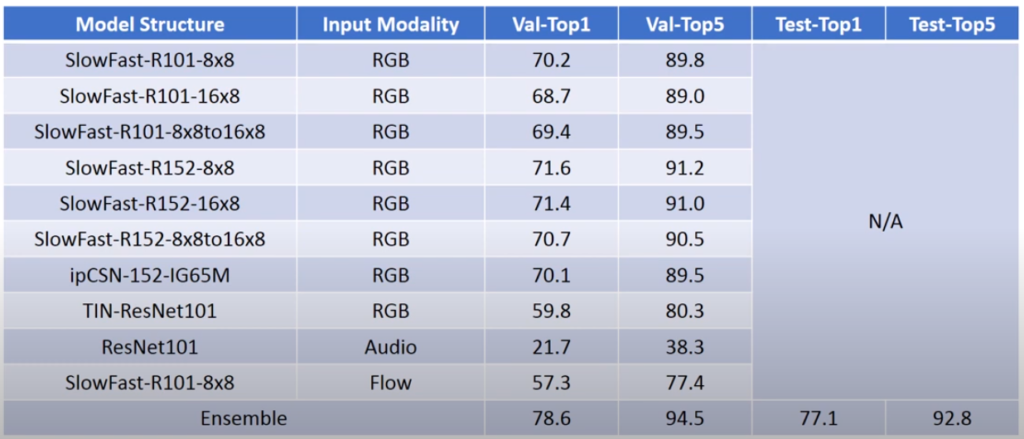
CUHK-Sensetime 팀은 여러 챌린지에서 많이 사용하는 Ensemble 방식으로 당시 성능이 좋았던 여러 방법론에 적용하여 높은 성능을 나타냈습니다. Ensemble 한 방법론으로는 프레임 단위 clip을 입력으로 받은 SlowFast, CSN, TIN이 있으며, 이들 뿐만아니라 Audio와 Optical Flow를 각각 입력으로도 하여 Ensemble에 추가하였습니다.
- SlowFast
이전에도 비디오 관련 인식/검색 연구에 대한 조사를 할 때 유명하여 몇번 리뷰를 거쳤던 방법론 입니다. 특징으로는 두 종류의 입력을 두 종류의 모델로 처리하는 것이 있으며, 그 중 한 가지는 motion의 semantic한 정보를 얻기 위해 Dense한 프레임 입력을 받지만 이를 받는 모델 자체의 파라미터 수는 많지 않고 가벼우며, 다른 한 가지는 프레임 내의 spatial information에 따른 visual한 정보를 얻기 위해 Sparse한 프레임을 입력으로 받되 상대적으로 모델의 크기가 큰 구조를 띄고 있습니다. 해당 모델은 이러한 구조로 당시 여러 데이터 셋에서 SOTA의 성능을 냈던 것으로 기억됩니다.
- CSN (Channel Separated Networks)
CSN은 MobileNet에서 제안되어 사용되던 Depthwise Convolution 연산을 3D convolution 모델인 3D ResNet으로 가져와 적용한 방법론으로 각 channel 별로 다른 kernel을 통해 연산되어지기때문에 모델 용량이 줄어들면서 좋은 성능을 보이는 방법론 입니다.
- TIN (Temporal Interlacing Networks)
TIN이란 TSM(Temporal Shift Modules)의 다음 버전으로 TSM에서는 각 프레임에서 얻은 feature 맵을 시간 축으로 한칸씩 옮겼다면, TIN에서는 옮기는 정도 또한 학습을 해 여러 프레임의 feature 맵을 얽혀놓은 구조의 방법론입니다. 해당 방법론은 2020년도에서 여러 데이터 셋에 SOTA의 성능을 보인바 있기에 Ensemble의 요소로써 사용된 것으로 보입니다.
- Audio Networks
입력이 소리 데이터일 경우 Log-Mel Spectogram 형태로 바꿔주고 ResNet-101 모델을 통해 feature를 추출하였습니다.
- Optical Flow Networks
입력이 Optical Flow인 경우 Dense Inverse Search 방식으로 Optical Flow를 계산하였으며 이를 SlowFast-101의 입력으로 두어 feature를 추출하였습니다.
- Ensemble
앞서 소개한 방법론들을 Ensemble하기 위해 우선적으로 validation set에서 단일 방법론 별로 예측을 하였으며, Grid Search를 통해 각 방법론 별 weight가 최대의 validation 정확도를 나타낼 수 있도록 찾아내어 test set에도 이를 적용하였습니다.
2.2 Google Cloud AI – Leveraging Weakly Supervised Data and Pose Representation for Action Recognition
Google Cloud AI 팀도 마찬가지로 Ensemble 방식을 사용하였으며, RGB의 프레임에 대한 두 가지 방법론과 Optical Flow, Pose Representation 에 대한 Multi-modal feature가 추가되어졌습니다. 또한 추가로 Weakly supervised pre-training 방식을 활용해 높은 성능이 나타난 특징을 보입니다. 이 방식은 RGB의 프레임에 대한 방법론인 두 가지의 backbone network를 사용하였으며 이들은 각각 ResNet3D, EfficientNet-L2입니다.
- Pre-training ResNet3D with weakly labeled videos
ResNet3D를 Pre-training하기위해 우선 Kinetics 비디오의 meta 데이터를 이용해 수많은 비디오가 검색되어 모아졌습니다. 여기서 meta 데이터란 데이터를 위한 데이터라는 뜻으로 비디오에서는 비디오의 주제 혹은 캡션과 같은 것이 될 수 있습니다. 이렇게 모아진 비디오를 활용한 Pre-training에는 Kinetics 비디오가 제외된 새로 모아진 비디오만이 사용되었고 이에 두 가지 loss가 적용되었으며, 그 중 하나는 video representation의 향상을 위해 BERT의 비디오 제목에 대한 Text representation과의 margin loss 이며, 나머지 하나는 Kinetics의 700개 class 에대한 classfication loss 입니다. 이렇게 ResNet3D에 Pre-training 과정을 추가해 71.2%에서 74.4%의 성능 향상을 얻었다고 합니다.
- Pre-training EfficientNet-L2 with unlabeled images
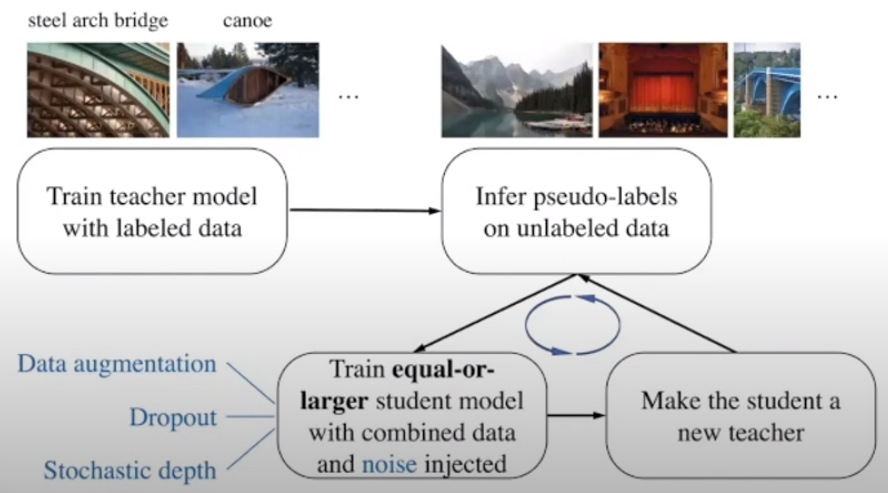

EfficientNet-L2가 각 프레임 별로 Spatial 한 정보를 주기 위해 사용되기에 앞서 ImageNet 데이터 셋으로 학습된 teacher 모델을 통해 Self-supervised Learning 방식의 일종인 Pseudo-Labeling 과정이 추가되어 label이 없는 3억개의 이미지 데이터로 학습을 진행하였으며 ImageNet에서 당시 SOTA를 뛰어 넘는 높은 성능을 보였습니다.
앞서 설명한 두가지 방법론과 Optical Flow로 ResNet-101에서 예측한 값과 Pose로 EfficientNet-L2에서 예측한 값을 Ensemble하여 Top-1 accuracy에서 78.6으로 CUHK-Sensetime팀과 같은 성능을 보이게 되었습니다.
2.3 Reference
[1] https://www.youtube.com/watch?v=KOQFxbPPLOE&t=575s
3. Results of Temporal Action Localization in ActivityNet Challenge 2020
Temporal Action Localization task는 내용이 많아진 관계로 레퍼런스만 참조하겠습니다.
3.1 Reference
[1] https://www.youtube.com/watch?v=W2hpoZk–Zg