
해당 논문은 카메라 모션 정보를 통해서 Object 의 Depth를 추정하는 방법을 제안합니다. 이때 카메라 모션 정보는 uncalibrated 상태라고 합니다.
본 논문의 티저영상 입니다. 해당 영상에 대해서 설명드리면 uncalibration 카메라를 이용해서 상대적인 모션 정보와 Object Detection 박스의 스케일 등을 통해 Depth를 추정합니다. 이러한 뎁스 추정에는 카메라의 모션정보와 박스가 들어가기 때문에 LSTM을 베이스로 설계하였다고 합니다. 그럼 해당 논문에서 어떻게 이러한 방법으로 뎁스 추정이 가능한지 살펴봅시다.
Depth from camera motion and object detection
Motion and Detection Inputs
본 논문에서 사용하는 입력은 다음과 같이 정의할 수 있습니다.

정리하면 저희가 알고있는 일반적인 Object Detection의 결과라고 할 수 있는 박스의 중심좌표와 가로,세로 크기를 나타내는 x,y,w,h와 카메라의 모션정보가 담긴 p에 대해서 모델은 입력받게 됩니다. 이때 p는 상대적인 카메라 위치이며 X,Y,Z 값으로 상대적인 값을 나타냅니다.
Camera Model

우리가 가장많이 알고있는 pinhole camera model을 이용한 3D camera frame coordinates 수식은 (3)과 같습니다. (아래 0,0,1이 없을뿐) 그리고 해당 수식을 (4)와 같이 각각에 대해서 나타낼 수 있습니다. 자 여기까지는 우리가 알고 있는 그냥 영상이해에서 배운 카메라의 일반적인 2D-3D 수식입니다. (본 논문에서는 이를 직접적으로 이용하지 않습니다. 왜냐면 uncalibration 카메라에서 뎁스를 추정하기 때문이죠)
Depth from Optical Expansion & Detection
자 이상적인 모델이라면 z(뎁스)가 달라지면 박스의 스케일이 달라지겠죠? (멀리있으면 작아지고 가까이 있으면 커지니까) 이를 나타내면 아래 그림에서의 Box1과 Box2의 상황입니다.
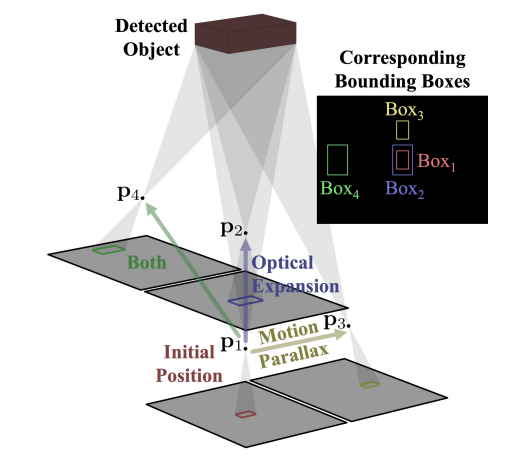
자 그러면 저자는 여기서 스케일만 달라지므로, width와 height의 스케일만 가지고 Z를 추정하기 위한 수식을 세웁니다.

본 논문에는 W에 대해서만 설명하고 H는 동일하게 진행하면 된다고 하는데요.. (진짜 W를 H로만 변경하면 됩니다.) 자 일반적으로 센터 중심으로 박스의 오른쪽 끝 x축과 왼쪽 끝 x축의 차이를 계산해서 박스의 width를 계산합니다. 그리고 이는 수식(5)에 나타납니다. 그리고 여기서 사용되는 x의 값을 앞서 (4)에서 구한 관계를 대입하면 3D에서의 WIDTH를 계산할 수 있습니다. ((5)번과 같이) 그리고 이렇게 구한 (5)번 수식에서 Z를 곱하면 (6)과 같은 수식이 전개됩니다. 이와 같이 H도 동일하게 전개하면 됩니다.
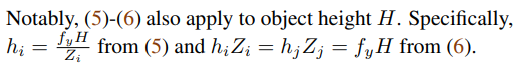
자 일단 이렇게 수식을 구하고, 본 논문에서는 카메라의 모션 정보도 사용하므로 모션정보도 함께 이야기해봅시다. 우리는 앞에서 카메라의 상대적인 변화값을 p라고 정의하였습니다. 자 다시 현재 이야기중인 상황은 Z값만 달라져서 스케일의 변화만 발생한 상황이기 때문에, 이를 수식으로 나타내면 다음과 같습니다.
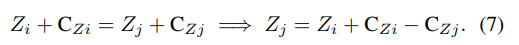
굳이 설명하자면… 현재 P값은 상대적인 포지션 값을 의미하고, 현재 상황은 나머지는 똑같고 Z값만 달라져서 박스의 스케일만 다른 상황을 가정합니다. 따라서 하나의 observation에서 다른 observation의 Z를 표기하면 수식(7)과 같습니다. 자 그럼 이제 수식(7)과 수식(6)을 잘 조합해서 Z에 대해서 정리하면 다음과 같습니다.
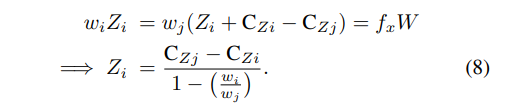
넵 그렇습니다. Z를 예측하는데 있어서 박스의 width 비율과 상대적인 p값 (카메라의 모션정보)만 있으면 Z를 추론할 수 있게 됩니다. 동일하게 height로 변경해야 한다면 w를 h로마 변경하면 됩니다.
Depth from Motion Parallax & Detection
앞에서 뭔가 Z에 대해서 수식을 나타냈으므로 Z를 추론할 수 있을것 같습니다. 하지만 실제 상황에서는 센터가 동일하고 Z축만 다른 observation은 많이 존재하지 않습니다. 더욱이 일반적인 상황이라면 Box1,Box2보다는 Box3,Box4의 상황이 많이 나타납니다.
이러한 상황에 대해서도 보충자료에 해당 증명하는 내용을 담았습니다.

Using all Observations to Improve Depth
현실에서 적용될때는 딱 두개의 observation만 가지고 Depth를 추정하면 오류가 커지겠죠.. 따라서 최대한 많은 observation을 사용해서 Depth를 추정합니다.

저희가 많이 보던 매트릭스죠..? least-squares approximation을 통해서 다음과 같이 여러 observation의 정보를 가지고 Z를 추정할 수 있으며, 이는 실험세션에서 BOX_LS라고 표기했다고 합니다.
Depth from Motion and Detection Network
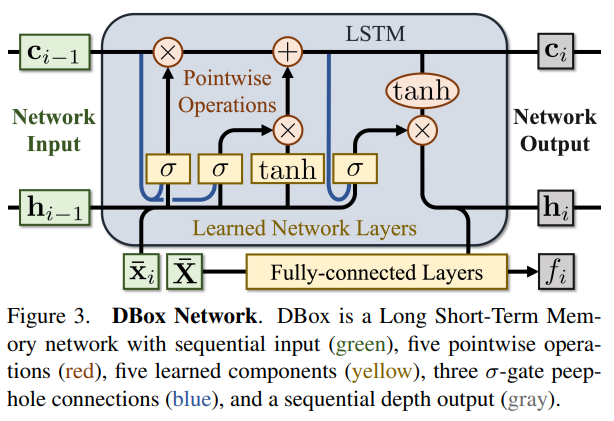
자 이제 앞에서 새롭게 정의한(?) 수식을 기반으로 이를 딥러닝 네트워크에 적용합니다. 위의 그림이 제안하는 딥러닝 모델이며 LSTM를 베이스로 하였습니다. 위의 그림에서 실질적으로 추정하는 Depth가 f_i 입니다.
Normalized Network Input.
모델의 입력은 아래와 같이 bounding box coordinates를 각각 마다 normalize 했다고 합니다. 정리하면 정규화된 bounding box 값과 상대적인 카메라 모션 p가 됩니다.

Normalized Network loss
저자는 처음에 straightforward loss를 사용했다고 합니다.
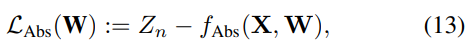
근데 입력에서 Normalized를 했으므로 Loss도 동일하게 정규화를 진행했다고 합니다.
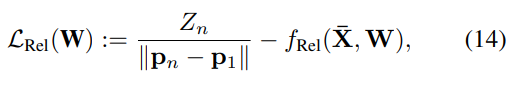
이 두 Loss에 따른 차이는 실험에서 결과로 나타냅니다.
Depth from Motion and Detection Dataset

본 논문에서는 자신들이 제안한 네트워크 학습을 위한 데이터셋도 제작합니다. 해당 데이터셋을 저자는 Object Depth via Motion and Detection Dataset (ODMD)라고 명명하였습니다. [데이터셋 링크]
사실 논문에서 약 한페이지 반정도를 Dataset에 대해서 설명하고 실제 모션에 대해서 어떻게 모션정보를 다양하게 만들었는지 설명하고 있는데….. 해당 내용에 대해서 궁금하시면 직접 확인하시는게 좋을것 같습니다.
Experimental Result
해당 논문에서는 아무튼 본인들이 만든 ODMD 데이터셋에 대해서 실험을 수행하는데, 이때 Depth를 평가한 metric은 다음과 같습니다.
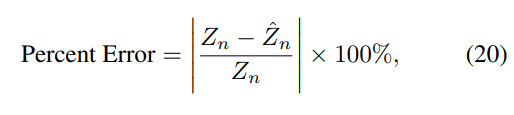
이를 기준으로 평가한 결과는 다음과 같습니다.
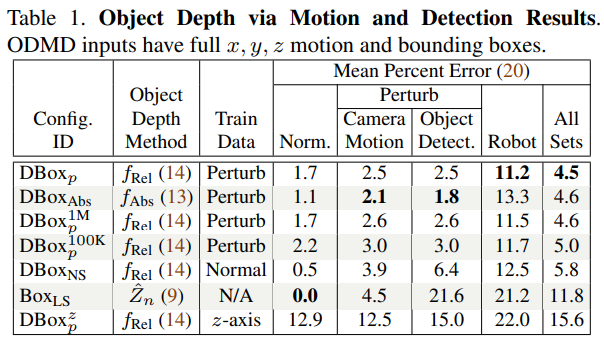
테이블 1의 경우 자신들의 데이터셋을 다양한 방법으로 평가한 결과 입니다. 모든 결과는 10개의 observation을 사용한 결과라고 합니다. 위 테이블에서 DBox_p와 DBox_abs는 앞서 언급한 Loss가 다른 경우를 의미합니다. DBox^z_p는 z-axis로만 움직인 경우(위 본문에서 가장 첫 번째 가정), Box_LS는 least-squares approximation을 이용 Depth를 계산했습니다. 그리고 1M과 100K는 iteration 횟수라고 합니다. 마지막으로 DBox_NS은 Perturb 없이 학습한 결과라고 합니다. (조금 이상하네요 실험을 나타내는 방식이)
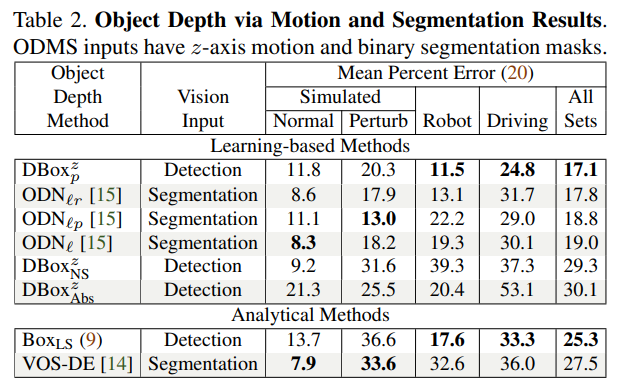
그래도 다른 방법론과의 비교를 위해서 Segmentation 입력의 방법론과 비교한 표도 나타내고 있습니다. ODN이 다른 논문에서 제안한 방법입니다.
Conclusion
논문은 굉장히 단순하나 아직 제가 부족함이 많아서 그런지 논문이 가진 잠재적인 능력에 대해서 정확히 잘 모르겠습니다. 그래도 CVPR2021에 accept된 논문이니… 해당 논문이 가진 정확한 의미에 대해서 다시 고민해보겠습니다. 논문에서 저자는 uncalibrate camera motion과 detection bounding box만을 가지고 최초로 depth estimation을 수행하였고, ODMD라는 데이터셋도 공개하는것이 큰 contribution이라고 합니다. 이러한 방법은 mobile application에서 사용할 수 있다고 하는데, 제가 해당 부분에 대해서 잘 못읽었는지 리뷰에서 잘 나타내지 못해 아쉽네요.. 대신 해당 저자의 유튜브 영상을 공유하며 리뷰를 마치겠습니다.
좋은 글 감사합니다.
한가지 궁금한 점이 있는데, 맨 처음의 입력으로 검출된 박스의 정보들과 카메라의 모션 정보가 필요하다고 나와있는데, 모션정보는 어떻게 구할 수 있나요?
요즘은 하드웨어가 좋아서 하드웨ㅇㅓ로 구할수도 있다고 하네여