해당 논문은 영상의 스타일의 유사성을 기반으로 하여 영상을 서칭하는 방법론에 대해 연구한 논문인 듯 합니다.
먼저 해당 논문의 초록 부분을 간략하게 설명드리면, 영상의 표현법을 학습하는 것은 영상 검색에 매우 중요한 역할을 수행하는데, 특히 학습된 검색 임베딩(search embedding) 안에 거리는 영상의 유사성이 반영되어야합니다. 하지만 영상 스타일의 다양한 세부 디테일을 구분하도록 임베딩을 학습하는 것은 매우 어려운데, 이는 스타일을 어떻게 정의하고 labeling 해야할지에 대한 어려움이 존재하기 때문입니다.
이러한 문제점을 위해 해당 논문에서는 디지털 아트들의 세부 디테일 유사성에 대한 표현 방식을 weakly supervised로 학습하는 방법론을 제안합니다.
음. 쉽게 말해서 해당 논문은 디지털 아트에 대한 이미지 기반 리트리벌을 하고 싶은 듯 합니다. 전제가 디지털 아트이기 때문에, 일반적인 영상 기반 리트리벌과는 다른 어려움이 존재하는데 가장 큰 어려움은 아무래도 작품들 개개인의 독특한 생심새(예를 들어 작품의 질감, 배치, 명암 등)를 모델이 어떻게 해석하고 구분할지 인 것 같네요.
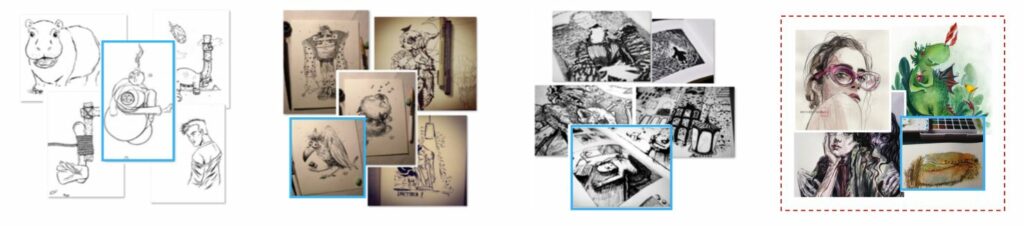
그림1은 해당 논문의 결과를 나타낸 그림인데, 쉽게 말해 자신들의 방법론은 fine-grained style을 잘 학습시켰기 때문에 다른 방법론에 비해 영상의 세부 스타일을 더욱 세밀하게 잘 잡아낸다고 합니다.
그에 대한 예시로 우측 붉은 점선 박스 내 결과를 보면, 이전의 방법론들은 세부적인 스타일이 비슷하다기 보다는, 수채화로 그려진 다양한 작품들을 관련 영상으로 반환하지만, 자신들이 제안하는 방법론은 정말로 세부적인 디테일이 유사한 영상들을 반환하더라~ 라는 것을 의미합니다.(근데 왜 그럼 똑같은 query에 대한 비교를 안했지?)
아무튼 해당 논문의 contribution은 다음과 같습니다.
- ALADIN Fine-grained Style Embedding.
ALADIN은 All Layer AdaIN의 약자로 해당 논문의 구조를 지칭하는 말입니다. ALADIN은 영상 스타일에 대한 임베딩 검색을 학습하는 architecture로, style encoder layer들에 대해 Adaptive instance normalization을 모두 적용시켜 coarse-grained style과 fine-grained style 모두를 구분할 수 있는 검색 임베딩을 학습하였습니다.
Adaptive instance normalization에 대해서는 밑에서 다시 설명드리려고 합니다. - Behance Artistic media Fine-Grained dataset(BAM-FG).
해당 논문에서는 디지털 아트에 대하여 총 262백만개의 작품들을 모았으며 그 중 310K가 fine-grained style로 그룹 지어져 있다고 합니다. 대충 데이터 셋을 제안한다는 것 같은데, 해당 데이터 셋에 대해서는 큰 관심이 없어서 이번 리뷰에 관련 내용을 다루지는 않겠습니다. - Weakly supervised learning of fine-grained style.
해당 논문에서 말하기를, fine-grained artistic style similarity에 대한 표현법을 weakly supervised 방식으로 학습하는 연구를 처음 제안하였다고 합니다. 이전의 스타일 기반 영상 검색 방법론들은 오직 coarse-grain style만을 구분하였다고 합니다. 하지만 ALADIN은 contrastive learning을 통해 coarse와 fine-grained level의 style 검색을 모두 잘 수행할 수 있었다고 합니다.
Adaptive Instance Normalization(AdaIN)
ALADIN에 대한 본격적인 개념에 들어가기 앞서, AdaIN에 대해 간략히 알아봅시다. AdaIN은 지난번 stylegan 논문 리뷰에서도 잠깐 언급을 드렸었는데, 쉽게 말해 입력 feature가 임의로 주어진 스타일로 normalization되게끔 만드는 것입니다.
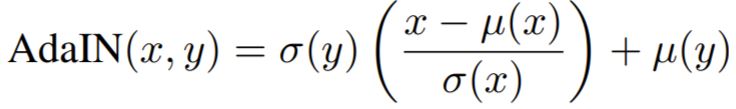
위에 수식은 AdaIN를 식으로 나타낸 것으로, x는 content input을, y는 style input을 의미합니다.
아시다시피 \mu, \sigma 는 각각 평균과 표준편차를의미하는데, 해당 평균과 표준편차는 feature의 channel-wise로 계산된 값들입니다.
이러한 AdaIN의 목적은 instance normalization이 특정한 단일 스타일로 입력을 정규화시킨다는 점을 이용하여, style을 제공함으로써 adaptive 하게 content feature에 스타일을 적용시켜보자 라는 취지입니다.
ALADIN Architecture
그럼 본격적으로 ALADIN의 구조에 대해 알아봅시다. 일단 ADAIN은 Neural Style Transfer 방법론에 많이 사용됐습니다. NST는 영상을 컨텐츠와 스타일로 분리하여, 영상에 새로운 스타일 코드로 수정이 가능하게끔 만드는 네트워크입니다.
하지만 이러한 NST는 검색 임베딩으로 사용할 때 그리 효과적이지 못했다고 합니다. (해당 내용은 뒤에서 다루도록 하겠습니다.)
그래서 ALADIN은 latent code를 입력으로 하여 적절한 스타일 인코더 레이어를 타고 나온 activation 값들의 평균과 표준편차를 추출하였으며, 이렇게 추출된 값들을 contrastive approach로 학습시킴으로써 기존 NST와 달리 검색 임베딩의 적합하도록 학습시켰다고 합니다.
여기서 activiation 값들의 평균과 표준편차를 나타낸 것이 뒤에 Adaptive Instance Normalization을 사용하기 위한 입력 값으로 보시면 될 것 같습니다.
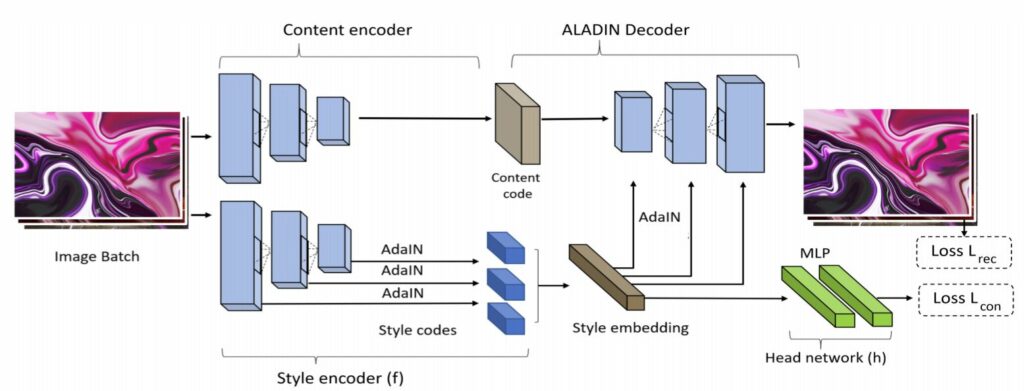
ALADIN은 Encoder-Decoder(E-D) 형식으로 이루어져있습니다. 먼저 encoder를 살펴보시면, 크게 content encoder와 style encoder로 나눌 수 있는데, content encoder는 총 4개의 컨볼루션 레이어로 구성되어 feature map을 downsampling 합니다.
Style encoder의 경우, 3개의 컨볼루션 레이어들로 구성되어있으며, 각각 64, 128,256개의 필터로 구성되어 있습니다. 해당 encoder를 타고 나온 feature map은 어떠한 FC layer를 사용하지 않고, 단순히 channel-wise하게 평균과 분산을 계산하였습니다.
이렇게 구한 style code들은 encoder의 필터 개수보다 2배 더 많게 구성되어 있는데 이는 각 output feature map의 평균과 분산을 나타내기 때문입니다.
그 다음에는 해당 style code들을 모두 합침으로써, 896-D search embedding 벡터를 만들게 됩니다.(128+256+512=896)
디코더의 경우에는 인코더와 동일한 형태를 가지고 있으며, style code는 decoder feature와 동일한 크기로 분할하여 AdaIN을 적용시킵니다. 처음에 볼 때는 디코더가 content encoder와 동일한 형태이겠거니 생각했는데, 스타일 코드를 가지고 AdaIN을 적용시키려면, style encoder와 동일한 feature 개수를 가지고 있어야 하므로 style encoder와 동일한 모형으로 확인됩니다.
아무튼 AdaIN을 적용하는 수식이 아래와 같다고 합니다.
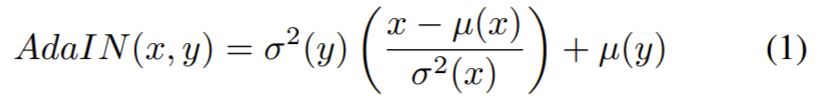
여기가 정말 신기한게, 위에 AdaIN과 비교하자면 당연히 x, y는 각각 style decoder에서 나온 content와 style encoder에서 나온 style code여야만 하는데, 해당 논문에서는 이를 반대로 정의하고 있습니다.

즉 x가 style encoder layer의 feature map 이며, y가 decoder에서 나온 content feature map이라는 것인데… 이게 오타인지 아니면 정말로 기존의 AdaIN 방식과 다르게 적용한 것인지를 잘 모르겠네요…
아무튼 ALADIN에서 style embedding에 512 size를 가진 multi-layer perceptron을 적용시킨다고 합니다. 그 후 L2 normalized를 적용하여 128차원 벡터를 생성하게 됩니다.
이러한 MLP를 h, 기존 style embedding을 만들었던 style encoder를 f로 표현하여 128차원 출력 벡터는 h(f(.))로 표현합니다. 아무튼 이런식으로 MLP를 사용한 것이 style embedding을 바로 학습한 것보다 훨씬 더 좋은 계산 효율을 보여줍니다.
Training with Implicit Project Groups
일반적인 딥러닝 기반 metric learning은(예를 들어 triplet loss) 시각적 유사성과 임베딩의 근접함 사이에 상관관계가 존재한다고 판단하여 이를 이용해 학습시켰습니다.
주어진 학습 데이터셋 T에 대해, proejct group? G \subset T 는 랜덤하게 선택됩니다. 또한 G에서부터 랜덤하게 선택된 영상 a를 ‘anchor’라고 정의합니다.
positive들로 구성된 그룹영상들을 G^{+}=G \backslash a , negative들로 구성된 그룹 영상들을 G^{-} \subset T \backslash G^{+} 라고 합니다.
그러면 이제 어떤 미니배치 B에 대하여, triplet(a,p,n) 중 p \in G^{+}, n \in G^{-} 를 의미하며, metric learning의 목적에 맞게 아래와 같은 식을 최소화 하려고 합니다.
\sum_{(a,p,n)\in B}[\epsilon + \mid f(a) - f(p) \mid_{2} - \mid f(n) - f(p) \mid_{2} ]_{+}
최근에 위와 같은 contrastive learning은 매우 큰 batch size를 이용하게 되면 성능향상을 보인다는 결과가 있었는지, 해당 논문에서도 그룹 영상의 크기를 1024로 정했다고 합니다.
즉 (a, b) \in G_{i} for i = [1, 1024] 이며 positive와 negative 각각 1장씩하여 2024개의 batch를 사용했다고 합니다.
B={b_{1}, b_{2}, ..., b_{2N}} 이며 여기서 b_{2i} 는 b_{2i-1}과 같은 그룹입니다. 그러므로 최종 contrastive learning loss는 아래 수식과 같습니다.
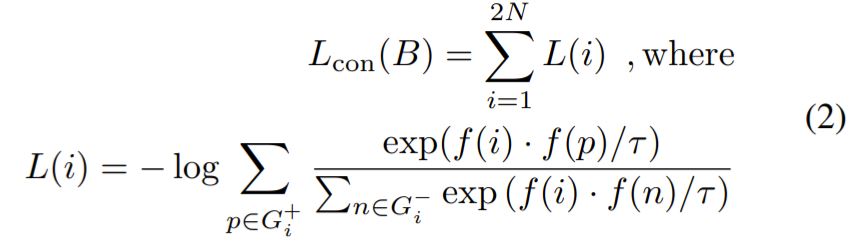
\tau 는 0보다 큰 값을 가지는 temperature parameter라고 합니다.
또한 ALADIN 은 Encoder-Decoder 구조이기 때문에, reconstruction loss term을 두었다고 합니다.
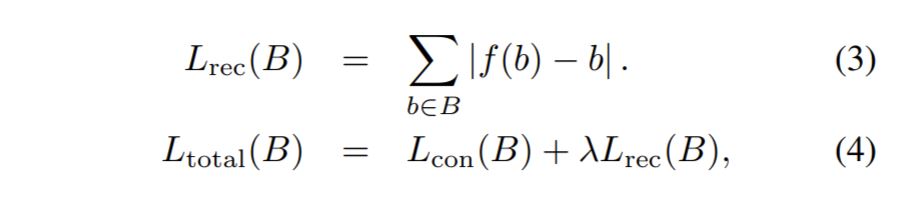
근데 이것도 이해가 안가는게, 분명 b가 image란 말이죠? 근데 f(b)는 style code일텐데, 이 둘을 어떻게 L1 loss로 비교하는지… 논문이 참 그렇네요.
Experminets
정량적 결과에 대해서는 너무 내용이 방대하여 추후에 추가할 예정입니다.

그림3은 이미지 서칭에 대한 정성적 결과를 나타낸 것입니다. DML은 coarse-grain style을 임베딩으로 하는 방법론이며, ResNet은 ALADIN과 유사하게 fine-grained embedding을 학습하도록 한 것입니다.
결과를 살펴보시면, 먼저 DML은 Coarse-grain style에 대한 임베딩을 학습해서인지, query 영상의 style과는 비교적 거리가 멀어보이는 결과들이 종종 나타납니다. 또한 ResNet 역시 fine-detail이 유사한 결과들을 잘 못나타내는 모습을 보이는데, network backbone을 이용하여 style을 뽑는 방법과, AdaIN을 이용하여 style code를 뽑는 방법의 차이를 볼 수 있습니다.
감상평
실험도 다양하게 진행하였고 contribution도 명확하고 좋은 논문으로 생각되나, 방법론에 대한 설명 및 디테일이 너무 부족하여 이해하는데 의문이 많이 생기는? 터라 읽으면서 많이 아쉬웠던 논문입니다.