안녕하세요, 이번주는 sim-and-real co-training에 대한 연구들 리뷰해보려고 합니다. 사실 합성 데이터는 현실에서 얻는 데이터와 visual, sensor, dynamics gap이 존재합니다. 따라서 제아무리 풍부한 합성 데이터로 학습을 한들, 현실에서 로봇이 시뮬레이션에서 학습한대로 행동하는 과정에서 각종 변수에 의해 한 번도 보지 못 한 상황에 놓이며 policy가 붕괴될 수 있습니다. 이렇게 BC 계열의 policy는 학습 데이터의 분포에 강하게 의존하기 때문에 시뮬레이션에서 다양한 Domain Adaptation기법이나 Augmentation 기법이 제안되었습니다. 이에 대해 “그냥 sim, real 데이터 동시에 학습시키니까 domain gap 해결이 효과적으로 되던데?”인 co-training이 제시되었지만 empirical한 연구에서 그쳤다는 아쉬움이 있었는데요, 더 나아가 구조적으로 co training의 objective를 명확하게 정하고, 이를 강화하는 파이프라인을 제시한 연구입니다.
Introduction
Behavior Cloning 기법들은 robot manipulation 분야에서 주류 접근법으로 주목받아 왔습니다. 그러나 이러한 기법으로 강인하고 일반화 가능한 성능을 얻으려면 다양한 환경과 객체 구성, 작업에 걸쳐 대규모 시연 데이터셋을 수집해야 하는데, 이는 실제 로봇으로 수행할 경우 막대한 인력·시간과 비용이 소요되어 확장성이 떨어집니다. 이를 해결하기 위해 시뮬레이션을 활용한 데이터 수집이 대안으로 떠올랐습니다. 물리 시뮬레이터가 발전하고 데이터 생성 기술이 발전하면서 가상 환경에서 방대한 로봇 시연을 비교적 저렴하게 생성할 수 있게 되었지만, 시뮬레이션에서 학습된 정책을 현실 세계에 그대로 적용하는 것에는 여전히 큰 어려움이 존재합니다. 같은 동작이라도 가상 환경과 실제 환경에서의 visual observation이 다르거나, 센서 노이즈나 물리 역학의 차이 등으로 인해 시뮬레이터에서 잘 동작한 정책이 현실에서는 실패하는 문제가 발생합니다. 특히나 Visuomotor control에서는 조명, 텍스처 등 시각적 차이로 인한 갭이 매우 커서, 현실 배치 시 변하는 시각 조건에도 정책이 견고함을 유지하도록 학습하는 것이 어렵습니다. 이러한 domain gap을 줄이기 위해 Domain Adaptation 기법들이 등장했으나, 파라미터에 매우 민감하고 visual gap만을 해결하다보니 action과의 연관성은 여전히 문제로 남아있었습니다.
위 문제를 해결하기 위해 저자들은 co-training, 시뮬레이션 데이터의 풍부함과 현실 데이터의 현실스러움을 동시에 학습시키는 방법을 선택했습니다. 핵심 아이디어는 co-training 프레임워크를 구축하되, 기존과 같이 단순히 두 도메인의 데이터를 합쳐 학습하는 데 그치지 않고 두 도메인의 observation-action 관계 분포를 동일한 latent space에 정렬하는 objective를 명시적으로 만들었습니다. 저자들은 Latent에서 시뮬레이션과 현실의 유사한 상태들이 서로 가깝게 위치하도록 만들어 observation과 그에 대응하는 action의 joint distribution를 정렬하면 더 풍부하고 task-relevant한 신호를 학습할 수 있다고 주장합니다. 예를 들어 같은 작업을 수행하는 시뮬레이션 장면과 현실 장면이 있다면, 두 장면을 단순히 픽셀 단위로 비슷하게 만드는 것이 아니라 “로봇이 취해야 할 행동”까지 고려해 latent space에서 정렬하면 policy가 두 domain에 공통된 특징 (집중해야 하는 부분)에 주목하게 된다는 것입니다. 이를 구현하기 위해 저자들은 Optimal Transport에 영감을 받은 손실 함수를 만들고 더 나아가 대량의 시뮬레이션 데이터와 소량의 현실 데이터 간의 심각한 데이터 불균형 문제를 다루기 위해 UOT 기반으로 확장했다고 합니다. 그 결과, 아래 Figure 1과 같이 소수의 현실 데모만으로도 풍부한 시뮬레이션 데이터를 활용하여 현실에서의 success rate를 30%까지 향상시켰으며, 나아가 시뮬레이션으로만 학습한 상황에서의 zero shot sim to real 또한 실험으로 입증했습니다.
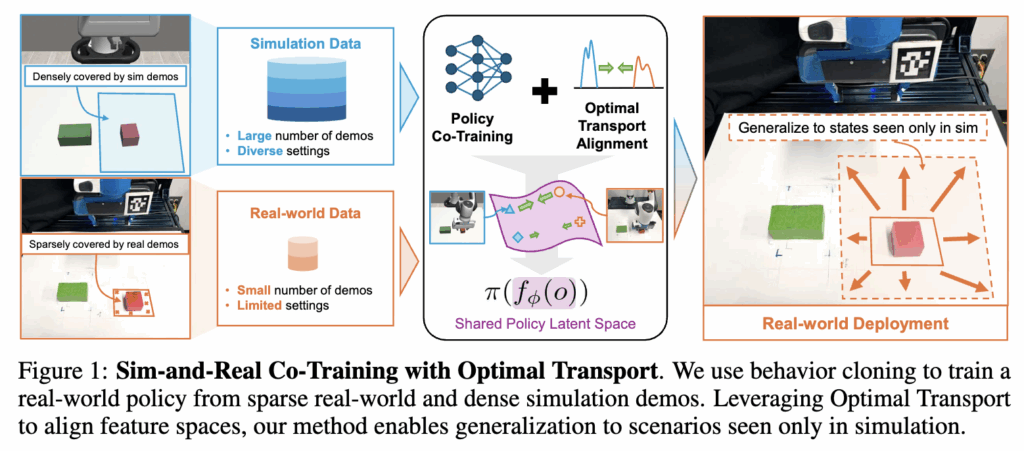
Related Works
늘 나오는 이야기지만, 로봇 조작을 위한 정책을 가르치는 Behavior Cloning은 효과적임에도 다양한 환경에 적응하려면 방대한 현실 데이터가 필요하다는 가장 큰 비용 문제가 있습니다. 이에 대한 대안으로 MimicGen과 같은 도구를 이용해 시뮬레이터에서 적은 시연만으로도 대량의 데이터를 생성하는 방법이 주목받았습니다. 하지만 시뮬레이션 데이터만으로 학습하면 Sim-to-Real 갭 때문에 현실 적용 시 성능이 떨어지며, 특히 quasi-static 작업에서는 visual gap이 가장 큰 걸림돌이 됩니다. 따라서 visual gap을 주된 문제삼아 Sim-to-real Gap을 줄이기 위해 다양한 시도가 있었으나 각각 명확한 한계가 존재했습니다.
- Domain Randomization : 시뮬레이션 환경을 무작위로 바꿔가며 현실과 비슷하게 만들려 했으나, 두 환경의 특징이 정확히 매칭된다는 보장이 없고 세밀한 정보를 놓치기 쉽고, 파라미터에 매우 민감하다고 합니다.
- Domain Adaptation : 시뮬레이션과 현실의 데이터 분포를 맞추려는 시도가 있었지만, 대부분 Marginal Distribution만 맞추려 시도했기 때문에 전체적인 통계치는 비슷해질지 몰라도, 정작 “특정 상황에서 어떤 행동을 해야 하는지”에 대한 연결 고리는 잃어버리는 문제가 있다고 합니다.
- Co-training : 단순히 sim과 real 데이터를 동일 배치에 특정 비율로 섞어 학습하는 방식입니다. 의외로 효과적이었지만, latent space를 명시적으로 일치시켜주지 않기 때문에 학습이 불안정하거나 한쪽으로 치우칠 우려가 여전히 남아 있었다고 합니다.
따라서 저자들은 co-training과 Optimal Transport를 결합해 co-training의 장점인 데이터 다양성을 유지하면서 latent space를 구조적으로 정렬하는 통합 프레임워크를 제안했습니다. 이 때 기존의 unsupervised 방식과 달리, 현실 데이터에 포함된 행동 정보를 학습 신호로 활용해 vision과 action의 Joint Distribution을 정렬함으로써 의미 정보를 보존했다고 합니다.
Problem Formulation
저자들은 해결하고자 하는 문제를 simulation (source domain)과 real (target domain) 둘 다의 데이터를 사용해 하나의 정책 π를 학습하는 Sim-and-Real Co-Training 으로 정의했습니다 . 두 domain 모두 동일한 로봇과 task를 다루며, 근본적인 상태 공간 S와 행동 공간 A는 공유한다고 가정했습니다. 로봇은 카메라 영상이나 3D 센서로부터 visual observation(o)를 얻고 로봇 관절 상태, end effector 위치인 proprioception 정보 x도 함께 받습니다. 이를 통해 정책은 π(a | z, x) 형태로 동작합니다. (z는 o를 인코딩한 latent입니다.) 목표는 현실 도메인에서 높은 성능을 내는 동시에, 현실 시연 데이터에 포함되지 않은 상황에도 대응할 수 있는 정책을 얻는 것입니다. 이를 위해 저자들은 공통 잠재 공간 Z을 학습하는데 초점을 두어 문제를 해결했습니다.
시뮬레이션과 현실 간의 domain gap은 주로 시각적 차이 (o의 분포 차이)로 나타나며, 같은 상태 s를 두고 보더라도 시뮬레이터가 생성하는 영상 o_src와 실제 카메라가 촬영한 영상 o_tgt은 다릅니다. 예를 들어 같은 물체와 로봇 배치여도 시뮬레이션 상에서는 텍스처와 조명이 인위적이지만, 실제 이미지는 질감, lighting, 카메라 노이즈 등의 변수를 가지고 있습니다. 결국 source와 target 도메인 간의 확률분포 P_src(o)와 P_tgt(o)이 불일치하며, 이것이 정책 일반화에 어려움을 주는 핵심 원인이라고 합니다.반면에 Action(a)이나 proprioception(x)은 동일 작업에 대해 시뮬레이터와 현실이 큰 차이가 없다고 가정한다고 합니다. 이는 두 도메인에서 데이터를 생성하는 방식이 유사하고, 특히 ee의 경우 시뮬레이션과 유사한 정도로 로봇 자체의 상태 추정이 정확하다고 본다고 합니다.
따라서 저자들은 visual domain gap에 집중해 시뮬레이션과 현실의 관측을 동일한 표현 공간 Z에 매핑하는 인코더 f φ를 학습하는 것을 목표로 합니다. 이때 중요한 것은 task-relevant한 특징만 남기고 도메인 특유의 차이는 걸러낸 domain invariant한 표현을 얻는 것이라고 합니다. (X-sim과 동일한 목표지만 x-sim은 contrastive learning을 사용해 인코더를 학습시킨것이 차이인 것 같습니다.)
이를 위해 저자들은 두 가지 목표를 언급했습니다.
- 시뮬레이션과 현실 시연 데이터에 공통으로 등장하는 상황들에 대해서는 두 도메인의 observation이 동일한 z로 매핑되도록 학습
- 시뮬레이션에서만 등장하고 현실에는 없는 상태들에 대해서도, 나중에 현실에서 유사한 장면이 나오면 인코더가 그에 맞는 일관된 임베딩을 내도록 일반화 능력을 학습. (이 부분이 task-relevant한 특징을 학습한다는 맥락이라고 이해해도 될 것 같습니다.)
핵심은 결국 단순 도메인별 시각 정보 이상으로, 본질적으로 지금이 어떤 상태인가?를 파악하도록 인코더를 학습하는것이 목표입니다. 그러나 co-training은 세팅상 현실 데이터가 전체에서 소량만 차지하기 때문에, 필연적으로 시뮬레이터가 커버하는 분포가 현실보다 넓고 다양한데, 이러한 partial data overlap 문제 또한 해결했다고 합니다.
Methods
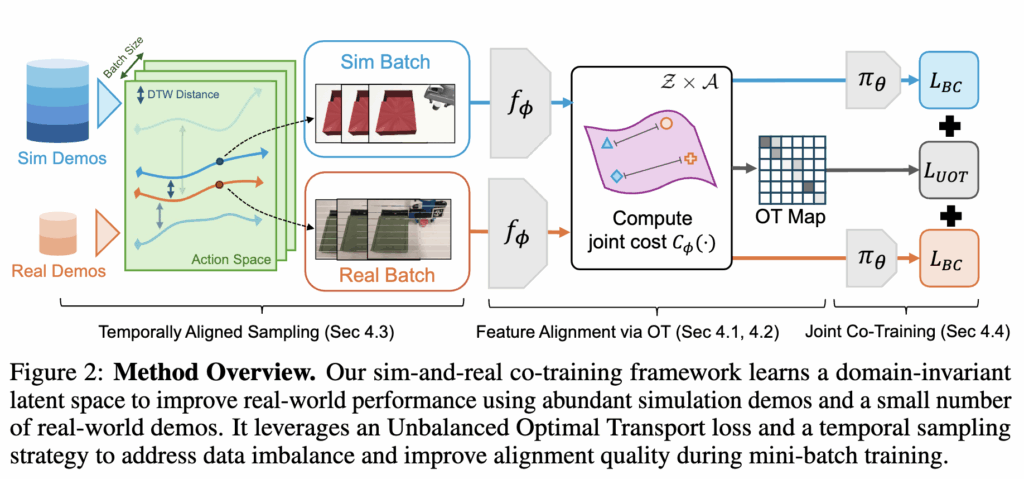
저자들은 sim, real의 강건한 표현이 가능한 인코더를 학습하기 위해 Optimal Transport를 통해 latent representation을 명시적으로 정렬하는 co-training 프레임워크를 제안했습니다. 핵심은 target domain과 source domain간의 visual latent feature의 정렬을 유도하기 위해 action정보를 활용하는 것입니다. 이를 위해 저자들은 joint observation-action 분포를 정렬하기 위해 OT에 기반한 loss를 제안하고, UOT (Unbalanced Optimal Transport)와 temporally-aware sampling strategy를 통해 데이터 불균형 문제를 해결했습니다. 이러한 요소들이 위의 Figure 2처럼 하나의 프레임워크로 제안되었습니다. 요소별로 하나씩 뜯어서 설명해보도록 하겠습니다.
Optimal Transport for Action-Aware Feature Alignment

Optimal transport는 두 확률분포 사이의 Wasserstein 거리를 최소화하는 매핑(transport plan)을 계산하는 수학적 프레임워크로, 해당 연구의 입장에서 생각해보면 시뮬레이션과 현실 데이터의 observation 임베딩 z와 action의 분포 간의 거리를 줄이는 데 활용됩니다. 핵심은 분포를 옮길 때 단순히 visual적인 유사도만 보는것이 아닌 행동까지 포함한 cost 계산식을 통해 유사한 행동을 해야하는 두 도메인의 state들을 latent space에서 가깝게 해주는 것입니다. 이렇게 하면 인코더가 도메인에 관계없이 유사한 로봇 행동을 이끌어낼 수 있는 시각적 특징들을 뽑아내도록 훈련되고, 결과적으로 정책이 시뮬레이션과 현실 모두에서 일관되게 작동할 수 있습니다.구체적으로, 시뮬레이션 데이터 집합 D_src = {(o_src^i, a_src^i)}와 현실 데이터 집합 D_tgt = {(o_tgt^j, a_tgt^j)}가 주어졌을 때, 인코더를 학습시키는 목표는 변환된 latent feature와 action의 관절값분포 P_src(z_src, a_src)와 P_tgt(z_tgt, a_tgt) 사이의 Wasserstein 거리를 최소화하는 것입니다. 워셔슈타인 거리가 비용 함수에 따라 정의되는데, 저자들은 아래 d로 z와 A에서의 거리(오차의 제곱)를 사용했습니다.
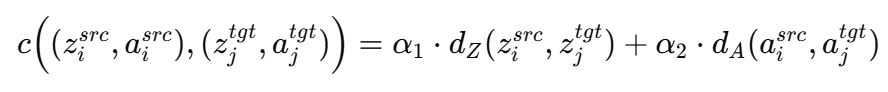
이 정의에 따라 OT 문제를 풀면, sim-real 간 행동이 유사한 데이터 쌍들을 가능한 한 서로 대응시키도록 인코더가 유도되고 이 때 인코더와 transport plan은 교차 최적화 방식으로 학습되는데, 보통 Sinkhorn 알고리즘 등을 사용하여 최적 Π를 찾고, Π가 주는 비용을 줄이도록 인코더를 업데이트하는 방식입니다. 이 과정을 통해 인코더는 시뮬레이션/현실 데이터 쌍 간의 비용을 점차 낮추는 방향으로 표현을 개선하고, 결과적으로 두 도메인의 임베딩 분포가 행동 측면에서 잘 맞춰진 공간이 형성된다고 합니다. (사실 그렇구나 하고 봤기 때문에 정확한 수학적인 계산은 아직 잘 모릅니다 하하,,)
이 때 추가적인 고려사항으로, 시뮬레이터와 실제 로봇 제어기의 차이 때문에 d_A(a_src, a_tgt)를 직접 비교하는 것이 올바른 학습으로 이어질 수 없다고 합니다. 예를 들어 시뮬레이터에서는 이상적인 PID 제어 명령을 사용하는데, 현실에서는 사람이 teleoperation한 데이터일 경우 동일한 행동이라도 제어 신호의 규모나 분포가 다를 수 있다고 하네요. (사실 잘 모르겠습니다) 이를 보완하기 위해, 저자들은 행동 유사도의 지표로서 proprioception(x)를 사용하는 현실적인 절충안을 택했습니다. EE의 위치는 시뮬레이션과 현실에서 표현이 일관되고 로봇의 실제 동작과 밀접하게 연관되어 있기 때문이라고 합니다. 따라서 실제 구현 상으로는 OT 비용 함수에서 action 대신 동일한 시간의 ee position 간 거리를 사용하여 두 도메인의 (임베딩 z, 로봇 상태 x) 조인트 분포를 정렬했다고 합니다.
Unbalanced Optimal Transport for Robust Alignment
일반적인 OT는 source의 모든 샘플을 target에 전부 매칭해야 하고, target의 모든 샘플도 source에 매칭시켜야 한다는 엄격한 제약이 있는데, 시뮬레이션 데이터가 현실보다 훨씬 많다면 한정된 현실 샘플에 여러 시뮬레이션 샘플을 억지로 붙여야 하거나, 반대로 매칭되지 않는 시뮬레이션 샘플들끼리도 어떻게든 짝지으려다 왜곡된 대응이 발생할 수 있다고 합니다. 시뮬레이션 데이터의 분포 중에는 현실 데이터에 아예 존재하지 않는 시뮬레이션 상태들 (sim only로 촬영한 데이터)도 많은데 이들까지 억지로 대응시키면 latent space가 비틀어진다고 합니다.
이를 해결하기 위해 저자들은 Unbalanced Optimal Transport (UOT) 기법을 적용했습니다. UOT는 OT의 제약식을 완화하여, 분포 질량이 반드시 보존되지 않아도 되도록 여지를 주는 방법입니다. (유하게 의미있는 구간만 맞춰준다고 밖에 이해 못 한것 같습니다,,) 구체적으로는, source 분포 p와 target 분포 q 사이의 OT 해법에 KL divergence 기반 페널티를 추가함으로써 unmatched mass를 허용한다고 합니다. 쉽게 말해, 꼭 모든 시뮬레이션 데이터를 어느 타깃 샘플에 대응시키지 않아도 되며, 대신 대응되지 않은 부분에 대해서는 페널티를 부여하고 넘어가는 방식이라고 합니다. 이렇게 하면 두 분포 중 정말 유사한 부분집합만 선택적으로 강하게 align한다고 하네요.저자들은 구현할 때 미니배치 단위의 샘플 집합에 대해 엔트로피로 정규화된 UOT loss를 위와 같이 정의했다고 합니다. 혹시나 궁금해하실 분이 있을까봐 캡쳐해두었습니다..
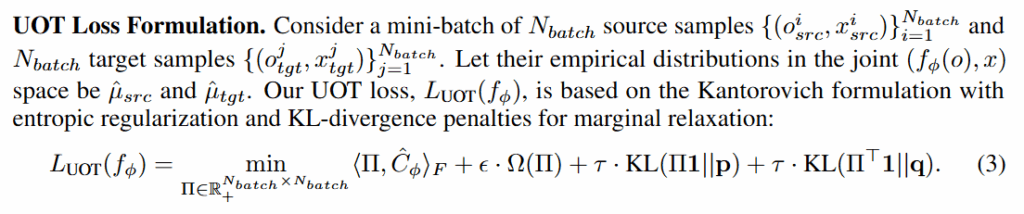
τ가 0에 가까우면 거의 일반 OT처럼 계산되고, τ가 크면 무시되는 형태라고 합니다. 이러한 UOT 기반 손실을 사용하면, 매 배치마다 sim-real 샘플 간 최적 부분 대응을 찾고 인코더를 그 방향으로 학습시킨다고 합니다. 결과적으로 UOT 방식의 loss를 통해 필요한 곳만 매칭하고 나머지는 버릴 수 있는 융통성을 인코더 학습에 부여하여 sim-real 간의 데이터 불균형으로 인한 부작용을 방지한다고 합니다.
Temporally Aligned Sampling
전체적인 method 상에서는 맨 앞 부분이지만 필요성이 OT를 위함이라 뒤에 설명되어있습니다. 저자들은 현실적으로 구현을 위해 미니배치 샘플링의 불일치 문제를 더 풀어야 한다고 합니다. 로봇 조작 데이터는 시간에 따른 trajectory의 시퀀스 형태인데, 시뮬레이션과 현실에서 무작위로 state-action pair를 샘플링해 미니배치를 구성하면 작업 단계가 뒤죽박죽인 쌍이 만들어진다고 합니다. 예를 들어 시뮬레이션에서는 작업 초반의 관측이, 현실에서는 작업 후반의 관측이 한 배치에 들어가 OT 매칭을 시도하면 엉뚱한 상태들끼리 맞춰집니다. 따라서 저자들은 시간적으로 정렬된 샘플링을 제안했습니다. 시뮬레이션 trajectory와 현실 trajectory 간의 유사도를 미리 계산하여 서로 비슷한 진행을 보이는 pair를 선정한 뒤 그 안에서 샘플들을 추출합니다. 구체적으로, 각 시뮬레이션 데모 trajectory ξ_src와 현실 데모 trajectory ξ_tgt에 대해 ee sequence의 Dynamic Time Warping (DTW) 거리를 계산해줍니다. DTW는 두 시계열의 유사도를 재는 알고리즘으로, 서로 다른 길이의 시퀀스라도 비교할 수 있고 전체 동작 패턴의 차이를 수치화한다고 합니다. 계산된 DTW 거리를 해당 두 trajectory의 비유사도로 보고, 이를 softplus 함수(시간상 그냥 그렇구나 했습니다.. 질문 주시면 찾아서 답해드리겠습니다)를 통해 샘플링 가중치 w(ξ_src, ξ_tgt)로 변환해줍니다. 거리 d가 작을수록 w 값이 크고, w값을 기준으로 비슷한 시뮬레이션-현실 경로 쌍이 선택될 확률을 올려줍니다.
실제로 미니배치를 구성할 때는 먼저 확률분포에 따라 한 개의 시뮬레이션 trajectory와 현실 trajectory 쌍(ξ_src, ξ_tgt)을 뽑습니다. 그리고 나서 그 둘 내부에서 같은 시점대의 전환들 (o, x, a)을 몇 개씩 샘플링하여 배치를 채우고 DTW로 정렬된 시점들을 기준으로 근처 시간대의 샘플을 짝지어 뽑아 fine-grained alignment를 적용합니다. 이를 통해 실질적으로 대응되는 상태들을 학습할 수 있다고 합니다. 부록에 이에 대한 실험 결과를 첨부했는데, 실제로 OOD에서의 성능이 sampling을 사용하지 않았을 때 보다 성능이 oracle 수준 (사람이 직접 맞춤)으로 뛰어난 것을 볼 수 있습니다.
Overal joint co-training framework

우선 인코더와 정책을 모두 초기화 해준 뒤, 시뮬레이션과 실제 환경의 trajectory 쌍 간 DTW행렬을 계산해줍니다. 이 D_src와 D_tgt는 이후 매칭 시 샘플링 전략에 사용됩니다. 이제 T번의 iteration 동안 src/tgt trajectory 쌍을 DTW 거리 기반으로 샘플링하여 페어링된 배치를 구성하고 인코더를 통해 각 trajectory의 observation, state를 latent feature로 변환한 뒤 OT cost를 구성한 뒤, 해당 비용 행렬을 최소화 하는 행렬을 계산한 뒤 UOT loss를 계산해줍니다. 이후에는 시뮬레이션과 현실에서 샘플링한 BC 데이터를 통해 인코더와 policy를 통해 loss를 계산한 뒤에 한 번에 공동으로 업데이트 해줍니다.
Experiments
저자들은 현실에서 20hz 주기의 D435 카메라 (제 3자 뷰)와 Franka Panda를 가지고 Diffusion Policy, 3D Diffusion Policy를 가지고 다음과 같은 질문에 답을 얻으려 실험을 진행했다고 합니다. 시뮬레이션 환경은 Robosuite를 사용했고, 시뮬레이터 상의 카메라 파라미터는 현실을 기준으로 정밀하게 calibration했다고 합니다. Task에 따라 10~25개의 human demo를 촬영하고, 이를 MimicGen을 통해 200~1000개의 가상 demo로 변환했다고 합니다. 베이스라인으로는 시뮬레이션(source) 데이터만 활용, 현실(target) 데이터만 활용, 기존의 배치 구성만 같이 하는 co-training, MMD Domain Adaptation loss를 추가한 co-training으로 진행됐습니다. Task는 아래와 같이 6개의 task로 진행했습니다.

- 제안한 방법이 복잡한 조작 과제들을 시뮬레이터와 실제 환경 모두에서 성공적으로 학습하는지
- 시뮬레이터에서만 본 상황(Out-of-Distribution)에도 현실에서 잘 일반화되는지
- 이미지, pointcloud 등 여러 모달리티에 걸쳐 동작하는 일반성을 보이는지
- 시뮬레이션 데이터의 규모를 늘리면 일반화 성능이 향상되는지
Cross-Domain Generalization Results
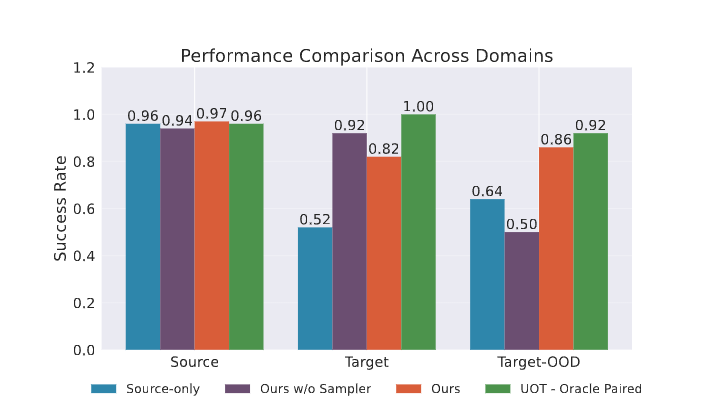
일단 RGB 기반의 Source 도메인에서의 적응 능력입니다. 저자들은 카메라 시점(V)이나 텍스처(T)가 학습 때와 달라지는 OOD 상황을 설정하여 평가했습니다 T-O가 시뮬레이션에서의 OOD입니다. 실험 결과, 현실 데이터만 사용한(Target-only) 정책이나 시뮬레이션 전용(Source-only) 정책은 OOD 성공률이 0%입니다. 이는 명확한 한계이기 때문에 어찌보면 당연한 결과라고 생각합니다. Co-training의 경우에는 Viewpoint에 대한 강인성이 아예 없는 것을 확인할 수 있습니다. 시각과 액션이 고려되지 않았기 때문이라고 볼 수 있을 것 같습니다.
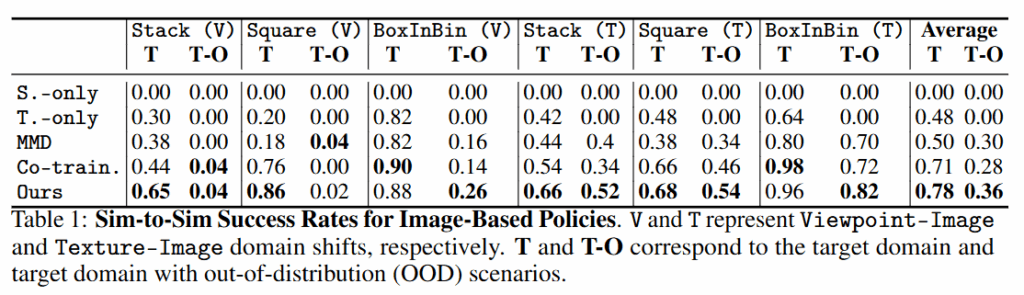
모달리티를 pointcloud로 넘어갔을 때도 비슷한 양상을 보였습니다.
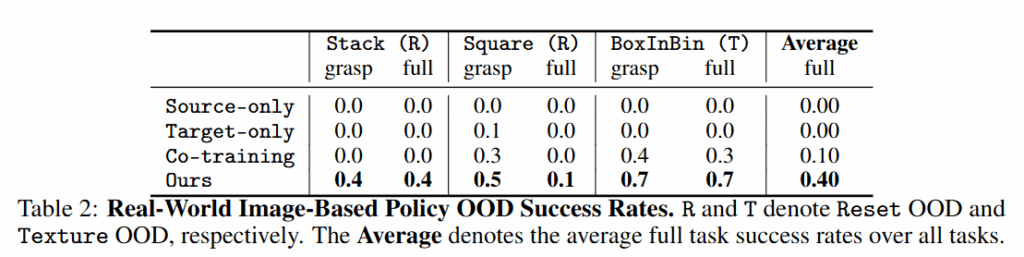
Image 기반의 Real World에서는 더 뚜렷한 차이를 볼 수 있었습니다. 특히 보지 못 한 초기위치에는 아예 대응을 못하는 모습 (전형적인 DP의 한계)를 볼 수 있습니다. Co-training 또한 현실에서 초기위치에 대한 일반화 능력을 준다고 했는데, 시뮬레이션에서 보지 못 한 환경에 대해서는 0에 수렴하는 것을 볼 수 있습니다.
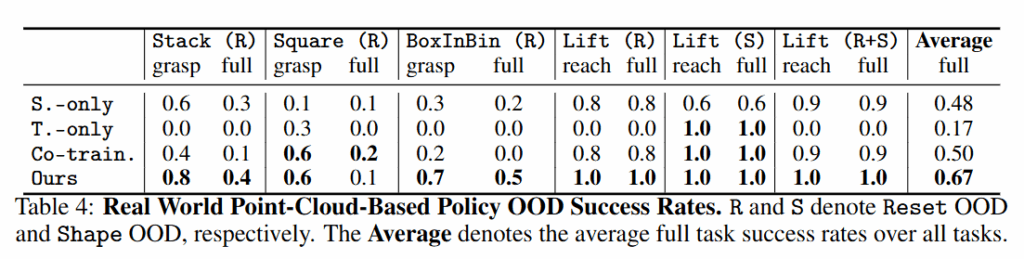
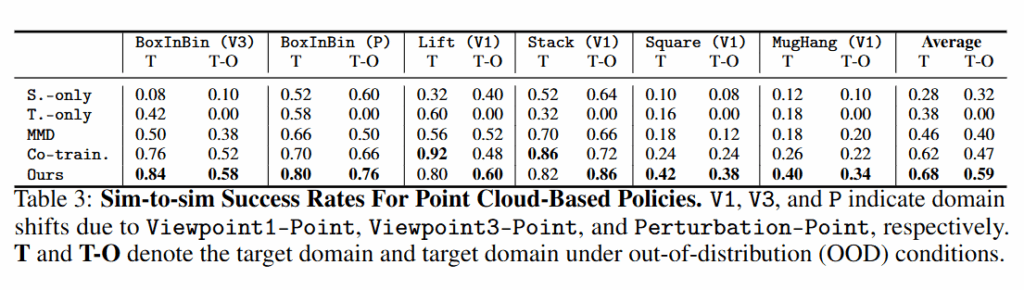
point cloud를 활용하는 경우 조금 나아진 모습을 보이지만 시뮬레이션 데이터와의 공동 학습은 현실 데이터만으로 학습하는 것보다 훨씬 유리하며, 특히 제안한 OT 정렬을 활용하면 현실에서 드물거나 처음 마주치는 상황에 대해서 확실히 우수한 성능을 확인할 수 있습니다.
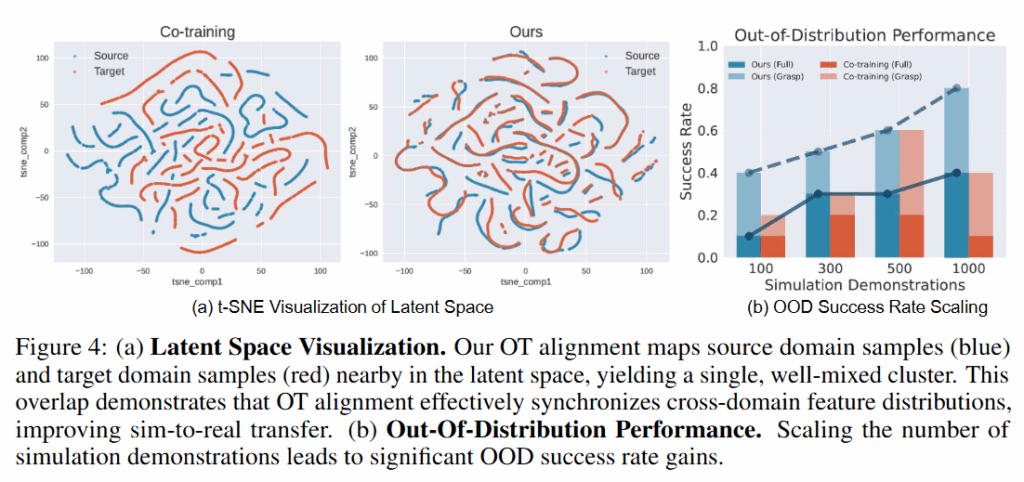
전체적으로 정리해보자면, 저자들의 OT 기반 co-training이 특히 현실에서 학습 데이터 분포를 벗어난 변화 에 대해서 공동학습 대비 훨씬 뛰어난 일반화 능력을 증명했습니다. 이러한 학습 방식이 실제로 본 적 없는 상황도 본 것처럼 할 수 있는 (행동에 대한 이해)를 한다고 생각하빈다. 또 무엇보다 시뮬레이션 데이터가 어떤 면에서 도움을 줄 수 있는지가 뚜렷하고, 현실 데이터가 적은 상황에서 Target-only 대비 크게 향상된 성능을 얻을 수 있다는 것을 확인했습니다. 위와 같이 t-SNE를 보았을 때도 정렬이 잘 된 것과 이에 따라 OOD에서의 성능이 뛰어남을 확인할 수 있습니다. 무엇보다 action을 anchor 삼아서 latent를 정렬하는 sim2real의 새로운 방향과 이를 통한 OOD에서의 성능 향상을 확인할 수 있어서 앞으로 합성데이터의 방향에 대해서 해당 관점으로 더 생각해볼 수 있지 않을까 싶습니다.