안녕하세요. 저의 첫 번째 X-Review에서는 요즘 서베이 중인 OVAD 논문을 다루어보고자 합니다. 해당 논문은 OVAD 태스크를 처음으로 제시한 논문입니다.
1. Introduction
컴퓨터 비전의 주요 목표 중 하나는 이미지 내에서 다양한 시각 정보들을 localize 및 recognize 하는 것입니다. 다들 알고 계시다시피 OVD task는 image-text 쌍의 weak supervision을 사용하여 보지 못한 객체에 대해서도 detection을 잘 수행할 수 있도록 발전해왔습니다. 그러나 단순 클래스를 넘어선 자세한 정보에 대해서 얼마나 잘 일반화할 수 있는지는 불분명하다고 저자는 말합니다.

속성(attribute)은 객체의 정체성에 중요한 역할을 합니다. 위 그림에서 초록색 박스를 단순히 곰이라고만 인식하기보다, 나무로 만들어졌다는 정보까지 인식할 수 있다면 그 정보만으로도 이 곰이 모형이고 무해하다는 것을 깨달을 수 있습니다. 따라서 object와 attribute를 모두 탐지하는 모델은 이 두 정보를 결합하여 더욱 풍부하고 상황에 맞는 추론을 가능하게 합니다.
이러한 문제 의식에 따라, 저자는 Open-vocabulary Attribute Detection(OVAD)라는 태스크를 제시합니다. OVAD는 다음 두 단계로 구성됩니다.
- OVOD: novel object를 포함하여 이미지 내 모든 object를 detect
- attribute: 탐지된 모든 object에 존재하는 속성을 결정 (뒤에 서술할텐데, 정해진 attribute에 대해 positive 또는 negative로 분류하는 classification 문제입니다.)
본 논문의 주요 contribution은 다음과 같습니다.
- OVAD task를 정의
- OVAD task를 위한 깨끗하고 밀집된 OVAD 벤치마크 제안
- OVAD task를 위한 attribute-focused baseline method 제안
- 여러 오픈소스 foundation 모델의 attribute detection 성능 테스트
2. Related Work
OVAD 태스크, 벤치마크, 베이스라인 방법론을 모두 제시한 논문이다보니, Related Work를 조금 자세히 다루어보고자 합니다.
Attribute prediction
- 초기 연구는 attribute라는 것을 객체의 한 부분(자동차의 바퀴, 사람 얼굴의 눈 등)으로 정의했다고 합니다. 그러나 이는 부분 단위의 object detection 문제라고 볼 수 있습니다.
- 기존 벤치마크는 신발, 의류, 동물 등 특정 도메인에만 국한되어 있습니다.
- 또한 일부 연구는 image → attribute → object 와 같이 attribute를 중간 단계 표현으로 활용하고자 했습니다. 즉 attribute를 OVOD의 성능 향상을 위한 중간 도구로써 활용한 것입니다.
→ 본 논문에서는 형용사로 표현되는 visual attribute에 초점을 맞추었으며, zero-shot 방식으로 객체의 attribute를 구별하고 탐지하는 것을 목표로 합니다.
Attribute detection benchmark
- COCO Attributes: COCO 데이터셋에 visual attribute를 어노테이션한 최초의 벤치마크입니다. 그러나 29개의 object category만 포함한다는 한계가 있습니다.
- Visual Genome: 68,000개 이상의 attribute category를 제공하지만, 각 객체에 대한 attribute는 0.74개에 불과해 매우 희소합니다.
- VQA datasets: attribute를 질의하는 용도로 도입되었지만, attribute에 대한 성능을 분리해 분석할 수 없습니다.
- VAW: 풍부하고 신뢰할 수 있는 positive / negative attribute label을 제공하고, 각 object-attribute 쌍에 대해 최소 50개의 instance가 존재합니다. 그러나 자동 필터링을 사용했기 때문에 이미지 당 인스턴스, 인스턴스 당 attribute의 측면에서는 매우 희소합니다.
- Open Images: 9백만 개의 이미지, 288개의 object category를 제공하지만 15개의 attribute category만 제공합니다.
→ 위와 같은 한계점을 보완하기 위해 clean하고 dense한 attribute annotation을 갖춘 벤치마크를 제안합니다.
Open-vocabulary methods
OVD task는 Intro에 서술하였듯, image-caption 쌍을 활용한 weak supervision을 통해 처음 보는 객체도 올바르게 탐지하는 것을 목표로 합니다. 이와 관련된 후속 연구들은 다음과 같습니다.
- localized image-caption matching: caption의 일부를 이미지의 국소 영역과 정교하게 matching하도록 학습
- object query에 형용사를 추가한 fine-grained object detection
- extra class annotation을 사용해 detector의 classifier module을 학습
- psuedo-bounding-box를 사용해 detector 학습
→ 이러한 open-vocabulary 연구 흐름에 attribute를 포함하도록 확장합니다.
Vision-language models
흔히 알고있듯, 웹 상의 대규모 데이터를 사용하는 foundation 모델들은 vision 정보와 language의 align이 맞추어지도록 학습되어, 시각적 추론 작업에서 탁월한 성능을 보입니다.
→ 다섯 가지 오픈소스 foundation 모델에 대해 OVAD 성능 평가를 진행합니다.
3. Open-vocabulary Attribute Detection
3.1. The OVAD Task
앞서 서술했듯이 OVAD task는 [step 1] OVOD, [step 2] 탐지된 모든 object에 대한 attribute 판단, 두 단계로 나뉩니다. 이때 base class 집합을 O^B, novel class 집합을 O^N이라고 정의합니다.
step 1에서는 기존 OVOD와 마찬가지로, 학습 중에 O^B은 class label과 bbox가 모두 주어지지만, O^N은 그럴 수 없기 때문에 image-caption 쌍을 통해 weak supervision으로 학습됩니다.
이와 달리 step 2에서는 학습 중에는 attribute가 모든 클래스에 대해 전혀 주어지지 않으며, 평가 시점에만 주어집니다. 따라서 학습 중 attribute에 대한 모든 지식은 image-caption 쌍 또는 사전 학습된 VLM에서 파생됩니다.
또한 attribute 인식 능력 자체를 평가하기 위해, 테스트 시 box-oracle을 적용합니다. box-oracle이란 모든 객체에 대해 정답 class와 bbox가 주어진 세팅을 의미합니다. 이를 통해 detector(step 1)의 영향이 제거되어 순수 attribute 분류(step 2) 능력만 평가합니다.
3.2. The OVAD Benchmark
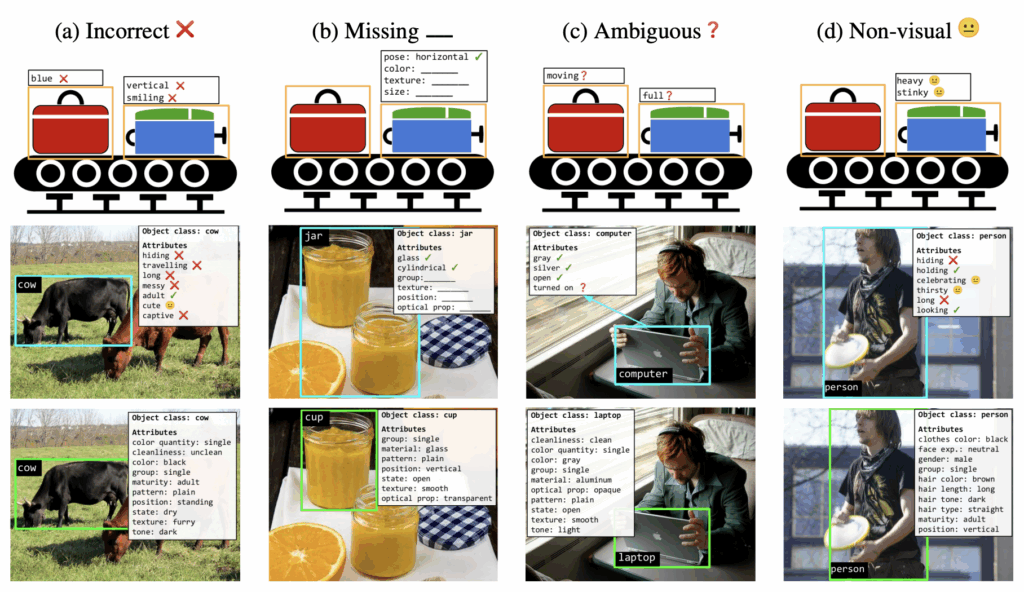
기존 데이터셋들의 한계점을 아래와 같이 총 네 가지로 분류하였습니다. (네 유형 간의 경계는 사실상 모호하다고 저자는 설명합니다.) 위 그림에서 첫 번째와 두 번째 행은 기존 한계점에 대한 예시이며, 마지막 세 번째 행은 본 논문에서 제시하는 벤치마크입니다.
Type-A Incorrect
잘못된 attribute를 할당한 경우입니다. (hiding, travelling, long 등 맞지 않는 속성이 cow에 할당됨)
Type-B Missing
attribute가 누락된 경우입니다. 이미지에서 속성의 시각적 근거가 충분하다면 attribute로 포함되어야 하는데 그렇지 않은 경우를 말합니다. (jar 예시에서 병의 텍스처나 위치 속성이 없음)
Type-C Ambiguous
주어진 이미지만으로 판단할 수 없는 attribute를 할당한 경우입니다. (사진만 보고 노트북이 turned on 상태인지는 모름)
Type-D Non-visual
시각적 정보로 표시할 수 없는 attribute를 할당한 경우입니다. (thirsty 등)
본 논문에서는 위와 같은 한계점을 보완하기 위해, 모든 객체에 대해 annotation 할 수 있고 시각적으로도 모호하지 않은 attribute 집합을 선정하고자 했습니다. MS-COCO(object detection) validation 데이터셋에서 무작위로 2,000개의 이미지를 뽑아 누락되거나 부정확한 박스를 수정하여 14,300개의 object instance를 얻었습니다. 그 후 각 instance에 대해 117개의 attribute를 수동으로 labeling 하였습니다.
Selection of attributes
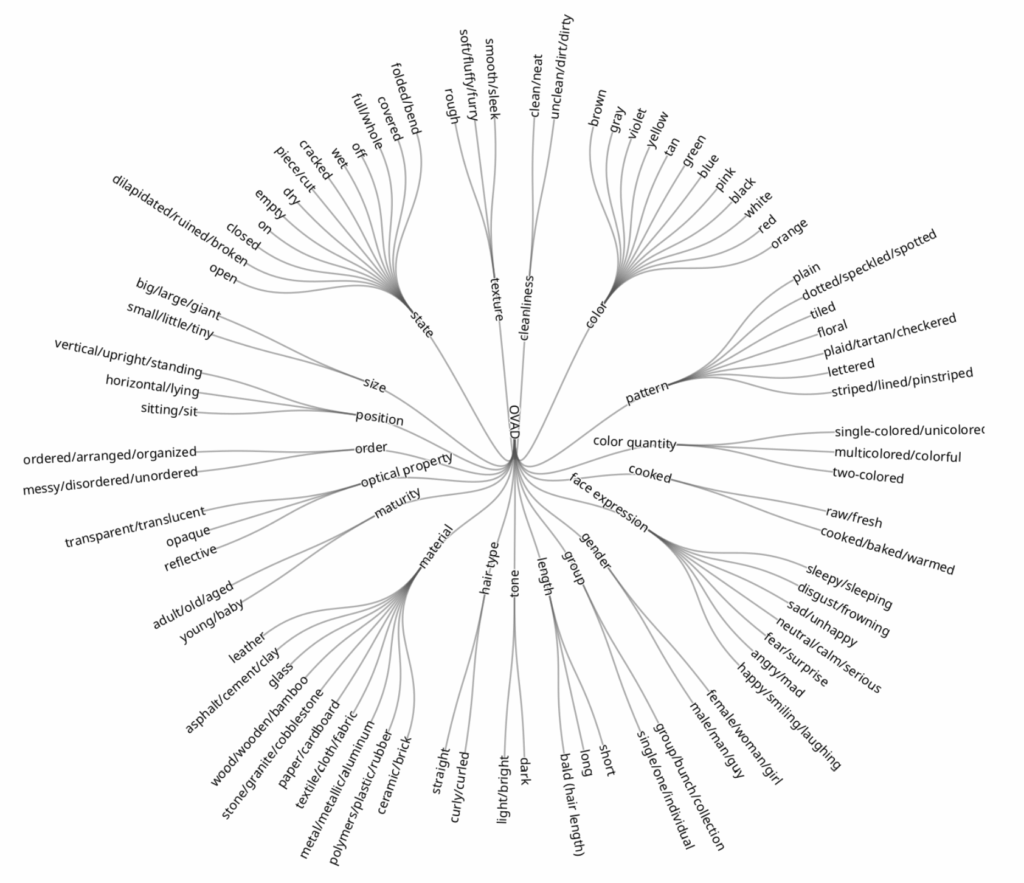
COCO Captions의 캡션에서 형용사를 추출하고 동의어 별로 그룹화한 뒤, 추상적이거나 non-visual한 형용사는 수동으로 제거합니다. 이 과정을 통해 총 117개의 attribute를 얻었고 이들을 19개의 상위 클래스(attribute 유형)로 분류하였습니다. 이 분류 체계의 정확한 구조는 위 그림에서 확인하실 수 있습니다.
Annotation process
자동화 툴을 사용하지 않고 사람이 직접 모두 annotation하였으며, 모든 attribute에 대해 positive / negative / unknown 중 하나로 분류합니다. 이때, attribute 유형 내에서의 각 속성들은 mutual exclusive합니다. (position이라는 유형에서 vertical과 horizontal이 동시에 positive일 수는 없는 것이 그 예입니다.) 따라서 각 유형 내에서 하나가 positive라면 나머지는 전부 negative로 분류하며, 또는 모두 unknown으로 분류합니다. unknown으로 분류된 속성은 평가에서 제외됩니다.
Statistics
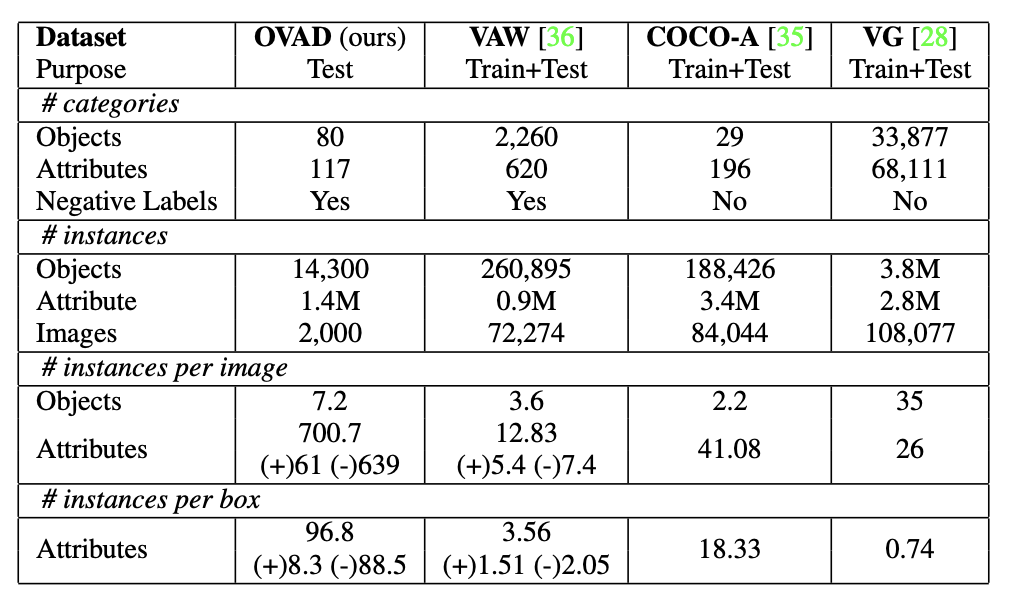
위는 기존 데이터셋과의 통계량 비교를 나타낸 표이며, (+)는 positive, (-)는 negative attribute label을 의미합니다.
Evaluation metric
다음 두 가지 평가 방식을 사용합니다.
(1) Open-vocabulary detection: “object detection → attribute” 전체 파이프라인 성능을 평가
- 80개 클래스에 대해 AP50(IoU=0.5)
- IoU ≥ 0.5인 매칭에 대해서 attribute mAP
(2) Box-oracle setting: object의 정답 bbox와 label은 주고 attrbute 탐지 성능만을 평가
- 주어진 bbox 내에서 attribute mAP
4. OVAD Baseline Method
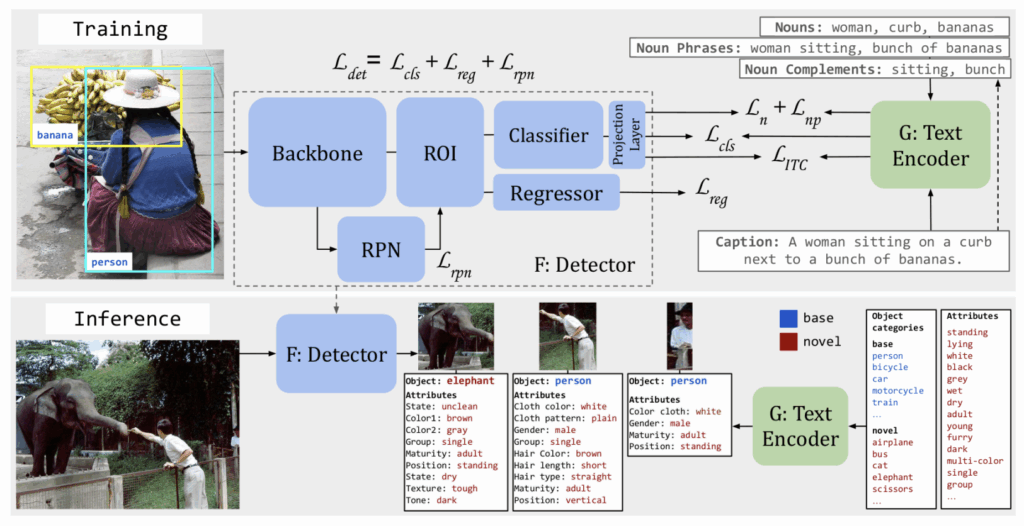
OVAD-Baseline은 다음 두 모델로 구성됩니다.
(1) frozen language model G (CLIP을 사용)
(2) Faster R-CNN 기반 object detector F (classification head를 선형 레이어로 교체하는데, 이 선형 레이어는 visual feature가 언어 모델 G의 언어 공간으로 투영되도록 합니다.)
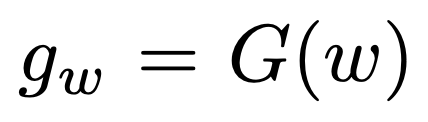
: text w의 임베딩 표현
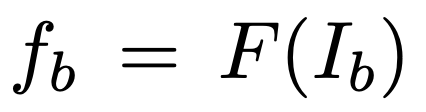
: image I의 box 영역 b의 임베딩 표현
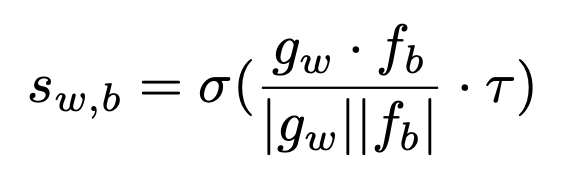
g_w와 f_b 간 cosine similarity를 사용하며, tau는 temperature 하이퍼파라미터이고 sigma는 sigmoid 함수입니다.
Training objectives
detector F는 다음 세 가지 목표로 학습됩니다.
(1) 이미지에서 객체를 localize
L_det = L_cls + L_reg + L_rpn
(2) 이미지와 캡션 임베딩을 매칭
L_ITC = −(y log(s_{C,I}) + (1 − y) log(1 − s_{C,I}))
- s_{C,I}는 캡션 C와 이미지 I간 코사인 유사도, y는 C와 I가 positive 쌍이면 1, 아니면 0
(3) novel class와 attribute를 예측하기 위해 proxy-label로 classifier branch 학습
캡션의 일부분인 parts-of-caption(명사, 명사구, 명사보어)을 proxy-label로 삼아 학습합니다. 이 parts-of-caption은 오픈소스 소프트웨어인 spaCy의 품사 태깅 방법을 사용해 얻습니다. 이때 명사구란 형용사+명사와 같이 속성 정보를 더욱 명확하게 포함하는 형태이며, 명사 보어란 명사구에서 명사를 제외한 형태입니다.
이때 proxy-label에 대응하는 bbox를 정확히 알 수 없으므로, 예측된 bbox 중 가장 큰 것(F(I_b_max))과 매칭합니다. 또한 임의의 image-caption 쌍을 사용해 negative proxy label도 생성합니다.
binary cross entropy loss를 사용하며, 명사와 명사구/명사보어에 대한 loss는 각각 L_n, L_np입니다.
5. Experiments
5.1. Open-vocabulary Attribute Detection
OVAD-Baseline과 기존 OVD 모델의 OVAD 성능을 비교하였습니다.
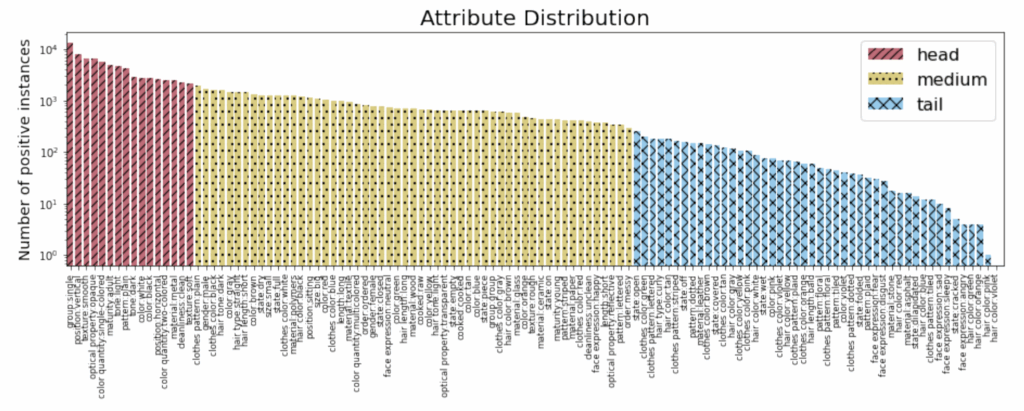
먼저 속성의 분포는 위와 같이 long-tail 분포이기 때문에 head, medium, tail에 대한 성능을 각각 측정하였다고 합니다. head는 16개, medium은 55개, tail은 46개의 attribute class를 포함합니다.
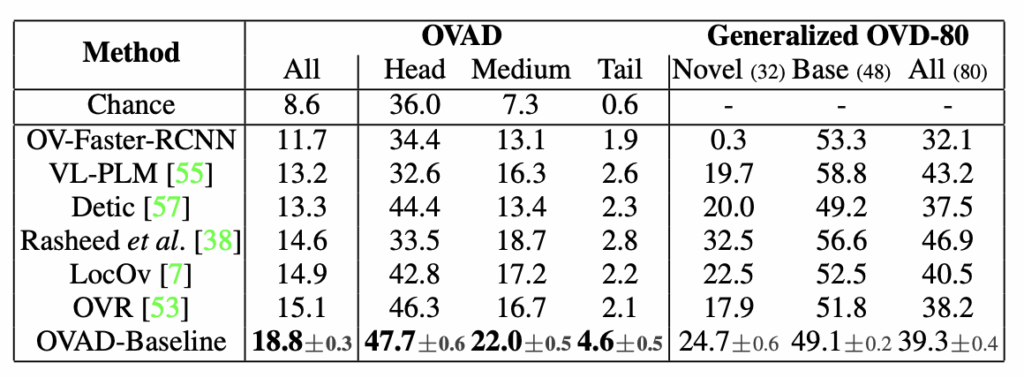
여기서 OVAD는 말그대로 OVAD(object detection + attribute classification) 실험이고, Generalized OVD-80은 object detection 성능입니다. (3.2절의 Evaluation metric (1)에 해당)
먼저 OVAD를 보면, OVAD-Baseline이 기존 OVD 모델보다 모든 분포에서 mAP가 가장 높음을 확인할 수 있습니다. 그러나 Generalized OVD-80에서는 기존 OVD 모델이 OVAD-Baseline보다 더 높은 객체 탐지 성능을 보이는 경우도 있습니다. 따라서 object detection에서 좋은 성능을 보이는 모델이 반드시 OVAD에서도 더 나은 것은 아니라는 점을 확인할 수 있습니다.
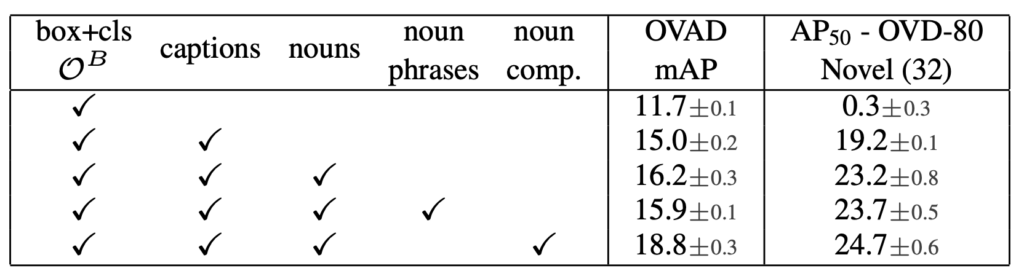
위는 parts-of-caption에 대한 ablation 실험입니다. 먼저 특별한 처리 없이 caption을 학습에 포함시키는 것만으로도 성능이 크게 향상되는 것을 볼 수 있습니다. 또한 명사 보어(noun comp.)를 사용하는 것이 attribute supervision을 더욱 명시적으로 만들고 언어 구조의 구성성을 최대한 활용한다고 저자는 설명하였습니다.
5.2. Foundation Models Applied to Attributes
OVAD 벤치마크의 가치를 입증하기 위해, 저자는 5개의 사전 학습된 VLM의 zero-shot 성능을 비교하였습니다. 이때에는 attribute 성능만을 독립적으로 파악하기 위해 box-oracle 설정을 사용합니다.
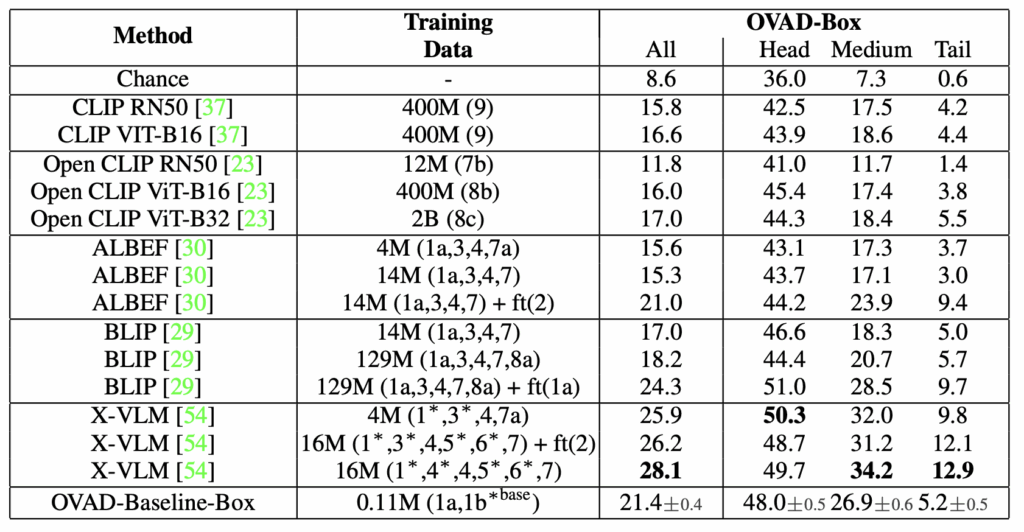
위 결과를 보면 알 수 있다시피 foundation model에게 attribute detection은 어려운 과제입니다. 비교적 훨씬 적은 데이터셋으로 학습된 OVAD-Baseline의 성능에도 미치지 못하는 경우가 많습니다. 저자는 이를 통해 foundation model이 객체 클래스에 편향되어 있으며 attribute와 같은 fine-grained한 특징을 포착하지 못한다고 설명합니다.
6. Conclusion
본 논문은 OVAD 태스크를 제안하고, 태스크 평가를 위한 clean하고 dense한 벤치마크를 소개했으며, baseline 방법론을 제시했습니다. 또한 foundation 모델들의 속성 인식 능력을 테스트하여 이 모델들의 성능이 낮다는 것을 발견하였고, 그렇기 때문에 OVAD의 발전을 위한 추가적인 연구가 필요하다는 주장을 하며 글을 마무리하고 있습니다.
읽어주셔서 감사합니다.
안녕하세요 예은님 리뷰 감사합니다.
OVAD 태스크에 대해서 잘 설명해주시고 related works도 자세하게 작성해주셔서 편하게 흐름 따라가면서 읽을 수 있었던 것 같습니다. OVAD는 detection을 하고 각 attribute에 대한 pos/neg classification이라고 설명해주셨는데요, 모델이 실제로 학습할 때 box 내부의 시각적 패턴과는 관계없이 caption에 등장하는 단어들과 가장 그럴듯한 attribute를 찾는것 같은데, 처음 예시에서 곰이 wooden이라는 것을 어떻게 알 수 있었을까요?