안녕하세요, 두 번 째 x-review로 WorldMM을 가지고 왔습니다. 저희 논문 작업에서 벤치마크를 만들면, 그걸 테스트할 여러 LVU methods 중 하나가 WorldMM인데, 처음에 아키텍처를 봤을 때 굉장히 복잡해 보였으나, 읽을 수록 뭔가 심플하게 구성한 애들을 모아보니 복잡해진(?) 느낌이 들었습니다. 그래서 방법론 쪽 설명에 더 집중해서 리뷰를 작성하게 되었습니다… 리뷰 시작합니다!
Introduction
오늘날의 video LLMs는 수 시간에서 며칠에 이르는 긴 비디오를 다루고 추론하는 것을 목표로 합니다. 비디오를 효율적으로 다루는 문제에 있어서, 최근 연구들은 비디오의 모든 프레임을 다루는 것은 계산 비용이 높기 때문에 (질문과) 관련 높은 일부 프레임들만 검색해서 집중하는 memory based 접근을 사용합니다. 하지만 현재 방법론들은 텍스트 표현에 지나치게 의존하고 있습니다. 최근 방법론들 중에는 탐지한 사건/클립을 캡션 등의 텍스트로 변환한 다음 retrieval(검색)이나 reasoning(추론)에 이용하는데, 이렇게 변환된 텍스트 피처만 사용하게 되면 visual한 세부 정보가 손실됩니다. 반대로 시각 정보와 텍스트를 무조건 같이 쓰려고 하면 오히려 불필요한 시각적 context가 모델의 추론을 방해한다는 문제점이 있습니다. 따라서, 주어진 질문과 가장 관련된 장면을 검색하려면 adaptive하게 멀티모달 메모리를 선택하는 메커니즘이 필요합니다. 예를 들면, 질문이 “어떤 색깔이었어?” 라면 시각적 기억에 집중하고, “그때 어떤 행동을 했어?”라면 텍스트 메모리에 집중하는 선택 메커니즘이 필요하다는 것입니다. 또, 현재 모델들은 미리 정해둔 시간과 개수로 클립을 검색하는데(ex. 30초 길이의 클립 3개 검색), 이 방식은 모델이 다양한 시간 범위의 질문을 다루는 능력을 제한한다는 문제가 있습니다. 예를 들면 “축구 경기의 후반전에 무슨 일이 일어났는가?”라는 질문은 30초보다 훨씬 긴 시간적 맥락을 요구하죠. 결국 검색할 때 hour-level의 요약 정보와 minute-level 분 단위의 세부 정보를 결합하여 다양한 시간 스케일에서 동적으로 정보를 모을 수 있어야 합니다.
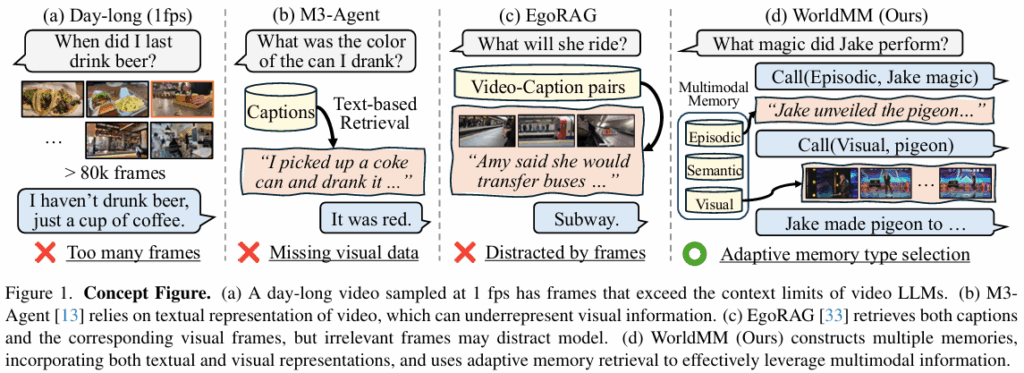
위와 같은 문제를 해결하기 위해 저자들은 WorldMM이라는 새로운 memory-based agent를 제안합니다. 텍스트 기억과 시각 기억을 분리해서 보관하고 질문에 adaptive하게 최적의 기억 모달리티와 시간적 granularity(얼만큼의 시간 범위를, 몇 분 정도를 볼 것이냐)를 선택합니다. 세부적으로는 다음과 같은 요소로 구성됩니다.
- Text Memory
- episodic memory : 다양한 time scale의 사건event들을 저장
- semantic memory : 관계나 습관 같은 고차원적, 장기적 지식을 지식 그래프 knowledge graph로 저장.
- Visual Memory
- Long Video를 short segments로 나누고 검색 저장소 내에 indexing해서 저장하여 모델이 필요할 때마다 시각 정보에 저장할 수 있도록 저장
- Retrieval Agent
- 각 쿼리(질문)에 필요한 정보를 찾을 수 있게, 모달리티와 Timescale 전반에 걸쳐 가장 관련 있는 메모리를 반복적으로 선택
이와 같은 모델 설계는 retrieval시 모달리티 두 개를 다 쓰려는 비효율에서 벗어날 수 있으며, 서로 다른 시간 규모에서 작동하는 여러 지식 그래프를 활용함으로써 적절한 시간 세분화 수준으로(granularity)로 정보를 검색할 수 있습니다. 본격적인 방법론 설명에 들어가기에 앞서, WorldMM이 원하는 정보를 검색retrieve하는 과정을 간단히 설명드리겠습니다. 검색을 위한 episodic memory를 선택한 뒤 retrieval agent는 모든 시간대의 잠재적인 관련 정보를 각 메모리에서 수집합니다. 이 다음 수집한 ‘후보’들은 질문의 answer로 쓰일 정보가 무엇일지 결정합니다. 마지막으로, 오직 reasoning에 필요한 정보만을 모으기 위해 모든 비디오 context에 동적으로 접근합니다. 추가로, 모델은 이 retrieval 과정을 여러 번 수행하는데, 그렇게 각 쿼리에 대해 가능한 모달리티-검색어 조합 범위를 넓힐 수 있고 적합한 정보를 adaptive하게 선택할 수 있게 됩니다.
Methods
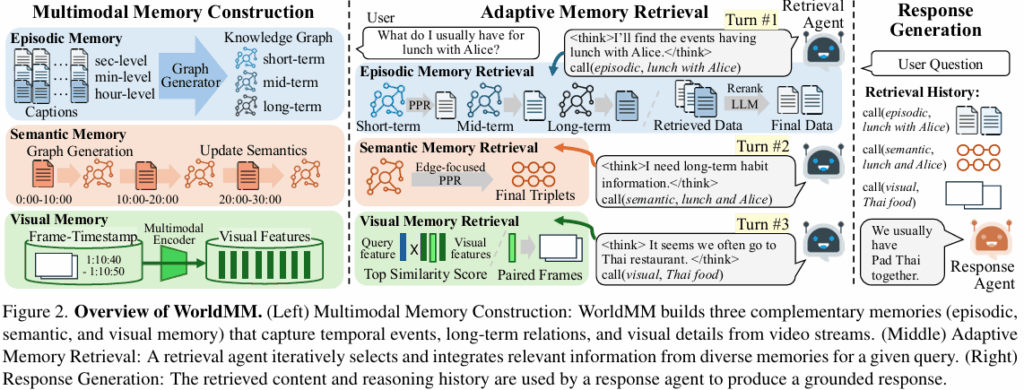
저자들은 text와 visual 맥락을 모두 고려해서 멀티모달 기억을 저장하고, 이를 통해 long video에서의 종합적인 이해와 reasoning을 가능하게 합니다. 모델은 세 단계로 작동하는데,
- 멀티모달 기억 생성multimodal memory construction
- 적응적 기억 검색 adaptive memory retrieval
- 응답 생성 response generation
순으로 동작한다. 비디오가 들어오면, WorldMM은 가장 먼저 두 개의 textual memeory(episodic, semantic)와 하나의 visual memory를 만들고, 이후 retrieval agent가 반복적으로 각기 다른 timescale의 메모리로부터 쿼리 관련 정보를 수집합니다. 정보 수집은 질문에 대답하기 충분한 정보가 모일 때까지 반복됩니다. 마지막으로, 쿼리와 검색된 contents가 response agent에게 전해져 메모리 속에서 응답을 생성합니다.
Memory construction과 Adaptive memory retrieval 과정은 각 메모리 별로 진행되는데, 하나하나 살펴보겠습니다.
Multimodal Memory Construction
효율적인 memory agent가 달성해야 하는 바는 두 가지이다.
- text memory와 visual 정보 중 adaptive하게 중요 정보 선택
- 다양한 시간 범위의 knowledge를 검색
위 두 가지 목표를 달성하기 위해 WorldMM은 세 가지 유형의 메모리를 구축합니다. 이 메모리들은 시각, 텍스트 모달리티에 걸쳐 상호 보완적인 비디오 지식을 저장합니다. Episodic Memory(Textual)은 다양한 timescale의 사건들을 포착하고(초, 분, 시간 단위), semantic memory(textual)는 고차원의 관계 관련 지식을 점층적으로 업데이트하며, visual memory는 시각적, 공간적 세부 정보를 보존합니다. 세 메모리들을 통해 긴 비디오의 episodic retrieval, semantic reasoning, visual grounded 이해를 가능하게 합니다.
- Episodic Memory Construction
- 목적 : 다양한 시간 범위의 사건을 저장하는 textual graph 제작
- 먼저 비디오를 몇 초 단위로 자를 지(as segment) 정의합니다
- \mathcal{T}=\{t_{0},t_{1},...,t_{N}\}, \quad t_{0}<t_{1}<\dots<t_{N}
- ex. {10초, 1분, 30분, 1시간, ..}l
- 비디오를 정해둔 시간 단위로 자르고, video LLM을 이용해서 캡션을 생성합니다.
- ex. 1분 단위로 비디오를 자르고, 각각의 segment마다의 캡션 생성
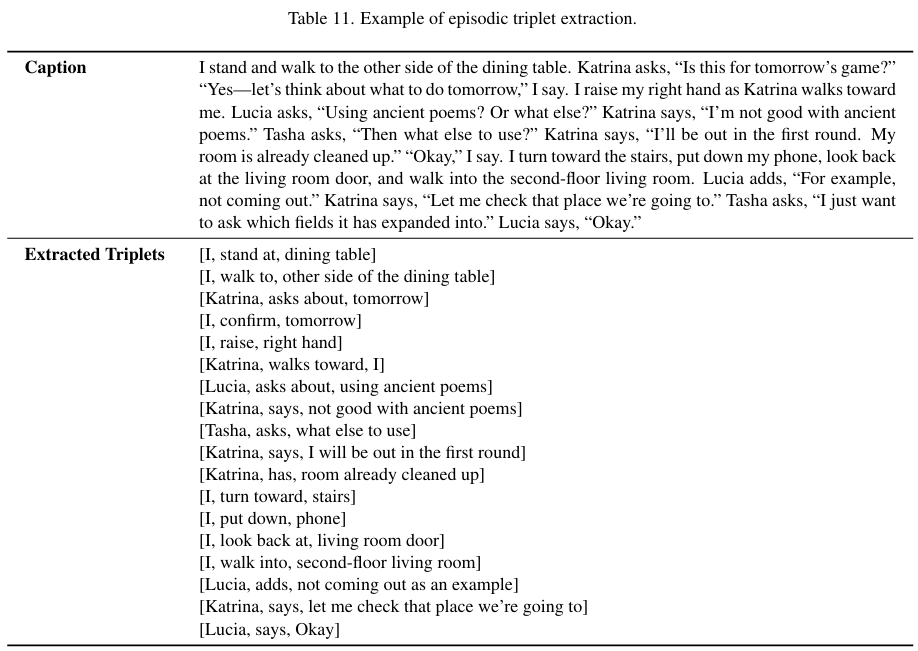
- 캡션을 factual triplets로 변환한 뒤 knowledge graph로 저장합니다.
- ex. triplet 예시
2. Semantic Memory Construction
목적 : 비디오 내에서 관계나 습관 같은, 장기적이고 축적되는 지식을 포착
Epdisode graph는 독립적인 사건들로부터 구축되기 때문에, 멀리 떨어진 장면들 간의 연속성을 유지하지 못하고 고차원적 지식을 포착할 수 없습니다. 반면, semantic memory는 시간이 지남에 따라 관계 및 습관 관련 지식을 지속적으로 통합하는 “진화하는” 그래프를 유지합니다. 아래는 세부 구성 과정입니다.
- 입력 비디오를 고정된 시간 단위(t_s)의 segment로 분할
- 각 segment에 대한 텍스트 캡션 생성 → semantic triplets(T_{t_s}^k)로 변환
- 이때 특정 사건의 세부 정보보다 개념적인 지식conceptual knowledge에 집중하여 추출
- 지식 통합 과정 Consolidation Process
- 기존의 안정적인 관계를 보존하면서 새로운 지식 통합
- 임베딩 기반 유사도 검사: 임베딩 기반 유사도를 사용하여 현재 그래프(G_{t_s}^k)와 새로 추출된 트리플(T_{t_s}^{k+1}) 사이의 중복되거나 충돌하는 부분을 식별
- 새로 추출된 triplet(T_{t_s}^{k+1})과 기존 그래프 내 유사도 높은 triplets를 LLM으로 넘긴다
- 오래되거나 충돌된는 triplet(T_{remove})과 수정 또는 추가해야될 triplet(T_{update})을 결정하고
- consolidate 과정을 거친다.
- \text{Consolidate}(G_{t_s}^k, T_{t_s}^{k+1}) = (G_{t_s}^k \setminus T_{remove}) \cup T_{update}
- 겹치거나 제거 필요한 triplet 제거하고, 업데이트할 triplet를 합친다.
- Visual Memory Construction
- Visual Memory는 말 그대로 객체의 생김새나 정확한 공간적 맥락 같이 시각적인 세부 정보를 포착하기 위해 구축합니다. 이때 visual memory를 떠올리는 두 가지 시나리오를 가정하는데,
- Retrieval Agent가 구체적인 키워드와 관련된 장면을 검색할 때Retrieval Agent가 이전 검색 단계에서 식별된 타임 스탬프를 가지고 해당 프레임을 검사할 때
- 쉽게 말하면 텍스트 기반의 에피소드 메모리 등을 먼저 검색해서 “어제 오후 2시”처럼 특정 시간대를 알아낸 경우 입니다.
- 자연어 쿼리를 통한 피처 기반 검색
- 비디오를 고정된 시간 규모(t_v)의 segment로 분할한 뒤, 멀티모달 인코더를 이용해서 각 segment를 visual feature로 인코딩합니다.따라서 feature-based visual memory는 visual feature 임베딩들의 집합으로 구성됩니다.피처 기반 시각 메모리 : \mathcal{M}{v}^{f}=\{f{v}^{1},f_{v}^{2},...,f_{v}^{L}\} 정확한 temporal grounding을 위한 타임스탬프 기반 검색
- 각 프레임(<span style="color: initial;">I_i)을 해당 타임스탬프(t_i)와 짝지어 저장합니다.\mathcal{M}{v}^{I}=\{(t{i},I_{i})|I_{i}=V(t_{i}), t_{i}\in[0,len(V)]\}이를 통해 비디오의 특정 순간에 대한 시각적 증거에 직접적으로 접근할 수 있게 되고, 최종적으로 visual memory는 위 두 가지 메모리를 포함합니다. → \mathcal{M}{v}=\mathcal{M}{v}^{f}\cup\mathcal{M}_{v}^{I} 결국 세그멘트 단위 메모리와 프레임/시간 단위 메모리를 계층적으로 저장한다고 이해하시면 될 것 같습니다.
- Retrieval Agent가 구체적인 키워드와 관련된 장면을 검색할 때Retrieval Agent가 이전 검색 단계에서 식별된 타임 스탬프를 가지고 해당 프레임을 검사할 때
- Visual Memory는 말 그대로 객체의 생김새나 정확한 공간적 맥락 같이 시각적인 세부 정보를 포착하기 위해 구축합니다. 이때 visual memory를 떠올리는 두 가지 시나리오를 가정하는데,
Adaptive Memory Retrieval
이 파트에서는 WorldMM이 어떻게 쿼리와 가장 관련된 멀티모달 메모리를 동적으로 검색할 수 있는 지를 제시합니다.
Retrieval Agent
Long video에서 reasoning을 수행하기 위해서는 여러 세 가지 메모리 소스에서 오는 정보들을 통합하는 과정이 필요합니다. 이를 위해 Retrieval agent는 사용자의 질문과 검색 이력을 바탕으로 어떤 메모리에 접근할 지, 그리고 어떤 쿼리를 발행할 지를 반복적으로 결정합니다. 각 메모리의 요소의 고유한 특징을 활용해서 Retrieval agent는 adaptive하게 관련 source과 모달리티 특화 쿼리를 생성합니다. 이 과정을 반복해서, 에이전트는 점진적으로 검색 전략을 다듬고 더 나은 knowledge collection을 생성합니다.
⇒ 결국 원래의 사용자 질문(쿼리,q)와 지금까지의 검색 이력(r_i)을 가지고 어떤 메모리를 뒤져볼 지 판단하고, 그 메모리에 맞는 맞춤형 검색어(쿼리)를 생성해냅니다. 수식적으로 보면 아래와 같습니다.
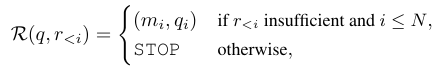
m : 어떤 memory source(episodic/semantic/visual)를 볼 것이냐
q_i : 메모리 맞춤형 검색 쿼리 search query
Retrieval agent가 메모리-검색어 쌍을 출력했다면, 출력된 메모리를 가지고 search query(q_i)를 넣어서 관련 정보를 찾게 됩니다. 이후 검색 이력(r_{<i})를 업데이트하고 다음 iteration을 적용하게 되죠. 만약 retrieval agent가 STOP를 출력했다면, 충분한 정보를 수집했다고 판단하고 반복 작업을 종료합니다. 그리고 모든 검색 결과 {{{r_1, …,r_n}}}를 Response agent(응답 에이전트)에 전달해서 최종 답변을 생성합니다. 다음은 각각의 Memory에서 Retrieval을 수행하는 과정을 알아보도록 하겠습니다.
Episodic Memory Retrieval
에피소드 메모리 검색에서의 핵심은 어떻게 적절한 시간 범위를 설정하느냐 ({10초,1분,5분,10분, …}의 temporal range 중 어디를 선택할 것이냐}) 입니다. WorldMM은 coarse-to-fine한 multi-timescale 검색 전략을 사용합니다. construction 단계에서 생성했던 각 시간 범위 별 graph를 가지고, 각 시간 범위 별로 PPR score와 쿼리에 의한 그래프 기반 검색 프레임워크를 사용해서 top k 개의 후보 캡션을 검색합니다. 이후 LLM을 사용해서 모든 timescale에 걸쳐서 검색된 후보들과 쿼리를 분석해서 가장 관련 높은 시간 범위를 선정하고 검색된 내용을 정제해서 최종 top-m개의 캡션을 출력합니다. Multi scale memory에서 검색하는 과정에서 모델은 넓은 범위의 시간적 맥락과 세밀한 세부 정보를 모두 활용하게 됩니다.
Semantic Memory Retrieval
knowledge graph의 형태로 표현되는 Semantic Memory에서의 검색은 위와 마찬가지로 PPR 기반의 검색 알고리즘이 사용됩니다. 하지만 Episodic Memory 검색에서 노드와 시간적 구조를 기반으로 수행되었던 것과 달리, Semantic memory에서의 retrieval은 entity 간의 edge에 인코딩된 관계적 지식에 집중합니다. (entity는 모델이 중요 정보만 기억하기 위한 ‘keyword’ 비슷한 개념으로 보시면 되겠습니다.) 기존 PPR score는 노드 단위의 관련성을 측정했기 때문에, semantic memory retrieval에 맞추기 위해 edge 기반 추론에 적합하도록 각 엣지에 연결된 두 노드의 PPR 값을 합산한 값을 해당 엣지의 점수로 할당합니다. 수식적으로는 아래와 같습니다.
\text{Score}(\text{edge}_{u,v}) = \text{PPR}(u) + \text{PPR}(v)이후 이 PPR score가 가장 높은 top k개 edge의 top-k개 triplet을 최종 검색 결과로 사용합니다.
Visual Memory Retrieval
Memory Construction할 때 처럼 feature-based mode와 timestamp-based mode 두 가지 검색으로 나뉩니다.
- Featrue-based mode
- retrieval agent가 만든 쿼리를 멀티모달 인코더를 사용해서 텍스트 피처 f_t로 인코딩한 뒤, \mathcal{M}_v^f의 visual feature들과의 코사인 유사도를 계산해서 top k개의 관련 높은 비디오 segment를 검색합니다.
- Timestamp-based mode
- episodic retrieval 이후 특정 시간 범위가 식별되면, 그에 해당하는 프레임들을 \mathcal{M}_v^I에서 직접 가져옵니다.
이 두 가지 모드를 결합함으로써, WorldMM은 semantic&temporal level 모두에서 시각 정보에 유연하고 효과적으로 접근할 수 있게 됩니다.
Response Generation
Retrieval agent가 충분한 정보를 모았다고 판단하면 검색 프로세스를 끝냅니다. 선택된 메모리를 포함한 retrieval history(검색 이력), 질문했던 쿼리들, 검색 결과들을 user query(원래 질문)와 함께 response agent에 전달합니다. Response Agent는 검색된 정보에 근거하여 최종 답변을 생성합니다.
Experiments
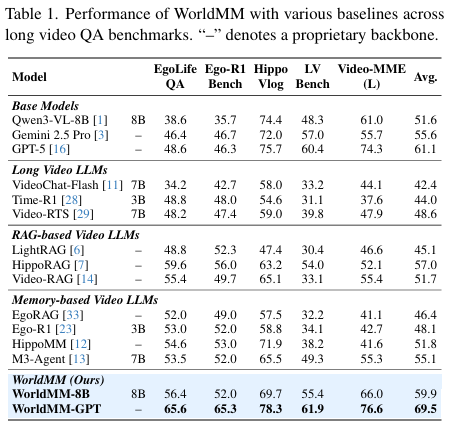
우선 Table 1은 WorldMM이 모든 LVU 벤치마크에서 SOTA를 달성했으며, 특히 retrieval&response agent로 GPT-5를 적용한 WorldMM-GPT 모델은 기존 SOTA보다 무려 8.4% 향상된 정확도를 보여주었습니다. 또 주목할 점은 같은 GPT를 백본으로 사용하는 HippoRAG나 HippoMM과 비교해도 WorldMM의 정확도가 높은 것으로 볼 때, 이는 WorldMM이 텍스트와 visual 메모리를 통합하고 질문에 따라 시간 범위를 adaptive하게하게 선택하기 때문에 발생한 결과라고 저자들은 주장합니다.
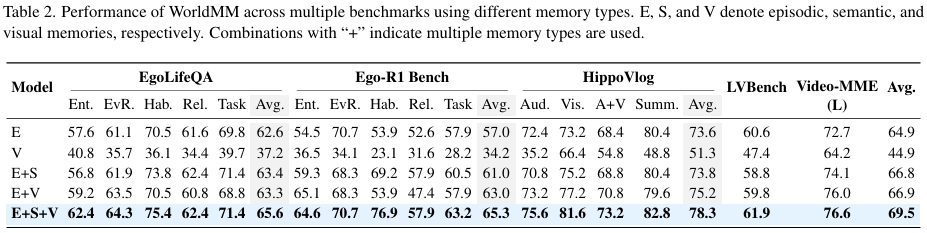
Table 2는 WorldMM이 구성하는 세 가지 메모리(Episodic, Semantic, Visual)가 전체 성능에 어떻게 기여하는 지를 분석한 Ablation study 입니다. 결론부터 말하자면, 각 메모리가 상호 보완적인 역할을 수행하며, 하나라도 빠지면 특정 유형의 질문에 대한 답변 능력이 크게 저하되었습니다. 각 벤치마크의 sub task별로(entity, event recall, habit, …) 각 메모리 ablation을 진행한 표라고 보시면 되겠습니다.
- Episodic memory
- 먼저 Episodic memory only(E)와 Visual memory only(V) 버전으로 비교했을 때, V의 경우 E와 달리 성능이 20% 이상 떨어진 것을 확인할 수 있습니다. 이는 곧 현재의 모델이 텍스트 정보를 그래프로 잘 정리하는 반면 visual 정보를 정리하는 것은 여전히 힘들어한다는 의미입니다.
- Visual Memory
- 모든 메모리를 사용한 E+S+V 세팅과 visual memory를 제거한 E+S 세팅 결과를 비교했을 때, 전체 메모리를 사용한 것의 성능이 4.2% 정도 더 좋았는데, 이는 텍스트만으로는 해결하기 어려운 공간적 정보나 시각적 세부 정보를 visual memory를 통해 더 정확하게 해결했음을 보여줍니다. 특히 시각 정보를 더 요구하는 EntityLog(객체 식별), Event recall(사건 회상) 항목에서 정확도를 크게 높인 점이 인상적입니다.
- Semantic Memory
- semantic memory는 long term dependency와 추상적인 관계를 추론해야하는 카테고리(ex.HabitInsight)에서 가장 큰 이점을 제공합니다. 실제로 Ego-R1 Bench에서, 모든 메모리를 활용한 E+S+V 모델은 S가 없는 E+V보다 Hab. 카테고리 성능이 23%나 향상되었음 보여, 의미적 메모리가 장기 기억을 축적하는 구조화된 지식 베이스로서 매우 효과적임을 입증합니다.
Conclusion
WorldMM은 adaptive retrieval을 통해 텍스트와 시각 정보를 통합하는 멀티모달, multi scale 메모리를 도입합니다. 서로 다른 모달리티와 시간 규모에 걸쳐 분리된 메모리를 구축하고, 관련 정보를 반복적으로 식별하는 retrieval agent를 결합함으로써, Long video에 대한 유연한 추론을 가능하게 합니다.
아직 LVU 입문자이다 보니 처음 이 논문을 쭉 보았을 때는 굉장히 복잡해보였는데(물론 복잡합니다..) 찬찬히 정리하고 보니 은근히 단순한 구조라는 생각이 들면서, novel한 구조는 아니라는 생각도 들었습니다. 특히 episodic memory를 구성할 때 여러 timescale로 나눈 캡션들의 triplet을 싹 다 저장해두겠다고 했는데, 실제 실험 세팅은 (벤치마크 맞춤으로 설정하긴 하나) 30초, 3분, 10분, 1시간 단위로 temporal segment를 했기 때문에 진정한 한 사건에 대한 temporal segmentation은 아니지 않나 싶네요. 긴 글 읽어주신 분들 감사합니다!