안녕하세요. 오늘 리뷰할 논문은 NaVILA: Legged Robot Vision-Language-Action Model for Navigation이라는 논문입니다.
여러 후속 논문들에서 이 논문을 자주 사이테이션하거나 베이스라인으로 잡고 있길래한번 읽어봐야겠다 싶어서 찾아서 읽어보게 되었습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
먼저 해당 논문은 기존 VLN 연구를 바퀴달린 로봇과 달리 지형이 어렵고 복잡한 상황에서도 이동할 수 있다는 장점을 가진 다리 달린 로봇(Legged)으로 확장한 연구중 하나라고 합니다. 그리고 저자는 주로 자연어로 학습이 이루어진 LLM, VLM의 추론 결과를 정밀하고 비언어적인 행동으로 변환해야하는 순간 추론과 로봇의 움직임을 제어하는 실행을 하나로 통합하는 일을 어려워진다고 말합니다.
그래서 저자들은 다리 로봇 VLN을 위한 2단계 프레임 워크인 NaVIL를 제안합니다.
조금더 구체적으로 말씀 드리면 기존 VLM을 파인튜닝해서 “오른쪽으로 30도 회전”과 같은 언어 형태의 mid level action을 출력하는 VLA를 만들고 이 지시를 따라서 실제로 실행 하기 위한 low level action 정책(Locomotion)을 학습합니다. (VLA가 출력하는 mid-level action은 저수준 명령 없이도 목표 위치와 이동 방향에 대한 정보 언어로 전달하는 것으로 이해하시면 좋을 것 같습니다.)
일단 저자가 제시한 프레임 워크는 3가지의 장점을 갖는다고 합니다.
- 로우레벨 행동 정책을 VLA로부터 분리함으로써(2단계 분리), 저수준 정책 부분만 교체하면 동일한 VLA를 서로 다른 로봇에 적용할 수 있다.
- 행동을 mid level 언어 지시로 표현하면, 실제 휴먼 비디오나 VQA 태스크 등 다양한 데이터 소스를 활용해서 VLA를 학습할 수 있다.(실세계의 데이터를 활용해서 일반화 성능을 끌어 올릴 수 있게 한다고 합니다.)
- 각각 두 단계로 분리한 모듈이 서로 다른 반복횟수로 실행한다. (일반적으로 크고 계산 비용이 큰 VLA은 저반복으로 실행해서 명령을 제공하는 반면에, 실제 보행 정책은 실시간(고반복)으로 동작시키게끔 한다고 합니다.)
그리고 저자는 VLA를 학습하기 위해서 기존 VLM 프레임워크 안에서 VLN에 필요한 과거 히스토리와 현재 관측을 통합하는 방법, VLN 과제에 맞게 설계한 전용 내비게이션 프롬프트를 만드는 방법, 연속 환경에서의 내비게이션 성능을 높이기 위해 유튜브에 있는 human touring 비디오의 실세계 데이터를 활용하는 방법, VLN의 일반화 성능을 강화하도록 구성한 데이터 블렌드를 도입하는 방법을 제시합니다. 해당 전략에 대해서는 메서드 파트에서 자세하게 다루도록 하겠습니다.
결론적으로는 위와 같은 전략을 통해서 저자들은 VLM을 내비게이션 중심 에이전트로 파인튜닝 하면서도 동시에 일반적인 비전-언어 데이터셋들로도 같이 학습시켜서 좀더 광범위한 일반화 능력을 유지할 수 있었다고 합니다. (여기서 human video 라고 하면 수집된 유튜브의 egocentric한 touring 비디오를 말한다고 보시면 좋을 것 같습니다. 사람이 직접 걸어다니면서 실내나 실외 공간을 보여주는 영상이라고 보시면 될 것 같습니다. 해당 논문이 human video 로 직접 학습하는 것이 연속 환경에서의 내비게이션을 향상시킨다는 점을 처음으로 보였다고 합니다. )
그리고 VLA 뒤에 붙어있는 locomotion 정책, 저수준 행동을 담당하는 보행 정책 부분을 학습 시키기 위해 기존 방법들(teacher-student 기반 distillation)이랑 다르게 이부분은 single stage 기반으로 보행 정책을 학습합니다. 또 기존 연구와는 다른 흐름으로 LiDAR 센서를 활용해 포인트 클라우드로 부터 높이 맵을 구성하여 이를 locomotion 컨트롤러의 입력으로 넣어주게 됩니다. 이 컨트롤러는 높이 맵과 더불어 VLA 모델의 출력을 입력으로 받아서 이를 속도 명령(선속도, 각속도)로 변환해주고 실제 로봇 다리의 관절의 위치를 제어해서 해당 속도를 추종하게끔 하는 역할을하게 됩니다. 높이 맵을 사용하게 때문에 장애물 회피에 강인하다는 장점을 갖는다고 합니다.
결괴적으로 저자들이 제안한 이러한 방식이 기존의 고전적인 VLN 벤치마크에서 sota 대비 좋은 결과를 보였다고 합니다. 자세한 내용은 실험파트에서 다루도록하고 바로 메서드 관련 부분에 대해서 설명드리도록하겠습니다.
Methods
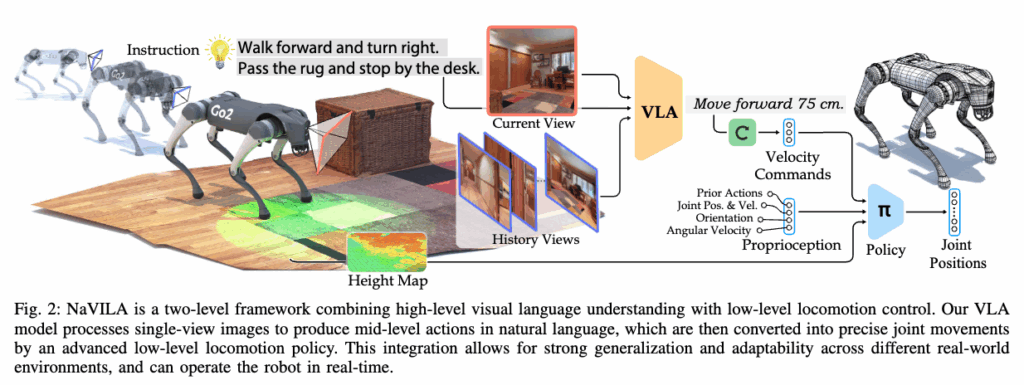
위 fig 2는 introduction에서 설명드린 내용 그대로 라고 보시면 되는데, 다시 요약 설명드리면 NaVILA는 크게 2단계로 분리된 프레임 워크이고, VLA는 현재 이미지 뷰와 과거 이미지 뷰 그리고 자연어 프롬프트틀 받아서 출력으로 자연어로 된 웨이포인트 지시를 생성합니다. 그럼 locomotion 정책은 이걸 전달받음과 동시에 라이다 기반으로 생성한 높이 맵도 함께 받아서 실제 로봇을 제어하는데 있어서 정밀한 관절움직임을 할 수 있는 실제 액션값을 출력하게 됩니다.
먼저 NaVILA라는 프레임 워크는 다중 이미지 추론에 있어서 효과적인 성능을 보이고 순차적인 이미지 간 관계를 이해하는데 있어서 중요한 VLN 과제에 적합한 VLM 모델인 VILA를 기반으로 합니다. 그리고 이를 내비게이션 수행에 있어서 잘 학습시키기 위해 여러가지 방법들을 적용합니다.
Navigation Prompts
VLN에서 입력으로 들어가는 현재 프레임이랑 과거 프레임은 서로 다른 목적을 가지면서 학습을 하게 됩니다. 예를 들어서 시간 t 시점의 이미지는 말 그대로 현재 관측이라가지고 “지금 교차로에서 우회전할지”, “도착했으니 멈출지” 와 같이 약간 즉각적인 의사결정에 도움을 주는 친구고, 그 이전 프레임들은 메모리 뱅크처럼 동작하면서 “내가 어디서 출발했고”, “이미 어디를 지나왔는지” 같은 진행 상황 추적을 돕는데에 기여를 하는 친구라고 보시면 될 것 같습니다.
그래서 기존 VILA 학습 방식처럼 프레임을 균일 샘플링만 해버리면 이 구분이 깨지니까 NaVILA는 최신 프레임 t는 current observation으로 따로 떼고 나머지 과거 프레임은 균일 샘플링하되 시작 프레임(trajectory 가장 첫 프레임)은 무조건 포함시키는 전략을 사용합니다. 시작 프레임 하나를 무조건 디폴트로 포함시켜놓으면 내가 어디서부터 왔는지를 추론하기가 훨씬 쉬워질 것 같긴할 것 같습니다. 그리고 프롬프트 안에서도 텍스트로 “historical observations:” / “current observation:” 이런 식으로 해당 프레임이 과거프레임인지 현재 프레임인지를 명시적으로 구분하는식으로 내비게이션 프롬프트를 구성하게 됩니다. 예시는 아래 피규어를 참고하시면 좋을 것 같습니다.

Learning from Human Videos
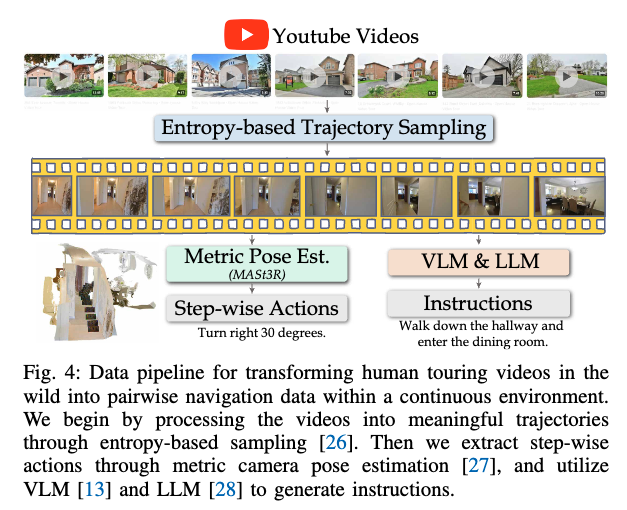
다음은 휴먼 비디오 파트인데 기존에도 휴먼 비디오가 도움 된다는 연구는 있었지만 대부분은 이산 환경 설정에서 사전학습 용도 정도로만 썼고, 그 이유가 연속 환경 내비게이션에 직접적으로 학습에 사용하기 위해서는 결국 연속 행동 라벨을 만들어야하는데 그 과정이 어려웠다고 합니다.
근데 최근엔 in-the-wild 환경에서도 metric pose estimation의 기술이 발전하면서 (캘리브레이션/IMU/GPS 없는 유튜브 투어 영상 같은 것에서도), 휴먼 비디오에서 카메라 포즈를 뽑고 그걸로 스텝별 행동을 추출할 수 있게 되었다고 합니다. 그래서 이런 추출 파이프라인을 간단하게 요약해서 설명드리면 2K 유튜브 egocentric touring 영상 -> entropy 기반 샘플링으로 20K trajectory 뽑고 -> MASt3R로 프레임간 카메라 pose 추정해서 step actions 만들고 -> VLM 캡셔닝 + LLM rephrasing으로 각 궤적에 대한 자연어 지시문을 만드는 식으로 구성되어있습니다. 이러한 과정을 통해서 유튜브 휴먼 비디오를 가지고 연속 환경 내비게이션에 직접 활용될 수 있게끔 라벨링을 했다고 보시면 좋을 것 같습니다.
SFT Data Blend
마지막으로 논문에서 SFT 데이터 블렌드가 꽤 중요하게 나오는데, 저자들 주장은 간단히 요약해서 말씀드리면 내비게이션 데이터만으로 SFT하면 특정 행동에 과적합되기 쉽고 지시문 다양성도 부족해서 일반화가 깨질 수 있다 라는 것입니다. 그래서 NaVILA는 (1) 실제 human video 내비게이션, (2) 시뮬 기반 R2R-CE/RxR-CE, (3) 보조 내비게이션 데이터(EnvDrop 증강 지시문 + trajectory summarization), (4) 일반 VQA 데이터 이렇게 4 가지를 섞어서 데이터를 구성했다고 합니다.
시뮬 데이터는 Habitat(실내 3D 환경에서 에이전트를 움직이는 시뮬레이터)에서 shortest path follower(최단 정답 경로를 만들어주는 도구)로 geodesic 최단 경로 행동(유클리드 직선거리가 아니라 벽 뚫고 잇는 직선거리가 아니라 벽/ 장애물 고려해서 실제로 로봇이 갈 수 있는 가장 짧은 경로)시퀀스를 생성하게 되고 그 결과 스텝 단위의 내비게이션 비디오를 얻게 된다고 합니다. 각 샘플은 (t+1)프레임으로 이루어진 비디오와 시간 스텝 t 에서의 해당 오라클 행동을 구성되게 됩니다. 그리고 stop 라벨이 적은 데이터 불균형 문제를 해결하기 위해 리밸런싱기법을 적용한다고 합니다.(구체적인 과정에 대한 언급은 따로 없었습니다.)
정리하면 R2R-CE, RxR-CE 시뮬레이터 환경에서 에이전트가 움직이면서 trajectory video를 만들고 각 시간 스텝 t 마다 정답행동(shortest path follower가 만들어줌)을 생성한다라고 이해하시면 좋을 것 같습니다. 이렇게 생성된 데이터는 앞서 설명한 프레임 추출 전략을 거치면서 내비게이션 작업 프롬프트와 페어로 구성되게 됩니다.
그리고 저자들은 R2R-CE, RxR-CE의 지시문의 다양성이 부족하다는 문제를 해결하고자 auxiliary 내비게이션 데이터셋을 추가로 활용합니다. EnvDrop을 통해 지시문 증강을하고 또 추가적으로 내비게이션 궤적 요약이라는 과제를 도입해서 하나의 궤적 비디오가 주어졌을 때 첫번째 프레임을 유지하고 과거 프레임들을 균일하게 선택하는 식으로 샘플링된 프레임을 이후 LLM은 이 프레임을 바탕으로 로봇의 궤적을 서술하는 과제를 수행하도록 하게끔 합니다. 이때 해당 궤적에 대한 지시문을 정답으로 사용하게 됩니다. 내비게이션 요약 과제를 도입한 이유에 대해서는 저자가 논문에 명시적으로 언급하지는 않았으나 개인적인 생각으로는 VLN을 잘하려면 단순히 현재 프레임 과거 프레임만 보는게 아니라 내가 어디서 시작했고 어디를 이미 지나왔고 지금까지의 이동 패턴이 어떻게 되는지를 이해를 해야하는게 중요한 것 같습니다. 그래서 이런 비디오를 보고 궤적을 요약해봐 라는 과제를 주게 되면 LLM이 프레임들 사이의 공간 변화라던지 등을 언어로 정리하는 능력을 배우게 되고 이게 VLN에 있어서 도움이 되는 역할을 하기 떄문이지 않을까 싶습니다.
그리고 여기에 더불어서 마지막으로 저자들은 공간적 장면 이해를 더 강화하기 위해
ScanQA 데이터 까지 넣어서 보강했고 또 여기에 모델의 일반적인 능력을 유지하기 위해서 일반 VQA 데이터 셋까지 포함해서 데이터를 구성합니다.
결국 결론은 VLN만으로 좁게 학습시키지 말고 내비게이션 데이터만으로는 부족한 공간(3D) 장면 이해 능력과 일반 시각-언어 상식을 같이 유지시키기 위내비게이션과 직접 관련이 없는 데이터셋까지 SFT 블렌드에 섞는 전략을 가져간다라고 이해하시면 좋을 것 같습니다.
Locomotion policy
앞서 설명드린 부분은 NaVILA 프레임워크중에서 앞단계(VLM 관련)에 대한 내용 이었다면, 해당 파트 부터는 두번째 단계 locomotion 정책 관련하여 설명드리도록 하겠습니다.

일단 해당 연구는 Go2 라는 사족보행 로봇을 기반으로 연구를 진행합니다. 위 그림에서 보이는 것 처럼 로봇은 머리 베이스 부분에 LiDAR 센서를 가지고 있고 로봇 개 같은 경우에는 다리의 12개 과절 모터만 제어하도록 세팅을 하였다고 합니다. 그리고 Locomotion 정책 이전에 동작하는 VLM은 {move forward, turn left, turn right, stop} 같은 고정된 단어 집합을 출력합니다. 이 지시를 locomotion 정책이 곧바로 관절 값으로 변환하는 구조가 아니라 먼저 고정된 속도 명령으로 매핑합니다. 그리고 VLM이 함께 예측한 이동 거리/회전 각도에 맞춰 해당 속도를 얼마 동안 유지할지(duration) 를 정해 주고, 그 시간 동안 locomotion policy가 그 속도를 추종하도록 입력을 구성하게 됩니다.
그리고 locomotion policy 학습에 있어서는 PPO 알고리즘을 사용했다고 합니다. 입력으로 들어가는 데이터로는 proprioception가 있는데 proprioception 데이터에는 로봇의 선속도(linear velocity) 및 각속도(angular velocity), 자세(orientation), 관절 위치(joint positions), 관절 속도(joint velocities), 그리고 이전 행동(previous action)이 포함이 된다고 합니다. 그리고 추가적인 데이터로 LiDAR 기반으로 생성한 높이 맵 또한 활용하게 됩니다.
기존 이 locomotion 정책 학습에 있어서 teacher-student 기반 distillation 학습 방식을 사용하는 것과 다르게 저자들의 단일 단계 RL을 기반으로 한 학습 방식이 시간 효율적으로 학습가능하다고 주장하하고 또 정책이 환경과 직접 상호작용하면서 학습하기 때문에 탐색을 통해 새로운 전략을 발견할 가능성이 있다라고 주장하는데 이 부분은 강화학습 공부를 하고 봐야 이해가 될 것 같습니다..
Experiments
실험 파트 입니다. 저자들은 아래 4가지 질문에 답하기 위한 실험을 구성하였습니다.
- VLA의 성능은 VLN-CE 벤치마크와 일반적인 spatial scene understanding 과제에서 기존 SOTA 방법들과 비교해 어떠한가?
- single-stage Locomotion 정책의 성능은 policy distillation 기반 접근들과 비교해 어떠한가?
- 시뮬레이터에서 보행 내비게이션(locomotion navigation)을 어떻게 평가할 수 있으며, 이러한 시나리오에서 NaVILA는 얼마나 효과적이고 유연한가?
- NaVILA 파이프라인을 실제 로봇 VLN 실험에 성공적으로 deploy할 수 있는가?
VLA의 성능은 VLN-CE 벤치마크와 일반적인 spatial scene understanding 과제에서 기존 SOTA 방법들과 비교해 어떠한가?
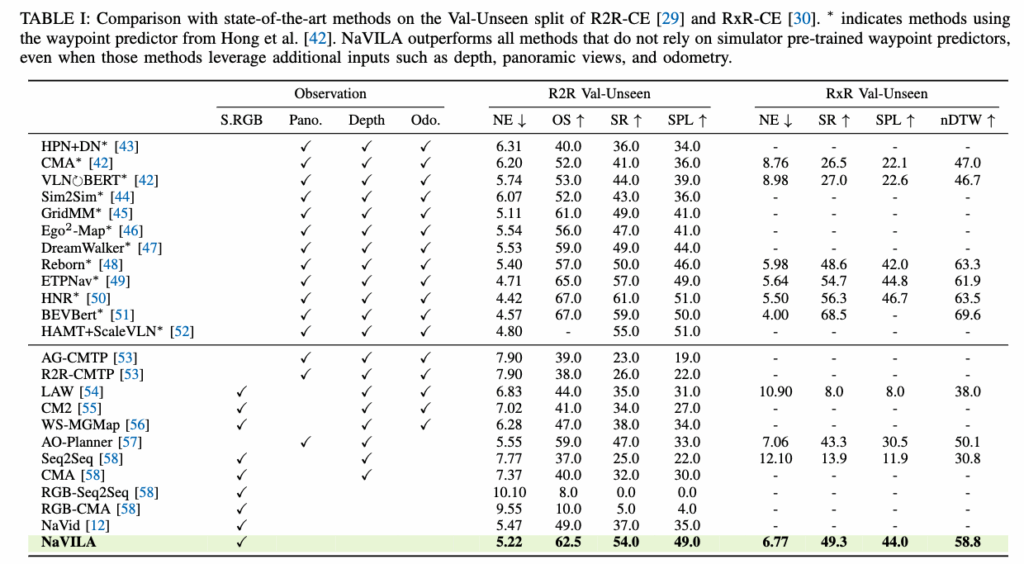
NaVILA는 단일 모델만으로도 두 벤치마크(R2R, RxR)에서 single-view RGB만으로도 파노라마/오도메트리/사전학습 waypoint predictor에 기대는 베이스라인들과 동급이거나 더 좋은 성능을 보이는 것을 볼 수 있습니다. 저자들은 센서나 추가 모듈을 많이 얹지 않아도 VLA 자체의 일반화로 성능을 끌어올릴 수 있었다고 합니다.
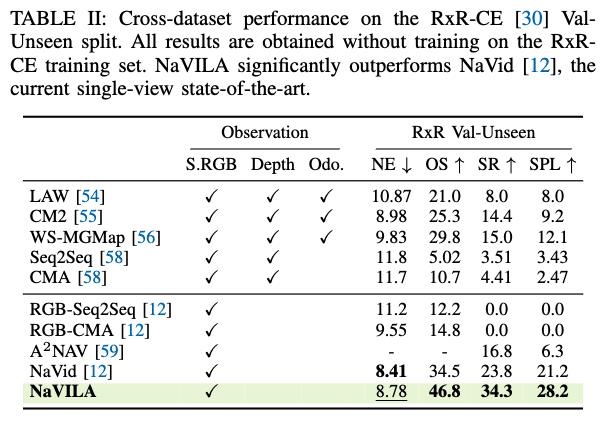
위 실험은 cross-dataset 테스트인데 NaVILA를 R2R로만 학습하고 RxR은 학습에 쓰지 않은 상태에서, RxR val-unseen에서 제로샷 성능을 확인하는 실험이라고 보시면 좋을 것 같습니다. 이때 NaVid 대비 특히 SR에서 큰 폭(약 10%p) 개선을 보임으로써 현재 SOTA 모델 대비 좋은 제로샷 성능을 주장합니다.
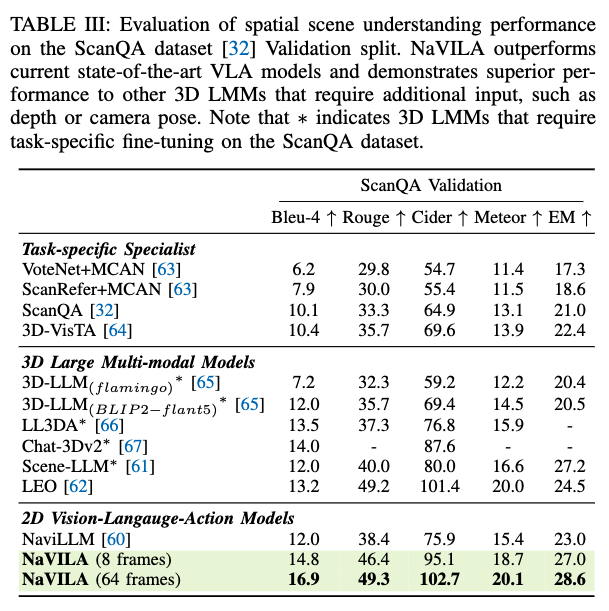

NaVILA를 내비게이션용 모델로만 보지 않고, 공간적 장면 이해(3D QA) 쪽도 같이 평가를 진행합ㄴ디ㅏ. ScanQA validation에서 multi-view 이미지를 넣고 답변 생성 지표(BLEU/ROUGE/CIDEr 등)로 평가했을 때, 기존 NaviLLM 대비 큰 폭으로 개선되고, 저자들은 프레임 수를 늘리면(64 frames) 3D 입력(RGBD/3D scan, pose 등)을 쓰는 모델들과 비교해도 경쟁력이 있다는 식으로 주장합니다. 여기서 논문이 강조하는 메시지는 다른 모델들은 더 많은 3D 정보를 요구하는데 우리는 이미지 기반으로도 꽤 성능이 잘 나온다를 보여주는 것 같습니다.
single-stage Locomotion 정책의 성능은 policy distillation 기반 접근들과 비교해 어떠한가?
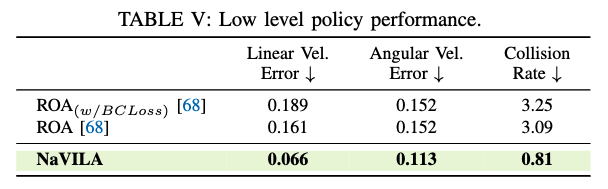
저수준 locomotion 정책을 정책 증류(teacher–student) 계열인 ROA와 비교해서 저자가 학습한 RL 정책이 왜 더 유리한지 보여주는 실험이라고 보시면 좋을 것 같습니다. ROA는 잘은 모르지만 학습 시점에는 특권 정보(시뮬레이터가 제공해주는 아주 좋은 정보들)를 쓰는 teacher를 만들고, 이를 실제 센서 입력만 받는 student가 따라가도록 감독하는 방식인데, NaVILA의 저수준 정책은 이런 증류 단계 없이도 속도 추종 정확도(선속도/각속도 오차) 와 장애물 회피(충돌률 지표에서 더 좋은 성능을 보이는 모습을 확인할 수 있습니다. 특히 저자들은 충돌률에서의 꽤 큰 차이를 바탕으로 실제 주행 안정성 측면에서 저자들의 학습 방식의 효과를 강조합니다.
시뮬레이터에서 보행 내비게이션(locomotion navigation)을 어떻게 평가할 수 있으며, 이러한 시나리오에서 NaVILA는 얼마나 효과적이고 유연한가?
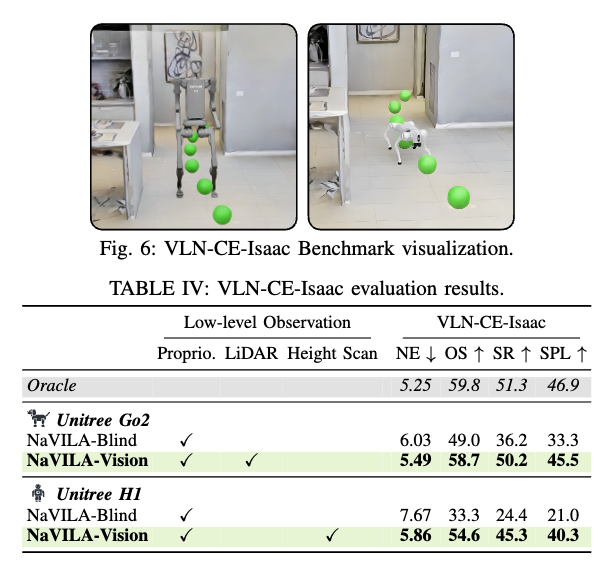
기존 VLN-CE는 Habitat 기반이라서 정밀한 저수준 로봇 제어까지 포함한 현실적인 물리를 충분히 반영하기 어렵다는 한계가 있다고합니다. 그래서 논문은 Isaac Sim 기반의 VLN-CE-Isaac 벤치마크를 새로 구성했고, 이러한 방식은 고수준 계획부터 저수준 실행까지 포함한 전체 파이프라인 평가가 가능하다는 점을 주장합니다. 실제로 세팅은 R2R과 동일한 장면들을 사용하되, 그림 6과 같이 그 환경 안에 로봇을 배치하여 실험을 구성하고 R2R Val-Unseen 분할에 포함된 1,839개의 궤적중에서 현실적인 내비게이션 시나리오를 보장하기 위해 품질이 높은 메쉬 를 갖추고 실제로 주행 가능한 1,077개의 궤적을 선택했다고 합니다. 또 일관성을 위해 우리는 기존 연구들과 동일한 평가 지표를 사용해 성능을 평가했다고 합니다. 그리고 VLN-CE-Isaac은 다양한 로봇 플랫폼과 호환된다라는 점에서 실제로 Go2뿐 아니라 H1 같은 다른 로봇 플랫폼에도 적용해 실험하면서 시각 입력(높이맵 등)을 쓰는 정책이 blind 정책(proprioception 데이터만 사용)보다 SR이 크게 상승하고(Go2, H1 모두) 또한 명령을 완벽히 실행하는Oracle 저수준 정책과 비교했을 때 성능 차이를 보여줍니다. 더불어 벤치마크 자체 난이도/현실성을 보여주는 실험이라고 보시면 좋을 것 같습니다.
NaVILA 파이프라인을 실제 로봇 VLN 실험에 성공적으로 deploy할 수 있는가?
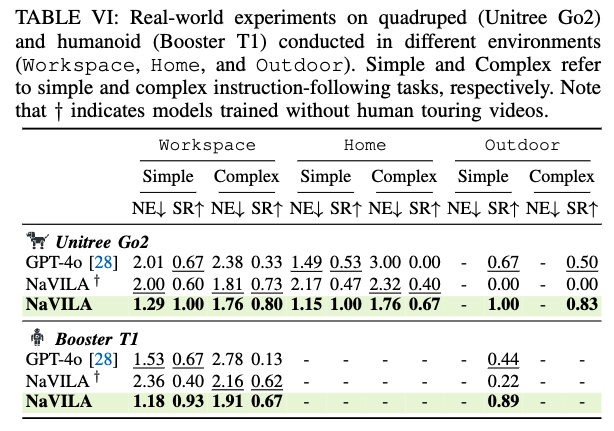
실제 환경에서의 실험에서는 Workspace/Home/Outdoor 세 환경에서 총 25개 지시문을 3회 반복하고 단순 과제와 복잡 과제를 나눠 평가를 진행합니다. 좀더 구체적으로 설명드리면 단순 지시문은 한 두 개의 내비게이션 명령으로 이루어지고 로봇이 방 사이를 이동할 필요가 없는 상황이라고 보시면 됩니다.(“의자로 가서 멈춰”와 같은 지시문). 반대로 복잡 지시문은 세 개 이상의 명령을 포함하고 로봇이 여러 방이나 랜드마크를 통과해야 하는 상황입니다.(“방을 나가서 오른쪽으로 돌아, 앞에 있는 방으로 들어가서 테이블에서 멈춰”와 같은 상황).
비교 대상으로는 최신 VLM인 GPT-4o를 두는데 결과적으로 NaVILA가 더 좋은 성능을 보입니다. 또 YouTube egocentric data(휴먼 투어링 데이터) 를 추가로 학습에 넣었을 때 야외 환경 일반화가 더 좋아지는 것도 결과로 확인할 수 있습니다. 마지막으로 2단계(two-level) 구조의 장점을 강조하기 위해, 동일한 VLA를 유지한 채 로봇 플랫폼(휴머노이드 T1)에서도 재학습 없이 평가를 수행했고, 카메라 높이/시야각이 달라도 비슷한 성능을 보이는 것을 확인할 수 있습니다.
아래는 정성적 결과 입니다.


Conclusion
처음에는 기존 mid-level을 2D 내비게이션 (전진/회전/정지 + 거리/각도)로 두고, 저수준을 별도 정책으로 붙이는 방식 자체는 이미 널리 쓰이는 패턴이어서 2 단계로 분리한게 뭔가 저자의 기여라고 볼 수 있을까라는 생각이었는데, 그게 아니라 이러한 구조 덕분에 고수준 VLM/VLA는 다양한 데이터(시뮬레이터 VLN, VQA, ScanQA, 그리고 YouTube 투어링 비디오 같은 실세계 비디오)로 스케일업이 가능하다 라는 것을 보여줄 수 있고, 여러 legged 플랫폼에 확장 가능하면서 저수준은 RL로 강인한 주행 안정성을 확보하는 방향으로 정리된 논문이다라고 이해를 하면서 읽었던 것 같습니다. 그리고 Locomotion 정책을 튜닝을 한다면 충분히 legged robot 플랫폼만이 아닌 다른 휠 플랫폼으로의 확장까지를 보일 수 있을 것 같긴하다라는 생각이 듭니다. 왜냐면 뭔가 논문 자체도 legged에 특화되도록 엄청난 디테일을 고려한 설계가 들어있는 것 같지는 않았고 범용적인 내비게이션 프레임워크를 legged에서만 보여준 느낌이다 보니 굳이 legged 기반으로 한정 지을 필요는 없다는 생각이 들었습니다. 물론 서두에 저자가 언급하였지만(어려운 지형 이동의 이점) 근데 바퀴 로봇만의 장점도 있으니 바퀴 로봇까지 확장 해볼법도 하다라는 개인적인 생각이 드는 것 같습니다.
이상 리뷰 마무리하도록 하겠습니다. 감사합니다.