안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 Video Moment Retrieval task를 다룬 논문입니다. 연차보고서 작성 관련하여 Scene Graph Generation(SGG)를 활용한 task 및 프로젝트를 찾아보고 있는데, 눈에 띄어 읽어보았습니다.
그럼 리뷰 시작해보겠습니다.

Introduction
Video moment retrieval, video temporal grounding은 자연어 쿼리가 들어왔을 때 비디오에서 쿼리에 해당하는 구간(temporal segments)을 찾는 task입니다. 아무래도 입력 쿼리가 자연어 형태이다 보니 Vision-Language의 모달리티 간 상호작용을 잘 활용하려는 흐름으로 발전되고 있다고 합니다. 최근에는 LLM의 사전 지식을 활용해 이벤트가 발생하는 경계에 대한 정보로 활용하는 방법론들도 제안되고 있습니다.
기존 방법론들은 보통 DETR 구조를 기반으로 하거나 multi-scale의 temporal feature sequence를 활용하기 위해 FPN 구조를 활용하였는데, 아키텍처 구조를 떠나 대부분 선행 연구들이 사전학습된 CLIP이나 I3D같은 visual encoder를 사용하였다고 합니다. CLIP의 문제점이라고 하면 이제는 그 전개가 익숙하죠. 여기서 추출되는 feature는 의미론적으로 global한 특성을 띄기에 dense prediction을 수행하거나 뭔가 object 수준의 세밀한 구조적인 특징을 활용하기 어렵습니다(논문에서는 frame-level feature라고 표현합니다).
“Are frame-level features truly sufficient for video moment retrieval?“
본 논문의 문제 정의도 유사합니다. 실제 moment retrieval 시나리오에서는 쿼리가 object 수준의 정보를 활용해야 하는 경우가 많지만 기존 방법론들은 frame-level의 global feature를 사용해서 이러한 능력이 떨어진다는 것이죠.

저자들은 쿼리가 object-centric하게 처리되어야 하며, temporal modeling도 명확히 object-level에서 이루어져야 한다고 주장합니다. 위 Figure 1을 보면 ‘person opens the laptop’이라는 자연어 쿼리가 주어졌을 때 기존의 frame-level 접근법은 국소적인 시각 정보를 처리하는 능력이 떨어져 노트북이 닫힘에서 열림으로 변하는 순간을 잘 포착하지 못합니다. 하지만 제안하는 object-centric 접근법은 비디오 전반에 걸쳐 관련된 object(사람, 노트북)을 탐지 및 추적하고 이들의 관계를 예측하여 이를 바탕으로 각 object에 대한 의미 / 외형 정보를 인코딩하는 object-level feature sequence를 구축해 올바른 예측에 성공합니다.
본 논문은 object-centric한 moment retrieval 프레임워크를 제안합니다. 우선 scene graph parser로 입력 쿼리를 장면 그래프로 파싱해서 쿼리와 연관된 객체들을 추출합니다. 이후 open-vocabulary scene graph generation model인 OvSGTR을 사용해서 각 video frame에 대한 장면 그래프를 생성하고, 이와 관련된 object, relation feature를 생성합니다. tracking 알고리즘으로 이 feature들을 시간 순서대로 정렬된 시퀀스로 구성하고, 이 시퀀스에 relational tracklet transformer를 사용해서 객체 수준의 상태 변화를 포착합니다. object 및 이들 간의 관계를 시간적/공간적으로 잘 모델링하여 입력 쿼리에 대응하는 순간들을 기존보다 더 정밀하게 탐지할 수 있게 하였습니다.
저자들은 Charades-STA, QVHighlights, TACoS 벤치마크에서 일관적으로 기존 방법론들보다 좋은 성능을 달성하여 제안하는 방법론의 효과를 입증하였고, object-level temporal modeling이 중요함을 강조하였습니다.
Defects of Frame-Level Approaches
본격적으로 방법론을 살펴보기 앞서, 논문에서 저자들이 주장하는 기존 frame-level 방법론들의 한계점을 살펴보겠습니다.
대부분의 기존 moment retrieval 방법론들은 전역적인 representation이 visual contents를 textal query와 정렬하는데 충분하다고 가정하고 frame-level feature를 사용하였습니다. 하지만 객체 지향적(object-oriented)인 쿼리가 입력되었을 때는 이런 가정이 자주 무너진다고 합니다. 저자들인 주장하는 한계점들은 다음과 같습니다.
Lack of Fine-Grained Visual Detail.
Frame-level 피쳐에는 국소적인 시각 정보가 부족합니다. 기존 방법론이 사용한 사전학습 인코더들은 이미지단위 / 비디오 단위로 학습이 진행되어(CLIP, I3D 등) 국소적인 객체의 외형보다는 전역적인 의미론적 정보를 모델링하게 됩니다. 결과적으로 물체의 상태 변화(노트북이 열려 있는지, 닫혀 있는지)와 같은 미묘한 시각적 정보를 잘 활용할 수 없죠. 이런 미묘한 변화는 전역적인 의미론적 변화에 반영되지 않기 때문에 해당 정보를 활용하기 위해서는 모델이 기본적으로 세부적인 시각 정보를 모델링 할 수 있어야 합니다.
Insufficient Modeling of Object Relationships.
기존의 visual encoder들은 물체 간 관계를 모델링하도록 학습되지 않았기 때문에, 이들이 출력하는 frame-leve representation은 시각적 문맥 상 물체의 상태를 추론하는 데 있어 필수적인 객체 간 관계를 포착하는 능력도 매우 떨어집니다. ‘사람이 노트북을 연다’는 관계 정보를 명시적으로 알고 있으면, 이들 간 물리적인 상호작용을 추론할 수 있겠죠. 하지만 이런 관계 정보를 잘 활용하지 못하기에 사건 / 행동을 이해하는 능력에 한계가 있습니다 .
Inability to Track Multiple Objects.
마지막으로 기존의 frame-level 방법론들은 사건이 진행됨에 따라 다중 물체의 일관된 표현을 유지하는 데 한계가 있습니다. 이 때문에 여러 물체들의 상호작용을 계속 모델링하는 것이 불가능했죠. 특정 장면에서 중요한 물체가 잘 포착되어도, 다른 관련 물체들의 정보가 함께 잘 유지되지 않았다고 합니다.
저자들은 기존 방법론들의 이런 한계를 극복하기 위해, 명시적으로 객체 수준의 외형 정보 및 이들 물체 간 상호작용 정보를 명시적으로 모델링하는 object-centric framework를 제안합니다.
Object-Centric Framework for Moment Retrieval
제안하는 프레임워크의 전반적인 개요는 아래 Figure 2와 같습니다. 기존 방법론들은 frame-level feature에만 의존했지만, 제안하는 방법론은 입력 쿼리와 관련된 물체들과 이들 간 관계(relationship) 모두에 대한 feature sequence를 활용합니다.
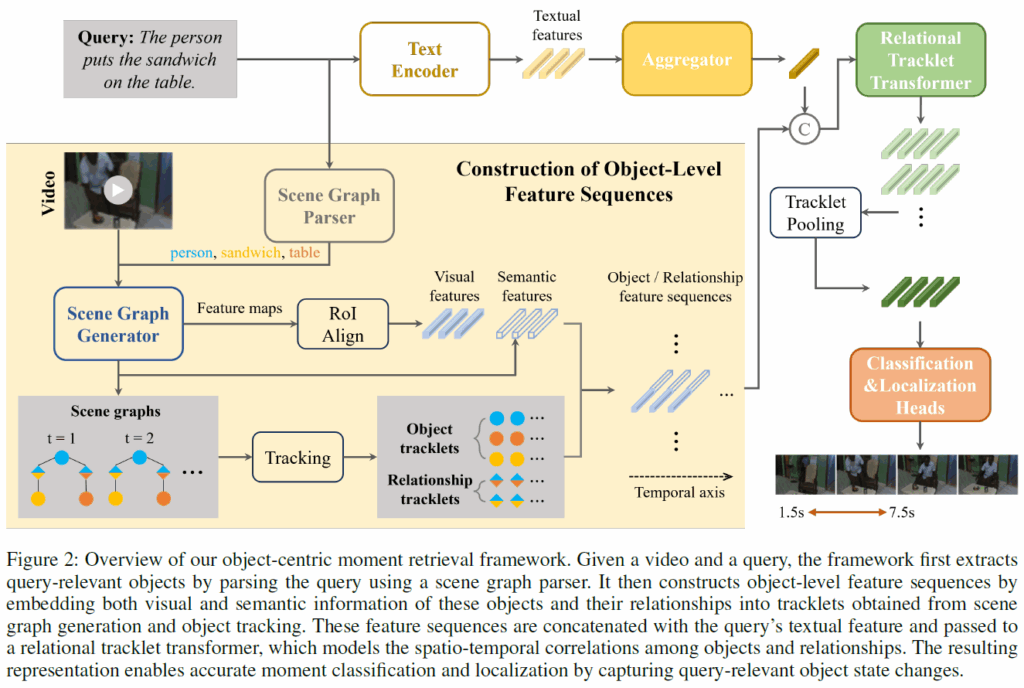
Object-Level Input Construction
가장 먼저 쿼리를 scene graph로 파싱하여 입력값을 준비합니다. 이때 사전학습된 scene graph parser인 FACTUAL을 사용해 자연어 쿼리에서 object node들과 이들 간 관계를 추출합니다. 이렇게 얻은 object class list는 open-vocabulary scene graph generation(OV-SGG) 모델을 프롬프팅 하는데 사용해서 각 비디오 프레임에서 관련 물체들과 이들 간 pair-wise relation을 탐지하게 합니다. 이 때 사용한 SGG 모델은 OvSGTR로, video scene graph generation 모델은 아니고 Visual Genome 데이터셋으로 사전학습한 image 기반의 SGG 모델입니다. OvSGTR에 입력 프롬프트로 object 뿐만 아니라 relation class list도 함께 입력해주어야 하는데, 아직 SOTA 모델들이 open-world relationship을 안정적으로 탐지하지 못하기 때문에 Visual Genome 데이터셋의 relation 클래스 셋을 사용했다고 합니다.
여기서 사용한 OV-SGG 모델은 scene graph 예측 결과와 백본(swin transformer)의 중간 피쳐맵을 출력해주는데, feature map에 RoIAlign을 적용하여 물체들 및 relation의 RoI feature를 추출해줍니다(relation의 RoI feature는 주어, 목적어 물체의 bbox 합집합을 사용합니다). RoI visual feature와는 별개로, OV-SGG 모델의 최종 출력값에서 텍스트 프롬프트와 정렬된 semantic feature를 추출합니다. 이렇게 추출한 visual feature 및 semantic feature는 상호보완적인 정보이기에 함께 사용해서 물체 상태의 외형 정보 및 개념적 정보를 모두 포착할 수 있도록 하였습니다.
프레임 별로 예측값을 뽑은 이후에는 tracking 알고리즘을 적용해 예측된 object 및 relationship 결과를 temporal 축으로 엮어줍니다. 이 때 frame rate를 낮게 설정했기 때문에(1 or 0.5 fps) IoU 대신 코사인 유사도를 사용한 feature 기반 매칭을 사용하였다고 합니다. 결과적으로 각 물체들의 궤적은 object tracklet으로 구성되고, threshold 이상의 confidence 점수를 가진 relation들은 특정 object pair에 대응하는 relation triplet으로 묶어줍니다. 마지막으로, visual feature와 semantic feature를 concat한 뒤 tracklet에 임베딩하여 object-level feature sequence를 구축합니다. 이 때 특정 물체나 관계가 존재하지 않는 타임 스탬프에서는 시간적 정렬을 유지하기 위에 벡터를 0으로 채워주었다고 합니다.
Object-Centric Model Architecture
앞에서 object-level feature sequence를 만들었으면, 이제 이를 활용해서 물체들 및 이들의 상호작용의 시공간적 상관관계를 효과적으로 포착할 수 있는 모델로 예측을 수행해야 합니다. 저자들은 이를 위해 시간 순으로 정렬된 객체/관계 tracklet을 처리하도록 설계한 relational tracklet transformer를 제안합니다.
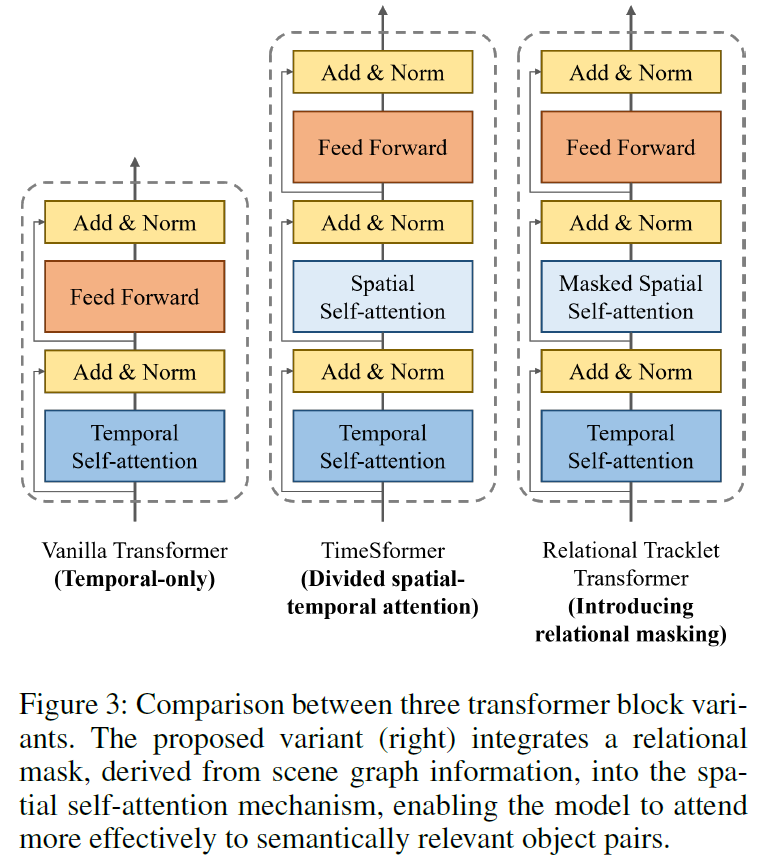
기본적으로 제안 모델은 TimesSformer라는 모델을 기반으로 설계되었다고 합니다. 기존 모델의 경우 시공간 어텐션이 결합되어 있었는데(spatio-tempral self-attention), TimeSformer의 경우 이를 별도의 시간 / 공간 어텐션 모듈로 분해하여 효율성을 높인 모델이라고 합니다. 하지만 TimeSformer 구조에서는공간 모델링 과정에서 모든 tracklet이 동일하게 취급되어 이들의 의미론적 관계가 무시되었다고 합니다.
이런 한계를 개선하기 위해 저자들은 graph-aware spatial attention mechanism을 도입하였습니다. 일단 spatial attention을 의미적으로 관련된 entity들로 제한하고, 동시에 장면 그래프 구조를 반영한 binary attention mask를 생성합니다. 트랜스포머의 입력값은 다음과 같이 object 및 relationship tracklet의 sequence를 concat한 값입니다.
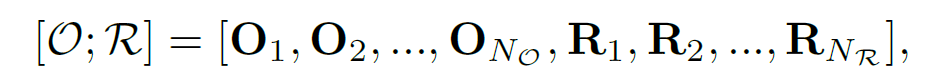
여기서 O, R은 각각 object 및 relationship feature sequence set을 의미합니다. 이 때 binary mask m은 ({N}_{O}+{N}_{R})×({N}_{O}+{N}_{R}) 차원의 0과 1로 이루어진 행렬이고, 이 때 object tracklet {O}_{i}가 relationship tracklet {R}_{j}의 subject나 object이면 {m}_{i, {N}_{O+j}} = {m}_{{N}_{O+j}, i} = 1, 그 이외에는 0으로 채워져 있습니다. 대각 성분은 self-attention을 보존하기 위해 1로 채웠다고 합니다. 이 마스크는 장면 그래프의 relational structure를 인코딩하고, spatial self-attention 중에 적용된다고 합니다.
좀 더 구체적으로, 각 temporal position j에 대해 spatial self-attention은 다음 특징 벡터 집합에 계산됩니다.
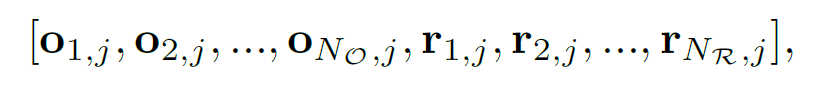
여기서 {o}_{i,j}와 {r}_{i,j}는 각각 시간 j에서의 {O}_{i} 와 {R}_{i}의 object, relationship feature입니다.
이와 다르게, temporal self-attention은 시간에 걸쳐 각 tracklet 내에서 독립적으로 적용됩니다.
relational tracklet transformer는 입력 tracklet당 하나의 feature sequence를 생성하므로, tracklet 차원을 따라 max pooling을 적용해 통합된 temporal feature sequence를 만듭니다. 이후 이 시퀀스는 classification head 및 localization head로 입력됩니다.
text feature의 경우, 사전학습된 텍스트 인코더(CLIP, BERT)로 input query를 token-level feature sequence로 인코딩하고, multimodal fusion이 가능하도록 learnable linear attention mechanism을 사용해 토큰 임베딩을 하나의 texture feature vector로 집계합니다. 이 aggregated feature는 각 frame feature와 concat되어 fused visual-textual sequence를 만들고, 이렇게 만들어진 시퀀스에 temporal positional embedding을 추가한 뒤 SA 블록으로 구성된 트랜스포머에 입력합니다. 이 단계에서 다양한 시간적 길이를 가진 순간들을 처리하기 위해 중간 트랜스포머 계층에서 L, L/2, L/4 등의 해상도를 가진 multi-scale temporal feature가 생성되고, 이 multi-scale sequence의 각 요소는 moment의 후보가 됩니다.
classification head가 각 후보의 relevance score p를 예측하고, localization head가 이에 대응되는 시작 지점과 끝나는 지점 (s,e)를 예측합니다(regression이죠). 여기서 top-N 후보들 {({p}_{i}, {s}_{i}, {e}_{i})}이 선택되고, Soft-NMS로 중복 값들을 후처리합니다.
Experiments
실험은 Charades-STA , QVHighlights, TACoS 벤치마크에서 수행되었습니다.
Charades-STA는 약 30초 길이의 6,672개의 비디오 및 텍스트 쿼리 16,128로 이루어진 데이터셋입니다. QVHighlights는 10,148개의 비디오와 10,310개의 쿼리로 구성되며 각 쿼리가 여러 moment와 대응될 수 있는 데이터셋이라고 합니다. TACoS는 평균 길이 4.8분의 요리 비디오 127개 및 18,818개의 query-moment pair로 구성된 데이터셋입니다. . 비디오 프레임은 Charades-STA와 TACoS는 1fps로, QVHighlights의 경우 0.5fps로 추출되었습니다.
Charades-STA와 TACoS에서는 다양한 temporal IoU(tIoU) threshold에서의 Recall@1(R1)과, 상위 1개 예측과 정답 사이의 mean IoU(mIoU)를 리포팅 하였다고 합니다.. QVHighlights는 쿼리가 여러 segment에 대응 될 수 있는데, 기존 연구들과 같이 tIoU threshold값 0.5~0.95의 mAP를 사용하였다고 합니다.
실험에서 text encoder로는 CLIP-B를 사용하였고, frame-level visual encoder로는 (1)SlowFast-R40 및 CLIP-B의 visual branch를 사용하거나 (2) VideoMAEv2-b를 사용하였다고 합니다.
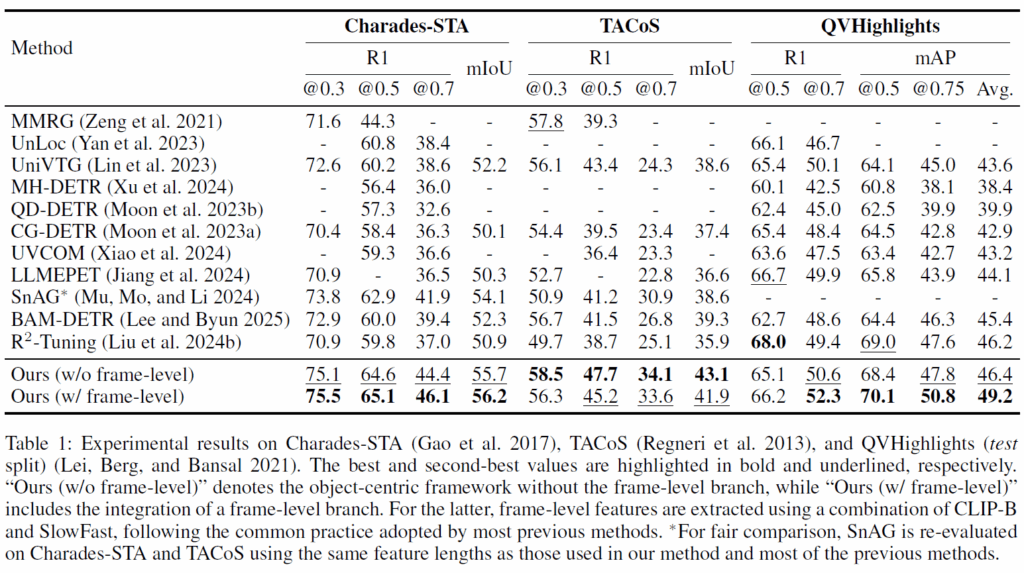
Table 1에 기존 방법론들 및 제안 방법론의 비교 실험 결과를 나타내었습니다. 대부분 기존 방법론들은 CLIP , SlowFast , I3D, C3D 와 같은 인코더를 사용하여 추출된 frame-level feature를 사용한 것입니다. 기존 방법론들과 비교했을 때 전반적으로 상당히 개선된 성능을 보였습니다.
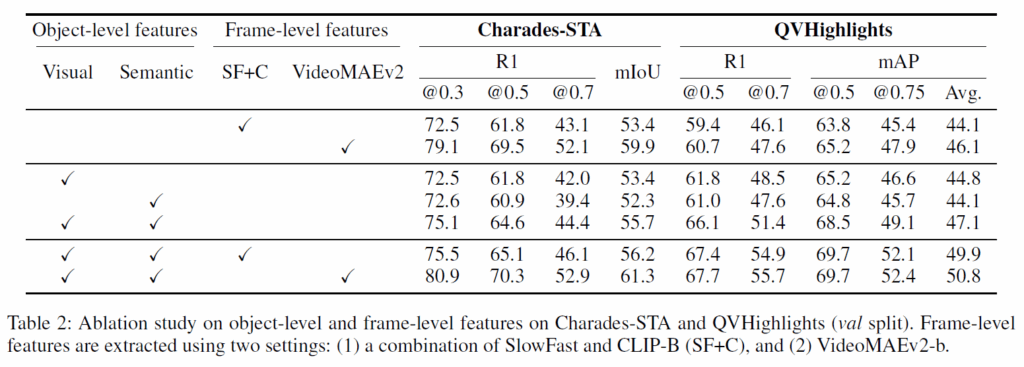
표 2에서는 object-level 및 frame-level feature의 영향을 평가하기 위해 수행된 ablation study르 나타내었습니다. SlowFast+CLIP-B(SF+C)뿐만 아니라 다중 프레임을 입력 받아 motion 정보를 모델링 할 수 있는 성능 좋은 비디오 인코더인 VideoMAEv2-b도 함게 비교하였습니다.
1,2행은 frame-level baeline 결과이고, 3~5행은 object-level framework에서 visual feature 및 semantic feature를 모두 사용하는게 중요함을 보여줍니다. 둘 중 하나라도 없으면 성능이 상당히 저하되는 것을 확인할 수 있습니다.
마지막 두 행은 object-centric + frame-level을 결합한 모델을 평가한 것입니다.
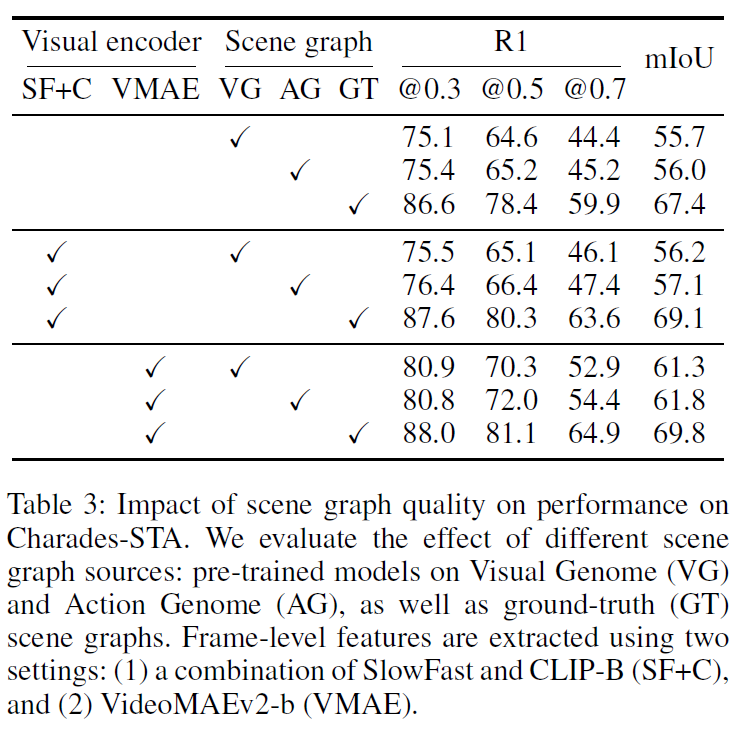
Table 3에는 scene graph 품질의 영향을 평가하였습니다. 여기서 AG는 Charades-STA의 키프레임에 대한 장면 그래프 주석을 활용한 Action Genome 데이터셋으로 OVSGG 모델을 학습시킨 것으로, VG 데이터셋으로 훈련했을 때보다 Charades-STA에서 더 품질 좋은 장면 그래프를 얻을 수 있습니다(데이터셋 튜닝한 것으로 생각해도 될 것 같습니다. GT는 이름 그대로 정답값을 사용한 oracle upper입니다. scene graph의 품질이 좋아질수록 성능 상 이득을 볼 수 있음을 확인할 수 있습니다.
중간중간 연구하다보면 항상 SGG task를 어디에 쓸 수 있을지에 대한 고민을 했는데, 읽으면서 더욱 깊게 그런 생각을 하게 만드는 논문이었습니다. 읽으면서 방법론보다는 적용 범위에 대한 고민을 했네요.
사실 SGG 모델이 잘 동작하고 품질 좋은 장면 그래프를 만들 수만 있다면 사용할 수 있는 곳은 많습니다. 하지만 아직까지 연구들이 그렇게 성숙하지 못해서 ‘꼭 SG를 쓰지 않고 VLM으로 우회하면 되지 않을까요?’라는 질문에 대한 답변을 자신있게 하지는 못하고 있습니다. VLM이나 LLM은 모델이 꽤 무겁고 fine-grained한 정보를 잘 처리하지 못하니 이를 사용하지 않고 바로 풍부한 SG를 만들어 낼 수 있으면 VQA, captioning, moment retrieval, image generation 등 다양한 곳에서 쓸 수 있을텐데, 아직까지 공개된 데이터셋으로는 고차원적인 무엇인가를 하기에 한계가 있는 것 같아요. 결국 돌고 돌아 벤체마크의 문제네요 허허.. 그렇다고 제가 지금 당장 데이터셋을 만들긴 어렵고, 누군가가 foundation model을 활용하던지 해서 더욱 풍부한 데이터셋을 공개해주면 좋겠습니다.
이만 리뷰 마무리하도록 하겠습니다.
감사합니다.