안녕하세요, 저번 주에는 VLA 모델의 대표작 중 하나인 SmolVLA에 대해서 리뷰를 했었습니다. 해당 논문에서 Baseline으로 언급된 것이 Vision Action(VA) 기반의 ACT였고, 이에 대해서 흥미가 생겨서 기존에 공부했던 내용에 +alpha를 해서 review를 작성해보려 합니다. 해당 논문에서는 단순히 학습 방식만을 제시하는 것이 아니라 기존의 high-end 로봇을 대신할 하드웨어 플랫폼을 제시함과 동시에 이에 적합한 학습 방식을 제시하는 내용이라서 이 두 부분에 대해서 집중해서 봐주시면 되겠습니다~

- Conference: RSS 2023
- Authors: Tony Z. Zhao, Vikash Kumar, Sergey Levine, Chelsea Finn
- Affiliation: Stanford University; UC Berkeley; Meta
- Title: Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
1. Introduction
로봇에게 정밀한 조작 작업을 주기 위해서는 정확한 closed-loop feedback을 포함하며 환경 변화에 대응해 계획을 조정하거나 다시 짜기 위한 높은 수준의 hand-eye coordination을 요합니다. 가령 소스 컵의 뚜껑을 열거나 배터리를 끼우는 동작은 pick and place와 같은 단순한 동작에 비해서 여러 테크닉을 요구하는 섬세한 동작을 부가적으로 요하는 task들이라고 볼 수 있습니다.
정밀 조작을 위한 기존 시스템은 정확한 state estimation을 위해 고가의 로봇과 high-end 센서를 사용합니다. 그러나 해당 논문에서는 이렇게 high-end 센서만을 사용하는 것에서는 한계를 느끼고 연구 level에서 접근 가능한 정밀 조작 저비용 시스템을 개발했습니다. 그리고 저비용 시스템의 정밀도 문제를 해결하기 위해 시스템에 학습을 도입하는 방식으로 신경망 자체가 저가 로봇의 오류를 능동적으로 학습하여 문제를 상쇄하는 방식을 제안합니다.
해당 시스템에서는 범용 webcam의 RGB 이미지를 액션으로 직접 매핑하는 end-to-end policy를 훈련하는 것이 최종 목표이고, 이 논문에서는 해당 방법이 정확한 state estimation이나 명시적 모델링 없이도, end-to-end Vision → Action policy가 충분한 closed-loop feedback을 학습할 수 있음을 보이, 조작 정책을 학습하는 것이 전체 환경을 모델링 하는 것보다 훨씬 간단하다고 합니다.
여기서 저자는 서브 issue를 느끼고 end-to-end 정책의 성능이 학습 데이터 분포에 크게 의존하고, 정밀 조작은 인간의 숙련도에 따라 오히려 더 noise한 정보가 들어갈 수있는 점 또한 시스템으로 해결하는 방법을 제시했습니다.
따라서 해당 논문에서 제시하는 것은 두가지입니다.
Teleoperation System
- 두 세트의 저렴한 기성품 로봇팔을 사용해 원격 제어 설정
- 서로 조종과 환경에 맞게 크기가 조정되어 있음
- 원격 제어에 joint space mapping 사용
- 더 쉬운 backdriving을 위해 3D 프린팅 부품으로 설정을 보강
- 2만 달러 예산 내의 매우 유능한 원격 제어 시스템
Imitation Learning Algorithm
- 모방 학습의 Compounding error(복합 오차)문제를 해결하기 위한 Action chunking 사용
- 실질적으로 결정해야 되는 작업의 횟수를 k배로 감소
- action chunking을 통해 Markovian decision process 위에서 temporal abstraction을 도입한 정책을 학습
- 정책의 매끄러움 향상을 위한 temporal ensembling(시간적 앙상블) 제안
- sequence modeling을 위한 transformer를 사용하고 human demonstration의 multimodality와 ambiguity를 모델링하기 위한 CVAE 도입
결과적으로 이 두 개를 제시함으로서 높은 정밀도와 풍부한 접촉이 필요한 작업을 가능케하고, 이전 방법들을 압도하는 성능을 보인다고 말하고 있습니다.
2. Related Work
Imitation learning for robotic manipulation & Addressing compounding errors
Imitation learning은 로봇이 전문가의 행동을 모방하여 정책을 학습하는 방식으로, 초기의 Behavior Cloning(BC) 접근에서는 시간에 따라 예측 오차가 누적되는 compounding error(오차 누적) 문제가 심각했습니다. 이를 완화하기 위해 과거 관측을 활용하는 history 기반 모델, 새로운 학습 목표 함수, 정규화 기법, 멀티 태스크 및 few-shot 학습, 언어 조건부 정책, 키포인트와 같은 구조적 정보 활용 등 다양한 개선 시도들이 제안되었습니다. 또한 분포 이탈을 보정하기 위해 DAgger 계열과 같이 on-policy 데이터 수집과 전문가 수정을 결합한 방식, 시연 과정에서 노이즈를 주입하는 방법, 오프라인 보정 데이터를 생성하는 접근이 등장했으나, 이들 방법은 전문가 개입 비용이 크거나 저차원 상태 또는 특정 작업에만 국한되는 한계가 있어 고차원 시각 입력을 기반으로 한 정밀 조작 문제에 일반적으로 적용하기에는 부족했습니다. 이에 본 논문은 pixel-to-action 설정을 유지하면서, 단일 행동 대신 action chunking을 통해 동작 시퀀스를 예측함으로써 유효 시계열 길이를 줄이고, 결과적으로 compounding error를 완화하는 접근을 제시합니다.
Bimanual manipulation
양팔 조작을 활용한 초기 연구들은 환경의 역학이 알려져 있다는 가정하에 고전적 제어 관점에서 문제를 다루었으나, 이러한 모델을 설계하는 과정은 시간이 많이 소요되며 복잡한 물리적 특성을 가진 물체에 대해서는 정확도가 제한될 수 있습니다. 최근에는 강화학습, 인간 시연을 모방하는 학습, 그리고 motor primitives를 연결하기 위한 키포인트 예측 학습 등 다양한 학습 기반 방법들이 양팔 조작 시스템에 통합되고 있습니다. 일부 연구들은 다빈치 수술 로봇이나 ABB YuMi와 같은 고가의 로봇을 사용하여 세밀한 조작 작업에 초점을 맞추었으나, 본 연구는 각 팔당 약 5천 달러 수준의 저가형 하드웨어로 전환하여 고정밀 폐루프 조작을 수행하는 것을 목표로 합니다. 본 연구에서 제안하는 텔레오퍼레이션 시스템은 leader 로봇과 follower 로봇 간의 조인트 공간 매핑을 사용하는 기존 방식과 가장 유사하지만, 특수 인코더나 추가 센서, 가공 부품을 사용하지 않고 시판 로봇과 3D 프린팅 부품만으로 구성되어 비전문가도 2시간 이내에 조립할 수 있다는 점에서 차별성을 가집니다.
3. ALOHA: A Low-cost Open-source Hardware System for Bimanual Teleoperation

해당 연구에서는 정밀 조작을 위한 접근 가능하고 고성능의 텔레오퍼레이션 시스템, ALOHA를 개발하고자 하면서 5가지의 설계 고려사항을 제시합니다.
- Low-cost: 전체 시스템은 대부분 로봇 연구실에서 예산 범위 내에 있어야 하며 시스템 전체가 단일 산업용 arm과 비슷한 가격을 가져야 합니다.
- Versatile: 실제 물체를 이용한 광범위한 정밀 조작 작업에 적용할 수 있어야 합니다.
- User-friendly: 시스템은 직관적이고 안정적이며 사용하기 쉬워야 합니다.(비전문가도 컨트롤 가능해야 함)
- Repairable: 설정이 불가피하게 고장날 경우 수리를 간단히 할 수 있어야 합니다.
- Easy-to-build: 연구자가 쉽게 구할 수 있는 재료로 신속하게 조립할 수 있어야 합니다.
원칙에 따라서 ALOHA follower 부분은 저가용 로봇 팔 ViperX 6-DoF 팔을 사용해 양손 평행 parallel-jaw 그리퍼 설정을 구축합니다. 가격 유지 및 관리 고려 사항으로 인해 손은 사용하지 않고, 해당 모델은 Dynamixel 모터를 구해 쉽게 수리가 가능하다고 합니다. 로봇 팔에 기본으로 장착되어 있는 OEM gripper는 정밀한 조작을 처리할 만큼 좋지 않아서 3D 프린팅을 활용해 손가락을 설계하고 그립 테이프를 부착했다고 합니다.
ALOHA의 leader 부분은 조작 용이성을 위해 ViperX 6-DoF보다 사이즈가 더 작은 3300달러 비용의 WidowX를 써서 joint space mapping을 사용한다고 합니다(작은 로봇을 사용해도 joint 기반이기 때문에 사용자가 조작 중에 크게 어려움을 겪을 것이라고는 보이지 않습니다). VR과 같은 컨트롤러를 사용하지 않는 이유는 singularity 문제를 잘 해결하지 못하고, 계산량이 추가로 들어간다는 것의 한계가 있습니다. 또한 로봇의 속도에 맞추지 못하고 사람이 빨리 움직이는 현상도 방지하고, 장치를 기반으로 하기에 작은 진동을 VR보다 상쇄할 수 있다는 이점이 존재합니다.
Teleoperation 경험을 향상하기 위해 leader로봇에 3D 프린팅된 핸들 및 가위 매커니즘을 적용해서 이진 열림 방식이 아니라 지속적으로 적은 힘으로도 조작할 수 있도록 합니다.

또한 teleoperation 중에 사용자가 중력에 의해 로봇팔을 오래 조작하는 것이 어려울 수도 있기에 이를 해결하는 고무 밴드 하중 균형 매커니즘 설계를 적용했다고 합니다. 이를 통해서 결과적으로 사용자가 부담을 적게 가지면서 조금 더 오래 데이터셋 수집 작업을 연속적으로 진행할 수 있다고 합니다.

부가적인 시스템으로는
- 20x20mm 알루미늄 압출재가 있는 로봇 케이지
- 4개의 480 x 640 RGB 스트리밍용 webcam(Logitech C922x)
- 50hz 데이터 기록
을 사용해서 결과적으로 $20,000 내에서 양손 Teleoperation 설정 ALOHA를 구축했습니다.
해당 시스템을 활용해서 수행할 수 있는 task는 아래와 같습니다
- Precise tasks: 지퍼 케이블 타이 조이기, 지갑에서 신용카드 꺼내기, 지퍼백 열고 닫기
- Contatct-rich tasks: 컴퓨터 보드에 288pin ram 삽입, 책 페이지 넘기기, 타공판 같은 곳에서 체인 및 벨트 조립과 같은 작업
- Dynamic tasks: 탁구 라켓으로 탁구공 저글링 하기, 공이 떨어지지 않도록 균형잡기, 공중에서 비닐봉지 흔들어서 열기
4. Action Chunking with Transformers
ALOHA에서 수집한 데이터를 활용하기 위해 새로운 알고리즘 ACT(Action Chunking with Transformers)을 해당 논문에서는 제시합니다.
ACT의 파이프라인은
- ALOHA를 이용해 human demo 수집
- leader robot의 joint space를 기록하고 이를 정답 action으로 사용(여기서 follower의 joint를 사용하는 것이 아니라 leader를 사용하는 이유에 대해서 논문에서 말하기로는 PID 컨트롤러를 통해서 follower에 전달되는 힘의 일부 정부가 소실될 수도 있어서 사람이 원하는 암묵적인 의미까지 정답으로 활용하려고 한다고 말하고 있습니다.)
- observation으로는 follower robot의 현재 joint space와 4대의 카메라에서 들어오는 이미지 피드로 구성되어
- 미래 aciton의 sequence를 예측하도록 ACT를 훈련 후(여기서 예측은 다음 시간 단계에서 양쪽 팔의 목표 관절 위치가 됩니다),
- 테스트 시에는 lowest validation loss를 달성하는 정책을 로드하고 환경에서 roll out합니다.
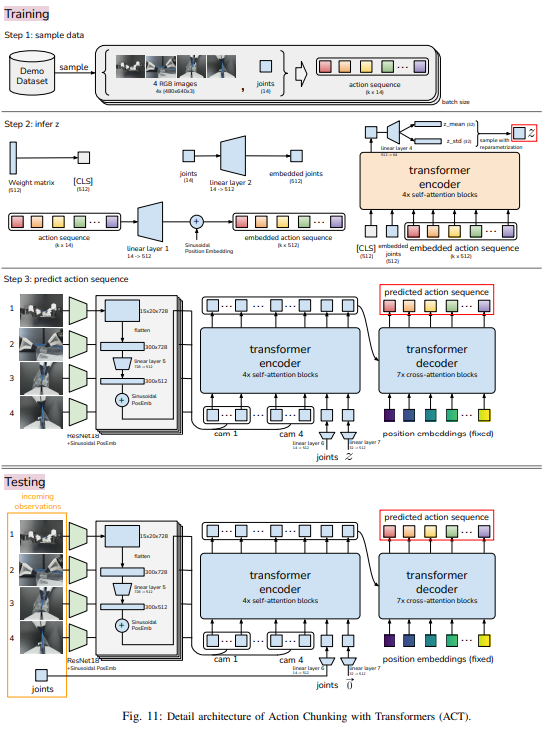
그러면 ACT의 구성에 대한 부가적인 설명을 진행하도록 하겠습니다
A. Action Chunking and Temporal Ensemble


학습 알고리즘은 위와 같이 구성되어 있습니다. 해당 부분에서 강조되는 내용은 Action Chunking입니다. Action Chunking은 개별 액션이 함께 그룹화되어 하나의 단위로 실행되어 저장 및 실행이 더 효율적으로 이루어지는 신경 과학 개념이라고 합니다(논문 내의 문장). agent는 매 k 단계마다 observation을 수신하고 다음 k 액션을 생성하고 액션을 순서대로 실행합니다. 이는 작업의 유효 범위가 독립된 액션을 예측하는 것이 아니라 일정한 흐름이 있는 것을 예측하기에 계산이 k배 감소함(?)을 의미합니다.
정책 모델은 \pi_{\theta}(a_{t}|s_{t})대신에 \pi_{\theta}(a_{t:t+k}|s_{t})를 모델링하여 k개의 step을 추가로 예측한다고 볼 수 있습니다. 이러한 chunking 방식은 human demo의 멈추는 동작이 진행 중의 멈춤인지, 판단이 안되는 멈춤인지, 끝난 멈춤인지 예측하는데 시간 단계에서 바라보기 때문에 non-Markovian 행동을 모델링 하는데 도움이 된다고 볼 수 있습니다.
이러한 chunking 방식을 무작정 연결하는 것은 부드러운 움직임을 주지 못하기 때문에 각 타임스텝마다 정책을 Query한 후 예측을 결합하기 위해서 temporal ensemble, 지수 가중치 방식을 사용합니다. w_{i}= \exp(-m*i)(m은 가중치가 얼마나 빨리 줄어들게 할지 하는 하이퍼 파라미터, i는 예측이 생성된 시점으로부터의 거리 또는 순서) 식을 활용해서 현재 타임에 맞는 aciton을 지수 가중치 방식을 통해 결합합니다.

이러한 방식은 인접한 time step의 action들을 집계하여 계산하는 편향을 초래하지 않으면서 추가적인 학습 비용을 발생시키지도 않고 부드러운 움직임을 생성하는데 큰 도움을 줍니다
B. Modeling human data
인간 시연 데이터는 본질적으로 노이즈가 많으며, 동일한 관찰 상태에서도 서로 다른 행동 궤적이 나타나는 확률 기반의 특성을 가집니다. 또한 정밀도가 덜 요구되는 구간에서는 인간의 행동이 보다 확률적으로 나타나므로, 정책이 모든 구간을 동일하게 모사하기보다는 높은 정확성이 요구되는 구간에 선택적으로 집중하는 것이 중요합니다. 해당 논문은 이러한 특성을 고려하여 action chunking 정책을 생성 모델로 학습하는 방식을 채택했습니다.
정책은 현재 관찰 s_t가 주어졌을 때 행동 시퀀스 a_{t:t+k}를 생성하도록 Conditional Variational Autoencoder(CVAE) 형태로 학습됩니다. CVAE는 encoder와 decoder로 구성되며, encoder는 학습 과정에서만 사용되어 decoder를 학습시키는 역할을 수행하고 테스트 단계에서는 제거됩니다. Encoder는 diagonal Gaussian으로 파라미터화된 잠재 변수(스타일 변수) z의 평균과 분산을 예측하며, 학습 효율을 높이기 위해 이미지 관찰은 제외하고 고유수용성 관찰(proprioceptive observation, 여기서는 joint space 라고 볼 수 있습니다.)과 행동 시퀀스에만 조건을 부여합니다.
CVAE decoder는 잠재 변수 z와 현재 관찰 정보(이미지 및 관절 상태)에 모두 조건을 부여하여 행동 시퀀스를 예측합니다. 테스트 단계에서는 z를 사전 분포의 평균인 0으로 설정하여 정책을 결정론적으로 디코딩합니다. 학습은 전문가 시연 데이터셋 D에 대해 다음과 같은 목적함수를 최소화하는 방식으로 수행됩니다.
min_{\theta}−\sum_{s_{t},a_{t:t+k}∈D} \log \pi_{\theta}(a_{t:t+k}|s_{t})이는 모든 시연 상태–행동 시퀀스 쌍에 대해 모델이 예측한 행동 시퀀스의 로그 가능도를 최대화하도록 정책 파라미터 \theta를 최적화하는 것을 의미합니다.
최종적으로 CVAE 학습은 재구성 손실, 정규화 항을 함께 고려하며, 전체 손실 함수는
여기서 \beta는 잠재 변수 z를 통해 전달되는 정보량을 조절하는 하이퍼파라미터로, 값이 클수록 불필요한 변동성을 억제하고 보다 압축된 표현을 학습하도록 유도합니다. 이를 통해 정책은 인간 시연의 노이즈를 효과적으로 완화하면서, 정밀 조작에 중요한 행동 패턴에 집중할 수 있습니다.
C. Implementing ACT

해당 논문에서는 CVAE를 기반으로 하여 action sequence를 생성하는 방법을 제시했습니다. 위 사진에서 주황색 부분은 latent space를 출력하는 CVAE Encoder가 되고 파란 부분은 CVAE Decoder가 되어 inference 때에는 Decoder만 사용하는 방식으로 진행됩니다. Encoder는 계산 효율성을 위해 이미지 observation은 제외하고 joint와 CLS, k개의 step으로 이루어진 action sequence를 받습니다.

구체적인 이해를 위해 부록에 있는 사진을 보면 가중치들의 전체적인 흐름(?)을 담고 있는 CLS와 linear layer를 통과한 embedded joint, action sequence를 transformer encoder에 넣어줍니다. 여기서 action sequence는 시간에 대한 순서를 위해 position embedding을 해줍니다. transformer encoder에서 나온 값을 linear layer에 통과시켜서 latent space인 z를 만들어줍니다. CLS의 개념은 BERT에서 나온 개념으로 action sequence에 대한 정보를 함축하면서 학습한 값(?)이라 이해하시면 쉬울 것 같습니다.
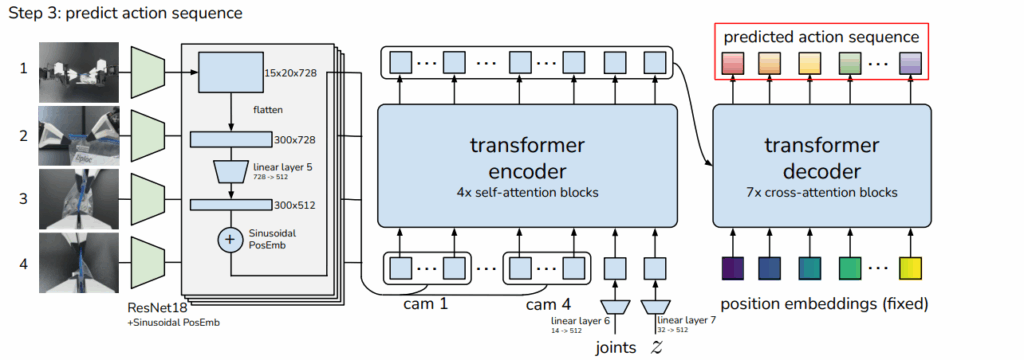
이렇게 만들어진 Z는 CVAE의 Decoder 구조에 들어갑니다. 이때는 resnet을 통과한 feature(15 x 20 x 728)를 flatten 시킨 값을 300 x 512로 맞춘 후 공간 정보를 유지하기 위해 transformer의 positional embedding과 위치에 대한 값을 추가해줍니다. 이를 z, joint 함께 인코더에 넣고 나온 값을 transformer decoder에 K, V로, k step의 시간 정렬을 위한 position embedding은 Q로 들어가서 예측 action sequence를 뽑아내게 됩니다. 여기서 나온 값의 차원은 k x 512 차원이기 때문에 MLP를 통해 k x 14(7 DoF 로봇 2개의 joint)로 down-projection되어 k스텝동안 예측된 target joint positions에 대응하게 됩니다.
여기서 loss는 L1 loss를 사용한다고 하는데 이에 대한 추측으로는 L2 loss는 평균을 만들듯이 action sequence를 흐리는 경향이 있어서 중앙값의 경향에 더 가까운 L1 loss가 더 높은 성능을 낸다고 추측되고 실제로 L1이 더 정밀하게 모델링한다고 합니다. 또한 상대적인 변화량보다는 절대적인 변화량을 사용하는 것이 좋다고 하는데 이에 관해서는 누적 오차의 이유라고 볼 수 있을 것 같고 다음에 나오는 실험 단계에서는 80M개의 파라미터를 가지는 모델에 대해 from scratch로 훈련되었다고 합니다.
5. Experiments
해당 논문에서는 정밀 조작 테스크에서 ACT의 성능 평가를 위한 실험도 제시를 합니다. ALOHA를 이용한 6개의 실제 세계 테스크 외에도 MuJoCo에서 두개의 시뮬레이션 된 정밀조작 테스크를 구축하여 이에 대한 평가를 진행합니다. Task의 종류는 아래와 같습니다.
A. Tasks
8개의 모든 테스크는 정교한 양팔 조작을 요합니다
- 지퍼를 정확하게 잡아서 지퍼백 열기
- 리모컨 잡고 배터리 섬세하게 밀어 넣기
- 작은 소스컵의 뚜껑 열기
- 벨크로 타이를 끼워서 붙이기?
- 작은 테이프 조각을 판지 상자의 모서리에 붙이는 것
- 마네킹 발에 신발을 신기고 신발의 벨크로 스트랩으로 고정
- 큐브 옮기기(sim)
- 큐브 끼우기(sim)

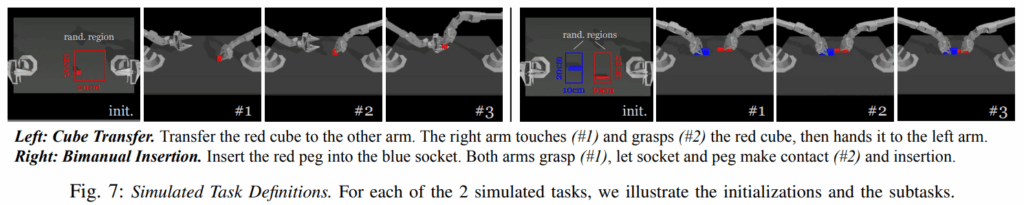
B. Data Collection
6개의 실제 작업에 대해서는 ALOHA 텔레오퍼레이션 시스템을 활용하여 시연 데이터를 수집합니다. 각 시연은 작업에 따라 약 8–14초가 소요되며, 이는 50Hz 제어 주기를 기준으로 약 400–700 타임스텝에 해당합니다. Thread Velcro 작업을 제외한 모든 작업에 대해 50개의 시연을 수집하고, Thread Velcro 작업에 대해서는 난이도를 고려하여 100개의 시연을 기록합니다. 이에 따라 각 작업당 시연 데이터의 총량은 약 10–20분 분량이며, 물체 재배치 및 텔레오퍼레이터의 실수로 인한 재시도를 포함하면 실제 데이터 수집에는 약 30–60분이 소요됩니다.
두 개의 시뮬레이션 작업에 대해서는 스크립트 정책을 사용한 시연과 인간 시연의 두 가지 유형의 데이터를 수집합니다. 시뮬레이션 환경에서의 텔레오퍼레이션은 ALOHA의 leader 로봇을 사용하여 시뮬레이션된 로봇을 제어하는 방식으로 수행되며, 작업자는 모니터를 통해 환경의 실시간 렌더링을 관찰합니다. 두 경우 모두 각각 50개의 성공적인 시연을 기록합니다.
C. Experiment Results
ACT의 성능을 평가하기 위해 기존의 네 가지 imitation learning 방법과 비교 실험을 수행합니다.
- BC-ConvMLP: 이미지 관측을 컨볼루션 신경망으로 처리한 뒤, 추출된 특징을 로봇의 조인트 위치와 결합하여 단일 액션을 예측하는 가장 기본적인 행동 복제 방법입니다.
- BeT(Behavior Transformer): Transformer 구조를 사용하지만 action chunking을 적용하지 않고, 관측 이력으로부터 단일 액션을 예측합니다.
- RT-1: Transformer 기반 방법으로, 과거 관찰의 고정 길이 이력을 입력으로 받아 하나의 액션을 출력합니다.
- VINN: 새로운 관찰이 주어지면 시각적 특징 공간에서 가장 유사한 k개의 관측을 검색하고, 가중 k-최근접 이웃 방식을 사용하여 해당 액션을 반환합니다.
ACT, BeT, VINN에서 사용되는 시각적 특징 추출기는 시연 데이터로 fine-tuning된 ResNet을 사용하며, 각 방법의 하이퍼파라미터 설정은 아래와 같습니다.

sim 작업의 경우에는 50번의 시행으로 3개의 랜덤 시드에 걸쳐 성능을 평균냈고, real-world 작업은 하나의 시드를 실행하고 25번의 시행으로 평가했다고 합니다.
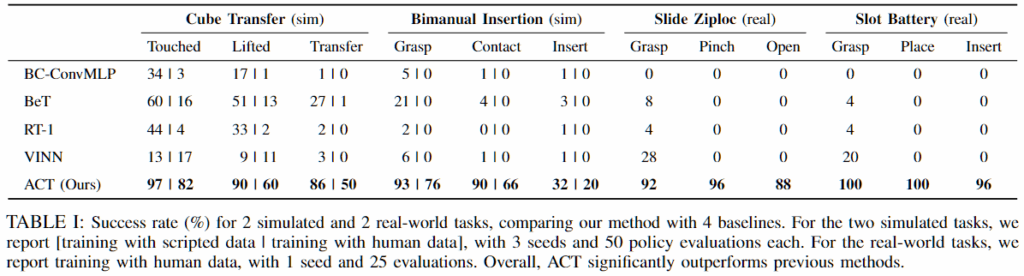

실험 결과 ACT는 기존 방법들보다 전반적으로 더 높은 성능을 보입니다. 이는 비마르코프적 행동을 효과적으로 학습하고, 기존 imitation learning에서 자주 발생하던 로봇 정지 문제를 완화했다고 논문에서는 분석했습니다. 인간 시연 데이터를 사용한 경우 시뮬레이션 데이터보다 성능이 낮게 나타났으며, 이는 인간 데이터의 확률성과 다중 모달성이 imitation learning 문제를 더욱 어렵게 만들기 때문입니다. (아래 표에서는 비교 대상 중 가장 높은 성능을 보인 BeT와의 결과를 비교합니다.) Thread Velcro 작업에서는 단계가 진행될수록 성능이 저하됩니다. 2단계에서는 오른쪽 팔이 그리퍼를 너무 일찍 닫아 공중에서 케이블 타이의 꼬리를 잡지 못하는 문제가 발생합니다. 3단계에서는 삽입 정밀도가 부족하여 케이블 타이의 루프를 놓치는 경우가 많습니다. 이러한 실패는 케이블 타이가 배경 대비가 낮고 이미지에서 차지하는 비중이 작아, 시각 관찰만으로 정확한 위치를 추정하기 어렵기 때문이라고 결론지었고, 실제로도 그리퍼를 보면 크게 눈에 케이블 타이가 잘 안보인다는 것을 확인할 수 있었습니다.

6. Ablations
결과적으로 ACT의 핵심
- Action chunking & temporal ensembling: non-Markovian적 데모를 더 잘 처리하는 능력
- CVAE: noisy한 인간 데모를 잘 모델링하는 능력
- high-frequency: 주파수에 따른 진행 능력
을 평가해봤다고 합니다.
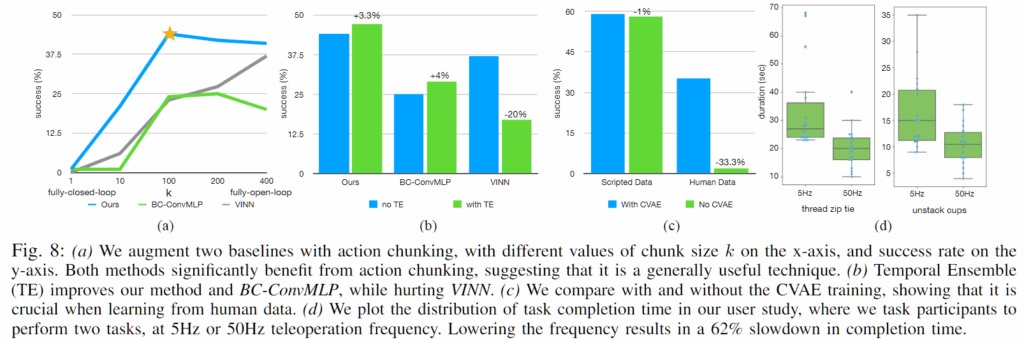
A. Action Chunking and Temporal Ensembling
k=1에서는 성능이 매우 낮게 나타나며, k가 증가함에 따라 성능이 크게 향상됩니다. 그러나 k가 지나치게 커질 경우 반응형 행동이 감소하고 긴 행동 시퀀스 모델링이 어려워져 성능이 다시 하락합니다. BC-ConvMLP에서는 출력 차원을 확장하여 action chunking을 적용하고, VINN에서는 다음 k개의 행동을 검색하는 방식으로 이를 구현하였습니다. 이 결과는 ACT 모델만을 개선한 것만이 아니라, action chunking 자체가 성능 향상을 가져온다는 점을 보여줍니다. Temporal Ensembling은 전반적으로 소폭의 성능 향상을 제공하였으나, VINN과 같이 유사 행동을 검색하는 방법에서는 가중 평균이 오히려 성능 저하로 이어지는 것을 볼 수 있었습니다.
B. Training with CVAE
CVAE objective 없이 현재 관찰이 주어졌을 때 액션 시퀀스를 직접 예측하고 L1 손실로 학습한 ACT와 비교한 결과, 시뮬레이션의 스크립트 데이터에서는 노이즈가 거의 없어 CVAE의 효과가 크지 않게 나타났습니다. 반면, 현실 세계의 인간 시연 데이터에서는 CVAE를 적용했을 때 약 33%의 성능 향상이 관찰되어, 인간 데이터의 확률성과 다중 모달성을 모델링하는 데 CVAE가 중요한 역할을 함을 확인할 수 있습니다.
C. Is High-Frequency Necessary?
정밀 조작 작업에서 고주파수 제어의 효과를 분석하기 위해 50Hz와 5Hz 텔레오퍼레이션을 비교한 결과, 50Hz 제어를 사용할 경우 작업 시간이 5Hz 대비 약 62% 단축되었으며, 예를 들어 케이블 타이 조이기 작업은 33초에서 20초로 감소하였습니다. 이러한 결과는 정교한 fine manipulation을 수행하기 위해서는 고주파수 텔레오퍼레이션이 필수적이며, 이는 저가형 하드웨어 기반 시스템의 한계를 보완해줍니다.
7. Limitation and Conclusion
결과적으로 해당 논문에서는 텔레오퍼레이션 시스템 ALOHA와 새로운 모방 학습 알고리즘 ACT로 구성된 정밀 조작을 위한 저비용 시스템을 제시했습니다. 이를 통해서 앞으로 저비용 오픈 소스 시스템이 세분화된 로봇 조작을 발전시키기 위한 중요한 단계이자 접근 가능한 리소스가 되기를 바란다고 하면서 해당 논문을 마치고 있습니다.
해당 논문을 보면서 하드웨어와 소프트웨어를 동시에 제시를 하는 논문으로서 정말 단순한 장치이지만 혁신적인 패러다임을 가져올 수 있을 것이라고 보이고 해당 논문의 1저자이신 Tony Z. Zhao는 이를 활용해서 스타트업?을 마련한 것으로 보아서는 단순히 소프트웨어의 한계만 극복하는 것으로 로봇 세계에서는 패러다임을 바꾸기에는 무리가 있지 않나 라는 생각도 드는 것 같습니다.
Appendix
ALOHA 플랫폼에서 Shadow Teleoperation System에서 할 수 있는 15가지 작업 중 Baoding ball in-hand rotation task 빼고(손가락이 없어서) 14개까지 커버가 가능하다고 합니다.

위에서 설명드린 ACT의 전체적인 구조도 입니다.