본 논문은 최근 핫한 토픽은 3D Gaussian Splatting 을 Place Recognition (PR) 분야에 접목한 논문입니다. 기존 PR 모델들이 피처 레벨에서의 추상적인 퓨전에 집중했다면, 본 논문은 명시적인 Scene Representation 을 통해 두 모달리티를 시각적, 기하학적으로 완벽하게 융합한 뒤 장소를 인식하겠다는 접근 방식을 취하고 있습니다. 바로 리뷰 시작하겠습니다.
1. Introduction
자율주행의 핵심인 Place Recognition(PR)에서 Camera와 LiDAR를 결합하는 Multimodal Fusion은 이제 거의 표준이 되었습니다. 하지만 저자는 기존 연구들(MinkLoc++, LCPR 등)이 “Interpretability(해석 가능성)의 부재”라는 한계를 가진다고 지적합니다. 대부분의 기존 방식은 이미지의 Feature 벡터와 포인트 클라우드의 Feature 벡터를 네트워크 중간에서 단순히 Concatenation하거나 Attention으로 섞어버립니다. 이렇게 되면 물리적으로 이 두 정보가 어떻게 정합되었는지 알기 어렵고, Black Box 처럼 동작하게 됩니다.
그래서 저자는 3D Gaussian Splatting (3D-GS)을 도입합니다. 원래 3D-GS는 렌더링을 위한 기술이지만, 저자는 이것을 “LiDAR의 기하학적 정보와 카메라의 텍스처 정보를 하나의 통합된 3D 표현형(Representation)으로 묶는 그릇”으로 활용하자고 제안합니다.
즉, “추상적인 벡터끼리 섞지 말고, 아예 3D 공간상에 컬러와 형태를 가진 Gaussian 덩어리들을 만들어서 그 자체를 학습하자!”라는 것이 핵심 아이디어입니다. 이를 위해 GSPR이라는 새로운 네트워크를 제안하며, 여기서 추출한 Spatio-temporal Feature를 통해 SOTA 성능을 달성했다고 합니다.
이에 대한 intro figure 는 아래와 같고, 자세한 동작 방식에 대해선 method 단락에서 살펴보겠습니다.
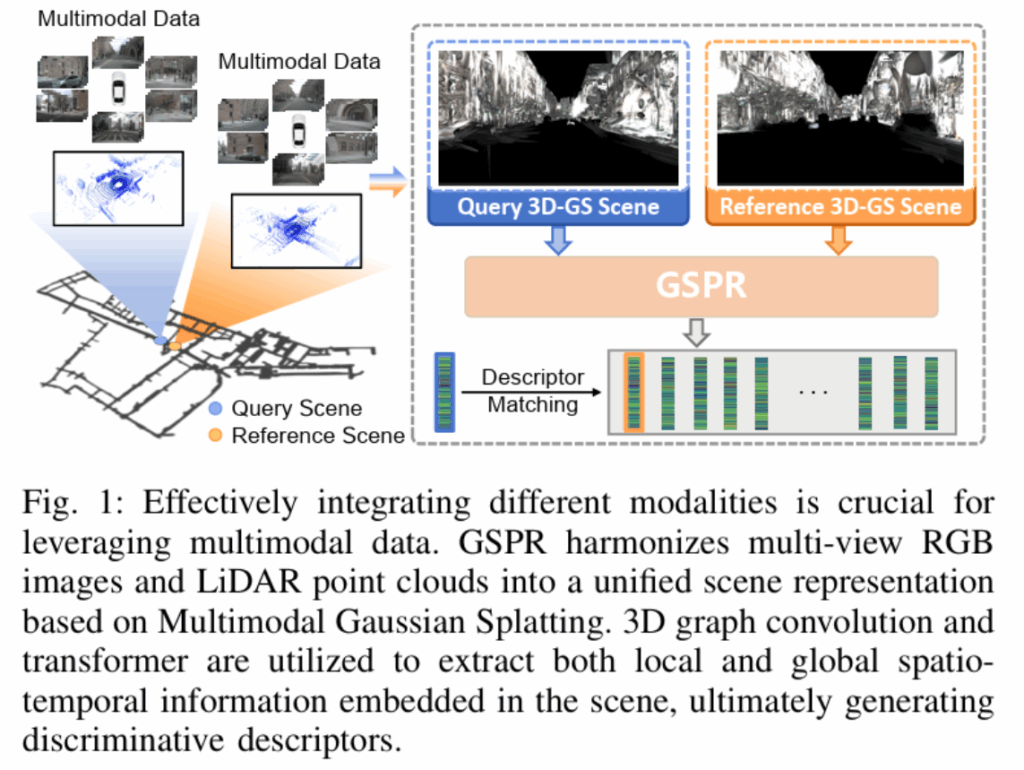
2. Method
본 논문의 방법론은 크게 1) 장면을 3D Gaussian 으로 표현하는 단계 (MGS) 와, 2) 이를 학습하여 Descriptor 를 뽑는 단계 (GDG) 로 나뉩니다. 최종 동작 방식 figure 는 아래와 같으며, 2.1절과 2.2절에서 각가 살펴보겠습니다.
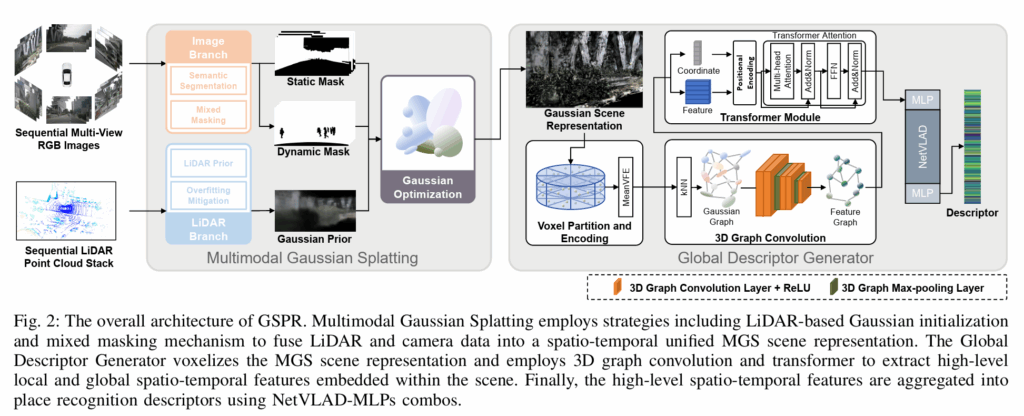
2.1. Multimodal Gaussian Splatting (MGS)
Multimodal Gaussian Splatting (MGS) 방법은 Image Branch 와 LiDAR Branch 를 통해 다중 모달 데이터를 처리한 후, 가우시안 최적화(Gaussian Optimization)를 통해 서로 다른 모달리티를 시공간적으로 통합된 명시적 장면 표현으로 통합합니다. 이는 실제 LiDAR point clouds 보다 더 넓은 커버리지 영역과 더 균일한 분포를 가진 장면 표현을 제공합니다. 아래 그림과 같은 과정으로 진행됩니다.
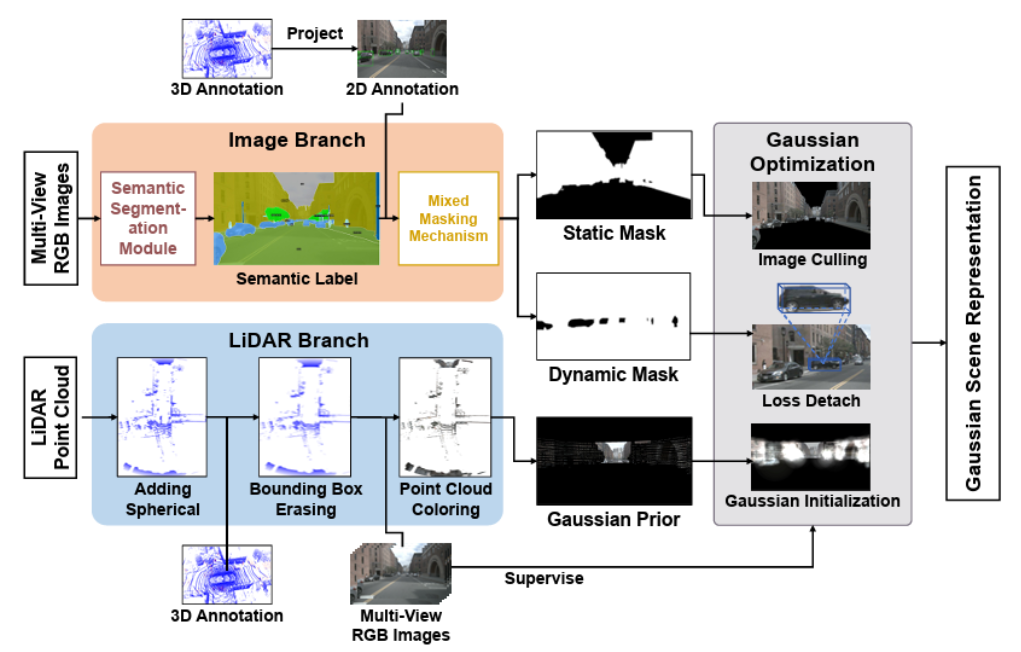
기존의 3D-GS 방식은 SfM(Structure from Motion)으로 초기 포인트 클라우드를 만드는데, 자율주행 환경(무한한 야외, 텍스처 부족, 고속 주행)에서는 SfM이 자주 실패합니다. MGS는 이를 해결하기 위해 LiDAR를 Prior로 사용하여 Gaussian을 초기화하고 최적화합니다.
1) LiDAR 기반 Gaussian 초기화 (Initialization)
LiDAR point clouds 를 Gaussian 의 position prior 로 사용합니다. 이에 대한 3D Gaussian ㅂ문포의 수식은 아래처럼 표현할 수 있습니다.
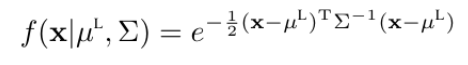
위 수식에서 \mu^L 는 LiDAR point cloud 의 position 을 의미하며, 3×3 행렬인 \Sigma 는 공분산 행렬을 의미합니다.
색상의 경우 LiDAR 포인트를 카메라 이미지 평면에 투영하여 해당 픽셀의 RGB 값을 가져옵니다. 그리고 이 값을 Gaussian 의 Spherical Harmonics(SH) 초기값으로 사용한다고 합니다. 즉 각각의 Gaussian 은 초기부터 LiDAR 를 참고하여 정확한 위치와 색상 정보를 가지고 시작하게 되는 것입니다.
2) Overfitting 방지
LiDAR는 사거리가 한정되어 있어 먼 하늘이나 배경 정보가 없습니다. 3D-GS가 이를 학습하려다 보면 가까운 곳에 둥둥 떠다니는 아티팩트(Floating Artifacts)를 만듭니다.
이를 막기 위해 LiDAR 범위 바깥쪽에 가상의 점들로 이루어진 거대한 반구(Spherical Dome)를 추가하여 먼 배경(하늘 등)을 별도로 처리하도록 유도합니다.
3) Mixed Masking Strategy (동적 객체 제거)
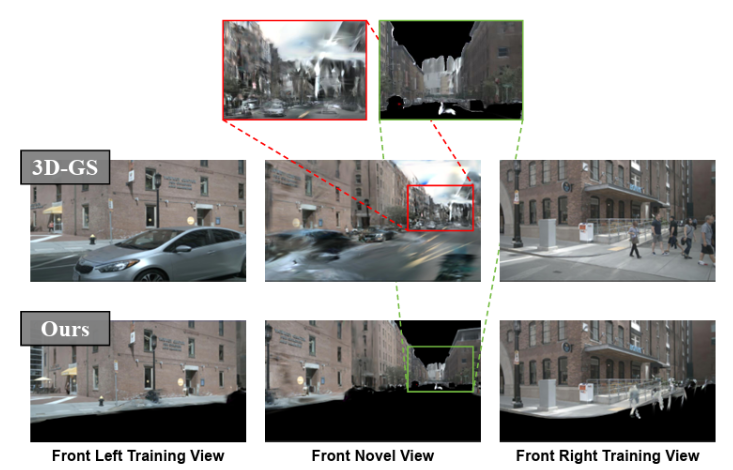
Place Recognition에서 움직이는 차나 사람은 보통 노이즈로 간주하곤 합니다. 저자는 두 가지 마스크 만들어 학습에서 배제합니다. 위 그림처럼 말이죠.
- Static Mask: Segmentation 네트워크(Mask2Former) 로 하늘, 도로 등을 구분.
- Dynamic Mask: 3D Bounding Box를 이미지에 투영하여 차량/보행자 영역을 찾음.
또한 마스킹된 영역에 대해서는 Gradient가 전파되지 않도록 loss detach 처리를 하여, Gaussian이 움직이는 물체 대신 정적인 배경 구조만 학습하도록 강제한다고 합니다.
2.2. Global Descriptor Generator (GDG): 특징 추출 단계
MGS를 통해 생성된 scene 은 수만개의 질서없는 Gaussian 덩어리 입니다. 이를 바로 network 에 넣을 수 없기 때문에, 구조화 과정을 거쳐 최종적으로 descriptpor 를 뽑습니다.
1) Voxel Partition & Encoding (구조화)
전체 3D 공간을 원통형(Cylindrical) Voxel로 잘게 쪼갭니다. 이후 각 Voxel 안에 들어있는 여러 Gaussian들의 속성값 (위치, 크기, 회전, 투명도, SH계수 등 총합 59개 channel)을 평균(Mean)내어 하나의 Voxel feature로 압축합니다.
2) 3D Graph Convolution
생성된 Voxel들은 서로 떨어져 있으므로, k-NN 알고리즘을 써서 각 Voxel마다 주변 이웃 Voxel들을 찾아 연결하여 graph 를 생성합니다. 여기에 3D Graph Convolution 을 적용하여 Voxel 내의 특징과 이웃 voxel 들의 특징을 aggregation 합니다. 이를 통해 local feature 를 추출할 수 있게 됩니다.
3) Transformer Module (Global Context 학습)
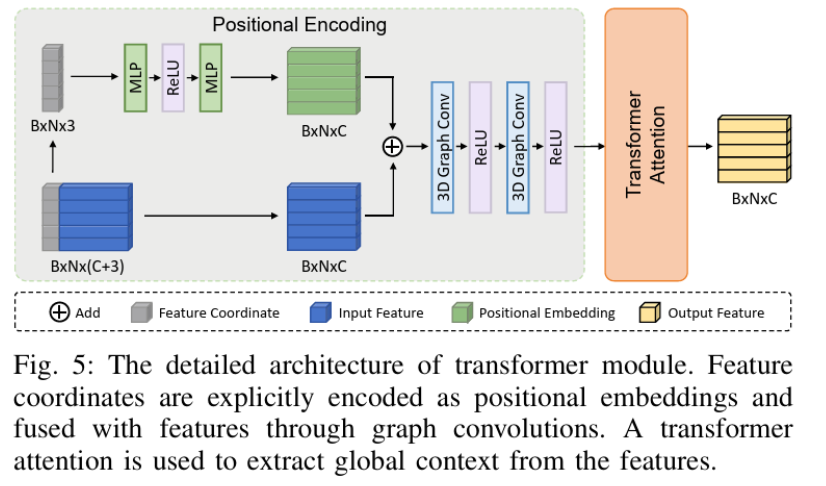
GCN은 주변의 local 한 영역만 보기 때문에, 멀리 떨어진 요소들 사이의 관계는 학습할 수 없습니다. 이를 해결하기 위해 추가적으로 Transformer Encoder를 붙입니다. 각 Voxel의 3D 좌표 정보를 인코딩해서 positional enbedding 정보로 더해주고, 모든 Voxel끼리 self-attention 연산을 수행하여 scene 전체의 global context 를 파악하게 됩니다.
위 3가지 과정을 거친 후 최종적으로 NetVLAD 를 통해 하나의 global descriptor (1×256) 를 생성할 수 있게 됩니다.
3. Experiment
3.1. Place Recognition Performance
실험은 크게 NuScenes, KITTI, 그리고 KITTI-360 에서 진행하였습니다.
결과 table 은 아래와 같습니다.
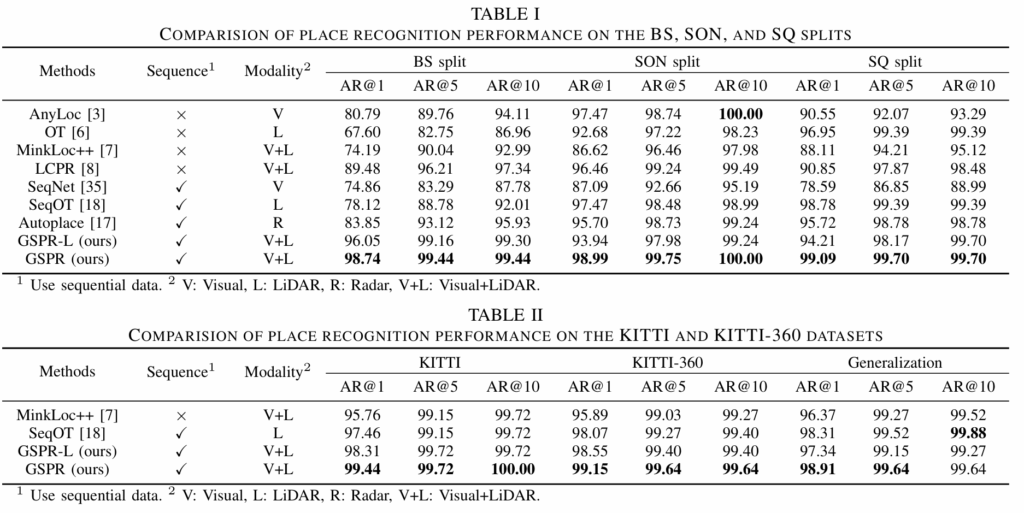
먼저 Table I은 NuScenes 데이터셋에서의 장소 인식 성능을 보여줍니다. 실험은 Boston Seaport(BS), Singapore-OneNorth(SON), Singapore-Queenstown(SQ)의 세 가지 스플릿에서 진행되었으며, GSPR을 기존의 SOTA 모델들과 비교하고 있습니다.
저자들의 최종 버전인 GSPR 이 모든 지표에서 타 방법론을 능가하고 있습니다. 또한 연산량을 줄인 경량화 버전인 GSPR-L조차도 96.05%의 AR@1을 기록하며 기존 모델들 대비 높은 성능을 보입니다. 이는 GSPR이 복잡한 도심 환경이나 조명 변화가 심한 조건에서도 매우 강인한 장소 인식 능력을 가지는것을 시사한다고 저자들은 말합니다.
다음으로 Table II는 KITTI와 KITTI-360 데이터셋을 이용한 실험 결과입니다. 저자는 이 실험을 통해 모델의 일반화(Generalization) 성능을 강조하고 있습니다. 표의 ‘Generalization’ 열을 보면, KITTI 데이터셋으로만 학습된 모델을 가중치 미세 조정(Fine-tuning) 없이 바로 KITTI-360 데이터셋에 적용했을 때의 결과를 확인할 수 있습니다. 타 방법론 대비 높은 성능을 통해 GSPR 이 학습하지 않은 낯선 환경에서도 안정적으로 동작함을 주장합니다.
3.2. Ablation
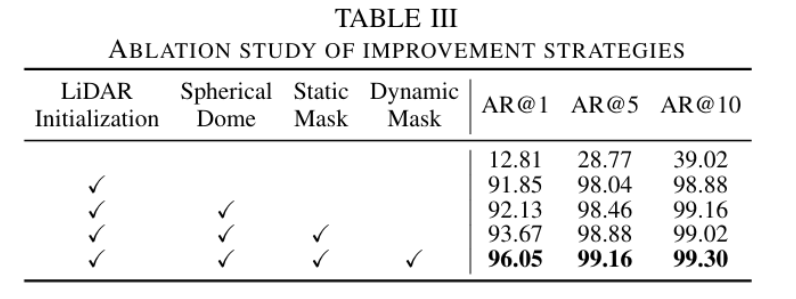
다음은 ablation 결과입니다. LiDAR Initialization 과정 없이 기본 3D-GS 로 생성한 gaussian scene 을 사용하게 될 경우 엄청나게 낮은 성능을 달성합니다. 이는 아마 nuScenes 데이터셋에서 SfM이 신뢰할 수 있는 스파스 재구성 결과를 생성하기 어렵고, 이로 인해 가우시안 초기화가 불충분하고 장면 재구성이 최적화되지 못하게 되어 그렇다고 저자들은 설명합니다.
이후 제안하는 여러 요소들을 추가함으로써 점차 성능이 오르는 결과를 보이고 있습니다.
제안하는 방식의 경우 3D-GS 의 optimization 과정이 필요하기 때문에 실시간 추론 관점에서는 scene 구축에 걸리는 시간이 bottle-neck 이 될 수도 있습니다. 저자들도 이를 의식하여 GSPR-L 이라고 하는 경량화 버전을 제안했지만 e2e 실시간 모델을 위해서는 조금 개선할 점이 있어보입니다.
그럼에도 3D Gaussian Splatting 테크닉을 PR task 에 적용시켜 본 아이디어가 돋보이는 논문이라는 생각은 듭니다. 리뷰 마치도록 하겠습니다.