안녕하세요. 첫번째 X-review네요.
바로 시작하겠습니다.

1. Introduction
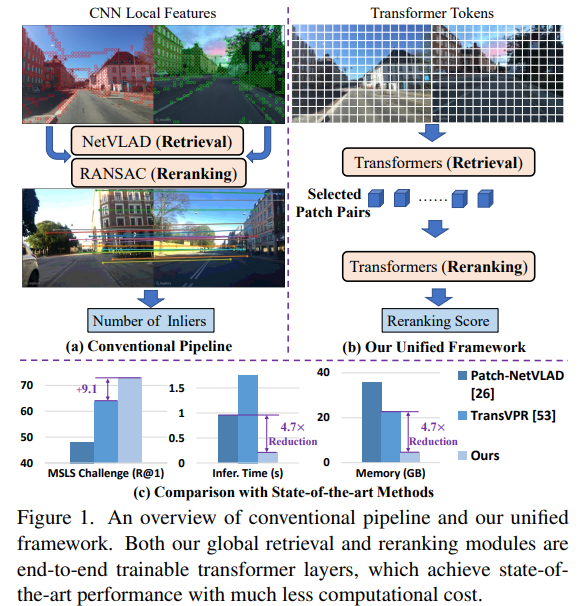
VPR에서는 주로 two stage로 retrival을 진행하는데, 먼저 global retrival과 reranking을 진행합니다. 지금까지의 논문들은 먼저 global retrival로 top N개의 이미지를 먼저 선정하고, 이 이후에 RANSAC와 같은 geometric verification을 진행하는 방식으로 reranking을 진행했습니다. 그러나 R2Former은 geometric한 정보뿐만 아니라 task-relevant information도 사용하여서 reranking을 진행할 수 있다고 얘기하고 있습니다.
그리고 R2former는 backbone으로 기존 CNN이 아닌 ViT를 선택했습니다. 최근 연구들이 VPR에서 ViT가 강한 성능을 보이기에 선택했다고 얘기하지만, 특이하게도 local한 영역을 보기에 local information이 encode되는 CNN계열과 다르게 ViT계열은 global한 receptive field를 가지기에 local한 matching을 바로 진행하기 어렵다고 지적하고 있습니다.
이 논문의 contribution은 아래와 같습니다.
- One-stage(global retriaval+reranking)로 two-stage 방법론보다 높은 성능
- 중요한 local feature에 attention하는 reranking module 설계
- 기존 reranking 방법론보다 빠르고, 메모리도 적게 듦
2. Problem Formulation and Training Objective
먼저 positive와 negative를 정의하고 있습니다.
positive는 10m이내이며, embedding space상에서 가장 가까운 image를 positive로 사용합니다. 단순히 제일 가까운 거리를 기반으로 택하는 것이 아닌, 10m이내이며 encoder를 타고나온 feature embedding을 기반으로 선택합니다.
negative는 25m 이상인 이미지를 전부 negative로 정의합니다.
query, positive, negative의 feature embedding을 E_q, E_p, E_n으로 표현한다면
global retrieval loss는 아래와 같습니다.
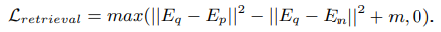
(||와 제곱은 L2 norm을 의미하고,m은 margin을 의미합니다)
local한 matching을 위한 reranking loss는 아래와 같습니다.
reranking module은 2개의 이미지를 input으로 받아 two-logit score L을 내놓습니다.
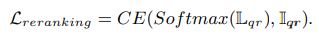
(L: logits score, I: GT label for query-reference pair, CE: Cross Entropy)
3. Global Retrival Module
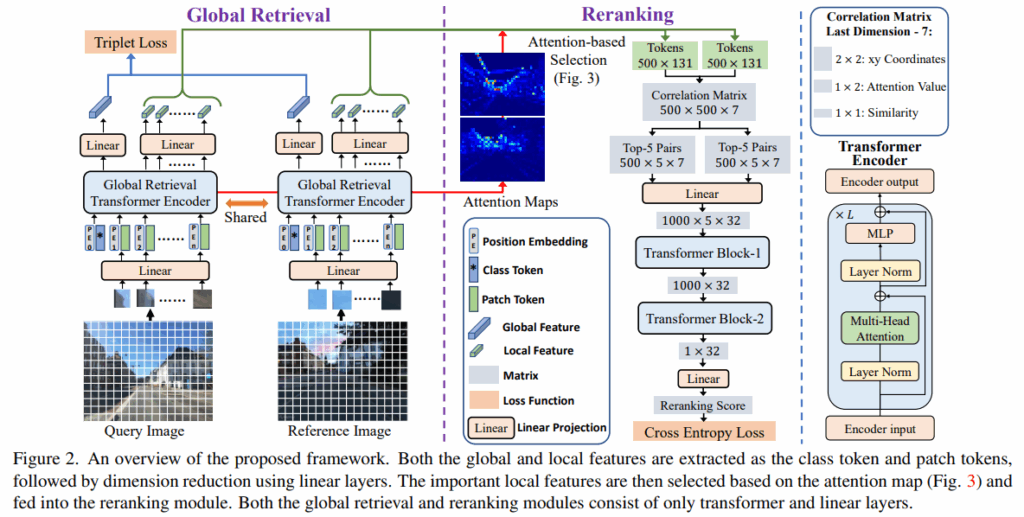
Gloabl한 descriptor를 뽑는 module입니다. ViT를 backbone으로 사용합니다.
특징으로는 query와 reference 이미지 모두 하나의 encoder를 사용합니다.
global descriptor를 뽑아내는 과정에서 aggregation이나 keypoint extraction과정이 없습니다. 해당 논문은 transformer 모듈만을 통해서 feature들을 뽑아내고 있는 점을 강조하고 있습니다. 자세히 알아보겠습니다.
먼저 이미지를 patch token으로 변환한 후 ViT를 통과시킵니다. (추가적으로 Positional Embedding을 interpolation하는 방식으로 다양한 해상도도 처리 가능하게 해줬다고 얘기하고 있습니다)
그리고 encoder를 거친 CLS token을 linear layer를 거쳐 global feature용 256차원으로 변환해줍니다.
또한 뒤에서 두번째 layer(penultimate)에서 뽑은 patch tokens을 local feature용 128차원으로 변환해줍니다.
(local feature를 256이 아닌 128차원으로 뽑은 이유는 연산과의 trade-off 때문입니다)
global feature: CLS[B, 1, 768] => [B, 1, 256]
local feature: patch tokens[B, N, 768] => [B, N, 128]
4. Reranking Transformer Module
이 부분이 핵심이라고 생각합니다. 결국 reranking 과정은 local한 level에서 판단을 해야하는데, database와 query의 semantic정보(db에는 없는 차량이 나타나는 경우 등)가 다르거나, 환경(시간대, 밤낮)이 다른 경우를 다루기 위한 방법을 R2former는 matching을 이용하여 해결합니다. 물론 기존의 알고리즘적 방법론이 아닌 transformer를 이용한 module을 제시하여 해결합니다. 자세히 알아보겠습니다.
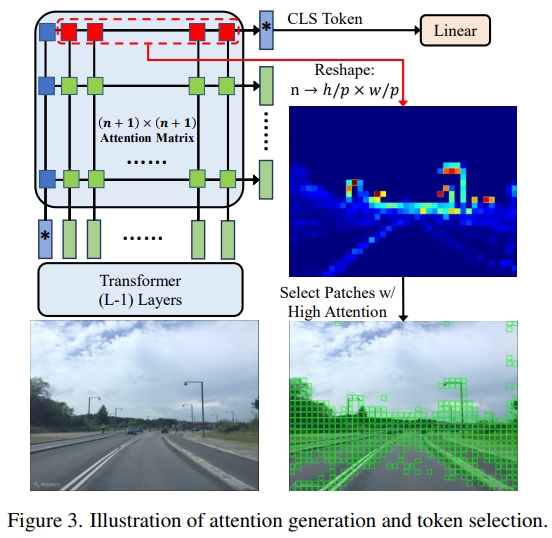
640×480의 이미지가 있고, 한 patch가 16×16이라면 1200개의 patch가 생깁니다. 저자는 patch들 중 일부만 의미있는 정보를 담고 있다고 주장합니다. 기존 연구들은 모든 scale의 local feature를 다 쓰거나, 추가 module을 이용해서 attention map을 만들었지만, 저자는 기존 attention map의 topK만 쓰는 방법을 통해, 더 간단하고 성능도 잘 나오는 방법을 택했습니다.
1200개의 patch와 CLS token 1개의 상관관계는 스스로 내적해서 (1200+1) x (1200+1)의 correlation matrix로 표현할 수 있습니다. 하지만, global retrival에서 CLS token의 정보를 이용해서 retrival을 진행했던 점을 생각하면, CLS token이 집중하는 곳이 global context에 기여하는 token임을 알 수 있습니다. 따라서 CLS token 기반 500개의 patch를 뽑고, 각 patch마다 x,y좌표, attn value을 추가로 더하여 131(128+3)차원으로 저장합니다.
이제 뽑은 patch들과 정보를 가지고 reranking을 진행합니다.
기존 RANSAC과 같은 geometric verification은 positional value만 사용하기에, R2former는 positional value에 attention value, correlration을 같이 고려해줍니다. 위에서 뽑은 500개의 token에 대해 각 좌표, positional embedding, attention value, cosine similarity를 계산한 500x500x7의 correlation matrix를 만듭니다. 연산의 효율을 위해, 각 token에 대해 feature 공간에서 가장 가까운 5개만 선택하여 2개의 500x5x7의 matrix로 축소합니다. 그리고 concat한 후 linear layer을 통해 1000x5x32로 확장시킵니다.
그 후 2개의 transformer block을 통과시켜 최종적으로 reranking score를 뽑아냅니다.
transformer block1은 가장 가까운 5개의 쌍에서 중요한 정보를 CLS token으로 압축하고,
transformer block2는 1000개의 cls token정보를 32차원의 vector로 변환합니다. 그리고 최종적으로 linear head를 거쳐 True/False(같은 장소 여부)로 이진 분류합니다.
5. Experiment
학습 데이터셋은 MSLS(Mapillary Street-Level Sequences)를 사용했습니다.
평가 데이터셋은 MSLS의 Val / Challenge set, Pitts30k, Tokyo 24/7, R-SF, St Lucia.
또한 25m 이내인 경우를 정답으로 처리했습니다.
Comparision with State-of-the-art
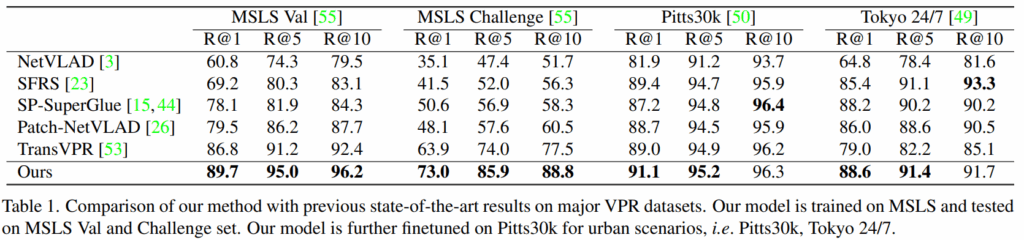
기존의 SOTA들과 비교하였을 때의 결과입니다. Validation set에서는 2.9%의 향상이 있었고, Challenge Set에서는 9.1%라는 큰 향상이 있었습니다. MSLS라는 대규모 데이터셋으로만 학습했음에도 Pitts, Tokyo에서도 SOTA를 달성함을 보아 대규모 데이터로 학습하는 것이 real-world deployment에 횔씬 좋다고 주장합니다.
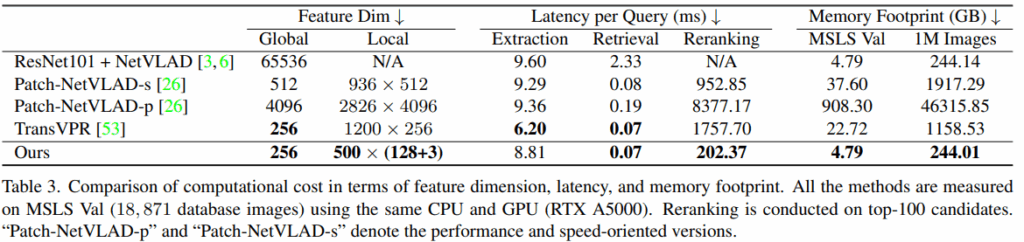
기존 Reranking 방법론들은 주로 RANSAC기반의 Geometric Verification을 사용합니다. CPU에서 작동하는 RANSAC과 다르게 R2Former은 GPU상의 Forward Pass 한번으로 동작하기에 병렬처리에 용이하고 기존 방법론 대비 20배 빠르다고 주장하고 있습니다. 그리고 이미지당 Top-500개의 local feature만 저장하기에 메모리 역시 189배 절감할 수 있다고 주장합니다.
6. Ablation Study
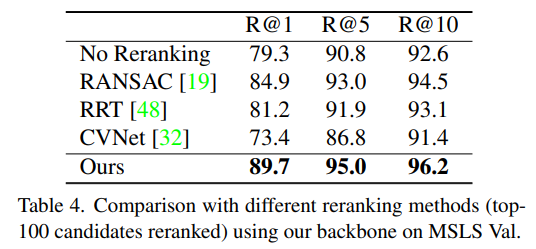
Ablation study를 통해, RANSAC기반의 Geometric Verification보다 횔씬 우수한 성능을 보인다는 것을 증명했습니다. 또한 추론 시간도 RANSAC의 22% 미만으로 뛰어난 성능 뿐만 아니라 추론 속도 역시 좋음을 보였습니다.

다양한 Backbone을 적용해보아 ViT가 가장 높은 성능을 낸다는 사실을 알 수 있었습니다. 그런데 의외로 ViT-Small와 ViT-Base의 성능차이가 Reranking을 적용했을 때 차이가 적었고, 또 Reranking을 적용했을 때는, ResNet50기반의 Backbone도 ViT와의 성능 간극을 상당히 줄인 것도 볼 수 있었습니다.
7. Visualization
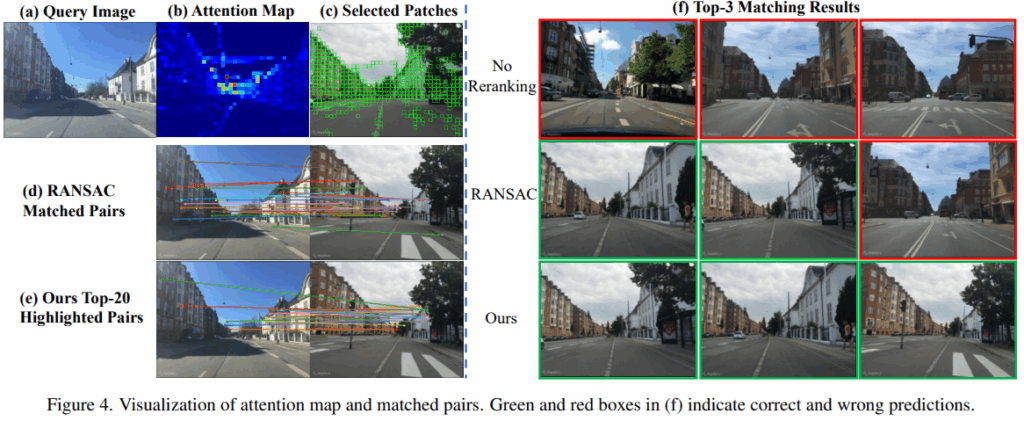
Attention map을 보기 infomative한 부분에 잘 집중하고 있었고, RANSAC처럼 엄격하게 기하학적 부분을 매칭하진 않았지만, 의미 있고 정확한 매칭 쌍을 찾고 있음을 보여주고 있습니다.
안녕하세요 정우님 좋은 리뷰 감사합니다. 해당 연구가 멀티스펙트럴을 사용하지 않는다는 점 빼고는 정우님께서 하시는 연구와 큰 틀에서는 비슷한 연구라는 생각이 듭니다! 읽다가 궁금한 부분이 있어서 질문남깁니다!
Q1.
해당 방법론은 백본으로 ViT를 사용하는데, 서두에서 ViT계열은 global한 receptive field를 가지기에 local한 matching을 바로 진행하기 어렵다고 지적하고 있다고 언급만 하시고 바로 끝나서 헷갈리는데 그럼 흐름이 해당 방법론이 ViT의 단점으로 언급되는 local한 matching에 있어서 보완하고자 한 것이 두번째 컨트리뷰션(Reranking Transformer Module파트)과 직접적으로 연관이 된다고 이해해도 될까요?
Q2.
그리고 두번쨰 질문은 Global Retrival Module파트에서 aggregation이나 keypoint extraction 과정이 없다는 말이 (transformer 모듈만을 통해서 feature들을 뽑아내고 있는 점)이 장점으로 보이는데 사실상 뭔가 CLS를 aggregator로 쓰는 것 같은 느낌인데 그럼 aggregation이 있는게 아닌지가 궁금합니다!(제가 잘못 이해한 부분이 있다면 편하게 말씀해주셔도 됩니다)
Q3.
Global Retrival Module 에서 맨마지막 레이어가 아닌 뒤에서 두번째 layer(penultimate)에서 feature를 뽑는 이유에 대한 저자의 언급이 있었는지 궁금합니다! local feature용을 뽑는다는 관점에서 마지막 레이어 보다는 로컬 정보를 보존하기 위해 뒤에서 두번쨰 레이어에서 fearue를 뽑은 건지가 궁금합니다.
Q4.
500개의 token에 대해 각 좌표, attention value, cosine similarity를 계산한 500x500x7의 correlation matrix를 만든다고 하셨는데 각 좌표, attention value, cosine similarity라면 좌표가 x,y라고 했을 때 500x500x4가 나와야할 거 같은데 7인 이유가 궁금합니다.
Q5.
CLS token 기반 500개의 patch를 뽑는다고 하셨는데 topK=500은 고정인지, 데이터셋,해상도에 따라 바뀌는지 가 궁금합니다, 잘 몰라서 하는 질문일 수도 있는데 1200 중 500이면 꽤 큰 비율같아서 질문드립니다. 아니면 topK=500,feature 공간에서 가장 가까운 5개만 선택과 같은 하이퍼파라미터가 성능을 좌우할 수 있을 것 같은데, 어떤 기준으로 정했는지나 얼마나 이 하이퍼 파라미터가 성능에 얼마나 민감한지에 대한 분석같은 실험은 따로 없었는지 궁금합니다!
감사합니다.
안녕하세요 우현님 좋은 질문 감사합니다.
차례차례 얘기해보겠습니다.
Q1. 네 맞습니다. ViT의 global receptive를 얘기를 해서, 결국 reranking module의 필요성을 강조하고 있습니다.
Q2. 기존 연구들은 Global Retrival에서 일반적으로 GeM pooling과 같은 aggregation 기법을 추가로 사용을 하거나 keypoint extraction을 진행했습니다. 물론 CLS token이 aggregation한 정보를 담고 있는 것은 맞지만 attention 과정에서 자연스럽게 얻어지는 것이지 추가적인 기법을 적용한 점이 아니라는 점에서 aggregation이나 keypoint extraction 과정이 없다고 주장하고 있습니다. 정리하면, 기존 연구들의 GeM pooling이나 keypoint extraction을 사용하지 않고 transformer의 CLS token을 이용했다~라고 얘기하고 있다고 보면 될 것 같습니다.
Q3. 이유는 나와있지 않고, 또한 ablation도 없습니다. 생각을 해봤을땐, ViT를 통과하면서 앞부분 layer는 기하학적 의미를 많이 가지고 뒷부분으로 갈수록 semantic한 정보를 모으게 됩니다. 그렇기에 local한 feature를 위해서, 한칸 앞을 실험적으로 선택한게 아닌가 생각이 듭니다.
Q4. 2개의 이미지여서 각각 (x, y, x’, y’, attn val, 코사인 유사도, positional embedding)이여서 7개가 나옵니다. 제가 positional embedding을 누락했네요 … 🙁
Q5. 이 역시 당연히 저자들은 실험을 해서 선택을 했을 것이라고 생각하지만, ablation으로 나와있지는 않았습니다.