안녕하세요 이번주 x-review 에서는 VLA가 시점 변화에 강건하지 못한 점을 sim 데이터로 해결하되, 그 사이에서 생기는 sim2real gap을 효과적으로 줄이는 연구에 대한 논문을 리뷰해보려고 합니다. 최근 다양한 연구들이 diffusion 기반으로 영상이나 이미지를 생성해 data augmentation을 진행하는데, 시뮬레이션을 통해 학습한 빠르고 효과적인 GAN 방식을 통해 문제 해결을 시도한 것이 포인트라고 생각하시면 될 것 같습니다.
Introduction
최근 VLA와 같이 다중 작업이 가능한 모델들은 발전하고 있습니다. 다만 저자들은 많은 tabletop manipulation 데이터셋들이 고정된 3인칭 카메라로 관측 영상을 수집한다는 점을 지적합니다. 이러한 고정 카메라 시점에 의존한 데이터로 학습된 정책은 카메라 viewpoint shift에 매우 취약해집니다. 저도 체감한 부분이지만 실제로 저자들이 관찰한 바에 따르면, 고정 카메라 데이터셋으로 학습한 로봇 정책은 실행 시 카메라 시점이 조금만 달라져도 성공률이 완전히 0으로 추락하는 현상이 나타났다고 합니다. 연구자들이 데모 수집 중 카메라를 고정해두는 이유는 일관된 시각 관측을 확보하고, 깊이 센서나 모션 캡처 센서의 반복적인 calibration을 피하며, 단순히 실험 세팅을 편하게 유지하기 위함이라고 주장합니다. 저자들은 이렇게 한 시점으로만 모은 데이터는 새로운 시점을 마주하면 일반화하기 어려운데, 이는 카메라 시점 변화가 장면 전체의 시각적 분포를 바꾸기 때문이라고 주장합니다. 결국 모델 입장에서는 새로운 카메라 위치에 맞춰 로봇의 위치를 추정해야 하는 문제가 생겨나고, 이로 인해 완전히 보지 못한 시점에 대한 적응이 매우 힘들어진다는 것입니다.
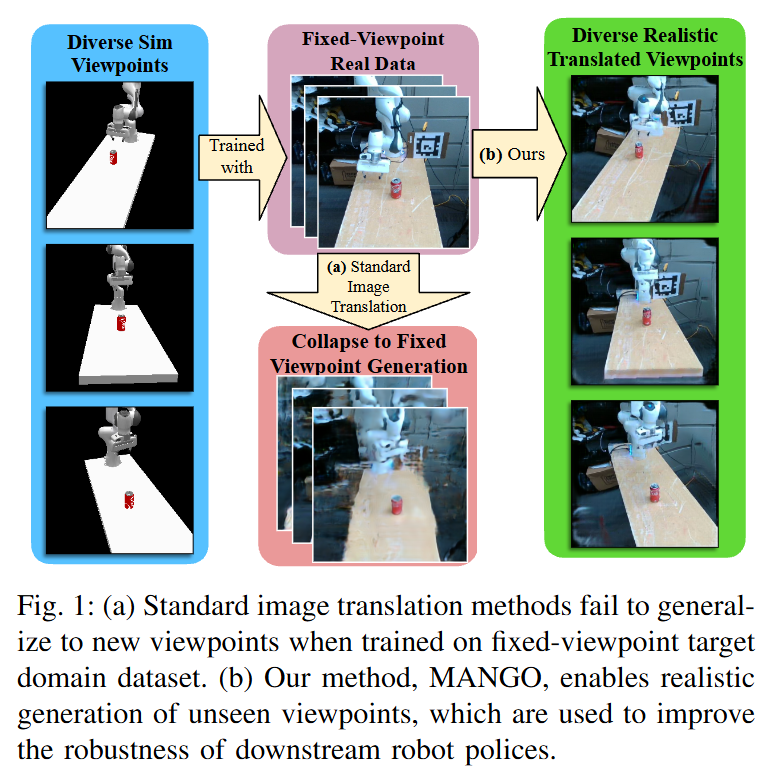
이러한 고정 카메라 데이터의 한계를 극복하기 위해, 저자들은 시뮬레이션 기반 데이터 증강 접근을 제안했습니다. Digital twin 환경에서 다양한 카메라 시점에서 시뮬레이션 데모를 수집한 뒤 시뮬레이션 영상들을 실제 이미지로 변환해주는 transfer 모델을 학습해 sim2real gap을 메우는 Multiview Augmentation with Novel Generated Observations (MANGO)를 제안했습니다. 이름처럼 MANGO는 멀티뷰의 새로운 관측 데이터를 생성하여 데이터셋을 확장하는 방식으로 증강합니다.
다만 이 때 저자들은 증강을 위해 GAN 기반 모델을 사용하는 것이 Diffusion 모델보다 효율적이라고 주장했습니다. 일반적으로 하나의 로봇 시연 데이터셋은 매우 많은 수의 이미지 관측을 포함하며, 저장 및 학습 편의를 위해 이미지 해상도를 낮춰 사용하는 경우가 많다는 점에 주모갷다고 합니다. 예를 들어, 단일 task에 대한 비교적 작은 규모의 로봇 데이터셋이라도 약 150개의 에피소드를 15~30Hz로 기록하면 대략 180,000장 이상의 이미지를 포함하게 됩니다. 이렇게 방대한 데이터셋을 증강하려고 할 때, 현재 저자들이 주장하는 sota 모델인 ZeroNVS를 사용하면 약 435시간이 소요된다고 합니다. 이는 ACT모델 기준으로 동일 데이터로 학습에 사용되는 5시간에 비해 너무 많은 시간이 소요되고, diffusion을 통한 증강은 현실적으로 계산 비용 측면의 병목이 될 수밖에 없다고 합니다. 저자들은 MANGO를 통해 2700배 빠른 증강 속도를 볼 수 있었다고 합니다. 따라서 저자들은 아래와 같이 main contribution 세가지를 꼽았스빈다.
- 새로운 sim2real transfer 모델을 통한 새로운 시점에 대한 이미지를 생성할 수 있는 MANGO 프레임워크 제시
- MANGO로 생성된 데모 영상으로 학습한 로봇 정책이 camera position shift에 대한 강인성이 diffusion 기반의 방법보다도 크게 향상됨을 보임
- 기존의 unpaired image translation 문제를 해결하기 위해 개발된 여러 방법들과 대비하여, 로봇 시연 데이터셋 도메인에서 MANGO가 성공적일 수 있었던 이유 분석
Related Works
Visual Sim2Real for Robotics
저자들은 로보틱스 연구에서 시뮬레이션이 널리 활용되고 있지만, 시뮬레이션 데이터를 실제 로봇 정책에 적용하기 위해서는 visual sim2real gap을 줄여야한다고 주장했습니다. 이를 위해 시뮬레이터의 사실성을 극단적으로 높이는 접근법이 있으나 이는 비용이 크고 한계가 존재합니다. 또한 조명이나 질감 등을 무작위로 바꾸는 Domain Randomization 역시 적절한 범위를 결정하기 어렵고 방해에 대한 견고함을 얻는 대신 성능을 희생해야 하는 한계가 있다고 합니다. (Domain Randomization 연구들에서 성능 하락을 보진 못 한것 같은데 한 번 생각해봐야 할 문제인 것 같습니다.) 이에 대한 대안으로 Image-to-Image Translation 방식이 제안되었다고 합니다. MANGO는 기존의 translation 모델들과 다르게 특정 포인트 (grasping, action consistency 등) 만을 노리지 않고 agnostic한 특성을 지녀 하나의 모델로 완성도 있는 translation이 가능하다고 합니다. 또한 diffusion 기반의 translation은 오히려 스타일을 엄격히 규정하는 데 불리할 수 있, MANGO에 적용된 segmentation 기반 InfoNCE 손실 함수는 GAN뿐만 아니라 다양한 이미지 변환 아키텍처에 이론적으로 적용 가능하다는 점을 어필했스빈다.
Robot Policy Viewpoint Invariance
로봇 정책이 다양한 카메라 시점 변화에도 일반화될 수 있는 시점 불변성을 확보하는 것 또한 중요한 task이고, RoboNet이 다중 시점 학습의 유효성을 처음으로 입증했다고 합니다. Multi-View masked world model은 시점 불변 인코더를 통해 인상적인 견고함을 보였으며, MoVie는 테스트 시점에 새로운 시점으로 인코더를 adaptation시키는 방식을 취했다고 합니다. 하지만 MANGO는 이러한 테스트 시점의 적응이나 학습 외의 추가적인 실제 환경 이미지를 요구하지 않는다는 차별점이 있다고 합니다. 또한 VISTA와 같이 3D priors를 활용해 새로운 시점을 생성하는 방식은 시뮬레이션 기반의 새로운 궤적 생성이 어려워 인간의 시연 데이터에 의존해야 하고, 높은 리소스를 소모한다는 점을 언급했습니다. 최근의 3D Diffusion Policy나 Adapt3R 등의 연구들이 calibrated 다중 RGBD 센서를 사용하여 3D 장면을 구성함에도 불구하고 여전히 특정 시점 변화에 취약하거나 복잡한 센서 구성을 요구하는 것과 달리, MANGO는 단일 RGB 카메라만으로도 충분한 시점 견고성을 달성할 수 있음을 강점으로 제시했습니다. 다만 여기서 robosplat을 언급하지 않은것은 좀 의외였습니다. 카메라 시점 변화에 굉장히 강인함을 보여서 인상깊었었는데,,
Method
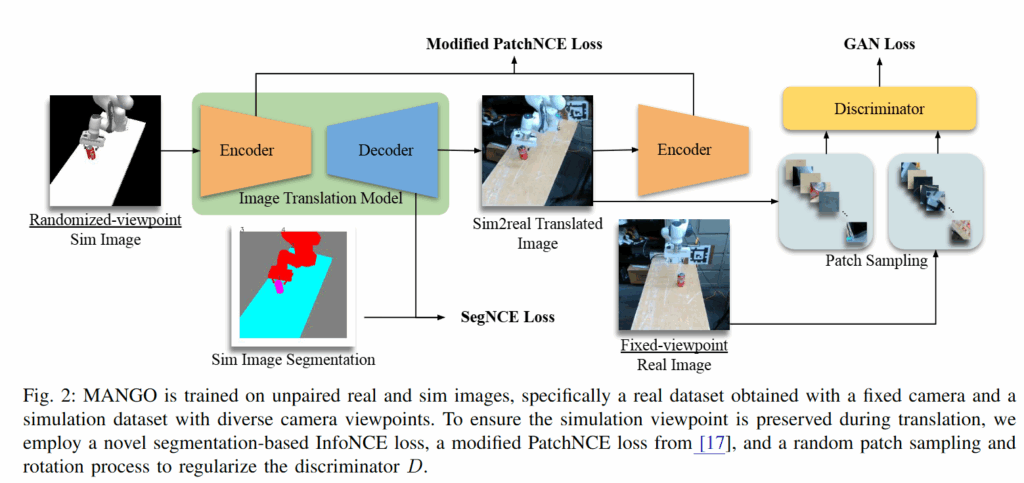
Image to Image Translation
우선 앞서 말했듯 저자들은 MANGO를 simulation에서 real로 시각적 관측을 변환하기 위한 unpaired image-to-image translation 방법으로 제안했습니다. 고정된 시점에서 촬영된 소량의 real image dataset 만을 사용해 simple digital twin에서 수집한 다양한 camera viewpoint의 simulation observation을 현실적인 unseen viewpoint로 정확하게 translation 하는 unpaired image-to-image를 하는 것을 목표로 삼았다고 합니다.
저자들은 unpaired image-to-image translation 문제를, domain A에서 domain B로 이미지를 변환하되 paired dataset 없이 학습하는 문제로 정의했습니다. 이때 두 개의 분리된 데이터셋 D_A와 D_B를 사용하며 D_A는 simulation 이미지, D_B는 real-world 이미지로 구성되고, 일반적으로 ∣DA∣>∣DB∣인 설정을 사용한다고 합니다. 또 저자들은 Contrastive Learning for Unpaired Image-to-Image Translation 에서 제안된 unsupervised 방식으로 접근했다고 합니다. Unsupervised로 접근한 이유는 real-world dataset에 대해 simulation 이미지가 매핑되어야 할 정답 이미지나 레이블이 존재하지 않기 때문이라고 합니다. 찾아보니 최대한 input domain과 구조적으로 유사한 target domain 이미지를 생성할 수 있어서 선택한 것 같습니다. 이 때 저자들은 image translation 모델이 style은 target domain에 맞게 바꾸되, content는 보존해야 한다고 설명했습니다. 이를 위해 MANGO는 target domain의 style을 학습하기 위해 GAN architecture를 사용하며, content preservation을 위해 앞서 말한 Contrastive Learning for Unpaired Image-to-Image Translation InfoNCE loss를 기반으로 하되, scoring function을 수정한 PatchNCE loss를 사용한다고 설명했습니다. 추가적으로 저자들은 generator feature를 segmentation 정보로 정렬시키는 segmentation-based InfoNCE loss를 새롭게 제안했습니다.
파이프라인은 Figure 2와 같이, unpaired real (고정뷰), sim (다양한 카메라뷰 + segmentation map) 이미지들을 사용하고, simulation에서의 viewpoint 정보가 translation 과정에서 유지되도록 하기 위해 segmentation-based InfoNCE loss, modified PatchNCE loss, 그리고 discriminator를 정규화하기 위한 random patch sampling 및 patch-wise random rotation을 사용한다고 합니다. 아래는 이해를 위해 저자가 활용하는 InfoNCE loss 식에 대해 GPT가 설명해준 내용인데 참고하시면 좋을 것 같스빈다.

Style Loss

저자들은 생성된 이미지가 target domain의 style을 따르도록 하기 위해 standard GAN loss를 사용했습니다. 이때 generator를 G, discriminator를 D로 두고, GAN objective를 위 식과 같이 정리했습니다. 저자들은 CycleGAN이나 CUT과 같은 image translation GAN들이 D_B에 포함된 이미지들이 공유하는 공통적인 속성을 target domain의 style로 학습한다고 합니다. 그러나 MANGO에서 사용하는 로봇 데이터셋에서는 이미지 간 차이가 주로 robot pose와 object pose에 의해 발생하며, background나 tabletop과 같은 요소는 거의 동일하다고 합니다. 이로 인해 naive한 discriminator가 반복적으로 등장하는 시각적 패턴을 암기하게 되고, generator에게 이를 그대로 재현하도록 강제할 수 있다고 합니다. 이를 완화하기 위해 저자들은 Pix2Pix에서 제안된 PatchGAN 아이디어를 채택하여 discriminator가 이미지 전체가 아니라 local patch만을 보도록 설계했다고 합니다. 또한 저자들은 discriminator에 입력되는 patch의 위치를 무작위로 샘플링하고, 각 patch에 대해 random rotation을 적용했다고 합니다. 이를 통해 discriminator는 특정 viewpoint에 종속된 global 구조를 학습하지 못하게 되며, 결과적으로 보지 못한 viewpoint에 대해서도 style을 강제할 수 있는 강하게 정규화된 discriminator가 된다고 하네요.
Content Loss
Content Loss는 modified patch NCE loss와 segmentation-based NCE loss로 이루어져있습니다. 먼저 저자들은 PatchNCE loss를 source domain 이미지 d∈D_A와 translated image d^=G(d)의 encoder feature 사이의 InfoNCE loss로 정의했습니다. 입력 이미지 d를 encoder에 통과시켜 여러 layer에서 feature map을 얻고, layer l에서 샘플링된 feature 집합을 Z_l로 정의했습니다. Translated image d^ 역시 encoder에 통과시켜 Z^l를 얻으며, 이때 각 집합에서 동일한 spatial index에서 샘플링됩니다. 저자들은 layer l에서 i번째 feature i에 대한 InfoNCE loss를 다음과 같이 정의했습니다. ρ는 cosine similarity를 활용했다고 합니다.
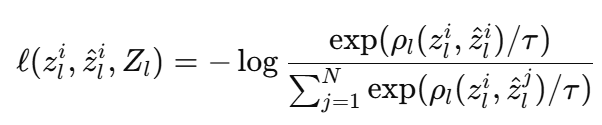
전체 PatchNCE loss는 아래와 같이 정의했습니다. 다만 해당 formulation이 동일한 spatial location의 feature 쌍은 positive이고 나머지는 negative라는 가정을 따르지만 로봇 데이터셋에는 background와 tabletop처럼 반복되는 영역이 많고, simulation 데이터에서는 이러한 영역이 동일한 pixel value를 가지기 때문에, 서로 다른 위치의 feature들이 매우 유사해지는 false negative 문제가 발생한다고 합니다. 이를 완화하기 위해 저자들은 modified scoring function을 도입했습니다. Negative sample의 cosine similarity가 threshold 클 경우, 해당 score에 특정 숫자 (0~1 사)를 곱해 penalty를 완화합니다. 정리하자면 아래 수식은 simulation 이미지와 그 translated 이미지에서 같은 위치의 feature들은 가깝게, 다른 위치의 feature들은 멀어지도록 generator의 feature 표현을 학습시키는 Patch 단위 contrastive content preservation loss라고 할 수 있을 것 같습니다.
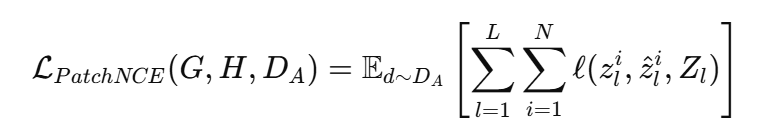
Segmentation NCE Loss
저자들은 simulation 환경에서는 각 이미지에 대한 ground-truth segmentation map을 얻을 수 있다는 점을 활용했다고 합니다. Object boundary가 translation 과정에서 유지되는 것이 object-centric manipulation policy 학습에 중요하기 때문에 더 효과적이라고 합니.
각 feature z_i∈Z 는 대응되는 segmentation label y_i∈{1,…,C}를 가지며, feature map 해상도가 낮을 경우 segmentation map을 nearest-neighbor downsampling으로 맞춰서 진행했다고 합니다. 저자들은 SegNCE loss를 아래와 같이 정의했습니다.
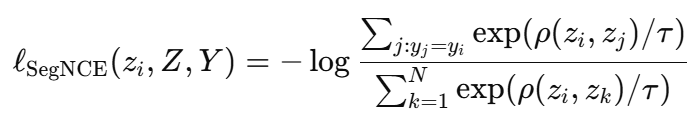
저자들은 이 formulation에서 동일한 segmentation class에 속한 모든 feature가 positive sample이 되며, target distribution은 uniform distribution이라고 합니다. Ground-truth segmentation을 사용하기 때문에 false negative가 발생하지 않아, scoring function ρ에 cosine similarity를 그대로 사용한다고 설명했습니다. 전체 SegNCE loss는 아래와 같이 정의됩니다. 이 수식은 simulation 이미지에서 같은 segmentation class에 속한 모든 patch feature들이 서로 가깝게 모이고, 다른 class의 feature들과는 멀어지도록 generator의 feature 표현을 학습시키는 segmentation-aware contrastive content loss 입니다.

학습시에는 아래와 같이 generator의 loss를 사용한다고 합니다. Discriminator의 경우 GAN loss의 negative로 사용합니다.
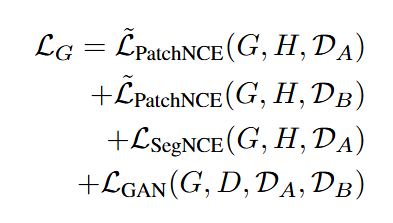
Experiments

저자들은 MANGO가 고정 카메라로 수집된 real-world dataset만을 사용해 학습되었음에도, 보지 못한 camera viewpoint에서 강인한 로봇 정책을 학습할 수 있는지를 검증하고자 설계했습니다. 이를 위해 실제 로봇 환경과 시뮬레이션 환경을 함께 사용했으며, image translation 성능뿐 아니라 최종 downstream task인 robot manipulation policy에서의 SR을 평가 지표로 삼았습니다. 실험 전반에서 고정된 single external RGB camera로 수집된 real-world demonstration dataset을 사용했으며, 시뮬레이션에서는 다양한 camera pose에서 동일한 task를 수행하는 synthetic demonstrations를 생성했습니다. 이후 MANGO를 이용해 simulation image를 real-world style로 변환하고, 이 변환된 이미지들을 사용해 로봇 정책을 학습했습니다. 실험을 통해 답하고자 하는 질문은 아래와 같습니다.
- MANGO가 기존 unpaired image translation 방법들보다 새로운 viewpoint를 보존한 채 현실적인 이미지를 생성할 수 있는가?
- MANGO를 통해 학습한 모델이 실제로 unseen camera viewpoint에서 성능이 좋은가?
- MANGO를 통해 학습한 모델이 기존의 이미지 기반 augmentation이나 Domain Randomization에 비해 성능이 좋은가?
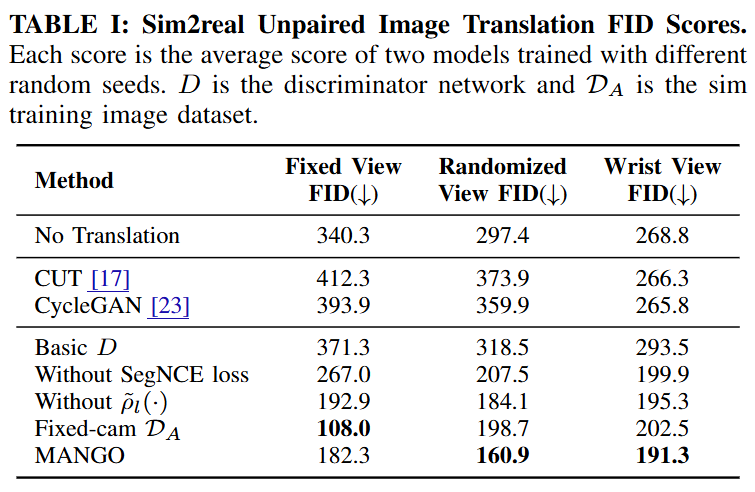
Table 1을 보면 일단 MANGO는 Randomized View test set에서 가장 낮은 FID를 보여주었습니다. 저자들은 특히 discriminator 설계가 모든 test set에서 FID에 가장 큰 영향을 미쳤다고 설명했습니다. 또한 SegNCE loss를 제거하거나 modified PatchNCE의 scoring function 을 사용하지 않을 경우, FID가 크게 악화됨을 보였습니다. 이를 통해 저자들은 viewpoint-preserving translation에는 SegNCE, modified PatchNCE, 그리고 강하게 regularized된 discriminator가 모두 필수적이라고 결론지었습니다. 저자들은 Table 1의 FID 값이 일반적인 computer vision benchmark보다 높은 이유로 robotics scene이 out-of-distribution이며 test set 규모가 작기 때문이라고 합니다.
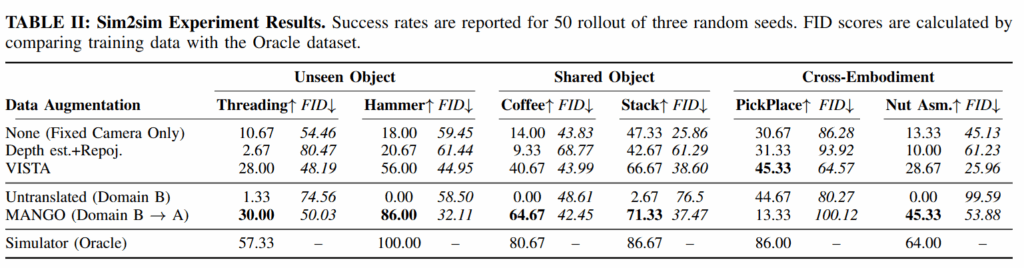
또 아래 Table2, 4를 보면 다양한 세팅에서 시각적인 품질 뿐만 아니라 실제로 10배이상 파라미터가 많은 VISTA 방법으로 학습을 진행했을 때 보다 imitation learning의 성능이 shifted cam에서 좋은것을 볼 수 있습니다. VISTA는 기존의 diffusion 기반 view point augmentation 방법론입니다. 이미 Robosplat이 이겼었는데 왜 robosplat과의 비교는 없는지 아쉽습니다.. 코드가 아직 없는건가

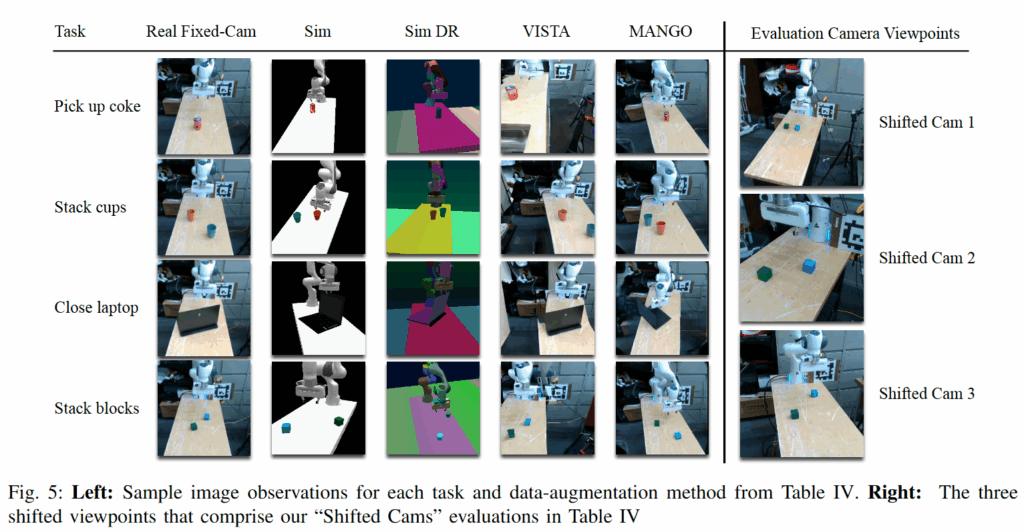
특히 위의 table 4와 fig 5는 real world 환경에서의 실험 내용을 담았습니다. 저자들은 MANGO의 성능을 검증하기 위해 pick up coke, stack cups, close laptop, stack block의 네 가지 manipultaion을 수행했습니다. 저자들은 모든 작업을 수행하기 위해 단일 이미지 변환 모델을 학습시켰으며, 이때 약 6만 개의 시뮬레이션 데이터와 약 3만 5천 개의 고정 시점 실제 데이터를 활용했다고 합니다. policy는 ACT를 사용했습니다. 저자들은 RLBench를 활용해 생성한 디지털 트윈 시연 데이터를 MANGO로 변환하여 합성 데이터를 만들었으며, 이를 150개의 teleoperation 데이터와 co-training 시켰다고 합니다. 특히 ACT를 선택한게 사전 학습이나 언어 조건의 영향 없이 오직 이미지 데이터의 품질이 정책 성능에 미치는 효과를 독립적으로 확인하기 위함이라고 합니다.
결과를 보면 우선 data augmentation 없이는 shifted cam에서 성능이 급감하는 것을 볼 수 있습니다. Sim에서의 DR은 제한적인 상황에서만 성능 증가를 보여주는 sim2real gap을 보이는 반면, visual gap을 줄인 MANGO는 일관되게 성능이 향상하는 것을 볼 수 있습니다. VISTA의 경우 성능은 준수하지만 모델 크기가 크고 inference 시간이 길며, 현실의 demo를 다른 view로 바꿔주는 것이기 때문에 trajectory증강등 시뮬레이션을 활용한 데이터 분포 확장에 유리하지 않다는 점을 어필했습니다.