이번 리뷰 논문은 요즘 로봇 러닝 분야에서 눈에 띄는 성과를 보이고 있는 GigaAI에서 출판한 논문입니다. GigaAI에서 수행 중인 연구 중에서 가장 대단한 연구라고 생각하는 기법을 들고 왔습니다. NVIDIA의 COSMOS와 대항되는 기법이라고 보시면 됩니다.
+ 내용이 너무 많아서 part 1: GigaWorld-0-Video와 part 2:GigaWorld-0-3D로 구성하여 리뷰를 진행합니다.
Intro
Embodied AI 연구는 지능형 에이전트가 현실 세계와 상호작용하는 능력을 구현하는 것을 목표로 하지만, ‘비용이 많이 들고 확장하기 어려운 실제 데이터 수집 문제’라는 근본적인 난관에 직면해 있습니다. 로봇이 현실에서 데이터를 수집하는 과정은 하드웨어, 안전, 인력 비용의 제약으로 인해 그 규모와 다양성을 확보하기가 매우 어렵습니다. 이러한 데이터 병목 현상을 해결할 유망한 대안으로 World Models이 부상하고 있습니다. 월드 모델은 현실 세계의 동역학, 외형, 공간 구조를 모방하는 고충실도 시뮬레이터로서, 제어 가능한 조건 하에서 고품질의 합성 데이터를 대규모로 생성하는 ‘데이터 엔진’의 역할을 수행할 수 있습니다.
해당 논문에서 제시된 GigaWorld-0는 바로 이 ‘데이터 엔진’의 개념을 VLA 학습을 위해 설계된 월드 모델 프레임워크입니다. GigaWorld-0는 두 가지 핵심 구성 요소의 시너지를 통해 이 목표를 달성합니다.
첫째, 사실적인 영상 생성을 담당하는 GigaWorld-0-Video는 대규모 영상 생성 기술을 활용하여 외형 (e.g. texture, material, light), 시점, 행동 의미를 정밀하게 제어하며 풍부하고 일관된 2D observation data를 생성합니다. 둘째, GigaWorld-0-3D는 3D 생성 모델링, 3DGS 재구성, 미분 가능한 물리 시스템 식별 등을 결합합니다. 이는, 생성된 데이터의 시점 간의 공간적 일관성을 보장하고, 객체의 강성과 변형성을 모델링하여, 충돌, 중력과 같은 물리적 제약 조건을 갖출 수 있도록 합니다.
이 논문의 가장 중요한 주장은 GigaWorld-0가 생성한 합성 데이터만으로 학습된 VLA 모델(GigaBrain-0)이 어떠한 실제 로봇 상호작용 데이터 없이도 현실 세계의 물리적 로봇 환경에서 뛰어난 작업 성공률을 달성했다는 점입니다. 이는 Embodied AI 연구의 데이터 수집 패러다임을 근본적으로 바꿀 수 있는 잠재력을 시사합니다.
++ 해당 기법이 이전 기법들과의 차별 포인트를 Video + 3D generation models의 통합 데이터 엔진이라는 점이라고 밝히네요. 흠… 이는 COSMOS도 지향하는 바이기에 COSMOS랑 차별 포인트를 제시해주면 좋았을 텐데… 아쉽네요
Method
GigaWorld-0 Models
GigaWorld-0는 앞선 다룬 바와 같이 사실적인 영상을 생성하기 위한 GigaWorld-0-Video와 물리적, 기하하적 제약 을 준수하기 위한 GigaWorld-0-3D로 구성이 됩니다. 해당 기법들은 구체적으로 아래와 같은 expert로 구성됩니다.

GigaWorld-0-Video는 Tab 1에서 보이는 바와 같이 4가지 생성 모델로 구성됩니다. 이들 중, GigaWorld-0-Video-Dreamer는 Image-text-to-video (IT2V) generation을 위한 Mixture-of-Experts (MoE)로 large-scale embodied interaction data로 학습된 Video Foundation Model 역할을 합니다. 해당 모델을 기반으로 GigaWorld-0-Video-AppearanceTransfer, GigaWorld-0-Video-ViewTransfer, GigaWorld-0-Video-MimicTransfer라는 세 종류의 Post-training adaptation models은 각각 appearance (e.g. texture, lighting), camera viewpoints, action modalities에 대한 일반화를 가지기 위해 전용 controllable branch를 이용합니다.
특히, GigaWorld-0-Video-MimicTransfer는 사람의 1인칭 조작 시연 영상을 로봇이 실행 가능한 궤적으로 변환하여 cross-embodiment generalization이 가능하도록 합니다.
+ 또한, 파이프라인 효울성을 위해 multi-view video generation, FP8-precision training acceleation, denoising-step distillation, FP8-efficient inference를 추가했다고 합니다.
GigaWorld-0-3D에서는 모듈식 파이프라인을 통해서 물리적으로 기반이 잡힌 3D 장면을 구축합니다. GigaWorld-0-3D-FG는 3D generation model을 통해서 foreground assets을 생성합니다. GigaWorld-0-3D-BG는 3DGS를 사용하여 배경 환경을 재구성합니다. GigaWorld-0-3D-Phys는 상호 작용 가능한 객체의 물리적 틍성을 모델링하고 로봇 팔에 대한 미분 가능한 식별?을 수행하도록 한다고 합니다. GigaWorld-0-3D-Act는 실행 가능한 팔 모션을 계산합니다.
GigaWorld-0-Video
체화된 AI 모델의 일반화 성능은 학습 데이터의 시각적 품질과 다양성에 크게 좌우됩니다. GigaWorld-0-Video는 기존의 대규모 영상 생성 모델들이 모델 파라미터를 확장하는 데 집중했던 것과 달리, MoE 아키텍처, sparse attention, FP8 precision training 등을 통해 효율성과 제어 가능성을 극대화하는 차별화된 접근 방식을 채택했습니다.
GigaWorld-0-Video-Dreamer
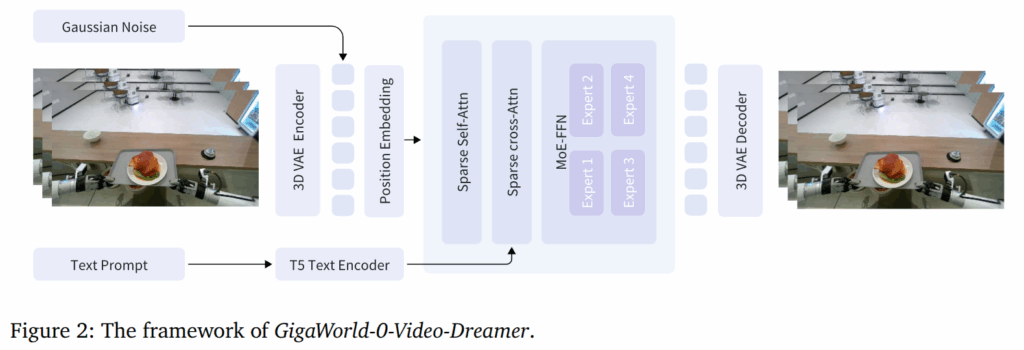
이 모델은 GigaWorld-0의 ‘Foundation Video Generation Model’ 역할을 합니다. MoE 아키텍처를 통해 모델이 영상의 각기 다른 의미 영역에 동적으로 특화되도록 하며, 희소 어텐션과 FP8 정밀도 학습을 적용하여 계산 비용과 메모리 요구량을 크게 줄였습니다. 이를 통해 대규모 데이터셋에 대한 효율적인 학습이 가능해졌습니다.
Model Details. 해당 모델은 IT2V generation model로 전반적인 구조는 Fig 2에서 볼 수 있습니다. 해당 모델은 Flow-matching 모델을 기반으로 합니다. 해당 기법의 generative process는 아래와 같습니다.
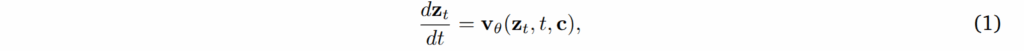
여기서 z_t 는 time t에 대한 latent feature로 c는 text와 image conditioning을 표현합니다. v_{\theta} 는 해당 모델의 velocity parameter입니다. 입력 정보에 대한 표현력을 위하여 3D-VAE architecture (Wan 2.1)를 이용하며, 비디오를 시간 방향으로 4배, 높이와 너비 방향으로 8배 압축하여 16 채널의 latent feature로 변환합니다. Patchification (1x2x2) -> 압축된 데이터는 다시 patch 입력. 그 다음에 3D Rotary Position Embedding (3D RoPE)를 이용하여 비디오의 프레임 간 시간적 순서와 화면 내의 공간적 위치 정보를 모델에게 효율적으로 전달합니다. text conditioning은 T5 encoder를 이용합니다.
GigaWorld-0-Video-Dreamer의 모델 본체는 sparse attention mechnisms을 얹은 DiT로 구성됩니다. 또한, ㄹFFN 블록에 MoE를 통합합니다.
+ DeepSeek-V2와 달리 shared expert를 사용하지 않으며, 대시, N_r = 4개의 routed experts를 구성하고, 토큰 당 K_r = 2의 experts를 별도로 구성한다고 합니다… 해당 설계는 중복된 파라미터 공유 없이 서로 다른 의미론적인 영역 전반에 걸쳐 dynamic specialization를 가능하게 한다고 합니다… 또한, MoE load balance를 보장하기 위해서 DeepSeek-v3의 complementary balance loss를 사용한다고 합니다.
++ 사실 무슨 말인지 저도 모르겠습니다… 정보 공유 차원에서 정리합니다. 하하….
Function as Data Engine. 해당 모델은 단순한 비디오 생성 모델을 넘어, VLA을 학습시키기 위한 고품질 데이터를 스스로 생성하는 데이터 엔진 역할을 수행하며, 이를 위해서 비디오 내에서 로봇의 움직임을 역으로 추정하는 GigaWorld-0-IDM (Inverse Dynamics Model)을 같이 제시합니다. (대략적인 동작 방식은 아래의 Fig 12-13에서도 볼 수 있습니다.)

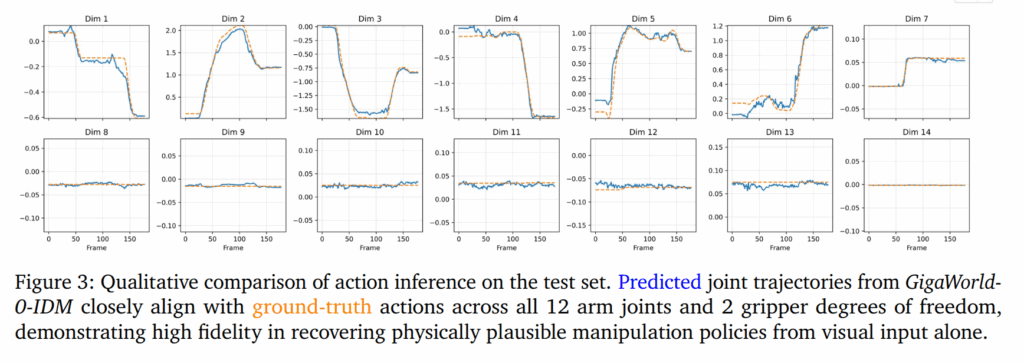
동일한 초기 프레임에서 시작하더라도 서로 다른 text prompt가 입력된다면 다른 형태의 generated video sequence V를 생성 할 수 있습니다. 그럼 이를 기반으로 GigaWorld-0-IDM f_IDM은 joint-angle trajectory를 예측합니다. 이렇게 얻은 비디오-로봇 액션 쌍은 실제 로봇을 직접 구동할 필요 없이 대규모 VLA 모델 학습에 사용 가능합니다. GigaWorld-0-IDM의 성능은 fig 3에서 볼 수 있습니다.
GigaWorld-0-Video-AppearanceTransfer
해당 모델은 VLA 모델이 실제 환경에 배포될 때 마주하는 시각적 도메인 격차라는 고질적인 문제를 해결하는 것에 집중합니다. 이 기능은 텍스트 프롬프트만으로 영상 속 객체의 텍스처, 재질, 조명을 자유롭게 편집하여, 제한된 실제 데이터의 시각적 다양성을 폭발적으로 증가시킵니다. 이를 통해 모델은 다양한 조명이나 재질 변화에 대한 강건성을 확보하게 됩니다.
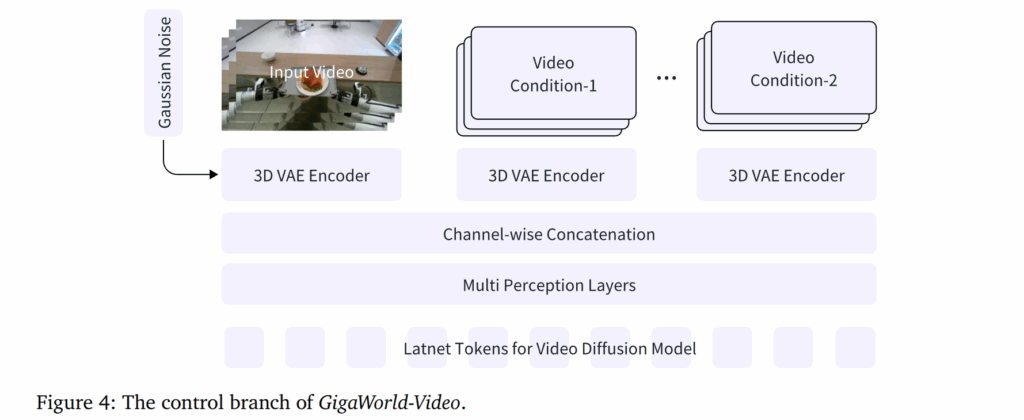
Model Details. GigaWorld-0-Video-AppearanceTransfer는 자연어 지시로 real-world video sequences에 대한 texture, material, illumination를 geometric and motion consistency를 지키면서 에디팅하는 것을 목적으로 합니다. 구체적으로 해당 모델은 사전 학습된 GigaWorld-0-Video-Dreamer를 기반으로 하며, lightweight control branch를 확장하여 구축됩니다. fig 4에서 보이는 바와 같이 ControlNet은 높은 parameter overhead 때문에 사용하지 않았다고 합니다. 대신, parameter-efficent한 control mecchnism을 도입했다고 합니다. 해당 방법은 복제 대신에 Channel-wise Concatenation을 사용하는 방식을 이용합니다.
+ 이는 base model이 MoE를 사용하는 경우에 문제가 된다고 합니다. MoE layers를 복제하면 model size가 drastically increase한다고 합니다.
Multiple video conditions (e.g. depth, surface normals)이 주어졌을 때, 먼저 3D VAE를 이용하여 latent feature로 변환합니다. 해당 control latent는 Diffusion-process에 활용되는 noise latent와 함께 Channel-wise Concatenation을 수행합니다. 이렇게 결합된 텐서는 channel-compressed MLP layers를 통해 Transformers blocks에 적합한 최종 latent feature로 가공 됩니다.
해당 모델은 appearance control을 위해서 텍스트 프롬프트를 활용하여 질감, 재질, 조명과 같은 전경 및 배경 속성을 독립적으로 조작해야 합니다. 이를 위해서는 기하학적 사전 정보를 요구합니다. 실제 영상 또는 시뮬레이션 영상에서 깊이 및 normal map을 추출하기 위해서 VideoDepthAnything과 LOTUS를 사용합니다. 이로부터 얻은 map들은 정규화하고, 3채널 입력으로 변경합니다. EMMA와 RoboTransfer에서 정의된 절차를 따라, 3D VAE에 의해 인코딩 됩니다.
Function as Data Engine. GigaWorld-0-Video-AppearanceTransfer는 다양한 시각적 일반화를 달성하기 위한 데이터 엔진 역할을 합니다. 이는 아래의 fig 14, fig 7 볼 수 있습니다. 아래의 그림에서 볼 수 있는 바와 같이 real2real 및 sim2real에서의 appearance transfer 모두 지원합니다. 이를 통해 실제 세계 혹은 시뮬레이션의 로봇 데이터에서 텍스트 프롬프트만으로 사용자가 지정한 텍스쳐, 색상, 조명 조건을 갖춘 사실적 변형을 모델이 합성할 수 있습니다. 해당 기능은 추가적인 실제 세계 혹은 시뮬레이션 렌더링 없이도 시각적으로 다양한 외관적 다양성이 갖춘 대규모 데이터 생성이 가능하도록 하여, VLA 모델이 외형 변환에 강건성을 크게 향상 시킬 수 있다는 잠재력을 부여합니다.

GigaWorld-0-Video-ViewTransfer
단일 시점 데이터만으로 학습된 모델이 다른 시점에서는 성능이 저하되는 시점 일반화 문제를 정면으로 다룹니다. 이 기능은 단일 시점 영상으로부터 완전히 새로운 시점의 영상과 그에 맞는 로봇 행동을 생성함으로써, 고가의 다중 카메라 설비 없이도 풍부한 공간 정보를 학습시켜 데이터 수집 비용을 극적으로 절감하고 모델의 시점 일반화 성능을 획기적으로 개선합니다.
Model Details. 월드 좌표계 W_A에서 작동하는 로봇이 있을 때, 해당 로봇은 egocentric video V_A와 로봇 베이스에 상대적으로 표현된 end-effector poses T^{ee->base}를 가지고 있을 수 있습니다. 저자는 로보 베이스가 재배치된 W_A -> W_B로 월드 좌표계가 변경된 새로운 observation V_B를 생성하는 것을 목적으로 합니다. 새로운 시점의 영상을 생성할 때, 로봇 팔의 움직임을 물리적으로 일관되어야 합니다. 이를 위해서 아래와 같은 관계를 유지하도록 합니다.
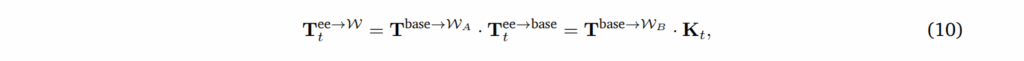
여기서 K_t는 W_B 내에서 재배치된 베이스에 상대적인 새로운 ee pose를 나타냅니다. 이를 풀면 다음과 같습니다.
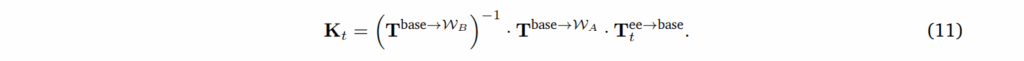
합성된 video V_B는 새로운 뷰 포인트와 변경된 action sequence를 일관되게 가져야만 합니다.
GigaWorld-0-Video-ViewTransfer는 사전 학습된 GigaWorld-0-Video-Dreamer를 기반으로 하여 dual-condition control branch를 통해 학습됩니다. viewpoint 변화로 인한 3D consistency를 가지기 위해서, control signal을 2가지 요소~(1) background 3D consistency: video condition-1, (2) robot arm 3D consistency: video condition-2.~로 나눕니다.
짝을 이룬 V_A, V_B를 사용하는 것을 어렵기 떄문에 self-supervised training pair를 생성하기 위해서, double-re-projection strategy를 이용합니다. 이는 Fig 5에서 볼 수 있습니다.

video condition-1을 위해서 MoGe를 이용하여 먼저 W_A 에서의 스케일링된 깊이를 추정하여 W_B로 warp하고 다시 원본 뷰로 다시 투영합니다. 재투영된 비디오는 입력 조건으로 사용되며, 원본 V_A는 GT로 활용합니다. 움직이는 로봇으로부터 장면 기하학을 분리하깅 위해서 warping 과정 중에는 로봇팔을 마스킹(~SAM2) 합니다.
video condition-2의 경우, 변화된 액션 시퀀스 K를 시뮬레이터 내에 렌더링하여 fig 5와 같은 arm-only video를 생성합니다. 해당 정보는 명시적인 3D guidance를 제공합니다.
모델은 두 video condition을 받아 V_A를 예측하도록 비디오 생성 학습이 진행됩니다. 해당 기법은 EgoDemoGen을 따릅니다…
Function as Data Engine. GigaWorld-0-Video-ViewTransfer는 scalable viewpoint augmentation engine로 작동합니다. Fig 15에서 보이는 바와 같이 단일 비디오가 주어지면 기하학적으로 일관된 로봇 행동을 동반하면서 임의의 새로운 시점으로부터 사실적인 관측값을 생성할 수 있습니다. 이는 추가적인 데이터 수집 없이 모델에게 다양한 egocentric data를 대규모로 확장간으하게 하여 시점 변ㅂ화에 대한 강건성을 향상 시킬 수 있게 합니다.

GigaWorld-0-Video-MimicTransfer
로봇 학습에서 가장 큰 경제적 장벽 중 하나인 원격 조작 데이터 수집 비용 문제를 직접적으로 해결합니다. 풍부하고 저렴하게 확보할 수 있는 인간의 1인칭 시연 영상을 로봇이 실행 가능한 궤적으로 변환하는 파이프라인을 구축함으로써, 대규모 행동 데이터에 대한 접근성을 민주화할 수 있는 확장 가능한 대안을 제시합니다.
Model Details. GigaWorld-0-Video-MimicTransfer는 사전 학습된 GigaWorld-0-Video-Dreamer를 기반으로 fig 4에 보이는 바와 같이 control branch로 사후 학습된 모델입니다. 사람 손과 로봇 팔 조작이 정렬된 데이터 쌍의 희소성 문제로 저자는 robotic-arm manipulation videos만 이용하여 학습을 진행합니다. 구체적으로 저자는 두 가지 video condition을 이용합니다. video condition-1은 조작 장면을 제어하고, video condition-2는 사람 손의 움직임을 모방하도록 로봇 팔의 움직임을 강제합니다. fig 6에서 볼 수 있는 바와 같이 video condition-1을 갖추기 위해서 원본 비디오에서 로봇 팔을 마스크 처리하고 배경만 남깁니다. video condition-2의 경우, 원본 팔의 궤적을 사용하여 시뮬레이션된 로봇팔을 구동하여 사람과 유사한 조작을 묘사하는 합성 비디오를 생성합니다. 모델은 두 condition으로부터 마스크되지 않은 원본 robotic-arm manipulation video를 재구성하도록 학습됩니다. 추가적인 학습 정보와 데이터 구성 절차는 MimicDreamer를 따른다고 합니다.

+ 논문 설명 중 핵심적인 설명이 빠진 것 같아 보충합니다. 사람 손 데이터를 모델에 입력하기 전에 사람 손의 3D keypoint를 추출하고, 여기서 특정 키포인트 (e.g. wrist)를 ee로 가정하고 IK를 수행해 로봇 궤적을 얻습니다. 이로부터 얻은 궤적을 기반으로 시뮬레이션하여 fig 6과 video condition을 얻습니다. 사람 손은 마스킹되어 로봇 손 마스크로 덮어진다는 가정으로 데이터를 생성합니다. ~ MimicGre
++ 즉, 앞선 전처리를 통해 모델의 사람 손 데이터 입력은 video condition-1과 같은 형태로 가공되어집니다. 이를 이용한 트릭입니다.
Function as a Data Engine. GigaWorld-0-Video-MimicTransfer는 fig 16에서 보여주는 바와 같이 1인칭 사람 시연 영상을 로봇 팔 조작 영상으로 변환하는 데이터 엔진 역할을 합니다. 구체적으로, 인간의 손은 입력 영상에서 마스크 처리되어 video condition-1으로 사용되며, 장면 컨텍스트를 유지합니다. 한편, 인간의 손에 대한 주석이 달린 엔드 이펙터 포즈를 사용하여, inverse kinematics (IK)를 통해 로봇 팔의 해당 관절 각도를 계산하고, 결과적인 팔 포즈를 시뮬레이터에서 렌더링하여 video condition-2를 생성합니다. 이 두 가지 입력에 조건화되어, 모델은 원래 인간의 행동을 모방하는 사실적인 로봇 팔 조작 영상을 합성하며, 이를 통해 robot learning을 위한 확장 가능하고 비용 효율적인 데이터 증강을 가능하게 합니다.


더 나아가, GigaWorld-0-Video는 embodied manipulation 시나리오 특성을 더 반영하기 위해서 multi-view video generation과 generation acceleration을 통합했다고 합니다. Multi-view synthesis를 위해서 (EMMA, RoboTransfer, DriveDreamer-2)를 따라 multi-view images를 width dimension을 따라 단일 panoramic input으로 결합합니다. 해당 설계 방식은 diffusion model 특성을 보존하고 in-context learning capabilities를 활용하기 위한 방식으로 소량의 multi-view data에 대한 fine-tunning 후, 모델은 architectural modifications 없이 여러 viewpoint에 걸쳐 temporally and spatially coherent한 video를 생성할 수 있습니다. Fig 7과 Fig 13에서 보이는 바와 같이 egocentric 및 third-person observations 과 같은 cross-view consistency를 보여주며, 해당 기법의 잠재력을 보여줍니다.
+ 위 내용에 대해서는 저도 어떻게 했다는 건지 잘 모르겠네요… 아시는 분은 댓글로 알려주시면…. 하하…
Video generation을 가속화하기 위해, GigaWorld-0-Video는 denoising step distillation (DMD… Yin et al., NeurIPS 2024)를 이용하여, sampling process를 one step으로 줍입니다. FP8-precision inference와 결합되면 standard diffusion models에 비해 50배 이상 향상된 속도를 달성합니다.
… + 추가로 비디오 생성 모델의 hallucination과 artifact를 줄이기 위해서 여러 차원에서 비디오를 평가하는 evaluation pipeline을 활용합니다. 각 비디오에 대해서 quality score가 계산되어 pre-training, fine-tunning 또는 rejection에 대한 적합성을 결정합니다. ~ geometric consistency, multi-view coherence (Robotransfer), text-to-video alignment + physical plausibility (COSMOS-reason1)를 활용함 ~
++ quality score에 따라 VLA을 위한 3가지 데이터 셋 분류 ~pre-training, fine-tunning, rejection~에 배치되는 것 같습니다. 기준과 이유에 대해서는 논문에서 찾지 못했습니다만… fine-tunning > pre-training > rejection 순으로 배치되지 않을까 싶습니다. 아무래도 fine-tunning이 최종적인 영향을 많이 줄테니깐 정교해야 할 것 같네요.