안녕하세요. 이번에 소개할 논문은 롱컨텍스트 LLM이 긴 입력에서 정보를 실제로 어떻게 찾아 쓰는지를 모델 내부 attention head를 통해 분석한 연구입니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
이 연구는 롱컨텍스트 언어 모델이 입력의 임의 위치에 있는 정보를 실제로 어떻게 활용하는지, 그 내부 메커니즘을 분석하는 데 초점을 둡니다. 최근 롱컨텍스트 언어 모델링 연구들은 좋은 성과를 보여주고 있는데, 그 대표적인 예가 바로 Needle-in-a-Haystack 테스트입니다. 이 테스트는 매우 긴 입력 속에 숨겨진 짧은 문장 하나(바늘)를 정확히 찾아내는 능력을 요구하며, 모델의 롱컨텍스트 처리 능력을 평가합니다. 이런 능력은 단순한 검색을 넘어, 실제 롱컨텍스트 태스크에서처럼 정보 검색과 추론이 여러 단계로 얽혀 있는 문제를 풀기 위한 기초가 됩니다.
저자들은 4개 모델 패밀리, 6가지 모델 스케일, 그리고 3가지 파인튜닝 설정에 걸친 실험을 통해 관찰 결과를 제시합니다. 분석 결과 트랜스포머의 여러 어텐션 헤드 중, 극히 일부의 헤드만이 질문에 필요한 정보를 직접 찾아내고, 입력 토큰을 출력으로 연결하는 역할을 수행한다는 것을 발견했습니다. 저자들은 이 헤드들을 retrieval head라고 부릅니다. 중요한 점은, 이 retrieval head가 활성화되느냐에 따라 모델의 출력이 사실에 근거한 답변인지, 아니면 환각(hallucination)인지가 거의 결정된다는 것입니다. 해당 헤드가 활성화되면 모델은 입력 문서에 근거한 답을 내놓지만, 활성화되지 않거나 실험적으로 마스킹되면(Fig. 1) 모델은 필요한 정보를 찾지 못하고 그럴듯한 거짓 답을 만들어냅니다.
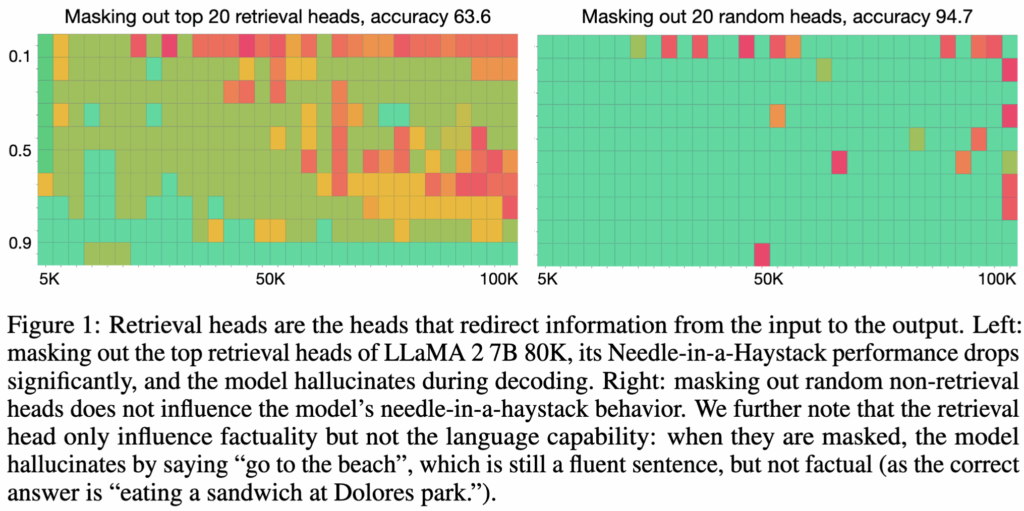
이 발견은 “모델이 바늘을 제대로 찾을 때와 못 찾을 때, 어텐션 메커니즘 내부에서는 무슨 일이 벌어지고 있는가?”라는 질문에서 출발합니다. 저자들은 이 문제를 이해하기 위해 두 가지 선행 연구에서 중요한 영감을 얻습니다. 하나는 RNN 시대의 CopyNet으로, 입력 토큰을 출력으로 복사하는 단일 헤드 어텐션 구조입니다. 다른 하나는 트랜스포머 내부에서, 앞에서 본 패턴을 다시 만나면 그걸 따라가도록 돕는 Induction Head입니다. 이 두 관찰을 종합해 저자들은, 인컨텍스트 러닝에 induction head가 핵심적인 역할을 하듯, 정보 검색을 담당하는 특수한 어텐션 헤드가 존재하며, 이들이 조건부 copy-paste 알고리즘을 구현하고 있을 것이라는 가설을 세웁니다.
이를 검증하기 위해 저자들은 트랜스포머 구조 내에서 retrieval head를 자동으로 탐지하는 알고리즘을 설계하고(2. Detecting Retrieval Head), 실험을 통해 그 성질을 분석합니다(3. Basic Properties of Retrieval Heads). 그 결과는 다음과 같습니다.
- retrieval heads are universal and sparse: LLaMA, Qwen, Mistral 등 어떤 모델 패밀리든, 6B부터 34B, MoE 구조까지 포함해, 입력 정보를 재현할 수 있는 모델이라면 공통적으로 소수(<5% 수준)의 retrieval head가 존재합니다.
- they are intrinsic: 예를 들어 LLaMA2 base처럼 짧은 컨텍스트로 사전학습된 모델에도 이미 retrieval head가 들어 있습니다(대규모 프리트레이닝의 결과). 그리고 이후 long-context 지속 사전학습(예: 80K), chat 파인튜닝, sparse upcycling을 거치더라도, 완전히 새로운 검색 메커니즘이 생긴다기보다 기존 retrieval head를 그대로 재사용하는 경향이 관찰됩니다.
- they are dynamically activated according to the context: 가장 강한 retrieval head들은 컨텍스트가 어떻게 바뀌어도 꾸준히 활성화되는 반면, 나머지 약한 retrieval head들은 필요한 정보의 부분에 따라 활성화 위치가 달라집니다. 그래서 일부 head를 제거해도 모델이 정보를 조금은 가져오는 경우가 생기고, 이는 head들이 서로 기능을 보완한다는 관찰로 이어집니다.
- the retrieval heads are causal: 긴 문서 안에 “샌프란시스코에서 제일 좋은 건, 맑은 날 돌로레스 파크에서 샌드위치 먹는 거다” 같은 정답 문장(needle)을 넣어둔 뒤, 정보를 찾아오는 역할을 하는 retrieval head를 전부 마스킹하면 모델은 문서에서 정답을 못 찾아 “가장 좋은 건 금문교를 방문하는 것”이라는 환각을 보이고, retrieval head를 일부만 마스킹하면 “샌드위치”처럼 일부 단서는 맞추지만 “돌로레스 파크” 같은 세부 정보는 놓치는 식으로 부분 검색만 되며, 반대로 retrieval head가 아닌 다른 헤드를 랜덤하게 마스킹해도 정답을 찾는 능력은 크게 흔들리지 않습니다. 또한 아무것도 마스킹하지 않았는데도 환각이 발생하는 경우를 보면, 그 순간에는 retrieval head가 아예 활성화되지 않아 문서에 정답이 있어도 이를 끌어오지 못한 상태인 경우가 많다는 관찰 결과를 보입니다.
저자들은 더 나아가 chain-of-thought 추론 역시 retrieval head에 크게 의존한다는 점을 지적합니다. 모델이 단계적 추론을 수행하려면, 중간중간 입력 정보를 다시 참조해야 하는데, 이 과정에서도 retrieval head가 핵심적인 역할을 한다는 것입니다.
저자들은 retrieval head 발견이 롱컨텍스트 모델링에 주는 의미를 크게 두 가지로 정리합니다.
- 기계적 해석 가능성(mechanistic interpretability) 측면에서, “조건부 검색 알고리즘을 수행하는 특정 서브네트워크”를 비교적 명확히 집어냈다는 점에서 의미가 크다.
- 컨텍스트 압축 기법이 사실성을 유지하지 못하는 이유를 설명해 주며(retrieval head를 제거해버리는 경우), KV cache compression 처럼 실전 배포에 중요한 연구도 용량만 줄이는 문제가 아니라, retrieval head에 어떤 영향을 주는지를 반드시 고려해야 한다.
2. Detecting Retrieval Head
이제 저자들이 retrieval head를 실제로 어떻게 찾아내는지, 그 방법을 살펴보겠습니다. retrieval이란 결국 디코딩 과정에서 입력에 있던 토큰을 출력으로 복사해서 붙여넣는(copy-paste) 행동이 반복되는 것이고, 그렇다면 그 행동이 얼마나 자주 나타나는지로 head를 점수화하여 접근합니다. 저자들은 이를 위해 retrieval score라는 지표를 도입합니다. retrieval score가 높다는 건, 다양한 컨텍스트에서 통계적으로 봤을 때 해당 head가 입력 토큰을 출력으로 자주 가지고오는 경향이 강하다는 의미고, 그래서 이런 head를 retrieval head로 간주할 수 있다는 주장입니다.
Needle-in-a-Haystack
이 retrieval head 탐지 알고리즘은 Needle-in-a-Haystack 테스트에서 시작합니다. 질문 q와 그에 대응하는 정답 k(needle)를 준비한 뒤, 긴 컨텍스트 x(haystack)의 임의 위치 구간 iq에 k를 삽입합니다. 그리고 LLM에게 “x를 보고 q에 답하라”고 시킵니다. 이때 (q,k)는 긴 컨텍스트 x와 의미적으로 무관하게 만들고, q가 모델의 내부 지식만으로는 답할 수 없도록 설계합니다. 따라서 정답이 맞게 생성되었다면, 그 답은 모델이 아는 지식이 아니라 컨텍스트에서 복사해 온 것이라고 볼 수 있습니다.
Retrieval Score for Attention Heads

auto-regressive 디코딩 동안, 현재 생성 중인 토큰을 w라고 하고, 어떤 attention head의 점수를 a라고 하겠습니다.
그림 2에서 설명하듯, 특정 attention head가 needle에서 토큰을 “복사-붙여넣기” 했다고 판단하려면 두 조건을 만족해야 합니다.
- 지금 생성한 토큰 w가 정답 문장 k 안에 포함되어 있어야 합니다.
- 그 head가 가장 크게 어텐션한 입력 위치가 needle이 삽입된 구간 안에 있고, 그 위치의 입력 토큰이 w와 동일해야 합니다.
이 조건을 만족하며 복사된 토큰들의 집합을 g라고 하면, retrieval score는 “정답 토큰 중에서 이 head가 실제로 복사해 온 토큰의 비율”로 정의됩니다. 예를 들어 정답이 10토큰인데 retrieval score가 0.9라면, 그 head가 10개 중 9개를 컨텍스트에서 직접 가져와 출력한 것입니다.
Retrieval Head Detection Algorithm
저자들은 다양한 입력 컨텍스트에 대해 모든 attention head의 retrieval score를 계산합니다. 각 언어 모델에 대해, 서로 다른 Needle-in-a-Haystack 샘플 3세트를 구성하며, 각 샘플은 (q, k, x) 튜플로 이루어집니다. 각 샘플에서 (q, k)는 x와 의미적으로 무관하도록 만들고, q가 모델의 기존 지식으로는 답할 수 없다는 것을 모델 출력을 통해 확인합니다.
그 다음, 각 (q, k, x) 샘플에 대해 컨텍스트 길이를 1K부터 50K까지 범위에서 20개를 균일하게 샘플링해 테스트하고, 각 길이마다 q(및 needle 삽입 위치)를 컨텍스트의 시작부터 끝까지 균일하게 10개 깊이로 바꿔가며 실험합니다. 저자들은 이 정도 규모의 테스트면 평균 retrieval score가 몇 개 샘플만으로도 수렴해 결과가 나온다고 설명합니다. 결과적으로 각 언어 모델은 대략 600회 정도의 retrieval 테스트를 수행합니다.
각 테스트에서 head별 retrieval score를 계산하고, 이를 평균내어 head의 최종 retrieval score로 사용합니다. 최종적으로 retrieval score가 상대적으로 큰 head들을 retrieval head로 간주합니다. 논문에서는 임계값을 0.1로 두어, 어떤 head가 전체 테스트에서 10% 이상 copy-paste 행동을 보이면 retrieval head로 분류했습니다.
3. Basic Properties of Retrieval Heads
이 섹션은 retrieval head가 공통적으로 갖는 성질이 뭔지를 세 가지로 정리합니다.
- Universal & Sparse: 롱컨텍스트 능력이 있는 모델이라면 소수의 retrieval head가 존재한다.
- Dynamic: retrieval head는 항상 켜져 있는 게 아니라, 컨텍스트나 토큰에 따라 다르게 활성화된다.
- Intrinsic: retrieval head는 후속 학습으로 새로 만들어진 게 아니라, base model 단계에서 이미 내재적으로 존재하며, 이후 파생 모델들도 대체로 같은 head들을 재사용한다.
3.1 Universal and Sparse
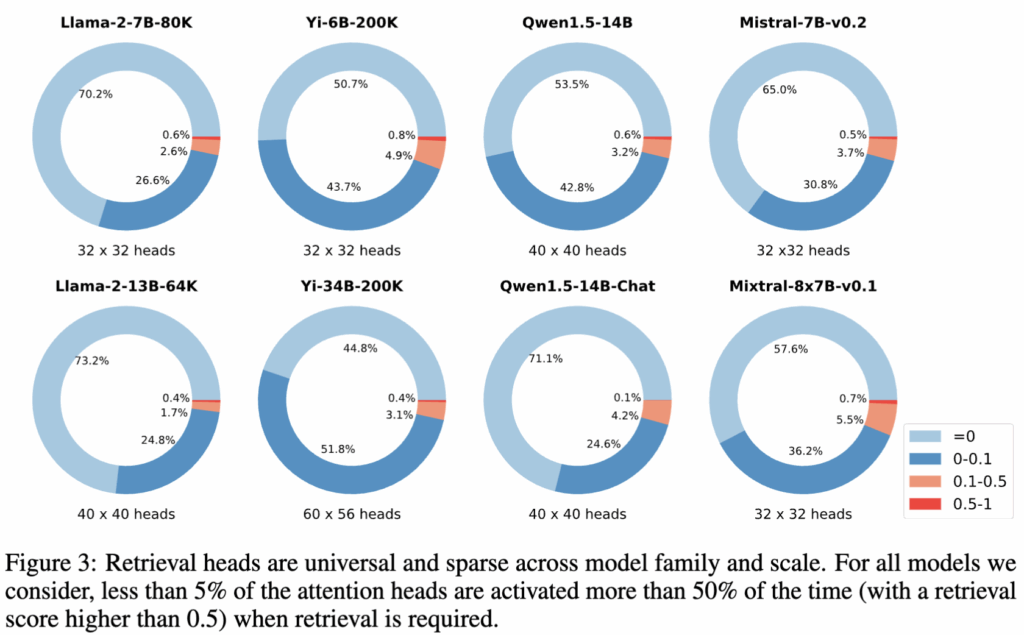
Figure 3에서 보듯, 사전학습 방식이나 파인튜닝 방법, 그리고 아키텍처가 어떻게 다르든, 모든 모델에서 소수의 retrieval head가 일관되게 존재함을 확인할 수 있습니다. 전체 어텐션 헤드 중 약 25%에서 52% 정도는 매우 낮은 빈도로 copy-paste 행동을 보이며, retrieval score가 0에서 0.1 사이에 머뭅니다. 반면 약 45%에서 73%의 헤드는 retrieval score가 0으로, 검색과는 전혀 다른 기능을 수행하고 있음을 의미합니다.
실제로 retrieval score가 0.1을 넘는, 즉 질문된 토큰의 최소 10% 이상을 검색해 오는 헤드는 전체의 약 3%에서 6%에 불과합니다. 그리고 모델마다 전체 파라미터 수나 어텐션 헤드의 총 개수는 크게 다름에도 불구하고, retrieval head가 차지하는 비율은 거의 일정하게 약 5% 수준이라는 것을 알 수 있습니다.
3.2 Dynamically Activated Based on Tokens and Contexts
다음으로 저자들은 retrieval head가 입력 문맥에 얼마나 민감하게 반응하는지를 분석합니다. 즉, 어떤 헤드는 문맥과 무관하게 항상 활성화되는지, 아니면 특정 상황에서만 작동하는지를 살펴봅니다. 예를 들어 “샌프란시스코에서 가장 좋은 일은 맑은 날 돌로레스 파크에서 샌드위치를 먹는 것이다”라는 needle 문장을 넣었을 때, 어떤 헤드는 문장 전체에 대해 활성화되는 반면, 다른 헤드들은 “샌드위치를 먹는 것”이나 “돌로레스 파크에서”와 같은 특정 구절에서만 활성화됩니다.
이를 정량화하기 위해 저자들은 activation frequency라는 개념을 도입합니다. 이는 한 헤드가 최소 한 개 이상의 토큰에서 활성화되는 빈도를 의미합니다. activation frequency는 높지만 retrieval score가 낮은 헤드는, 특정 토큰이나 특정 문맥에서만 선택적으로 활성화되는 헤드라고 해석할 수 있습니다.
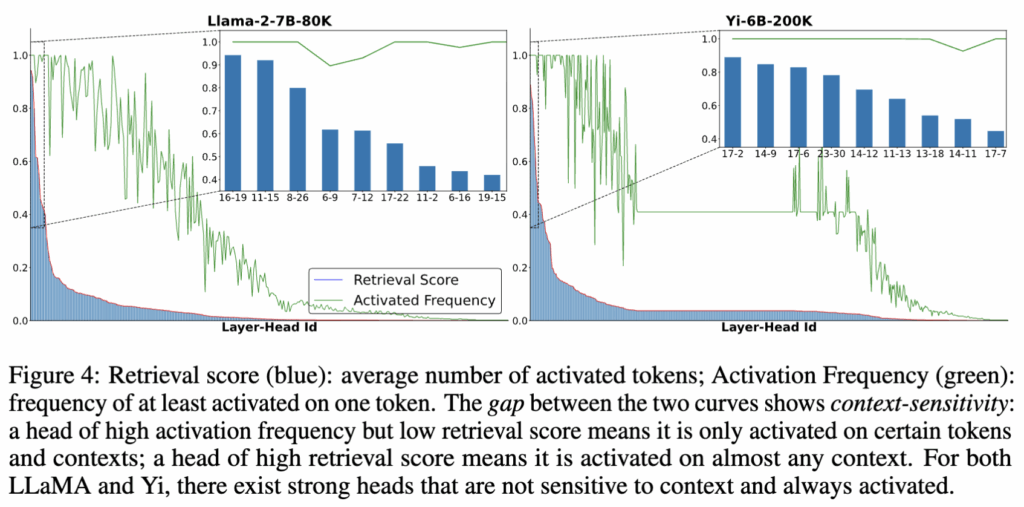
Figure 4에 따르면, LLaMA-2-7B-80K와 Yi-6B-200K 모델에는 각각 12개와 36개의 가장 강력한 retrieval head가 존재하며, 이들은 모든 실험에서 항상 활성화됩니다. 반면 나머지 weaker head들은 입력 토큰이나 문맥에 따라 선택적으로 활성화되는 모습을 보입니다.
3.3 Intrinsic
마지막으로 저자들은 retrieval head, 즉 입력의 임의 위치에 있는 정보를 활용하는 능력이 base 모델에 이미 내재된 속성임을 보입니다. 이는 대규모 사전학습의 결과로 형성된 것이며, 이후의 소규모 학습은 이러한 헤드의 활성화 패턴에 큰 변화를 주지 않습니다.
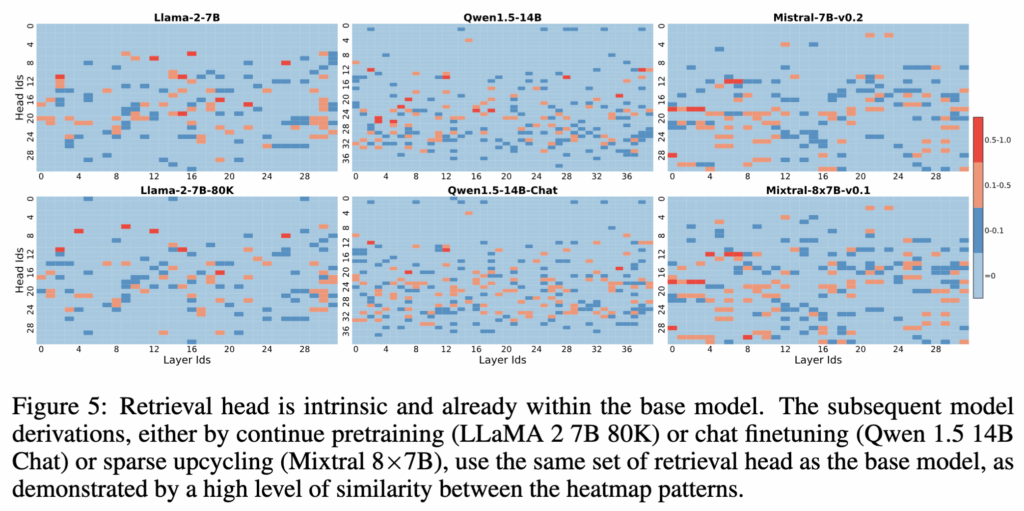
Figure 5에서는 base 모델들의 retrieval score 분포를 첫 번째 행에, 그에 대응하는 파생 모델들의 분포를 그 아래 행에 제시합니다. 연속 사전학습을 했든, 챗 파인튜닝을 했든, 혹은 sparse upcycling을 거쳤든, retrieval score의 히트맵이 매우 유사하게 유지되는 것을 확인할 수 있습니다.
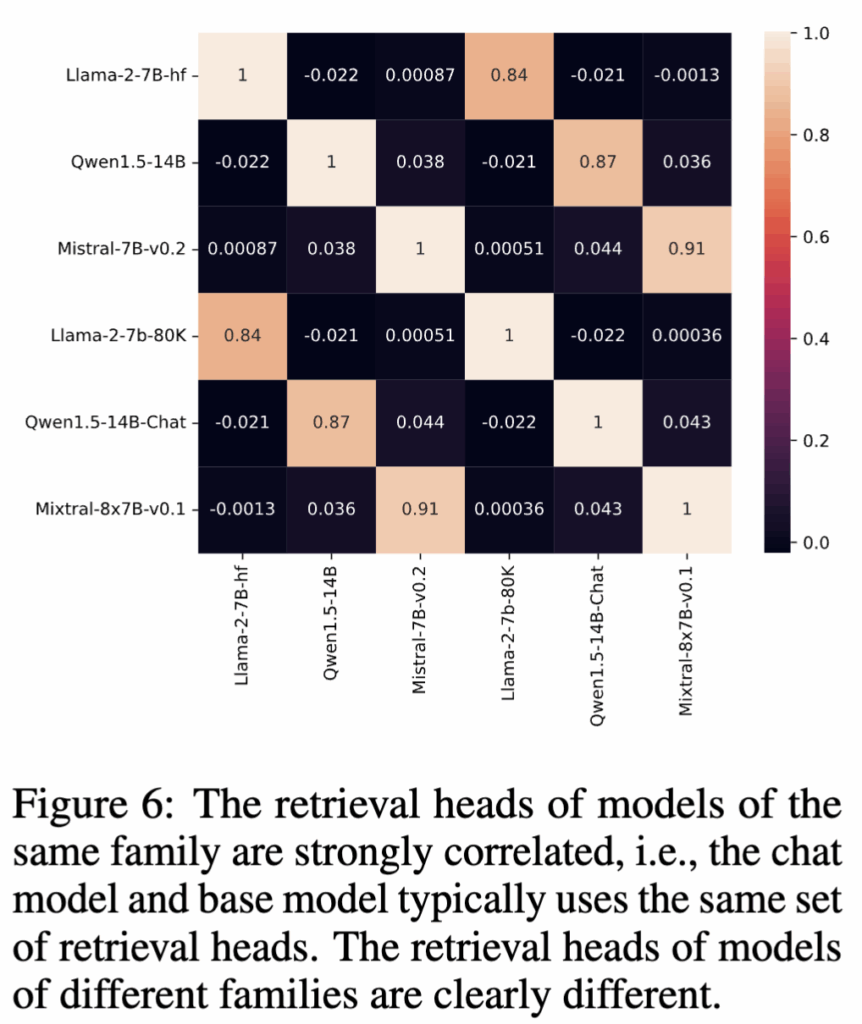
Figure 6에서는 이를 보다 엄밀하게 검증하기 위해 모델 간 retrieval score 분포의 상관관계를 계산합니다. 그 결과, base 모델과 그 파생 모델들 사이에서는 피어슨 상관계수가 0.8을 넘을 정도로 매우 높은 유사도를 보입니다. 반면 서로 다른 모델 패밀리 간에는 상관계수가 0.1 이하로 떨어지는데, 이는 각 모델이 서로 다른 사전학습 레시피를 사용했음을 반영하는 결과라고 볼 수 있습니다.
4. Influence on Downstream Tasks
이 섹션에서는 retrieval head가 실제 다운스트림 태스크에 어떤 영향을 미치는지를 분석합니다. 모든 실험에서는 오픈소스 언어 모델인 Mistral-7B-Instruct-v0.2를 사용합니다. 먼저 retrieval head가 Needle-in-a-Haystack 테스트에서 사실성(factuality)을 어떻게 설명하는지 보여줍니다. 모델이 needle을 성공적으로 찾아낼 수 있을 때는 retrieval head가 항상 활성화되는 반면, needle을 찾지 못하고 환각을 일으킬 때는 retrieval head가 부분적으로만 활성화되거나 아예 활성화되지 않습니다. 이후에는 retrieval head가 입력 문서에서 정보를 추출해야 하는 질문응답 태스크에는 큰 영향을 미치지만, 모델의 내부 지식만으로 답을 생성하는 과제에는 상대적으로 영향이 적다는 점을 보입니다. 마지막으로 chain-of-thought와 같은 보다 복잡한 추론 과정에서 retrieval head가 어떤 역할을 하는지도 함께 분석합니다.
4.1 Retrieval Heads Explains Factuality in Needle-in-a-Haystack
먼저 Needle-in-a-Haystack 테스트에서는 retrieval head 탐지에 사용했던 세 가지 테스트 셋과는 다른 추가적인 needle 테스트 셋을 구성합니다. 이후 retrieval head 또는 무작위로 선택한 head를 점진적으로 마스킹하면서 모델의 변화를 관찰합니다.
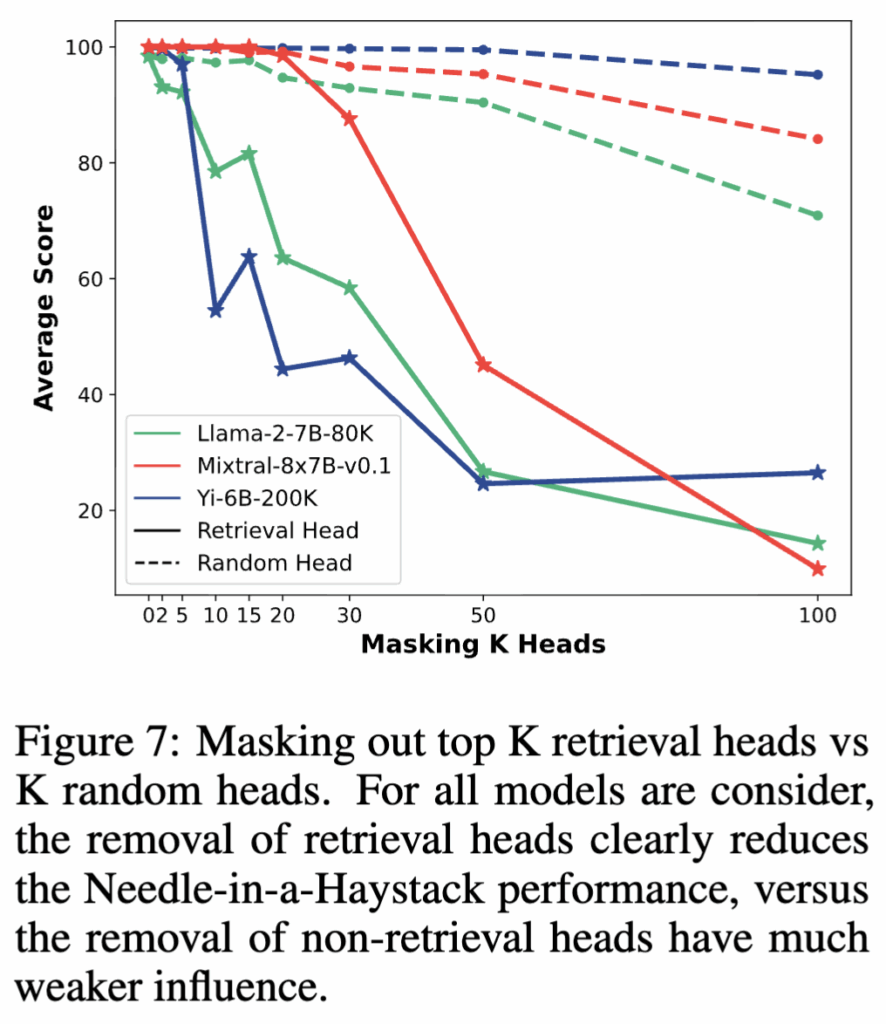
Figure 7에서 볼 수 있듯이, retrieval head를 마스킹하면 모델의 Needle-in-a-Haystack 성능은 크게 저하되는 반면, 무작위 head를 마스킹했을 때는 상대적으로 성능 변화가 크지 않습니다. 특히 마스킹한 head의 개수 K를 50개(전체 head의 약 5%)까지 늘리면, 모든 모델에서 needle 테스트 성능이 50 이하로 급격히 떨어집니다. 이는 상위 retrieval head들이 대부분의 needle 검색 능력을 담당하고 있음을 확인할 수 있습니다.
이 과정에서 저자들은 세 가지 유형의 오류를 관찰합니다.
- Incomplete retrieval: 정답을 일부만 가져오고 핵심 디테일을 빠뜨리는 경우
- Hallucination: 아예 문서 기반 답을 못 만들고 그럴듯한 환각 문장을 생성하는 경우
- Wrong extraction: 문서에서 가져오긴 했는데, needle이 아니라 haystack의 엉뚱한 부분을 끌어와서 틀리는 경우
마스킹이 없는 상태에서도, retrieval head가 활성화되었지만 잘못된 위치에 어텐션을 주어 잘못된 추출이 발생합니다. 환각이 발생하는 경우에는 retrieval head가 입력의 첫 토큰에 과도하게 주의를 집중하는 경향이 나타나는데, 이는 “attention sink”로 알려진 현상으로, 정보량이 적은 더미 토큰에 주의가 몰리는 상황으로 해석할 수 있습니다.
마스킹하는 head의 수를 점차 늘리면, 처음에는 가장 강력한 일부 retrieval head가 제거되면서 불완전한 검색이 나타나기 시작합니다. 이 상태에서는 남아 있는 약한 retrieval head들이 목표 정보의 일부만을 가져옵니다. 저자들은 이를 비유적으로, 각 retrieval head가 ‘바늘’의 일부 조각만을 들고 있지만, 이 조각들이 모여 완전한 바늘을 만들지는 못하는 상태라고 설명합니다. 이러한 현상은 retrieval score가 0.4보다 큰 head들을 마스킹하기 시작할 때 주로 나타납니다. 이후 더 많은 head를 마스킹하면, 검색 능력이 완전히 붕괴되며 환각이 발생합니다.
4.2 Influence on Extractive QA
다음으로 저자들은 extractive QA 태스크에서 retrieval head의 역할을 분석합니다. 이는 사용자가 논문, 재무 보고서, 법률 문서와 같은 PDF를 업로드한 뒤, 문서 내부의 특정 정보를 질문하는 태스크입니다. 질문에 사용되는 지식이 모델의 내부 지식에 존재하지 않도록 하기 위해, 저자들은 최신 뉴스 기사들을 수집한 뒤 그중 일부 단락을 추출하고, GPT-4를 사용해 해당 단락을 기반으로 질문–정답 쌍을 생성하는 방식으로 extractive QA 데이터셋을 구성합니다.
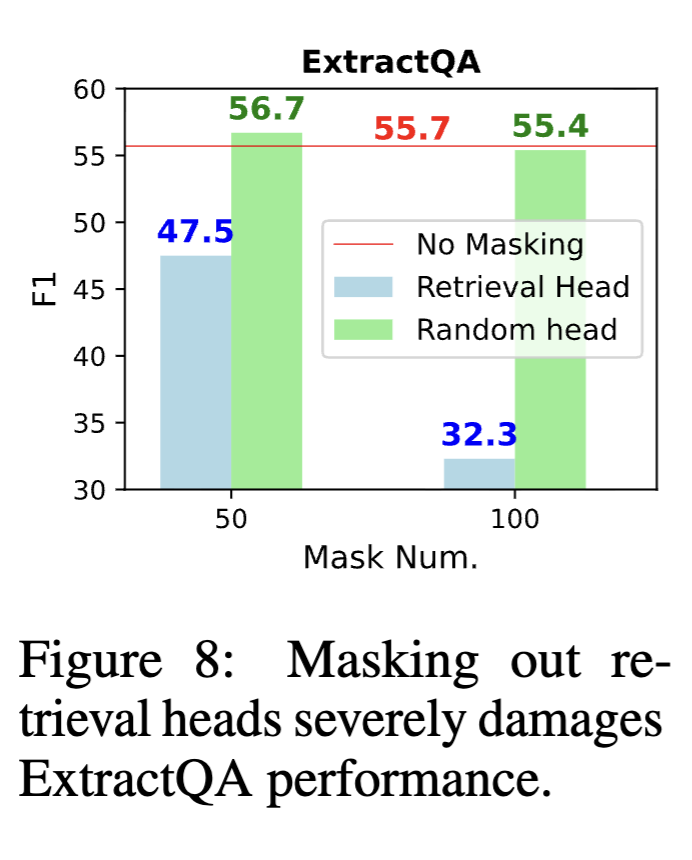
Figure 8에서 보듯, 무작위 non-retrieval head를 마스킹해도 성능에는 거의 영향을 주지 않습니다. 반면 retrieval head를 마스킹할 경우 F1 점수가 각각 9.2%, 23.1%까지 크게 감소합니다. 이 결과는 실제 문서 기반 QA 과제가 retrieval head의 기능에 강하게 의존하고 있음을 보여줍니다.
4.3 Chain-of-Thought Reasoning also Requires Retrieval Heads
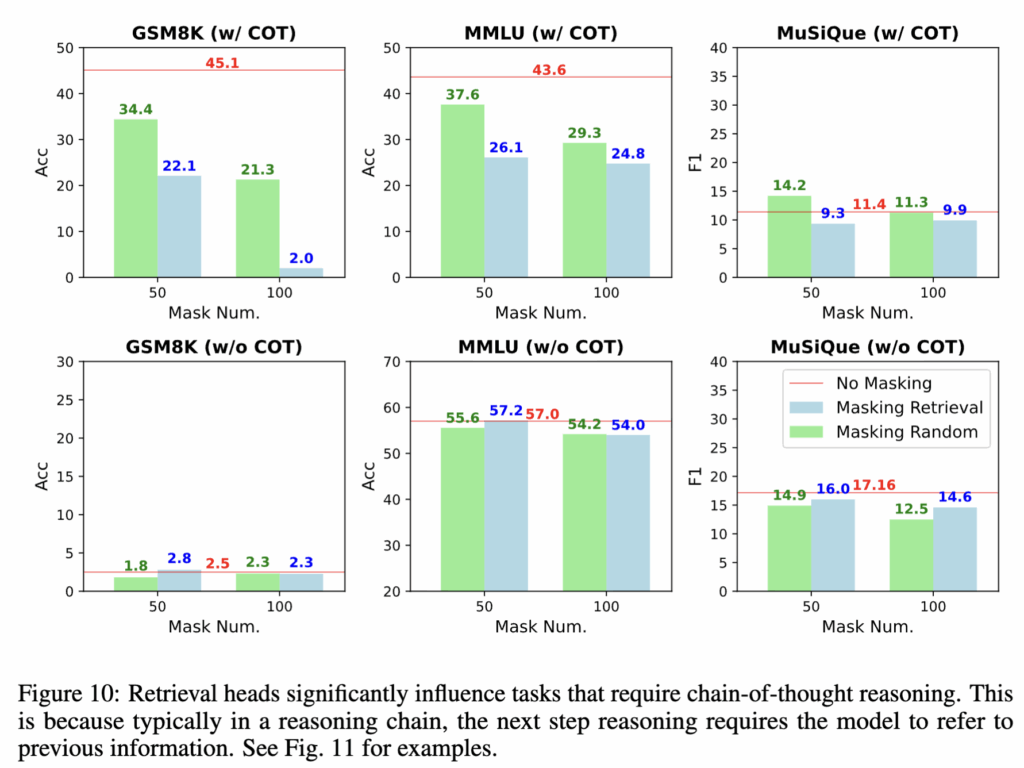
마지막으로 저자들은 Mistral-7B-Instruct-v0.2를 대상으로 MMLU, MuSiQue, GSM8K 벤치마크에서 chain-of-thought 사용 여부에 따른 성능 변화를 분석합니다. Figure 10에 따르면, answer-only 프롬프트(즉, CoT 없이 정답만 생성하도록 하는 설정)에서는 retrieval head나 무작위 head를 마스킹해도 성능 변화가 거의 없습니다. 이는 이 경우 모델의 출력이 주로 FFN 레이어에 저장된 내부 지식에 기반하기 때문으로 해석됩니다.

반면 chain-of-thought 방식의 추론에서는 retrieval head를 마스킹할 경우 성능이 눈에 띄게 저하됩니다. 대표적인 오류 사례를 살펴보면(Fig. 11), 모델이 입력에 포함된 중요한 정보를 전혀 참조하지 못한 채 환각을 일으키는 모습을 보입니다.
5 Discussions
General Functionalities of Attention Heads
트랜스포머 기반 언어 모델을 이해할 때, 우리는 보통 FFN 레이어는 지식을 저장하는 공간, 어텐션 레이어는 알고리즘을 구현하는 공간으로 바라봅니다. 기존 연구에서 논의된 induction head는 입력 내에서 반복되는 패턴을 찾아내는 역할을 수행하는데, 이 점에서 정보 검색과 반복을 수행한다는 측면은 retrieval head와 어느 정도 유사합니다.
다만 저자들은 retrieval head를 induction head와 동일시하지는 않습니다. Induction head는 정보를 ‘찾아오는 것’보다, 입력에서 패턴을 발견해서 규칙 유도를 수행하는 데 초점이 있다면 retrieval head는 문맥에 따라 입력 정보를 출력으로 재지정(redirection)하는 역할을 주로 담당하며 규칙 자체를 추론하지는 않습니다. 저자들은 retrieval head 외에도, 앞으로의 연구를 통해 다양한 알고리즘과 기능을 수행하는 또 다른 유형의 어텐션 헤드들이 더 발견될 것이라고 보고 있습니다.
Relationship to Local and Linear Attention and State-Space Models
롱컨텍스트 모델링의 효율성을 개선하기 위해, local attention, linear attention, state-space model(SSM) 또는 이들을 결합한 하이브리드 아키텍처에 대한 연구들이 활발히 진행되어 왔습니다. 그러나 저자가 아는 한 현재까지 linear attention이나 SSM 기반 아키텍처 중 Needle-in-a-Haystack 테스트를 성공적으로 통과한 경우는 없습니다. 이는 롱컨텍스트에서 임의 위치의 정보를 정확히 검색하기 위해서는 full attention이 사실상 필수적일 수 있음을 알 수 있습니다. 대표적인 예로, Mistral v0.1은 sliding window attention을 사용했기 때문에 Needle-in-a-Haystack 테스트를 통과하지 못했지만, 이후 v0.2에서 full attention으로 변경하자 테스트를 통과할 수 있었습니다. 이러한 결과는 본 논문의 결과와도 잘 맞아떨어집니다. 입력의 임의 위치에 있는 정보를 정확히 활용하려면, retrieval head가 전체 KV cache에 접근할 수 있어야 하며, 이를 위해서는 full attention 구조가 필수적이라는 것을 알 수 있습니다.
이번 논문에서의 결론은 롱컨텍스트 LLM이 긴 입력에서 필요한 정보를 정확히 가져와 쓰는 능력은 소수의 특정 attention head, 즉 retrieval head에 크게 의존한다는 점입니다. retrieval head가 활성화되면 모델이 입력에 근거한 답을 내는 경향이 강해지고, 반대로 활성화가 약하거나 마스킹되면 필요한 정보를 못 찾아 환각으로 이어진다는 걸 실험으로 보여줍니다. attention head가 어떤 역할을 맡고 있는지를 retrieval 관점에서 분해해 보여준 점이 인상적이였고, 모델 내부 구성요소가 실제로 어떤 기능을 수행하는지 알 수 있어 앞으로 관련 실험을 설계할 때 참고해야겠다는 생각이 들었습니다.
감사합니다.