제가 이번에 리뷰할 논문은 작년 12월 중순에 공개된 논문으로, affordance reasoning에 기존 pretrained VLMs를 그대로 활용한 연구입니다. 성능이 굉장히 크게 개선되었다는 점에 눈에 띄고, 다른 VLM들을 어떻게 융합하여 사용하였는지 궁금하여 읽게 되었습니다. reasoning과 grounding을 분리하는 것이 더 효과적임을 어필하며, 상상을 활용한다는 점에 다른 연구들과 차별화를 보이고자 한 것으로 보입니다. 어디에 제출하였고 인정을 받을 수 있는 지 굉장히 궁금하네요.
Abastract
affordance는 상호작용이 이루어지는 영역을 인식하는 것으로, 기존의 모델들은 high-level reasoning 모델과 low-level grounding 모델을 하나의 파이프라인으로 통합하고, 과도한 annotation 데이터에 대한 학습에 의존하는 경향이 있었습니다. 이로인해 일반화 성능의 한계가 존재하였으며, 해당 논문은 training-free 방식의 에이전트 기반 프레임워크인 A4-Agent를 제안하므로써 일반화 성능을 높이고자 하였습니다. A4-Agent는 (1) 생성모델로 상호작용이 어떻게 이루어질지를 시각화하는 Dreamer, (2) Large VLM으로 상호작용이 이루어지는 물체 영역을 결정하는 Thinker, (3) VFM을 통해 실제로 상호작용이 이루어지는 영역을 찾는 Spotter로 구성됩니다. 해당 논문은 task에 특화된 데이터로 학습을 하지 않고도, 다양한 벤치마크에서 zero-shot 방식으로 기존의 학습 기반의 SOTA 방법론을 능가하는 일반화 성능을 보였으며, real-world 세팅에서도 강인하게 작동함을 입증하였습니다.
Introduction
affordance prediction은 시각적 인지와 물리적 상호작용을 연결하는 핵심 요소로써, embodied AI와 로봇 조작에서 중요한 역할을 합니다. 이는 단순히 물체가 무엇(what)인지를 인식하는 것을 넘어, 자연어 지시로부터 어디(where)에서 어떻게(how) 상호작용이 이루어지는지 이해하는 것을 목표로 합니다. 이러한 affordance prediction을 위해서는 자연어를 이해하고 작업과 관련된 물체 영역을 인식하는 “high-level reasoning” 능력과, 픽셀 레벨에서 정확하게 상호작용이 이루어지는 영역을 인식하는 “low-level grounding”능력이 요구됩니다.
전통적인 기법은 주로 grounding에 집중하여 affordance map을 예측하는 regression 문제로 접근하였으나, 이러한 방식은 high-level reasoniong 능력이 부족하다는 한계가 존재하였습니다. 이를 보완하기 위해 최근 연구들은 LLM을 활용하여 reasoning과 grounding을 통합한 end-to-end 모델을 학습하는 방향으로 연구가 이루어졌으나, 이러한 방식도 reasoning과 grounding 사이의 트레이드 오프 관계, 일반화의 어려움으로 인해 real-world로의 확장에 어려움을 겪었습니다. 이에 본 논문은 high-level reasoning과 low-level grounding을 end-to-end로 결합해야 하는 지에 대한 의문을 제기합니다.
이러한 의문을 바탕으로 해당 논문에서는 training-free 방식의 agentic framework인 A4-Agent를 제안하였습니다. 핵심 아이디어는 reasoning과 grounding 과정을 분리하는 것으로, foundation models를 3단계로 구성한 프레임워크를 제안합니다. 먼저, (1) Dreamer: 사람의 인지 과정에 영감을 받아 생성 모델을 이용하여 상호작용이 “어떻게(how)” 이루어질 지를 시각적으로 상상합니다. 이후, (2) Thinker: 앞서 상상한 시나리오를 결합하여, VLMs를 이용하여 작업 지시문을 해석하고 “어떤 물체 부위(what)”와 상호작용을 해야하는 지 구조화 된 언어적 표현을 생성합니다. 마지막으로 (3) Spotter: VFMs를 활용하여 상호작용이 실제로 “어디서(where)” 이루어지는 지를 인식합니다. (※ 참고로, 3단계로 이루어져 있지만, Dreamer 과정이 2개의 agent를 쓰기 때문에 A4인 것 같습니다.. 그런데.. 마지막 spotter 단계도 2개로 보이네요..?)
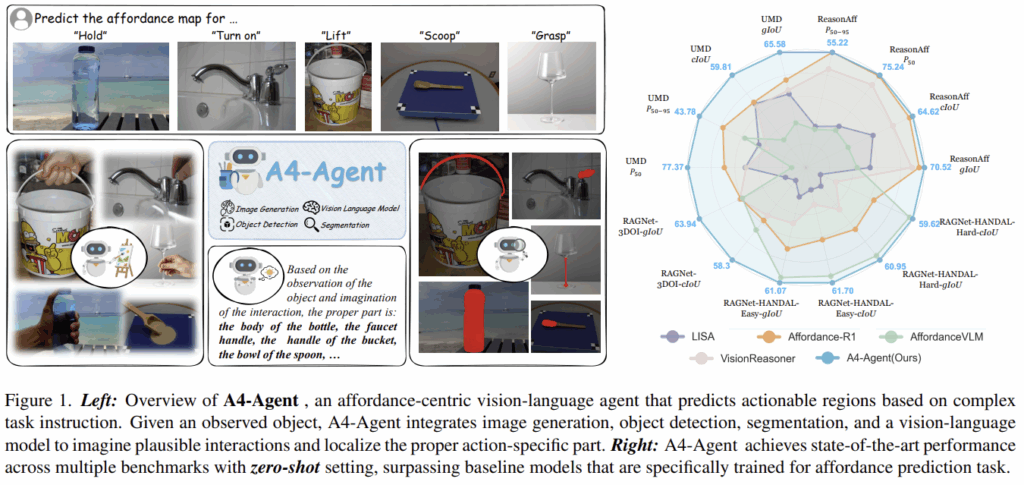
이러한 구조는 Figure 1에서 확인할 수 있으며, 저자들은 작업에 특화된 학습 없이도 zero-shot 방식으로 기존의 학습 기반 방법론들을 능가하는 성능을 달성하였으며, real-world에도 강인한 일반화 성능을 보였습니다.
해당 논문의 contribution을 정리하면
- training-free agentic framework인 A4-Agent를 제안하여, zero-shot 방식으로 학습 기반을 능가하는 SOTA 달성
- reasoning과 grounding을 분리함으로써 affordace prediction을 위한 새로운 접근법을 검증하였으며, 실험을 통해 이러한 방식의 효과를 입증
- Imagination-assisted affordance reasoning 패러다임을 제안하며, affordance prediction에 있어 상상의 중요한 역할을 확인함
Motivation
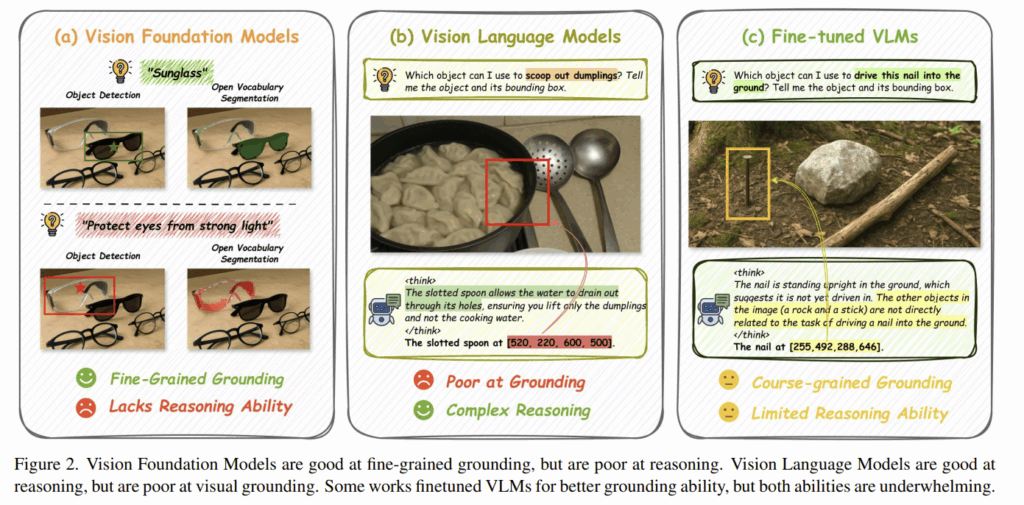
Affordance prediction은 지시문을 이해하여 어떤 물체 부위(what)에서 어떻게(how) 상호작용이 이루어지는 지 인식하는 high-level reasoning과 시각적으로 상호작용이 어디서(where) 이루어지는 지 인식하는 low-level grounding 능력이 요구됩니다. 위의 Figure 2는 foundation 모델에 대해 나타낸 것으로, (a)VFMs는 영역을 찾는 능력이 좋지만, 복잡한 지시문을 이해하여 의미론적으로 대응되는 영역을 찾는 reasoning 능력이 부족합니다. (썬글라스는 잘 찾지만, 빛으로부터 눈을 보호하는 역할에 대해서는 이해하지 못하고 있죠.) (b)MLLMs는 인상적인 reasoning 능력을 보이지만, 종종 공간적 이해 능력이 부족하여 정밀한 affordance 예측에는 한계가 있습니다.(“… scoop out dumplings”라는 명령에 대해, 구멍이 뚫린 스푼은 육수는 빠져나가도 만두만 건질 수 있다고 굉장히 잘 추론하였으나, 그에 대응되는 box 영역은 엉뚱한 부분을 나타냅니다.) 기존 패러다임은 단일 end-to-end 모델을 grounding 데이터로 학습시킴으로써 이를 해결하고자 하였으나, Figure 2의 (c)와 같이 둘을 결합한 패러다임은 이상적 결과로 귀결되지 않았으며(예시는 못을 땅에 박으려면 어떤 물건을 사용해야하는 지 지시문이 주어졌을 때, 돌과 나무가 직접적으로 연관되지 않는다는 답변과, 못의 bounding box를 반환하고있는데, 사실 추론을 통해 돌로 박을 수 있다는 답변을 할 수 있으나, 거기가지 추론이 도달하지 못하였다는 것을 보여주고자 한 것으로 보입니다.), 근본적으로 다음과 같은 한계가 존재합니다.
- Limited generalization. 제한된 데이터 셋으로 학습할 경우 실제 환경의 모든 다양성을 포함할 수 없어 새로운 물체와 환경으로의 일반화가 어려움
- Capability trade-offs. reasoning과 grounding 능력을 동시에 최적화하려면 모델이 서로 다른 object를 균형있게 조절하며 학습하는 데는 어려움이 있음
- Poor flexibility. 새로운 강력한 foundation 모델이 등장할 경우 부분적으로 업데이트가 불가하며, 전체 시스템을 재학습해야 함
- Gap to closed-source models. fine-tuning이 필요하므로 체크포인트가 공개된 open-source 모델에 한정되므로 closed-source 모델로 적용이 어려움
따라서 해당 논문은 reasoning과 grounding을 특화된 agent로 분리하는 방식을 연구하였으며, affordance 인식 문제는 본질적으로 multi-stage로 이루어져야 함을 주장합니다. 따라서 최신 foundation 모델들을 활용하여 각 구성 요소를 독립적으로 설계하고, test-time에 agent framework를 통해 이를 조율하는 A4-Agent를 제안하였습니다. 이러한 방식은 사전 학습된 모델의 지식을 활용해 추가 학습 없이도 다양한 시나리오로 일반화할 수 있으며, 각 단계를 모듈화하여 독립적인 업그레이드가 가능하다는 이점이 있습니다. 또한, 명시적으로 단계적인 추론을 수행하므로, 추론 과정의 오류 분석 및 개선이 용이해진다는 장점이 있습니다.
A4-Agent
Problem Definition
이미지 \mathbf{I}와 작업에 대한 description \mathbf{T}(e.g. "open the refrigerator")가 주어졌을 때, 상호작용에 대응되는 affordance 영역 \mathcal{A}_{ff}을 찾는 것을 목표로 합니다. 이러한 영역은 downstream task에 따라 bounding box \{\mathbf{B}_i\}^N_{i=1}나 keypoint \{\mathbf{P}_i\}^N_{i=1}, segmentation mask \{\mathbf{M}_i\}^N_{i=1}가 될 수 있으며, 해당 논문에서는 segmentation mask로 실험을 진행하였다고합니다.
Overview
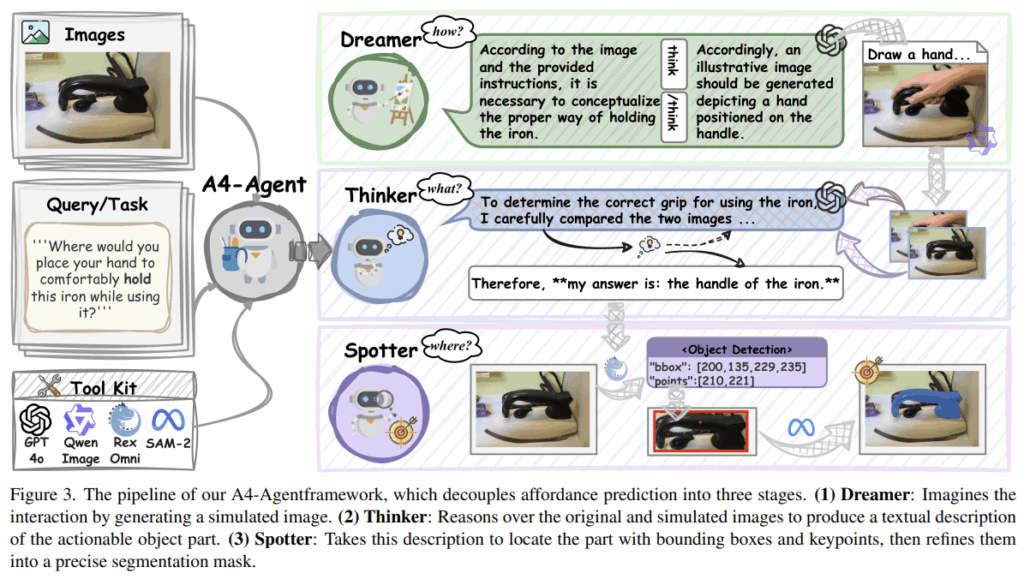
Figure 3은 A4-Agent의 프레임워크로, 학습과정 없이 zero-shot 방식으로 affordance 영역을 추정하게 됩니다. 이미지와 description으로부터 바로 bounding box나 mask를 추론하던 기존 방식과 다르게, reasoning 과정을 통해 상호작용 영역인 물체 부위를 추론한 뒤 grounding을 수행하게 됩니다. reasoning은 2단계로 이루어지며, 상호작용이 어떻게(how) 이루어지는지 상상하는 Dreamer와 어떤 물체 부위(what)에서 상호작용이 이루어지는 지 추론하는 Thinker로 구성됩니다. 이후, Spotter를 통해 영상 내 어디(where)에서 상호작용이 이루어지는 지 픽셀 수준으로 예측합니다.
1. Dreamer: Image How to Operate
사람의 경우, 도구를 사용할 때 머리속으로 어떻게 상호작용 할 지 시뮬레이션해보고, 다양한 시나리오를 상상합니다. 이로부터 영감을 받아 저자들은 Dreamer를 설계하였습니다. 텍스트 정보에 의존하기보다, 가능한 상호작용 상태를 시각화하는 이미지를 생성하도록 하는 것 입니다.

해당 과정은 위의 시스템 프롬프트\tau를 활용하여, 이미지 \mathbf{I}와 text 지시문 \mathbf{T}을 이용하여 VLM \Phi_{VLM}을 통해 시뮬레이션 텍스트 프롬프트 \mathbf{T}_{sim}을 출력하도록 합니다. \mathbf{T}_{sim}는 이미지에 나타난 target object와 기능적 부위를 명시하고, 최소한의 상호작용을 구체화하며(e.g. "a right hand grasping the vertical refrigerator handle"), 이미지로 지원 가능한 속성만 포함하도록 하였다고 합니다.
\mathbf{T}_{sim} =\Phi_{VLM}(\mathbf{I},\mathbf{T},\tau)
이후, \mathbf{I}는 \mathbf{T}_{sim}와 함께 이미지 생성 모델 \mathcal{G}(여기서는 Qwen을 사용함)에 입력되어 상상에 대응되는 이미지 \mathbf{I}_{sim}를 생성합니다. \mathbf{I}_{sim}는 그럴듯한 접촉 및 행동 단서를 시각적으로 묘사하여 상호작용이 이루어져야 할 위치를 명확히 드러내며, 이를 통해 해당 행동의 타당성을 평가할 수 있도록 하였다고 합니다.
\mathbf{I}_{sim} = \mathcal{G}(\mathbf{I},\mathbf{T}_{sim})
2. Thinker: Decide What to Operate

다음 단계는 상호작용이 이루어지는 물체 부위에 대해 추론하는 단계로, 원본 이미지 \mathbf{I}와 상호작용을 상상한 이미지 \mathbf{I}_{sim}, 작업 \mathbf{T}이 주어졌을 때, 위의 프롬프트를 함께 VLM에 입력하여 다음 3단계를 거치도록 합니다.
- \mathbf{I}에서 핵심 구성요소와 상호작용 부위 후보를 인식
- \mathbf{I}_{sim}을 참고하여 해당 affordance와 일관된 접촉 및 행동 단서 추론
- 실행 가능한 부위를 다시 원본 이미지 \mathbf{I}에서 grounding 한 뒤 간결한 specification으로 표현
출력은 자유 형식으로 추론 과정을 나타내는 Thinking과, 기계가 판독 가능한 Output JSON을 출력하도록 합니다. Output JSON에서 "task", "object_name", "object_part"을 파싱하여 사용하며, object part는 "the [object part] of the [object name]" 형태로 표현됩니다. 이렇게 구한 affordance에 대한 text description \mathbf{D}는 text 형태로, 추론 과정을 해석 가능하도록 합니다.
3. Spotter: Locate Where to Operate
마지막으로 Spotter는 앞의 추론 과정을 통해 생성된 affordance 영역에 대한 정보를 픽셀 수준의 위치 정보로 변환하는 과정으로, text 기반의 affordance description \mathbf{D}가 주어지면 coarse-to-fine으로 visual groundingㅇ르 수행합니다. 이는 open-vocabulary object detection을 이용하여 초기 영역을 식별하고, 이후 segmentation 모델을 적용하여 픽셀 수준의 마스크를 구합니다. 이러한 2단계 방식은 segmentation 모델이 텍스트보다는 bounding box나 point와 같은 시각적 프롬프트에서 더 잘 동작하기 때문이라합니다.
1) Open-Vocabulary Object Detection
RexOmni라는 SOTA OVD 방법론을 적용하였으며, text description \mathbf{D}로부터 bounding box \{\mathbf{B}_i\}^N_{i=1}와 물체 영역 내 대표적인 keypoint \{\mathbf{K}_i\}^N_{i=1}(여기서는 중심점인듯합니다)를 예측합니다.
2) Fine-Grained Segmentation with SAM
이후 bounding box와 keypoint를 SAM에 프롬프트로 입력하여 segmentation mask \{\mathbf{M}_i\}^N_{i=1}를 생성합니다.
Spotter 모듈의 각 모델은 더 뛰어난 모델로 독립적으로 변경 가능합니다.
Experiments
Experimental Details
VLM으로는 GPT-4o, 생성 모델은 Qwen-Image-Editing, OVD 모델은 Rex-Omni, segmentation 모듈은 SAM2-Large를 이용하였습니다.
[ Results on ReasonAff Dataset ]
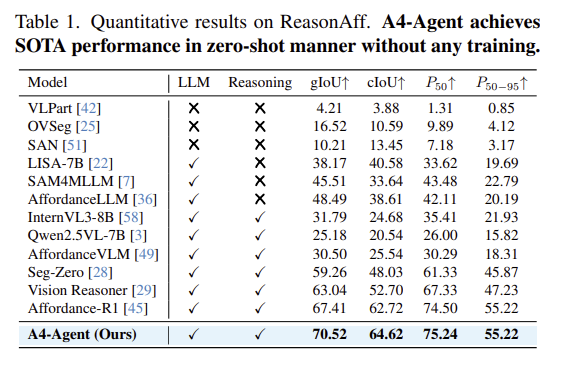
Table 1는 암묵적인 지시에 대하여 추론이 요구되는 ReasonAff 데이터 셋에서의 실험 결과를 리포팅한 것 입니다. A4-Agent는 학습 없이도 모든 지표에서 SOTA를 달성하였으며, 학습 기반 방법론인 AffordanceLLM와 강화학습 기반의 방법론인 Affordance-R1과 비교했을 때 뛰어난 추론 능력과 일반화 성능을 보였습니다. 이는 reasoning과 grounding을 분리함으로써 상호보완적인 강점을 활용할 수 있으며, 상상을 기반으로 추론하는 과정을 통해 추상적인 지시를 보다 잘 이해할 수 있었으며, 학습 데이터로 한정되지 않기 때문에 더 다양한 지시어로 일반화가 가능한 것으로 분석하였습니다. 아래의 Figure 4는 정성적 결과를 나타냅니다. 제가 affordance grounding 실험을 할 때, 와인잔에 대한 “hold”의 경우 와인대를 잘 표현하지 못하여 어려움을 겪었는데, 해당 모델에서는 제가 다른 이미지로 실험해보았을 때도 아래의 예시와 같이 해당 부위를 정확히 찾는 것을 확인할 수 있었습니다.

[ Results on RAGNet Dataset ]
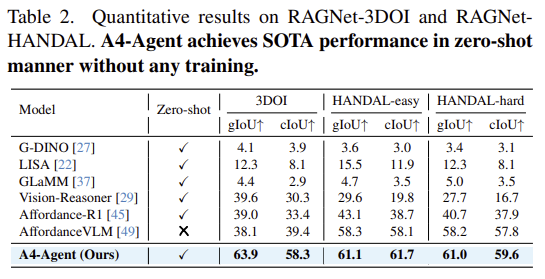
Table 2는 추론 기반의 affordance segmentation에 초점을 둔 RAGNet 데이터셋에서의 실험 결과로, A4-Agent가 다른 방법론들과 비교했을 때 뛰어난 성능 개선이 이루어졌음을 확인할 수 있습니다. 아래의 Figure 5가 정성적 결과이며, 마찬가지로 A4-Agent가 학습 기반의 방법론인 AffordanceVLM보다 우수한 성능을 보였습니다. 이는 복잡한 추론이 필요한 경우에 작업에 특화된 fine-tuning보다 에이전트를 조합하는 이러한 프레임워크가 더 효과적임을 입증하였으며, reasoning과 gronding을 구분하는 것이 효과적임을 다시한번 보여줍니다.

[ Results on UMD Dataset ]
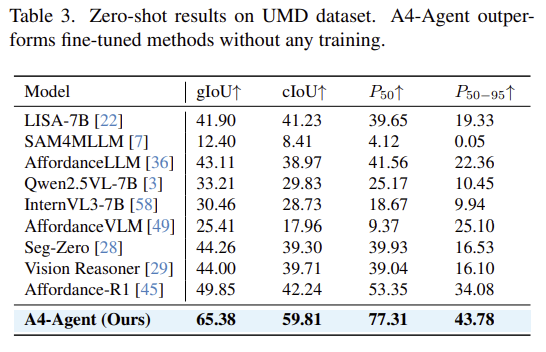
Table 3은 action 라벨로부터 Affordance 영역을 추론하는 전통적인 연구에서도 잘 작동함을 입증하기 위한 실험 결과입니다. 마찬가지로 zero-shot 방식이지만 학습 기반의 방법론들보다 더 뛰어난 성능을 달성하였습니다.
[ Qualitative Results on Open-World Images ]

위 Figure 6은 open-world 이미지로 추가 검증한 결과입니다. 새로운 물체(e.g. 디지털기기), 복잡한 장면에서 가장 적절한 부위(e.g. 드라이버의 끝 부분), 복잡한 추론(e.g. 구멍이 뚫린 숟가락으로 물을 뺄 수 있고, 바위로 못을 박을 수 있음.)에도 잘 작동한다는 것을 확인하였습니다. 두번째와 마지막 행은 위의 Figure 2에서 기존 VLM과 VFM에 대한 분석에 사용된 결과인데, VLM을 fine-tuning한 결과에서는 바위로 못을 박을 수 있다고 인식하지 못하였는데, 저자들이 제안한 방식에서는 추론이 가능하다는 것이 굉장히 인상적입니다.
[ Ablation Study ]
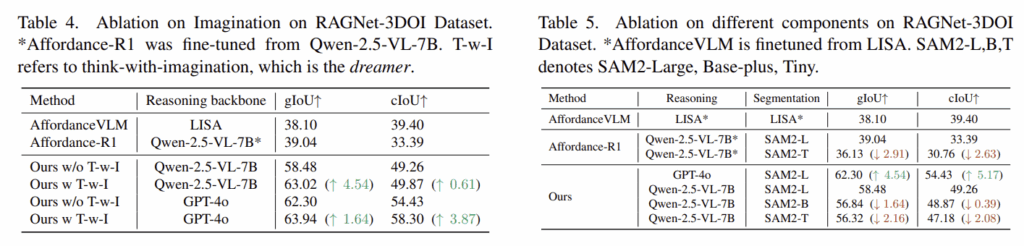
- Table 4는 시각적 상상이 얼마나 효과가 있는 지 실험한 결과로, T-w-I가 상상 모듈이며, T-w-l이 포함될 경우 성능이 개선되는 경향을 확인할 수 있습니다.
- Table 5는 각 구성요소에 대한 강인성을 분석한 것으로, Qwen-2.5-VL를 GPT-4o로 대체할 경우 성능이 유의미하게 개선되는 것을 확인하였으며 이후 더 강력한 모델이 등장하면 업데이트를 통해 계속 확장이 가능함을 보였습니다. 또한, SAM2-Large를 더 작은 SAM2-Base-Plus/Tiny로 대체할 경우 성능이 소폭 하락하지만, 전체적인 프레임워크는 여전히 기존 방법론보다 뛰어나며, Affordance-R1에서의 성능 저하보다 더 작은 성능 저하가 일어남을 어필하며 방법론의 강인성을 어필합니다.
Conclusion
해당 논문은 affordance를 예측하는 데 학습이 불필요한 프레임워크 A4-Agent를 제안합니다. high-level reasoning과 low-level grounding을 분리함으로써, reasoning에는 VLM, grounding에는 VFM을 활용하였으며, Imagination 매커니즘을 제안하여 상호작용에 대한 시각화를 통해 추론을 보조할 수 있음을 확인하였습니다. 또한 다양한 실험을 통해 해당 방법론이 다양한 벤치마크에서 뛰어난 성능을 보임을 입증하였습니다.