안녕하세요 이번에 리뷰할 논문은 CoRL에 2022년에 발표된 RECON: Rapid Exploration Controllers for Outcome-driven Navigation 입니다. 저어번에 리뷰한 ViKiNG에서 얕게 다루고 넘어갔던 내용들이 RECON에 자세하게 다룬 것 같아서 좀 깊이 있게 이해해보고자 읽게 되었습니다. 해당 논문도 큰 흐름은 지금까지 리뷰했던 ViNT,NoMaD,ViKiNG등과 다 비슷하다고 보시면 좋을 것 같습니다 마찬가지로 목표 이미지가 주어졌을 때 지도 없이 처음 보는 환경에서 어떻게 빠르게 목표까지 내비게이션을 수행할 수 있는가를 연구한 논문이고, 아마 이 논문이 지금까지 리뷰했던 논문 중에서는 가장 먼저 발표된 논문일텐데 지금까지 리뷰했던 논문들에서 자연스럽게 이어지는 아이디어들의 초기 형태를 보는 느낌으로 읽어주셨으면 좋겠습니다.
리뷰 시작하도록 하겠습니다.
Introduction
RECON 논문은 Visual 기반 내비게이션에서 새로운 환경에 대해 얼마나 강인하게 잘 작동할 수 있는지에 대한 문제를 다루는 연구라고 보시면 될 것 같습니다. 저자들은 실제 환경에서 로봇이 안정적으로 내비게이션을 수행하기 위해서는, 단순히 잘 가는 정책을 학습하는 것만으로는 부족하고, 오프라인 학습데이터 셋과 실제 환경 간의 차이를 이해할 줄 알아야하고, 예를 들어 학습데이터가 8월에 수집되었는데 실제 운행은 12월이라면 차이가 있을 테니 이에 대한 차이를 이해할 줄 알아야하고, 주행 가능성을 판단하고 이를 능동적으로 탐색할 수 있어야한다고 이야기 합니다.
저자들은 이 문제를 완전히 새로운 환경에서 목표를 어떻게 찾을 것인가? 라는 관점에서 즉, 목표 위치가 이미 지도 상에 주어져 있고, 그저 거기까지 잘 가는 문제가 아니라, 아예 처음 보는 환경에서 목표 이미지 하나만 주어졌을 때 그 목표를 발견하는 문제로 설정하고 이를 해결하려고 합니다.
저자들은 서로 다른 환경이라 하더라도 물리적 구조로 보았을 때는 유사성이 존재한다는 점을 활용하여(예를 들어 길처럼 보이는 공간, 사람이 걸어 다닐 수 있을 법한 영역, 코너나 막다른 공간 같은 구조는 환경이 바뀌어도 반복해서 등장하는 것과 같은) 학습 기반 접근을 통해 이러한 공통된구조를 사전에 학습해두면, 새로운 환경에서도 훨씬 빠르게 탐색을 수행할 수 있을 것이라고 보는 것입니다.

이러한 문제 설정 하에 RECON은 서 위 피규어 1에 나온 Clearpath Jackal이라는 모바일 로봇을 사용해 실제 환경 실험을 수행합니다. 로봇은 여러 다른 환경에서 수집된 대규모 오프라인 주행 데이터를 가지고 이를 통해 저자들이 표현하는 일반적인 내비게이션 어포던스를 학습합니다. 여기서 어포던스라는 것은, 특정 장면을 보았을 때 여기는 갈 수 있어 보인다 / 여긴 막혀 있을 가능성이 크다 같은 판단이라고 이해하시면 좋을 것 같습니다.
RECON의 핵심적인 접근법은 정보 병목구조를 이용해 목표에 대한 압축된 표현을 학습하는 것입니다. 이 잠재적 목표 모델은 단순히 목표 이미지를 그대로 기억하는 것이 아니라, 내비게이션에 실제로 필요한 정보만을 남기도록 학습됩니다. 이 문장에서 정보 병목 구조라던가 잠재적 목표 모델이라던가 이런 워딩은 논문에서 그대로 가져온 것이라 부연 설명을 좀더 드리면, 일단 정보 병목은 말그대로 정보를 병의 목처럼 압축 시키는 구조인 인코더 구조를 저렇게 표현하는 것 같습니다. 따라서 결국 현재 관찰 이미지와 목표 이미지를 저 정보 병목 구조를 태우게 되면 latent 공간내에 z벡터로 압축 요약되는 구조로 표현이 되고 저 z 벡터를 잠재적 목표로 표현하기 때문에 잠재적 목표 모델이라고 저자들은 표현을 하는 것 같습니다. 저자들 설명에 따르면 이 latent 표현 안에는 지각 정보, 어떤 공간이 이동 가능한지에 대한 priors, 그리고 짧은 시간 범위에서의 제어 전략까지 함께 녹아 있다고 볼 수 있습니다.
또 하나 중요한 구성 요소는 non-parametric memory입니다. 이것도 말이 어려운데 단순히 Topology map 이라고 생각하면 좋을 것 같습니다. RECON은 새로운 환경에대한 탐색 정보를 이 메모리에 누적하면서, 탐색과 내비게이션을 점점 더 효율적으로 수행하게끔 합니다.
위와 같은 모델 구조나 토폴로지 그래프를 통해 RECON은 짧은 시간(수 분 단위)의 탐색만으로도 새로운 환경에서 목표 지점으로 이동할 수 있는 행동을 만들어낸다는 점을 주요한 기여로 제시합니다. 특히 저자들이 강조하는 핵심 기여는 이전에 한 번도 관측하지 않은 환경에서 사용자가 지정한 목표 이미지를 발견하기 위한 탐색 전략을 제안했다는 점입니다. 이 과정에서 RECON은 기하학적 지도나 구조화된 센서 정보 없이, 오직 RGB 이미지 관측 스트림만을 사용합니다.
저자가 반복해서 강조하는 또 하나의 포인트는, 목표 이미지에 대한 압축된 표현(z 벡터)이 단순히 메모리를 줄이기 위한 것이 아니라, 강인한 탐색을 가능하게 하는 핵심 메커니즘이라는 점입니다. 예를 들어, 같은 장소를 아침과 저녁처럼 전혀 다른 조명 조건에서 촬영한 목표 이미지가 주어지더라도, 두 이미지는 latent 공간에서는 충분히 가깝게 표현되어야 하고, 그래야만 모델이 일관된 행동을 만들어낼 수 있다고 합니다. 즉 진짜 이 목표로 가기 위해 필요한 정보만 압축하여 학습이 되었기 때문에 이러한 성질은 시간대나 계절에 따라 랜드마크의 외형이 크게 바뀌는 실제 환경에서는 사실상 필수적이라고 볼 수 있습니다.
실험은 RECON은 실제 이동 로봇에 적용해서 8개의 서로 다른 개방형 실환경에서 총 100시간 이상의 실험을 통해 평가했다고 합니다. 결과적으로 RECON은 새로운 환경에서 단 20분간의 탐색만으로도 최대 80m 떨어진 목표 이미지를 발견할 수 있음을 보였고 조명 변화나 새로운 장애물이 등장하는 상황에서도 비교적 안정적인 성능을 유지하는 모습을 보여줬다고 합니다.
Method
메서드 파트 부분입니다. 저자들은 RECON의 전체 과정을 3단계로 나눕니다.
- 오프라인 데이터로부터의 학습 : 여러 과거 환경에서 수집된 주행 데이터(비디오 궤적)를 이용해서 보통 이런 장면에서는 보통 이렇게 움직여야 해 라는 일반적인 내비게이션 능력과 시각 입력을 압축한 표현을 학습하게 됩니다.
- 새로운 환경에서의 지도 구축 : 새 환경에 들어가면, 직접 탐색을 하면서 토폴로지 그래프 형태의 메모리를 쌓아갑니다. SLAM처럼 정밀한 metric map은 아니지만 어떤 관측끼리 연결되어 있고 서로 얼마나 떨어져 있는지(시간적 거리)정도는 메모리로써 기억을 해둡니다.
- 새로운 환경에서의 목표 지점 내비게이션 : 일정 시간 탐색이 끝나면 이제 이미 구축된 그래프와 학습된 latent goal model을 이용해 목표 이미지를 향해 경로를 찾아가게 됩니다.
결국 오직 카메라에서 보이는 이미지 시퀀스와 과거에 이런 이미지였을 때 이런 식으로 움직였더니 이렇게 바뀌더라라는 경험 데이터만을 가지고 내비게이션을 배우게 됩니다. 그리고 저자들은 궤적 데이터의 퀄리티에 대해 아무런 가정을 하지 않습니다. 예를들어 사람이 조이스틱으로 막 몰아본 데이터여도 괜찮고, 로봇이 자기 마음대로 랜덤 워크를 한 데이터여도 괜찮고, 그냥 프리셋 정책으로 대충 돌아다닌 것이라도 상관없다고 합니다. 꼭 똑똑한 expert demonstration일 필요 없다는 거고,
그저 로봇이 어떻게 움직였고, 그때 시각 관측이 어떻게 바뀌었는지만 충분히 많으면 된다 라는 것입니다.
데이터 수집 및 라벨링

데이터를 어떻게 모았는지 설명드리도록 하겠습니다. 저자들은 time-correlated random walk 기반의 자기지도식(self-supervised) 데이터 수집 전략을 사용합니다.
쉽게 말하면, 로봇이 완전한 white noise 랜덤이 아니라, 어느 정도 연속성을 가진(random walk 스타일의) 행동을 하면서 여러 환경을 이리저리 돌아다니게 만든 뒤 그때의 비디오 궤적들을 전부 데이터셋으로 모은다 라고 이해하시면 좋을 것 것 같습니다. 이 데이터셋은 18개월에 걸쳐 여러 실제 실외 환경에서 수집되었고, 그 과정에서 계절 변화, 조명 변화 등으로 인한 굉장히 다양한 외형적 변화를 포함하고 있다고 합니다. 예를들어 여름에 비오는 날 찍힌 길과 겨울에 눈오는 날 찍힌 같은 길이 완전히 다른 이미지로 들어와 있는 셋업입니다. 이렇게 다양한 조건에서 수집된 데이터를 바탕으로 latent goal model을 학습했기 때문에, 나중에 실험결과 파트에서 보여줄 것이지만 새로운 계절, 장애물 , 조명 등 에서도 모델이 비교적 안정적으로 동작할 수 있었다고 보시면 될 것 같습니다.
Train
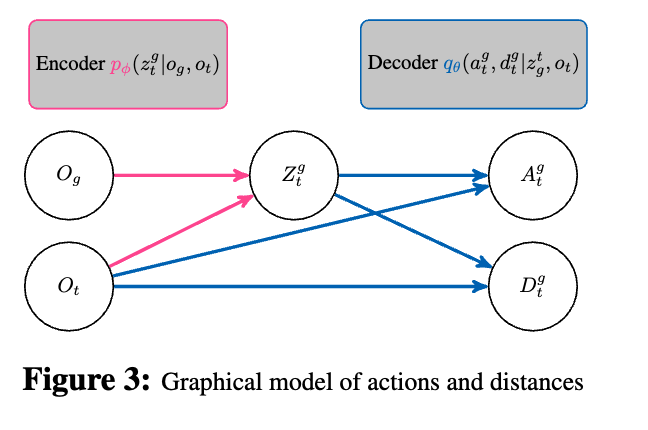
RECON의 가장 중요한 아이디어 중 하나는 앞서 언급하였지만 목표 이미지를 그대로 쓰지 않고 지금 상황에서 의미 있는 목표 표현으로 압축한다 것입니다. 실제 환경에서는 목표 이미지 o_g 와 현재 관측 o_t 사이에 많은 task-irrelevant factors이 존재한다고 합니다. 내가 목적지 까지 찾아가야하는 태스크와는 무관한 요인인데 예를 들어 시간대 변화, 날씨 및 조명 변화, 카메라 노출 차이, 주변에 생겼다 사라진 임시 장애물 등이 될 수 있을 것 같은데, 아무리 데이터가 다양하고 많다 한들 이런 요소들을 그대로 표현 공간에 담아버리면,
모델은 같은 장소지만 외형이 다른 경우를 같은 목표로 잘 인식하지 못할 수 있으니 RECON에서는
정보 병목(Information Bottleneck)구조를 사용해서 목표 이미지 o_ 를 현재 관측 o_t을 가지고 잠재 목표 표현 z^g_t 로 압축합니다.
핵심은 이 표현이지금 내가 이 위치에 있을 때, 이 목표를 향해 어떤 행동을 해야 하는지 와 얼마나 멀리 떨어져 있는지를 예측하는 데만 유용하면 된다는 점입니다.
바로 Loss function을 설명드리도록 하겠습니다.
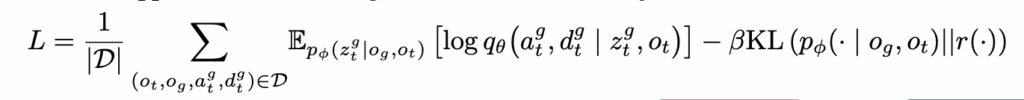
여기서 loss function의 구조를 보면,
인코더 : p_\phi(z^g_t \mid o_g, o_t)
디코더 : q_\theta(a^g_t, d^g_t \mid z^g_t, o_t)
사전 분포 : r(z)=\mathcal{N}
\mathcal{D}는 (o_t, o_g, a^g_t, d^g_t) 네 요소로 구성된 궤적 데이터셋을 나타낸다고 보시면 됩니다.
일단 첫 번째 항 \mathbb{E}[\log q_\theta(\cdot)] 은
현재 관측 o_t 가 주어졌을 때, latent goal z^g_t 가
행동 a^g_t 과 목표까지의 거리 d^g_t 를 예측하는 데 필요한 정보를
잘 요약해서 가지고 있는지를 학습시키는 항이라고 보시면 될 것 같습니다. 결과적으로 디코더가 출력하는 액션과 거리 예측 오차를 최소화하도록 유도하면서 z가 navigation에 쓸모 있는 표현이 되도록 만드는 항이라고 이해하시면 좋을 것 같습니다.
두 번째 항인 KL 항은 latent goal 표현이 특정 목표 이미지에 과도하게 종속되지 않도록 제한을 거는 역할을 한다고 보시면 좋을 것 같습니다. 저번 ViKiNG 리뷰에서도 언급하였지만 이 항은 KL을 통해 인코더가 생성하는 z의 분포가 사전 분포 \mathcal{N}(0,I) 와 너무 멀어지지 않도록 규제함으로써 목표 이미지가 주어지지 않은 탐색 상황에서도 prior에서 샘플링한 latent가 의미 있는 subgoal로 해석될 수 있도록 만들어줍니다. 어떻게 보면 KL 항은 RECON이 latent sampling 기반 탐색을 가능하게 만드는 핵심 장치라고 이해하시면 될 것 같습니다.
deployment
지금까지는 로봇이 지금 위치에서 특정 subgoal까지 어떻게 이동할 것인가라는 비교적 로컬한 제어 능력을 학습하는 과정을 다뤘다면 여기 절에서는 그 로우레벨 능력을 바탕으로 새로운 환경 전체를 어떻게 탐색라고 원하는 목표 지점까지 도달할 수 있는가에 대해서 설명드리도록 하겠습니다.
앞에서 언급하였지만 RECON의 두 번째 핵심 구성 요소는 토폴로지 메모리 입니다.
로봇이 새로운 환경을 탐색하면서 직접 가봤던 위치들을 노드로 저장하고, 그 사이의 관계를 거리 예측값으로 연결해 나가는 그래프 형태의 메모리고 보시면 될 것 같습니다.
RECON에서 탐색 과정에서 중요한 것은 지금 이 시점에서, 어떤 서브골을 향해 움직이는 게 가장 유리한가를 선택하는 것인 것 같습니다. 다음 서브골을 선택하는 과정에서 로봇은 앞서 학습한 latent goal model을 사용해서 다음에 방문할 만한 노드를계속해서 제안하고 그 서브골을 향해 일정 시간 동안 실제로 이동하면서 데이터를 수집하면서 이동을 합니다. 여기서 중요한 점은 RECON에서 서브골은 더 이상 이미지가 아니라 latent 변수 z 로 표현된다는 것입니다.
이 latent 서브골은 두 가지 방법으로 얻어질 수 있습니다.
목표 이미지가 주어졌을 때 사후분포 p_\phi(z \mid o_t, o_g) 에서 샘플링, 즉 그냥 내가 이곳이 왔던 곳이라 토폴로지 맵이 있다면 서브골이 있을 테니 이 서브골을 통해 샘플링을 한다는 것이고 만약에 내가 와본 곳이 아니어서 서브골 자체도 모른다면 사전분포 r(z)= \mathcal{N}(0,I)에서 샘플링하여 이를 서브골 z로 활용하게 됩니다. 따라서 이렇게 선택된 서브골 z 와 현재 관측 o_t 가 주어지면, 디코더 q_\theta(a_t, d_t \mid z, o_t)가 지금 취해야 할 액션 값이랑 해당 서브골까지의 거리를 동시에 예측하게 됩니다.
실제 새로운 공간에 로봇이 놓여졌을 때 어떻게 동작하는지 탐색 관점에서 자세하게 설명을 드리도록 하겠습니다. 먼저 RECON의 탐색 전략은 전통적인 frontier-based exploration 아이디어와 비슷하다고 합니다. 그래프의 각 노드는 내비게이션 목표로 얼마나 자주 선택되었는지를 기준으로 관리되면서
선택 횟수가 적은 노드일수록 아직 충분히 탐색되지 않은 프론티어로 간주됩니다.
이때 RECON은 상황에 따라 세 가지 행동 모드 중 하나를 선택합니다.
(i) Feasible Goal : 지금 목표로 바로 갈 수 있음
만약 로봇이 현재 위치에서 이 목표는 충분히 도달 가능하다라고 판단하면, 굳이 새로운 탐색을 하지 않고 목표 그 자체를 서브골로 채택합니다. 이 판단의 기준은 목표 임베딩 z^g_t 가 사전분포 r(z) 하에서 얼마나 높은 확률을 갖는지를 보는 것인데. 만약r(z^g_t) 가 크다면 지금 보고 있는 장면과 목표 이미지의 관계가 모델이 학습 중 자주 봤던 패턴(in-distribution)이라는 의미니깐 모댈이 거리 예측도 믿을 수 있고, 바로 가도 될 것 같다는 판단하게 되는 것입니다.
결국 RECON은 latent 공간에서의 확률을 이용해 이 목표가 지금 상황에서 현실적인지”를 판단한다라고 이해하시면 좋것 같습니다.
(ii) Explore at Frontier : 여기가 끝자락(프론티어)이니, 새로운 방향으로 가야함
만약 로봇이 현재 위치한 노드가 그래프 상에서 가장 덜 탐색된 프론티어에 가깝다면,
RECON은 이때 prior r(z) 에서 latent 서브골을 샘플링합니다.
지금 내가 있는 곳이 내가 만든 토폴로지 맵에서 끝자락에 위치하니 이 근처에서 갈 수 있을 법한 새로운 방향 하나 만들어서 가보자라는 식으로 서브골을 향해 가게 되는데 여기서 이 서브골이 완전히 무작위 행동이 아니라 이미 학습된 latent goal 분포에서 나온 도달 가능해 보이는 방향이라는 것입니다.
그래서 랜덤 액션을 쓰는 기존 탐색 방식들보다 훨씬 효율적으로 탐색이 진행이 된다고 보시면 됩니다. 여기서 도달 가능해 보이는 방향으로 샘플링이 가능하도록 하게 하는 것이 손실함수의 두번째 KL이 적용이 된 항이라고 보시면 됩니다.
(iii) Go to Frontier : 저쪽 덜 본 곳으로 직접 가도록 함
이 경우는 현재 위치는 프론티어가 아니지만 근처에 덜 탐색된 이웃 노드가 존재하는 경우라고 보시면 좋을 것 같습니다. 이때는 굳이 새로운 latent를 샘플링하지 않고, 사후 분포에서(서브골 알고 있음)가장 덜 탐색된 이웃 노드 자체를 서브골로 설정하여 이동하게 됩니다.
결과적으로 이렇게 이동은 SubgoalNavigate 루틴을 통해 고정된 시간 동안 실행되고 roll-out이 끝나면 도착한 위치가 그래프에 노드로 추가되고 방문 횟수가 갱신되고 토폴로지 맵에새로운 엣지가 연결됩니다. 이 과정을 반복하면서 토폴로지 메모리는 점점 환경을 더 잘 커버하게 됩니다.
설명했던 알고리즘은 아래와 같습니다.

이제 바로 실험파트로 넘어가도록 하겠습니다.
Experiments
이제 실험 결과에 대해 설명드리도록 하겠습니다.
RECON의 실험은 크게 다음 네 가지 질문에 답하는 형태로 구성되어 있습니다.
Q1. 로운 환경에서의 시각적 목표 발견(visual goal discovery) 측면에서, RECON은 기존 연구 방법들과 비교하여 어떤 성능을 보이는가?
Q2. 탐색 이후, RECON은 자신이 획득한 경험을 활용하여 목표 지점까지 효율적으로 내비게이션할 수 있는가?
Q3. 실제 환경에서 흔히 발생하는 시각적 교란이나 환경 변화에도 얼마나 강인한가?
Q4. 정보 병목 기반 latent 샘플링, 그리고 토폴로지 메모리 같은 구성 요소들이 실제로 얼마나 중요한 역할을 하는가?
Q1, Q2
먼저 저자들은 RECON을 다양한 야외 환경에서 평가하였습니다.
주차장, 교외 주거 지역, 보도, 카페테리아 등 실제 로봇이 마주할 수 있는 환경들에서 평가했고
학습에 사용된 환경과는 완전히 다른 unseen환경에서 실험을 진행했다고 합니다.
저자가 설정한 5가지의 베이스라인 모델을 아래와 같습니다.
- PPO + RND : 강화학습에서 많이 쓰이는 novelty 보너스 기반 탐색 방식의 대표적인 방법
- InfoBot : RECON과 마찬가지로 정보 병목 구조를 사용하지만 토폴로지 메모리는 사용하지 않는 방법.
- Active Neural SLAM (ANS) : meric 맵을 기반으로 커버리지 최대화를 수행하는 전통적인 SLAM 계열 방식
- ViNG : 무작위 액션을 실행해서 토폴로지 그래프를 점진적으로 쌓아가는 방식
- ECR (Episodic Curiosity) : 프론티어에서 랜덤 액션을 수행하는 방식이고 RECON의 goal rollout을 제거한 모델

일단 결과적으로는 RECON은 모든 기준선 대비 가장 빠르고 안정적으로 목표를 발견하고, 다시 그 목표로 돌아오는 데에도 가장 뛰어난 성능을 보입니다.
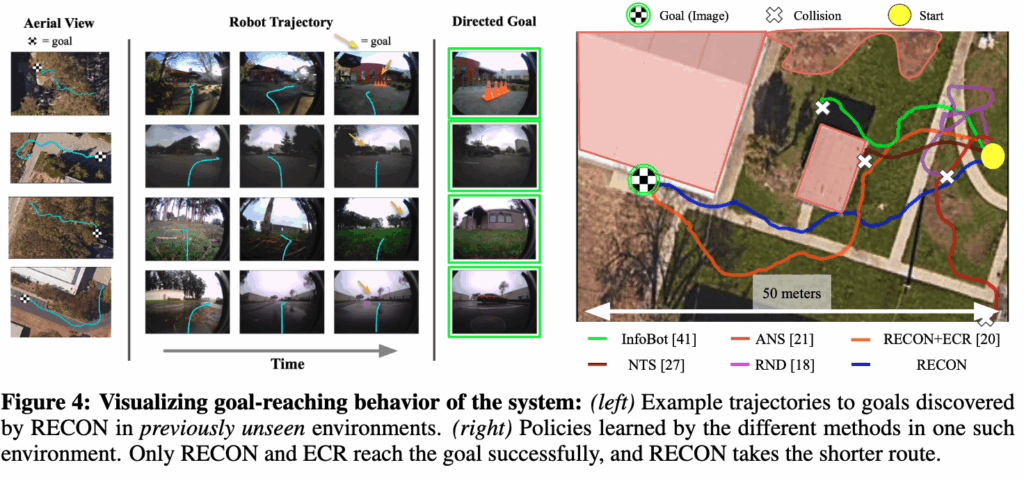
그리고 Q2에 해당하는 한 번 찾은 목표를 다시 잘 갈 수 있느냐 에 대한 결과도 확인할 수 있는데,RECON 계열 모델들은 탐색 과정에서 구축한 토폴로지 메모리를 활용하여 한 번 발견한 목표로의 경로를 다시 이동 할 수 있습니다. 탐색이 끝난 뒤에는 단순히 헤매는 것이 아니라 경험을 활용해 훨씬 짧고 안정적인 경로로 목표에 도달할 수 있는 모습을 보입니다.
반면에 다른 기준선 방법들은 가장 단순한 환경을 제외하면 한 번 찾았던 목표조차 다시 찾아가지 못하는 경우가 대부분이고 위 그림 4를 보면 체커보드 목표로 안정적으로 이동한 방법은 RECON 계열뿐이였고 다른 모든 방법들은 중간에 충돌하거나 경로를 유지하지 못했다고 합니다. 심지어 RECON은 ECR 절제 모델 대비 약 30% 더 짧은 시간에 목표에 도달하는 모습을 보입니다.
Q3
실제 야외 환경에서의 내비게이션에 있어서 환경 변화는 항상 존재 합니다.
차량이나 보행자처럼 계속 움직이는 동적 장애물도 있고, 계절 변화나 시간대 차이에 따라 같은 장소라도 외형이 완전히 달라지는 경우가 흔하기 때문에 실사용 관점에서 중요한 것은 장면이 조금 바뀌었을 때도, 이 로봇이 같은 장소로 인식하고 같은 행동을 할 수 있는지 인 것 같습니다.
특히 RECON처럼 토폴로지 메모리를 사용하는 방법에서는 그래프의 노드가 단순히 이미지 하나로 저장되기 때문에 어떻게 보면 더 중요하게 다뤄져야하는 부분이 아닐 까 싶습니다. 이를 무시하게 되면 조명 변화나 일시적인 장애물 때문에 표현이 흔들리면 메모리 자체가 아무런 쓸모가 없을 수 있기 때문입니다.
따라서 저자들은 이러한 강인성을 검증하기 위해 저자들은 비교적 직관적인 실험을 설계합니다.
먼저 로봇을 새로운 junkyard 환경에 배치한 뒤 파란색 덤프스터가 포함된 목표 이미지를 향해 탐색을 수행하도록 합니다. 그 이후에는 추가적인 탐색은 전혀 하지 않고 이미 학습된 goal-reaching policy만을 사용합니다. 이 상태에서 이전에 한 번도 보지 못한 장애물 , 서로 다른 조명·기상 조건 을 순차적으로 환경에 추가하여 로봇이 여전히 목표에 도달할 수 있는지를 확인하는 실험을 진행합니다.

결과적으로 제시된 그림 5를 보면,
이러한 변화가 있음에도 불구하고 로봇은 모든 조건에서 목표까지 안정적으로 도달하는 모습을 확인 할 수 있습니다. RECON이 단순히 본 적 있는 장면을 다시 본 것처럼 착각해서 움직이는 게 아니라 이 서브골로 가려면 이렇게 가야해 라는 실제로 필요한 정보만을 latent 표현으로 유지하고 있다는 점을 보여주는 실험이라고 보시면 좋을 것 같습니다.
예를 들어 조명 변화 는 목표까지의 실제 이동 경로에는 영향을 주지 않고(즉, latent 표현에서 자연스럽게 무시됨) 또 일시적인 장애물 같은 경우는 로컬 제어 단계에서 회피되며 전체적인 목표 인식에는 큰 영향을 주지 않는 이런 동작이 가능했던 이유를 저자들은 정보 병목 구조 덕분이라고 설명합니다.
Q4
앞선 실험들에서 RECON이 전반적으로 좋은 성능을 보였는데 여기서는 도대체 어떤 설계가 실제 성능을 만들어냈는가? 를 보여주는 실험입니다. RECON을 구성하는 여러 요소들 latent goal sampling, 정보 병목, 토폴로지 메모리 중 무엇이 얼마나 중요한지를 ablation 실험을 했다고 보시면 좋을 것 같습니다.
먼저 저자들은, prior에서 latent goal을 샘플링해서 이동하는 방식 자체가 탐색에 정말 도움이 되는지
를 확인하기 위해 비교적 단순한 실험을 합니다.
환경의 토폴로지 그래프는 아예 만들지 않은 상태에서, RECON을 새로운 환경에 배치해 5분간 무지향 탐색(을 수행하게 합니다. 이때 비교 대상은 두 가지입니다.
- 프론티어에서 무작위 행동 시퀀스를 실행하는 경우
- 샘플링된 latent goal을 향해 roll-out을 수행하는 경우
결과적으로는 latent goal을 향해 roll-out하는 방식이 약 5배 빠르게 환경을 커버하는 것을 확인 할 수 있습니다. 결국 RECON의 탐색은 그냥 랜덤으로 돌아다니는 탐색이 아니라 학습된 분포 내에 가볼 만한 방향을 찍고 가보는 탐색이기에 이런 결과를 보인다 라는 것을 보여주는 것 같습니다.
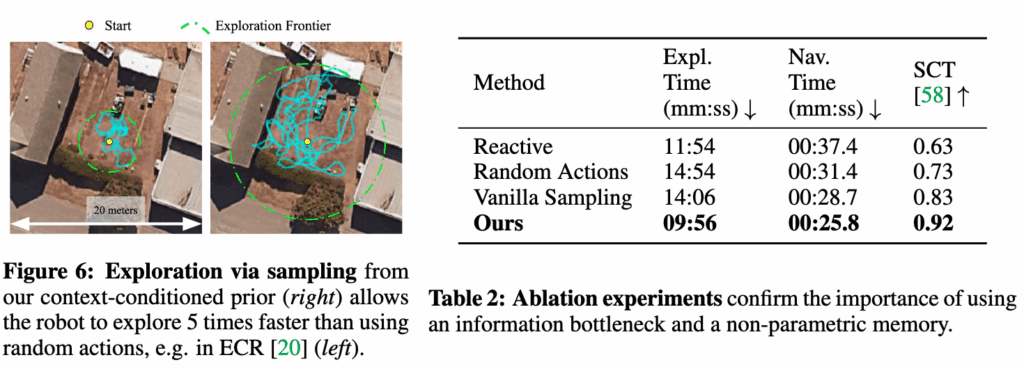
다음으로 저자들은 RECON의 핵심 구성 요소들을 하나씩 제거한 변형 모델들을 비교합니다.
토폴로지 메모리를 완전히 제거하고, 현재 관측만을 기반으로 즉각적인 행동을 결정하는 방식의 실험(Reactive) 그리고 프론티어에서 goal rollout 대신 랜덤 액션 시퀀스를 실행하는 변형의 실험(Random Actions)사실상 ECR 기준선과 동일함. 그리고 정보 병목 없이 단순히 목표 조건부 정책과 거리 예측만 학습한 방식의 실험(Vanilla Sampling) 압축된 latent goal 표현을 학습하지 않는 구조라고 이해하시면 좋을 것 같습니다.
일단 결과적으로 먼저 Vanilla Sampling의 성능 저하가 매우 크게 나타납니다.
joint prior에서 latent goal을 샘플링하긴 하지만, 먼 거리의 목표를 거의 발견하지 못하는 모습을 보이는데, 이에 대해 저자들은 정보 병목이 없는 경우 latent 표현이 태사크와 무관한 시각 정보까지 함께 담아버리게 되고 그 결과 샘플링된 goal들이 탐색에 실제로 도움이 되지 않는 방향으로 작용한다고 분석합니다.즉, 샘플링 자체보다, 무엇을 샘플링하느냐가 중요하는 점을 보여주는 실험결과로 보시면 좋을 것 같습니다. 그리고 Reactive 방식은 탐색 단계만 놓고 보면 의외로 큰 성능 저하는 보이지 않습니다.
이는 goal sampling 전략 자체가 그래프 없이도 탐색을 일정 부분 커버할 수 있음을 보이는데, 결정적인 차이는 recall 단계,즉 이미 발견한 목표로 다시 이동하는 능력에서 발생하는 모습을 보입니다.
토폴로지 메모리가 없는 경우, 한 번 찾았던 목표조차 다시 찾아가지 못하는 경우가 많아지고 결국토폴로지 메모리가 RECON의 내비게이션 성능에 핵심적 요소임을 보여줍니다.
Conclusion
실제 로봇 운용 환경에서는 새로운 환경에서 데이터를 새로 수집하는 비용이 매우 크고 반면에 과거 여러 환경에서 쌓아온 경험은 충분히 활용할 가치가 있다라는 점에서 RECON은 , 과거 환경에서 학습한 내비게이션에 중요한 공통된 구조를 새로운 환경 탐색에 재활용하는 방향으로 문제를 해결하려고 하는 것 같았습니다. 결국 이런 관점은 ViNT, NoMaD, ViKiNG으로 이어지는 흐름과도 자연스럽게 이어지는 것 같았고 해당 계열 연구의 출발점에 가까운 논문이라는 점에서도 의미가 있는 것 같다라는 생각이 듭니다.
이만 리뷰 마무리하도록 하겠습니다. 감사합니다.
안녕하세요 우현님 좋은 리뷰 감사합니다.
읽다보니 데이터를 18개월 촬영해서 논문하나 썻다는게 참.. 많은 생각이 들게 하네요, 질문이 하나 있는데
“지금 내가 있는 곳이 내가 만든 토폴로지 맵에서 끝자락에 위치하니 이 근처에서 갈 수 있을 법한 새로운 방향 하나 만들어서 가보자라는 식으로 서브골을 향해 가게 되는데 여기서 이 서브골이 완전히 무작위 행동이 아니라 이미 학습된 latent goal 분포에서 나온 도달 가능해 보이는 방향이라는 것입니다.” 서브골을 향해 간다는게 어떤 말인지는 알겠으나, 토폴로지 맵에서 끝자락이라면 사실 아예 처음보는 뷰 이거나 모델이 확신을 가지지 않는 길들이 나올수도 있을텐데 그때 되돌아가지 않고 새로운 곳을 탐험한다고 이해하면 될까요?