안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 LVU연구인 Vgent입니다. NIPS2025에서 spotlight로 선정된 연구입니다.
Introduction
대규모 비디오 언어 모델(Large Video Language Model, LVLM)은 영상과 자연어를 동시에 다루며 짧은 영상에 대해 뛰어난 이해 및 추론 능력을 보여주고 있지만, 긴 영상에 대해서는 아직 성능이 좋지 않습니다. 수십분에 달하는 긴 영상은 방대한 수의 프레임으로 이루어져 있기에 모델의 context 한계를 넘어서는 토큰을 입력해야하며 긴 시간에 걸친 연속적인 상황 정보를 이해해야한다는 어려움이 있기 때문입니다. 일반적인 짧은 비디오와는 다르게 30분 길이의 긴 비디오는 20만개 이상의 토큰을 필요로하기에 일반적인 LVLM 모델의 입력 context의 한계를 크게 초과합니다. 기존 연구들은 프레임을 sparse하게 샘플링하거나 토큰을 압축하는 방법(token compression)을 통해 입력 길이를 줄였지만, 이는 시각 정보의 손실이 불가피하고 영상의 세부 정보를 파악하기 어렵다는 단점이 존재합니다. 이로 인해 긴 영상에서의 질문에 대해 일관된 좋은 성능을 내지 못하고 질문, 비디오와 질문에 따라 성능의 편차가 심하다는 문제가 존재합니다.
검색 기반 증강 생성(Retrieval-Augmented Generation, RAG)는 자연어 처리 분야에서 대규모 자연어 모델(Large Language Model, LLM)의 context 한계를 극복하기 위해 제안된 방법으로 질문과 관련된 외부 지식을 활용하여 모델의 입력에 추가하는 것으로 성능을 개선하는 방법입니다. 최근에는 이러한 RAG를 비디오에 활용하려는 시도들이 등장했습니다. 긴 영상의 caption을 활용하여 관련된 부분을 검색하여 답변을 하는 방법입니다. 하지만, RAG를 활용하여 영상을 이해하는 방법에는 몇가지 문제가 존재합니다. 첫번째로 긴 비디오를 여러 클립으로 잘라서 각각을 하나의 문서로 활용하여 검색하는 기존의 방법은 긴 비디오 속 객체들의 연속성 혹은 시간적 맥락이 연결이 되지 않아 정확한 추론에 방해가 된다는 문제가 존재합니다. 두번째로 RAG를 활용하는 긴 비디오 이해는 GPT와 같은 거대 폐쇄형 LLM(오픈소스로 공개되지 않은 LLM)에 의존하여 multi-turn 상호작용과 계획을 수행하는 planning agent 방식을 사용하는데 이는 비용이 높고, 또 유연성이 떨어진다는 단점이 존재합니다. 마지막으로 많은 기존 방법론들이 긴 비디오 내에서 일부 핵심 프레임만을 활용하기 때문에 영상의 장면 전환이나 맥락적 연결성을 놓친다는 문제가 존재했습니다. 따라서 RAG를 비디오에 활용함에도 불구하고 기존 긴 비디오 이해 연구의 단점인 긴 비디오의 정확한 내용을 파악하고 일관된 추론을 하지 못한다는 단점을 극복했다고 말하기 어렵습니다.
이러한 문제를 해결하기 위해서 저자는 Vgent 방법론을 제안합니다. Vgent는 그래프 기반 검색, 추론, 증강, 생성RAG 프레임워크로 추가적인 훈련 없이 기존 LVLM의 성능을 향상시키는 방법론 입니다. 핵심 아이디어는 그래프 기반 영상 표현을 활용하여 영상을 구조적 그래프 형태로 표현하고 비디오 클립을 노드로 삼아 공통적으로 등장하는 객체나 장면을 연결하여 비디오 클립 사이의 의미적 관계와 시간적 의존성을 보존합니다. 이렇게 구축된 영상 지식 그래프(video knowledge graph)는 오프라인으로 한번만 만들어두면 동일한 영상에 대해 여러 질문이 들어오게 되더라도 그래프를 활용하여 여러 질문을 재사용할 수 있어 매 질문마다 영상을 처음부터 처리하지 않아도 된다는 효율성 또한 제공할 수 있습니다.
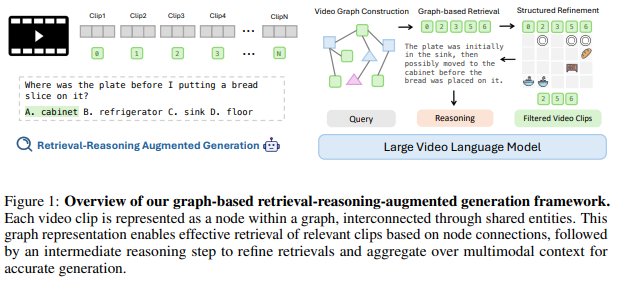
Figure 1은 그래프 기반의 RAG 프레임워크를 보여주고 있습니다. 각 클립을 하나의 노드로 표현하고, 서로 공통된 객체 혹은 장면을 공유하는 경우 노드로 연결하게 됩니다. 이러한 그래프 표현은 단순히 클립들의 순서를 나열하는 것이 아니라 영상 속 객체의 등장, 이동, 상호작용과 같은 시간적 연속성과 의미적 연속성을 포착할 수 있습니다. 질문이 주어지면, Vgent는 먼저 질문에서 핵심 키워드를 추출합니다. 추출한 핵심 키워드를 그래프에 존재하는 정보와 매칭하여 관련 클립을 검색합니다. 저자는 이렇게 검색하더라도 여전히 노이즈가 섞여 있을 수 있다는 것을 언급하며 이를 해결하기 위한 방법으로 구조적 추론(structured reasoning)을 도입합니다. 구조적 추론은 복잡한 질문을 구성 요소별로 나눈 후에 각 후보 클립 사이의 관련성을 검증합니다. 위 Figure1을 예시로 확인하면 먼저 질문의 핵심 요소들인 접시, 싱크대, 캐비닛, 빵이 어느 클립에 있는 지를 확인합니다. 그 후에 접시가 싱크대에서 캐비닛으로 이동하는 시간적 관계를 클립들을 통해 확인하고 결과를 정제합니다. 이러한 중간과정을 통해서 저자는 RAG의 노이즈를 줄이고 관련 클립들의 정보를 명시적으로 연결할 수 있습니다. 최종적으로는 LVLM이 명시적인 관련 정보를 활용하기에 보다 일관되고 맥락에 맞는 정확한 답변을 생성할 수 있습니다.

Figure 2는 Vgent의 파이프라인을 단계별로 보여주는 예시입니다. “영상 내 Zumba(줌바 댄스), clean and jerk(역도 동작), milking cow(소 젖짜기), playing trumbone(트롬본 연주)의 순서를 맞춰주세요”는 질문이 있을 때 먼저 “Zumba”, “clean”, “milking cow”, “trombone”과 같은 핵심 키워드를 추출합니다. 이어서 저자는 미리 추출한 DB로부터 핵심 키워드들에 해당하는 entity를 찾아 클립들을 후보로 가져옵니다. 위 예시에서는 5개의 클립(3,4,5,11,13)가 검색되었습니다. 그 다음 질문을 구조적으로 분해하여 각각의 키워드가 영상에 등장하는가와 같은 하위 질문(Q1, Q2, Q3, Q4)을 생성합니다. 그 후 각 하위 질문에 대해 예/아니오를 통해 검증을 수행합니다. 이 과정이 RAG의 노이즈를 최소화하는 과정입니다. 그 결과 각각의 핵심 키워드들을 포함하는 클립들로 정제할 수 있습니다. 그 다음 마지막으로 정도들을 모은 다음에 LVLM에 입력하는 것으로 최종 답변을 생성합니다. 그런데 위 예시에서 clean(청소)이라는 키워드와 clean and jerk(역도 동작)는 다른 의미를 갖고 있습니다. 이거는 의도한건지는 모르겠지만, RAG내 존재하는 노이즈를 보여주려고한 것 같습니다.
저자는 위 방법론을 다양한 데이터셋에서 다양한 크기의 모델로 실험하였으며, 기존 방법론들의 성능을 개선시키는 결과를 보여줍니다. 정리하면, 저자는 긴 비디오 이해를 위해 새로운 그래프 기반 RAG 프레임워크를 제안합니다. Vgent는 비디오 클립을 그래프의 노드로 표현하고, 핵심 entity를 통해 클립 사이의 관계를 연결합니다. 이를 통해 비디오 클립 사이의 의미적 관계와 시간적 의존성을 보존할 수 있습니다.
Method
Video Graph Construction
Vgent가 비디오 RAG를 활용하여 일관되고 정확한 답변을 생성하는 데에 있어 제일 중요한 부분은 결국 그래프로 구성된 오프라인 비디오 데이터베이스를 생성하는 것입니다. 먼저 비디오 전체를 일정 길이의 짧은 클립으로 분할합니다. 논문에서는 1FPS로 샘플링한 후에 64개의 프레임을 하나의 클립을 사용합니다. 이렇게하면 64초 길이의 클립을 얻을 수 있습니다. 각각의 클립이 오프라인 비디오 데이터베이스에서 하나의 노드가 됩니다. 각 클립을 LVLM에 입력하여 해당 클립의 핵심 정보를 추출합니다. 만약 클립에 자막이 있을경우, 자막이 추가되고 여러 entity를 추가합니다. 여기서 entity는 사람, 사물, 장소 등 주체나 행동 등 장면을 묘사하는 데에 필요한 핵심 단어들을 의미하며 장면을 설명하는 description도 핵심 정보에 포함됩니다. 위 방법을 통해서 클립마다 Entity와 Description 쌍을 생성하고 이를 클립의 정보로 활용합니다. 각 클립(노드)는 비디오의 노드 집합에 추가되고 클립마다 추출한 entity들을 전부 포함하는 전체 비디오의 글로벌 집합도 생성하여 entity를 추가합니다. 글로벌 집합 안에 entity가 존재하지 않는 경우에만 추가됩니다. 이렇게 전체 비디오의 entity를 추출하게되면 같은 entity를 공유하는 노드를 연결합니다. 이러한 그래프 구성을 통해 비디오 내 등장인물, 등장하는 객체 등이 재등장할 때 이를 명시적으로 그래프로 연결할 수 있으며 결과적으로 각 클립 사이의 의미적 연결성과 시간적 의존성을 확보할 수 있습니다. 이렇게 완성된 그래프는 추후 질의응답 때 효과적인 검색을 위해 사용됩니다.
Graph-based Retrieval
질의응답할 때 질문이 들어오면 먼저 문장에서 핵심 키워드를 추출합니다. 각각의 핵심 키워드는 질문에 담긴 중요한 객체나 사건, 인물 등을 식별할 때 사용됩니다. 앞선 Figure 1의 예시에서 확인할 수 있습니다. 논문에서는 LVLM에게 질문을 요약하여 핵심 단어들을 나열하도록 프롬프트를 통해 확보하며 이러한 키워드 집합을 K로 나타냅니다. 다음으로 추출된 키워드 K를 오프라인으로 생성한 데이터베이스 그래프 내 entity들과 비교하여 관련 클립 노드를 검색합니다. 구체적으로 각 키워드 k와 그래프의 전역 entity 집합 U에 있는 각 entity u의 설명 t_u간 유사도(similarity)를 계산하여 특정 임계치 \theta 이상인 유사한 entity들을 찾습니다. 유사도가 높은 entity u가 있다면 그 entity를 포함하는 모든 노드들을 후보 집합 R에 추가합니다. 이렇게 하면 질문에 언급된 중요한 요소들을 담고 있을 수 있는 후보 영상 클립들을 빠르게 골라낼 수 있습니다. 마지막으로 후보 노드들을 re-ranking하여 가장 관련성이 높은 N개를 선정합니다. 이때 re-ranking은 노드에 연결된 모든 정보들을 종합하여 평균 유사도를 계산하여 활용됩니다. 이때 N은 논문에서 20을 사용합니다.
Structured Reasoning
검색 단계에서 선정된 후보 클립들을 곧바로 LVLM에 모두 넣어 답변을 생성할 수도 있지만 저자들은 이러한 바로 답변을 생성하는 방식에는 문제가 있음을 지적합니다. 여러 클립을 한꺼번에 입력하면 정보 과부하로 인해 중요한 정보가 다른 내용에 묻힐 위험이 있습니다. 실제로 저자들의 오류 분석 결과 초기 검색된 클립들 중에 정답에 필요한 클립이 포함되어 있음에도 모델이 오답을 생성한 사례의 약 40%는 노이즈가 있는 클립의 방해로 인한 것이었다고 합니다. Vgent는 이를 개선하고자 최종 답변을 생성하기 전에 한 번의 중간 추론 단계를 거칩니다. Figure 2의 중간 하위 질문을 생성하여 reasoning하는 단계가 이 단계에 해당합니다. Divide and Conquer 전략으로 질문을 부분적인 하위 질문들로 세분화한 뒤에 구조화된 검증을 수행합니다. Introduction의 예시에서 설명했들이 예, 아니오로 대답할 수 있는 하위 질문을 생성하여 답변을 생성합니다. 이러한 검증 단계를 통해서 특정 클립이 질문에 관련이 있는 지 없는 지를 구분할 수 있습니다. 만약에 질문과 무관한 클립이 검증단계를 통해 필터링된 경우 해당 클립은 노이즈로 간주되고 최종 답변을 할 때에는 사용되지 않습니다. 이 단계를 통해 질문과 관련없는 노이즈들을 효과적으로 지울 수 있습니다. 마지막으로 남은 명시적으로 관련된 노드들만 남긴 후에 LVLM을 활용하여 하위 질문들에 대한 답변들을 요약, 종합하고 노드들에서 확인된 정보들을 바탕으로 context를 생성합니다. 최종 답변 생성 전 논리적으로 질문과 연관이 있는 질문들만을 연결하고 서술하는 것으로 바로 답변을 생성하던 기존 긴 디비오 이해 연구들에 비해 풍부한 정보를 가지고 답변을 생성합니다.
Multimodal Augmented Generation
최종 답변을 생성하는 단계 입니다. 이때는 위의 Structured Reasoning을 통해 얻은 정보들을 입력 context에 추가로 활용하여 답변을 생성합니다. 영상의 시각적인 특징뿐만 아니라 구조화된 추론 정보를 결합하여 최종답변을 생성하기 때문에 모델이 보다 정확하고 맥락에 맞는 답변을 일관적으로 생성할 수 있습니다.
Experiments
Vgent는 기존에 존재하는 LVLM에 추가적인 학습 없이 DB 생성, Divide and Conquer 전략의 구조화된 정보를 활용한 답변으로 성능을 향상시키는 방법론입니다. 저자는 기존에 존재하는 오픈소스로 공개된 논문들에 Vgent 방법을 곁들여 실험결과를 보여줍니다.

위 table 1은 기존 LVLM의 성능을 Vgent를 통해 향상시킨 결과를 보여줍니다. 긴 비디오 이해를 필요로하는 VideoQA 데이터셋인 MLVU, VideoMME, LVB 데이터셋 모두에서 저자의 Vgent를 활용하여 성능이 향상하는 것을 확인할 수 있습니다. 모든 데이터셋 전반에서 성능이 향상하는 것으로 저자는 Vgent가 일관되게 정확도 높은 답변을 생성한다고 주장하고 있습니다.

table 2는 기존 비디오 RAG 방법론과의 비교입니다. 방법론이라고해도 Video-RAG 밖에 없지만 기존 SOTA 모델인 Video RAG보다 모든 데이터셋, 세팅에서 압도적인 성능을 보여주며 저자의 Vgent가 효과적임을 보여주고 있습니다.


table 3과 table 4는 Ablation Study입니다. table3은 오프라인 데이터베이스를 생성할 때에 그래프를 통해 명시적으로 클립 사이의 연결을 해주는 것이 성능에 큰 영향을 준다는 것을 확인할 수 있고, 거기에 추가적으로 Structured Reasoning(SR)을 사용하는 것이 효과적임을 보여주고 있습니다. SR이 GraphRAG뿐만 아니라 NaiveRAG에서도 성능이 많이 오르는 것을 확인할 수 있습니다. 이는 저자가 제안하는 Divide and Conquer 전략이 효과적임을 보여주고 있습니다. 추가로 저자는 NaiveRAG에서의 SR을 적용했을 때의 성능 향상보다 GraphRAG에서 SR을 적용했을 때의 성능 향상이 평균적으로 높은 것을 근거로 GraphRAG 방식과 SR방식의 시너지를 확인할 수 있다고 주장하고 있습니다. table 4는 MLVU 데이터셋에서 retrieval하는 클립의 개수에 따른 성능 차이를 보여주고 있습니다.

정성적 결과와 함께 논문 리뷰를 마치겠습니다. 저자가 제안하는 방법론의 전반적인 흐름을 확인할 수 있으며 저자가 제안하는 Vgent의 그래프 기반 reasoning이 특히 Intermediate reasoning이 필요할 때 효과적임을 보여주고 있습니다.
감사합니다.