안녕하세요! 첫 X-Review를 작성하게 된 김기현입니다. 첫 Review 논문으로는 석준님과 우현님과 함께 우편물 배달 task를 수행하기 위한 VLA, SmolVLA 논문을 들고 왔습니다. 간단하게 한 마디로 요약하자면 기존의 Vision-Action(VA), 즉 언어 없이 시각 정보만으로 행동을 생성하는 방식에는 한계가 있어 VLM까지 활용하는 VLA까지 나왔는데 그 중에서도 경량화가 잘 되어 있다고 하는 것이 SmolVLA 입니다.
그러면 리뷰 시작하겠습니다

- Conference: arXiv 2025
- Authors: Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, Remi Cadene
- Affiliation: Hugging Face; Sorbonne University; valeo.ai; École Normale Supérieure Paris-Saclay (∗ Core team)
- Title: SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
1. Introduction
최근 몇 년동안 인공지능 분야는 다양한 작업을 수행할 수 있는 범용 모델인 foundation model 개발로 전환되면서 학습이 인터넷 규모의 대규모 데이터셋에서 비롯됩니다. 그러나 Robotics 분야는 객체 유형(object type), 위치(positions), 환경(environments), 작업(task) 전반에 걸쳐서 일반화 하는 것이 어렵습니다. 이를 해결하기 위해서 해당 논문의 저자는 VLA 중에서도 작지만 유능한 SmolVLA를 소개합니다.
저자가 말하는 SmolVLA는
- 경량 아키텍처(소비자 등급의 GPU에서 학습하고 CPU 상의 배포에 최적화 되어 있는 Vision Language Agent)
- 커뮤니티 주도 데이터셋을 활용한 사전 훈
- 비동기 추론
의 장점을 가지고 있어서 기존 VLA에 비해 적은 연산량으로도 충분한 로봇 모델을 구사한다고 하고 있습니다.
2. SmolVLA: small, efficient and capable
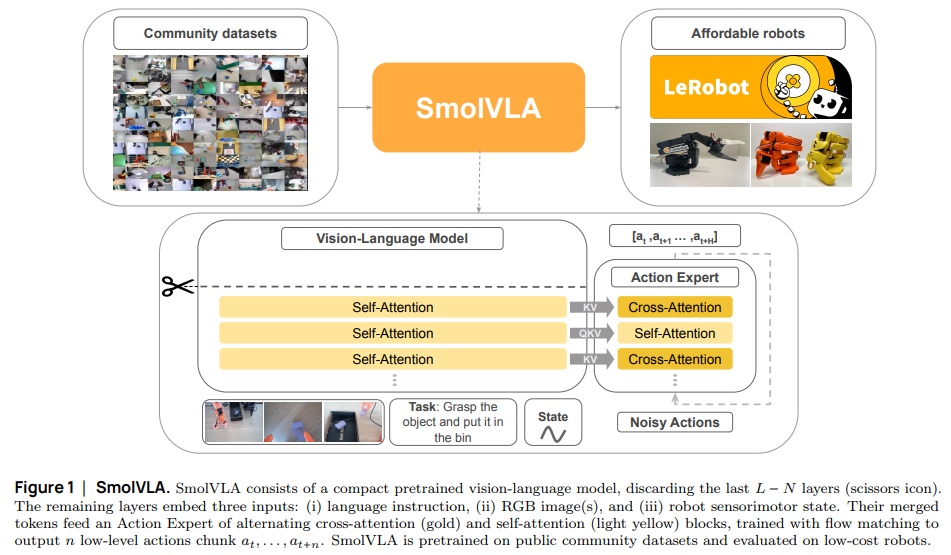
SmolVLA는 compact한 pretrain VLM과 flow matching으로 학습된 Action Expert로 구성된 경량 VLA입니다. 주어진 여러 이미지와 작업을 설명하는 언어 지시를 바탕으로 model은 일련의 행동을 출력할 수 있습니다. 이 모델은 커뮤니티 수집 데이터 셋에 대한 imitation learning으로 pretrain된 다음, 실제 및 시뮬레이션 환경 모두에서 평가 된다고 합니다. 또한 추론 시에는 아래에서 설명드릴 비동기 실행 스택을 도입해 더 빠르고 반응성이 뛰어난 제어를 가능하게 한다고 합니다.
2.1 Model Architecture
모델은 크게
- 인식을 담당하는 사전 학습 VLM – 상태 입력을 처리해 행동 전문가를 조건화하는 특징을 생성
- 행동을 학습하는 행동 전문가 – VLM에 공급되는 상태를 변경하는 행동 생성
두 부분으로 구성되어 있습니다. (Figure 1 참고)
VLM
같은 경우에는 사전 학습된 VLM을 backbone으로 사용해서 로봇이 환경을 인식 할 수 있게 하였습니다. VLM은 다양한 multi-modal 데이터로 pretrain되어 풍부한 세계 지식을 포착하기 때문에 로봇 환경에 대해서 이해를 할 수 있게 됩니다. 효율성과 접근성 보장을 위해 VLM 모델은 SmolVLM-2를 사용했다고 합니다.
시각적 특징 인코딩을 위해 SigLIP에 의존한다고 하고, VLM component는 효율성을 위해 token-shuffling 기법으로 토큰 수를 줄이는 Vision Encoder를 사용해 이미지 시퀀스를 처리한다고 합니다.
- SigLIP: 기존 clip에서 normalization을 두 번 하는 문제를 해결하기 위해 sigmoid로 binary classification 한 방식
- Token shuffling: 이웃한 여러 조각을 선택해 각 조각에 동일한 가중치 행렬로 차원을 축소한 뒤 이를 이어 붙여 차원을 맞추고, 최종적으로 MLP 블록을 통해 정보를 압축한 하나의 대표 토큰을 생성하는 과정이라고 합니다
기존 SmolVLM-2보다 더 빠른 추론 시간을 위해 타일링은 사용하지 않고, 프레임당 visiual token을 64개로 제한한다고 합니다. 또한 연산 효율을 위해 VLM의 일부 상위 레이어를 제거하거나 스킵하는 설정을 사용하며, 아래에서 실험으로 레이어 수에 따른 성능-효율 트레이드오프를 분석합니다.
결과적으로 VLM에는 Visiual token, Language token, State token(센서 모터 State로 언어 모델의 토큰과 차원을 맞추기 위해 linear projection layer를 통해 단일 토큰으로 만듭니다.)이 들어가게 됩니다.
Action Expert
action expert는 flow matching 기반으로 동작합니다. 그 중에서도 conditional flow matching transformer라는 것을 사용합니다. flow matching을 간단히 설명하자면 정답 속도(벡터장)와 예측 모델의 속도(벡터장)을 최소 제곱 오차를 내는 방식으로 계산합니다.

노이즈에서 실제 액션으로 가는 중간 지점을 의미하는 A^{\tau}_{t} = \tau A_{t} + (1-\tau)\epsilon를 활용해서 정답 속도는 이를 미분한 \frac{dA^{\tau}_t}{d \tau} = A_t - \epsilon이라는 값을 가지고 현재 예측한 벡터장과 정답 벡터장 사이의 차이를 제곱 오차로 정의하고, 이를 기대값 기준으로 최소화하도록 학습한다고 이해하면 됩니다. ({\tau}∈[0,1])
flow matching은 확률적 역과정보다는 명시적으로 정의된 벡터장을 따르기 때문에, Diffusion 기반 정책에 비해 경로가 더 안정적이고 제어에 유리하다고 볼 수 있습니다.
Interleaved cross and causal self-attention layers
action expert인 v_{\theta} 는 VLM feature를 조건으로 action chunk를 생성하며 VLM과 action expert 간의 상호작용은 attention 메커니즘을 통해 이루어 집니다. 기존에는 SA(self-attention)와 CA(cross-attention) 중에 하나를 사용했지만 SmolVLA는 이 둘을 모두 포함하는 interleave한 접근 방식을 사용합니다.

SA layer에 대해서는 causal attention mask를 사용해 과거 token에만 attention할 수 있도록 미래 액션 의존성을 방지합니다. 이로서 더 높은 성공률과 빠른 추론을 얻고, SA가 부드러운 action chunk 생성에 기여한다고 저자는 말합니다.
2.2 Pretraining data collected by the community
현재 로봇 데이터는 규모 정도가 작을 뿐만 아니라 센서 형태, 작동 모드, 제어 주파수가 다 다르기 때문에 통합이 어렵습니다. 이를 해소하고자 SmolVLA에서는 저가형 robotics 플랫폼과 표준화된 robotics 라이브러리를 사용하는 로봇 커뮤니티 데이터 셋으로 pretrain 하였다고 합니다. 다양한 환경에서 수집된 데이터셋이기에 노이즈에 대해서도 robust하다고 합니다.
일부 커뮤니티 데이터셋에는 작업에 대한 주석이 없거나 모호한 경우도 있는데 VLM을 통해서 이에 대한 간결한 작업 설명을 자동으로 생성해서 학습에 사용했다고 합니다. 또한 데이터 체제에서 카메라의 순서가 일관된 것이 학습에 유리해서 카메라를 표준화된 시점 유형으로 수동 매핑하고 이름을 변경해서 학습이 잘 될 수록 있다고 합니다.
2.3 Asynchronous inference
기존의 정책 생성 방식은 액션 청크를 출력하면서 새로운 관찰이 정책에 전달되어 다음 청크를 예측하는 과정(open-loop inference)으로 진행됩니다. 그러나 이렇게 계속 action chunk를 계산하고 다음 action chunk를 덮어쓰는 과정이 비효율적일뿐만 아니라 edge device에 배포가 어렵기 때문에 SmolVLA는 로봇 행동을 하는 부분과 로봇 정책을 생성하는 부분을 분리했습니다. (정식 명칭은 Policy Server과 Robot Client입니다)
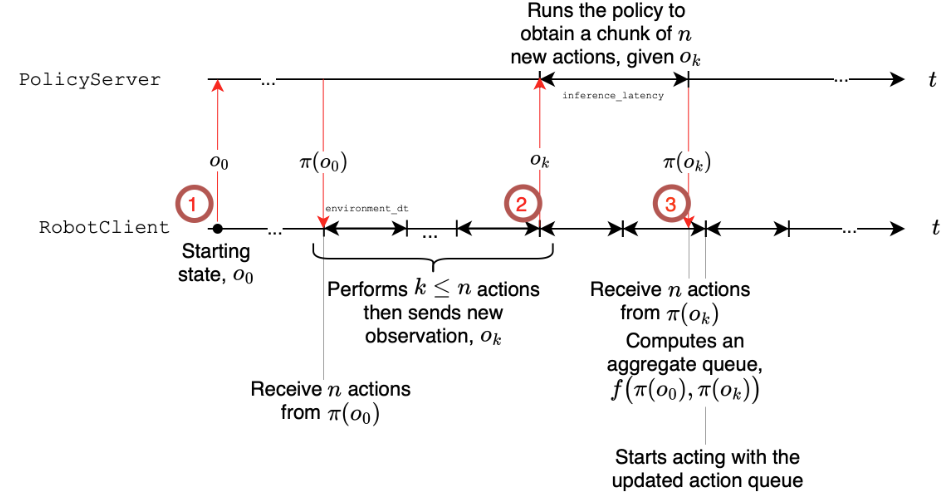
길이 n의 action chunk를 생성한 뒤 가장 앞의 행동부터 실행을 하다가 현재 남은 행동의 비율이 일정 비율 이하가 되면 관찰(o_{t})을 받아서 action chunk를 생성합니다. 생성된 action chunk는 남아있는 action chunk가 있으면 가중 평균을 내어서 적절히 혼합해서 사용한다고 합니다(기존의 것을 버리고 바로 사용하지 않는 이유는 action이 급격하게 바뀌면 튀는 현상을 보이기 때문에 이를 방지하기 위해 가중 평균을 사용합니다)
남은 액션 비율이 어느정도가 되면 새로운 action을 생성하는지에 대해서는 논문에서 최적의 값을 계산하는 식을 제시합니다
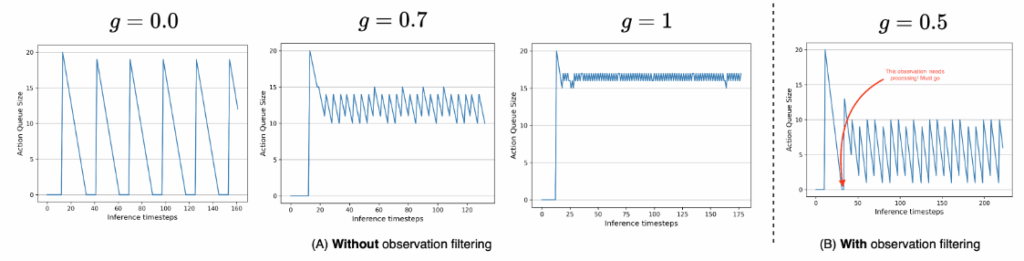
결과적으로 이 g 값(남은 action 비율)이 0.7 정도가 되는 것이 계산량과 동작의 흐름이 괜찮다고 합니다. 또한 observation filtering을 통해서 상황 변화가 없는 경우에는 컴퓨팅 자원을 획기적으로 줄일 수 있다고 합니다.
3. Experiments
평가 과정에서는 LIBERO와 Meta-World 같은 시뮬레이션 환경의 벤치 마크 상에서 평가하고, Real-World에서는 3개의 task(pick and place, stacking task, sorting task)를 수행하는 것에 대해서 평가를 수행했습니다. 또한 SmolVLA의 일반화 평가를 위해 투명 상자에 넣는 고급 vision 기능을 요구하는 task도 추가로 수행했다고 합니다.
(PyTorch 기반 LeRobot 프레임워크에서 SmolVLM-2를 backbone으로 고정한 채 450M 파라미터 규모의 모델을 AdamW와 코사인 학습률 스케줄로 bfloat16·멀티 GPU 환경에서 효율적으로 학습하고, action expert만을 대상으로 flow matching(일반적으로 inference 시에는 10-step 추론)을 통해 액션 청크를 생성·평가를 진행했습니다)
Baseline은 VLA 모델의 한 종류인 \pi_{0}[\latex]와 VA 모델인 ACT를 대상으로 비교했습니다.
simulation 상에서는 확산 정책 기반인 Diffusion Policy와 Octo, OpenVLA등을 추가로 가져와서 평가 비교에 사용했습니다.

결과적으로 다른 VLA에 비해서도 좋은 성능을 냈으며 \pi_{0}[\latex]와 비교하면 학습 속도가 40% 정도 빠르고 메모리 사용량은 6배가 적다는 것을 강조하고 있습니다.

또한 Real-World에 대해서 평가를 진행했을 때 ACT와 pi zero보다 더 우수하다는 것을 보이고 있습니다.
다음으로는 내부의 구조나 값을 어떻게 변경하였는지, 어떤 값이 최적인지에 대해 설명하는 table입니다.
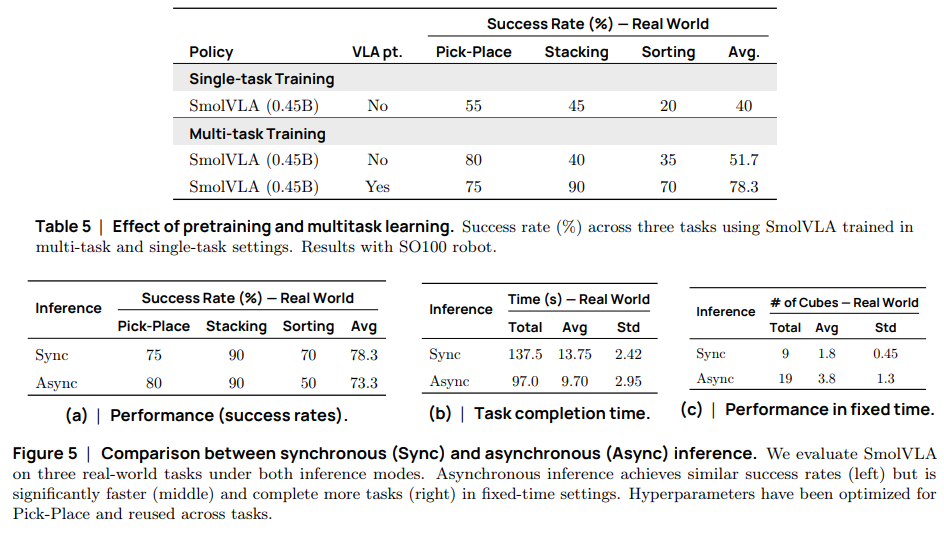
순서대로 설명하자면 Pretrain, 동기 비동기에 대한 성공률, 수행 시간, 고정된 시간 내에 수행한 사이클에 대한 평가 지표입니다. 이를 통해서 저자는 pretrain으로 상당한 이점을 얻을 수 있으며 비동기 수행을 통해 크게 하락하지 않은 정확도로 적은 시간 내에 task를 수행할 수 있다라는 것을 말하고 싶은 것 같습니다.
개인적으로 지표만 보았을 때는 성능만 보면 오히려 동기 추론이 더 나을 수도 있을 것 같지만 저자가 실험해보았을 때는 객체 위치 변화와 외부 변화에 더 큰 강건성을 보이고, 예측 지연을 회피해서 작업을 더 많이 해결할 수 있다고는 합니다. 이 부분은 직접 모델을 돌려보면서 실험을 하는 과정도 필요할 수도 있을 것 같다는 생각이 듭니다.
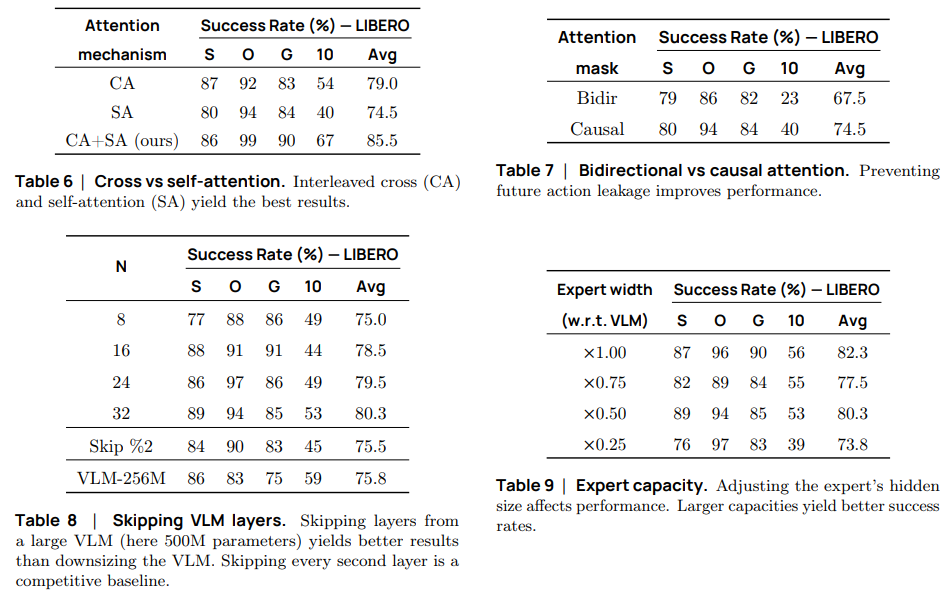
또한 Attention을 CA와 SA를 혼합하여 사용했을 때, mask를 통해 과거만 보고 추론했을 때, VLM layer를 처음 절반만 사용했을 때, action expert의 크기를 0.75 x d로 하는 것이 효율성과 성능 측면에서 좋다고 말하고 있습니다.
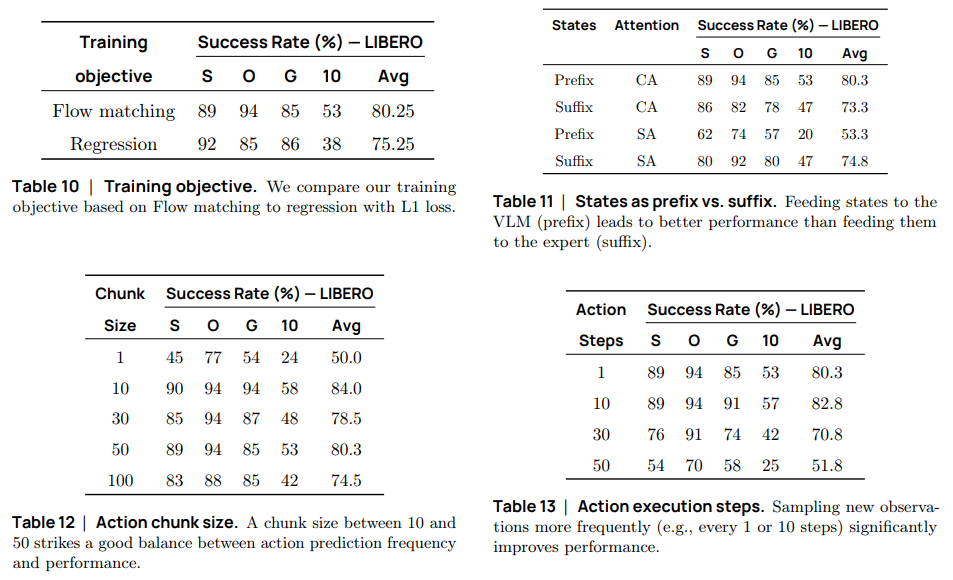
마지막으로 Flow matching 방식을 사용했을 때, State 정보를 VLM에 적용했을 때(Prefix는 VLM에 State를 넣은 경우, Suffix는 Action Expert에만 State를 넣은 경우), 액션 청크 사이즈를 50으로 했을 때, 관측치를 업데이트 하는 정도가 10이 되었을 때 적절한 성공률과 연산량을 얻을 수 있다고 하고 있습니다.
4. Discussion
결과적으로 소비자 등급의 하드웨어, 저비용 로봇에서 제어되고 기존 VLA에 비해서 효율적인 VLA 모델 SmolVLA를 제안한다는 내용을 담고 있고, 성공률이 저하되지 않으면서도 반응성이 좋고, 연산량도 기존 방식보다 적다는 것을 이점으로 가지고 있는 모델이라고 합니다.
이렇게 보니까 로봇을 동작하는 모델에서 VLM과 같은 대량의 데이터로 학습된 모델이 생각보다 큰 중요성을 보인다는 생각이 들었고, VLA는 동작에 대해서 명시적으로 주석을 제공했기 때문에 기존의 Vision Action 방식보다는 long-horizon task에 대해 일관된 행동을 할 수 있다는 것이라고 유추할 수 있었습니다. 또한 커뮤니티 규모로 로봇 데이터를 수집하는 것을 보니 로봇 데이터를 어떻게 하면 많이 모을까에 대해서도 앞으로 추가로 찾아보는 과정을 진행해 보아야겠다고 느꼈습니다.
이상 김기현이었습니다.
