안녕하세요, 이번주는 로봇을 위한 합성데이터 생성 방법론을 제안한 논문을 리뷰해보려고 합니다. 최근의 비디오 생성 모델에 대항해 VFM, VLM 등을 활용해 비디오 생성 모델 만큼 확장성 있지만, 더 적은 리소스로 action정보까지 수집하겠다는 연구입니다.
Introduction

저자들은 최근 범용 로봇 정책을 학습시키기 위해 막대한 양의 visuomotor 데이터가 필요하지만, 실제 로봇을 이용한 데이터 수집은 비용이 많이 들고 특정 환경에 국한되는 한계가 있다고 지적합니다. 반면 웹에서 손쉽게 구할 수 있는 오픈월드 이미지들은 현실 세계의 다양한 장면을 거의 무제한으로 포함하고 있어, 로봇 조작 과제에 자연스럽게 부합하는 방대한 시각 데이터를 낮은 비용으로 확보할 수 있는 잠재력이 있습니다. 그러나 이러한 이미지에는 로봇 동작에 관한 정보가 전혀 없기 때문에, 시각 정보는 풍부하지만 실행 가능한 액션 시퀀스가 결여되어 있어 로봇 학습에 직접 활용되기 어렵습니다. 이처럼 오픈월드 이미지와 로봇 수집 데이터가 서로 보완적인 특성을 지님에도 불구하고, 적절한 로봇 행동 데이터의 부족 때문에 현재까지 이 풍부한 시각 자원이 로봇 학습에 충분히 활용되지 못하고 있다고 설명합니다.
이 문제를 해결하기 위해, 저자들은 IGen이라는 새로운 프레임워크를 제안합니다. IGen은 in the wild 이미지로부터 충분히 현실감 있는 영상 데이터와 그에 대응하는 로봇 액션 시퀀스를 생성할 수 있습니다. 구체적으로 IGen은 대형 비전 모델을 활용하여 2D 이미지를 구조화된 3D 장면 표현으로 변환하고, VLM의 추론 능력을 이용해 장면에 해당하는 task를 순서대로 high-level, low level 명령으로 변환하며, 이러한 명령을 실행하여 시간에 따라 변화하는 영상을 합성합니다. 저자들은 IGen을 통해 얻은 vision-action 쌍의 데이터만을 가지고 학습한 정책이 실제 데이터로 학습한 정책과 비슷한 성능을 보이는 등 해당 방법론으로 생성한 데이터의 품질과 실효성을 확인할 수 있었다고 하빈다. 추가로 Robot Learning from any images 연구와 같이 일반화된 로봇 정책 학습을 위해 오픈월드 이미지로부터 손쉽게 대규모 데이터를 획득하는 새로운 경로를 제시하는 것이라고 강조합니다. 다만 저자들의 방법의 경우 이미지와 text instruction만 있다면 아무런 추가 작업 없이 해당 영상을 통한 데이터 생성이 가능한 것이 강점이라고 볼 수 있을 것 같습니다. 추가로, 기존 로봇의 경험을 잘 학습하지 못한 비디오 생성 모델과 달리, 인터넷 이미지로부터 로봇에게 필요한 행동 정보를 VLM을 통해 생성해 인간의 경험이 담긴 데이터가 아닌 로봇의 경험이 담긴 영상을 생성하고, 그에 따른 retargeting 없이 순수한 로봇의 액션을 그대로 제공할 수 있다는 강점이 있습니다.
Methods
전체 아키텍처는 세 단계로 구성되며, 입력 이미지를 로봇이 조작 가능한 작업 공간으로 변환하는 3D reconstruction, 3D 공간 내 키포인트들을 토대로 로봇의 행동을 계획하는 action planning), 생성된 pointcloud sequence를 렌더링하여 해당 작업의 observation과 action을 얻는 단계로 이루어집니다.
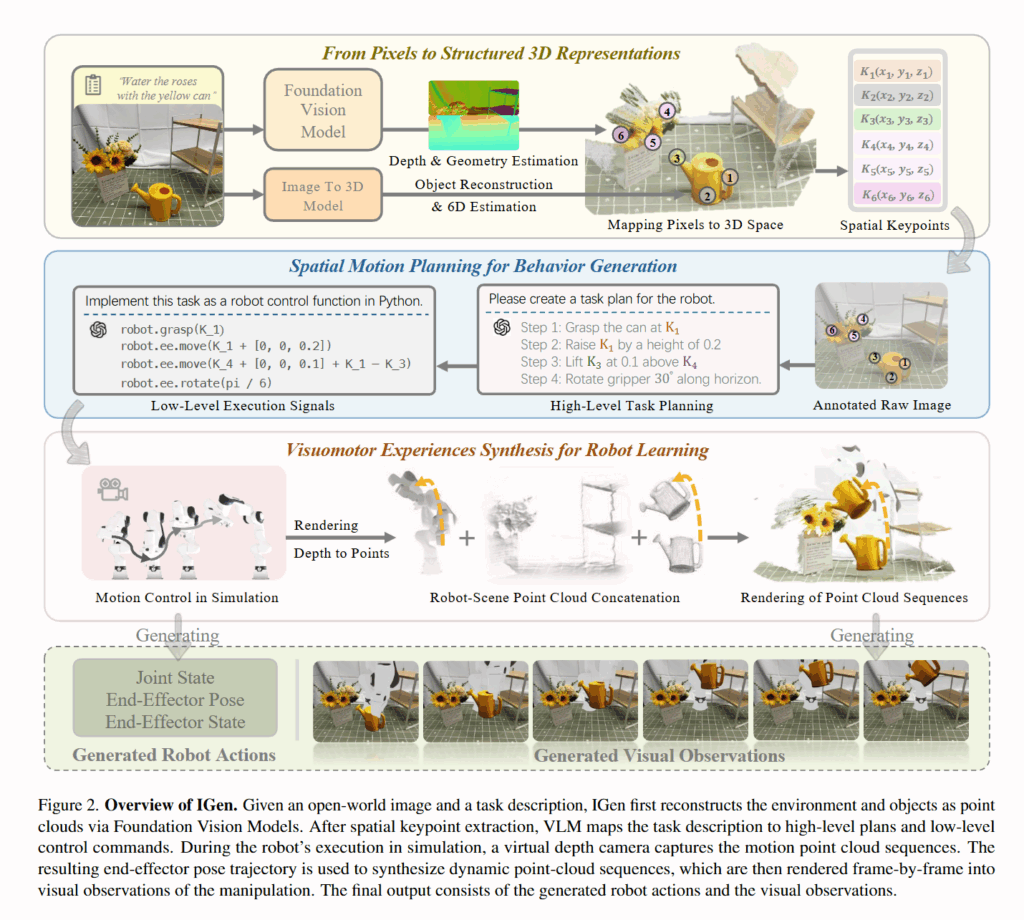
From Pixels to Structured 3D Representations
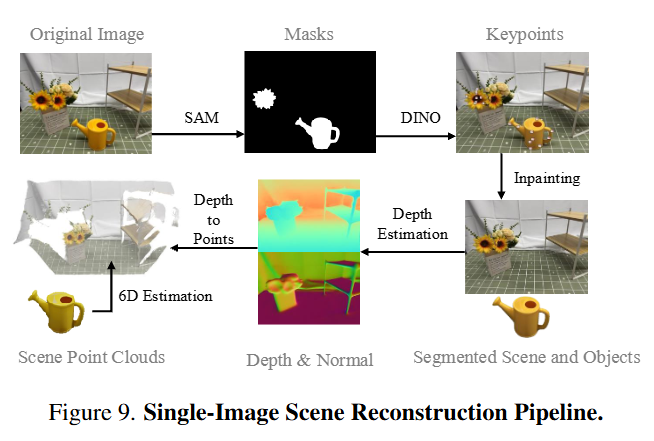
저자들은 먼저 인터넷에 있는 2D 이미지를 로봇의 기준으로 표현 가능한 구조화된 3D 표현으로 변환합니다. 이를 위해 monocular depth estimation 모델 (Metric3D)를 사용하여 depth를 추정합니다. 이 때 2년전의 연구를 활용하는 이유에 대해 고민을 해봤는데, mono depth 서베이 논문을 보니 실제적인 RMSE 성능은 낮아도 일관성 지표에서는 최신 방법론 보다는 강한 모습을 보여서 그런 것이 아닌가 하고 추측해봅니다. 이후 LLM 프롬프팅을 통해 text instruction에서 실제로 이미지 내에 존재하는 상호작용 대상에 대해서 분할을 진행해줍니다. 이후 마스킹된 이미지 (객체들)에서 SAM과 DINOv2 를 통해 feature embedding들을 얻고, 해당 임베딩들과 그에 해당하는 3차원 좌표에 Kmeans clustering을 적용하여 공간 정보를 담고있는 키포인트들을 추출합니다. 이후 너무 많은 후보들을 추려내기 위해 mean shift clustering 또한 진행해줍니다.(여기까지는 ReKep의 구조와 매우 유사합니다.) 이렇게 작업을 수행하기 위해 필요한 객체들의 2D, 3D 키포인트들을 추려냅니다. 이후에는 조작 대상 객체를 따로 분할해 사전학습된 TRELLIS 모델을 통해 3D mesh화를 진행한 후, Color pointcloud로 변환해준다고 합니다. 그뒤에는 Inpainting 모델을 사용해 조작 대상 객체를 지운 배경 사진을 얻고, 이를 같은 depth estimation 모델을 통해 pointcloud로 변환해줍니다. 이후에는 6D estimation 모델을 통해 Full pointcloud를 원래 사진상의 위치에 재배치 해줍니다. 이러한 과정을 거치고 나면 분리된 조작 대상 객체의 full pointcloud, 배경의 pointcloud, 작업 수행을 위해 의미있는 2D, 3D keypoint들을 전부 얻게 됩니다.
Spatial Planning for Behavior Generation
다음 단계로, 저자들은 VLM의 시각적인 추론과 계획 능력을 활용하여 로봇의 행동 생성을 안내합니다. 이 과정도 ReKep의 구성을 따랐다고 합니다. 설명하자면 앞서 얻은 키포인트들과 그 3D 좌표에 대한 설명과 원본 이미지, task instruction을 VLM에 입력으로 넣어주고, VLM은 주어진 작업을 여러 하위 단계로 분해하여 각 단계별로 관련 키포인트에 대한 action description을 생성합니다. 이 과정을 통해 고수준의 작업 계획이 이루어집니다. 저자들은 이를 실제 로봇이 실행 가능한 저수준 제어 명령으로 변환하기 위한 end-effector pose 기반의 파이썬 기반 제어 언어를 개발했다고 합니다.
각 작업 단계별로 이 제어 프레임워크는 미리 정의된 키포인트 조건부 동작 함수를 호출하여, 해당 단계에서 end effector의 pose를 계산합니다. Pre-manipulation stage에서는 물체를 정확히 잡기 위해 GraspGen 모델을 사용하여 end effector의 pose를 예측하고 이동합니다. Manipulation stage에서는 선택된 조작 대상 물체의 키포인트는 엔드 이펙터와 함께 움직이는 것으로 취급하고 환경에 존재하는 나머지 키포인트들을 anchor로 삼아서 엔드 이펙터를 어떻게 움직일지 정해줍니다. 이렇게 각 단계의 EE 위치들이 정해지면, 모션 플래너를 통해 trajectory를 계산해 로봇의 action으로 변환해줍니다. 이렇게 계획된 경로는 시뮬레이터 상에 로봇을 두고 실행해 pointcloud와 action값들을 얻어줍니다.
Experience Synthesis for Robot Learning
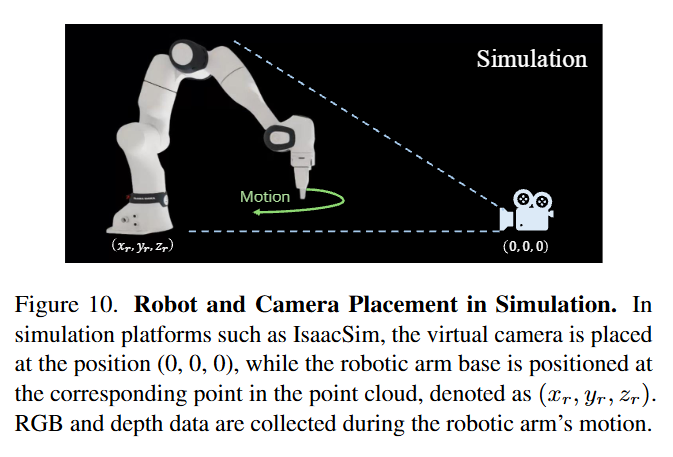
마지막 단계에서, 저자들은 로봇의 action 시퀀스와 동기화된 시각 관찰 데이터를 얻기 위해 실시간 pointcloud 렌더링에 기반한 데이터 합성 기법을 제안했습니다. 앞서 계획된 로봇 행동 시퀀스를 시뮬레이터에서 실행하면서, 가상 카메라를 통해 매 time step마다 RGB-D 프레임을 렌더링하여 로봇의 움직임에 따른 pointcloud 변화를 실시간으로 포착합니다. 이렇게 얻은 로봇과 gripper의 동적 pointcloud 시퀀스와, 변화하지 않는 배경의 정적 pointcloud를 조합하여 전체 장면의 시간에 따른 3D 상태를 표현하였습니다.
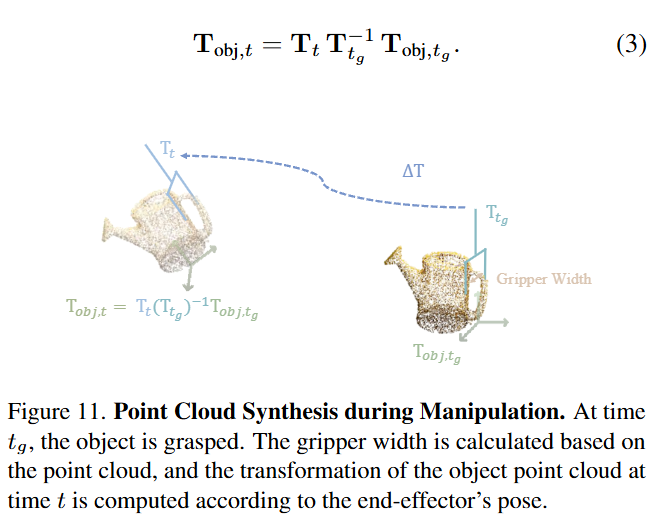
Manipulation에 대한 설명은 아래와 같이 로봇이 물체를 집는 순간부터 그리퍼를 놓을 때까지 (실질적인 상호작용)의 구간에서는 먼저 객체 pointcloud를 기준으로 grasp width를 정해 해당 width만큼만 grasping을 진행한 뒤, 파지 이후의 순간 부터 end effector의 rigid transform에 따라 대상 물체의 포인트클라우드가 함께 이동하도록 Transform을 계산해 로봇이 물체를 쥐고 상호작용하는 상황에서의 장면을 생성해줍니다. 이렇게 얻은 배경, 로봇, 로봇에 따라 움직이는 객체 pointcloud를 통합된 시퀀스로 구성하고, 가상 카메라를 통해 이를 매 프레임마다 렌더링하여 최종적인 visualization 시퀀스를 얻습니다. 최종적으로 open world 이미지 한 장 만으로 task instruction에 해당하는 로봇,액션 페어 데이터를 얻을 수 있게 됩니다.
Experiment
자들은 세 가지 핵심 연구 질문에 답하고자 실험을 설계했다고 밝혔습니다. Q1: IGen이 다양한 장면의 이미지로부터 현실감 있는 데이터를 생성할 수 있는가? Q2 : IGen이 환경에 부합하고 작업 지시문을 충실히 따르는 로봇 행동을 효율적으로 생성할 수 있는가? Q3 : IGen을 사용해 단 한 장의 이미지로부터 합성한 데이터만으로 로봇 정책을 학습하여, human demonstration 없이도 실제 로봇 조작을 성공적으로 수행할 수 있는가?
Scene Reconstruction Fidelity
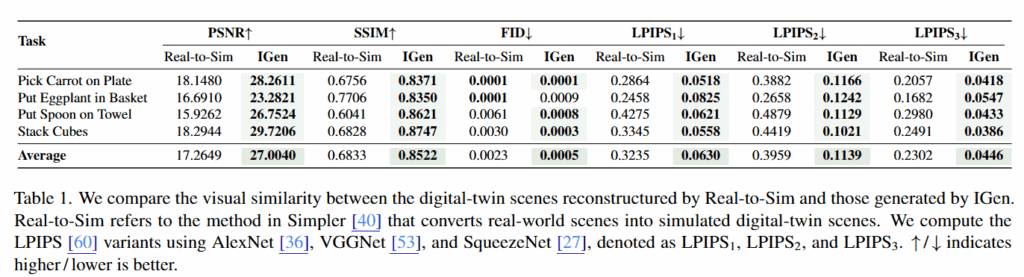
동일한 이미지로부터 Simpler 프레임워크에서 제공하는 Real-to-Sim 방법으로 복원한 결과와 비교 평가했습니다. PSNR, SSIM, FID, LPIPS 등의 다양한 지표를 활용하여 원본 이미지와 재구성된 장면의 일치도를 측정했다고 합니다. Table 1에 나타난 바와 같이 IGen이 모든 지표에서 Simpler의 Real-to-Sim보다 우수한 성능을 보였다고 합니다.
Evaluation of Behavior Generation
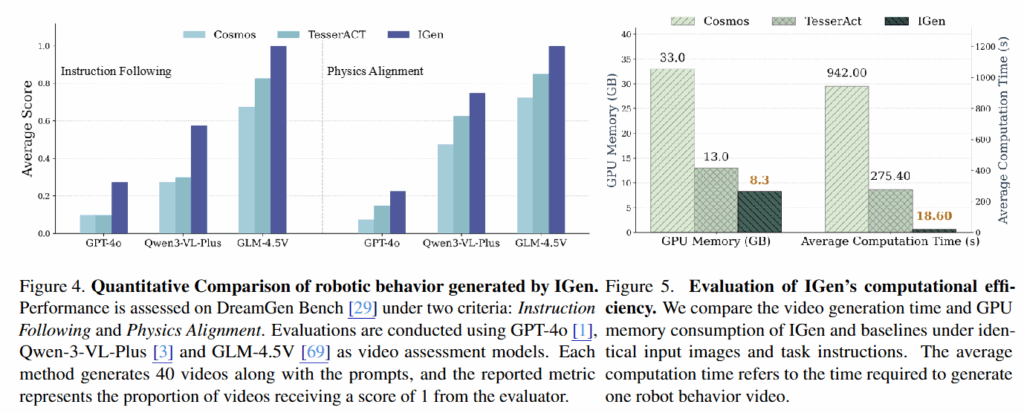
하나의 이미지와 task instruction을 통해 얻은 영상에 나온 객체들이 얼마나 instruction에 맞게 행동하는지, 최근 video world model인 Cosmos, TesserACT와 비교해서 실험했습니다. 비교 대상이 최근 핫한 Sora2나 Wan2.5, Veo3가 아닌것은 조금 아쉽지만 robot behavior를 나타낼 수 없으니 비교 대상에서 제외했다고 합니다. 비디오 모델들이 아직 로봇 자체의 상호작용에 대한 비디오 생성 능력이 부족함을 어필하는 실험입니다. GPT-4o, Qwen3-VL-Plus, GLM-4.5V 모델들을 통해 총 40개의 비디오를 생성한 후 점수를 매겨 0과 1 사이의 숫자로 정규화하여 표현했다고 합니다. 실험 결과 앞선 방법론들 보다 Instruction Following과 Physics Alignment에 대해 점수가 일관되게 높은 것을 확인할 수 있고, 더 나아가 GPU Memory와 Computation Time또한 낮은것을 알 수 있습니다. 다만 뭔가 함정이 있는 것 같은게 우선 비디오 생성 모델들을 활용하게된 가장 큰 이유인 deformable, articulation, 자연스러운 조명 효과나 결과물의 현실성은 평가되지 않았고, computation time 또한 파이프라인의 일부만 계산한 것 같습니다. 현재 코드가 공개되지 않아 직접 구현하는 중인데 단일 4090 GPU로 TRELLIS와 Task Planning 부분만 돌려도 40초 정도가 소요됩니다. 정성적인 결과의 경우 아래와 같이 로봇이 작업하는 모습이 더 유의미하게 반영되는 것은 확인할 수 있습니다.

Robot Learning from Unstructured Images

마지막으로, 저자들은 IGen으로부터 얻은 데이터만으로 학습한 정책을 실제 로봇에 적용하여 인간 시연 데이터 없이도 조작 작업을 수행할 수 있는지 검증했습니다. 하드웨어 구성은 위 사진과 같이 Franka Research 3와 전면에 서치된 Microsoft Kinect (RGB only)를 이용했습니다. 모델은 Pi-0을 사용했고, 아무런 finetuning 없이 적용했을 때는 성공률 0%에 가까운 제로샷 성능만 보여 현재 설정에서의 범용성이 제한적임을 먼저 확인해주었다고 합니다. 이후 해당 모델을 real teleoperation 데이터로 finetuning한 경우와, IGen을 통해 생성한 데이터로 finetuning한 경우를 비교했습니다.
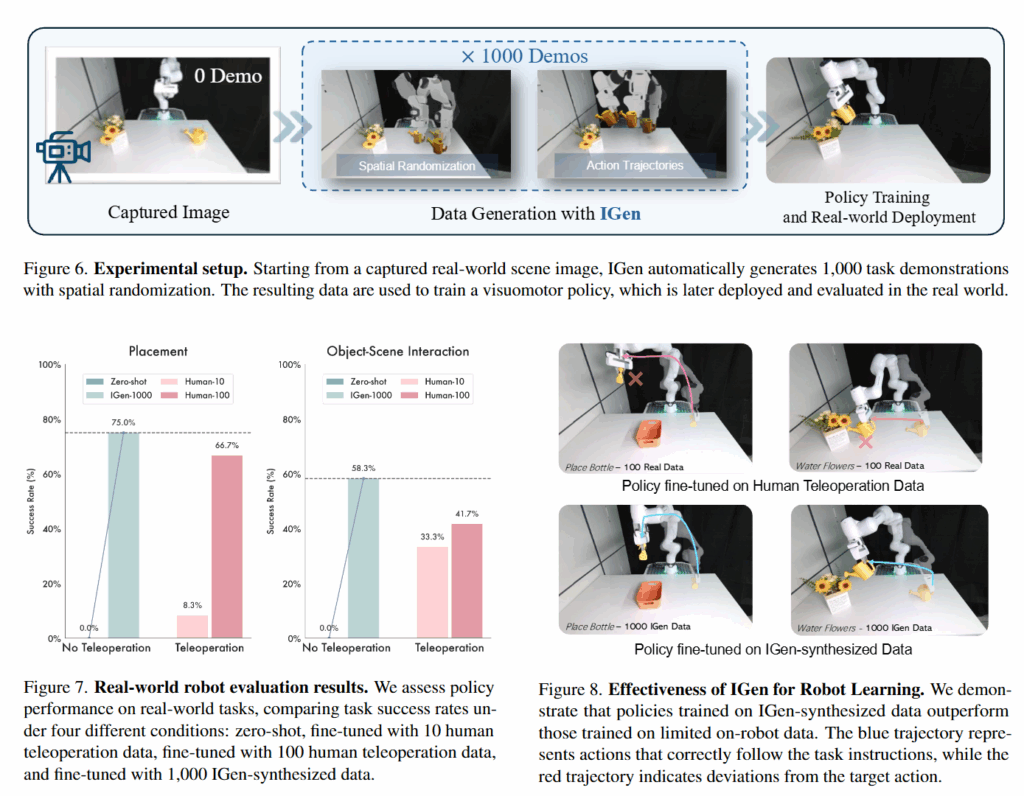
실험 결과, 아무런 teleoperation 없이 각각 10개, 100개의 human teleoperation 데이터보다 1000개의 IGen 데이터를 통해 학습한 경우의 성능이 더 좋은 것을 보이며 IGen의 필요성을 입증했습니다. Figure 8을 통해서는 IGen 데이터로 학습한 정책이 하늘색 경로와 같이 로봇이 지시된 목표를 정확히 따라간 반면, 적은 실제 데이터로 학습된 정책은 빨간색 경로처럼 목표 동작에서 벗어나는 모습을 보이며 teleoperation 데이터보다 훨씬 견고한 모습을 보인다고 주장했습니다.
Conclusion
우선 open world의 이미지로부터 아무런 인간의 노력 없이 현존하는 로봇 학습용 데이터를 생성할 수 있다는 점, 이 과정을 실제 시뮬레이션에서의 URDF 기반 로봇 제어와 계산된 pointcloud 기반으로 이루어져 비디오 생성 모델들 보다 더 로봇 입장에서의 자연스러운 장면과 action 데이터 생성을 만든다는 점에서 기여도가 있는 것 같습니다. 다만 근본적인 한계인 풍부한 deformable등에 대한 물리적, 시각적인 묘사가 불가능하다는 한계와 task instruction을 의미있게 풀어나가는 것을 VLM에게 low level 수준까지 맡기는 것은 한계가 있다고 생각합니다.