본 논문은 지도 없는 야외 환경에서 로봇이 사람 중심(Human-centered)의 주행을 수행할 수 있도록 새로운 알고리즘을 제안하는 논문입니다.
Intro
야외 환경은 공사 현장이나 계절 변화 등 동적인 요소가 많아 정밀한 지도를 유지 관리하는 것이 현실적으로 어렵다고 합니다. 따라서 사전에 구축된 지도 없이 센서 데이터에만 의존해 즉각적으로 판단하는 ‘Mapless Navigation’ 능력을 로봇에게 보유하는 것은 매우 중요하다고 하네요.
지금까지 주행 기술은 주로 LiDAR를 이용한 기하학적 분석에 의존해 왔습니다. 그러나 라이다는 큰 장애물은 잘 피하지만, 낮은 잔디, 화단, 연석(Curb) 같이 높이 차이가 미미한 지형지물은 구별하기 어렵습니다. 더 큰 문제는 사람 중심 환경에 대한 이해 부족입니다. 예를 들어, 로봇에게는 똑같은 평평한 땅이라도 사람이 다니는 인도와 차가 다니는 차도, 건너도 되는 횡단보도는 엄연히 다릅니다. 기하학적 정보만으로는 이러한 사회적/의미적 규칙을 이해할 수 없습니다.
이를 극복하기 위해 기존 연구들에서는 Semantic Segmentation 모델 등을 썼지만, 이는 방대한 학습 데이터가 필요하고 낯선 환경에서는 잘 작동하지 않는 일반화 문제가 있었습니다.
저자들은 최근 급부상한 VLM의 강력한 제로샷 추론 능력에 주목했습니다. VLM은 따로 학습시키지 않아도 이것은 횡단보도이니 건너도 된다”거나 “저기는 화단이니 밟으면 안 된다”는 식의 Logical Reasoning이 가능하기 때문입니다.
이를 바탕으로 저자들은 VL-TGS라는 새로운 프레임워크를 제안합니다. 먼저 LiDAR 데이터를 이용해 물리적으로 주행 가능한 여러 개의 후보 경로를 생성합니다 (CVAE 활용). 그리고 이렇게 생성된 경로들을 카메라 화면 위에 시각적으로 표시한 뒤, VLM에게 사람이라면 어떻게 이동할 것 같은지를 모델에게 물어보도록 해 가장 적절한 경로를 선택하게 합니다. 구체적인 방법론은 아래에서 다뤄보겠습니다.
Method
지도 없는 전역 네비게이션은 로봇이 사전에 구축된 지도에 의존하지 않고 즉각적인 주변 환경 너머에 있는 먼 목표지점에 도달하는 것을 요구합니다. 이를 달성하기 위해, 저자들은 기하학적 정보와 RGB 시각 정보를 모두 결합한 멀티모달 센서 데이터를 활용하여, 로봇을 목표로 안내하는 지역(local) 경로들을 반복적으로 생성합니다. 아래 그림은 제안하는 방법론의 overall framework을 나타내고 있습니다.
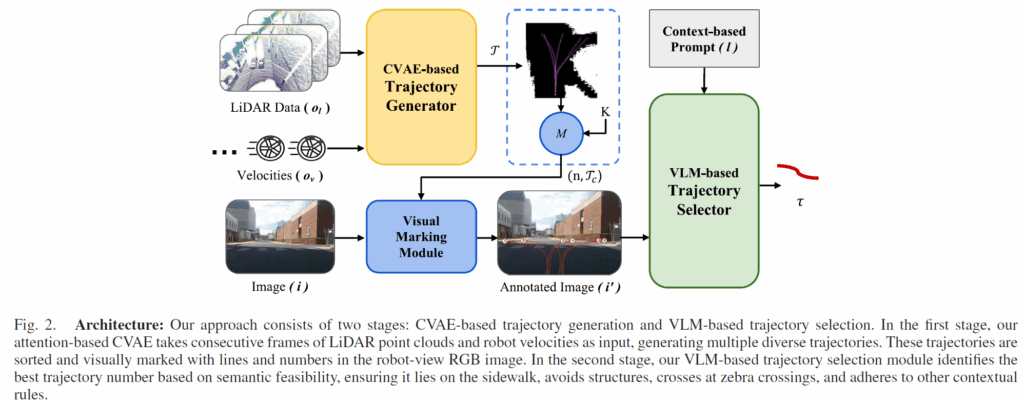
대략 2단계 파이프라인을 통해 navigation을 수행하는데, 우선 첫 번째 단계에서는 기하학적 주행 가능성(traversability) 제약 조건을 만족하는 고정된 길이(예: 10m)의 다수 후보 경로들을 생성합니다. 그런 다음, 인간과 유사한 의사결정에 기반하여 최적의 경로를 선택합니다.
구체적으로, 논문에서 수행하는 navigation task는 목표 지점 g \in \mathcal{O}_g과 현재 위치 사이의 상대적 위치를 GPS 정보를 통해 제공되었다는 가정하에서, 해당 정보를 토대로 목표까지의 최적 경로를 제공하고 시나리오의 주행 가능성 제약 조건을 만족하는 경로 \tau를 계산하는 것입니다.
\tau = \text{VL-TGS}(l, i, o, g)으로 표현할 수 있으며, 여기서 o = {o_l, o_v, i}는 로봇의 관측값들을 나타냅니다. o_l \in \mathcal{O}_l은 LiDAR 관측값을, o_v \in \mathcal{O}_v는 로봇의 속도, 그리고 i \in \mathcal{I}는 카메라로부터 얻은 RGB 이미지를 나타냅니다. 마지막으로, l \in \mathcal{V}는 주행 가능한 경로를 획득하기 위해 시각-언어 모델(VLM)에 주어지는 언어 지시어(instruction)를 나타냅니다.
저자들은 Conditional Variational AutoEncoder(CVAE)를 사용하여 LiDAR 센서로부터 얻은 기하학적 정보 o_l \in \mathcal{O}_l과 로봇의 오도미터로부터 얻은 연속적인 속도 o_v \in \mathcal{O}_v를 처리하고, 기하학적으로 주행 가능한 영역에 놓인 경로들의 집합 \mathcal{T} = \text{CVAE}(o_l, o_v)을 생성합니다.
이렇게 생성된 경로들은 Lidar와 속도 정보만을 가지고 있기 때문에 그림 1(C)에 보이는 횡단보도와 같이, 기하학적으로는 유사하지만 색상-의미적으로는 다른 상황들을 처리할 수 없게 됩니다. 따라서 저자들은 RGB 이미지로부터 장면 이해를 제공하기 위해 VLM을 사용합니다.

저자들은 CVAE로부터 생성된 실제 세계(real-world)의 웨이포인트들을 곧바로 사전학습된 VLM의 입력으로 사용하기 어렵다는 점 때문에 해당 경로들을 RGB 이미지 위에 덧씌우는 방식을 적용했다고 합니다. 구체적으로, CAVE로부터 생성된 여러 경로들에 대해 각 경로의 제일 끝에 0부터 시작하는 숫자를 배치합니다(그림1 A, B, C 그림에서 녹색, 붉은색 선들 예시 참조). 이 숫자들은 목표까지의 거리 순서를 나타내며, 가장 낮은 숫자가 가장 짧은 거리를 가진 경로에 해당한다고 하고, 저자들은 아래 수식을 통해 넘버링 된 경로들을 이미지 픽셀 수준의 객체로 매핑합니다.
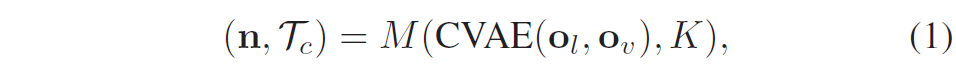
K는 실제 세계의 LiDAR 좌표계에서 이미지 평면으로의 변환 행렬을 나타내고 \mathcal{T}_c는 변환된 경로들을, n \in \mathcal{N}은 각 경로에 대응하는 숫자를 의미합니다. 논문에서 M에 대한 정의는 따로 하지 않고 있는데 아마도 수식1의 변환 및 투영 과정을 나타내는 함수로 해석이 됩니다.
아무튼 이렇게 변환된 경로 \mathcal{T}_c와 숫자 n \in \mathcal{N}이 포함된 이미지 i와 함께 언어 지시어 l가 입력으로 주어진다면 이제 VLM이 시나리오에 대한 색상-의미적 이해를 바탕으로 주행 가능한 하나의 경로를 선택합니다.
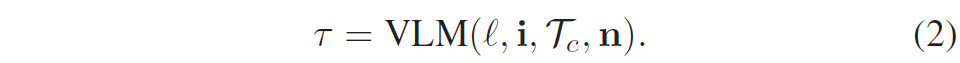
저자들은 가장 높은 확률을 가진 경로를 인간과 유사한 경로로 간주하여 선택하였다고 하며 수식적으로는 \max P(\tau | l, i, \mathcal{T}_c, n)으로 표현됩니다. 즉 저자들이 수행하는 앞으로의 task는 가장 높은 확률의 경로를 추측하는 것으로 이해하시면 될 것 같습니다.
Geometry-Based Trajectory Generation
경로 집합 \mathcal{T}는 연관된 confidence를 가진 경로들을 생성하기 위해 CVAE에 의해 생성됩니다. 구체적으로, CVAE 디코더를 위한 조건 값을 계산하기 위해 각 관측값 {o_l, o_v}을 encoder에 입력으로 합니다(c = f_e(o_l, o_v)). 그 후 임베딩 벡터는 임의의 신경망 f_z(\cdot)를 통해 z = f_z(c)로 계산이 된다고 합니다.
로봇의 주행을 위해 충분한 수의 후보 경로를 생성하려면, 로봇 전방의 모든 주행 가능 영역을 커버하는 다수의 경로를 만들어야 합니다. 저자들이 사용하는 디코더는 하나의 임베딩 벡터로부터 하나의 경로를 생성하도록 설계되었기 때문에, 다채로운 경로들을 생산하려면 다수의 임베딩 벡터들을 사용해야 합니다.
저자들은 다양한 임베딩 벡터를 생성하기 위해 우선 선형 변환을 통해 임베딩 벡터 z를 직교 축으로 투영하였다고 합니다. 여기서 각 투영된 벡터는 하나의 주행 가능 영역에 대응한다고 하네요. 그리고 아래 수식을 통해 c에 대한 경로들을 생성합니다.
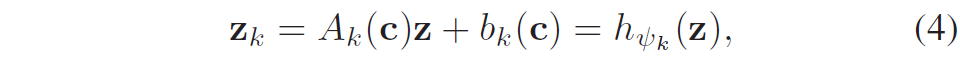
여기서 h_{\psi_k}는 z의 선형 변환을 나타냅니다. 이렇게 변형된 각 임베딩 벡터 z_k를 디코더에 입력하면, 디코더는 확률 분포 p(\tau_k | z_k, c, \bar{\mathcal{Z}}_k)를 통해 최종적으로 k번째 경로 \tau_k를 생성합니다.
모델의 학습 과정은 기존 연구인 MTG와 동일하게 진행되는데 저자들은 모델이 생성한 경로가 물리적으로 갈 수 있는 길인지(Traversability Loss), CVAE가 분포를 잘 학습했는지(Lower Bound), 그리고 경로들이 서로 충분히 다른지(Diversity Loss)를 평가하여 모델을 최적화했습니다.
VLM-Based Trajectory Selection
이 단계에서는 알고리즘1과 같이, 후보 경로들 중 최적의 하나를 선택합니다.

CVAE가 생성한 새로운 경로 세트 \mathcal{T}_n은 기하학적으로는 훌륭하지만, 딥러닝 모델의 특성상 항상 100% 주행 가능한 경로만 나온다는 보장은 없습니다. 그래서 저자들은 단일 시점의 결과만 믿는 게 아니라, 연속된 2개의 시간 스텝(t=2) 동안 생성된 경로들을 모두 모아서 후보군 \mathcal{T}를 구성합니다. 저자들은 후보가 많을수록 그중에 진짜 좋은 경로가 섞여 있을 확률이 높아진다고 판단한 것으로 보입니다.
하지만 경로가 너무 많으면 서로 겹치는 경로들이 이미지 위에 잔뜩 그려지면서 VLM이 알아보기 힘들게 됩니다. 그래서 저자들은 먼저 목표까지의 거리 순으로 경로들을 정렬한 뒤, 서로 너무 비슷한 경로들은 제거하는 필터링 과정을 거쳤다고 합니다. 아래 수식 5와 같이 하우스도르프 거리(Hausdorff distance)를 기준으로 정렬을 했다고 하네요.
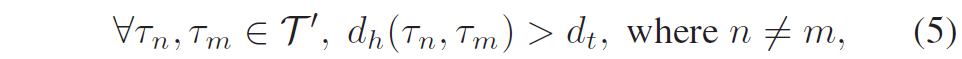
여기서 d_h(\cdot, \cdot)는 두 경로 사이의 하우스도르프 거리(두 곡선이 얼마나 닮았는지 측정하는 지표)입니다. 두 경로의 차이가 d_t보다 클 때만 유의미한 경로들로 판단하며 이는 모양이 거의 똑같은 중복 경로들을 제거하고 시각적으로 명확한 서로 다른 경로들(\mathcal{T}')만 남겨 VLM에게 제공한다고 생각하시면 됩니다.
정제된 경로들(\mathcal{T}')은 변환 행렬 K를 통해 이미지 평면 위의 경로 \mathcal{T}_c로 투영됩니다(\mathcal{T}_c = P_c(\mathcal{T}', K)). 그리고 아까 소개드렸듯이 각 경로 끝에는 식별 번호 n이 붙습니다.
이제 준비된 이미지(i), 경로 정보(n, \mathcal{T}_c), 그리고 언어 지시어(l)를 VLM에게 입력으로 줍니다. VLM은 이 정보를 바탕으로 주행 가능성, 사회적 규범(Social Compliance), 목표까지의 거리 등을 종합적으로 고려하여 최적의 경로 \tau를 선택합니다. 이는 수식 앞서 보여드렸던 수식 (2)로 표현됩니다.
그리고 저자들은 VLM이 올바른 판단을 하도록 돕기 위해, 다음과 같은 구체적인 프롬프트(l)를 사용했습니다.

대략적으로 나는 바퀴 달린 로봇이고 높은 턱은 못 넘어간다는 식으로 역할을 부여하고, 사람처럼 안전하게 목표로 가는 경로 하나만 골라라는 임무를 부여합니다. 그리고 반드시 포장된 도로(pavement)로 다녀야 하고, 울퉁불퉁한 곳은 피하고, 연석(curb)은 넘지 마라와 같은 제약조건과 마지막에 숫자가 작을수록 목표에 더 가까운 경로라는 정보까지 함께 텍스트 지시어로 전달해주는 방식입니다.
이를 통해, VLM이 경로를 선택하면 모션 플래너가 이를 따라 로봇을 움직입니다(a). VLM은 추론 속도가 느리기 때문에 한 번 대답하는 데 2~4초 정도 걸리지만, 저자들은 생성 단계에서 10m짜리 긴 경로를 미리 만들어두었기 때문에, VLM이 다음 판단을 내리는 동안 로봇이 멈추지 않고 부드럽게 주행을 이어갈 수 있다고 합니다.
Experiments
학습에 사용한 데이터셋은 Global Navigation Dataset 데이터셋이고, 추론 플랫폼은 Velodyne VLP16 LiDAR와 Realsense D435i 카메라가 장착된 Clearpath Husky 로봇을 사용했다고합니다. 그리고 모델 연산은 인텔 i7 CPU와 엔비디아 RTX 2080 GPU가 달린 노트북에서 처리했습니다. 경로 생성에는 어텐션(Attention) 메커니즘이 적용된 CVAE(MTG: Mapless trajectory generatorwith traversability coverage for outdoor navigation 방법론에서 사용된 인코더인듯.)과 경로 선택을 위한 VLM으로 GPT-4V를 사용했습니다.
저자들은 화단(Flower bed), 연석(Curb), 횡단보도(Crosswalk), 코너(Corner)의 4가지 시나리오에서 여러 모델의 경로를 시각적으로 비교했습니다. 비교방법론들로는 MTG (LiDAR 기반), ViNT / NoMaD (이미지 기반), CONVOI(이미지+LiDAR 기반) 등을 사용했습니다.
정량적 평가 지표로는 Traversability와 Fréchet Distance를 사용했다고 하는데 이들은 각각 생성된 경로가 실제로 갈 수 있는 영역 위에 있는지 비율과 로봇의 경로가 사람이 직접 조종한 경로와 얼마나 비슷한지를 의미한다고 합니다.
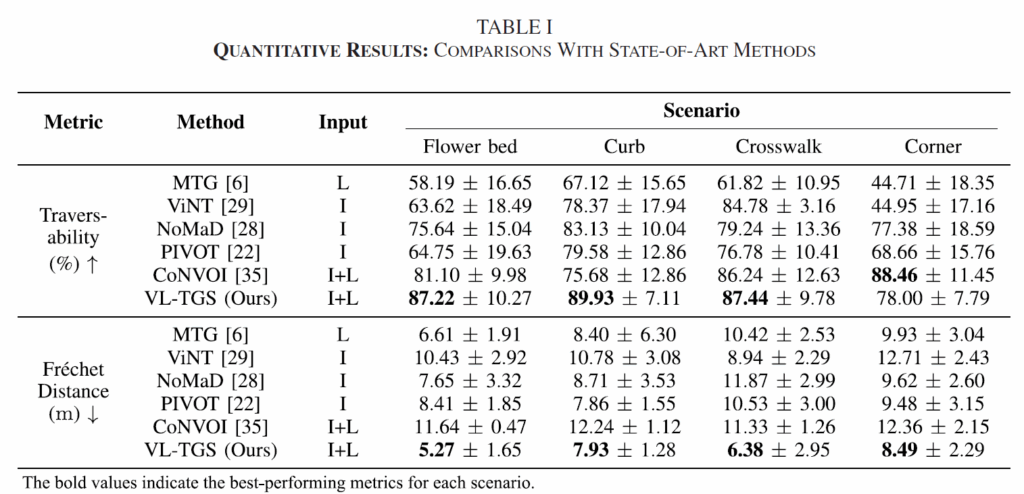
정량적 결과 표입니다. 결론부터 말씀드리면 저자들이 제안하는 방법론이 거의 모든 상황에서 타 방법론들보다 좋은 성능을 보여주고 있습니다. 아무래도 저자들의 방법론은 Image와 Lidar를 모두 사용하다보니 Lidar만 사용하는 MTG나 이미지만 사용하는 NoMaD와 비교해서 당연히 더 좋은 성능을 보여준다고 생각을 했었습니다.
근데 CoNVOI라는 방법론은 Image와 LidaR만을 사용했음에도 불구하고 일부 시나리오에서는 이미지만 사용한 NoMaD나 PIVOT보다 더 낮은 정량적 성능을 보여주는 경우가 발생하네요. 그리고 CoNVOI가 표면적으로는 점수가 아주 높은 경우들이 존재하는데 저자들은 이것이 잘못된 수치라고 합니다? CONVOI는 시작점과 끝점, 딱 두 개의 웨이포인트(Waypoint)만 생성하여 직선으로 연결하게 되는데 점이 두 개뿐이니 그 점들이 장애물 위에 찍힐 확률이 낮아 점수는 잘 나오지만, 실제로는 그 사이를 잇는 직선 경로가 장애물을 통과해버리는 경우가 많아 실제 주행 단계에서는 장애물이 부딪히는 경우가 발생한다는 것 같네요.
그리고 Lidar 기반의 MTG는 주행 가능성 점수가 다른 비교 방법론들 대비 매우 낮게 나왔습니다. 저자들은 이러한 결과에 대해서 두 가지 이유를 드는데, 첫째로는 실험 시나리오 자체가 LiDAR로는 감지하기 힘든 지형(화단, 낮은 연석 등)이라고 합니다. 둘째는 MTG 알고리즘 자체가 ‘주행 가능성’보다는 ‘목표 지점까지의 최적 경로(Optimality)’를 우선시하다 보니, 안전하지 않은 길이라도 지름길이라면 선택해버리는 경향이 있었기 때문에 성능 자체가 낮게 나온 것이 아닌가로 판단하였다고 하네요.
반면에, Fréchet Distance에서는 타 방법론들과 비교해서 나름 경쟁력 있는 성능이 나왔는데 이는 MTG나 VL-TGS 둘 다 부드러운 곡선 형태(Smooth trajectories)의 경로를 생성하며 이게 사람이 조종하는 방식과 비슷하기 때문에 그런 것이라고 합니다.
NoMaD의 경우에는 횡단보도처럼 직선으로 뻗은 길은 잘 가지만, 코너를 돌거나 상황이 급변하는 동적 환경에서는 경로를 이탈하는 경향이 있었다고 합니다. 특히 화단이나 연석 시나리오처럼 부드러운 회전이 필요한 곳에서는 성능 편차가 매우 컸습니다.
결과적으로 VL-TGS는 모든 시나리오에서 가장 사람과 비슷한 부드러운 경로를 생성하면서도, 주행 불가능한 영역을 확실하게 피하는 유일한 모델이라고 저자들은 주장합니다.
Ablation Study
다음은 ablation study입니다. Ablation study에서 저자들이 수행한 실험은 크게 2가지로, VL-TGS의 두 핵심 축인 Trajectory Generator와 Trajectory Selector에 대한 절제 실험을 수행했습니다. 저자들은 각 모듈을 제거하거나 단순화했을 때 주행 성능이 어떻게 저하되는지를 비교 실험을 통해 분석하네요.
첫 번째 실험은 저자들이 제안하는 CVAE 같은 복잡한 모델로 경로를 생성하는 것이 아닌 그냥 무작위로 그리거나 직선으로 연결하는 방식입니다. 특히 직선으로 연결하는 방식은 PIVOT 방법론과 유사한 방식이라고 하여 아래 실험에서 PIVOT이라고 표기되어있습니다.

그림4는 생성된 후보군들을 정성적으로 표기한 것이며 PIVOT 방식은 인도가 아닌 잔디를 뚫고 가는 반면에 저자들이 제안하는 방식은 인도를 통한 알맞는 경로를 생성하는 것을 확인할 수 있습니다. 참고로 CONVOI 방식은 이미지 상에서 장애물이 없는 구역을 찾아 번호를 매긴 뒤, 그 지점까지 직선으로 연결하는 방식으로, 그림4 a를 보시면 출발점과 목표점은 안전한 곳에 찍히지만, 웨이포인트 사이를 단순히 직선으로 잇다 보니 경로 중간이 장애물과 겹치는 상황이 발생했습니다.
두 번째 실험은 VLM으로 경로를 선택하는 것이 아닌 그냥 생성된 경로 중에서 목표랑 제일 가까운 걸 고르는 방식에 대한 실험입니다. 이를 위해 VLM 선택기를 제거하고, 단순히 거리 기반 휴리스틱(Heuristic)을 사용하는 MTG 방식과 비교했습니다.
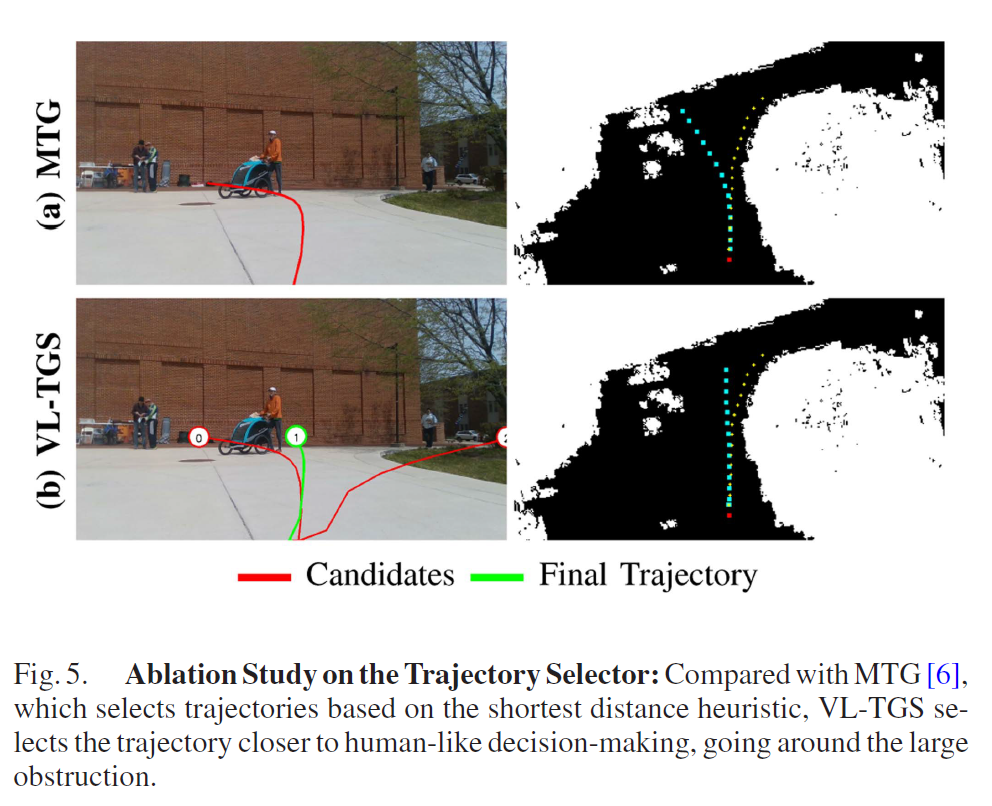
결과는 위의 그림5와 같은데 MTG는 CVAE로 좋은 경로를 만들어내긴 하지만, 선택 기준이 목표점까지의 최단 거리다 보니 동적인 사람 및 사물을 뚫고 지나가는 경로가 가장 짧다고 판단하여 선택해버립니다. 그리고 위의 예시에서는 볼 수 없지만, 저자들이 확인한 바로는 건물을 뚫고 지나가는 경로가 가장 짧다고 판단하여 이러한 잘못된 경로를 선택해버린다고도 하네요.
반면, VLM은 시각 정보를 통해 “저것은 건물(장애물)이니 돌아가야 한다”거나 “사람이 있으니 피해야 한다”는 맥락을 이해합니다. 따라서 그림 5(b)처럼 건물을 우회하는, 더 안전하고 사람다운 경로를 선택한다고 합니다. 이는 VLM이 경로를 선택하는 방법론에서 적합하다고 볼 수 있겠네요.
결론
경로를 생성하는 파트와 생성된 경로 후보군들을 정해놓고 VLM이 선택하는 두가지 파트를 통해 navigation을 하는 방법론으로 좋은 경로를 생성할 수 있다면 VLM을 통해 사람처럼 안전하게 길을 가는 경로를 선택할 수 있다는 것이 재밌었네요. 근데 아쉬운건 ablation study가 정성적 case 한가지씩만 보여줬던거라 이걸 고대로 신뢰할 수 있는지는 쉽지 않을 듯 합니다. 근데 비교 실험 대상 자체가 랜덤하게 샘플링하기, 직선상 웨이포인트 잇기 등 단순한 방식들이라.. 당연히 해당 방식들이 성능이 안좋을거라는 확신이 있어 리뷰어들이 그냥 넘어간게 아닌가 싶기도 하구요.