이번 주 X-Review에선 25년도 NeurIPS에 게재된 논문 <Don’t Just Chase “Highlighted Tokens” in MLLMs: Revisiting Visual Holistic Context Retention>을 소개해드리겠습니다. 88.9%의 pruning ratio에도 기존 성능의 96%를 보존하며 SOTA를 달성한 VLM token pruning 방법론입니다
이 분야로 지금 연구를 진행하고 있진 않지만 VLM 쪽 vision token pruning/merging 쪽은 어떻게 발전하고있는지 꾸준히 살펴보는 차원에서 읽게 되었습니다.
리뷰 시작하겠습니다.
1. Introduction
MLLM은 captioning, question answering, video understanding 등 다양한 비전 분야 task에서 빠르게 발전하고 있습니다. 정말 하루가 멀다하고 많은 모델들이 쏟아지고 있는 상황입니다. 이렇게 새로운 모델들이 많이 제안되는 만큼, MLLM의 vision token으로부터 비롯되는 연산량 문제 관련 연구도 다양하게 진행되고 있습니다. 336 해상도를 갖는 이미지 한 장을 입력받았을 때, LLaVA-1.5는 576개, LLaVA-NeXT는 2,880개를 뽑아 사용합니다. 멀티 이미지나 비디오를 다루는 모델들은 훨씬 많은 개수를 입력해야하는 상황인 것이죠.
연산량 관련 연구들은 수 천개의 vision token을 모두 사용하지 않음으로써 추론 시 발생하는 computational overhead를 완화하고자 합니다. 결국 사용하지 않을 vision token의 기준을 무엇으로 잡을 것인지가 이 분야 연구의 핵심 아이디어라고 볼 수 있습니다. 기존 연구에선 attention score나 gradient 정보를 통해 각 토큰의 중요도를 정량화하여 제거할 토큰을 선정하는 것이 기본적인 흐름이었습니다.
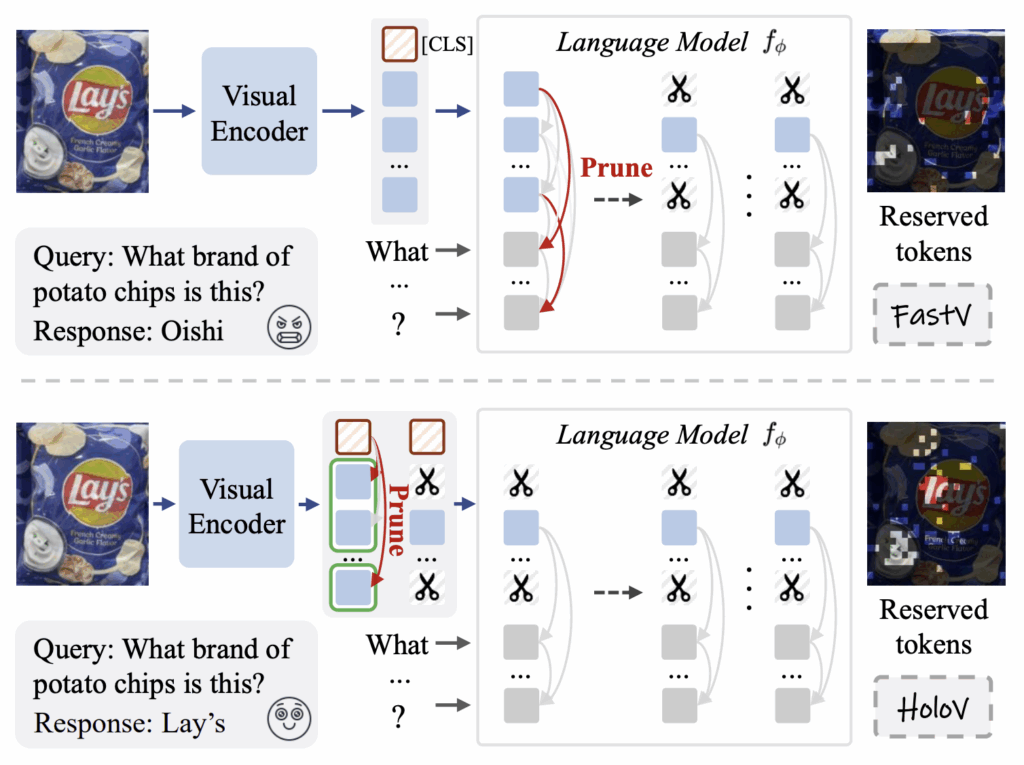
위 그림 1 상단에는 이전 방법론 중 하나인 “FastV”의 모식도가 나타나있습니다. FastV는 가장 직관적인 pruning 방법론이라고 보시면 됩니다. LLM layer 내부에서 계산되는 V-T attention weight를 각 토큰의 중요도라 보고, 그 중요도가 낮은 하위 R%의 토큰은 지운 뒤 뒷단으로 넘겨주는 것입니다. 이렇게 텍스트와의 상관관계를 바탕으로 pruning하는 방식도 있고, 반대로 [CLS] 토큰이 나머지 vision token으로 주는 attention weight를 점수로 삼아 pruning하는 vision-centric 방식도 있습니다. 저자가 본 논문에서 제안하는 HoloV도 후자에 속한다고 볼 수 있습니다.
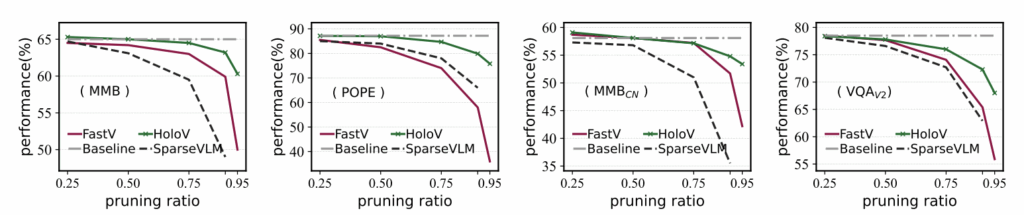
위와 같은 기존 pruning 방법론들이, 전체 visual token을 사용하는게 비효율적임을 증명한 것은 사실입니다. 그러나 이들이 일관성을 가진채로 효율적인지는 다시 보아야 한다고 이야기합니다. 그림 2를 보시면, 4개 벤치마크에 대해 보라 실선으로 표시된 FastV와 점선으로 표시된 SparseVLM은 pruning ratio를 늘림에 따라 성능 하락 폭이 점점 커지는 것을 볼 수 있습니다. (반면 HoloV는 극단적인 pruning ratio에도 성능이 나름 보존됩니다.) 저자는 이러한 현상이, “attention이 높은 토큰일수록 정보량도 많을 것이다”라는 기존 방법론들의 가정으로부터 발생한다고 이야기합니다.
이 가정은 얼핏 당연해보이지만, 실제로는 pruning ratio가 커질수록 토큰 간의 spatial semantic relation을 완전히 무시하게 됩니다. Attention score가 높은 토큰들은 대체로 그들끼리 유사하기 때문에 특정 영역에 뭉쳐있게 되고, 그렇다보니 pruning ratio를 키울수록 서로 비슷비슷한 토큰만 살아남게 되는 것입니다. Pruning 후 모델이 보는 토큰들은 더이상 어떠한 구조적 정보를 포함하고 있지 않다는게 저자의 주장인 것이죠.
정리하자면, 장면의 전반적인 semantic comprehension을 위해서는 주요 토큰들의 공간적, 의미적 연결성이나 주체에 대한 정보 등이 필요합니다. 그러나 서로 비슷한 토큰만 남게되면 정보의 다양성이 떨어져 모델이 장면을 해석하는 데에 어려움을 주고, 성능 하락이 클 수 밖에 없다는 이야기입니다.

추가적으로, MLLM의 기반이 되는 transformer attention 연산의 positional encoding mechanism에는 spatial 편향이 있다고 합니다. 그림 3 우측은 FastV가 ratio에 따라 pruning한 결과물을 나타내고 있는데, 실제로 가장 윗 줄과 아랫 줄의 토큰들이 많이 살아남는 것을 볼 수 있습니다. 이러한 편향을 안고 남긴 토큰을 추론에 쓴다면 당연히 성능 악화와 환각을 일으킬 수 있겠죠.
여기까지 기존 방법론들의 문제를 알아보았고, 저자는 이를 극복하기 위해 “How to locate and preserve those not highlighted but critical to visual holistic understanding tokens?”라는 질문을 던지게 됩니다. Attention이 높은 토큰만 써서는 장면 이해에 한계가 있다는 점을 깨닫고 score는 낮지만 중요한 토큰을 어떻게 구할지 고민하게 된 것이죠.
인지 과학에 따르면 사람은 시각 정보를 파악할 때 배경, 공간 구조와 같은 글로벌 정보와 자잘한 로컬 정보를 합쳐가며 이해를 완성한다고 합니다. 기존 text-mapping 분석 방식을 활용해 visual token과 text 단어 간 매핑을 진행해본 결과가 그림 3 왼쪽에 나타나있습니다. 왼쪽 상단에 스키타고 있는 그림은 몇 개의 흩어진 토큰으로 설명이 가능하다고 볼 수 있는데요. 예를 들면 여러 지역에 걸쳐 흩뿌려져 있는 “snow”, “ski”, “hills”와 같은 3개 단어만 있어도 이 장면을 설명할 수 있다는 뜻입니다. 앞서 저자가 이야기했던 주요 토큰들이 바로 저 단어에 상응하는 vision token들이라고 볼 수 있습니다.
이러한 motivation을 안고, 저자는 visual token pruning 과정에서 semantic connectivity와 contextual attention 간 균형을 명시적으로 잡는 방법론 HoloV를 제안합니다. 기존처럼 attention 값이 높은 토큰만 살리는 것이 아니라 이미지 전체의 정보를 고려한다는 측면에서 visual holistic context를 보존한다고 볼 수 있습니다. 참고로 HoloV는 여타 pruning 방법론처럼 model-agnostic한 기법입니다.
논문에는 저자가 언급한 기존 방법론의 문제 및 motivation에 대한 상세 분석이 있는데, 결론은 같기에 우선 리뷰에서는 넘어가겠습니다. 관련해서 질문 주시면 추가 설명 간단히 드리도록 하겠습니다.
2. Methodology
저자는 이미지의 전체 맥락(holistic context)을 잘 보존할 수 있는 HoloV를 제안합니다. 앞서도 언급했듯 vision-centric 방식, 즉 LLM decoder에 입력을 태워보지 않고도 pruning을 수행할 수 있는 갈래에 속하기 때문에 효율성 을 강구하는 방법론 중에서도 좀 더 효율적이라고 볼 수 있겠네요.
2.1 HoloV Framework
이제 HoloV가 어떻게 높은 pruning ratio에도 정보를 잘 보존하는지, 그 방식을 알아보겠습니다. 우선 아래 그림 4가 HoloV의 핵심 framework를 보여주고 있습니다.
Introduction에서 저자가 던진 질문은 “어떻게 하면 highlight 되지는 않았지만 실제 context 이해에 중요한 토큰을 알아볼 수 있을까?”였습니다. 이를 위해 HoloV는 crop-wise adaptive allocation 방식을 도입해 강조되진 않았지만 다양한 토큰(저자가 찾고자했던 토큰)들로 attention을 decentralize하고자 합니다. 뭔가 용어가 추상적이라 영어 단어로 그냥 적었는데, 기존에 서로 유사한 토큰들에만 높게 뿌려져있던 attention 가중치를 다양한 토큰들에게 재분배해주는 컨셉 정도로 이해해볼 수 있겠습니다.

그림 4를 같이 보며 설명드리겠습니다. 큰 흐름만 간략히 설명드리겠습니다. 먼저 이미지를 초록색으로 표시된 여러 crop으로 쪼개고, 각 토큰과 각 crop의 중요도를 계산합니다. 이후에는 살려야할 토큰을 각 crop에 몇개씩 할당할지를 결정하여 나머지는 버리는 것이 HoloV의 전부입니다.
이제부턴 각 단계를 좀 더 자세히 설명드리겠습니다.
앞서 attention 방식이 내재하는 positional encoding에 의한 bias를 완화하기 위해, 먼저 visual token을 공간 축에서 crop함으로써 재배열합니다. 한 이미지에 대한 토큰 개수를 N_{v}라 할 때, 균등한 \mathcal{C}개 crop으로 나누는 것입니다. 그림상으로는 초록색 구역들이 이 crop이라 볼 수 있습니다.
이렇게 얻은 c번째 crop에 대한 feature를 Z_{v}^{c} \in{} \mathbb{R}^{M \times{} d}라 할 때, 해당 crop 내부 토큰간 유사도 matrix S^{c}를 아래 수식 (1)과 같이 계산합니다.
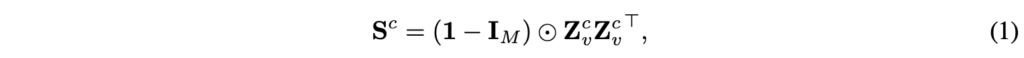
수식 (1)에서 I_{M}은 self-similarity를 마스킹하기 위한 항등 행렬입니다. 현재 crop 내에서 자기 자신을 제외한 M-1개 토큰과의 유사도가 매트릭스에 담길 것입니다.
다음으로는 아래 수식 (2)를 통해 crop 내에서 한 토큰이 다른 토큰들과 얼마나 다른지 아래 수식 (2)와 같이 구해줍니다. 수식상 현재 토큰이 갖는 유사도 벡터S_{i}^{c}의 분산을 보는 것입니다.
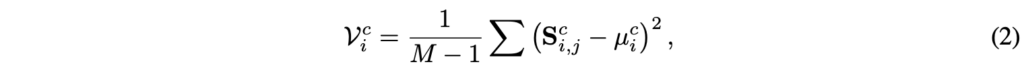
\mathcal{V}_{i}^{c}가 높다는 것은 i번째 토큰이 다른 토큰들과 다양한 connection을 가진다는 것입니다. 저자는 이를 해당 토큰이 crop 내 semantic 구조를 대표한다는 것으로 해석하였습니다. 이 부분이 바로 와닿지는 않았는데, 앞선 예시에서의 “ski”는 자체적으로 의미가 명확한 객체 중심의 토큰이기 때문에 “snow”, “cloud” 각각 토큰에 대한 유사도 편차가 클 것이라는 의미입니다. 반대로 뒷배경에 해당하는 “cloud” 관점에서는 “snow”나 “ski”나 유사도가 비슷비슷하게 나오겠죠. 이렇게 다른 토큰들과 다양하게 연결되어있는 토큰이 이 crop을 이해하는 데에 핵심이 된다는 것이 저자의 insight입니다.
저자는 방금 얻은 contextual diversity와 기존 방법론들과 동일한 방식인 attention saliency을 둘 다 활용해 토큰의 점수를 얻습니다.
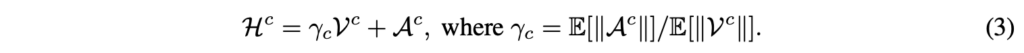
위 수식 (3)에서 \mathcal{A}^{c}는 [CLS] 토큰이 각 토큰에 주는 attention weight입니다. 특이한 점은 평균 norm의 비율인 \gamma{}_{c}를 분산 앞에 곱해준다는 것입니다. 아무래도 하나는 분산이고 하나는 attention weight이다보니 두 값간 scale을 맞춰주는 역할도 하고, 일종의 adaptive한 하이퍼파라미터처럼 동작하는 것이라고 볼 수 있습니다.
Adaptive holistic token allocation
수식 (3)까지 하여 토큰의 중요도를 계산했습니다. 이젠 이 중요도를 기준으로 여기서 남길, 삭제할 토큰을 어떻게 정하는지 알아보겠습니다. Pruning 후 남길 총 quota 값 T'은 \mathcal{C}개 crop에 동적으로 할당됩니다. 이 때 crop의 중요도에 따라 quota가 넘치는 crop이 부족한 crop으로 넘겨주기도 하는데, 중요도 w_{c}는 먼저 아래 수식 (4)를 통해 추출됩니다. 단순히 crop 내 토큰들의 중요도를 기준으로 계산하고 있고, \tau{}는 sharpness를 조절하는 하이퍼파라미터입니다.
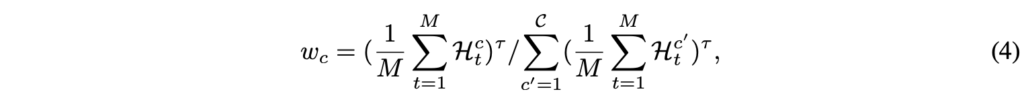
초기의 quota q_{c} = \lfloor{}w_{c}\hat{N}_{v}\rfloor{}이고, \hat{N}_{v}는 남길 토큰의 개수입니다. 이렇게 1차적으로 결정된 q_{c}가 만약 crop의 토큰 개수보다 크면 (overflow) 할당되지 못하는 quota가 생깁니다. 남겨야할 토큰 개수와 score에 따라 이 crop에서 20개를 남기려고 했는데, 한 crop 내 토큰 개수가 16개씩이라면 4개는 아직 남기지 못한 상황이 되는거죠. 이런 경우 quota는 재분배됩니다.
재분배 시 quota는 q_{c} = min(q_{c} + \Delta{}_{c}, M)로 수정됩니다. 이 때 \Delta{}_{c} \propto{} w_{c} · (M − q_{c})입니다. 이 재할당은 반복적으로 이루어지기 때문에 그냥 비례라는 표현을 쓴 것 같고, pruning이 가능해질 때까지 수행합니다. 결국 crop이 중요한지, 남길 수 있는 토큰 개수가 많이 있는지를 같이 고려하여 재할당하는 것입니다. 반대로 각 crop별로 다 채웠음에도 아직 살려야할 토큰 개수가 남아있다면(fall short) 그냥 아직 결정되지 않은 애들 중 중요도가 높은 토큰 순서대로 해당 개수를 채웁니다.
Top-k visual token selection
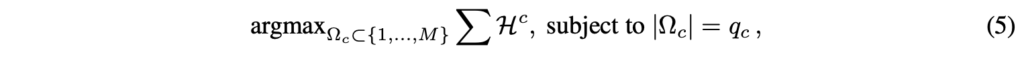
수식 (5)는 진짜 남길 토큰을 고르는 과정입니다. 각 crop 내에서 점수의 합을 최대로 만드는 q_{c}개 토큰을 찾는 것이니, 단순히 crop 내 Top-w_{c}개 토큰을 살리고 나머지를 지운다고 보시면 됩니다.
결국 방법론의 핵심은 이미지를 crop 단위로 나누어 너무 좁은 영역의 토큰들만 살아남는 것을 방지하였으며, crop 내 다른 토큰과의 유사도 분산이 큰 토큰을 중요 토큰으로 삼은 insight 이렇게 두가지 정도로 볼 수 있겠습니다.
3. Experiments
3.1 Experimental Setup
Benchmarks
HoloV 방법론은 잘 학습된 모델의 평가 과정을 최적화하는 기법이니 별다른 학습 과정은 없습니다. 평가는 여러 visual benchmark 데이터셋에서 진행되었습니다. Image understanding 관련해서는 흔히 사용되는 GQA, MMBench, MMB-CN, MME, POPE, VizWiz, ScienceQA, VQA v2, TextVQA, MMVet를 평가했습니다 . 또 video QA 관련해선 MSVD-QA, MSRVTT-QA를 평가에 썼다고 합니다.
Comparison methods
위 벤치마크들에 대해, 기초적인 추론 최적화 방법론부터 최근 방법론들까지 폭넓은 성능 비교를 진행합니다. 방법론들로는 ToMe, FastV, SparseVLM, HiRED, LLaVA-PruMerge, PDrop, MustDrop, FasterVLM, VisionZip, DART 등이 있다고 하는데 들어본 방법론도 있고 처음 보는 방법론도 있네요. 이들 중엔 일반적인 token merging, attention-based pruning, adaptive allocation, hierarchical retention 등등 다양한 방법론이 포함되어있다고 합니다.
저자가 각 방법론에 대해 한줄 요약해둔 것도 있어서 필요하신 분들은 참고하시면 좋을 것 같습니다.

3.2 Main Results
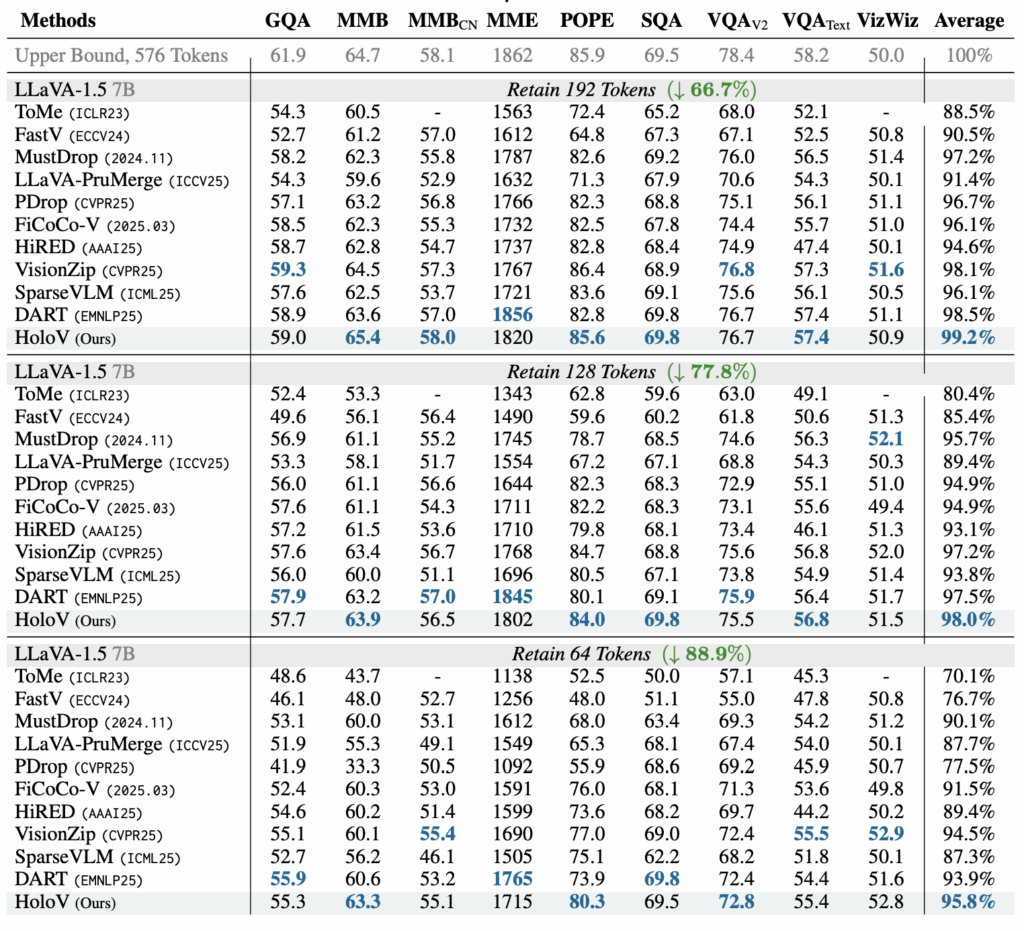
General-purpose benchmarks
표 1은 베이스라인 모델 LLaVa-1.5 7B 추론에 다양한 pruning 기법을 적용했을 때의 성능을 보여주고 있습니다. 기본적으로 HoloV는 모든 pruning ratio 세팅에서 가장 높은 성능을 달성하고 있습니다. 특히 베이스라인 대비 88.9% 제거된 개수만큼의 토큰을 써도 4.2%의 성능 손실만 발생한다는 점이 놀랍습니다. 지난번에 리뷰했던 VisionZip 방법론도 이전 방법론들보다 큰 격차로 성능이 높았었는데, 아예 관점을 바꿔 crop 내 유사도 편차가 큰 토큰을 선택하는 전략이 더욱 잘 동작한다는 것이 놀랍네요.
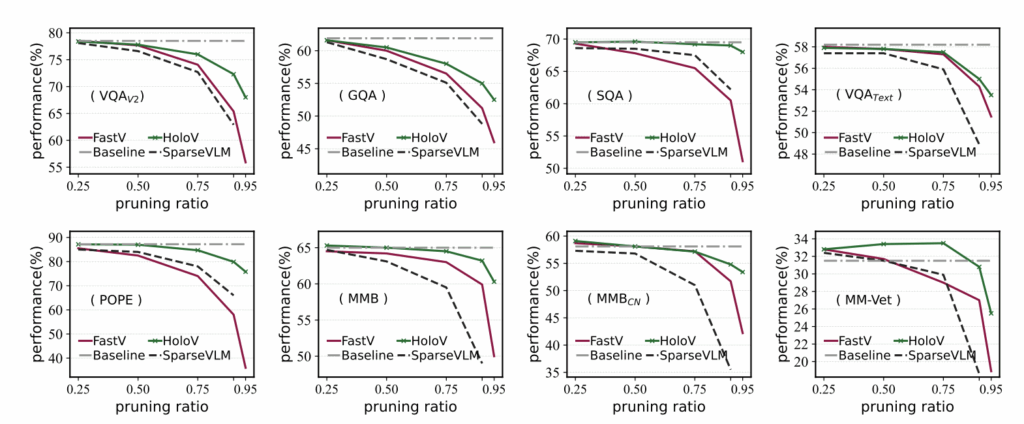
또한 그림 5에서는 pruning ratio 더욱 다양하게 바꿔가며 얻은 결과인데, FastV나 SparseVLM과 같은 단순 attention 기반 방법론들에 비해 HoloV는 굉장히 높은 pruning ratio에도 남겨진 토큰의 다양성이 유지(=이미지 전체 맥락 이해에 유리)되며 성능 방어에 상대적으로 성공하는 모습을 볼 수 있습니다.
Hallucination benchmarks validation
표 1에 나타나있는 POPE와 MME 성능을 통해 hallucination 관련 능력도 살펴볼 수 있습니다. 특히 POPE에서는 기존 방법론들의 성능을 압도하며 저자가 이야기했던 “attention 기반으로 토큰 잘못뽑으면 hallucination 발생 가능” 상황을 완화한다는 것을 알 수 있었습니다.
3.3 HoloV with Higher Resolution
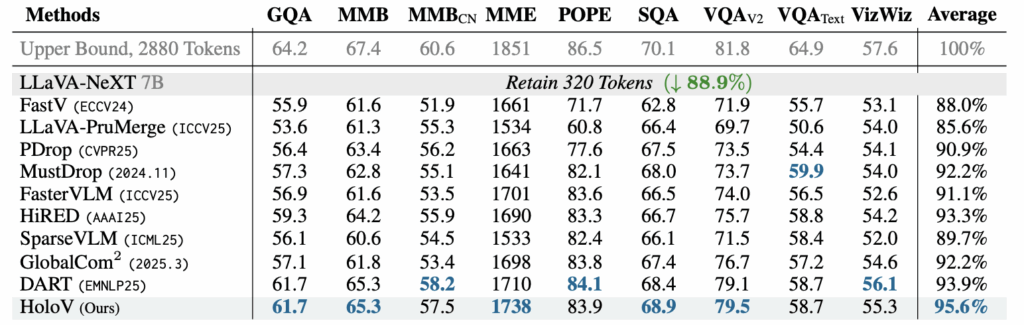
표 2에는 이미지 당 2,880개의 토큰을 소모하는 LLaVA-NeXT 7B 모델에 HoloV를 붙였을 때 성능을 보여주고 있습니다. LLaVA-NeXT는 AnyRes라는 vision token 생성 전략을 활용해 입력 이미지의 다양한 해상도에 대응할 수 있도록 설계되어있습니다. 이러한 전략에도 HoloV는 잘 맞아떨어져 베이스 LLaVA-NeXT보다 88.9%의 토큰을 덜 사용했음에도 95.6%의 성능을 유지하였습니다.
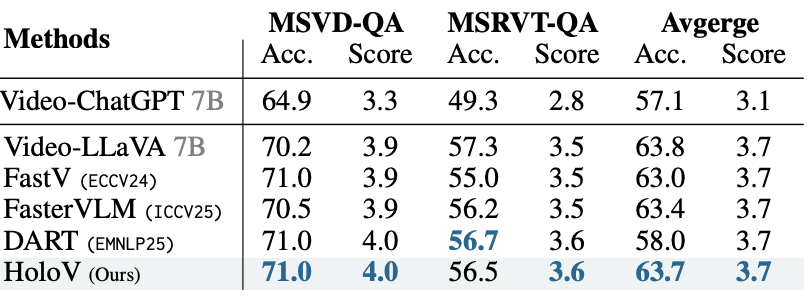
표 3은 HoloV가 붙은 Video-LLaVA 모델의 비디오 벤치마크 평가 성능입니다. 베이스 모델이 사용한 토큰 개수의 50%만 썼을 때 성능을 의미하며 다른 SOTA 방법론들과 거의 견줄만한 성능을 내고 있습니다. 여기선 편차가 그렇게 크진 않고, 또 DART 방법론은 평균 성능이 잘못들어간 것인지 확인해봐야겠네요. 아무튼 HoloV가 고해상도 이미지, 비디오에 대해서도 준수하게 동작함을 알 수 있었습니다.
3.4 Efficiency Analysis
추론 효율화 관련 연구이다보니 당연히 추론 속도나 효율성에 대해서도 살펴봐야겠죠.

위 표 4는 POPE 데이터셋에 대한 SOTA 방법론들과의 추론 효율성 비교 표입니다. 표에는 전체 추론 시간 (Time), prefill time, end-to-end latency, GPU memory usagedhk 정확도를 열별로 적어두었습니다. 효율성 측면에선 다른 방법론들에 비해 크게 떨어지지 않으면서 성능이 압도적으로 높다는게 드러나는 표입니다.
3.5 Ablation Analysis of Crop Numbers
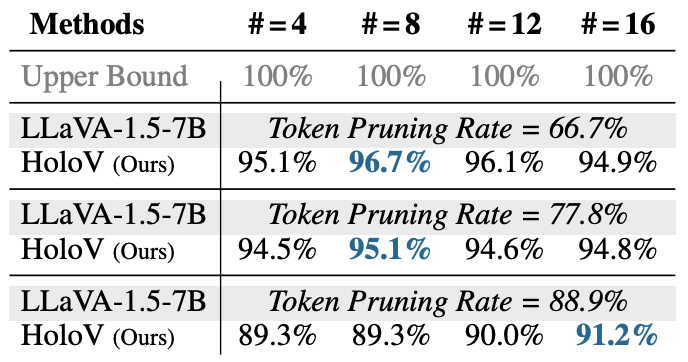
표 5는 방법론 상에서 균등하게 나누는 crop의 개수 \mathcal{C}에 대한 ablation 성능입니다. 앞서 프레임워크를 보여준 그림 4에서는 \mathcal{C}=6처럼 나타났지만, 실제 결과를 보았을 때 저자들은 딱히 \mathcal{C}에 따른 성능 편차는 크지 않다고 주장합니다. 이건 결국 \mathcal{C}를 몇으로 주든 quota는 일정하며, 남길 토큰은 동적으로 반복 재할당되며 최적을 찾아가기에 큰 차이를 주는 요소는 아니라고 이야기하는 것으로 보입니다. 근데 이 실험의 세팅에 대한 언급이 따로 없고 심지어는 표 5와 표 1 간 매칭되는 성능이 딱히 없어 결국 어떤 값을 썼는지는 알 수 없었습니다.
3.6 Visualization Analysis
마지막으로 정성적 결과를 살펴보며 리뷰 마치겠습니다.

그림 6은 다양한 pruning ratio에 따른 방법론별 시각화 결과로, 검은 토큰들은 버려진 토큰입니다. 이미지에서 박스는 이미지 내 주요 객체를 표시해둔 것으로, HoloV가 찾고자했던 주요 토큰들을 포함하고 있다고 볼 수 있습니다. 실제로 FastV에 비해 HoloV는 저자가 언급한 positional encoding으로부터 비롯된 bias도 적고, 실제 객체에 해당하는 토큰을 더 많이 살려 의미를 보존하는 것을 볼 수 있습니다.
마지막으로 논문에선 LLaVA 계열이 아닌 Qwen2.5-VL에 적용했을 때에도 SOTA임을 정량적으로 보여주는데, 해당 실험은 궁금하신 경우 찾아보시면 좋을 것 같습니다.
VLM의 추론 효율화의 한 갈래인 vision token pruning, merging 관련 연구가 실험실 레벨에서 수행하기 좋다는 생각이 있어 추후 연구 주제로 잡아볼만하다고 생각했는데, 이쪽 task의 논문을 읽을수록 정말 잡다한 학습 테크닉 없이 철저한 분석과 증명으로 방법론을 구성하고 서술해야한다는 점이 매력적이라고 느껴집니다. NeurIPS에 붙으려면 이 정도 분석과 논리력은 갖춰야한다는 것을 다시 한 번 꺠달을 수 있었던 논문이었습니다.