안녕하세요 최인하입니다. 오늘은 예전부터 리뷰하고 싶었던 Attention Is All You Need 논문을 리뷰해 보려고 합니다. 기존 자연어 처리 모델들이 attention으로 Encoder와 Decoder가 연결되어있는 구조로 좋은 성능을 보였는데, 논문에서 소개하는 Transformer model은 Encoder, Decoder 내부에서 attention을 수행하는 self-attention 기법을 도입하여 SOTA를 달성하였습니다. 또한 sequential한 데이터를 처리하는 RNN의 long term dependencies와 병렬화가 안된다는 문제를 해결하였습니다. 바로 시작해보겠습니다.
위의 그림은 Transformer model의 architecture 입니다. 순차적으로 Transformer model이 어떻게 machine translation task를 수행하는지 설명해보겠습니다.
우선 Transformer의 Encoder, Decoder 부분을 설명하기 전에 전처리 과정이라고도 할 수 있는 input Embedding 과정과 Positional Encoding 과정에 대해서 설명하겠습니다. “나는 학생이다” 를 “I am a student”로 번역하기 위해서, “나는 학생이다.”를 model이 이해할 수 있도록 Embedding하는 과정이 필요하겠죠 이 또한 Embedding layer를 통해 학습이 되며, 단어 즉 token 형태의 data를 수치 형태의 벡터로 변환합니다. 이 때 유사한 단어는 유사한 값을 지니도록 embedding을 수행하게 됩니다.
기존의 RNN과 달리 transformer는 sequential한 데이터를 병렬로 처리하므로 각 단어 즉 token의 위치에 대한 정보를 알지 못합니다. 따라서 위치 정보를 Positional Encoding 방식으로 Embedding 된 벡터에 주입합니다. positional Encoding 방식으로는 sinusoid positional encoding 방식이 사용되었습니다.
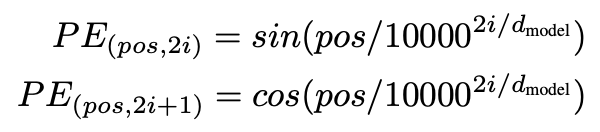
여기서 d(model)은 embedding vector의 차원입니다. pos는 입력되는 sequence data에서의 embedding vector의 위치입니다. (예를들어 나는 학생이다 에서 나는 : 0, 학생 : 1, 이다 : 2) i 는 0,1,2 .. 로 증가하며 embedding vector 내 차원의 순서를 표현합니다. 즉 홀수 차원은 cos을 짝수 차원은 sin 값을 받게 되겠죠? 이렇게 얻어진 벡터를 embedding 벡터에 더해줌으로써 단어의 정보를 담고 있는 벡터는 위치 정보까지 포함하게 됩니다. (더해지는 과정에서 embedding 벡터에 root(d(model))을 곱해줌으로써 스케일링을 수행합니다. 저는 임베딩 된 벡터의 수치가 작은 값인데 -1~1 사이의 값을 더해주게 되면 단어의 의미가 손실 되기 때문에 스케일링을 수행한다고 이해했습니다.) 이렇게 얻어진 벡터가 이제 Encoder에 들어가게 됩니다.
Encoder of Transformer
Attention
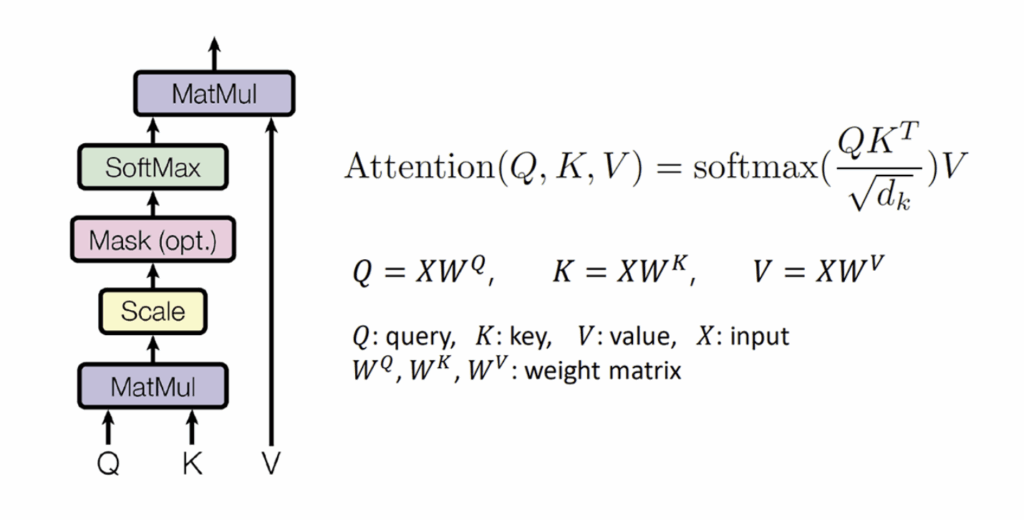
논문의 제목처럼 Transformer 구조에서는 Attention이 많은 부분을 차지합니다. 따라서 model 구조 안에서 attention이 어떻게 수행되는지 이해해야합니다. Attention의 식을 보면 다음과 같습니다.
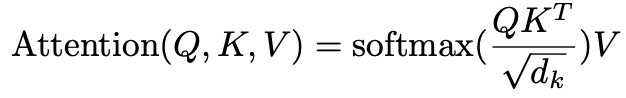
Attention을 구하기 위해서는 Q, K, V가 필요한데, 각각 Query, Key, Value를 의미합니다. Query, Key, Value에 대해서 제가 이해한 대로 설명해보겠습니다. (부정확한 부분이 있으면 댓글 남겨주시면 감사하겠습니다.) Query는 현재 처리하는 단어를 나타내는 벡터라고 이해했습니다. 즉 나는 지금 이 단어가 다른 단어와 얼만큼 연관성을 가지고 있는지 알고 싶어라고 질문할 때 Query는 질문의 역할을 하는거죠. Key는 각각의 단어에 대한 정보 값이라고 이해했습니다. 즉 Query를 받았을 때 Key를 dot product 해줌으로써 key 단어와 query 단어와의 연관성(attention score)을 계산해주는 역할을 수행하는 것으로 이해했습니다. 마지막으로 value는 위에서 말한 정보를 갖고 있는 벡터라고 이해했습니다. 즉 단어가 문장 내에서 다른 단어와 얼만큼의 연관성을 지니고 있는지에 대한 정보를 담고 있는 벡터입니다.

Query, Key, Value는 input에 학습된 가중치 벡터를 곱하면서 형성됩니다. 이렇게 구해진 Q, K, V 벡터로 Attention을 수행하게 됩니다. Encoder 내부 정보만 가지고 Attention을 수행하므로, Self-Attention이라고 합니다. Self-Attention의 수행과정은 위의 그림과 같습니다. 학습된 가중치 벡터로 뽑아진 query와 key를 dot product 해줌으로써 attention socre를 추출하고, 이를 softmax 태우기 전 키벡터의 차원에 root를 씌운 값으로 나누어 줍니다. (softmax에 큰 값이 들어가서 vanishing gradient를 유발할 수 있기 때문에라고 이해했습니다) 그후 softmax 값과 value 벡터를 곱해주고 나온 value 벡터를 전부 더해주면 최종 특징 벡터인 z가 나오게 됩니다.
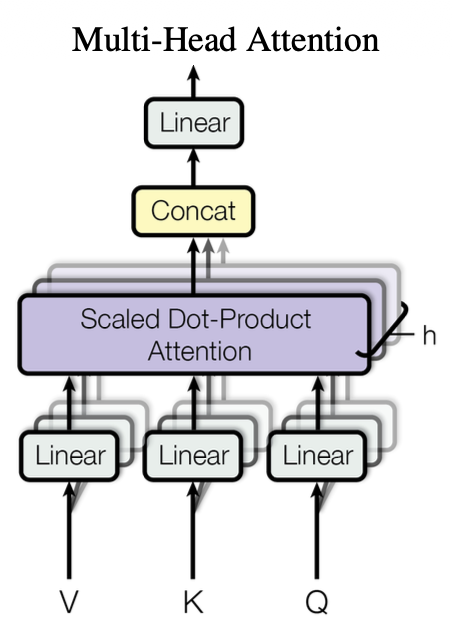
이 과정을 병렬적으로 수행한 것이 Multi-Head Attention입니다. CNN에서 여러 feature를 추출하기 위해서 여러 채널을 사용하는 것처럼 Multi-Head 또한 같은 방식이라고 이해했습니다.

그 후 head의 수만큼 증가된 z 벡터의 차원을 (concat 되므로) 학습되는 가중치 wo 벡터를 통해서 input 차원과 맞춰주는 과정을 거치게됩니다. 그후 residual connection과 LayerNorm 과정을 거치고 FeedForward Network에 들어가게 됩니다.
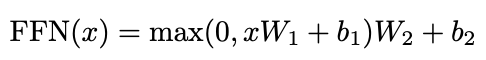
FeedForward Network에서는 각각의 z 벡터의 차원 즉 각각의 토큰에 대한 최종 정보를 비선형 변환하는 역할을 한다. 즉 더욱 고차원의 정보를 뽑아낸다고 이해했습니다. 이후 최종 Encoder의 최종 아웃풋이 나오게됩니다.
Decoder of Transformer
Decoder에서의 self-attention은 masked multi-head self-attention이라고 합니다. masked라는 표현은 transformer model이 training 과정에서 미래의 정보 즉 문장 내에서 다음 단어를 참조하는 것을 막기 위해 미래 단어와의 attention score를 의도적으로 -inf 값으로 보내는 과정을 의미합니다. 이러한 과정으로 model은 training 시 미래 단어에 대한 정보가 없는 특징 벡터 z를 output으로 내보내게 됩니다. 이러한 masked 작업이 필요한 이유는 inference시 model은 미래 단어를 보지 못하기 때문에 학습시에 미래 단어를 보면서 학습한다면 inference 성능이 낮게 나올 수 있기 때문이라고 이해했습니다.
그 후 Encoder의 최종 output의 key, value 벡터가 Decoder의 masked multi-head self-attention을 지나온 query 벡터와 attention을 수행합니다. 이 과정은 self-attention이 아니겠죠? 위에서 예시를 든 “나는 학생이다”, “I am a student”를 보면 Encoder(key, value)는 “나는 학생이다”의 key, value 값이 Decoder의 query는 “I am a student”의 query 값이 들어온다고 이해했습니다. 이제 주어진 key, query, value 벡터를 가지고 multi head attention을 수행 후 FFN을 지나고 Transformer model은 machine translation task를 수행하게 됩니다.
Evaluation
Transformer model은 450만개의 영어 – 독일어 문장쌍으로 학습을 진행했으며, 영어 – 프랑스어 같은 경우 3600만개의 문장쌍으로 학습을 진행했다고 합니다.
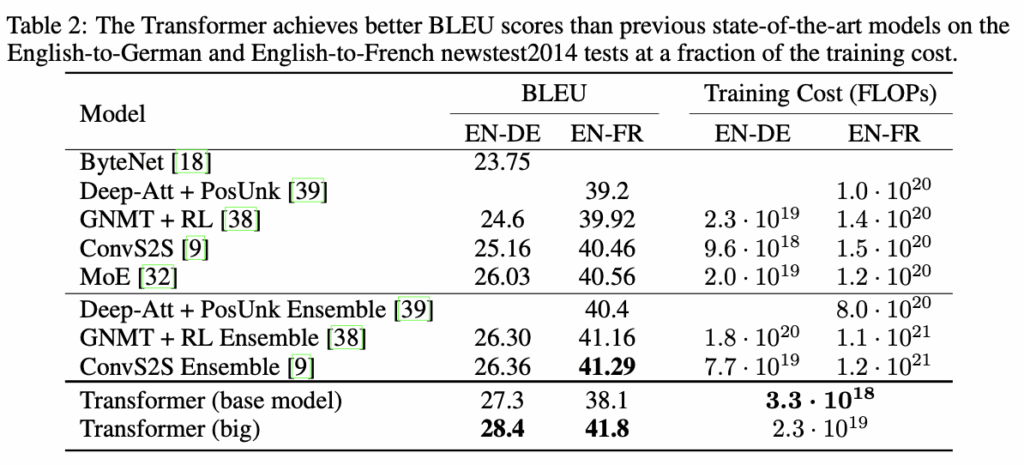
Table 2에서는 Transformer model이 기존의 machine translation model 보다 좋은 성능을 보이는 것을 보여준다. big model과 base model의 차이는 밑의 Table 3에 자세히 나와있으며, 학습 시간은 3.5일과 12시간이다.
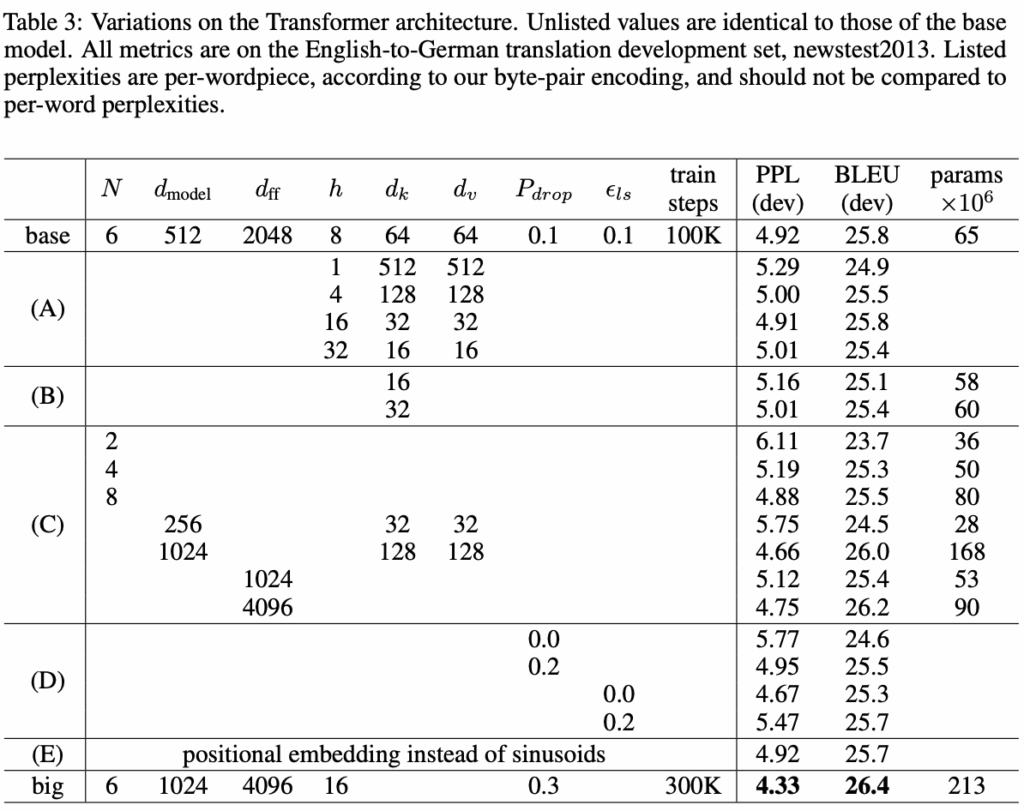
Table 3는 Transformer model의 하이퍼 파라미터를 바꿔가며 비교한 결과이다. 뭔가 보면서 BLEU가 전부 고만고만 하다가 Layer의 수 N이 2개로 줄어들면서 점수가 폭락한 것이 눈에 띄었다. 너무 얕은 layer는 정보를 잘 못 뽑는구나 생각헀다. 그리고 base model에서 FFN node수를 4096개로 늘렸을 때 거의 big model의 성능과 비슷해지는 것을 보고 FFN이 transformer에서 중요하구나 느꼈다. (비선형성의 추가)
이번 URP를 진행하면서 평소에 읽어보고 싶었던 Transformer를 읽을 수 있게 돼서 좋은 경험이었습니다. 읽어야지 읽어야지 했는데 지금이라도 읽은게 어디인가 싶습니다. 앞으로 논문에서 transformer 언급이 되면 기분이 좋을 것 같습니다. 긴 글 읽어주셔서 감사합니다!
안녕하세요 인하님, 좋은 리뷰 감사합니다.
쉽게 설명해주셔서 덕분에 공부가 많이 되었습니다.
positional encoding 부분에서 궁금한 점이 있는데요, 하필 sinusoid 형태의 함수를 사용하게 된 이유가 여러가지 있는 것으로 알고 있는데 그 부분을 이해해기 어렵더라고요. 논문에 어떻게 설명되어 있는지 조금 더 자세히 알려주실 수 있나요?
감사합니다.