안녕하세요. 이번에 소개할 논문은 Long-form Video Understanding 태스크 논문이며 긴 영상을 처리하는 방식을 인간이 비디오를 이해하는 흐름을 모사해 방법론을 제안합니다. 저자는 이를 위해 VideoAgent라는 에이전트 기반 시스템을 제안하는데, LLM을 중앙 에이전트로 두고 매 단계에서 “지금 정보로 충분한지”를 판단해 추가 프레임을 탐색하도록 설계합니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
Long-form video understanding는 말 그대로 몇 분에서 길게는 몇 시간짜리 영상을 대상으로 하기 때문에, 컴퓨터 비전에서 꽤 난이도가 높은 과제입니다. 이 문제는 단순히 “프레임에서 뭘 봤냐” 수준을 넘어, (1) 시각·언어 등 멀티모달 정보를 함께 다뤄야 하고, (2) 입력 시퀀스가 매우 길며, (3) 그 긴 맥락 위에서 추론까지 해야 합니다.
관련 연구들이 이 문제를 풀기 위해 여러 방향으로 시도해왔지만, 기존 모델들은 세 영역을 동시에 만족시키기는데 어려움을 겪고 있습니다. 요즘 LLM들은 긴 컨텍스트 처리와 추론 자체는 굉장히 강하지만, 시각 입력을 직접 다루는 능력은 부족합니다. 반대로 VLM은 시각 정보를 언어와 연결하는 건 잘하지만, 너무 긴 비디오 입력을 길게 모델링하는 데는 약한 모습을 보이고 있습니다. 그럼 VLM에 롱컨텍스트 능력을 추가하는 초기 시도도 있었지만, 실제 비디오 이해 벤치마크에서 기대만큼 성능이 나오지 않거나, 롱폼 비디오를 통째로 다루는 과정이 비효율적이라는 문제가 남습니다.
이 지점에서 저자들은 다음과 같은 질문을 제기합니다. “롱폼 비디오 전체를 모델 입력으로 그대로 제공하는 것이 과연 필요한가?” 저자들은 이게 인간이 영상을 이해하는 방식과도 다르다고 봅니다. 사람이 긴 영상을 이해할 때를 떠올려보면, 보통
- 먼저 영상 전체를 대충 훑어서 맥락을 잡고,
- 질문을 보고 “지금 답하려면 뭐가 더 필요하지?”를 생각한 다음,
- 필요한 정보가 있을 법한 장면을 반복적으로 더 찾아보고,
- 충분하다고 판단되면 그때 멈추고 답을 합니다.
즉 핵심은 “긴 영상을 한 번에 다 처리하는 능력”이라기보다, 질문에 맞춰 탐색을 조절하는 추론 능력이 더 중요하다는 관점입니다. 이 아이디어를 그대로 시스템으로 만든 게 VideoAgent입니다. 저자들은 비디오 이해 과정을 state–action–observation의 반복 과정으로 공식화하고, 이 과정을 통제하는 에이전트로 LLM을 둡니다(그림 1).
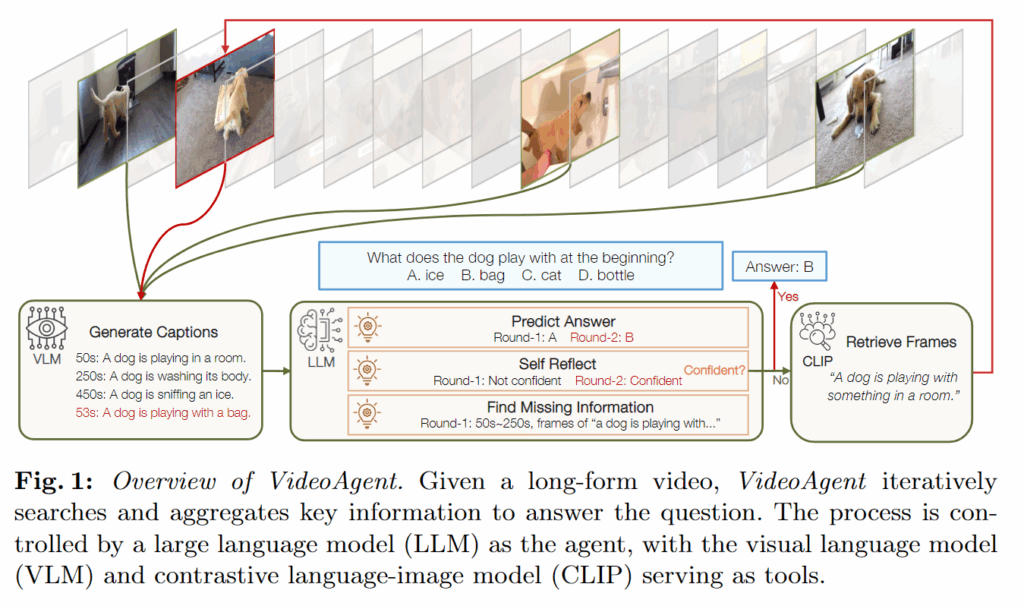
작동 흐름은 다음과 같습니다.
- 초기 단계: 비디오에서 균일 샘플링한 프레임 몇 장을 보고, LLM이 전체 맥락을 먼저 잡습니다.
- 반복 단계: 매 라운드마다 LLM이 “지금 정보(state)로 답이 가능한가?”를 판단합니다.
- 부족하다면, “무슨 정보가 더 필요하지?”를 action으로 결정하고,
- 그 정보를 찾기 위해 CLIP으로 프레임을 검색(retrieve)해서 새 프레임을 가져옵니다(observation).
- 가져온 프레임은 VLM이 캡션으로 텍스트화하고, 그 텍스트가 다시 상태를 업데이트합니다.
정리하면, VideoAgent는 VLM과 CLIP을 ‘도구(tool)’처럼 사용해서 LLM이 시각 정보를 간접적으로 이해하고, 동시에 긴 영상에서 필요한 부분만 반복적으로 찾아가며 답을 구성하도록 설계한 겁니다. 여기서 강조점은 “긴 비주얼 입력을 통째로 처리”가 아니라, 추론 기반의 반복 탐색 프로세스에 있습니다.
저자들은 기존 방식과의 차이를 두 가지로 명확히 잡습니다.
- 기존에는 프레임을 한 번에 균일 샘플링하거나 단일 iteration에서 한 번 뽑고 끝나는 경우가 많았는데, VideoAgent는 멀티 라운드로 프레임을 반복 선택합니다. 이러면 “지금까지 모은 정보”를 바탕으로 다음 탐색을 조정할 수 있어서, 필요한 정보가 더 정확하게 모인다는 주장입니다.
- 또 많은 방법들이 프레임 검색을 할 때 원래 질문을 그대로 쿼리로 쓰는데, VideoAgent는 쿼리를 재작성(rewrite)해서 더 세밀하고 정확한 프레임 검색이 가능하도록 합니다. 쉽게 말하면, 질문 문장을 그대로 던지는 것보다 “지금 내가 더 알고 싶은 포인트”를 쿼리로 다시 쓰는 게 검색 품질에 유리하다는 것입니다.
VideoAgent는 EgoSchema와 NExT-QA 두 벤치마크에서 각각 54.1%, 71.3% 정확도를 기록했고, SOTA인 LLoVi보다 각각 3.8%, 3.6% 높은 성능을 보이고 있습니다. 또한 VideoAgent는 효율성 측면에서도 장점을 가지는데, 이 성능을 내는 데 사용한 프레임 수가 평균 8.4장뿐이라서, LLoVi 대비 약 20배 적은 프레임으로도 성능을 낸다고 강조합니다. 그럼 각 구성 요소(상태 업데트 방식, 쿼리 재작성 전략, CLIP/VLM 연동 방식 등)는 뒤에서 방법론 파트에서 더 자세히 살펴 보겠습니다.
2. Method
먼저 Introduction에서 소개한 것 처럼 VideoAgent는 롱폼 비디오를 사람이 이해하는 방식에서 출발합니다.
- 먼저 몇 장면을 훑어서 맥락을 잡고,
- 질문에 따라 필요한 장면을 추가로 찾아보며,
- 충분한 단서가 모이면 그때 정보를 종합해 답을 내는 흐름으로 움직입니다. VideoAgent는 이 과정을 그대로 “반복적 탐색 + 누적 상태 업데이트” 문제로 바꿔서 구현한 프레임워크라고 보면 됩니다.
저자들은 이 과정을 상태(state), 행동(action), 관측(observation)의 시퀀스로 정식화합니다. 즉 전체 프로세스를 다음과 같이 정의합니다.
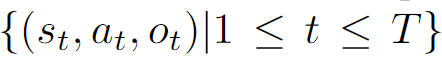
- st: 지금까지 본 프레임들에서 얻은 정보(누적 요약)
- at: 지금 답할지, 아니면 더 찾아볼지에 대한 결정
- ot: 이번 라운드에서 새로 가져온 추가 프레임(관측)
- T: 최대 반복 횟수 로 정의합니다.
그리고 이 의사결정 루프를 수행하는 에이전트로 GPT-4 기반 LLM을 둡니다.
2.1 Obtaining the Initial State
반복을 시작하려면 우선 “이 비디오가 대략 어떤 내용인지”에 대한 초기 맥락이 필요합니다. 그래서 VideoAgent는 비디오에서 N장의 프레임을 균일 샘플링해 VLM으로 이를 텍스트 캡션으로 바꿔 제공합니다.
구체적으로는 각 프레임에 “describe the image in detail” 같은 프롬프트로 캡션을 만들고, 그 캡션들의 묶음이 초기 상태 s1이 됩니다. s1은 비디오의 전반적인 내용을 잡기 위한 출발점으로 볼 수 있습니다.
2.2 Determining the Next Action
현재 상태 st가 주어졌을 때, 다음 행동 at는 사실 두 가지 선택지로 정리됩니다.
- Action 1: 지금 답한다. st에 있는 정보만으로 질문에 답할 수 있으면, 바로 답하고 루프를 종료합니다.
- Action 2: 더 찾는다. 정보가 부족하면, “무슨 정보가 더 필요한지”를 정하고 추가 프레임을 검색합니다.
문제는 이 선택을 모델이 어떻게 안정적으로 하냐는 건데, 저자들은 여기서 3-step 의사결정 루틴을 씁니다(그림 2).
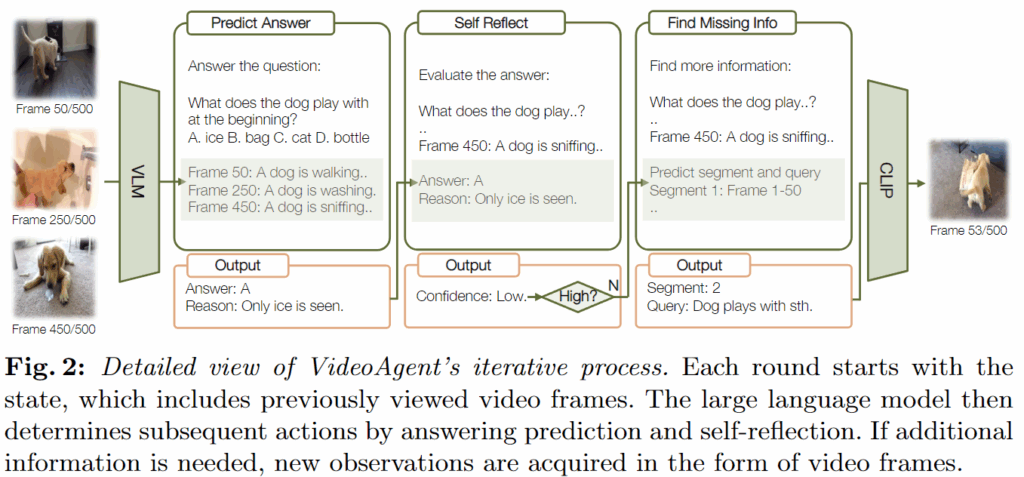
- 먼저 LLM에게 현재 상태와 질문만으로 일단 답을 만들어보게 합니다(CoT 기반).
- 그 다음 LLM이 자기 답변을 self-reflection 하도록 해서, “지금 정보가 충분한가?”를 신뢰도 점수로 내게 합니다. 점수는 1(부족), 2(부분), 3(충분) 세 단계입니다.
- 마지막으로 이 점수에 따라 Action 1 or 2를 선택합니다.
여기서 저자들이 굳이 단일 단계로 “다음 행동을 바로 선택”하지 않고 3-step을 쓰는 이유도 언급합니다. 직관적으로 단일 단계는 항상 더 찾는 쪽(Action 2)으로 쏠리는 경향이 있고, self-reflection을 넣어야 멈춰도 된다는 판단이 가능해진다고 주장하고 있습니다.
2.3 Gathering a New Observation
만약 LLM이 “정보가 부족하다”고 판단했다면, 그 다음은 “그럼 뭘 더 봐야 하지?”를 정해야 합니다. VideoAgent는 이때도 LLM에게 추가로 필요한 정보의 형태를 텍스트 쿼리로 명시하게 하고, 그 쿼리를 이용해 프레임을 검색합니다.
여기서 중요한 설계가 하나 더 들어갑니다. 저자들은 단순히 비디오 전체에서 프레임을 뽑는 게 아니라, segment-level retrieval을 합니다. 이유는 롱폼 비디오에서는 같은 단서가 여러 번 등장할 수 있고, 질문은 종종 특정 시점 이후/이전의 맥락을 요구하기 때문입니다.
예를 들어 질문이 “소년이 방을 나간 뒤 소파 위에 남아 있는 장난감이 뭐냐?”라면, 단순히 “소파 위 장난감”으로 검색하면 소년이 나가기 전에도 소파 위 장난감이 보일 수 있어서 오답으로 이어질 수 있습니다. 그래서 VideoAgent는 지금까지 본 프레임 인덱스들을 기준으로 비디오를 여러 구간으로 나누고, LLM이 “어느 구간(segment)에서 무엇을 찾을지”를 함께 예측하게 합니다. 예를 들어 LLM이 비디오의 i, j, k frames를 보았다면, 이 frames를 기준으로 비디오가 여러 segments로 나뉩니다. LLM은 “소파에 있는 장난감을 보여주는 frame을 찾아라”와 같은 query를 만들고, 이 query를 이용해 특정 segment (예: frame i부터 frame j까지의 segment 2)에서 정보를 검색하도록 지시할 수 있습니다
프레임 검색 도구로는 CLIP을 사용합니다. 각 (segment, query) 쌍에 대해 해당 구간에서 텍스트 쿼리와 코사인 유사도가 가장 높은 프레임을 반환하고, 이 프레임들이 이번 라운드 관측 ot가 됩니다.
2.4 Updating the Current State
새 관측(검색된 프레임)을 얻으면, 다시 VLM으로 프레임별 캡션을 만들고, 프레임 인덱스 순서대로 기존 캡션들과 정렬해서 concat합니다. 이렇게 업데이트된 캡션 집합이 다음 상태 st+1을 구성하고, 다시 다음 라운드 예측으로 넘어갑니다.
이처럼 상태를 단계적으로 확장하는 multi-round 설계를 택한 이유를 저자는 다음과 같이 설명하고 있습니다. 처음부터 프레임을 많이 넣어 한 번에 풀 경우 정보가 과해지고 노이즈가 늘어나 LLM이 긴 컨텍스트에서 쉽게 산만해지면서 오히려 성능이 떨어질 수 있고, 계산적으로도 비효율적이라 특히 1시간짜리 영상처럼 롱폼으로 갈수록 컨텍스트 길이 한계로 인해 확장성이 크게 제한됩니다. 반대로 프레임을 너무 적게 넣으면 질문에 필요한 핵심 단서를 놓칠 위험이 있습니다. 결국 VideoAgent의 포인트는 질문 난이도에 맞춰 필요한 만큼만 추가로 탐색하며, 최소 비용으로도 충분한 정보를 모으는 적응적 선택 전략에 있다는 것이 저자의 주장입니다.
3. Experiments
다음으로 실험 결과 살펴보겠습니다.
3.1 Datasets and Metrics
실험은 두 개의 대표적인 롱폼 비디오 QA 벤치마크를 사용하며, 특히 zero-shot 이해 능력에 초점을 둡니다. 두 데이터셋 모두 객관식(MC) 형태라서 평가지표는 accuracy로 통일합니다.
EgoSchema
EgoSchema는 롱폼 비디오 이해를 위한 벤치마크로, 5,000개의 egocentric 비디오(사람 1인칭 시점)에서 뽑은 5,000개의 객관식 질문으로 구성됩니다. 각 비디오가 3분 길이라는 점이 특징이고, 데이터셋은 test-only 형태입니다.
NExT-QA
NExT-QA는 일상 장면에서 객체 상호작용이 담긴 5,440개 비디오와 48,000개 객관식 질문으로 구성됩니다. 평균 비디오 길이는 44초이며, 질문은 Temporal / Causal / Descriptive 세 타입으로 나뉘어 다양한 수준의 비디오 이해를 평가합니다. zero-shot 평가에서는 validation set(570 videos, 5,000 questions)에서 진행하고, 추가로 ATP-hard subset도 함께 리포팅합니다. ATP-hard는 한 프레임만으로는 풀 수 없는 어려운 문제를 모아 장기 temporal reasoning을 더 강하게 요구하는 셋입니다.
3.2 Implementation Details
구현 측면에서 저자들은 전체 과정을 검색(CLIP retrieval) → 캡셔닝(VLM) → 추론(LLM)으로 고정한 파이프라인을 사용하고, 모든 비디오는 1 fps로 디코딩한 뒤 EVA-CLIP-8B-plus를 이용해 생성된 비주얼 설명과 프레임 특징 간 코사인 유사도 기반으로 관련 프레임을 검색합니다.
캡셔너는 데이터셋별로 달리 적용하는데, EgoSchema에서는 LaViLa를 사용하되 zero-shot 설정을 위해 ego4D로 재학습된 LaViLa를 활용하고 EgoSchema와 겹치는 비디오는 필터링하며, 캡셔닝에 사용할 비디오 클립은 CLIP retrieval이 반환한 프레임 인덱스를 기준으로 샘플링합니다.
반면 NExT-QA에서는 CogAgent를 캡셔너로 사용하고, 모든 실험에서 LLM은 gpt-4-1106-preview로 고정합니다.
3.3 Comparison with State-of-the-arts
EgoSchema

Table 1, 2에서 VideoAgent는 EgoSchema 전체 셋에서 54.1%, 500문항 subset에서 60.2% 정확도를 달성합니다. 이전 SOTA인 LLoVi 대비 +3.8% 높은 성능을 보이고 있고 Gemini-1.0 같은 proprietary 모델과도 비슷한 수준이라고 주장합니다. 여기서 저자들이 크게 강조하는 포인트는 프레임 효율인데, 평균 8.4 frames/video만 사용하며 기존 접근 대비 2배~30배 적은 프레임으로도 높은 성능을 달성할 수 있다고 합니다.
NExT-QA

Table 3에서 VideoAgent는 NExT-QA validation full set에서 71.3%를 달성하고, LLoVi 대비 +3.6% 높은 성능을 보여줍니다. 평균 사용 프레임은 8.2장으로 매우 적은데도, supervised/zero-shot 방식 포함 기존 방법들을 전반적으로 큰 폭으로 앞섭니다. 특히 ATP-hard 같은 더 어려운 subset에서 개선 폭이 커 복잡한 장기 추론 질문에서도 강하다는 것을 알 수 있습니다.
3.4 Analysis of Iterative Frame Selection
VideoAgent의 핵심 모듈은 반복적(iterative) 프레임 선택입니다. 저자들은 이 과정의 분석결과를 리포팅합니다.
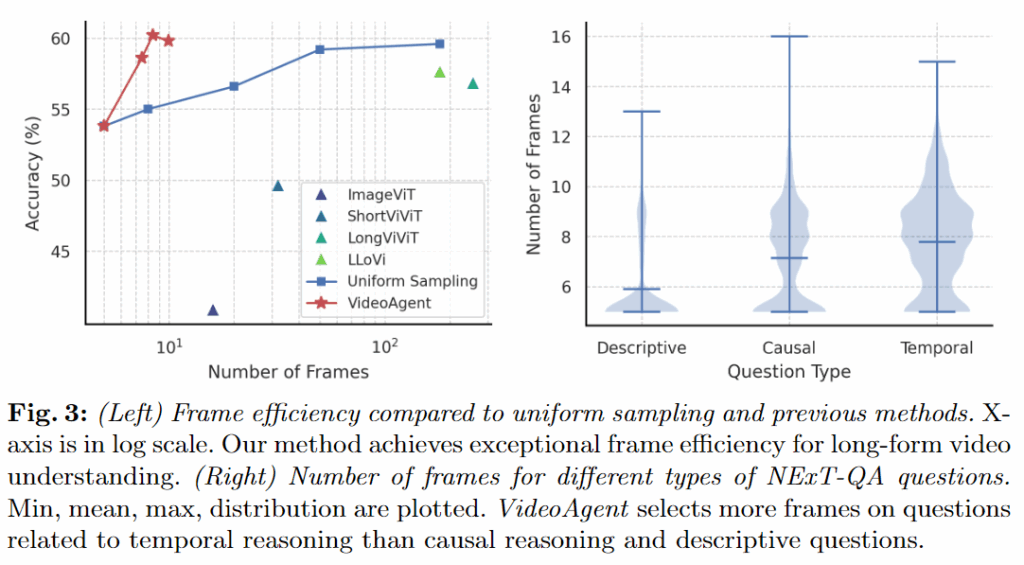
(1) Frame efficiency
고정된 프레임 수에서 정확도가 얼마나 잘 나오느냐로 평가합니다. Figure 3(왼쪽)에서 동일 프레임 수 기준으로 VideoAgent가 uniform sampling 및 다른 베이스라인을 크게 앞서며, 프레임 효율이 높다고 주장합니다.
(2) Number of rounds
또한 1~4 라운드 설정을 두고, 라운드 증가에 따른 성능 변화를 관찰합니다.
- 1 round: 53.8% (5 frames)
- 2 rounds: 58.6% (7.5 frames)
- 3 rounds: 60.2% (8.4 frames)
- 4 rounds: 59.8% (9.9 frames)
결과에 따르면 3라운드에서 포화되는 형태고, 그 이후는 정보가 더 늘어도 도움이 안 될 수 있음을 보여줍니다.
(3) Different question types
NExT-QA의 질문 타입별로 평균 사용 프레임 수 분포를 확인합니다(Figure 3 오른쪽). 평균은
- Descriptive: 5.9 frames
- Causal: 7.1 frames
- Temporal: 7.8 frames 으로 Descriptive은 몇 장만 봐도 되지만, Causal, Temporal은 더 많은 장면을 봐야 한다는 것을 알 수 있고 이와 같이 질문 유형에 따라 프레임을 동적으로 선택하는 것이 효율적이라는 것도 알 수 있습니다.
(4) Initial number of frames
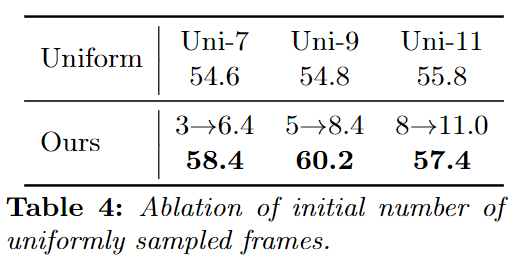
반복을 시작하기 전에 맥락을 잡기 위해 처음에 N장을 균일 샘플링하는데, N을 3/5/8로 바꾸어 실험한 결과를 리포팅합니다(Table 4).
결과적으로 초기 프레임은 5개를 사용하는 것이 최적이라는 것을 알 수 있습니다.
(5) Self-evaluation
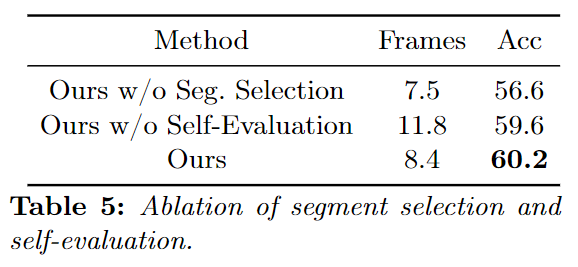
이 실험에서는 self-evaluation을 빼고 무조건 3라운드를 돌린 결과를 비교합니다. self-evaluation을 빼면 Table5에 나온 것과 같이 평균 프레임이 8.4 → 11.8로 늘고, 정확도는 60.2 → 59.6으로 떨어집니다. 즉, 프레임을 많이 본다고 해서 성능이 좋아지는게 아니고 정보의 적절성을 판단하고 결정하여 불필요한 반복을 줄여주는 것이 효율과 정확도에 있어 도움이 된다는 것을 알 수 있습니다.
4.5 Ablation of Foundation Models
저자는 프레임워크의 구성 요소인 LLM, VLM, CLIP에 대한 Ablation study도 진행합니다.

LLM ablation
Table 6에서 LLaMA-2-70B, Mixtral-8x7B, GPT-3.5, GPT-4 등을 비교하고 GPT-4가 가장 좋은 성능을 보입니다. 저자가 해석하기로는 “추론 능력”만이 아니라, 이 파이프라인이 반복 과정에서 JSON 형태의 구조화 출력을 요구하기 때문에 JSON을 안정적으로 출력하는 능력이 성능에 크게 작용했다고 주장하고 있습니다.
VLM ablation
Table 7에서는 VLM Ablation으로 BLIP-2, CogAgent, LaViLa를 비교합니다. CogAgent와 LaViLa는 캡션 길이가 꽤 달라도 성능은 비슷한 반면, BLIP-2는 성능이 확실히 낮은 모습을 보이고 있습니다.
CLIP ablation
Table 8에서는 Retrieval 모델로 OpenCLIP ViT-G, EVA-CLIP-8B, EVA-CLIP-8B-plus를 비교했을 때 성능이 대체로 비슷합니다. 이를 통해서 retrieval 단계가 성능을 제한하는 요소는 아니라는 것을 알 수 있습니다.
결론적으로 VideoAgent는 롱폼 비디오를 인간이 이해하는 과정을 모사하는 프레임워크를 제안했다는 데 있고, LLM, VLM, CLIP과 같은 파운데이션 모델이 빠르게 발전하고 있는 만큼, 더 좋은 모델을 통합함으로써 저자의 모델은 추가적인 성능 향상이 가능하며, GPT-4를 GPT-4V로 대체해 캡션 생성 없이 진행하는(caption-free) 방법론을 채택하는 방향으로도 확장될 수 있다고 하며 논문을 마무리하고 있습니다.
감사합니다.