
안녕하세요, 허재연 입니다. 오늘 리뷰할 논문은 ICRA 2023에 게재된 논문으로, 인접 프레임 간의 관계 변화를 포착하는 데 어려움을 겪는 기존 모델들의 한계를 극복하기 위해 Cross-Modality Knowledge Distillation과 Message Token을 도입한 논문입니다. 저는 지금 인접 프레임의 relation 변화를 잘 포착하기 위해 인접 프레임 간 motion 정보를 활용하는 식으로 실험을 수행하고 있는데, 해결방법은 다르지만 저의 문제 정의와 유사한 점이 많아 참고할만한 고찰이 있나 읽어보게 되었습니다. 아무래도 로봇 학회인 ICRA 논문인지라 Dynamic Scene Graph Generation 연구의 motivation을 Robot Planning쪽으로 연결시킨게 눈에 띄네요. 그럼 리뷰 시작하겠습니다.
Introduction
이전 리뷰들에서 설명했듯, Scene Graph Generation은 주어진 이미지에서 object detection을 수행하고 이렇게 검출한 object들 간 relation을 식별하여 <subject-predicate-object> triplet을 예측하는 task입니다. Video Scene Graph Generation(Dynamic Scene Graph Generation)은 이 작업을 비디오 프레임 단위로 수행합니다. 동적인 비디오의 각 프레임에서 Dynamic Scene Graph Generation(DSGG)가 잘 수행된다면 환경 인지, 자율주행, 로봇의 의사결정 과정 및 task planning과 같은 작업에서 시각적 이해도를 높이는데 활용될 수 있다고 기대하고 있습니다.
본 논문의 문제 정의는 기존의 DSGG 방법론들의 <subject-object> pair 간 relation이 이전 프레임과 달라졌을 때 이를 잘 인식하지 못한다는 것입니다. 어떻게 보면 당연하죠. relation이 바뀌는 지점을 프레임 단위로 맞추기는 쉽지 않을 것입니다. 이를 식별하려면 프레임 간 각 물체들의 미세한 움직임을 포착할 수 있어야 하는데 모델이 이러한 미세 변화까지는 잘 식별하지 못했죠.

위 Figure 1에서 STTran은 사람과 캐비넷 사이 접촉 관계 변화를 포착하지 못하고, 사람이 캐비닛과 접촉하지 않고 있다는 예측을 유지합니다. 이 뿐만 아니라, entity의 형태나 위치가 이전 프레임과 많이 변해도 실제 relation이 동일하게 유지되는 경우가 있습니다. 이런 상황에서는 모델이 relation 예측을 유지해야 하는지 그렇지 않은지 혼란을 겪을 수 있습니다.
논문의 저자는 기존 방법론들이 relation 변화 예측 과정에서 인접 프레임 간 relation feature의 차이 모델링을 충분히 고려하지 못하기 때문에 이런 현상이 일어난다고 주장합니다. 데이터에 내제된 relation 변화 정보를 충분히 활용하지 못하고 각 프레임의 relation 예측을 독립적으로 수행하고 있다는 것입니다.
이러한 문제를 해결하기 위해, 저자들은 relation label 차이에 대응하는 relation feature의 temporal difference를 모델링하는 것에 집중하여 Time-variant Relation-aware TRansformer({TR}^{2})를 제안합니다.
{TR}^{2}는 2가지 방법을 사용하였습니다.
첫 번째로 인접 프레임에서 relation feature 간 차이를 추출하고, 이를 대응하는 relation의 변화 정보로 사용합니다. 이 때 time-variant relation의 학습을 위해 cross-modality knowledge distillation을 사용합니다. 텍스트 relation label에 지정된 “a photo of a [subject] [predicating] an [object]”와 같은 프롬프트 문장의 텍스트 임베딩을 사용하여 관계 특징의 차이를 모델링하였습니다.
두 번째로는 TR2의 relation feature fusion module에서 트랜스포머 구조를 활용해 intra-frame 및 inter-frame 정보 융합을 수행합니다. 여기에 이전 프레임이 현재 프레임에 미치는 영향 정도를 반영하는 message token을 추가적으로 사용하여 relation 변화를 강조하였습니다.
위와 같은 방법으로 relation이 시간에 따라 변하는 정보를 명시적으로 모델링하여, 보다 정확하게 relation을 예측할 수 있게 하였습니다.
저자들이 주장하는 contribution을 정리하면 다음과 같습니다 :
- 우리는 최초로 DSGG에서 time-variant relation 예측을 위해 cross-modality guidance를 수행했다. 이 때 relation label에 대한 문장 프롬프트의 텍스트 임베딩 차이를 relation에 대한 supervision으로 사용하였다.
- 우리는 relation feature와 그 시간적 차이를 모델링하기 위해 message token을 포함한 relation feature fusion module을 설계하였다.
- 위 사항들을 반영해 {TR}^{2}(Time-variant Relation-aware Transformer)라는 새로운 프레임워크를 제안하였고, Action Genome 데이터셋에서 SOTA를 달성했다.
이어서 Method를 살펴보겠습니다.
Method
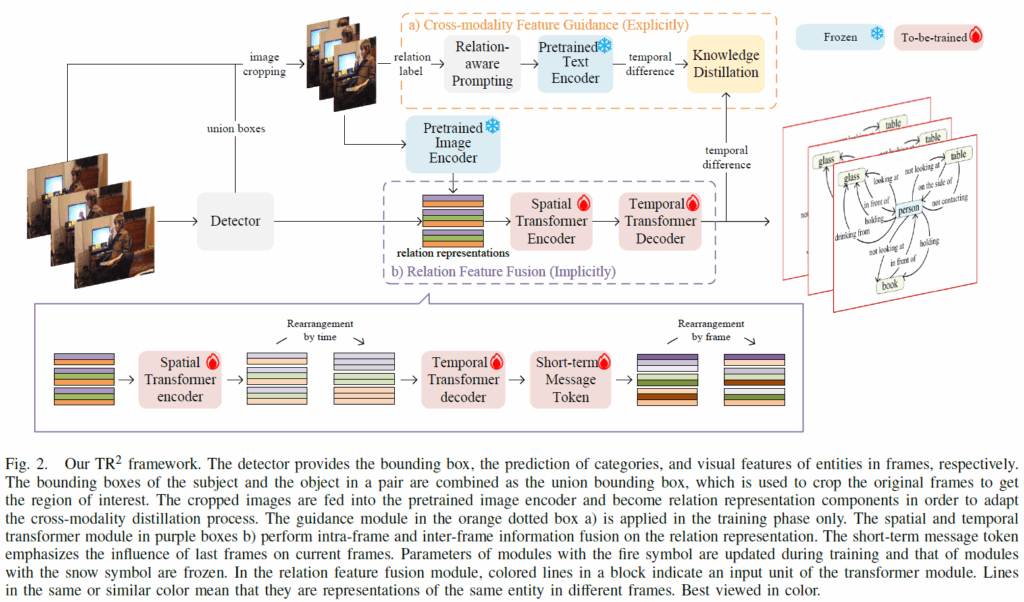
본 논문에서 제안하는 {TR}^{2} 모델의 전반적인 구조는 위 Figure 2와 같습니다. 먼저 큰 그림부터 살펴보겠습니다. 전반적으로는 Faster RCNN으로 각 프레임들의 object detection을 수행하고 이후 예측 결과들을 엮어 relation을 후처리하는 2단계 프레임워크인 STTrans를 기반으로 하는 것 같습니다.
우선, 가장 먼저 프레임들을 object detector에 입력합니다. 검출기 출력으로 프레임 내 entity 및 해당 entity들의 bounding box, 그리고 visual feature가 나옵니다. 출력으로 나온 visual feature는 프레임 내 relation representation(예측 triplet에서의 predicate 표현)을 구성하게 됩니다. 이후 과정에서 union box를 사용하는데, union box는 subject와 object box를 결합한 것입니다. 이후에, union box에 대응하는 triplet의 ROI를 유지하기 위해 입력 프레임을 union box로 crop하고 이렇게 자른 이미지를 VLM 인코더(CLIP)으로 인코딩합니다. 이렇게 크롭된 이미지의 프롬프트 기반 relation label은 이후 cross-modality feature guide에 사용합니다.
그 다음, 앞서 얻은 relation feature들을 relation feature fusion module에 입력하여 프레임 내 / 프레임 간 feature fusion을 수행합니다. feature fusion 이후 relation feature들로 최종 분류를 수행하여 predicate을 예측합니다. 학습 시에는 relation feature fusion 모듈의 출력 feature들이 cross-modality feature guide module로 학습됩니다.
Relation Feature Fusion
그림 2의 보라색 박스 b)는 시공간 트랜스포머(spatial-temporal transformer) 기반의 관계 특징 융합 모듈을 나타낸 것입니다. 여기서 공간적 / 시간적 fusion을 수행합니다. 관계 표현(relation representation)들에 대해 프레임 내 공간적 feature fusion을 먼저 수행하는데, 별다른 복잡한 과정 없이 트랜스포머 인코더를 사용해 Attention을 수행한다고 생각하시면 됩니다. 이어서 temporal 모듈로 입력해야 하는데, 그 전에 관계 표현을 entity 및 시간별로 재배열합니다. 이후 temporal decoder에서 각 entity 쌍의 relation feature sequence에 대한 long-term inter-frame fusion을 수행합니다.
공간 / 시간적 처리 이후, short-term message token을 사용해 시간에 따라 변하는 relation을 모델링합니다. 구체적으로는 다음의 수식 (1)과 같이 계산됩니다.
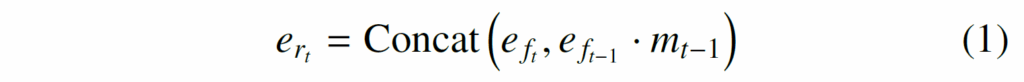
여기서 {e}_{f}는 temporal decoder의 출력을, t와 t-1는 현재, 이전 프레임을 나타냅니다. {m}_{t-1}은 이전 프레임이 현재 프레임에 얼마나 영향을 미치는지 평가하는 short-term message token입니다. 메시지 토큰은 다음과 같이 계산됩니다. g는 단순한 feed-forward network입니다.

마지막으로, relation representation들을 프레임별로 재배열 한 후 각 프레임에 대해 예측을 수행하게 됩니다.
Cross-Modality Feature Guidance
앞에서 언급한 것처럼, 인접 프레임 간 relation feature의 정보를 모델링하기 위해 cross-modality feature guidance를 수행합니다. relation이 변하는 상황에 좀 더 명확히 학습 signal을 주기 위함이죠. cross-modality feature guidance 모듈의 과정은 아래 Figure 3과 같습니다.
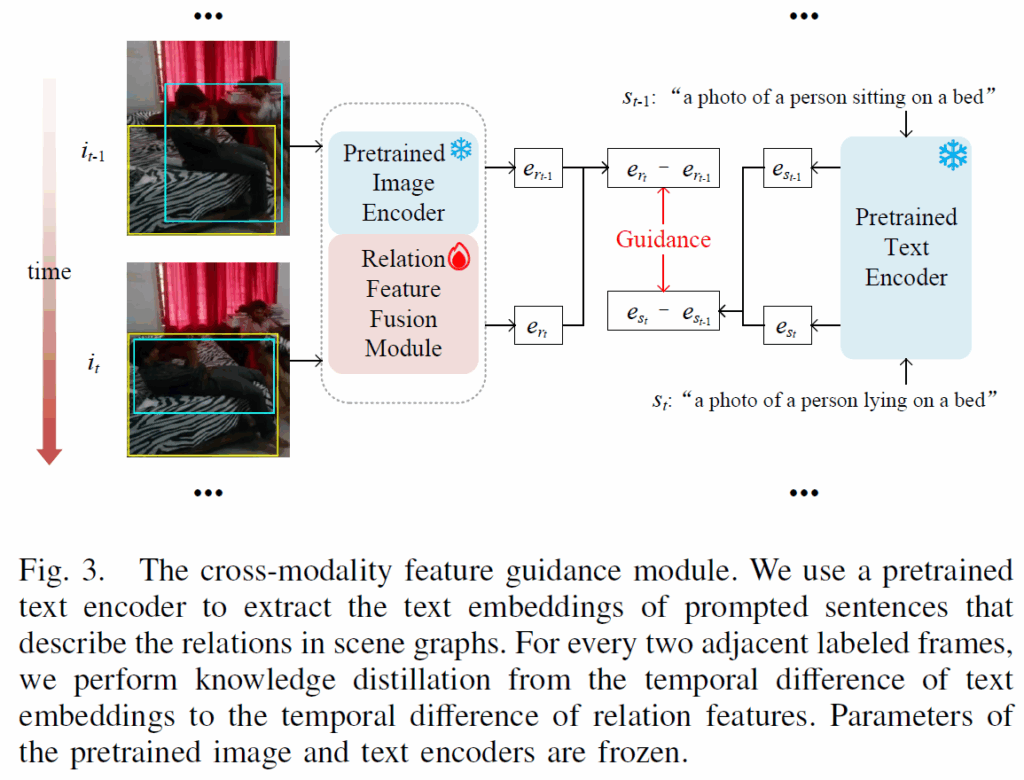
relation feature fusion 모듈 이후, 프레임 {i}_{t-1}과 {i}_{t}에 대한 사람과 침대 사이 relation representation {e}_{r_t-1}과 {e}_{r_t}를 얻고, relation 이 변하는 상황에서 label로 만든 텍스트 프롬프트로 텍스트 임베딩을 추출합니다. (GT 장면 그래프 내 주어, 목적어, 관계 단어들을 추출하여 “a photo of a [subject] [predicating] an [object]” 형식으로 문장을 구성). 이후 CLIP 텍스트 인코더를 사용해 구한 텍스트 feature {e}_{s_t-1}, {e}_{s_t}의 temporal difference를 학습 신호로 사용해 relation feature {e}_{r_t-1}, {e}_{r_t}간 temporal difference를 학습합니다. 일종의 knowledge distillation이죠.
Training
학습에 사용하는 objective funcsion은 1 entity classification loss, 2.relation classification loss, 3.knowledge distillation loss 3개의 항으로 구성됩니다. entity classification loss({L}_{obj})는 entity를 분류하는 cross-entropy이고, relation classification loss({L}_{rel})은 각 relation을 분류하는 cross-entropy입니다. 이 때 relation이 Attention, Spatial, Contact 3가지 카테고리가 있기 때문에 각각에 대해 분류를 수행하고 focal loss형태로 취합하게 됩니다. 마지막으로 knowledge distillation을 수행하는 {L}_{guidance} 손실함수는 학습 단계에서 cross-modality feature guide를 위해 다음과 같이 MSE를 사용합니다.
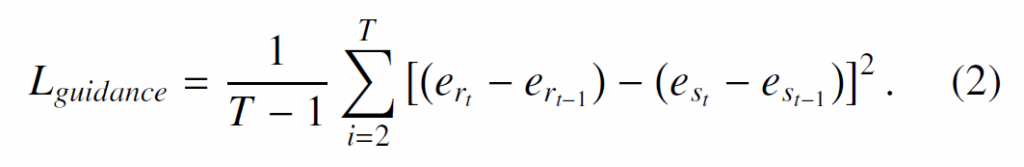
이에 따라 최종 total loss는 다음과 같습니다 :
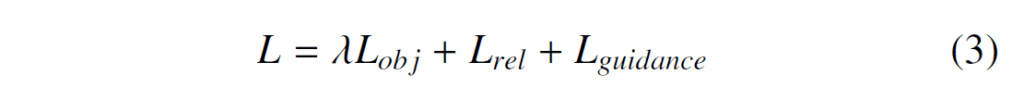
Experiment
DSGG task에서 항상 그렇듯 평가에 Action Genome dataset을 사용하였습니다. 모델의 detector는 ResNet-101기반 Faster-RCNN을 사용하였고, 관계 특징 융합 모듈에서 공간 모듈은 1개 층의 인코더, 시간 모듈은 8개의 헤드를 가진 3개 층의 디코더를 사용하였다고 합니다.
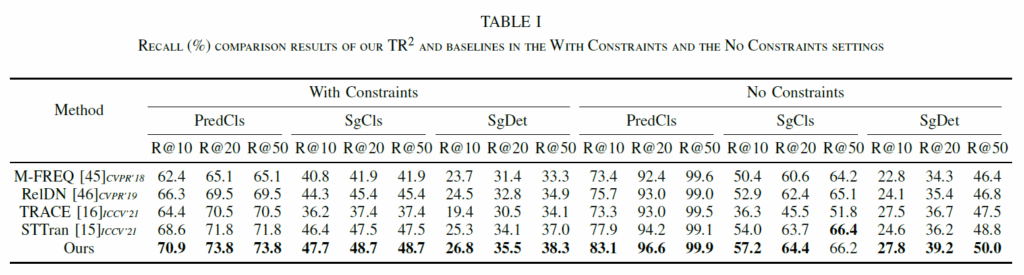
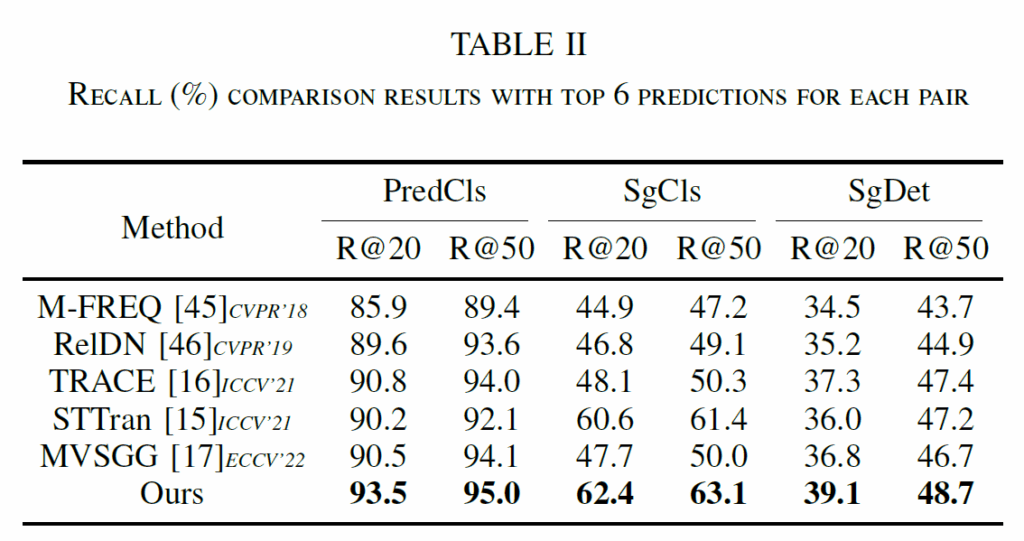
Table 1,2를 살펴보면, 제안하는 모델이 기존 몯멜들 대비 SOTA 성능을 보임을 확인할 수 있습니다. 한가지 아쉬운것은 좀 성능이 안좋은 21, 22년 모델들을 함께 비교했네요. 2022-2023년이라고 좀 더 성능이 개선된 모델들이 많이 제안됐었는데, 그런 모델들이 벤치마크에 빠져있는게 많이 아쉽습니다.
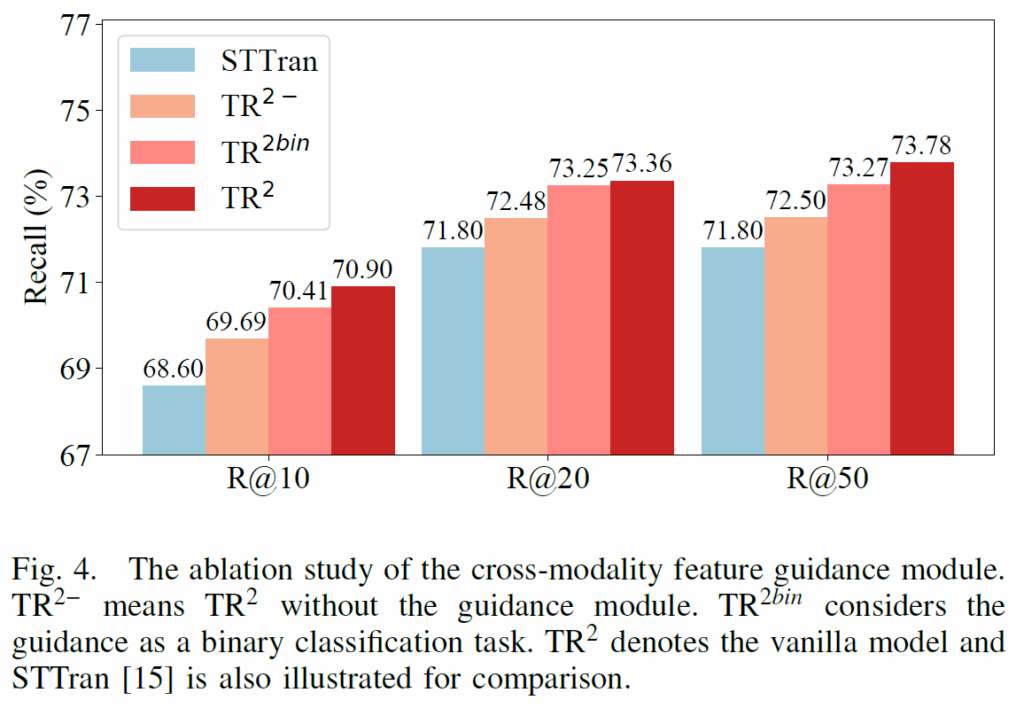

Figure 4,5,6에는 Ablation Study를 나타내었습니다. Figure 4에서 TR2-는 가이드가 없는 것이고, TR2bin은 binary classification으로 guidance를 학습시킨 것이라고 합니다. STTran을 베이스로 둔 것을 보아, STTrans가 베이스라인 모델인 듯 하네요. 비교 결과, finetuning된 프롬프트 텍스트 임베딩을 사용하는 TR2가 가장 성능이 좋았습니다. label text 자체를 활용한 것이 성능 향상에 도움을 줄 수 있음을 실험으로 보였습니다.
Table 3의 ablation에서는 feature 간의 직접적으로 증류를 수행한 {L'}_{guidance}보다 temporal difference에 대한 가이드가 더 유익함을 보였습니다. 이 때 {L'}_{guidance}은 다음과 같이 수성됩니다.
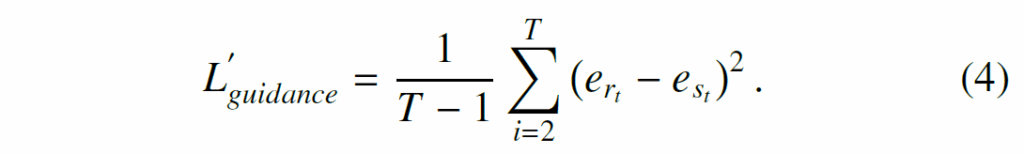
Table 4에서는 ablation을 통해 최적의 성능을 달성하는 데 있어 공간 모듈, 시간 모듈(디코더), 메시지 토큰이 모두 중요함을 보여주었습니다. 특히 장기 정보를 포착하는 디코더와 단기 정보를 강조하는 메시지 토큰을 동시에 사용할 때 성능이 가장 좋았다고 합니다.
인접 프레임의 relation 변화에 집중한 논문을 살펴보았습니다. CLIP 을 이용해서 GT predicate를 직접 학습 신호로 사용했다는 점이 인상 깊네요. 아이디어를 참고할 수 있을 것 같습니다.
이만 리뷰 마무리하도록 하겠습니다. 감사합니다.
리뷰 잘 읽었습니다.
TR²는 기본적으로 t-1과 t 사이의 relation feature difference에 집중하는 것 같습니다. 여기서 궁금한 점이 생기는데, relation 변화가 항상 인접 프레임에서 가장 잘 드러나는건가요? 예를 들어, 여러 프레임에 걸쳐 서서히 변하는 관계(다가가다 → 접촉)는 단순히 (t-1, t) 차이만으로 충분할지 궁금합니다.
그리고 장기적인 relation 변화를 포착하는 역할은 temporal decoder 쪽이 주로 담당한다고 보면 될까요?
장기적인 관계 파악이 중요할 것 같아 이런 질문 드립니다
안녕하세요 재연님 리뷰 잘 읽었습니다.
뭔가 이번 URP 세미나를 준비하면서 다시 알게된? 내용을 좀 적용해볼 수 있지 않나 해서 질문드립니다.
relation feature 는 spatial 이나 이미지쪽에서 뭐 정보를 얻는거지만, message token 은 전체 맥락을 전부 보는 learnable한 토큰으로 이해를 했씁니다. 사용하는 데이터셋의 길이나 장면전환의 정도에 따라 방법을 더 생각해볼 수 있겠지만 message token 을 첫번째 frame 을 anchor 로 선언해서 EMA 같이 지수이동평균을 사용해서 해당 프레임으로부터 얼마나 변했는지를 모델링하는 것이 어떤지 싶습니다. 장면이 전환되면 의미가 달라질 수 있으니 전체 프레임을 uniform 하게 sampling 해서 각 부분을 anchor 로서 사용하고, 각 부분에서 변화정도를 측정하는게 전체 프레임을 보는 것보다 최근 프레임의 변화에 더 민감하게 체크할 수 있는 방법이 아닐까 싶어 질문드립니다.
감사합니다.