제가 이번에 리뷰할 논문은 속성을 활용하여 물체를 인지하는 Attribute detection이라는 연구입니다. 제가 담당하고 있는 파지 과제에서 속성정보를 활용하여 유의미한 물체를 인식하는 연구를 진행하고있는데, 서베이를 하다 찾게 된 논문입니다.
Abstract
attribute detection은 색상과 텍스쳐, 재질 정보 등을 활용하여 물체를 인지하는 연구로, 최근 연구들은 노동력집약적인 어노테이션 과정에 의존합니다. 그러나 이러한 방식은 물체의 세부 수준에서 표현되므로, 어노테이터가 충분한 가이드를 받지 못할 경우 모호성이 발생하며, 미리 정의된 속성 집합에 한정되어 확장성이 제한된다는 근본적인 한계가 존재합니다. 해당 논문은 이러한 한계를 극복하기 위해 Compositional Caching(COMCA)를 제안합니다. COMCA는 training-free 기반의 open-vocabulary방식으로, 입력으로 target속성과 객체 리스트만을 요구하며, 웹규모 데이터베이스와 LLM을 활용하여 속성과 객체 간의 호환성을 판단하여 보조 캐시를 구성합니다. 속성의 조합을 고려하여 개시 이미지에는 soft-label을 부여하고, 이를 추론시에 입력 이미지와 캐시 이미지 사이의 유사도를 활용하여 계산되며, 이를 통해 VLM의 예측을 refine합니다. 해당 논문에서 제안하는 방식은 모델에 독립적으로 동작하며, 다양한 VLM모델과 호환이 가능하며, 공개 데이터 셋에서 실험한 결과 COMCA는 zero-shot 및 캐시 기반의 베이스라인에 비해 성능이 크게 개선되었으며, 학습 기반의 방식들과 비교했을 때도 경쟁력 있는 성능을 달성하였습니다.
Introduction
속성은 환경을 인식하는 방식에 중요한 역할을 합니다. 만일 동물은 식별하는 것을 목표로 한다면, 털의 색상, 크기, 뿔의 존재 유무 등의 특성에 집중하고, 건강상태를 인식하는 것을 목표로 한다면 크기, 피부 상태, 털의 패턴 등의 속성에 집중하게 됩니다. 이러한 분석을 위해 시각적 입력에 대해 이해하고있는 모델이 필요하며, 이러한 모델은 보통 객체와 그에 대응되는 속성 정보가 함께 어노테이션 된 데이터셋을 통해 학습됩니다.

그러나, 속성을 어노테이션하는 것은 시간이 많이 소요되며, 어노테이션시 충분한 가이드가 없다면 모호성이 발생하기 쉽다는 문제가 있습니다. Figure 1의 왼쪽 염소에 대해 어떤 사람은 붉은 털이라 할 수 있고, 어떤 사람은 갈색털이라 할 수 있는 것 입니다. 이런식으로 사람에 따라 표현이 달라질 수 있으며, 모호성을 해결하는 가장 단순한 방식은 사전에 속성 리스트를 정해두는 것 입니다. 그러나 이러한 방식은 모호성을 해결할 수 있으나, 하나의 속성에 대한 모든 가능한 목록을 포함할 수 없으며, 한정된 리스트에 대하여 학습된 모델은 새로운 속성을 고려하지 못하게 된다는 한계가 존재합니다.
최근 연구들은 추론시 자연어로 특성을 추출하는 방식으로 open-vocabulary 모델을 제안하여 이를 해결하고자 하였으나, 이러한 방식은 unseen 속성과 객체로 일반화는 가능하지만 여전히 학습에 사용된 데이터 셋에 편향되는 경향이 있고, 실제로 학습 기반의 방식들은 cross-dataset 세팅에서 성능 저하가 이루어지는 경우가 많습니다. (뒤의 실험파트에서 Figure 4참고)
저자들은 이러한 모호성을 해결하고, 속성에 대한 어노테이션의 한계를 극복하기 위해 학습 과정 없이 open-vocabulary 기반의 attribute detection 방식인 Compositional Caching(COMCA)를 제안합니다. COMCA는 VLM을 활용하며, 자동으로 할당된 속성 라벨과 함께 이미지들을 포함하는 보조 캐시로 이용하여 예측값을 refine하는 방식입니다. CLIP 예측을 보정하기 위한 캐싱 기법은 이미지 classification 분야에서 연구되었으며, 입력 이미지와 캐시된 라벨의 유사도를 가중치로 이용하여 캐시에 저장된 라벨을 가중합하여 모델의 예측을 보정하는 방식으로 이루어집니다. 이러한 방식은 classification에서는 효과적이지만, 가능한 모든 물체와 속성을 고려해야하는 attribute detection에서는 속성과 객체의 모든 조합을 고려해야하므로 비용이 너무 많이 든다는 문제가 있습니다.
COMCA는 다음 2가지 원리에 따라 캐시의 scalability를 확보하고자 하였습니다.: (1) 모든 속성이 모든 물체에 보편적으로 적용되지 않음 (2) 모든 물체에는 여러 속성을 동시에 가짐. 먼저, 첫번째 원리는 속성과 객체 사이의 호환성을 추정한 뒤, 캐시 쌍을 샘플링하는 2-step으로 구현됩니다. 공개 데이터베이스의 통계적 정보와 LLM의 질의를 통해 특정 속성이 특정 객체와 함께 등장할 확률을 추정한 뒤, 추정된 분포로부터 호환 가능한 객체들을 샘플링하고 데이터베이스에서 관련 이미지를 검색함으로써 주어진 속성에 대한 캐시를 구성합니다. 두번째 원리는 캐시 요소에 self-labeling을 통해 구현됩니다. 초기에는 각 샘플이 샘플링된 단일 속성에 대해서만 연관되어있어, 이미지 내의 다른 속성은 고려하지 못합니다. 이를 해결하기 위해, 관심 속성들의 텍스트 임베딩과 캐시 이미지 간의 유사도를 계산하여 소프트 속성 라벨을 부여하고, 이를 통해 이미지에 내재된 속성의 조합적 특성을 반영함으로써 각 캐시 요소의 속성별 기여도를 조절합니다.
저자들은 COMCA를 2개의 공개 벤치마크인 OVAD와 VAW에서 평가하였으며, 실험결과 training-free 베이스라인 대비 유의미한 성능 향상을 확인하였으며, 특정 학습 데이터셋에 편향되지 않으면서도 최신 학습 기반의 방법론들과 경쟁력 있는 성능을 달성하였다고 합니다. 특히, VLM의 사전학습 데이터나 구조에 의존하지 않고도 일관된 성능 향상이 이루어졌다는 점을 강조합니다.
해당 논문의 contribution을 정리하면,
- training-free 방식의 open-vocabulary 기반 attribute detection을 위한 COMCA를 제안하였으며, 이는 객체의 속성의 조합적인 특성을 활용하여 보조 캐시를 구축하고 이를 anchor로 사용하여 모델의 예측을 개선함
- 데이터베이스와 LLM으로부터 객체-속성 간 연관성에 대한 사전 지식을 추출하여 확장성을 확보하고, 캐시 구성에 활용함. 또한, soft-labeling을 통해 하나의 이미지에 다수의 속성이 존재할 수 있도록 함
- 실험적으로 모든 캐시 기반의 베이스라인 성능을 능가하며, 비용이 많이 드는 학습 기반의 방법론과 비교했을 때 경쟁력 있는 성능을 달성함. 이를 통해 training-free 방식의 open-vocabulary attribute detection의 실질적 가능성을 확인
Compositional Caching
1. Background
Problem Formulation
객체가 포함된 이미지 x \in \mathcal{X}와 속성 리스트가 주어졌을 때, 해당 이미지의 어떤 속성들이 존재하는지를 검출하는 것이 목표입니다. 자연어로 표현 가능한 속성 집합을 \mathcal{A}라 했을 때, 추론시 모델은 \mathcal{A}의 부분집합인 n개의 target 속성 A=\{a_1, ...,a_n\}를 입력으로 받고, 이러한 속성들은 m개의 target object들 O=\{o_1, ...,o_m\}과 연관됩니다. 이미지와 속성 리스트 입력으로부터 각 속성의 존재 여부를 나타내는 이진벡터를 출력하는 함수 f: \mathcal{X} ⨉A^n →[-1,1]^n를 구축하는 것을 목표로 합니다. 기존 연구들은 이미지-라벨 쌍으로 이루어진 데이터셋 D=\{(x,\mathbf{a})\}을 통해 f를 학습한 것과 다르게, 저자들은 training-free 방식으로 구하기 위해 VLM과 예측값 정제를 위한 보조 캐시를 도입하였습니다.
Adapting VLMs with caching
기존 연구들과 동일하게 VLM을 사용하여 f를 구성하였으며, 기본적으로 CLIP을 사용하였으나, SigLIP이나 BLIP등 다른 VLM과도 호환이 가능하며, visual encoder f_v와 text encoder f_t, 예측 모듈 3가지로 이루어집니다. f_v와 f_t는 이미지와 자연어를 d차원의 멀티모달 공간 \mathcal{Z} \in \mathbb{R}^{d}로 매핑시킨 뒤, 멀티모달 임베딩 사이의 코사인 유사도를 계산하여 클래스에 대한 점수를 구합니다. 해당 연구에서는 f의 관심 클래스 예제를 저장하는 보조 캐시를 이용하여 추가 학습 없이 개선이 가능하며, 클래스 집합 C에 대하여 K개의 샘플을 포함하는 캐시 \mathcal{C} = \{x^1_1, .... ,x^K_C\}가 주어졌을 때, 클래스 c \in C에 대한 예측은 아래의 식으로 정의됩니다. 이때 η_C(z) = exp(1-\Beta(-z))로 하이퍼파라미터인 \Beta에 의해 조절되는 정규화 함수로, 여기서는 1.0으로 설정하였다고합니다.

그러나 이러한 방식은 open-vocabulary 기반의 attribute detection에 적용할 경우, 가능한 모든 속성 라벨을 고려한다면 K \cdot n!의 이미지를 저장해야하므로 저장 공간이 비현실적으로 요구되며(OVAD 데이터로 적용할 경우 K \cdot 117!이 된다고 합니다..), 속성 당 K개의 positive sample만을 저장한다면 메모리 요구량은 낮아지지만 이미지가 가지는 다중 속성의 특징을 고려하지 못하게 됩니다. 또한, 속성은 객체에 따라 다양한 방식으로 표현될 수 있으며, 이를 랜덤하게 선택하게된다면 소수의 경우만을 대표하는 캐시가 될 수 있다는 문제가 있습니다. 따라서 저자들은 객체와 다중 속성 사이의 호환성(compatibility)에 초점을 맞추어 이를 해결하고자 하였습니다.
2. Compatibility for scalable caching
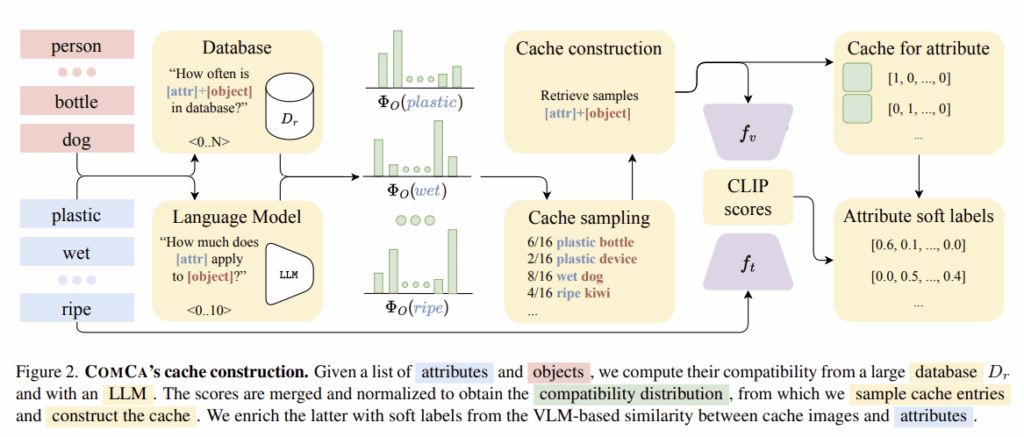
해당 섹션에서는 각 속성당 K개의 샘플을 저장하는 것과 동일한 메모리 요구량을 유지하면서, 속성-객체 호환성을 고려하여 각 예제에 여러 속성 라벨을 할당하는 방법을 제안합니다.
먼저, 속성 수가 증가하더라도 확장 가능하고, 객체 별 정보를 반영하는 캐시 \mathcal{C}를 구성하기 위해, 객체 전반에 대한 속성의 자연분포를 활용합니다. 속성 a \in \mathcal{A}와 객체 o \in \mathcal{O}가 주어졌을 때, 이들의 호환성에 대한 스칼라 값을 반환하는 함수 \varphi를 정의합니다. \varphi(a,o)는 객체 o가 속성 a를 가질 확률에 비례한다고 가정하고, \Phi_\mathcal{O}(a) = [\varphi(a,o_1), ..., \varphi(a,o_m)]를 속성 a가 각 객체들과 함께 등장할 확률 분포의 근사치로 사용합니다. 이후 속성 a에 대해 K개의 샘플을 할당하며, 이때 객체는 \Phi_\mathcal{O}(a)에서 샘플링합니다.
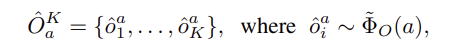
- \tilde{\Phi}_\mathcal{O}(a) = \Phi_\mathcal{O}(a) / \Sigma \Phi_\mathcal{O}(a) 로, \Phi_\mathcal{O}(a)를 정규화한 버전
즉, 속성 a와 잘 어울리는 샘플링된 객체 집합 \hat{\mathcal{O}}^K_a를 정한 뒤, 이 객체들과 속성을 조합한 text 쿼리를 이용하여 이미지를 검색함으로써 캐시를 구성합니다. (해당 논문은 SuS-X를 따라서 T2I(text-to-image) retrieval 방식으로 구현하였으나, Stable diffusion과 같은 생성 모델을 이용할 수 있다고합니다.)
Estimating attribute-object compatibility
속성-객체 조합이 적절한지 판단하는 데 사용되는 함수 \varphi를 구현하기 위해 2가지 전략을 이용합니다. (\varphi_{db}와 \varphi_{LLM})
먼저, 이미지와 캡션 쌍을 포함하는 대규모 데이터 셋 D_r 을 이용하는 방식은, 캡션 t를 사용하여 속성 a와 객체 o의 동시 등장 횟수를 데이터베이스 점수로 계산하는 방식으로 아래의 식으로 정의되며, 여기서 \mathbf{1}(z)는 조건 z가 참이면 1, 아니면 0을 반환하는 함수입니다.

그러나 이러한 방식은 캡션 작성 방식이나 데이터 수집 과정의 편향에 영향을 받을 수 있으므로, 저자들은 LLM의 추론 능력을 활용하는 방식도 함께 반영합니다.

- \pi_c는 호환성을 판단하도록 하는 프롬프트로, 속성-객체 쌍에 대한 가능성을 0~10 사이의 점수로 출력하도록 하며, GPT-3.5 Turbo를 이용하였습니다.
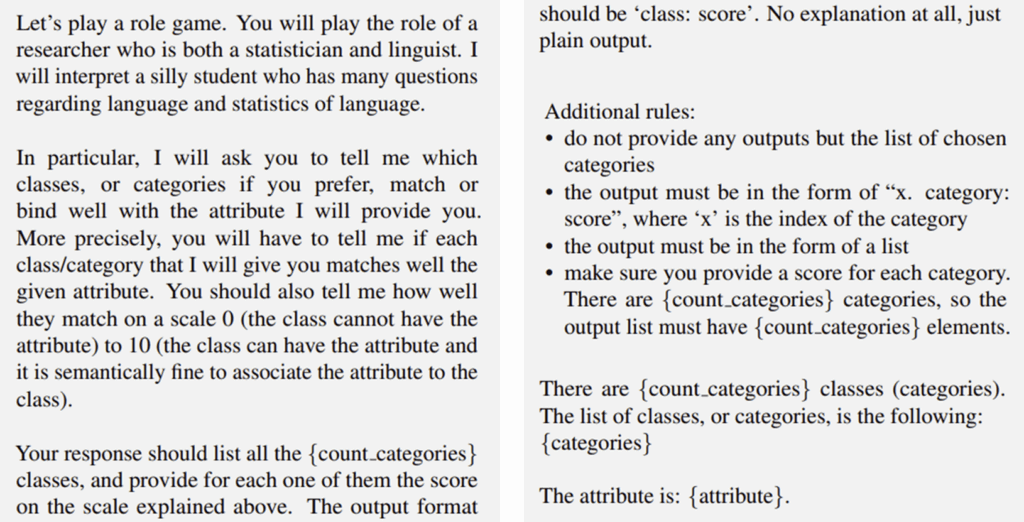
이러한 LLM을 활용하는 방식도 편향 문제가 발생할 수 있으므로, 해당 연구에서는 최종적으로 데이터베이스 기반의 점수와 LLM 기반의 점수를 곱셈으로 결합한 \varphi(a,o) = \varphi_{db}(a,o) \cdot \varphi_{LLM}(a,o)를 사용합니다.
3. Compositional cache refinement
앞선 과정을 통해 각 속성 a에 대해 K개의 샘플로 채워진 캐시 \mathcal{C}_H를 얻게되고, 초기에는 단일 속성에 대한 라벨만을 할당고있으나 실제로는 다중 속성이 공존할 수 있으므로, 이를 그대로 활용하며 잘못된 추론으로 이어질 수 있습니다. 예를 들어 설명을하자면, large blue car가 있을 때, (large, car) 조합으로 이루어진 이미지에 대해서 large에 대한 라벨만 positive로 이용한다면 이후 small blue car 이미지가 주어지면 해당 캐시는 blue 점수에는 기여하지 못하고, large에 대한 반의어로써 negative 역할만을 하게 될 수 있다는 것 입니다.
이러한 문제를 해결하기 위해, 저자들은 캐시 요소에 할당된 라벨을 정제하고자 VLM의 능력을 활용하여 soft label을 할당합니다. soft label s_a(x_c)는 아래의 식으로 정의되며, 속성에 대한 text 임베딩과 캐시 이미지의 visual 임베딩을 비교한 결과입니다.
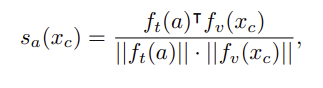
CLIP의 코사인 유사도를 활용해본 연구원분들은 아시겠지만, 이를 그대로 사용하기에는 분산이 낮은 경향이 있습니다. 따라서, 아래와 같이 정규화를 거쳐 정규화된 soft-label을 사용합니다. 여기서 µ_C와 \sigma_C는 임의의 속성과 캐시 요소 간 유사도의 평균과 표준편차를 의미합니다.

최종적으로 soft-label은 초기 label과 결합되어 soft-label을 이루고, 이는 아래의 식으로 정의됩니다. 여기서 \alpha는 하이퍼파라미터로, 0.6으로 설정하였다고합니다.
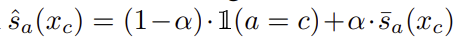
최종적인 soft-label \hat{s}_a를 활용하여 캐시 기반의 예측은 아래의 식으로 계산되며, 이는 기존의 CLIP 기반의 클래스 예측과는 다르게 a \neq c인 경우에도 각 캐시 요소 x_c를 속성 a에도 고려할 수 있도록 하여 캐시의 각 요소가 다중 속성 라벨을 가질 수 있도록 허용합니다.
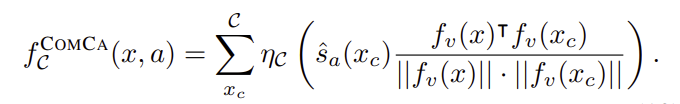
Final inference
이렇게 계산된 캐시 기반의 점수는 기존의 CLIP 기반의 클래스 예측과 결합되어 최종 예측 결과를 얻게 되며, λ=1.17로 설정하였다고 합니다.
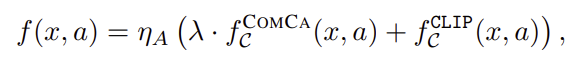
Experiments
평가에 사용된 데이터 셋은 2,000장의 MS-COCO 이미지에 대하여 80개의 클래스와 117개의 속성으로 구성된 OVAD와 10,392장 이미지에 대해 2,260개 클래스와 620개 속성으로 이루어진 VAW이며, 기존 연구를 따라 box가 주어진 설정과 객체 검출기로 물체를 찾은 box-free 설정 두가지에서 평가를 수행하였습니다. 평가지표는 mAP로, 데이터 셋 내 빈도에 따라 클래스를 head/medium/tail로 나누어 각 구간의 mAP도 함께 리포팅합니다. 구현에는 CLIP ViT-B/32를 기본 VLM으로 사용하며, 속성당 K=16를 기본으로 설정하고 box-free 세팅의 객체 검출기는 YOLOv11M를 이용하였다고 합니다.
Results
Comparison with SOTA

먼저, SOTA 방법론들과 비교를 수행합니다. 비교에는 zero-shot 방식, 캐시 기반의 방식, 학습 기반의 방식을 함께 리포팅하였으며, Table 1를 통해 두 벤치마크에서 COMCA 방식이 zero-shot 및 캐시 기반의 방식과 비교했을 때 모두 성능이 좋다는 것을 입증하였습니다. 또한, 학습 기반의 방식과도 비교하였을 때, 대규모 데이터로 학습된 LOWA 방식보다 두 벤치마크에서 모두 성능을 능가하는데, 이는 해당 방식이 training-free 방식임에도 경쟁력 있는 결과를 보여줌을 알 수 있습니다.
Experiments with multiple VLMs
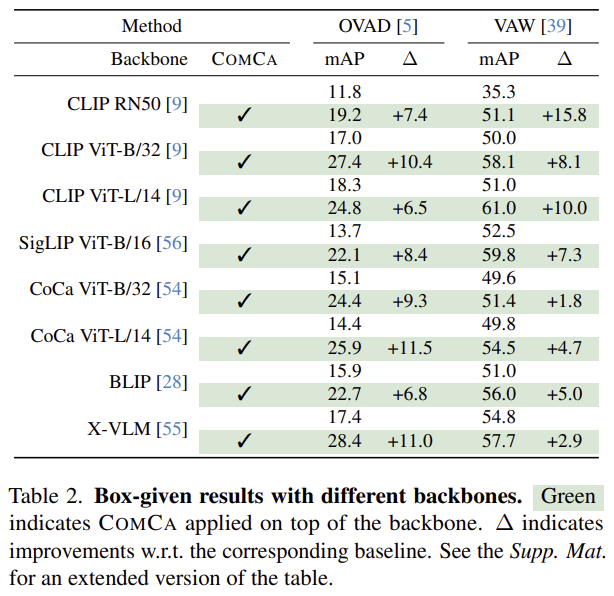
Table 2는 COMCA 방식이 model-agnostic함을 보이기 위해 다양한 백본과 VLM에 대한 실험을 수행한 결과입니다. OVAD와 VAW 모두에서 COMCA가 모든 백본에 대해 성능이 개선된다는 것을 확인하였으며, 해당 방식의 효과를 보여줍니다.
Cross-datasets advantages
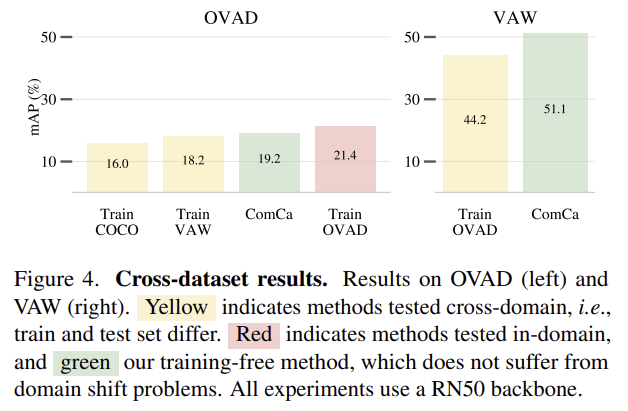
COMCA의 일반화 능력을 확인하기 위해 Figure 4는 cross-dataset 결과를 나타낸 것 입니다. OVAD와 VAW에 대한 결과 모두 학습 데이터와 평가 데이터가 다른 노란색 바에 비해 학습을 하지 않은 ComCa가 더 좋은 성능을 보였으며, in-domain인이 경우와 비교했을 때 경쟁력 있는 성능을 보여줌을 확인할 수 있습니다. 이를 통해 ComCA가 학습데이터에 편향되지 않는다고 주장합니다.
Box-free setting
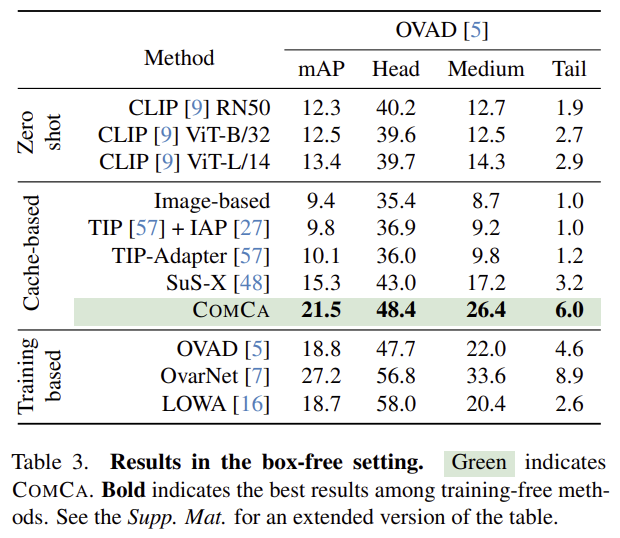
attribute detection 연구는 박스가 주어진 세팅을 기본으로 사용하지만, 실제와 더 유사한 시나리오에서 경쟁력을 확인하기 위해 box-free 세팅에서도 평가를 수행하였습니다. 해당 결과를 통해서도 COMCA 방식의 효과를 확인할 수 있습니다.
Qualitative results

Figure 3은 동일 백본에 대한 학습 기반 OVAD, zero-shot 방식, 캐시 기반인 COMCA에 대한 정성적 결과로, OVAD는 곰의 색상을 잘 예측하지만, 고양이의 색상 예측에는 실패하며, 두사람의 옷 패턴에 대해서도 잘못 예측합니다. 저자들은 옷의 패턴에 대해서 두번째와 마지막 이미지에 대해서 동일하게 tiled로 잘못 예측한다는 점을 통해 데이터 편향이라 추정하였으며, COMCA에 대한 결과 얼룩말의 시각적 패턴을 정확히 예측한다는 점을 어필하였습니다.
Ablation Study
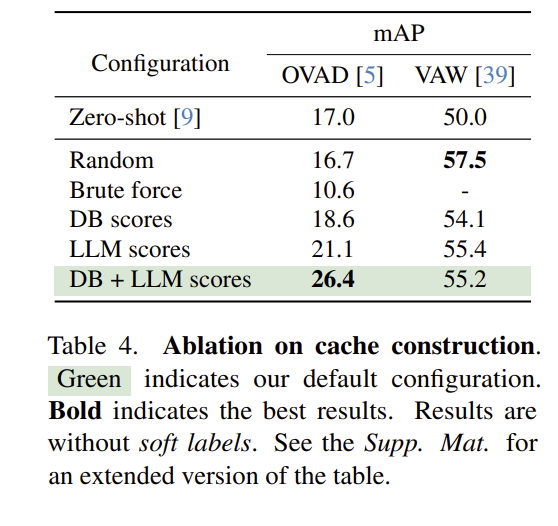
Table 4는 샘플링 방식이 성능에 영향을 미치는 결과로, 무작위로 K개를 샘플링하는 Random 방식과, 가능한 모든 조합을 고려하는 Brute force 방식을 함께 비교하였습니다. 참고로 VAW는 속성 미 객체 수가 너무 많기 때문에 Brute force를 실험할 수 없었고, OVAD에서는 두 방식 모두 성능이 매우 낮은 것을 확인할 수 있었습니다. VAW의 경우 Random에서 성능이 가장 좋았는데, 이에 대해 저자들은 VAW가 속성과 객체 수가 매우 많기 때문이라고 분석하였습니다. DB와 LLM score를 사용하는 경우 둘을 사용하는 게 OVAD에서는 가장 좋은 성능을 보였으며, VAW에서는 LLM score만을 사용하는 게 더 좋았다고 합니다.
Soft labels & Number of samples per attribute
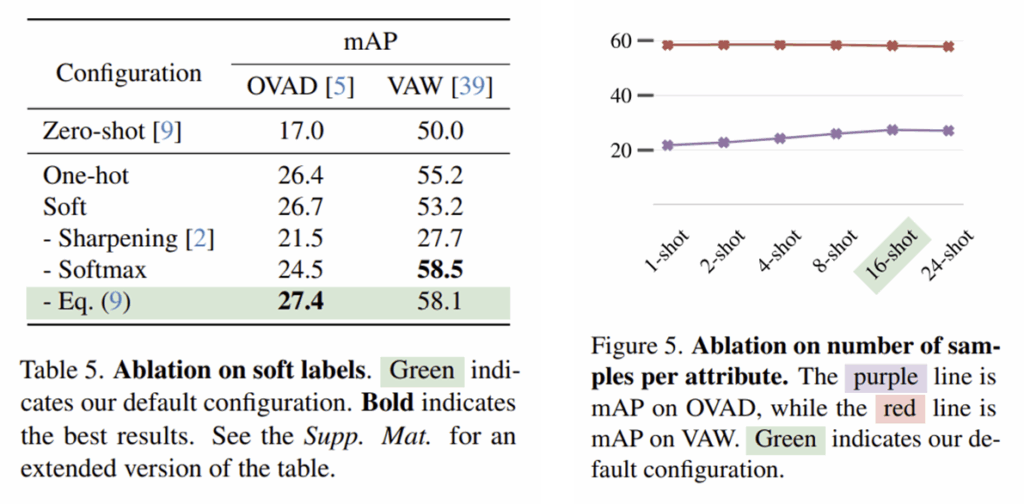
Table 5는 soft-label을 이용하는 것의 효과를 확인하기 위한 것으로, Soft는 정규화를 하지 않고 soft-label 점수를 그대로 이용하는 것이고, 아래의 3가지는 정규화 방식을 비교한 것 입니다.
Figure 5는 K의 수가 변함에 따른 성능 변화를 나타낸 것으로, 샘플 수가 증가할수록 OVAD에 대한 mAP가 증가하다 16에서 24개의 샘플로 넘어갈 때는 성능 변화가 거의 없는 것을 보고 K=16을 선택한 것으로 보입니다.
Conclusion
본 연구에서는 open-vocabulary 기반 attribute detection을 위해 Compositional Caching(COMCA) 기법을 제안합니다. COMCA는 VLM과 보조 이미지 캐시를 결합한 training-free 방식으로, LLM을 활용해 속성–객체 간 호환성을 추정하고 이를 기반으로 현실적으로 타당한 속성–객체 조합을 캐시에 포함합니다. 또한 하나의 이미지에 여러 속성이 공존하는 특성을 반영하기 위해 소프트 라벨링 기법을 도입하여, 각 캐시 요소가 다수의 속성 예측에 영향을 줄 수 있도록 설계함으로써 다중 속성 구조를 효과적으로 모델링합니다.
다양한 벤치마크와 설정에서의 실험 결과, COMCA는 zero-shot 및 기존 캐시 기반 방법론 대비 성능 향상을 확인하였으며, 일부 학습 기반 방식과도 경쟁력 있는 성능을 보였습니다. 특히, 학습 과정이 없기 때문에 데이터 편향의 영향을 줄였으며, cross-dataset 환경에서도 안정적인 성능을 유지합니다. 이를 통해 COMA는 open-vocabulary기반 attribute detection을 위한 실용적이고 효과적인 방식임을 보였습니다.
안녕하세요 승현님 좋은리뷰 감사합니다.
처음들어보는 내용이 많았지만 흥미롭게 읽게 되었습니다.
읽으면서 DB 기반이나 LLM 기반의 방식을 곱셈해서 환각을 줄인다던지 하는 부분이 좀 더 구체적으로 환각점수를 평가할 수 있다거나 했으면 좋았을 것 같습니다.
한가지 궁금한 점은 soft label 에서 가중치 알파값을 0.6으로 설정했는데 본래 라벨을 0.4비율로두고 나머지 멀티속성을 가질 수 있게 0.6의 비중을 둔것 같습니다. 여기서 0.6에 해당하는 부분에 어떤 속성들이 분포하는지 예시 figure 같은게 없었는지 궁금합니다. 한가지의 라벨이 전부 차지하는지 혹은 여러가지 라벨이 골고루 분포되었는지 궁금합니다. soft labeling 을 하면서 최종 confidence 에 민감해질수도 있을 것 같아서 질문드립니다.
감사합니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다!
compatibility를 구할때 db 기반 점수와 llm 기반 점수의 곱을 사용한 이유가 llm이 가진 편향의 영향을 줄이기 위함이라고 하는데, 한쪽 점수가 낮을 때 지나치게 보수적으로 작동하지 않는지 궁금합니다. 이 둘을 다르게 조합한 실험들도 논문에 나와 있는지 궁금합니다.
감사합니다.