안녕하세요. 새해 첫 엑스리뷰로는 기존에 읽어왔던 AVQA 관련 논문보단 VLM 에 관련된 논문을 들고왔습니다. 뭔가 한 태스크에 시야가 갇히는 느낌이 없지않아 있어서, 좀 다른 시야를 넓혀보고자 2025년 CVPR 에 등재된 논문을 들고왔습니다. 제목을 보면 요즘 VLM이 이미지를 어떻게 보고 있는지에 관한 분석이며 VLM의 새로운 구조를 제안한 것은 아니지만, 이미 존재하는 VLM 의 내부를 이해하려는 분석 중심의 연구입니다.
제가 VLM 관련된 논문들을 읽어오던 게 아니라 좀 부족할 수 있지만 질문해주시면 최대한 답글 달아보겠습니다. 그럼 리뷰 시작하겠습니다.
Abstract
최근의 VLM 들은 복잡한 시각적 콘텐츠를 이해하는 데 있어 매우 뛰어난 능력을 보여주고 있습니다. 그러나 이러한 VLM들이 시각 정보를 어떻게 처리하는지에 대한 내부 매커니즘은 여전히 거의 탐구되지 않은 상태입니다. 흔히들 블랙박스라고 명칭하죠
저자의 논문에서는 전반적인 계층 내에서의 attention 모듈에 초점을 맞추어 VLM 의 동작을 분석합니다. 이를 통해서 시각 데이터를 처리하는 방식에 대해서 몇 가지 핵심적인 사실을 밝혀냈다고 합니다.
- 쿼리 토큰의 내부 표현 (describe teh image) 와 같은 프롬프트의 표현은 VLM 내부에서 전역적인 이미지 정보를 저장하는 용도로 활용된다. 이러한 쿼리 토큰들을 기반으로 이미지 토큰들에 접근하지 않더라도 이미지를 놀랍도록 잘 묘사하는 응답을 생성할 수 있음을 보인다.
- 교차 모달 (cross modal) 정보의 흐름은 주로 중간 계층 (전체 계층의 25%) 에 의해 지배되고, 초기 계층과 후반 계층의 기여도는 상대적으로 매우 제한적이다.
- 세밀한 시각적 속성과 객체의 세부 정보는 이미지 토큰으로부터 공간적으로 국소화된 방식으로 추출된다. (spatially localized manner) 즉, 특정 객체나 속성과 관련된 생성 토큰들은 이미지 내의 해당 영역에 대한 강한 attention 을 보인다.
저자는 실제 세계의 복잡한 시각 장면을 활용해서 이러한 관찰 결과를 검증할 수 있는 새로운 정량적 평가 방법을 제안합니다. 그리고 최신 VLM에서 저자의 분석 결과가 효율적인 시각 정보 처리를 가능하게 하는 데 어떻게 활용될지 실증적으로 보여줍니다.
Introduction
앞서 Abstract에서 언급한 내용과 거의 비슷합니다.
VLM 은 LLM 의 강력한 확장 기능으로 등장하였고, 복잡한 시각적 장면을 매우 상세하고 정확하게 묘사해서 여러 분야에서 특히 로보틱스나 의료영상, 자율주행, 콘텐츠 생성 등에서 빠르게 채택되어가고 있습니다.
점점 더 많은 채택에도 불구하고 VLM이 종종 특정 작업을 해결하기 위한 블랙박스 에이전트 쯤으로 취급되고 시각 데이터를 처리하는 그 내부 매커니즘에 대한 이해는 제한적입니다. 이러한 매커니즘을 밝혀내는 것이 모델의 투명성이나 효율성 신뢰적인 측면에서 필수적이고 미래의 VLM 설계나 고위험 어플리케이션을 활용하는데에도 중요합니다.
저자는 VLM 이 입력 이미지와 함께 이 이미지를 설명해줘 “describe the image” 와 같은 쿼리를 받는 시나리오를 조사한다고 합니다. VLM 은 autoregressive 하게 응답을 생성하고 각 생성된 토큰은 입력이미지와 텍스트 모두에서 정보를 수집합니다. 저자는 시각 및 텍스트 간의 정보 흐름을 이해하는 것을 목표로 했고, VLM의 레이어를 가로지르는 attention 모듈을 통해서 몇 가지 중요한 통찰을 밝힐 수 있었다고 합니다. Abstract에서 언급한 내용을 좀 더 구체적으로 다시 설명드리면
- 모델은 고수준의 이미지 정보를 쿼리 텍스트 토큰으로 압축합니다. 이미지 토큰이 생성 토큰에 미치는 직접적인 영향을 차단해보고 시각 정보가 쿼리 텍스트 토큰을 통해서만 간접적으로 접근되도록 유도해서 이 통찰을 입증합니다. 놀랍게도 모델은 쿼리 텍스트 토큰에 인코딩된 시각 정보에만 의존해서 상세한 응답을 생성합니다.
- 중간 레이어는 시각에서 언어로의 지식 전달에 중요한 역할을 하는 반면, 초기 및 후기 레이어는 그 기여도가 미미합니다. 전체 layer의 25% 에서만 이미지 토큰에 접근하더라도 VLM 의 성능에는 아주 미미한 저하만 있다고 합니다.
- 세밀한 객체의 특징과 시각적 속성은 공간적으로 국소화된 방식으로 이미지 토큰에서 직접 추출됩니다.
저자는 위의 설명한 각 실험에서 VLM의 원래 출력과 수정된 출력 (이미지 토큰이 생성 토큰에 미치는 영향을 차단한다거나, 레이어의 통제 등) 간의 정렬을 측정해서 관찰을 검증하는 것에도 기여를 합니다. VLM 은 이미지를 설명하는 자유 형식의 텍스트를 성하기에, 텍스트를 비교하는 것은 단어나 문체에서 큰 차이가 있을 수 있고 이러한 어려움을 극복해야 했습니다.
기존 연구에서 영감을 받아 LLM 기반의 평가 프로토콜을 제안하고 수정된 응답과 원본 응답간의 일치도를 정량적으로 측정할 수 있게 했습니다. 의미론적 유사도나 객체의 포함 여부등을 평가하고 사람의 수동적인 평가가 없어도 객관적 비교가 가능하다고 합니다. 또한 인간 평가자의 판단과 LLM 의 평가 결과를 비교해서 LLM 기반의 평가 신뢰도를 높였다고 합니다. 또한 segmetation tool 등을 이용해서 VLM이 이미지의 특정 부분을 얼마나 정확하게 인식하고 텍스트 생성에 반영하는지도 평가할 수 있었다고 합니다.
그리고 이러한 분석과 검증을 통해 얻은 인사이트로는 VLM의 효율적인 시각 처리 방안을 제시합니다. VLM 의 내부 표현을 압축된 컨텍스트 공간으로 추출할 수 있게 되는데, 이는 Image Re-Prompting 이라는 새로운 응용으로 이어집니다. 해당 기술을 통해서 전체 이미지를 다시 처리하지 않고도 압축된 컨텍스트만으로 이미지에 대해 여러 질문을 효율적으로 답할 수 있다고 합니다. 압축된 컨텍스트는 원본보다 20배가량 작지만 VQA 성능을 96% 달성하여 그 효율성과 성능을 동시에 확보했다고 합니다.
Related Work
VLM 들은 대규모 언어 모델 (LLM) 을 확장하여 시각적 정보와 텍스트 정보를 함께 처리할 수 있도록 만든 모델입니다. 이러한 모델에서 LLM 은 대부분의 연산 분석을 담당합니다.
VLM은 일반적으로 다음과 같은 세가지 주요 구성 요소로 이루어집니다.
- 사전학습된 LLM : 텍스트 이해 및 생성을 담당합니다.
- 비전 인코더 : 입력 이미지를 처리하여 시각적 특징을 추출합니다.
- 어댑터 : 비전 인코더에서 추출된 시각적 표현을 LLM 의 임베딩 공간에 맞도록 조정하는 역할을 합니다.
초기의 VLM 은 CLIP 과 같은 모델을 비전 인코더로 사용했지만, 최신 모델들은 더 큰 비전 인코더를 사용해서 다양한 해상도의 이미지를 처리한다고 합니다. 시각적 임베딩은 MLP 기반의 어댑터를 통해 LLM 공간으로 맞추는 것이 일반적입니다. 저자의 연구에서는 최신 오픈소스 VLM 인 InternVL2-76B 모델을 분석하고 널리 사용되는 LLaVA-1.5-7B 등을 통해 결과를 검증해서 다양한 아키텍처에서 일반화될 수 있는지 분석합니다.
Interpreting LLMS
LLM이 널리 사용됨에 따라 트랜스포머의 어탠션 레이어나 FFN layer, 활성화 패턴등의 해석 연구가 활발히 진행되고 있습니다. logit lens 와 같은 기법은 각 레이어에 어떤 정보가 인코딩되어있는지 밝혀주는데, 저자는 이러한 기존의 연구와 달리 어텐션을 차단하는 기법을 (저자는 attention knockuout 이라고 부릅니다.) 모델 내에서 정보가 어떻게 흐르는지에 초점을 맞춥니다.
Interpreting VLMS
VLM 해석 분야는 계속 발전하고 있으며 기존 연구들이 모델 내 정보 저장의 위치나 사전학습된 인코더의 단점, VLM 의 환각 증상등에 주목해왔습니다. 저자의 연구는 압축된 고수준 정보와 국소화된 세부 정보 검색이라는 두 가지 주요 매커니즘을 통해 VLM의 내부 시각적 표현을 더 폭넓게 분석합니다.
이러한 이해를 바탕으로 VLM 의 효율적인 처리 방안을 탐구할 수 있는 새로운 응용 가능성을 제시합니다.
LLM-as-a-judge
LLM은 인간 주석가를 대체할 수 있는 대안으로 인식되고 있고, 다양한 작업에서 확장 가능하고 재현 가능한 평가 방법을 제공합니다. 특히 “Judging llm-as-a-judge with mt-bench and chatbot arena” 논문을 통해 LLM 을 사용해서 다른 LLM이 생서안 응답을 평가하는 개념을 확립했고, 저자도 이 내용을 활용해서 두 개의 자유 형식 텍스트 이미지 설명을 비교하고 객체 식별이나 환각 현상을 자동으로 평가하는 LLM 기반 평가 프로토콜을 도입합니다.
Preliminary
VLM 은 입력 이미지와 텍스트 쿼리를 처리하여 응답을 생성하기 위해 다음과 같은 3가지 종류의 토큰을 사용합니다.
- Image tokens : 입력 이미지 I 를 VLM 이 이해할 수 있는 벡터 형태로 변환한 토큰들입니다. 이 토큰들은 사전 훈련된 비전 인코더와 어댑터를 통해 생성됩니다. $T_{img} ∈ R^{|P{img}|×d}$ 여기서 P_img 는 전체 토큰 시퀀스 내에서 이미지 토큰들이 차지하는 인덱스 집합입니다.
- Query Tokens : 사용자가 VLM 에 입력하는 텍스트 쿼리입니다. 이 토큰들은 VLM 이 이미지에 대해 무엇을 알고 싶은지를 나타내는 역할을 합니다. $T_{txt} ∈ R^{|P_{txt}|×d}$ 여기서 |P_txt| 는 쿼리 토큰의 개수 P_txt는 전체 시퀀스 내 쿼리 토큰의 인덱스 집합입니다.
- Generated Tokens : 생성 토큰은 VLM 이 생성하는 응답 텍스트를 나타내는 토큰들입니다. 이 토큰들은 이전 토큰들의 정보를 바탕으로 순차적으로 생성됩니다. i번째 생성 토큰들은 $T^{(i)}{gen} ∈ R|P^{(i)}{gen}|×d$ 로 표현되고 P^i_gen 은 i번째까지 생성된 토큰들의 인덱스 집합입니다.
위의 3가지 토큰들이 전체 시퀀스 T로 결합됩니다. $T = [T_{img}, T_{txt}, T_{gen}]$
추가적으로 VLM 은 저희가 익히 많이 들어본 트랜스포머 아키텍처를 사용하며 여기서 정규화 + causal self-attention + FFN MLP 로 구성됩니다. (causal 은 마스킹 기법을 사용한다고 생각하시면 됩니다.)
What’s In The Image?

주요 실험들 이전에 저자가 분석한 attention 비율입니다. COCO 데이터셋에서 선택한 무작위 80장의 이미지에 대해서 Generated 토큰이 어떠한 다른 토큰들과 attention score가 높은지를 layer별로 분석한것인데, 질문 문장이 “Describe the Image” 라는 엄청 단순한 문장임에도 불구하고 전반적인 모든 layer에서 generated 토큰은 Query 토큰에 attention 을 주고 있습니다. 이러한 점으로 보아 저자는 Describe the Image 와 같은 일반적인 쿼리 텍스트가 이미지에 대한 고수준 정보를 압축하여 보유하고 있고, 이는 쿼리 텍스트가 단순한 명령이 아니라 이미지에 대한 풍부한 정보를 담는 매개체 역할을 할 수 있음을 보여줍니다. (텍스트 토큰은 전체토큰의 5% 미만의 비율을 차지합니다.)
저자는 이러한 비균일적 패턴에 주목하여 이미지 토큰과 쿼리 토큰에 축적되는 정보의 성격과, 이들이 생성 과정에서 수행하는 역할을 보다 잘 이해하기 위해 서로 다른 토큰 유형 간의 정보 흐름을 차단하고, (knock out) 그에 따른 생성 결과의 변화를 평가합니다. 또한 앞서 언급했듯이 Knockout 이 적용된 버전과 원래 버전의 출력을 비교할 수 있게, 정량화할 수 있게 하는 새로운 LLM 기반 평가 프로토콜을 제안합니다.
Attention Knockout in VLMs

저자는 4가지 방식의 KO 전략을 세웁니다.
- 원본의 KO 가 없는 형태
- Img 정보가 Gen 에게 가지 않도록 흐름을 차단
- Img 정보가 text 에 가지 않도록 흐름을 차단
- Img 정보가 Text 및 Gen 에 가지 않도록 차단
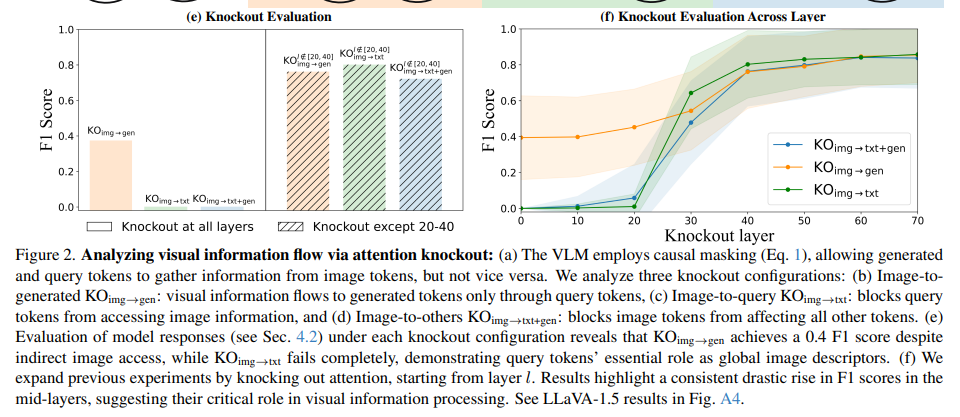
우선 KO 를 적용했던 방식중 이미지의 정보를 text에 넣지 않는 방식이 F1 Score가 가장 낮았고, Gen에만 막는 방식이 F1 Score 가 어느정도 유지가 되었습니다. 해당 결과는 평소 저희가 생각하는 양상과 다른데, Gen Token이 결과를 생성해내는 관점에서 이미지를 봐야할줄 알았지만 텍스트가 이미지를 Cross attention 으로 정보를 봐야 성능이 나온다는 뜻입니다.
우측 그래프를 보면 KO 를 0~70 layer중 중간에 적용했을떄의 성능 추이인데, 20~40 layer 이후에 적용하면 성능이 어느정도 회복됨을 알 수 있습니다. 이를통해 20~40 layer 상에서 image 의 정보들이 text에 스며들고, text의 정보를 gen 이 보게되어 성능이 회복됨을 알 수있습니다. 이를 통해 Text Token이 image의 global descriptor같은 역할을 한다는 것을 알 수 있습니다.

위의 F1 score 가 어떤 방식으로 계산되는 것인지에 대한 Figure 입니다.
아무것도 적용하지 않은 원본 VLM 의 응답과 각 방식의 응답에서 동일하게 내뱉는 부분은 TP로, 원본에는 등장하나 Modified 에서 등장하지 않는다면 FN으로, 그리고 modified 에만 등장하면 FP 로 계산하는 방식입니다.

앞서 언급했던 20~40 layer 에서 이미지의 정보가 text 정보와 교환되고 있다는 증거로 text token 이 이미지의 global descriptor 로서 이미지의 전역적인 부분을 보면서 정보를 습득한다고 생각하면 될 것 같습니다.
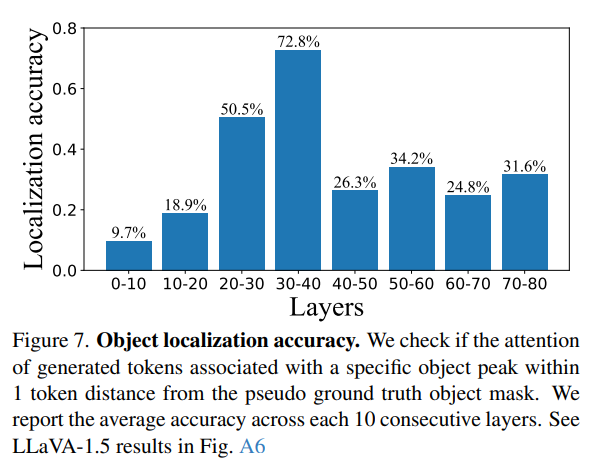
Fine-Grained Details Localized in Mid Layers

저자는 mid layer에서 생성 토큰이 이미지 토큰을 볼 떄, 그 attention 값들이 실제 객체 정답 mask 와 얼마나 유사한지를 시각적으로도 보여줍니다. 전반부 layer나 후반부 layer에서는 해당그림과 같은 mapping 이 잘 이루어지지 않으며, 이는 다음과 같은 accuracy figure 로 보여줍니다.
Efficient Visual Processing in VLMs
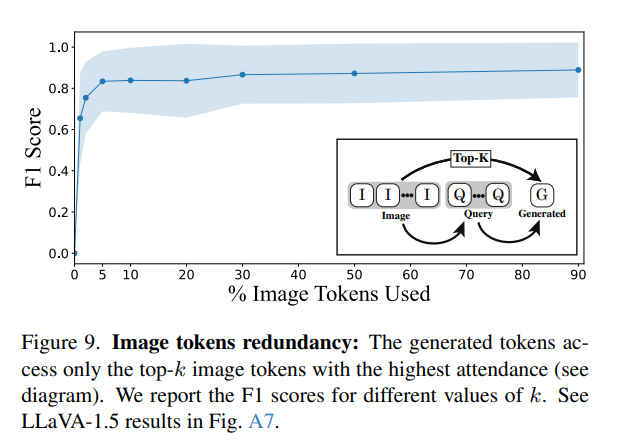
저자는 이미지의 정보가 text 토큰에 압축이 된다면 해당 압축된 정보를 토대로 VLM 의 추론을 도울 방법을 생각합니다. attention score 기반으로 image tokens 들을 일부분 pruning 하고 사용한 결과를 보여줍니다. 대부분 20~40 layer에서 높은 attention 이 분포했고, 5프로만 사용하더라도 기존의 성능을 어느정도 유지할 수 있었다고 합니다.
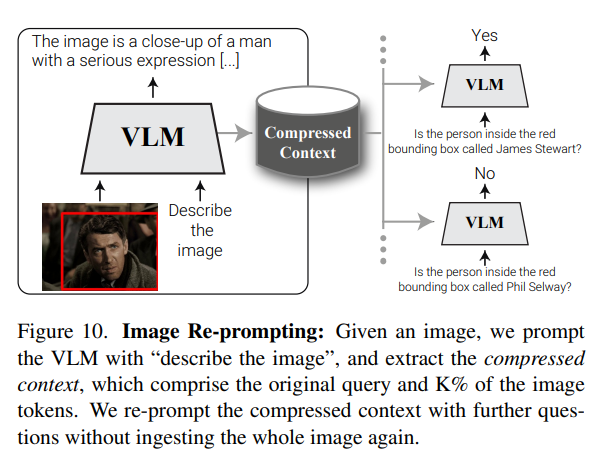
해당 Figure 는 앞서 언급한 Image Re-prompting 방법입니다. 아이디어 자체는 VLM 이 VQA 를 수행할때 매번 동일 이미지를 다시 볼 필요가 없고, 한번 요약된 시각 컨텍스트만 뽑아두면 이후 동일한 성능을 낼 수 있다는 것입니다. 이것을 저자는 Image Re-prompting 이라고 명칭합니다.
앞서 실험했던 생성토큰이 Image token 에 주는 attention score가 높았던 부분만 뽑아써도 성능이 유지되는 것을 토대로 compressed context를 쓸 근거를 마련했다고 생각하면 됩니다.
여기서 compressed context는 쿼리토큰과 상위 K% 의 Image token 을 사용했고 이미지 없이 VQA 를 수행해도 크게 성능이 떨어지지 않는점을 보입니다. 신기한 점은 OCR 이나 count 같은 task 는 성능이 오른다는 점입니다. 해당 기법이 한번 질문하는 상황에서는 어차피 VLA 를 한번 돌려야하니 크게 의미가 없을 수 있지만 한 이미지를 통해 여러번 질문한다면 동일 이미지를 계속 넣지 않아도 비슷한 수준의 성능을 보장할 수 있는 결과를 보여준다고 생각합니다. 또한 한 이미지에 여러 질문이 있더라도 사용이 가능하고 이후 결론에서 얘기하듯이 LLM 의 토큰수 제한이 보통 이미지에서 많이 차지하기 때문에, Re-prompting 방식을 통해 비디오나 더 많은 이미지의 처리가 가능하게 됩니다.

Conclusion
저자는 수십B 의 규모를 가지는 VLM 에 대해서 그 내부 동작을 이해하기 위한 의미있는 첫 단계를 제시했다고 합니다. VLM 내부의 시각적 표현과 처리 방식에 대해 새로운 사실을 밝혀냈고 제안한 평가 방법들로 이러한 방법들을 실증적으로 확인했습니다. 향후 연구에서 저자의 분석을 다중 이미지 및 비디오 입력으로 확장할 수 있고 Iamge Re-prompting 응용 또한 VLM 의 효과적인 시각적 컨텍스트 윈도우를 확장하는 방향으로 발전시킬 수 있을거라고 합니다. 뭔가 저자는 Iamge 를 한번 넣어서 얻은 compressed context에 여러 질문을 넣을 수 있는 방식을 언급한 것 같지만, 나이브하게 좀 더 생각해보니 small vlm 에 원본 이미지를 넣고 구한 compressed context들을 모아서 long video 에 대한 이해나, 긴 질문을 넣는다거나 하는 형태로도 사용이 가능할 것 같습니다.
감사합니다.
리뷰 잘 읽었습니다.
20~40 layer가 핵심이라는 결과는 흥미로운데, 읽다 보면 이런 궁금함이 생기는데요, 왜 하필 중간 레이어에서 시각 정보가 언어로 전달되는 건지? (초기에는 feature가 너무 로우레벨이고, 후반에는 이미 언어적으로 고정돼서이지?) 이 패턴은 VLM 구조 전반에서 자연스럽게 나타나는 현상인건디 아니면 InternVL 계열 구조의 특성인지 궁금합니다
좋은 리뷰 감사합니다. 분석 논문이라 재밌게 읽었네요.
쭉 읽다보면 전반적으로 internVL에 대한 실험 결과이고, appendix에 LLaVA에 대한 결과가 나와있는 것으로 보입니다. LLaVA, BLIP-2같은 VLM들이 비전 토큰을 LLM 입력으로 매핑해준다는 점에서는 유사하지만 그 방식과 규모에서 차이가 큰데요, 이런 다양한 VLM들에서도 동일한 경향이 유지되는지 궁금하네요. 관련 설명이 있나요?
감사합니다.
안녕하세요 인택님, 좋은 리뷰 감사합니다. 질문 한 가지 드리겠습니다.
“describe the image”와 같은 쿼리 토큰이 이미지의 전역 정보를 함축하는 역할을 한다고 하셨는데, 다른 식의 쿼리 토큰을 입력했을 때는 역할이 바뀌는 지에 대한 내용도 논문에 담겨있는지 궁금합니다. 예를 들어 “이미지 내 사람의 옷 브랜드가 뭐야?” 라는 쿼리 토큰을 입력했을 때, 예상대로 질문과 관련한 편향된 정보만 압축하는지 아니면 전역 정보 역시 담게 되는 건지 궁금합니다!
리뷰 재밌게 잘 읽었습니다. 인택님
중간 layer가 가장 표현력이 좋다는 점이 꽤나 흥미로운 논문이네요.
쭉 읽다보니 attention weight가 정보를 잘 표현한다는 가정도 깔려있는 것 같습니다.
또한 InternVL과 LLaVA를 중심으로 실험을 구성했는데, 구조적으로 다른 VLM에 대한 분석이 포함되지 않은 점은 다소 아쉽게 느껴집니다.
그렇다면 이러한 결론 “중간 layer의 표현력과 query token의 역할”이 다른 구조의 VLM에서도 일반적으로 성립한다고 볼 수 있을지에 대해서는 어떻게 생각해야 할까요?