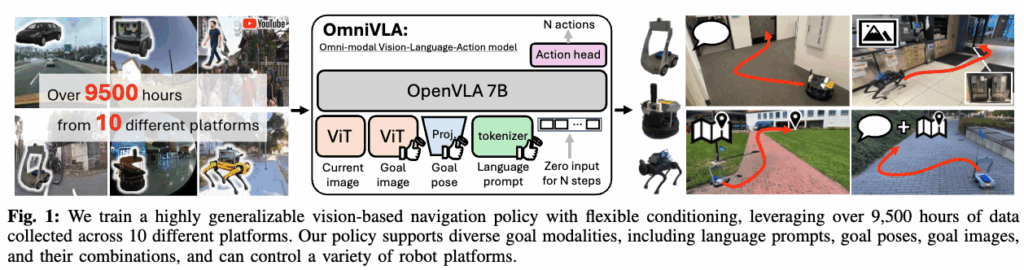
안녕하세요. 이번에 리뷰할 논문은 OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation입니다. 2025년 9–10월쯤 아카이브에 올라온 논문인데, 읽어보니 현재 연구실에서 돌리고 있는 모바일 플랫폼에도 적용 가능성이 꽤 높아 보여서 한번 공유하고자 가져왔습니다.
지금까지는 주로 이미지 goal이 주어졌을 때 그 목표까지 얼마나 안정적으로 찾아갈 수 있는지에 초점을 둔 방법론들을 많이 다뤘다면, 이번에 리뷰하는 논문은 그보다 한 단계 확장해서, 특정 단일 모달리티에 묶이지 않고 상황에 따라 여러 목표 모달리티( 언어, 포즈, 이미지 등) 를 유연하게 활용하면서 내비게이션을 수행하는 방향을 제안한다고 보시면 될 것 같습니다.
그래서 실제 로봇에 적용해본다고 가정했을 때도, 목표를 주는 방식이나 환경 조건에 따라 입력 모달리티를 바꿔가며 다양한 시나리오로 이리저리 적용해 볼 수 있겠다는 생각이 들었습니다. 그럼 바로 리뷰 시작해보도록 하겠습니다.
Introduction
저자들은 내비게이션을 수행하는데 있어서 “기존 방식들은 목표(goal)를 주는 방식 자체가 너무 한 가지로 고정돼 있지 않나?” 라는 문제의식을 가집니다. 사람은 실제로 길을 찾을 때 언어, 지도(GPS), 눈에 보이는 랜드마크 같은 걸 상황 따라 섞어서 쓰는데, 로봇 내비게이션 연구는 생각보다 의외로 단일 모달리티 목표에 맞춰 정책을 학습시키는 경우가 많다는 것을 저자들은 지적합니다.
예를 들어 목표가 가까우면 “건물 따라가서 입구로 가” 같은 언어 지시가 편하고, 목표가 멀면 좌표(2D pose/GPS) 로 찍어주는 게 더 효율적입니다. 그리고 실제 운용 관점에서는 “여기 좌표로 가는데, 마지막에는 이 랜드마크(이미지) 근처로 가”처럼 좌표 + 이미지 조합이 더 자연스러울 수도 있습니다.
그래서 저자들이 말하고자하는 포인트는 보통 범용 내비게이션이라고 부르려면 단일 입력만 잘하는 게 아니라, 여러 목표 표현을 유연하게 받아들이고(심지어 조합도) 성공적으로 수행해야 한다라는 것입니다.
로봇의 관측은 partial하고 각 모달리티의 서로 겹치는 정보 그리고 플러스 알파로 인해 이것들이 결국에는 네비게이션 수행에 있어서 상호보완적인 힌트로 작동될 수 있습니다. 예를 들어 좌표 goal는 기하학적으로 명확하지만 거기 가면 뭐가 보이는지에 대한 시각적 힌트가 없을 수 있고, 이미지 goal은 시각적인 측면에서 유리할 수 있지만 대략 어느 방향/거리로 가야 하냐는 공간적인 힌트가 약할 수 있습니다. 언어는 의미(semantics)로 보완을 해줄 수 있고요. 그래서 저자들은 여러 모달리티 목표를 같이 학습시키면, 모델이 기하(geometric : 2d Pose) + 시각(visual : egocentric Image) + 의미(semantic – language)를 더 풍부하게 이해하게 되고 결국 더 유연하고 범용적인 네비게이션을 수행할 수 있다고 주장합니다.
그리고 또 하나의 포인트는 데이터 관점입니다. 파운데이션 모델을 만들려면 데이터가 많아야 하는데, 현실의 로봇 내비게이션 데이터는 보통 이 데이터셋은 언어 지시가 있고, 저 데이터셋은 포즈 목표만 있고, 또 다른 건 이미지 목표만 있고 이런 식으로 모달리티가 갈라져 있는 경우가 많습니다. 그래서 기존 방식대로라면 학습에 쓸 수 있는 데이터가 내가 선택한 task representation에 의해 제한됩니다. 반면에 OmniVLA는 목표 표현 자체를 옴니-모달로 열어두면서, 서로 다른 데이터셋을 하나의 학습 프레임워크로 학습시킴으로써, 이런 데이터 제약에서 벗어나 멀티모달 LLM에서 task mixture가 성능을 올리는 것과 유사한 이점을 가져올 수 있다고 주장합니다.
정리하면, 이 논문에서 저자가 주장하는 핵심 포인트는 2가지인 것 같습니다. 첫번째는 내비게이션 목표는 원래 다양한 모달리티로 주어질 수 있는데, 기존 연구는 너무 단일 모달리티에 갇혀 있었다. 그래서 partial observation 환경에서는 모달리티들이 상보적으로 작동할 수 있게 끔 여러 목표 표현을 함께 쓰는 범용 정책이 필요하다.는 것이고 두번쨰는 데이터셋들이 모달리티별로 파편화되어 있으니, 옴니-모달 목표 학습이 오히려 파운데이션 모델을 만들기 위해서 데이터 관점에서 유리하다 라는 것으로 이해하시면 좋을 것 같습니다.
그래서 이 OmniVLA 라는 모델의 goal 입력은 (1) 2D Pose, (2) egocentric Image, (3) launage Prompt 를 기본 축으로 두고, 경우에 따라 이들을 섞어도 되는 형태로 설계합니다. 또 모달리티 불균형/희소성 문제를 해결하기 위해 학습 때는 modality dropout, 추론 때는 modality masking을 써서 특정 모달만 보고 대충 맞추는 모델이 아니라 주어진 목표 모달리티간의 표현을 고려해서 활용하는 그런 모델을 만들겠다는 전략을 설계합니다.
결국 OmniVLA는 멀티모달 목표를 받을 수 있는 내비게이션 VLA를 end-to-end로 만들겠다 라는 것이고 이어지는 파트에서는 실제로 해당 방법이 어떻게 설계되고 학습되었는지 다루도록 하겠습니다.
Methods
아키텍처는 기본적으로 VLA(OpenVLA)를 기반으로 합니다. 결국 VLM이 인터넷 규모로 사전학습하면서 얻은 지식과 VLA가 다양한 로봇 형태(cross-embodiment) 행동 데이터로 학습한 지식을 최대한 살리겠다는 것이고 이미 강한 prior를 가진 기반 모델에 goal-conditioning을 옴니-모달로 확장하는 방향으로 모델을 설계합니다.
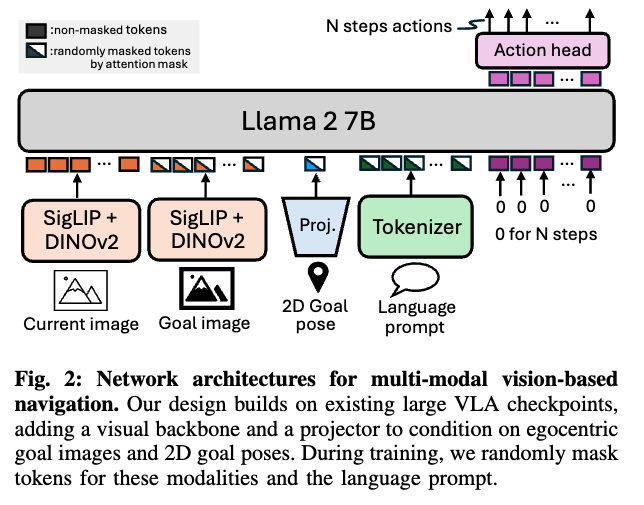
그림 2를 기준으로 보면 현재 관측(egocentric image)는 visual encoder(SigLIP+DINOv2)로 처리하는 것을 알 수 있고 목표(goal)는 세 가지 모달리티를 지원하는 것을 알 수 있습니다.
- visual goal(목표 이미지)
- positional goal(2D pose)
- language goal(자연어)
그리고 이 셋은 하나만 들어가도 되고 동시에 같이 들어갈 수 있는 형태 입니다.
그리고 이 서로 다른 목표 모달리티를 각각 따로 다루는 게 아니라, 결국 LLM에 들어가기 이전 공유 토큰 공간(shared token space)으로 projection되어서 LLM 백본 입력 토큰으로 함께 들어가는 식으로 동작합니다. 사실상 모달리티가 다르더라도 LLM 관점에서 보면 같은 토큰 시퀀스로 처리한다라고 보시면 좋을 것 같습니다. (근데 동일한 토큰 시퀀스로 처리하기 이전에 각 모달리티별 토큰끼리 어떠한 상호작용을 할 수 있게끔 하는 설계가 되어있는지는 논문에서 확인할 수는 없어 관련해서는 나중에 코드 단에서 한번 파악하고 나중에 해당 리뷰에 다시 추가하도록 하겠습니다. ) 일단은 그냥 각각의 인코더 프로젝터 토크나이저를 타고 나온 토큰 값들 하나의 시퀀스로 묶어서 그대로 그냥 LLM에 태우는 방식으로 이해하고 넘어갔습니다.
여기서 각 모달리티가 하나만 들어가거나 동시에 들어갈 수 있도록 할 수 있는 역할을 하는 것이 modality dropout입니다. 이건 앞에서 말한 데이터셋 파편화(모달리티 불균형/희소성)을 조금 해소하기 위한 장치이기도 합니다. 어떤 배치에서는 언어 goal을 가리고, 어떤 배치에서는 pose를 가리고, 이런 식으로 목표 입력을 랜덤하게 빠뜨려서, 모델이 특정 모달리티 하나만 편식하지 못하게 만드는 그런 느낌입니다. 결과적으로 주어진 모달리티가 뭐든(혹은 여러 개가 같이 오든) 그걸 받아서 행동을 뽑아내는 정책을 만들겠다는 의도로 이해하시면 좋을 것 같습니다.
행동 출력은 OpenVLA-OFT 방식을 따라서 LLM 출력 위에 linear action head를 붙여서 길이 N 짜리의 action sequence를 예측하는 방식으로 동작한다고 보시면 좋을 것 같습니다.
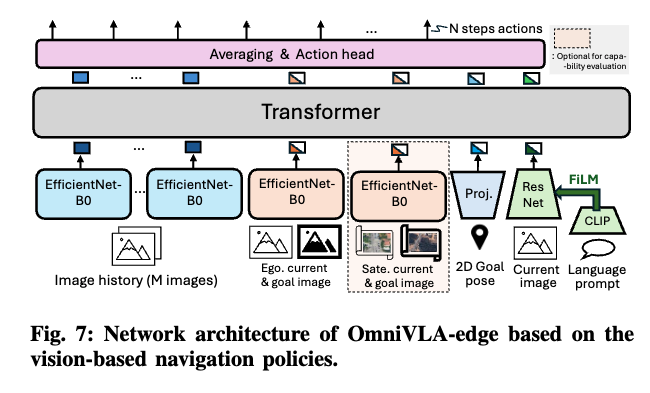
저자들은 이제 여기에 추가적으로 Edge 버전도 제안을 하는데, 논문이 단순히 OpenVLA(7B)로 끝이 아니라, ViNT 기반의 OmniVLA-edge도 같이 만듭니다. 이게 결국 현실 로봇 배포에서 7B 모델 추론이 부담되는 상황을 고려했을 수 도 있지만 해당 저자가 ViNT의 같은 저자임을 고려했을 때 그들이 일전에 제안했던 가벼운 파운데이션 모델을 안쓸이유도 없을 것 같긴합니다. 암튼 라마에 비해 상당이 라이트한 ViNT(50M)를 기반해서 목표 인코더들을 추가하고 modality dropout을 동일하게 적용해서 엣지한 옴니-모달 goal-conditioning을 또한 가능하다라는 것을 보여줍니다.
Train
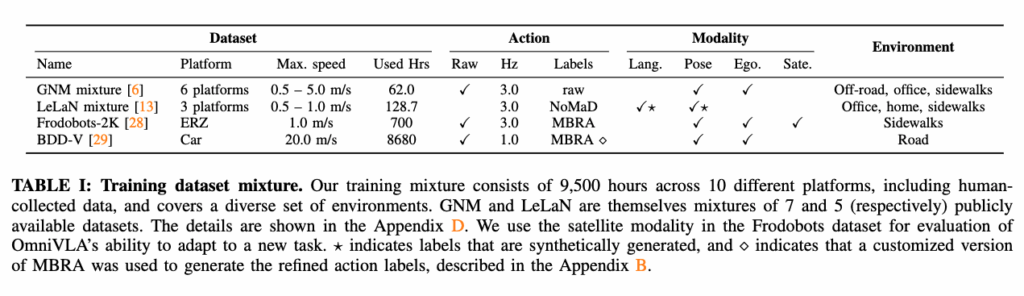
일단 데이터 셋 같은 경우는 공개 데이터셋 13개, 서로 다른 embodiment 10개, 총 9,500시간규모를 섞어서 학습했다고 합니다. 여기서 중요한 건 단순히 시간이 많다가 아니라, 환경/로봇 형태/모달리티가 다 다른 것들을 최대한 크게 섞어서 하나의 학습 프레임워크로 학습 시켰다는 것입니다. 저자 표현대로라면 “우리가 아는 한 가장 큰 규모의 mixture 데이터 셋이다”라고 언급되어있습니다.
근데 대규모 데이터를 쓰면 일반화가 좋아지지만, 수집이 커질수록 노이즈가 늘어서 결과적으로 데이터가 덜 정확해 질 수 있는 문제가 있습니다. 그래서 저자들은 학습시 Frodobots이라는 데이터 셋 같은 경우는 MBRA 로 생성한 합성 행동을 사용하고 LeLaN 데이터 셋 같은 경우는 NoMaD로 생성한 합성 행동을 라벨로 사용했다고 합니다. 그리고 BDD-V 데이터셋(자율주행 차량 데이터) 같은 경우는 저자들이 하고자 하는 소형 로봇 데이터 셋 사이의 큰 embodiment 갭을 충분히 반영하지 못하는 데이터 셋입니다.
그래서 기존 재어노테이션 방식이 그대로 사용하면 잘 안맞는다고 합니다. 그래서 이 데이터셋 같은 경우는MBRA의 접근을 변형해서 현재 상황에 맞게끔 그럴 듯한 합성 행동을 생성하는 재어노테이션 모델을 별도로 학습해서 사용했다고 합니다. 그리고 GNM mixutre 데이터 셋 같은 경우에는 고품질 raw 행동 데이터가 있으므로 해당 데이터셋 같은 경우는 그대로 사용합니다. 결국 중요한 것은 노이즈를 제거하기 위해 이미 검증된 재어노테이션/ 합성 행동 모델을 통해 pseudo-GT에 가까운 행동을 만들어서supervision으로 쓰는 것이고 GNM과 같이 현재 상황에 적합한 고품질의 raw 행동데이터 셋 같은 경우는 그대로 GT로 사용하는 식으로 실용적으로 접근했다는 점입니다.
여기가 어떻게 보면 이 섹션의 핵심일 수도 있을 것 같은데, 멀티모달 학습에서 가장 고려해야할 문제가 결국 어떤 샘플은 언어만있고, 어떤 샘플은 pose랑 이미지가 있고, 어떤 샘플은 이미지 목표만 있는 등 이런 데이터 불균형 문제라고 볼 수 있습니다.
위와 같은 문제를 해결하기 위해서 저자는 구체적으로는 조작 분야 VLA 선행연구를 따라, random dropout 방식으로 사용 가능한 모달리티 중에서 무엇을 조건부 입력으로 쓸지를 샘플링합니다. 논문에서 t_m으로 부르는 친구가 그 조건부에 해당한다고 보시면 됩니다. 예를 들어 GNM mixture의 샘플이면(GNM 데이터 셋은 데이터가 2D pose, Image goal 둘다 존재), t_m에 따라 목표 조건부 입력이 pose만 될 수도 있고 goal image만 될 수도 있고 pose + goal image 조합이 될 수도 있습니다.
이걸 샘플마다 독립적으로 수행하기 때문에 배치 전체가 자연스럽게 mixed-modality batch가 됩니다. 저자들은 이러한 드롭아웃 메커니즘이 멀티 모달 학습에 이있어서 학습 안정성을 높이고, 모든 모달리티/데이터셋을 폭넓게 커버하게 해준다고 주장합니다.
그리고 만약 t_m 조건부에 의해 안 쓰는 모달리티 같은 경우는 attention에서 제외하도록 합니다. 그냥 랜덤값으로 채운 뒤 attention mask를 통해서 어텐션 과정에서 해당 토큰을 참고하는 일이 없도록 설계합니다. 추론 과정에서도 마찬가지로 자연스럽게 목표 입력에서 해당하는 모달리티가 없다면 마스킹을 통해 입력으로 주어진 모달리티만을 참고해서 액션을 예측하는 방식으로 동작하게 됩니다.
현재 이미지 I_c와 목표 조건부(목표 이미지 I_g, 목표 pose p_g, 언어 l_g), 그리고 샘플링된 모달리티 선택 t_m을 넣어서, N-step action sequence를 예측합니다.
{\hat{a}<em>i}</em>{i=1…N} = \pi_\theta(I_c, I_g, p_g, l_g, t_m)
J_{il}=\frac{1}{N}\sum_{i=1}^{N}(a^{ref}_i-\hat{a}_i)^2
그리고 참조 행동({a^{ref}<em>i}</em>{i=1…N})을 따라가도록 MSE로 학습합니다. 논문에는 짧게 언급되어있지만 손실 함수 형태가 행동 모방 기반 supervised/IL 학습인 것 같습니다. 그리고 여기에 추가적으로 LeLaN 데이터 셋 같은 경우에는 object reaching을 더 잘 하게 하기 위해 추가적인 task-specific objective를 붙였다고 합니다. 자세한 내용은 LeLaN 논문과 해당 논문의 appendix를 살펴보시면 좋을 것 같습니다.
정리하면 데이터는 엄청 크고, 그리고 다양하게 섞어서(13 datasets / 10 embodiments / 9,500h)학습시켰다는 것이고 대신 그만큼 생기는 노이즈/embodiment gap은 합성 행동 + 재어노테이션 모델로 품질을 보정하였다고 보시면 됩니다. 그리고 각각 데이터셋에 따른 모달리티 불균형같은 경우는 데이터를 억지로 맞추는 대신, 학습과정에서 modality dropout + attention mask로 각 샘플에서 사용 가능한(goal) 모달리티들 중에서 독립적으로 선택해서 조건부 t_m (I_g, p_g, l_g 중에서 어떤 친구를 가릴지)을 구성하고, 가려지는 모달리티 토큰은 랜덤값으로 채우고 attention mask로 가려서 모델이 못 보게 하는 방식으로 학습을 진행합니다. 그리고 손실함수는 기본적으로 MSE기반으로 설계가 되어있고 일부 데이터셋(LeLaN)은 목적에 맞춰 task-specific loss를 추가하는 식으로 설계되었다고 보시면 좋을 것 같습니다.
Experiments
일단 실험같은 경우는 시뮬이 아니라 real-world에서 광범위하게 평가했고 다양한 베이스라인 모델들과 비교합니다. 그리고 저자들은 설정한 아래 질문에 초점을 맞춰서 실험을 구성합니다.
Q1 옴니-모달 사전학습(omni-modal pre-training)은 단일 모달리티 내비게이션 정책들보다 성능이 좋은가?
Q2 OmniVLA는 여러 목표 모달리티의 조합(composition) 을 따라갈 수 있는가?
Q3 OmniVLA는 새로운 목표 모달리티, 환경, 그리고 로봇 형태(embodiment)에 적응(adapt) 할 수 있는가?
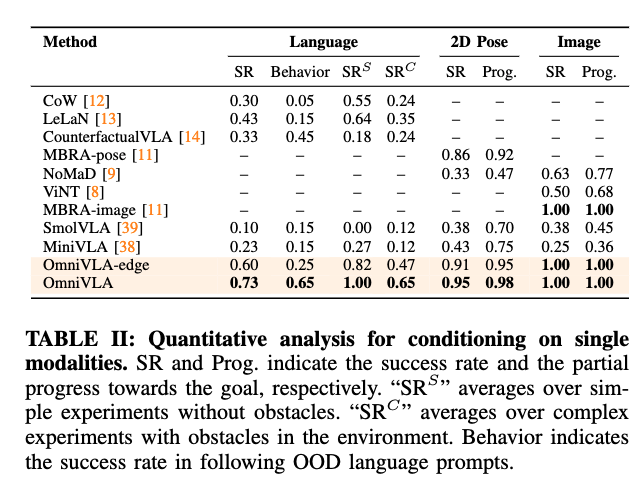
표 II에서 OmniVLA가 모달리티별 specialist 베이스라인(각각 단일 모달리티만을 학습시킨 모델)을 전반적으로 성능을 넘어서는 결과를 보실 수 있습니다. 어떻게 보면 Q1에 대한 답을 보이는 실험표입니다. 여기서 저자는 모달리티별로 쪼개진 데이터셋보다 훨씬 큰 규모의 mixture로 학습했기 때문에, 결국 더 일반화된 내비게이션 능력이 나온다라고 주장합니다. 그리고 단순히 학습 데이터 많아서 이김으로 끝내는 게 아니라, 사전학습된 VLA 백본(아키텍처 선택)과 사전학습 데이터의 성격 자체가 성능에 크게 영향을 준다는 점도 언급합니다.
그리고 추가적으로 해석할 부분은 엣지 모델과의 비교인데 OmniVLA-edge(ViNT 기반, LLM x) 는 애초에 내비게이션에 맞춘 아키텍처라서 모델 크기 대비 성능이 상당히 잘 나온다는 식으로 설명을 합니다. 다만 언어 지시 수행(language )에서는 여전히 큰 OmniVLA와 격차가 남는데, 저자들은 이걸 큰 모델이 사전학습 VLM/LLM으로부터 물려받는 vision-language prior의 이점으로 해석합니다. 또 OOD 프롬프트를 따르는지를 보는 Behavior 지표에서 OmniVLA와 LeLaN가 여기서 둘 다 동일한 도메인의 언어 프롬프트로를 학습했는데,격차가 두드러지는 것을 확인할 수 있습니다. 저자는 OmniVLA가 더 큰 사전학습 LLM/백본을 쓰기 때문에 OOD에 더 유연하다라고 해석합니다. 결국 언어 쪽은 특히 LLM의 힘이 크다라는 것을 보이는 것 같습니다.
그리고 표에는 없지만 NaVILA라는 강화학습기반의 VLN 모델이 있는데 해당 모델이 성공률 0.0으로 실패한 사례또한 언급합니다. 저자들이 언어 조건부 내비게이션은 프롬프트 포맷 자체가 모델의 가정과 맞아야 한다를 보여주는 예시로 들고 온 느낌입니다. NaVILA는 step-by-step 형태의 상세 지시를 요구합니다. 그래서 이 논문이 목표로 하는 open-set 자연어 프롬프트와 도메인 갭이 커서 아예 못 썼다고 합니다.
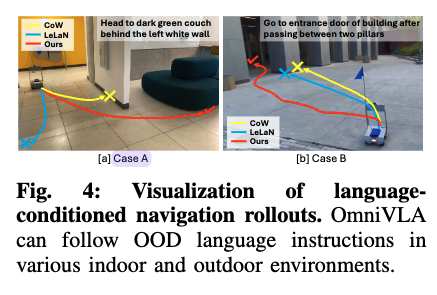
그림 4 같은 경우에는 목표 물체가 초기 위치에서 안 보이는 상황이라서, 정책이 프롬프트 안의 다른 정보들을 잘 활용해야 하고, OmniVLA는 성공했지만 LeLaN/CoW는 잘못된 물체 방향으로 가는 실험 결과를 보여줍니다. 여기서 결국 VLA의 prior의 이점을 보여주는 결과로 해석할 수 있을 것 같습니다.
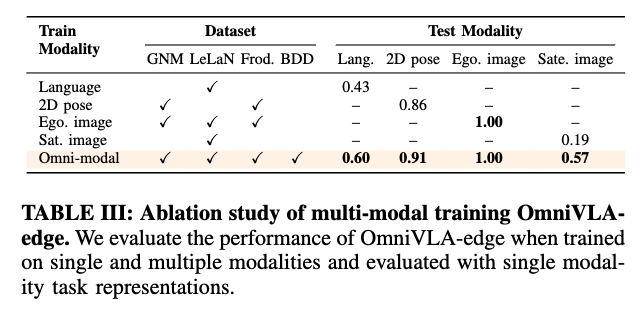
저자는 더 크고 다양한 데이터 mixture의 이점을 보이기 위해 아키텍처는 고정해두고(여기서는 OmniVLA-edge) 학습 데이터 구성만 바꿔서 비교합니다. 구체적으로는 OmniVLA-edge를 여러 버전으로 학습시키되,어떤 버전은 단일 모달리티 데이터만 보고 학습하고 그걸 멀티모달로 joint training한 OmniVLA-edge랑 비교하는 방식입니다.
이 평가에서는 위성 이미지(satellite images)를 새로운 목표 모달리티로 도입하고, 2D 목표 포즈 내비게이션과 동일한 환경 및 설정에서 성능을 평가했다고 합니다.(이 부분은 Q3에서 자세히 다루도록 하겠습니다.) 결과적으로 OmniVLA는 모든 단일 모달리티 성능을 능가하는 결과를 보입니다.
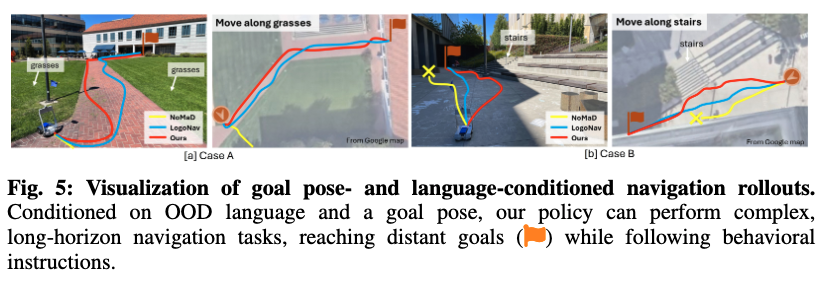
Q2에 답하기 위해서 저자는 10개 서로 다른 환경에서 태스크를 2D 목표 포즈와 행동을 지시하는 언어 명령 을 함께 제공하는 방식으로 지정하는 실험을 수행했다고 합니다. 각 환경에서 저자는 로봇의 초기 위치로부터 25–100m 떨어진 2D 위치를 제공하고, 동시에 로봇이 그 목표에 도달하기 위해 반드시 따라야 하는 행동을 명시하는 언어 프롬프트(예를 들어 “벽을 따라 이동하라”, “잔디 위로 이동하라”, “물체 A와 B 사이로 이동하라”)를 함께 제공하는 식으로 세팅하며, 이러한 프롬프트는 학습 데이터셋에는 포함되어 있지 않다고 합니다.
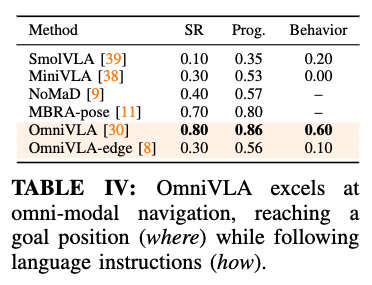
저자들은 이런 모달리티 조합을 연구한 사례가 없다고 합니다. 그래서 기존의 많은 방법들은 애초에 두 모달을 동시에 입력으로 받는 구조가 아니어서, 비교 대상도 어쩔 수 없이 2D포즈 조건부로 학습된 specialist(NoMaD, MBRA-pose)쪽으로 평가를 했다고 합니다. 근데 Table 2의 결과랑 달라서 따로 추가적인 실험을 했는지 해당 결과를 어떻게 봐야할지 헷갈리네요. 그리고 또 table 2 대비 behavior 성능도 5% 만 하락하였다고 합니다. 둘의 성능이 오르는 결과를 보여줬어야한다고 생각하지만 해당 부분에 대한 저자의 언급은 따로 없습니다.
그리고 마지막으로 Q3 네비게이션을 위한 파운데이션 모델로서의 역량 검증에 답하기 위해서 저자는 아래와 같은 3가지 측면을 평가합니다.
- 새 목표 모달리티 학습
- 새 데이터셋/새 환경 파인튜닝
- 새 로봇 embodiment로 확장
먼저 1번에 대해서 위성 모달리티 없이 pretrained 된 OmniVLA-edge의
모델 대부분은 freeze하고 egocentric goal image 인코더를 위성 이미지 인코더로 교체한 뒤
교체한 인코더만 새로운 모달리티에 대해서 학습합니다. 결과적으로 table 3에서 위성 목표 내비게이션만을 위해 학습된 specialist 정책 대비 성능이 크게 향상되었음을 보입니다. 이는 기존 정책이 쌓아놓은 내비게이션 affordance/표현은 유지하면서, 새 모달리티만 얹을 수 있다라는 것을 보여주는 것 같습니다.
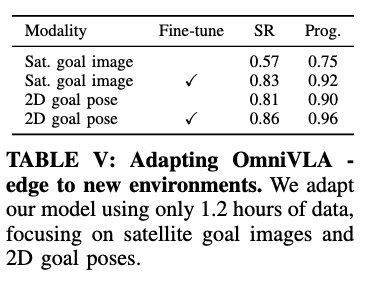
새 데이터셋, 새 환경에 대한 파인튜닝 같은 경우에는 두가지 시나리오로 나눠서 평가합니다.
(a) 시나리오 같은 경우 훈련에서 보지 못한 환경에서 2D pose + 위성 이미지 포함 1.2시간 데이터를 모아서 OmniVLA-edge를 파인튜닝하여 평가 한 결과 표 V를 보면 두 모달리티 모두 성능이 오르는 것을 확인할 수 있습니다.
(b)는 CounterfactualVLA 데이터셋으로 언어 도메인을 확장하는 케이스인데, 여기서 저자들은 파인튜닝 안정화를 위해 기존 모달리티 균형을 유지하려고, 파인튜닝 할 때 LeLaN에서 뽑던 데이터의 절반을CounterfactualVLA로 대체하는 식으로 배치를 구성해서 학습했다고 합니다.
결과는 표로 제공하지는 않고 논문에 간단하게 언급하고 넘어갔는데 아래와 같은 결과를 보였다고 합니다.
(SR, Behavior, SR^S, SR^C) = (0.825, 0.700, 1.000, 0.765)
를 달성하여, 원래 점수 (0.725, 0.650, 1.000, 0.647)대비 향상됨.

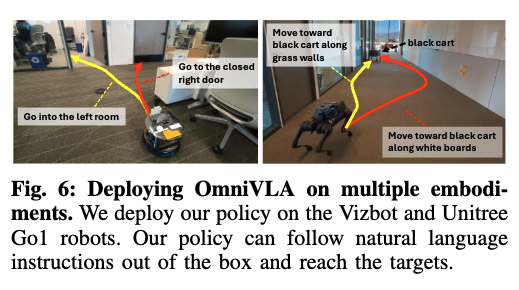
마지막은 cross-embodiment generalization을 실제로 보여주는 데모성 실험입니다. 그림 6 같은 경우는 바퀴형 VizBot, 4족 Go1에 서로 다른 카메라를 달고, 언어 조건부 내비게이션에서 테스트했을 때 OmniVLA가 지시를 따르고 목표에 도달하는 결과입니다.
결과적으로 해당 연구는 하나의 통합된 프레임워크 내에서 언어 프롬프트, 2D Pose, egocentric Image 와 같은 각 모달리티의 조합을 포함한 다양한 목표 모달리티에 대해서 유연하게 동작할 수 있는 진행했다는 점에서 되게 새롭고 흥미롭게 논문을 읽었던 것 같은데, 아쉬운점은 물론 한계가 있었겠지만 다양한 모달리티 조합 실험이 부족하거나, 특정 모달리티에서만 평가하는 것과 같은 아쉬운점은 조금 있는 것 같습니다. 해당 논문이 학회에 게재가 되면 게재된 버전으로 한번 다시 읽어보면 좋을 것 같습니다.
이만 리뷰 마치도록 하겠습니다. 감사합니다.
리뷰 잘 읽었습니다 우현님.
fig 2 전체 architecture 에서 action head 를 통해 출력으로 나오는 N 길이의 action sequence 는 어떤 포맷(?) 인가요? nomad 처럼 좌표값을 예측하는 느낌으로 이해하면 될까요?
그리고 각 모달이 동일 embedding token space 로 보내지는 과정이 되게 중요해보이는데,, 코드단에서 파악하신 후에 저에게도 공유해주시면 좋을 거 같습니다 ㅎ
(+ 이 OmniVLA 모델을 저희가 진행하게될 XLeRobot 플젝에 적용하는 것에 대해선 어떻게 생각하시나요? 이미 그쪽으로 생각중이실까요?)
안녕하세요 석준님 댓글 감사합니다.
저도 이 액션 시퀀스 값의 형태에 대해서 궁금했었는데, 논문에서는 명시적으로 언급하지는 않았지만 openVLA-edge에서 ViNT 모델을 쓴다는 점에서, 또 NoMaD에서 사용한 GNM을 포함하여 데이터 셋을 구성했다는 점에서 NoMaD와 같이 N step 짜리의 어떤 상대 좌표 값을 예측하는 waypoints 값이지 않을까 조심스럽게 생각이 드네요.. 하하 이것도 마찬가지로 추후에 코드단에서 파악하고 알려드리도록 하겠습니다.
NoMaD가 할 수 없는 어떤 object reaching을 할 수 있다는 점이나 또 야외 장거리 이동에 있어서 2D Pose를 사용할 수 있다는 점, 그리고 이 부분은 실제 로봇에 돌려봐야알겠지만 NoMaD보다 심지어 edge 모델 또한 성능을 능가한다는 점에서 충분히 적용해 볼만하고 아마도 다음 스텝으로 적용해보지 않을까 싶습니다!
물론 아직 해당 프로젝트가 실제 로봇에 배포할 수 있는 소스 코드는 제공하지 않았습니다만, 액션 시퀀스의 형태만 알면 NoMaD의 소스코드 참고해서 실제로 연구실에 있는 모바일 플랫폼에 적용시킬 수 있지 않을까 생각이듭니다.(물론 많은 시행착오가 있겠지만요..) 하하
안녕하세요 우현님 리뷰 잘 읽었습니다.
특정 단일 모달리티에 묶이지 않고 상황에 따라 여러 목표 모달리티( 언어, 포즈, 이미지 등) 를 유연하게 활용하면서 내비게이션을 수행하는 방향을 제안하는게 좀 흥미롭고 어렴풋이 생각해도 이 분야에는 저자가 말하는것 처럼 유연하게 활용하는게 맞다고 생각이 듭니다. 그래서 데이터셋들의 여러 모달리티들의 token 값을 하나의 공간으로 projection해서 같이 학습하는 것 같습니다. 근데 만약 데이터셋에 비전 정보랑프롬프트 데이터셋 만 있는경우 다른 정보들은 어떻게 처리하나요 ? 조건부로 유연하게 학습하려고하는거 같은데 다른 정보들은 결국 안들어가는건가요? 그 부분은 그냥 여러데이터셋을 학습에 사용하면서 조건에 맞게 액션값들을 내는게 핵심인건가요 ?
안녕하세요 우진님 댓글 감사합니다.
리뷰에서 말씀드렸다 싶이 예를들어 어떤 샘플이 현재 이미지 + 언어 프롬프트만 있고 2D 포즈/goal image가 없다면, 그 모달리티에 해당하는 토큰 슬롯은 그냥 채워두되 attention mask로 완전히 가려서 모델이 그 토큰을 보지 못하게 처리합니다. 그래서 결과적으로 그 샘플은 비전+언어 조건으로 정책이 학습됩니다. 반대로, 포즈만 있는 데이터면 포즈 토큰만 열어주고 나머지는 가리는 식으로 동작합니다.
그리고 말씀하신 것처럼 조건부로 유연하게 학습하려는 게 맞나? 에 대해서는 여기서 더 중요한 게 modality dropout입니다. 단순히 없는 건 안 넣는다라는게 아니라 있는 모달리티도 학습 중에는 일부러 랜덤하게 드롭해서 모델이 특정 모달리티 하나에만 과하게 의존하지 않도록 만드는게 핵심이라고 보시면됩니다. 결국 모델은 주어진 목표 신호가 무엇이든(또는 일부만 주어져도) 동일한 action head로 일관되게 행동을 내는 방향으로 학습된다고 이해하시면 됩니다.
마지막에 말씀주신것처럼 그럼 핵심이 여러 데이터셋 섞어서 조건 맞게 액션을 내는가 라는 관점도 맞는데, 다양한 데이터셋을 섞어 일반화되는 내비게이션 능력을 얻는 것, goal 표현이 다르더라도(언어/포즈/이미지) 같은 정책/같은 action space로 매핑되도록 학습해서, 테스트 때도 여러 모달리티를 조합해 쓸 수 있게 만드는 것 이 두가지가 핵심이다 라고 이해하심 좋을 것 같습니다. 감사합니다.