안녕하세요, 이번주는 3d object flow라는 개념을 활용한 open-world manipulation 연구를 리뷰해보려고 합니다. 최근 비디오 모델들의 물리적인, 시각적인 표현력이 급증하면서 manipulation 영상을 자연스럽게 생성할 수 있게 되었고, 비디오 모델의 능력을 manipulation이 가능하도록 실제 로봇 제어와 bridging 하는 연구라고 보면 될 것 같습니다.
Introduction
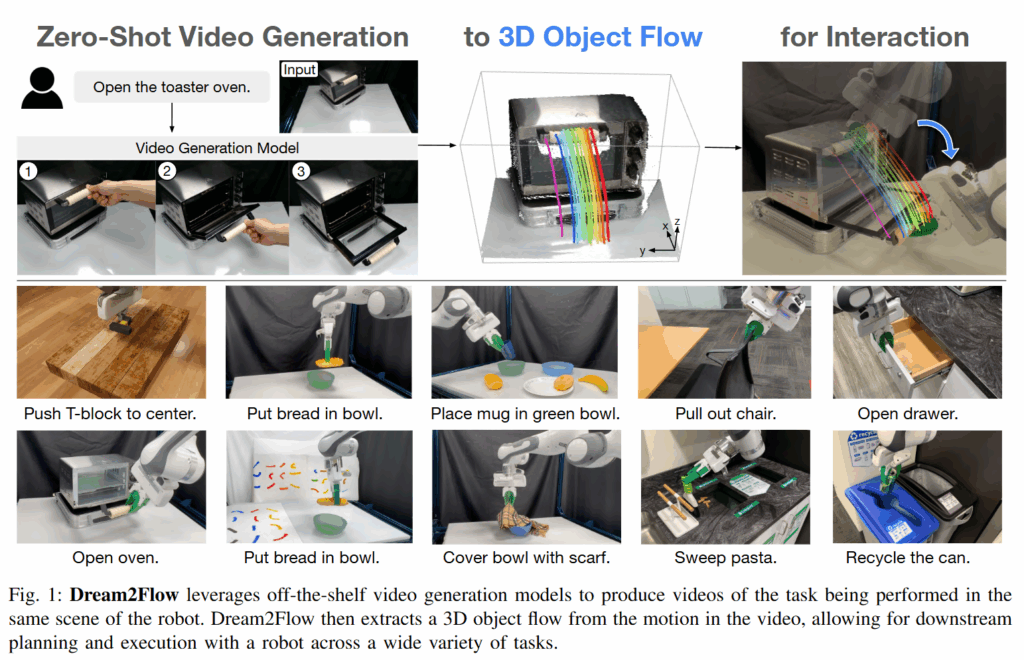
Dream2Flow는 생성 비디오 모델과 로봇 조작 사이의 간극을 메우기 위해 제안된 새로운 프레임워크입니다. 최근 비디오 모델링 기술의 발전으로, 주어진 초기 이미지와 자연어 instruction 만으로 현실감 있는 상호작용 영상을 제로샷으로 생성할 수 있게 되었습니다. 이러한 영상 생성 모델은 사람 손으로 물체를 다루는 풍부한 물리 상식과 상호작용 경험을 학습하고 있어, 로봇이 처음 보는 환경에서 새로운 작업을 수행할 때 직관적인 가이드로 활용할 수 있는 수준입니;다. 그러나 이때 embodiment gap 문제가 발생합니다. 비디오 모델이나 사람이 수행하는 동작과 실제 로봇이 수행해야 하는 동작 사이에는 불일치가 존재하여, 비디오 모델의 예측만으로 로봇을 바로 제어하기는 어렵습니다. 영상 속의 사람 손 동작을 로봇의 관절 명령으로 변환하는 과정에서, 로봇과 사람의 형태적 차이, 동역학 및 작동 범위 차이 등이 걸림돌이 됩니다.
저자들은 이러한 문제를 해결하기 위해 intermediate representation으로 3D object flow를 도입했습니다. 3D object flow는 비디오 모델이 예측한 객체의 움직임을 3D 공간상의 궤적으로 표현한 것입니다. 이렇게 객체 중심으로 표현했을 때는 어떤 객체가 어떻게 움직여야 하는지 embodiment-agnostic하다는 특징이 있습니다. 핵심 아이디어는 “무엇을 해야 하는가(객체의 움직임)”와 “어떻게 실행하는가(특정 로봇의 제어)”를 완전히 분리함으로써, 사람 중심으로 훈련된 비디오 모델의 예측을 로봇으로 연결하는 것이라고 보면 될 것 같습니다. 먼저 영상 생성 모델로 작업 장면의 미래 영상을 합성하고, 그 영상에서 객체의 3D 궤적을 추출하여 로봇의 좌표계에 정렬합니다. 이렇게 얻은 3D 객체 움직임의 변화를 추적하는 방향으로 로봇이 움직입니. 물체 중심으로 얻은 정보를 별개의 모듈을 통해 로봇이 따라가면서 행동하다보니 새로운 작업이나 로봇에 대해 작업별 시연 데이터나 추가 학습 없이 바로 적용 가능하다는 장점이 있습니다. 이를 통해 비디오 모델이 예측한 결과를 직접 제어 명령으로 바꿀 수 있게 비디오 모델의 상상력을 연결해준 범용 인터페이스로서 향후 로봇이 open world에서 manipulation을 진행하는데 있어서 중요한 작업을 했다고 주장합니다.
Methods
Dream2Flow의 방법론은 아래와 같이 비디오 생성, 3D object flow 추출, 로봇 policy 생성으로 구성됩니다. 딱히 복잡한 내용은 없습니다.
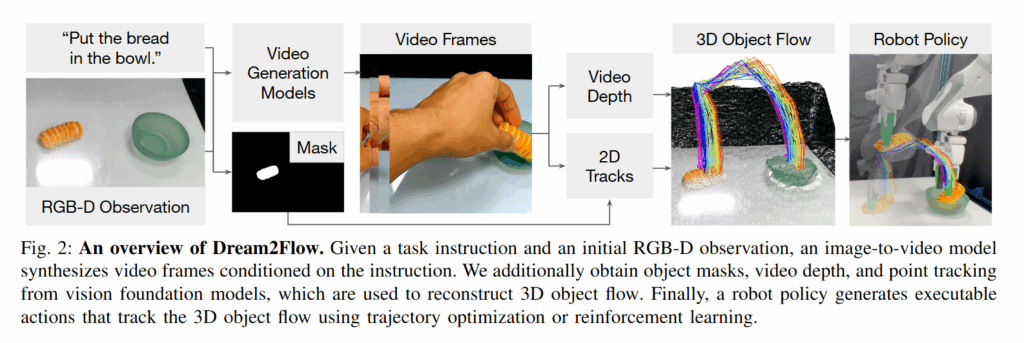
Video Generation

비디오 생성에는 Wan2.1, Kling 2.1, Veo 3와 같은 text conditioned image to video 모델들을 활용했다고 합니다. 이러한 모델들은 인터넷 영상으로 학습되어 인간이 물체를 다루는 물리적 상식이 내재되어 있기 때문에 활용했고, 오픈소스 모델들 보다는 veo 3가 성능이 좋다고 합니다. 점점 성능 좋은 모델들은 로컬에서 돌리기도 힘들고 애초에 오픈소스로 공개가 안 되는 것 같습니다. 비디오 모델의 입력으로는 로봇 작업 환경의 RGB-D 이미지와 text instruction이 들어갑니다. “Put the bread in the bowl”과 같이 작업을 한 문장으로 지시하며, 카메라는 정지한다와 같은 프롬프트를 추가하여 카메라 고정 및 부드러운 동작을 유도한다고 합니다. 또 이때 저자들은 로봇의 모습을 프롬프트나 초기 프레임에 포함하지 않는 것이 영상을 더 그럴듯하게 만드는 데 중요하다고 하빈다. 어찌보면 로봇이 작업하는 영상은 많이 학습을 안 했을테니 당연한 결과인 것 같습니다. fast motion, morphing, camera motion과 같은 negative prompt를 사용하여 객체의 급격한 왜곡이나 카메라 움직임 등을 억제하기도 했다고 합니다.
Extracting 3D object flows from videos
간단하게 요약하자면 영상 생성 모델의 출력을 객체가 masking된 depth 추적을 통해 객체 중심의 3D 경로로 변환하는 것입니다. 우선 각 비디오 프레임에 대해 Spatial TrackerV2 모델을 사용해 per-frame depth estimation을 수행하여 video의 depth를 얻습니다. 이때 현실의 depth와 정합하도록 스케일을 보정해준다고 합니다. 다음으로 Grounding DINO 모델을 이용해 비디오 모델의 input으로 들어간 목표 객체의 segmentation mask를 얻어냅니다. 이어서 CoTracker3 모델을 활용하여 비디오 전체에 걸쳐 객체 표면의 2D 특징 점들을 추적합니다. CoTracker3은 영상 속 점들의 가시성 여부까지 출력하기 때문에, 중간에 가려지거나 사라지는 경우도 감지할 수 있다고 합니다. 마지막으로, 추적된 2D 점들을 각 프레임의 depth 정보와 카메라 intrinsic을 이용해 3D로 lifting합니다. 이렇게 하면 비디오에서 포착된 객체의 움직임이 시간 t에 따른 3D point들의 형태로 얻어지며, 이걸 3d object flow라고 정의합니다. 3d object flow는 로봇 기준 좌표계로 정규화되어 있으므로, 이후 planner와 controller가 해석할 수 있는 궤적으로 사용할 수 있게 됩니다.
Action Inference with 3D Object Flow
추출된 3D 객체 흐름을 실제 로봇이 따라가도록 만들기 위해, 저자들은 두 가지 전략을 상황에 따라 사용했습니다. 먼저 push T task에서는 open-loop 방식으로 물체를 직접 밀거나 미는형태의 조작에서 particle-based dynamics model과 random-shooting 플래너를 사용했습니다. Point Transformer 기반의 particle dynamics model을 사용하여 현재 물체 입자들의 상태와 가상 push 행동 파라미터를 입력 받아 다음 시점에서 입자들의 위치 변화를 출력합니다. 그런 다음 플래너가 여러 개의 푸쉬 후보를 시뮬레이션하여, 입자 모델이 예측한 결과로부터 목표 객체 흐름과의 오차를 계산합니다. 이 중 객체가 목표 궤적에 가장 잘 수렴하도록 만드는 행동을 선택하여 로봇의 다음 푸쉬 동작으로 실행했다고 합니다. 이러한 랜덤 슈팅 방식의 최적화는 객체의 회전도 입자들의 움직임으로 표현해 단순한 강체 모델보다 정확하게 물체의 연속적인 이동을 할 수 있었다고 합니다.
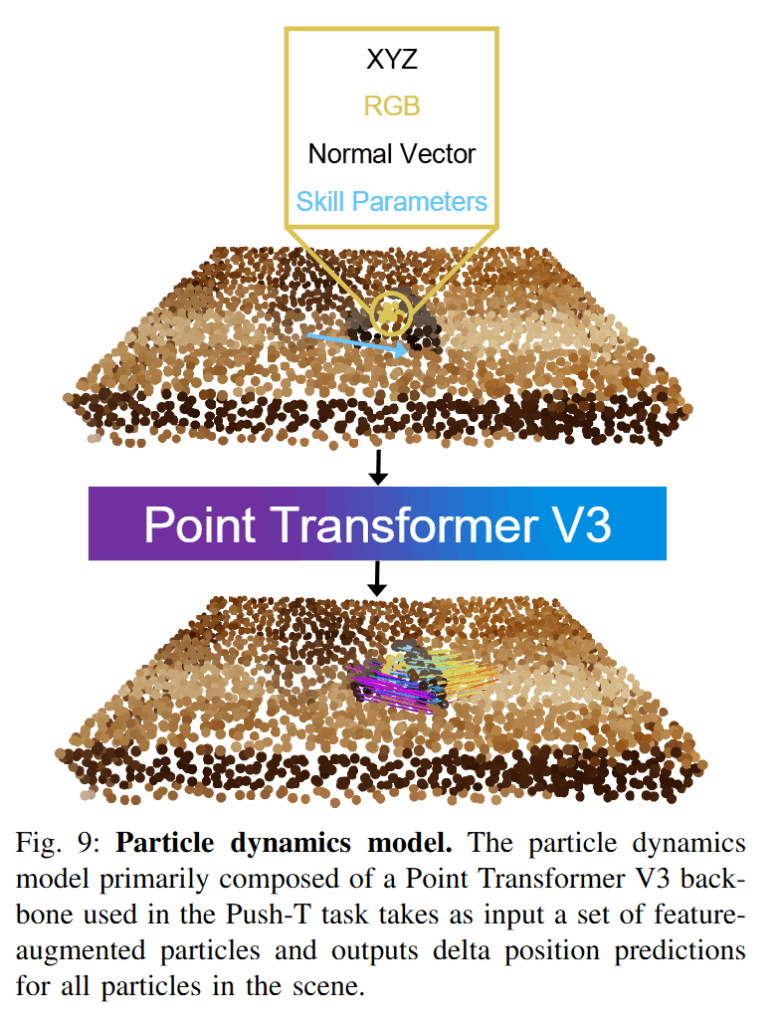
Push T 환경이 아닌 일반적인 grasping을 통해 작업을 수행할 때는 영상으로부터 추출된 3D object flow 중에서 실제로 움직이는 부분만 식별하기 위해 SAM 모델에 positive prompt(움직이는 부분)와 negative prompt(고정된 부분)를 주어 움직이는 영역의 마스크만 남기고 추적하는 기법을 사용했다고 합니다. 파지를 위해서는 AnyGrasp를 활용하여 grasping 후보들을 생성한 뒤, 생성된 영상에서 사람 손의 엄지 위치를 HaMer 모델을 기반으로 추론해 인간이 잡은 부분(엄지)과 가장 가까운 grasping pose를 사용했다고 합니다. 이렇게 하면 영상 속 상호작용에서 사람이 물체를 잡은 부분을 로봇도 동일하게 잡도록 유도해, 비디오 모델 (사람)이 의도한대로 행동할 수 있다고 합니다. 로봇이 물체를 집고 난 이후에는 PyRoki를 사용한 최적화 루프를 통해 객체의 흐름을 추적하며 움직였다고 합니다.

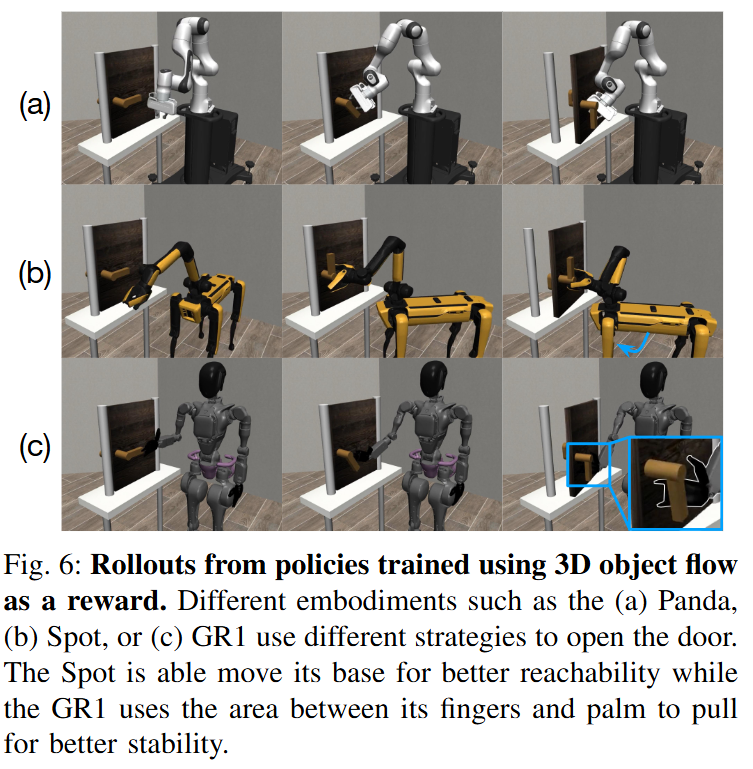
추가로 저자들은 강화학습과도 연계해, 문 열기와 같은 작업의 경우, 3d object flow를 reward로 하는 강화학습을 진행했다고 합니다. 시뮬레이터를 동역학 모델로 활용하여 SAC 알고리즘으로 policy를 학습시켰다고 합니다. 이러한 강화학습 기반의 방법은 객체 흐름을 embodiment 종류와 상관없이 따라갈 수 있도록 Franka, Boston Dynamics Spot, Fourier GR1 휴머노이드 등에서 학습할 수 있었다고 합니다. Flow를 따라감에 있어서 어찌보면 당연한 말이지만 Spot은 베이스를 움직일 수 있는 이점을 지니고, 휴머노이드는 손가락을 문고리에 끼워넣을 수 있는 이점을 지녔다고 합니다. 결국 비디오 생성 모델에서 현실과 정렬된 pointcloud를 추적하고, 이런 3d object flow를 어떻게 로봇의 행동으 연결시킬거냐?에 대한 구체적인 방법론들이 제시됐다고 보면 될 것 같스빈다.
Experiments
실험은 아래 사진과 같이 push T, put bread in bowl, open oven, cover bown, open door의 task로 진행했습니다. Initial States에서 반투명한 물체들이 겹쳐보이는 것은 다양한 initial state로 진행했다고 보시면 됩니다.

Properties of 3D Object Flow as a Video-Control Interface
먼저 일반화에 대한 실험이 진행됐습니다. Reference Setting에서 Dream2flow를 돌리고 나서, 각각 다른 변화들을 준 채로 성공률을 측정했을 때, object instance를 변화시킨 경우 빵이 더 길어진 경우에는 40% 감소가 있었지만 동그란 빵을 사용했을 때는 오히려 높아진 성능을 확인할 수 있었고, background나 view angle에 대해서도 꽤 강건한 결과를 얻을 수 있었다고 합니다.

다음은 실패 케이스에 대한 결과입니다. 다양한 작업에서 총 60번의 trial을 진행했을 때, 20번의 실패가 있었는데 대부분은 video 생성이 완전하지 않기 때문이라고 합니다. Object morphing이나 hallucination인 비디오 생성 모델의 전형적인 문제는 당연하지만 병목으로 존재하는 것 같습니다.


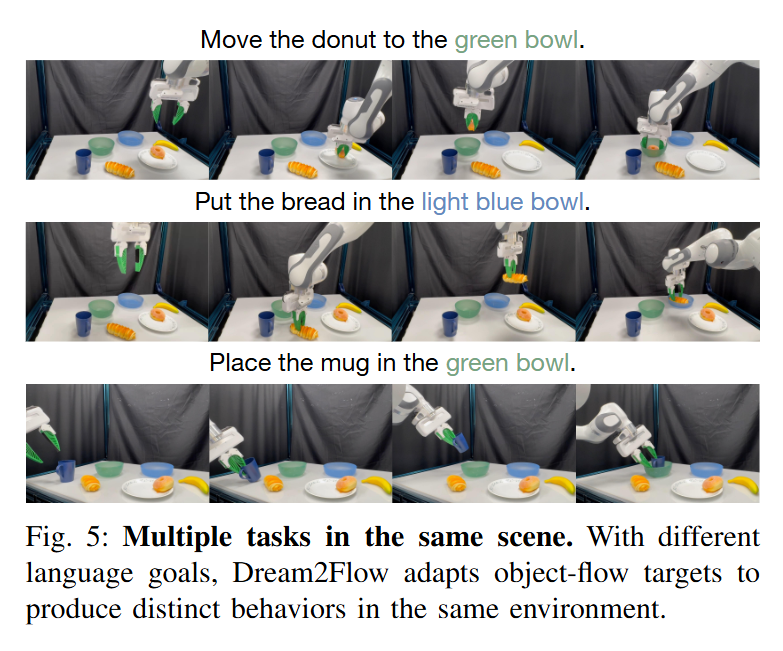
하나의 scene에서 얼마나 다양한 task를 수행할 수 있는지, task grounding은 잘 되는지에 대한 실험입니다. Video generation model이 text condition을 잘 입력받는 만큼 하나의 scene에서도 다양한 task를 성공적으로 수행할 수 있었다고 합니다.
How does Dream2Flow perform compared to alternative interfaces?
해당 실험에서는 3D Object Flow 인터페이스를 기존의 비디오 기반 객체 궤적 추출 방식들과 비교하여, 실제 로봇 조작에서의 성능을 비교했습니다. 비교 대상으로는 AVDC와 RIGVID 두 가지 방법을 사용하고, 결과는 아래 Table1고 ㅏ같습니다. Bread in bowl, open oven, cover bowl task에서 각각 10회씩 진행했고, AVDC는 생성된 비디오 프레임 간의 옵티컬 플로우를 계산해 객체의 2D 점 대응을 얻고 변환 시퀀스를 추정함으로써 파지 이후의 객체 궤적을 따라가는 방식입니다. RIGVID는 video depth를 통해 조작 대상 객체의 6D pose estimation을 추적하며 궤적을 생성하는 방법이지만, deformable (bread, cloth)에는 6D pose 정의가 불가능하기 때문에, 본 실험에서는 AVDC와 유사하게 3D point 사이의 강체 변환을 추정하는 방식으로 변형하여 평가하였다고 합니다.
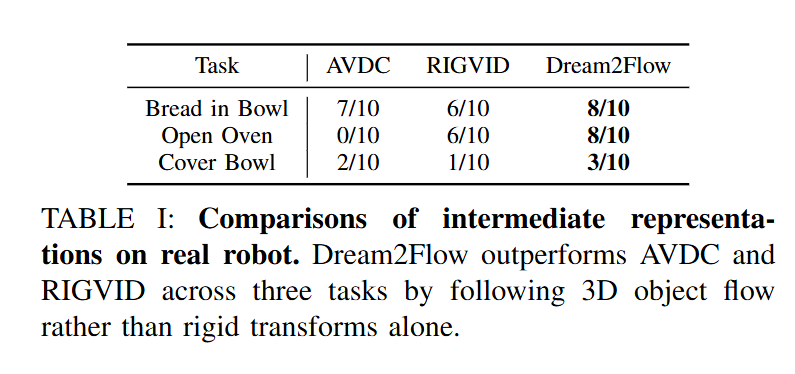
두 방법 모두 특정 상황에서는 가시적인 point의 수가 매우 적어져 변환 추정이 noise에 취약해지고, 이로 인해 로봇 실행 단계에서 불안정한 최적화 또는 실패로 이어지는 문제가 관찰되었습다고 합니다. 반면 Dream2Flow는 일부 점이 가려지거나 추적에 실패하더라도 나머지 점들을 통해 end effector 궤적을 유지할 수 있었으며, 이로 인해 실행 안정성이 상대적으로 높았다고 합니다. 특히 Cover Bowl과 같은 deformable 조작에서는 AVDC와 RIGVID 모두 강체 변환이라는 가정이 붕괴되어 거의 실패한 반면, Dream2Flow는 비교적 강건한 성능을 보였다고 합니다.
How does the choice of video model affect Dream2Flow in simulation and in real-world tasks?

사용된 비디오 모델들에 대한 비교도 진행되었는데, Veo 3의 경우 input state와 goal state를 모두 이미지로 입력받지 못하기 때문에 평가에서 제외했고, Wan2.1과 Kling 2.1의 경우 각각 Push-T와 Open Oven에서 서로 다른 강점을 보였다고 합니다. Kling에서 substantial morphing이 더 많았다고 합니다. Open oven의 경우 Wan 2.1은 일관된 camera view를 유지하는데 실패했다고 하네요. 카메라 시점 고정이나 articulation의 표현 등 physically plausable한 모습은 Veo 3가 훨씬 좋았다고 합니다.
Conclusion
Video Generation 모델들의 능력을 로봇까지 끌고와서 open world에서 RGB-D와 text 만으로 작업 수행이 가능하게 만든 것에서 어찌보면 end to end 모델과 추구하는 방향은 다르지만 더 나아가서 다양한 학습 데이터를 모으는 용도로도 발전될 수 있을것 같다는 것과 이 연구 뿐만 아니라 여러 연구들에서 다양한 vision model들을 결합해 원하는 데이터를 정제하는 것을 보고 적극적으로 활용해야겠다 느꼈습니다. 다만 영상 하나를 생성하는데 3분~11분이 걸린다고 하는데, 이러한 점은 사실 병목중에 하나가 아닌가 싶습니다. 뿐만 아니라 human hand의 작업을 기준으로 영상을 생성하기 때문에 구도상 사람 손에 객체가 많이 가려지는 경우엔 아쉽지 않을까 싶습니다. 또 비디오에서 의미있는 3d 정보를 추출할 때 3d object flow 대신 다른 4D reconstruction이나 trajectory field를 통한 접근은 어떨까 싶기도 합니다.
영규님 좋은 리뷰 감사합니다.
Task에 대한 final state를 보면 Open Door는 로봇이 모두 보이는 등 조금 더 scene level의 이미지인 것 같습니다. 인트로에는 object-level로 표현함으로써 embodiment-agnostic하도록 한 것으로 이해하였는데, 단순히 정성적으로 보여주기 위한 결과인것인가요?
또한, video generation 과정에서 작업을 한 문장으로 지시하고, 카메라는 정지한다는 프롬프트를 추가하여 카메라 고정 및 부드러운 동작을 유도한다고 하셨는데, 어떤 이유로 부드러운 동작이 가능한 지 잘 이해가 되지 않습니다. 혹시 설명해주실 수 있나요? 그리고 생성된 이미지에는 로봇 팔이 같이 보이는 지 궁금합니다.