오늘은 현재 제가 진행중인 실험과 관련이 있는, LiDAR-Camera Place Recognition과 관련된 논문 리뷰를 작성하고자 합니다. 컨셉적으로 많이 참신한 논문은 아닙니다만, 관련성 측면에서 정리해볼 겸 가져왔습니다. 바로 리뷰 시작하겠습니다.
1. Introduction
자율주행에서 Place Recognition은 GPS가 동작하지 않는 환경에서 루프 클로저(Loop Closure)를 수행하기 위한 핵심 단계입니다. 카메라는 풍부한 텍스처 정보를 제공하지만 조명이나 날씨에 취약하고, LiDAR는 구조적 정보는 정확하지만 텍스처가 부족하고 포인트 클라우드가 희소하다는 단점이 있습니다.
그래서 요즘은 이 둘을 합치는 Multi-modal fusion 연구가 활발한데요,저자는 기존 방식들이 “LiDAR는 360도 전방위를 보는데, 카메라는 제한된 FOV(Field of View)만 사용한다” 는 불균형(Imbalance) 문제를 지적합니다. 이로 인해 모달리티 간의 불균형이 발생하고, 차량의 진행 방향이 바뀌거나 viewpoint가 달라졌을 때 퓨전 효율이 급격히 떨어진다는 것이죠. 즉, “LiDAR는 뒤를 보고 있는데 카메라는 앞만 보고 있으면 매칭이 제대로 되겠냐?” 라는 게 저자의 핵심 주장인 것 같습니다.
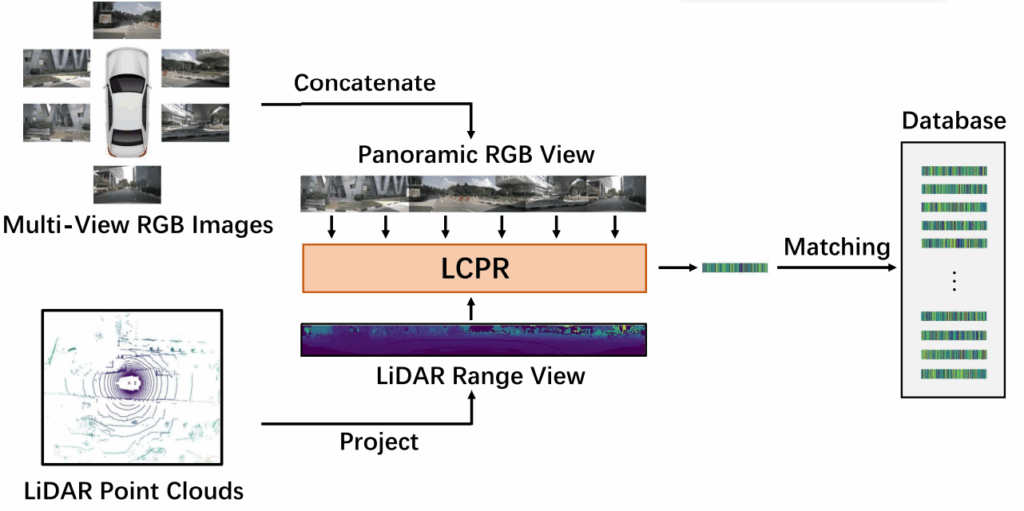
이에 저자는 Multi-view camera 이미지를 전부 엮어서 Panoramic view를 만들고, 이를 LiDAR와 결합하는 LCPR 네트워크를 제안합니다. 특히 여기서 주목할 점은 Vertically Compressed Transformer Fusion (VCTF) 모듈입니다. 도시 환경에서는 수직(Height) 정보보다 수평(Width) 정보가 중요하기 때문에, 수직 방향으로 feature 를 압축해서 연산량을 줄이면서도 Global Context를 잡겠다는 전략입니다. 대략적인 흐름도는 아래와 같으며, 자세한 사항은 method 에서 설명 진행하겠습니다.
2. Method
본 논문은 기존 Multi-modal PR 모델들이 가지는 FOV 불균형과 Viewpoint 변화(특히 yaw rotation)에 취약하다는 한계를 극복하고자 합니다.
2.1. Problem Definition & Architecture
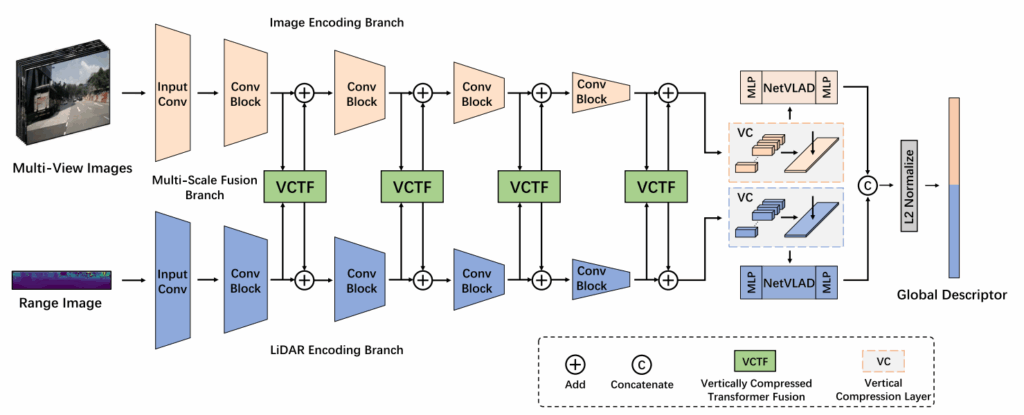
전체 모델 구조는 위 그림과 같으며, 크게 Image Encoding (IE) Branch와 LiDAR Encoding (LE) Branch 두 개의 스트림으로 나뉩니다. 입력으로는 360도를 커버하는 Multi-view RGB 이미지들과, LiDAR Point Cloud를 투영한 Range Image를 사용하며, 중간중간 두 모달리티간의 feature 를 VCTF 모듈에서 퓨전해주는 구조입니다.
2.2. Vertically Compressed Transformer Fusion (VCTF)
이 논문의 핵심인 VCTF 모듈이며, 구조는 위 그림과 같습니다. 저자는 Transformer의 Self-attention을 쓰고 싶은데, 그냥 쓰면 연산량이 너무 많으니 “수직 압축(Vertical Compression)” 이라는 아이디어를 도입합니다. 동작 방식에 대한 설명은 아래와 같습니다.

- Panoramic View 생성: 여러 장의 카메라 이미지를 width 방향으로 이어 붙여서 파노라마 feature map 을 만듭니다.
- Vertical Compression (VC): CNN과 MaxPool을 이용해 Image와 LiDAR feature map 의 높이(H) 차원을 1로 압축합니다. 결과적으로 feature map은 가로로 긴 구조가 됩니다.
- Multi-Head Self-Attention (MHSA): 압축된 Image feature와 LiDAR feature를 가로(Width) 방향으로 concat 한 뒤, 이를 하나의 시퀀스로 보고 self-attention을 수행합니다. 이를 통해 이미지의 특정 영역과 LiDAR의 특정 영역 간의 상관관계를 학습하게 됩니다.
- Expand & Add: attention이 끝난 feature는 다시 원래 높이(H)만큼 복제된 후에 원본 feature에 더해집니다.
저자는 도시 환경에서 높이 정보보다는 주변 배치의 순서(수평 정보)가 훨씬 중요하기 때문에 수직 정보를 압축해도 괜찮다고 주장합니다.
2.3. Yaw-Rotation Invariance
PR(Place Recognition)에서 중요한 것 중 하나가 회전 불변성인데, 저자는 VCTF 모듈이 Yaw-rotation equivariant 하다는 것을 수식적으로 증명하려 노력했습니다.
핵심 논리는, 차량이 회전하면 이미지나 LiDAR Range Image 상에서는 픽셀들이 가로축으로 이동하게 되는데, VCTF 내의 VC layer와 MHSA 모듈이 이러한 Column shift를 그대로 보존한다는 것입니다.
결과적으로 최종단인 NetVLAD에 들어가기 전까지 회전 정보가 잘 유지되다가, NetVLAD가 이를 받아들이면 회전에 강인한 묘사가 가능하다고 주장하고 있스빈다.
3. Experiments
3.1. Place Recognition Performance
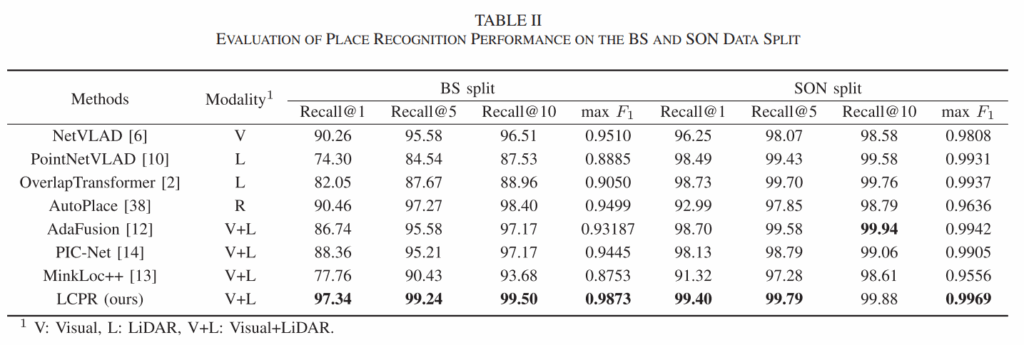
저자는 nuScenes 데이터셋에서 실험을 진행했습니다. 위 표를 보면, LCPR이 기존 SOTA인 MinkLoc++, PIC-Net, AdaFusion 등을 모두 제치고 Recall@1 성능 97.34% (BS split)를 달성했습니다. 데이터셋이 꽤 복잡한 도심 환경임에도 불구하고 성능이 잘 나오는 것을 확인할 수 있습니다. 또한, 당연한 말이긴 하겠지만 single-modality인 Overlap Transformer나 NetVLAD보다 월등히 높습니다.
3.2. Ablation Study
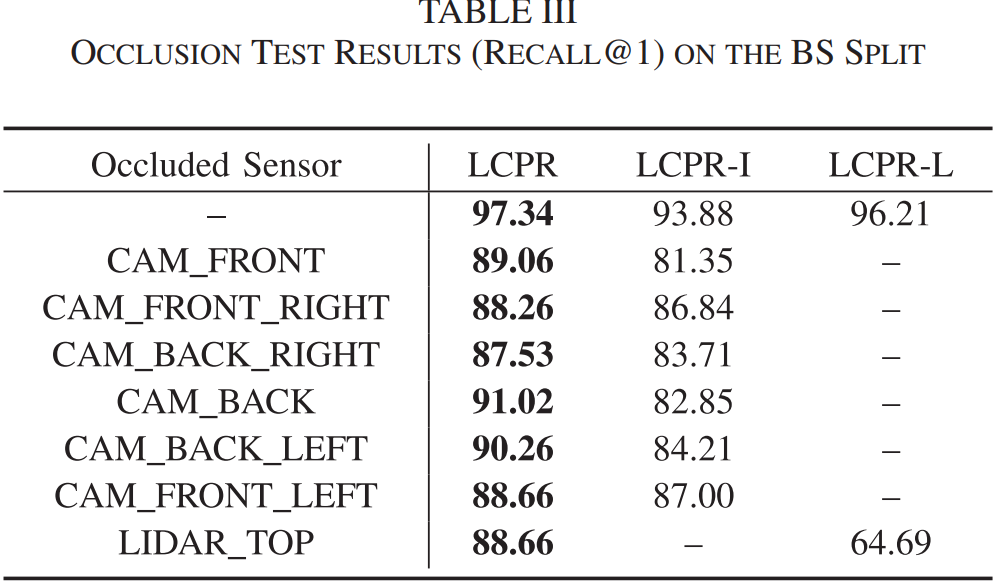
또한 저자는 위 표를 통해 센서를 하나씩 occlusion 시켰을때의 recall 성능을 리포팅합니다.
위 표의 첫 번째 행을 보면 Image만 썼을 때(LCPR-I)는 93.88%, LiDAR만 썼을 때(LCPR-L)는 96.21%가 나옵니다. 즉, LiDAR의 기여도가 Image보다 훨씬 높습니다. 저자는 이에 대해 RGB 이미지는 Depth 정보가 없고 빗방울 같은 노이즈에 취약해서 그렇다고 해석합니다. 퓨전을 했을 때 97.34%로 오르니 효과가 있긴 하지만, 베이스라인이 LiDAR 성능에 많이 의존하는 경향이 보입니다.
또한 행1~8을 살펴보시면 카메라와 라이다를 하나씩 가려가며(occlusion) 성능을 평가하고 있습니다. 생각보다 하락폭이 많이 큰게 좀 놀랍긴하네요.. sensor occlusion 이 생겼을때에도 하락폭을 최소화하는 연구가 필요해보입니다.

또한 위 figure를 통해 yaw 각도를 0도~360도로 돌려가면서의 성능을 테스트하고 있습니다. 아무래도 360도 방향으로 파노라마틱하게 feature 를 펼쳐서 그런지, 타 방법론들이 성능이 0으로 곤두박질 치는데에 반해 LCPR 의 경우는 성능을 유지하고 있습니다. OverlapTransformer 도 마찬가지로 rotation-invariant 를 고려한 방법론이기 때문에 유사한 경향을 보입니다.
리뷰 짧게 마치겠습니다. 읽어주셔서 감사합니다.
안녕하세요 석준님 리뷰 잘 읽었습니다.
해당 방법론에서 결국 핵심은 수평풀링을 통해, 연산량을 획기적으로 줄인채 attention을 하는 것과 VCTF 모듈을 통해 수학적으로 회전 불변성을 얻은 것이라 생각하면서 읽었습니다.
VCTF 모듈을 통해, 다른 모듈과 차별화되는 회전 불변성을 얻은 것은 실험적으로도 잘 드러난 것 같습니다. 그러나 수직 압축이 실제로 성능향상에 영향을 미쳤는지, 그리고 다른 일반적인 풀링(GAP이나 GeM등등)과 비교하였을 때도 성능 향상을 이루었는지 비교한 실험이 논문 내용에 있는지 궁금합니다.
댓글 감사합니다.
사실 있어야 당연하다고 생각하는데,, VCTF 모듈 절제실험이 없습니다..허허 저자가 숨기고 싶었던걸까요 (생각보다 향상폭이 낮아서?)
그리고 풀링 기법들에 대한 비교는 수행하지 않고 있습니다. 보통 최근 place recognition paper들에서 풀링 기법들에 대한 ablation 비교는 일반적으로 수행하지 않는데, NetVLAD나 gem 등과 같은 방식이 워낙 많이 알려져있고 유명한 기법이라 그냥 하나 선택해서 사용하는 그런 느낌으로 연구들이 진행되고 있습니다.
안녕하세요, 석준님. 좋은 리뷰 감사합니다.
제가 이해한 바로는 본 논문이 LiDAR와 카메라 뷰 간의 정렬(FOV 및 viewpoint alignment)을 맞춰가는 방법론을 제시한 것으로 보였는데,
저도 위에 정우님이 질문하신 것 처럼 압축하는 방식이 꼭 저런 방식을 사용해야 했는지, transformer이면 token pruning이나 token shuffling과 같은 토큰 압축 방식을 사용해도 되지 않았는지에 대해서 의문이 들었습니다.
그리고 VCTF의 4번째 단계에서 attention을 통과하기 전의 feature와 합친다고 되어 있는데 단순히 attention을 통과한 feature를 쓰는 것만으로는 어떤 한계가 있어서 마지막에 출력이랑 합치는 것인지 궁금합니다.
다시 한번 좋은 리뷰 감사합니다.