해당 논문은 텍스트-비디오 검색 연구에서도 LLM 및 CoT가 도입된 것 같아 읽어보게되었습니다.

- Conference: EMNLP 2025
- Authors: Prasanna Reddy Pulakurthi, Jiamian Wang, Majid Rabbani, Sohail Dianat, Raghuveer Rao, and Zhiqiang Tao
- Affiliation: Rochester Institute of Technology (뉴욕 로체스터 공과 대학교), DEVCOM Army Research Laboratory
- Title: https://aclanthology.org/2025.emnlp-main.1588.pdf
- Code: GitHub
1. Introduction
이 논문은 기존 텍스트-비디오 검색 시스템이 “왜 이 비디오가 검색되었는지” 를 설명하지 못한다는 점에서 출발했다고 합니다. 지금까지의 검색 방식은 대부분 텍스트와 비디오를 각각 벡터로 바꾼 뒤, 코사인 유사도가 높은 순서대로 결과를 정렬하는 구조였는데, 이 방식은 결과의 이유를 해석하기 어렵다는 X-AI 가 많이 언급하는 문제가 있었죠.
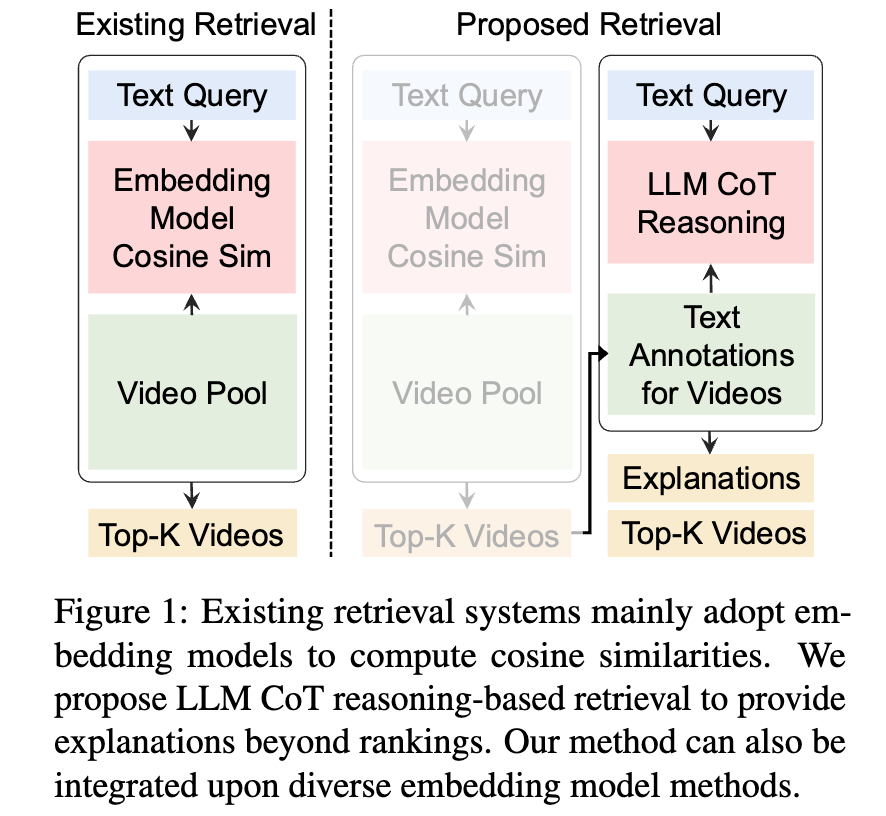
저자들은 이러한 한계를 해결하기 위해, 검색 자체를 임베딩 유사도 계산이 아니라 LLM의 단계적 추론(Chain-of-Thought)으로 수행하는 X-CoT를 제안하였습니다. 핵심 아이디어는 후보 비디오들을 한 번에 점수로 비교하는 대신, 텍스트 쿼리를 기준으로 비디오 쌍을 하나씩 비교하면서 “어느 쪽이 더 잘 맞는지”를 언어적으로 판단하게 하는 것이라고 합니다. 이 과정에서 LLM은 단순한 순위뿐만 아니라, 왜 그렇게 판단했는지에 대한 설명도 함께 생성하게 된다고 합니다.
또한 저자들은 LLM이 비디오를 더 잘 이해할 수 있도록, 기존 데이터셋에 객체, 행동, 장면 정보가 정리된 구조화된 비디오 어노테이션을 추가하였습니다. 그 결과, X-CoT는 검색 성능 자체도 향상시키면서, 동시에 모델의 판단 근거와 데이터 품질 문제까지 분석할 수 있는 설명 가능한 검색 시스템을 구현할 수 있었다고 하네요. 다시 말해, “검색 결과 + 이유”를 함께 제공하는 텍스트-비디오 검색 프레임워크를 제안한 연구라고 정리할 수 있겠네요. 본격적인 설명 시작하겠습니다.
2. Method
2.1 Video Annotation Collection
X-CoT에서는 검색 순위를 LLM의 추론으로 설명해야 하기 때문에, 비디오를 표현하는 텍스트 자체가 충분히 구조적이고 의미적으로 풍부해야 합니다. 그러나 기존 텍스트–비디오 데이터셋의 캡션은 대체로 짧고 coarse하다보니, 복잡한 비디오 내용을 추론에 활용하기에는 한계가 있었습니다. 이를 보완하기 위해 저자들은 기존 벤치마크를 확장하는 형태로 추가적인 비디오 어노테이션을 구축했다고 합니다.
구축에 있어 핵심 아이디어는, 비디오를 하나의 문장으로 요약하기보다는 객체(Object), 행동(Action), 장면(Scene) 단위로 분해해 LLM이 직접 reasoning에 활용할 수 있는 구조화된 텍스트로 바꾸는 것입니다. 이를 통해 빠른 움직임이나 다수의 객체가 등장하는 복잡한 장면도 보다 안정적으로 해석할 수 있고, 블러나 왜곡과 같은 시각적 노이즈로 인한 편향도 완화할 수 있다고 설명했습니다.
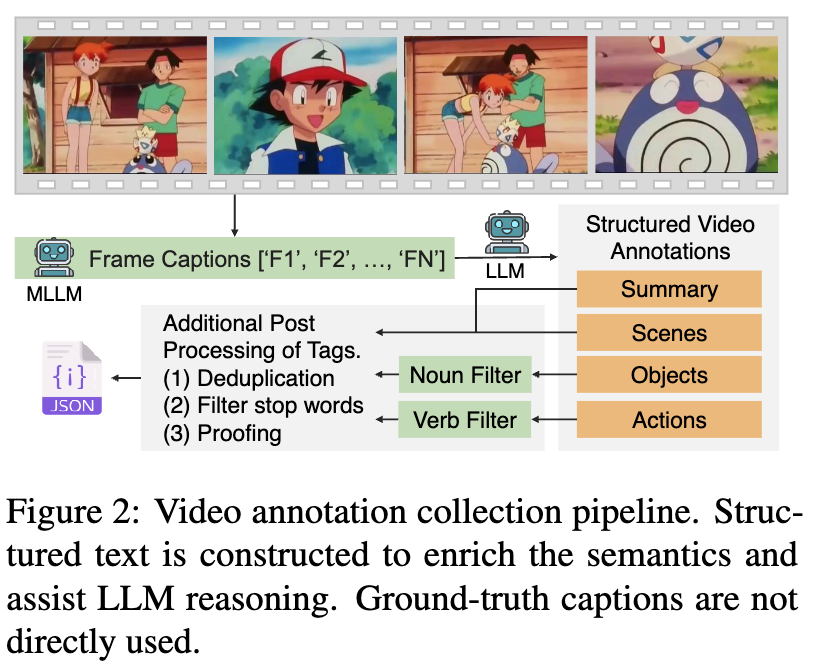
상단 Figure 2는 전체 어노테이션 수집 파이프라인입니다. 각 비디오에서 여러 프레임을 샘플링한 뒤, 중복 프레임을 제거하고 MLLM을 이용해 프레임 단위 캡션을 생성하였습니다. 이후 이 캡션들을 다시 집계·재구성하여, 비디오 전체를 설명하는 summary와 함께 objects, actions, scenes로 구성된 구조화된 어노테이션을 구합니다. 중요한 점은, 이 과정에서 기존 데이터셋의 GT 캡션을 그대로 사용하지 않고, LLM이 생성한 설명을 기반으로 의미 정보를 재구성했다는 점이라고 합니다.
그리고 앞서 만들어진 어노테이션에는 불필요한 단어나 중복 표현이 포함될 수 있기 때문에, 저자들은 아래와 같은 추가적인 후처리를 적용했습니다. 이러한 정제 과정을 통해 모든 비디오는 동일한 형식의, 비교 가능한 구조화된 텍스트 표현을 갖게 됩니다.
– 명사 필터를 통해 객체와 장면 관련 태그만 남기기
– 동사 필터를 통해 행동 정보 분리
– 의미적으로 중복되는 표현 병합
– 불필요한 stop word는 제거

상단 Figure 3에서 이렇게 재구조화된 어노테이션의 예시를 확인할 수 있습니다. 단순히 “피자에 재료를 올리는 장면”이라는 캡션 대신, 소스와 치즈라는 객체, 이를 바르고 뿌리는 행동, 그리고 장면의 시각적 특성이 정리되어 있는 걸 볼 수 있네요. 이처럼 세분화된 표현은 이후 X-CoT 단계에서 “왜 이 비디오가 쿼리에 더 적합한지”를 구체적인 근거 단위로 설명할 수 있게 만들었다고 합니다.
이후 Retrieval CoT에서 이루어지는 모든 pairwise 비교와 설명은, 바로 이 구조화된 비디오 어노테이션을 기반으로 수행됩니다.
2.2 Retrieval CoT
앞서 구축한 구조화된 비디오 어노테이션을 바탕으로, X-CoT는 본격적으로 설명 가능한 검색(explainable retrieval)을 수행합니다. 이 논문의 핵심은 기존처럼 임베딩 유사도로 한 번에 순위를 매기는 것이 아니라, LLM이 비디오 후보들을 쌍(pair) 단위로 비교하며 단계적으로 순위를 형성한다는 점입니다. 전체 파이프라인은 크게 세 단계로 구성됩니다.
Step 1. Top-K 비디오 후보 집합 생성
기존 임베딩 기반 검색 모델을 그대로 활용해, 주어진 텍스트 쿼리 q에 대해 Top-K 비디오 후보 집합을 생성합니다. 여기서 중요한 점은, X-CoT가 임베딩 모델을 대체하는 구조가 아니라는 것입니다. 임베딩 모델은 여전히 대규모 검색 공간에서 효율적으로 후보를 좁히는 역할을 하고, X-CoT는 그 이후의 소규모 후보 집합(K < 25)에 대해서만 추론을 수행하죠. 즉, 계산 비용을 통제하면서도 추론 기반 검색을 가능하게 만든 구조라고 하네요
Step 2. 쿼리와 적합한 비디오 및 선택한 이유 (reason) 생성
이 단계가 X-CoT의 핵심입니다. Top-K 후보들로부터 모든 비디오 쌍 [q, v_i, v_j]을 구성하고, 각 쌍을 LLM에 입력합니다. 이때 LLM은 단순히 “어느 쪽이 더 좋은가”만 판단하는 것이 아니라,
– 두 비디오 중 쿼리에 더 잘 부합하는 비디오를 선택하고
– 그 판단에 대한 자연어 기반 이유(reason)를 함께 생성합니다.
이 과정에서 앞서 생성한 객체, 행동, 장면 단위의 어노테이션이 LLM의 추론 입력으로 사용되며, LLM은 이를 근거로 비교 판단을 내리게 된다고 합니다. 결과적으로, 각 pairwise 비교는 binary preference(e.g. v_i < v_j)와 함께 해석 가능한 설명을 남기게 됩니다.
Step 3. 비교 결과 정제
여기서는 앞서 pairwise 비교 결과들을 그대로 순위로 사용하지 않고, Bradley–Terry(BT) 모델을 통해 한 번 더 정제한다고 합니다. LLM의 판단에는 노이즈가 포함될 수 있고, 비교 결과가 순환(cycle)을 이루는 경우도 발생할 수 있기 때문이죠. 저자들은 BT 모델을 사용해 각 비디오의 잠재적인 ability score를 추정하고, 이를 기준으로 최종 순위를 산출합니다. 이 과정을 통해 개별 비교의 불안정성을 완화하고, 일관된 전역 순위를 얻을 수 있도록 했다고 하네요.
BT 모델이 뭐죠?
여기서 사용된 Bradley–Terry(BT) 모델은, 여러 개의 pairwise 비교 결과로부터 일관된 전역 순위(global ranking)를 추정하기 위해 널리 사용되는 확률적 랭킹 모델이라고 합니다. X-CoT에서는 LLM이 생성한 쌍별 비교 결과가 서로 충돌하거나 순환 구조를 가질 수 있기 때문에, 이를 그대로 정렬에 사용하는 대신 BT 모델을 통해 한 번 더 정제한 것이죠
BT 모델에서는 각 비디오 v_i마다 하나의 잠재적인 ability score \theta_i > 0를 가정합니다. 이 값은 해당 비디오가 쿼리에 얼마나 잘 부합하는지를 나타내는 숨겨진 선호 강도로 해석할 수 있죠. 두 비디오 v_i와 v_j가 주어졌을 때, v_i가 v_j보다 선호될 확률은 다음과 같이 정의됩니다: P(v_i > v_j) = \frac{\theta_i}{\theta_i + \theta_j}
즉, ability score가 클수록 해당 비디오가 다른 후보들보다 선택될 확률이 높아지는 거죠. X-CoT에서는 LLM이 수행한 모든 pairwise 비교 결과를 관측 데이터로 삼아, Maximum Likelihood Estimation (MLE) 방식으로 각 \theta_i를 추정합니다. 이 과정은 “어떤 비디오가 얼마나 자주 이겼는가”를 단순히 세는 것이 아니라, 상대적으로 강한 후보를 이긴 경우 더 큰 가중치를 부여하도록 설계되어 있다고 합니다.
이러한 BT 기반 집계의 장점은 두 가지인데, 하나는 LLM의 판단에 포함된 노이즈나 모순적인 비교 결과(예: v_1 > v_2, v_2 > v_3, v_3 > v_1)를 자연스럽게 완화할 수 있다는 거고. 둘째는, 개별 비교 결과를 하나의 연속적인 점수 공간으로 통합함으로써, 최종적으로 안정적인 순위 정렬이 가능해진다고 합니다. LLM에서 종종 사용하는 기법 같습니다.
결과적으로 X-CoT의 최종 랭킹은 단순히 “LLM이 많이 이겼다고 판단한 비디오”가 아니라, 전체 비교 구조를 가장 잘 설명하는 ability score 기준의 전역 순위로 산출됩니다. 이후 이 순위를 기준으로 정렬한 리스트가 최종 검색 결과로 사용됩니다. 이 외로 더 궁금한 점이 있다면 댓글로 달아주시면 저도 다시 찾아보고 답변드리도록 하겠습니다.
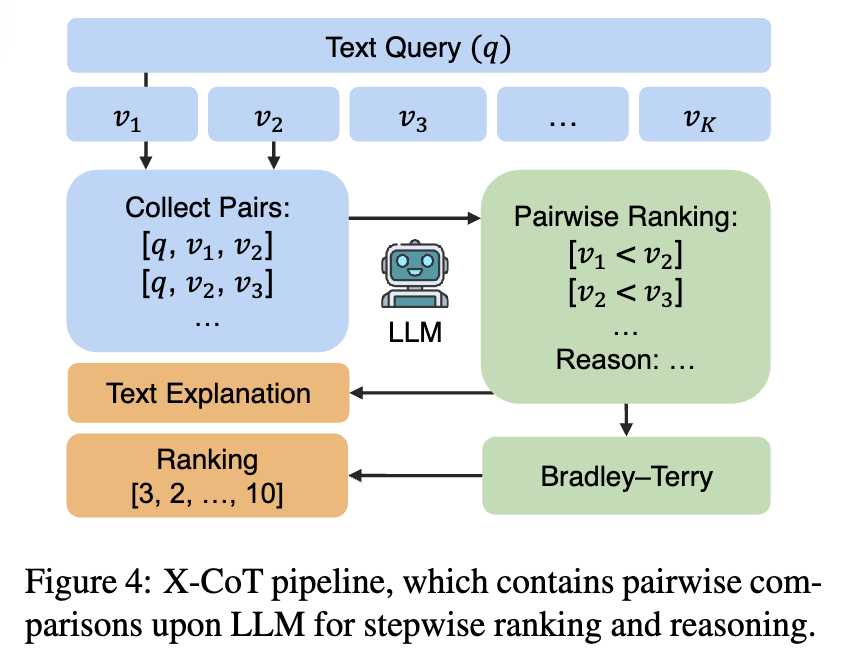
이제 전체 파이프라인을 그림과 함께 보고 마무리하겠습니다. 텍스트 쿼리와 Top-K 비디오 후보가 주어지면, LLM이 쌍별 비교와 그 이유 생성을 수행하고, BT 모델이 이를 집계하여 최종 순위와 함께 설명 텍스트를 출력하는 구조입니다. 즉, 결과는 단순한 랭킹 리스트가 아니라, “왜 이 비디오가 더 적합한지”에 대한 설명을 동반한다는 것이 기존 연구들과의 차별점 입니다.
정리하면, X-CoT의 Retrieval CoT는 임베딩 기반 후보 생성 → LLM 기반 pairwise 추론 → 통계적 랭킹 정제라는 세 단계를 통해, 기존 검색 시스템에서는 제공할 수 없었던 설명 가능한 텍스트-비디오 검색을 구현한 방법론이라고 볼 수 있습니다.
3. Experiment
3.1 Experimental Settings
데이터셋
MSR-VTT, MSVD, LSMDC, DiDeMo
평가지표
Recall@K(R@1, R@5, R@10), Median Rank(MdR), 그리고 Mean Rank(MnR)
X-CoT는 단독 검색기가 아니라 re-ranking 모듈이기 때문에, 먼저 임베딩 기반 모델을 사용해 Top-K 후보(K=20)를 생성한 뒤 그 위에서 X-CoT를 적용합니다. 이때 사용한 임베딩 모델은 세 가지로,
(1) CLIP-ViT-B/32
(2) Qwen2-VL 기반 VLM2Vec는 zero-shot 설정
(3) X-Pool은 텍스트–비디오 데이터로 학습된 retriever입니다.
이 구성에서 중요한 점은, X-CoT가 임베딩 모델의 종류와 무관하게 적용되는 플러그인 방식으로 평가되었다고 합니다.
3.2 Performance Comparison
아래 Table 1과 Table 2는 네 개 데이터셋 전반에서의 T -> V 검색 성능입니다. 모든 임베딩 모델, 모든 데이터셋에서 X-CoT를 적용했을 때 성능이 개선되었습니다.

먼저 MSR-VTT와 MSVD(Table 1)를 보면, CLIP 기반 검색 결과 위에 X-CoT를 적용했을 때 R@1이 각각 +2.1%, +5.6% 향상되었습니다. 이는 단순히 임베딩 공간에서의 코사인 유사도 정렬보다, LLM 기반 pairwise 추론이 더 정밀한 순위 판단을 수행했음을 보여줍니다. 이미 성능이 높은 X-Pool의 경우에도, X-CoT를 적용하면 소폭이지만 일관된 성능 향상을 보였다고 하네요
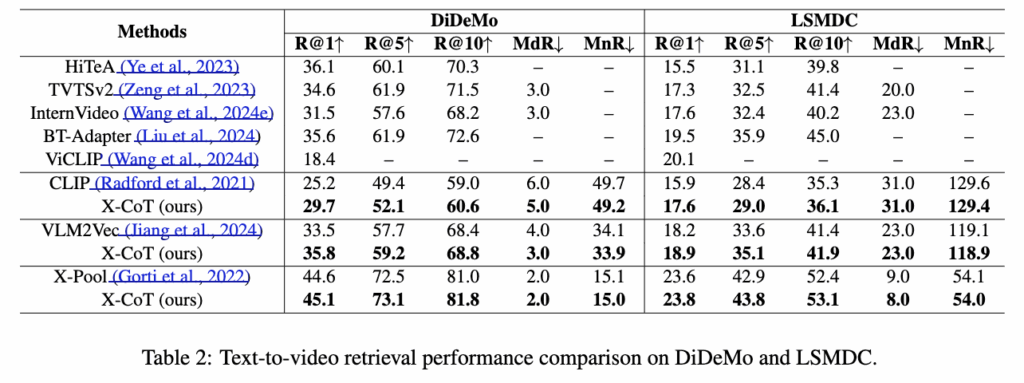
DiDeMo와 LSMDC(Table 2)에서도 동일한 성능이 나타납니다. 특히 DiDeMo는 시간적 순서와 행동 이해가 중요한 데이터셋인데, X-CoT는 R@1 기준으로 CLIP 대비 약 +4.5%, VLM2Vec 대비 약 +2.3%의 향상을 보였습니다. 이는 앞서 도입한 행동(action) 중심의 구조화된 어노테이션과 pairwise 비교 방식이 시간적 추론에 효과적이었기 때문이라고 합니다/
단, LSMDC의 경우 전체적인 성능 수치는 낮은 편이지만, 이 데이터셋 역시 영화 장면 기반으로 문맥 이해가 중요한 특성을 갖고 있습니다. 이 환경에서도 X-CoT는 모든 임베딩 백본 위에서 R@K와 랭킹 지표(MdR, MnR)를 안정적으로 개선하였다고 합니다. 특히 MnR이 감소한다는 점은, 상위 몇 개 결과뿐 아니라 전체 순위 구조가 전반적으로 정제되었음을 의미한다고 하네요
3.3 Ablation Study 및 Model Discussion
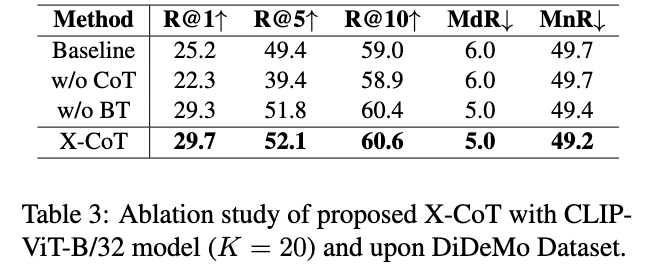
먼저 Ablation 실험(Table 3)입니다. CoT를 제거하고 LLM에게 Top-K 후보를 직접 정렬하도록 한 경우(w/o CoT), R@1 성능이 baseline 대비 오히려 크게 하락했습니다. 이는 LLM에게 다수의 후보 중 최적의 결과를 한 번에 선택하는 것보다, pairwise 비교 기반 추론이 훨씬 안정적임을 보여주는 결과라고 합니다.
반면, CoT는 유지하되 Bradley–Terry(BT) 집계를 제거한 경우(w/o BT)에는 baseline 대비 성능 향상이 있었습니다. 이는 LLM 기반 pairwise 비교 자체가 retrieval 성능 개선에 기여함을 의미한다고 하네요. 다만 CoT와 BT를 함께 적용한 X-CoT가 가장 높은 성능을 기록했고, R@1 기준으로 baseline 대비 약 4.5% 향상을 보였습니다. 이 결과는 pairwise 추론과 BT 기반 전역 랭킹 정제가 상호 보완적으로 작동함을 알 수 있었습니다.
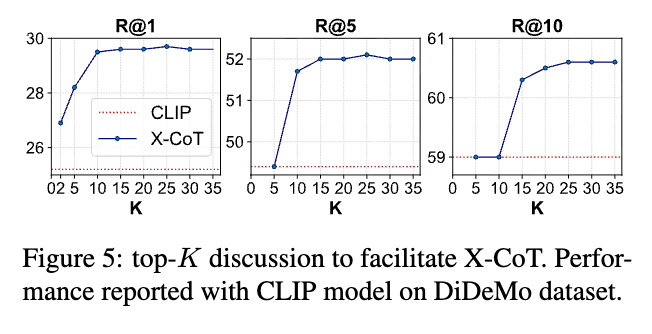
Top-K 범위에 따른 성능 분석(Figure 5)에서는 K가 증가할수록 X-CoT의 성능이 점진적으로 향상되며 안정화되는 경향이 있었습니다. 이는 X-CoT가 특정 K 값에 민감하지 않고, 다양한 후보 풀 크기에서도 효과적으로 동작함을 의미합니다.

이제 시각화 결과 보겠습니다. 설명 가능성 분석(Figure 6)에서는, 시각적으로 유사한 비디오들 사이에서 기존 임베딩 기반 방법이 구분에 실패한 반면, X-CoT는 행동(action) 차이를 근거로 올바른 비디오를 상위에 배치하였습니다. 이 과정에서 X-CoT는 선택 이유를 자연어로 함께 제공하여, 랭킹 결과의 근거를 명확히 드러냈습니다.

마지막으로 Figure 7에서는 검색 실패 사례도 보여주었는데요. 이 경우, X-CoT의 설명을 통해 오류의 원인이 모델 자체가 아니라 텍스트 캡션에 포함된 모호하거나 잘못된 표현임을 확인할 수 있었다고 합니다. 이를 통해 X-CoT가 retrieval 성능 평가뿐 아니라, 텍스트–비디오 데이터 품질을 진단하는 데에도 활용될 수 있음을 확인했습니다.
LLM의 추론 능력에 크게 의존한다는 한계와, Bradley–Terry 모델이 이진 선호만을 다룬다는 제약이 존재하지만, LLM 기반 CoT 추론을 텍스트–비디오 검색에 체계적으로 접목하여, 성능 향상과 함께 설명 가능성을 동시에 확보한 점이 인상적인 것 같습니다. 실제로 TVR 모델의 출력 결과를 보면 이 아이는 왜 이딴식(?)으로 출력했을까 의문이 있었는데 어느정도 그 이유를 간접적으로나마 알 수 있지않을까 싶네요
좋은 리뷰 감사합니다.
기존 방법처럼 텍스트 쿼리로 큰 범주의 유사도가 높은 클러스터에 접근하는 것 까지는 동일하지만, 클러스터 내부에서 소수의 비디오는 LLM으로 검색을 수행하게 되는 것으로 이해했습니다.
수행 방식에서 질문이 있습니다. X-CoT를 진행 2단계에서 q와 하나의 v끼리 비교하는게 아니라 비디오 쌍끼리 비교를 수행하는데, 비교할 pair 수를 늘려하면서 비디오 두개(vi, vj)를 비교했을 때의 이점이 무엇인지 궁금합니다. q-v 하나씩 비교하거나 q하나와 25개 정도의 v1~v25를 한번에 비교하면 pair-wise로 비교하는것보다 훨씬 효율적인 것 같아서요. vi-vj로 비교했을 때 해석가능성에 어떤 추가적인 이득이 있나요?
감사합니다.
좋은 질문 감사합니다. q–v를 각각 평가하거나 q와 여러 비디오를 한 번에 비교하는 방식은 계산적으로는 효율적이겠지만, LLM이 각 비디오를 절대적인 기준으로 판단해야 한다는 한계가 있습니다. 반면 v_i, v_j 를 직접 비교하면, 두 비디오 중 어느 쪽이 질의의 어떤 조건을 더 잘 만족하는지를 명확히 대조할 수 있게 된다고 합니다. 이 과정에서 생성되는 설명 역시 “왜 이 비디오가 다른 후보보다 더 적합한가”라는 상대적인 근거를 포함할 수 있게 되어, 단순 점수 기반 판단보다 해석하기 쉬운 장점이 있다고 생각합니다.
안녕하세요 주영님, 좋은 리뷰 감사합니다.
X-CoT가 CLIP과 같은 foundation model뿐만 아니라, 이미 좋은 성능을 가진 X-Pool 위에서도 일관된 성능 향상을 보였다는 점이 인상적인데, 그렇다면 X-CoT의 역할은 백본 모델의 단순한 오인식을 바로 잡는 ‘교정’ 역할에 가까운 지 아니면 임베딩 유사도로 포착할 수 없는 고차원적 추론을 추가하는 느낌인지 궁금합니다!
좋은 질문 감사합니다. X-CoT를 단순히 백본 모델의 오답을 고치는 ‘교정기’ 라기보다는, 임베딩 유사도만으로는 잘 드러나지 않는 차이를 비교해 주는 보완 단계로 보는 것이 나을 것 같습니다. 즉, 기존 TVR 방법론인 X-Pool처럼 이미 성능이 높은 모델 위에서도 성능 향상이 유지된다는 점은, X-CoT가 단순한 오류 수정이 아니라 행동이나 맥락과 같은 요소를 상대적으로 비교하며 판단을 보완하고 있음을 보여준다고 생각합니다.