제가 이번에 리뷰할 논문도 Audio Visual Question answering 태스크를 다루는 논문입니다. 저희가 실험중인 성능과 비슷한 성능을 달성하기도 했고, 실험 성능중 Audio 와 관련된 성능은 저희 모델과 비슷하지만, Visual 성능은 6퍼센트정도 떨어짐에도 불구하고 Audio-Visual 성능이 3퍼센트정도 높아 모델의 백본이나 학습 방법론에서 어떤 차이가 있을지 궁금하여 선택하게 되었습니다. ( MUSIC-AVQA 데이터셋은 각각 Audio, Visual, Audio-Visual 에 관련된 실험 성능이 존재합니다. ) 그럼 리뷰 시작하겠습니다.
Abstract
AVQA task 에서는 Audio 와 Visual 모달리티는 1) Spatial, 2) Temporal, 3) Semantic 3가지 레벨에서 학습이 됩니다. 저희가 baseline 으로 삼은 TSPM 논문과 비슷한 시기에 나와서 그런지 문제정의가 비슷한데, 저자는 기존의 AVQA 방법론이 2가지 주요 문제점을 가지고 있다고 언급합니다.
- 오디오-비주얼 정보의 Temporal 과 Spatial 수준에서 정렬이 되어있지 않다.
- 오디오-비주얼 정보의 의미적 불균형으로, 맥락 안에서 균형을 이루지 못하는 경우가 낮은 성능을 초래한다.
저자는 위의 문제점을 해결하기 위해 end to end Contextual Multi-modal Alignment (CAD) 네트워크를 제안합니다. 해당 네트워크는 1) 공간 수준에서 오디오와 비주얼 정보의 정렬을 보장하는 파라미터가 없는 확률적(Contextual) 블록을 도입하고, 2) 자기지도 설정에서 시간 수준의 동적인 오디오-비주얼 정렬을 위한 사전학습 기법을 제안, 3) 의미 수준에서 오디오와 비주얼 정보를 균형있게 만들기 위한 cross-attention 매커니즘을 도입함으로 위의 문제점들을 해결했다고 합니다. 또한 저자가 제안한 방법들이 추가적인 복잡도의 증가 없이 기존 방법들에 결합될 수 있다고 합니다.
Introduction
오디오-비주얼 의 멀티모달 입력을 다루는 태스크는 굉장히 많습니다. 비디오에 캡션을 달거나, 음성 인식을 한다거나, 누가 말하는지 speaker 를 인지, 소리의 위치를 추정, 질의응답등 많은 분야에서 해당 입력을 다룹니다.
앞서 언급했듯이 AVQA 에서는 공간,시간,의미 수준에서 잘 다루어야 학습이 가능합니다.
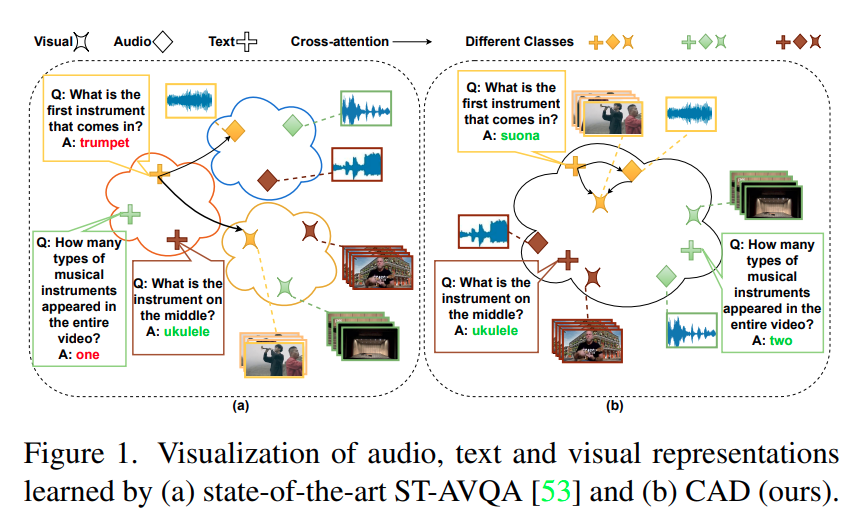
예를들어 그림 1에서 노란색 클래스에서 악기의 공간적 위치는 오디오와 비주얼 입력을 통해 결정할 수 있지만, ‘어느 것이 먼저 나오냐?’ 에 답하려면 악기의 소리를 동시에 듣고 비주얼 입력에서 그것을 동시에 보아야 합니다. 이 단계에서 소리와 악기의 시각적 등장 사이에 시간적 비정렬이 존재하면 학습을 저해할 수 있습니다. 또한 의미 수준에서는 악기의 소리와 외형을 악기의 라벨과 연결지어야 합니다. 다시 그림 1 (a) 에서 최신 방법인 ST-AVQA 에서는 오답인 트럼펫을 예측하는 방면, 저자의 방법은 suona 를 예측하는 것을 보여줍니다. 부연 설명으로는 ST-AVQA에서는 정답을 맞추기 위한 의미 수준의 학습이 없지만 저자의 방법론은 연주되었다 (played) 가 아니라 등장했다 (appeared) 에 관한 의미 수준의 학습이 잘 되어 있다고 주장하는 것 같습니다. figure만 보면 ST-AVQA 는 audio, visual, text 에 관한 각 모달리티가 서로 다른 클래스에 대해 묶여있지만, 저자는 동일 클래스에 대한 모든 모달리티의 정보가 통합된 공간에 정렬되어 있어서 AV 정보 신호의 균형을 맞출 수 있음을 알 수 있습니다.
AV 학습에 있어서 오디오와 비주얼 데이터는 네트워크에 별도로 입력이 되며, 서로 다른 샘플링 비율로 수집이 됩니다. 연산 자원과 긴 학습 시간의 제약 때문에 더 적은 메모리를 요구하는 오디오 데이터에 비해 비주얼 데이터가 종종 더 스파스하게 샘플링된다고 합니다. 이로인해 생기는 두가지 문제점이 있습니다.
- 오디오와 비주얼 스트림 간의 비정렬
- 하나의 문맥 내에서 오디오와 비주얼 의미 정보의 불균형
당연하게도 SOTA 를 달성하기 위해서는 오디오와 비주얼 정보는 완벽히 정렬되어 있는것이 좋습니다. 동시에 문맥 내에서 의미적으로 균형을 이루면 더 좋다고 합니다.
일부 방법론들은 self-attention 과 cross-attention 을 사용해 오디오, 비주얼 특징과 가장 상관있는 부분을 찾는데 이는 문제를 부분적으로 해결하며, 최근의 contrastive learning 을 이용해 비라벨 데이터들을 자기지도 방식으로 활용하는 것은 특징 공간 내에서 멀티모달 클래스 구분을 제한하는 문제가 있다고 합니다.
저자는 위 과제들을 해결하기 위해서 1. AV 공간 비정렬을 완화하기 위한 비주얼 특징용 Contextual 블록, 2. 자기지도 방식의 사전학습 과제로서 AV 특징의 시간정렬, 3. 동적 시나리오를 다루기 위해 AV 의미 균형을 만드는 cross-attention 모듈 체인을 제안합니다.
Method
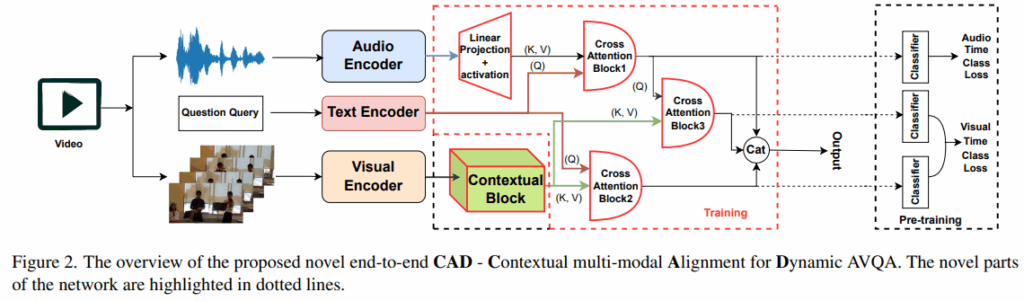
전체 학습 파이프라인은 매우 단순합니다. 지금 저희가 베이스라인으로 삼은 TSPM 과 생각보다 많은 부분이 유사한 것 같습니다.
우선 비디오를 통해 Audio, Visual 의 정보를 뽑게됩니다.
여기서 오디오의 백본으로는 PANNs 라는 CNN 기반 오디오 패턴 인식을 위해 개발된 대규모 사전학습 모델을 이용하며, 다양한 종류의 오디오 이벤트나 특징을 분류하는데 특화되어 있습니다.
비주얼 백본으로는 ViT를 사용하고 이는 ImageNet 으로 사전학습되어 있습니다. 다른 연구들은 보통 audio 백본으로는 VGGISH 를 사용하고, 비디오와 텍스트는 CLIP 에서 뽑아서 사용하는데, 저자는 비디오정보는 ViT를 사용하고 텍스트는 GloVe 에서 뽑은 단어 임베딩을 사용합니다.
우선 VGGISH 와 저자가 사용한 PANNs 백본의 표현력차이는 잘 모르겠으나 이후 보여줄 최종 성능에서 Audio 에 대한 성능이 VGGISH 를 사용하는 모델들과 크게 차이가 없는것으로 보아 표현력이 극단적으로 차이나는 것은 아니라고 생각했습니다.
다른 저자들이 비디오와 텍스트를 CLIP 에서 뽑아서 사용하는 이유를 저는 이미지와 텍스트의 임베딩 공간이 이미 어느정도 정렬이 되어있기 때문에, 동일한 512 차원으로 투영시켜 최초 input 으로 사용하는데에 안정성이 있다고 생각합니다.
그러나 저자는 GloVe 에서 뽑은 Text 임베딩과 ViT 조합을 사용하는데 앞서 언급했듯이 이미지와 텍스트가 정렬된 상태로 CLIP 을 사용하는 것과, 이렇게 정렬이 안되어 있는 3가지 모달리티를 사용하는 것이 각각 장단점이 있다고 생각하고, 저자는 정렬이 안되어있는 상태에서 각 모달리티를 spatio, temporal, semantic 한 차원에서 동시에 정렬시키고자 이러한 선택을 한 것 같습니다. 본문에는 따로 언급이 없습니다.. 해당부분은 실제로 분석을 해봐야 그 장단점을 확인할 수 있을 것 같습니다.
또한 GloVe는 단어별 임베딩 벡터를 내뱉으며, SOS 나 EOS 같은 시작과 문장 요약 토큰이 별도로 존재하지 않습니다. 따라서 전체 단어별 임베딩을 평균내서 뽑아놓고 사용하지 않았을까 추측할 수 있습니다. (해당 내용도 언급되어 있지 않습니다.)
다시한번 저자의 두가지 주요 문제정의를 말씀드리면
- Audio-Visual Misalignment : 오디오와 비주얼 정보의 시간적 또는 공간적 정렬이 제대로 이루어지지 않으며 이로 인해서 시간적 추론이 필요한 질문에 답하기 어렵게 됩니다. 예를 들면 소리가 나는 시점과 영상에서 해당 사물이 보이는 시점이 일치하지 않으면 학습하기 어렵습니다.
- Semantic Information Imbalance : 오디오와 비주얼 정보에서 나오는 의미론적 정보가 특정 문맥 안에서 균형 있게 처리되지 못합니다. 특정 모달리티의 정보가 과도하거나 부족하게 사용될 수 있어 질문의 의도와 맥락을 정확히 파악하는 데 어려움을 겪습니다.
저자의 CAD 모델은 위의 문제점을 해결하기 위해 다음과 같은 기법들을 도입합니다.
- 사전학습 : 오디오와 비주얼 입력을 1초 길이의 60개의 큐로 분할하여 시계열적으로 정렬합니다. 이를 통해 temporal level 에서의 오디오-비주얼 정렬을 학습할 수 있다고 합니다.
- 시공간적 Contexutal 블록 : 사전 학습 단계뿐만 아니라 실제 학습 단계에서도 시각적 특징 (visual cue) 에 이 블록을 적용합니다. 이를 통해 temporal level 에서의 오디오-비주얼 정렬을 학습합니다.
- 세 개의 cross-attention 모듈 : 사전 학습 단계에서 이 모듈들을 사용하여 오디오와 비주얼의 의미론적 정보를 정렬하고 균형을 맞춥니다.
AV Fine Temporal Alignment as pre-training
우선 1번내용을 보고 다른 AVQA 논문들의 모델들도 동일한 MUSIC-AVQA 데이터셋을 사용하고, 60초의 영상을 1초단위의 60개 segement로 사용하니 당연한 해결책 아닌가 의문이 들 수 있습니다. 이러한 의미는 아니고 저자는 AV Fine Temporal Alignment 를 위해 3개의 분류기를 둔 사전학습을 먼저 진행합니다. figure 2의 마지막 점선으로 된 pretrain 부분인데, Figure 3로 보여드리자면
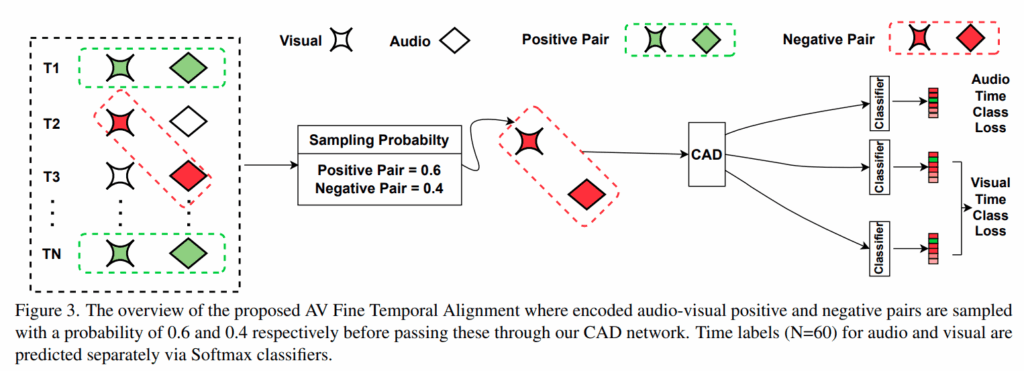
저자는 3개의 분류기를 통해 Audio 와 Visual 정보가 postitive pair 인지, negative pair 인지에 대한 정보를 사용하여 학습합니다. 간단하게 오디오 또는 비디오 데이터가 비디오의 총 60개의 시간 구간에서 어느 구간에 속하는지를 예측하는 것인데, 이를통해 오디오와 비디오의 스트림을 시간적으로 정확하게 일치시킬 수 있다고 합니다. Figure 2와 같이 봐야 어떤 모달리티를 사용하는지 알 수 있는데, 우선 Audio classifer 는 질문과 오디오 특징을 입력으로 오디오의 시간 레이블을 예측합니다. 아래 두개의 분류기는 비디오 스트림의 시간 레이블을 예측하는 것으로 하나는 질문쿼리를, 하나는 오디오와의 cross attention 결과를 쿼리로 사용하여 오디오의 시간적 정보가 비디오의 시간적 이해에 어떻게 기여하는지를 고려하여 예측합니다. 해당 과정을 통해 모델은 오디오와 비디오 정보가 시간적으로 얼마나 잘 정렬되어 있는지 학습하게되고 이후 end to end 로 모델을 학습할때 뒤의 3가지 classifier는 제거됩니다. 이때 학습되는 정보는 긍정적인 쌍, 즉 오디오와 비디오가 같은 2초에서 입력된다면, 오디오 분류기와 비디오 분류기 모두 2초를 예측해야하고, 부정적인 쌍, 즉 오디오는 2초, 비디오는 4초가 입력된다면 오디오는 2초를 비디오는 4초를 예측해야합니다. 이는 교차 엔트로피 손실로 계산되며 60대 40은 실험적으로 결정되었다고 합니다.
Contextual Block
논문에서 언급된 컨텍스트 블록은 시각적 특징으로부터 가장 관련성 높은 정보를 추출하는 데 중요한 역할을 합니다. 이 블록은 특히 학습 과정에서 오디오와 시각 정보가 공간적 수준에서 동시에 추출되는 데 어려움을 겪는 문제를 해결하기 위해 설계되었다고 합니다. 학습 순서는 다음과 같습니다.
- 시각 특징 샘플링 (Sampling Visual features) : 먼저 훈련 중에는 시각 특징 v 를 80%로 무작위 샘플링합니다. 이는 모든 특징을 사용하지 않고 일부를 선택하여 모델의 복잡성을 줄이고 효율성을 높일 수 있습니다.
- 평균 특징 계산 ( Averaging features) : 샘플링된 시각 특징 v를 채널 차원으로 평균을 냅니다. 이를 통해 특징의 전반적인 분포나 중심 경향을 알 수 있습니다.
- 마스크 생성 (Creating a mask M) : 계산된 평균 특징 fm 을 기준으로 특정 임계값 th 을 설정합니다. 이 임계값은 평균 특징의 최대값에 0.9를 곱한 값입니다.
- 컨텍스트 특징 추출 (Extracting contextual features cf) : 평균특징 fm 에 시그모이드 함수를 적용하여 컨텍스트 특징을 추출하고 확률적으로 나타냅니다.
- 무작위 선택 및 적용 (Random selection and application) : 앞서 생성된 마스크 m 과 컨텍스트 특징 cf 중에서 90% 확률로 무작위로 하나를 선택합니다. 이는 학습의 강건성을 높이기 위한 방법으로 매번 동일한 특징이 선택되는 것을 방지한다고 합니다. 이 무작위 선택을 원래 시각 특징 v에 곱하여 적용하며 이렇게 해서 일부 시각 특징은 0으로 처리되어 제거되거나 약화되며, 이는 모델이 특정 시각 정보에 더 집중하도록 유도합니다.

위의 컨텍스트 블록은 뒤의 audio, text, visual 정보들의 cross attention 결과들을 통해 최종 loss 함수를 거치고 나면 시각적 입력에서 공간적으로 관련성이 높은 특징들을 추출하도록 학습되어집니다. 즉 AVQA task에 맞게 어떤 시각적 영역이 현재 질문이나 오디오와 관련이 깊은지를 학습하게 되는 것입니다.
End-to-end CAD
저자가 제안한 CAD 모델의 최종 통합 및 예측 과정을 설명하는데, 간단히 이전에 얻어진 출력들, 3개의 cross attention을 거치고 나온 결과를 모두 concat 하여 하나의 벡터로 만듭니다. 이를 fc-layer를 통해 최종 예측을 진행하고 42개의 one hot 인코딩된 라벨과의 손실을 Cross Entropy 손실함수로 학습하게 됩니다.
Datasets
Music-AVQA : 해당 데이터셋은 최종 성능을 훈련하고 테스트하는데에 사용됩니다.
음악 공연과 관련된 Audio, Visual, Audio-Visual 의 질문-답변 쌍으로 구성되어 있습니다. 해당 데이터셋은 9290개의 유튜브 비디오, 45867개의 질문-답변 쌍을 포함하여 9가지 유형의 다양하고 복잡하며 동적인 AV 질문을 다룹니다.
ACAV100M : 이 데이터셋은 모델의 사전학습 단계에 사용됩니다. 사전 훈련에서는 AVQA 에 적용되기 전 더 일반적인 오디오-시각적 특징을 학습하도록 돕는다고 합니다.
Experiments
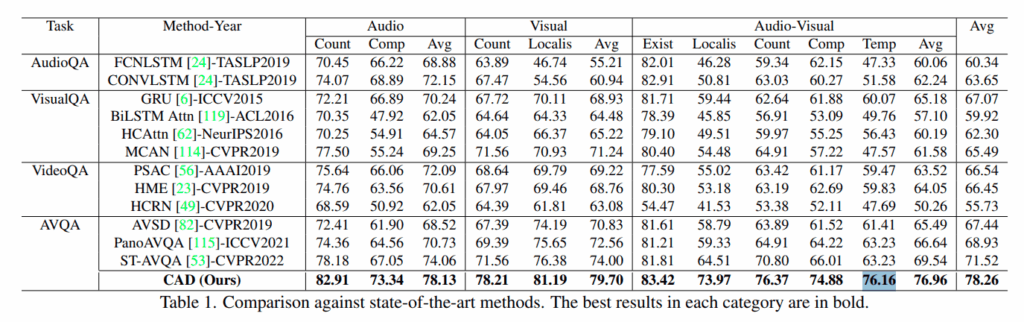
저자의 방법론이 Audio, Visual, Audio-Visual 에서 기존 방법론을 모두 크게 제치는 결과를 보여줍니다. 물론 2024년도에 저자의 성능과 비슷한 수치를 보여주는 많은 논문들이 등장하기는 했습니다. 우선 Task 에서 AudioQA 와 VisualQA VideoQA 등으로 나눈 기준은 질문에 답하기 위해 주로 사용되거나 요구되는 입력 모달리티에 따라 나눈 것이며, 따라서 해당 Task 칸에 있는 모델들이 Audio 나 Visual 쪽 성능이 유독 높았던 것을 확인할 수 있습니다.
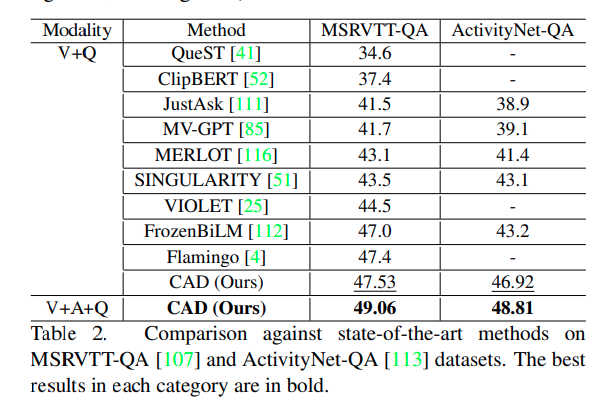
AVQA task만 다루는 것이 아닌 MSRVTT-QA 나 ActivityNet-QA 에서도 SOTA 방법론들과 비교하여 더 나은 성능을 보여줍니다. 기존의 VQA 방법론들은 MSRVTT-QA 데이터셋이나 ActivityNet-QA의 오디오 정보는 사용하지 않았지만 저자는 해당 audio 정보까지 사용하면 성능이 더 오르는 것을 실험적으로 보여줍니다.
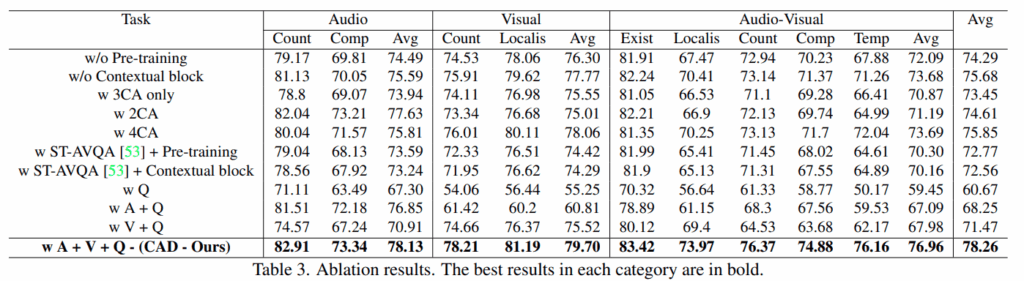
방법론적 ablation 입니다. 사전학습이나 contextual block 없이는 실험성능이 3퍼, 4퍼씩 감소하는 것으로 가장 폭이 크며, ST-AVQA 방법론에서도 사전학습이나 Contextual block을 넣었을때 성능이 오르는 것을 보여줍니다. 또한 w Q 성능을 통해 모델이 오디오와 비디오를 보지 않고도 60.67이라는 엄청 높은 성능을 달성하는 것을 알 수 있습니다. 이는 MUSIC-AVQA-R 데이터셋을 제안한 논문에서도 주장한 현상인데, 데이터셋의 분포를 모델이 학습하게되어 오디오와 비디오의 정보를 보지 않고도 일정 수준이상의 정답률을 보여주는 것입니다. 물론 질문만 보고도 어느정도 정답에 대한 힌트를 얻을수는 있을것입니다.
Conclusion
저자는 AVQA task 에서 CAD라는 네트워크를 제안하며 위에서 언급한 3가지 방법으로 문제를 해결합니다.
최근에 나온 성능들이랑 비교해도 낮지않은 성능이지만, 사용한 audio 백본이나 video 백본, 또는 사전학습에서 사용된 데이터셋등을 생각하면 실제 모델의 구조적 측면에서 pair comparison이 가능할까 싶기는 합니다. 물론 기존 ST-AVQA 방법론에 저자의 Pre-training 이나 contextual block 등을 적용했을때 성능이 오르는 것으로 어느정도 그 성능을 입증한 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사드립니다.
예전의 인택님 리뷰는 제가 공부했던 부분과 접점이 많았던 것 같은데 요즘 리뷰는 모르는 내용이 많아 방법론 이해하기가 어렵네요..하하 단순한 질문인데 Contextual Block 파트에서 “마스크 m과 cf 중 90% 확률로 무작위로 하나 선택”이라고 하셨는데
90%는 둘 중 하나를 고르는 사건의 확률인지(즉 10% 무작위 선택이 아닌건지 아니면 어떤게 디폴트 값인지) 아니면 m을 90%, cf를 10% 같은 편향(?) 선택인지가 궁금합니다.
감사합니다