안녕하세요 이번주는 real to sim to real 접근을 통한 나름(?) 참신한 방법을 통해 로봇 데이터 scaling의 가능성을 제안한 연구를 리뷰해보려고 합니다. 많은 연구들이 sim to real 부분에서의 개선을 노릴 때 real to sim의 확장성에 초점을 맞추어 VFM들에 힘입어 로봇 데이터의 재료로 인터넷 이미지 까지 활용해보자는 컨셉이 주를 이룬다고 생각하시면 될 것 같습니다.
Introduction
기존 Real-to-Sim-to-Real 접근법들은 현실 세계 데이터를 디지털 트윈 형태로 시뮬레이터에 재구성한 뒤, 시뮬레이션 상에서 데이터를 모으고 학습한 정책을 다시 실제 로봇에 적용하는 방식을 취해왔습니다. 이 때 Multi-view 카메라를 통해 3D reconstruction을 수행하지만, 실험실 세팅에서만 가능한 장치에 의존하는 경우가 대부분입니다. 이러한 하드웨어 세팅에 의존하는 하드웨어 중심 방법들은 효과적이지만 데이터 수집이 실험실 환경에 국한되어, 인터넷이나 일상에서 손쉽게 얻을 수 있는 다양한 in the wild 이미지로 확장하기는 어렵다는 한계가 존재합니다. 저자들은 ‘한 장의 이미지로부터 로봇이 바로 학습에 활용할 수 있는 완전한 데이터를 얻을 수는 없나?’ 라는 질문으로 연구를 시작했다고 합니다.
저자들은 기존 여러 제한된 input을 통한 데이터 생성 방법론들과 같이 foundation model들을 사용하는 것 입니다. 다양한 foundation model들의 도움을 받아 단일 RGB 이미지만으로도 충분히 물리적 장면을 복원하고, 물리 기반 렌더링 등 복잡한 파이프라인 없이도 실제와 같은 시각 observation을 생성할 수 있었다고 합니다. 즉, 꼭 여러 뷰의 영상이 없어도 되고, 세팅된 전문 촬영 장비나 3D asset library가 없어도 하나의 이미지에서 로봇 학습에 필요한 모든 정보를 추출해낼 수 있음을 어필하고 있습니다.
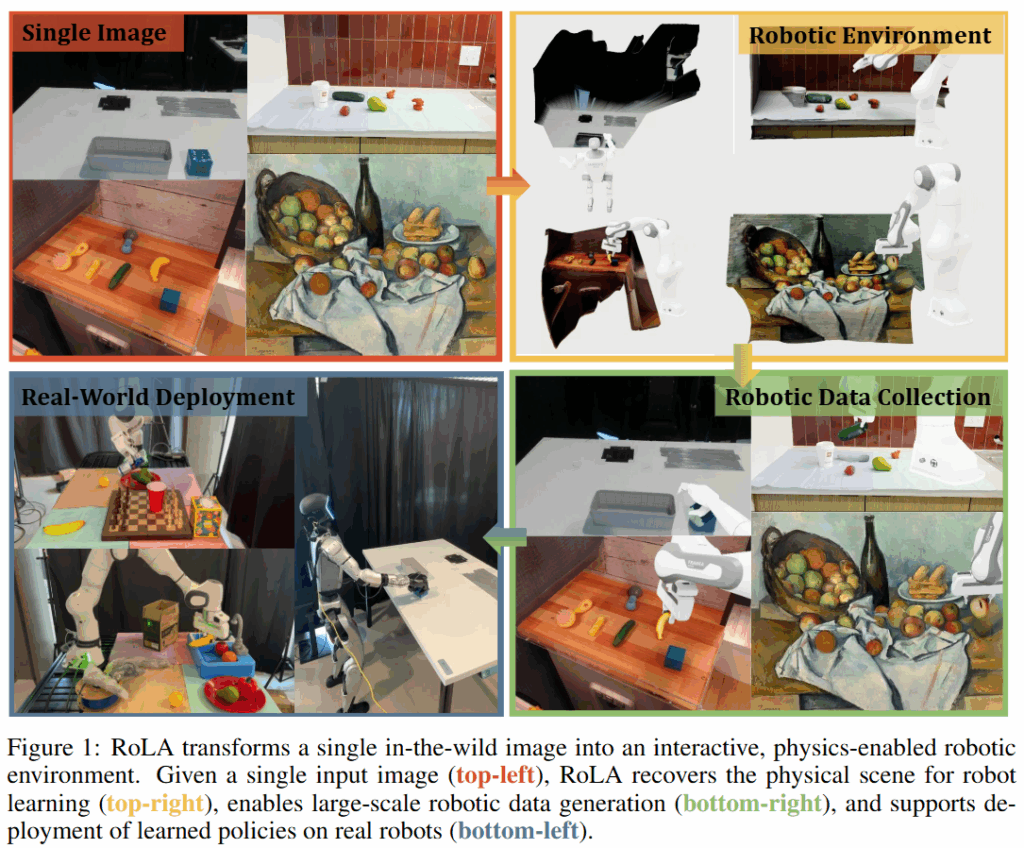
이러한 틀을 가지고 저자들은 특별한 하드웨어나 추가 정보 없이도 아무 이미지나 로봇 학습에 활용가능한 시뮬레이션 환경으로 변환하는 RoLA를 제안했습니다. RoLA(Robot Learning from Any Images)는 입력 이미지로부터 물리적으로 상호작용 가능한 scene을 자동으로 복원한 뒤, 그 안에서 photorealistic한 visuomotor policy를 위한 데이터를 대량 생성하여 정책 학습에 활용하는 end to end 파이프라인입니다. 해당 프레임워크는 큰 틀에서는 전형적인 real to sim to real 방법을 따라갑니다. 먼저 단일 이미지에서 객체와 배경의 3D 기하를 추정하고, 물리 속성까지 고려한 장면을 복원하여 시뮬레이션 asset으로 변환 후 카메라의 포즈를 추정하고, 로봇을 배치합니다. 이후에는 복원된 scene을 시뮬레이터에 불러와 다양한 로봇 task에 대한 대규모 시뮬레이션 데이터를 수집합니다. 마지막으로는 시뮬레이터에서 얻은 영상들을 현실 배경과 합성하는 visual blending 기법으로 로봇 데모 영상을 만들고, 이를 사용해 정책을 학습시킨 뒤 실세계 로봇에 이식해줍니다. 이 모든 과정이 사람의 개입 없이 완전 자동화되어 있으며, 어떠한 이미지라도 입력으로 받아들일 수 있는 범용성을 가지는 것이 장점이라고 합니다. 이러한 단일 자동화된 이미지 기반의 범용적인 파이프라인을 통해 저자들은 방대한 수의 인터넷 이미지를 로봇 학습에 활용하는 길을 열고 scalable robot learning에 힘쓰려는 것으로 보입니다.
Methods
방법의 핵심은 하나의 rgb 이미지로부터, 어떤 이미지던지 상관 없이 robotic environment를 만들어내고, 그 환경에서 visuomotor policy를 위한 학습 데이터를 취득하는 것입니다. 한 단계씩 살펴보도록 하겠습니다.
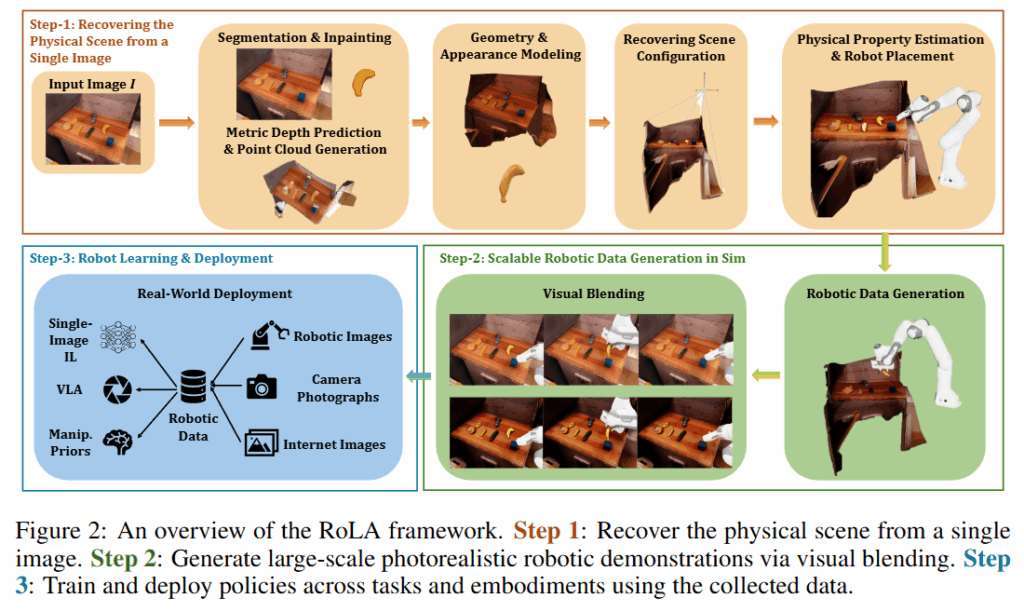
Recovering the physical scene from a single image
입력으로 한 장의 RGB 이미지 I가 주어졌을 때, 이 이미지는 어떤 물리적 장면 S를 카메라 C로 촬영한 결과라고 볼 수 있으며, I = π(S; C) 로 표현합니다. 여기서 π는 카메라의 projection function이고, C는 카메라의 intrinsics와 extrinsics 파라미터로 정의됩니다. 장면 S는 {O (object), B(background)}로 분류합니다. Textured mesh는 M, 물체의 position과 orientation을 각각 p,q, 물리량은 P로 나타냅니다. 전체 파이프라인의 1차적인 목표는 단일 이미지 I에서부터 { M, P, p, q, C }를 전부 복원하는 것입니다.
먼저 이미지로부터 장면의 기하적인 구조와 텍스쳐를 얻습니다. 객체들의 3D 모델과 배경의 3D 모델을 각각 구성합니다. Grounded Sam을 활용해 객체들을 segmentation 하고 wonder3D를 활용해 각 객체에 해당하는 mesh를 구성합니다. 이후 객체들을 뽑아내고 남은 자리를 image inpainting 모델을 활용해 메꿔줍니다. 여기서 전경과 배경이 분리된채, 각각 완성된 이미지들로 변환해줍니다. 이후에는 Depth Pro를 활용해 카메라 intrinsics와 배경 이미지에 대한 depth의 추론을 진행후 pointcloud로 변환해줍니다. 이 결과를 통해 height map을 복원해 배경에 대한 복원을 완료한다고 합니다. 여기까지 진행하면 K, 배경, 전경 메쉬들이 구성됩니다.
이제 객체의 size를 결정하고, 올바른 position과 orientation에 전경 객체들을 위치시키면 됩니다. 이를 위해 먼저 이미지 기반의 scale을 가지고 있는 mesh와 직전에 추론한 pointcloud를 가지고 mesh to point 알고리즘을 활용하여 전경 객체들의 크리를 정합하고, 정확한 위치와 방향에 위치하도록 보정한다고 합니다. Mesh to point는 1992년 제안된 고전적인 알고리즘입니다. 이를 통해 M, p,q또한 얻을 수 있습니다.
이후 시뮬레이션 상의 카메라의 위치 (extrinsic)을 정하기 위해 저자들은 supported plane 개념을 가지고 scene을 정합했습니다. 예를 들어 장면이 탁상 위라면 책상 상판이, 바닥 위라면 바닥면이 지지 평면입니다. 로봇 작업에서 이 지지면은 항상 중력의 방향과 수직이라고 가정할 수 있습니다. 먼저 배경의 pointcloud에서 바닥점 과평면 추정 알고리즘을 적용해 바닥 또는 책상 등 평평한 지지면의 법선 벡터n을 추출합니다. 그리고 n을 world 좌표(시뮬레이션)의 z축 으로 정렬하는 회전 행렬 R을 계산합니다. 이는 Rodrigues 공식을 통해 n을 단위 벡터z=[0,0,1]^T로 회전시키는 회전으로 다음과 같이 표기됩니다.
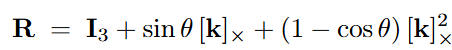
이렇게 계산된 식을 통해서 카메라의 위치를 구하고, 최종적으로 scene 복원에 필요한 모든 파라미터인 { M, P, p, q, C}를 전부 복원해줍니다. 물리적인 속성의 경우 여타 연구들과 마찬가지로 VLM에게 프롬프팅 해 추정된 속성을 그대로 활용했다고 합니다.
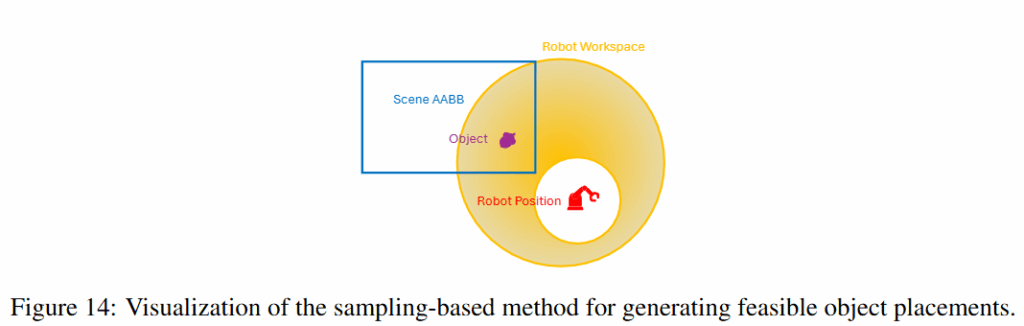
이제 만들어진 scene에 로봇을 두어야 하는데요, 위와 같이 로봇의 work space를 3D shell 모양으로 근사한 다음, 해당 영역이 작업 영역의 전체 scene의 AABB를 덮도록 베이스 위치들을 여러군데 정해서 무작위로 샘플링 해준다고 합니다. 해당 위치들 중 로봇이 기존 배경이나 객체와 collision이 일어나는 배치들은 필터링 하고, 그렇지 않은 영역들에 대해서 다양한 로봇 배치를 진행한다고 합니다. 이렇게 완성된 scene에서 시뮬레이션 데이터를 취득합니다.
Robotic Data Generation

데이터를 취득하는 과정은 특별한게 없습니다. 만들어진 시뮬레이션 환경 내에서 직접 space mouse나 키보드로 teleoperation을 진행하거나, CuRobo를 통한 motion planning을 진행한다고 합니다. Motion planning의 경우 위 figure 13과 같이 사진으로 부터 DINOv2 인코더 feature를 통해 파지점의 6d pose를 직접 예측하는 디코더 head를 학습시킨 신경망을 학습시켜 활용합니다. Pretrained manipulation policy를 활용한다고 하기도 하네요. 데이터 취득 시에는 background와 object를 더 사실적으로 합성하는 visual blending이라는 기법이 등장하는데, 이건 아래와 같이 전에 리뷰한 Re3Sim에서의 visual blending과 유사하게 z-buffer를 활용해서 occlusion을 잘 반영하는 정도라고 생각하시면 될 것 같습니다. 시뮬레이션 데이터는 {로봇 액션, RGB, Depth}쌍을 얻어준다고 합니다. 취득한 데이터로 VLA들을 학습시키면 파이프라인의 완성입니다.
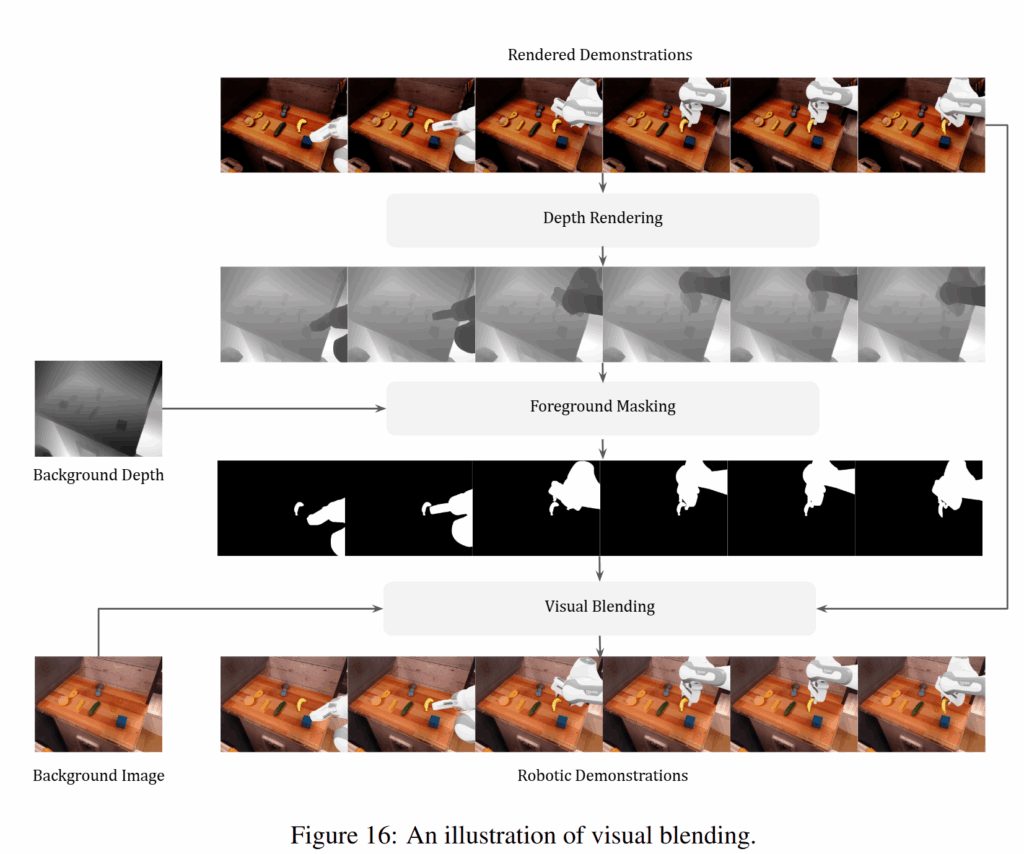
Experiments
저자들은 RoLA의 성능을 다각도로 검증하기 위해 다음의 핵심 질문들을 설정하고 실험을 진행했다고 합니다
- Q1: 단일 이미지로 복원한 장면이 실제로 로봇 정책 학습에 유용한가? (멀티뷰로 정밀 복원한 경우와 성능 차이는 어떠한가?)
- Q2: RoLA를 통해 효율적으로 대량의 로봇 데모 데이터를 생성할 수 있는가? 그리고 그 데이터 품질은 기존 기법들보다 뛰어난가?
- Q3: RoLA로 단일 이미지 기반의 로봇 학습이 실제 가능하며, 휴머노이드 등 다양한 형태의 로봇에도 적용될 수 있는가?
- Q4: RoLA를 활용해 대규모 VLA 모델을 훈련할 수 있는가? 또한 인터넷 이미지를 활용한 학습으로 로봇 성능 향상을 이끌어낼 수 있는가?
- Q5: RoLA의 시각적 블렌딩은 성능에 얼마나 기여하는가?
Q1. Physical Scene Recovery
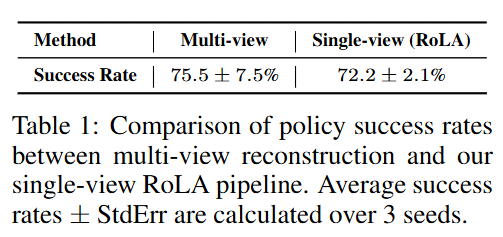
단일 이미지만으로 복원한 장면이 정확한 물리 특성을 재현하는지 검증하기 위해, RoLA와 멀티뷰 3D 복원 기법을 비교하는 실험을 수행했습니다. 바나나를 집어 stovetop 에 두기에 대해, 한 방법은 멀티뷰 카메라로 장면을 스캔하여 디지털 트윈을 만들고, 다른 하나는 RoLA의 단일 이미지 파이프라인으로 장면을 복원했습니다. 두 환경 모두에서 200개의 로봇 데모를 수집한 뒤 Diffusion Policy를 학습시켜 현실에서 평가했습니다. Table 1의 결과를 보면, 멀티뷰 방식의 정책 성공률이 약 75.5%, RoLA 단일뷰 방식은 72.2%로 거의 유사한 수준이며, 이는 단일 이미지로도 멀티뷰에 필적하는 현실감 있는 로봇 학습 환경을 구축할 수 있음을 보여주었습니다. 단일 이미지만으로 나온 성능임을 보면 요즘 foundation model들의 성능에 감탄하게 되고, monocular depth estimation 연구들의 연구 가치도 드러나는 부분이 아닐까,, 싶습니다.
Q2. Robotic Data Generation
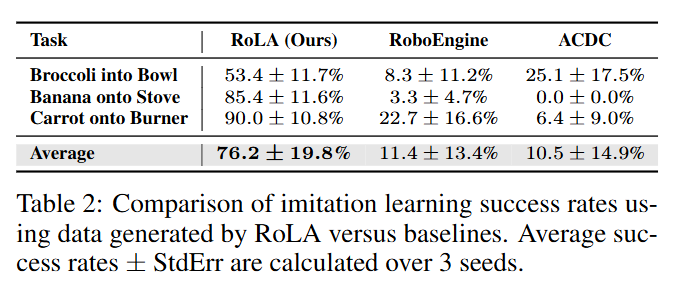
RoLA로 생성한 로봇 학습 데이터의 품질을 평가하기 위해, 모방 학습 환경에서 기존 기법들과 비교하였습니다. 세 가지 매니퓰레이션 과제에 대하여, 서로 다른 데이터 소스로 학습한 정책들의 성공률을 비교했습니다. 비교 대상은 ACDC (digital cousin)과 RoboEngine입니다. 각 방법으로 과제당 200개의 데모를 만들고 동일한 방법으로 정책을 학습한 뒤, 시뮬레이터에서 성능을 평가하였습니다. Table 2를 보면 RoLA가 모든 과제에서 높은 성능을 보여줍니다. 특이한게 바나나를 stove에 올리는 task의 경우 RoLA 데이터로 학습한 정책은 85.4% 성공률을 기록한 반면, RoboEngine 기반은 3.3%, ACDC 기반은 0%를 보여주었는데, acdc의 경우 검색 대상 데이터셋에 바나나가 없나..? 싶었습니다. 저자들은 RoLA가 복원한 물리 장면에서 수집한 시연 데이터가, 기존의 데이터에서의 검색 또는 픽셀 편집 기반 데이터보다 훨씬 물리적으로 정확하고 학습에 유용하기 때문이라고 합니다.
Q3. Single Image Robot Learning

RoLA를 활용하면 한 장의 이미지로 다양한 real robot을 학습시킬 수 있는가?에 대한 실험입니다. 이를 위해 바나나를 싱크대 안에 내려놓기와 음료 따르기를 진행했습니다. 이 때는 이미지 한 장을 D415로 촬영해 진행했다고 합니다. RoLA로부터 복원된 장면에서 200개의 데이터를 취득해 Franka Research3와 Unitree G1을 각각 학습시켰다고 합니다.
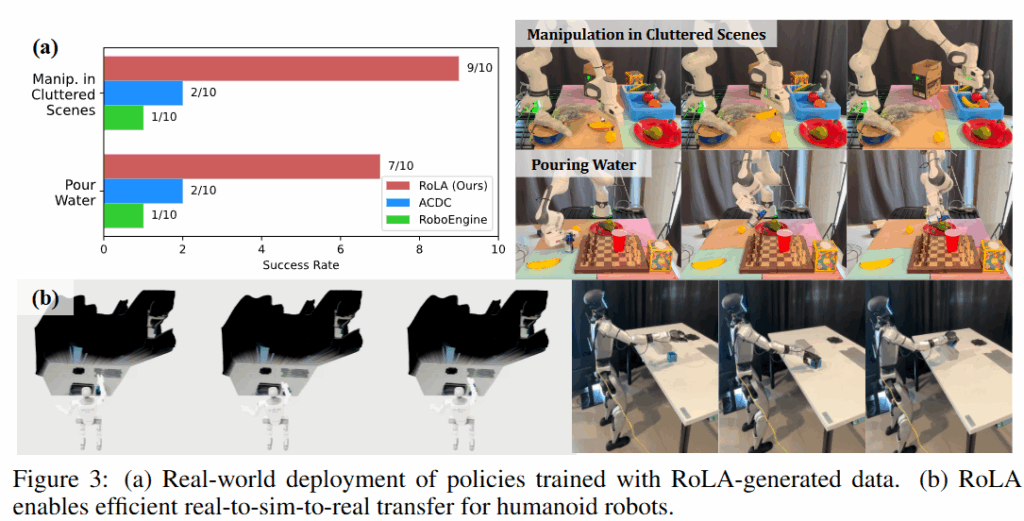
Q4. Training VLA with RoLA

저자들은 더 나아가 SimplerEnv에서 작동할 수 있는 VLA를 학습시키기 위해 RoLA를 활용해 6만개의 시연 데이터를 수집해 Qwen 2.5를 VLM 백본으로 사용하는 VLA를 학습시켰다고 합니다. 해당 환경에서 다음과 같은 success rate를 얻을 수 있었다고 합니다. 다만 이는 sim to real gap이 풀리지 않은 부분이라 현실에서 평가하지 않은것은 조금 아쉽지 않나.. 싶습니다.

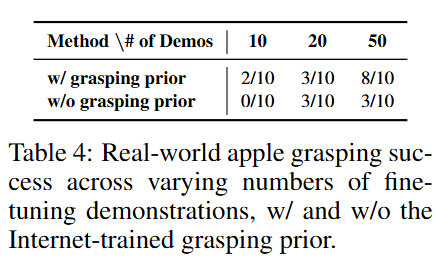
인터넷 이미지만을 가지고도 학습이 가능한가?에 대해서도 평가를 진행했는데, 다음과 같이 다양한 이미지 데이터로부터 사과를 집는 action을 학습해 아래 table4와 같은 결과를 보여주었습니다. 앞서 언급했던 grasping pose 추론 모듈을 활용했을 때 훨씬 더 성능이 좋아졌다고 합니다.
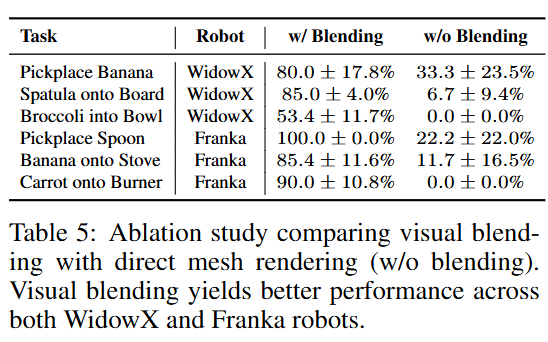
Q5. Does visual blending enhance performance?
논문에도 한 문장으로 끝났는데요, 다양한 로봇 세팅에서 visual blending이 있을 때 훨씬 더 좋은 성능을 보여주었다고 합니다.
Conclusion
확실히 단일 이미지에서 데이터 scaling을 할 수 있는 만큼 발전된다면 활용성이 엄청 커질 것으로 생각이 드는데요, 다만 물체가 복잡해지거나 task가 dextrous 한 경우에는 foundation model들에 의존하는 만큼 한계가 명확하지 않나 생각이 듭니다. 해당 논문에서 얻을 수 있는 인사이트는 실제 depth pro같은 모델들이 pick and place 수준의 task를 학습시킬 때는 생각보다 효용성이 높고, 추론된 pointcloud와 카메라 파라미터 만으로도 나름 cluttered scene을 학습시킬 수 있구나! 인 것 같습니다. Depth쪽 논문들도 시간이 된다면 좀 정리해가면서 필요하다면 활용해볼 수 있지 않을까 싶습니다.
안녕하세요, 좋은 리뷰 감사합니다. 덕분에 Real to Sim to Real로 어떻게 학습을 진행하는지 이해할 수 있었습니다.
리뷰 읽다 궁금한 점이 있어 간단히 질문 남기겠습니다.
1. 서두에서 제안하는 프레임워크가 ‘단일 이미지에서 3D 기하 추정 후 물리 속성까지 고려한 장면을 복원’ 한다고 작성해주셨는데, object들의 position/orientation과 시뮬레이션 상 카메라 위치를 구하는것 까지는 이해가 되는데 다른 물리 속성들은 어떻게 구하는지 헷갈립니다. texture mesh, 물리량 p가 물리적 속성인 것 같은데 이들은 어떻게 구하게 되나요? VLM 프롬프팅 해주면 뭔가 자연어 출력으로 파라미터들이 나오는건가요?
2. 기존에는 특정 하드웨어나 연구실 환경에 종속되어야만 한다는 한계가 있었지만, 제안하는 기법은 그런 제약이 없어져서 굉장히 다양한 환경을 모사해서 강건하게 동작할 수 있을 것 같습니다. 기존 방법론들이 조금만 환경이 틀어져도 잘 동작하지 않는다는 한계를 극복할 수 있을 것 같은데, 관련된 정량적/정성적인 실험 결과나 분석이 있나요?
감사합니다.
안녕하세요 재연님, 리뷰 읽어주셔서 감사합니다.
1. 말씀하신대로 texture나 기타 물리적인 속성은 VLM에 템플릿을 제공해 대답하게 한 뒤 결과로 나온 자연어 출력(사전 정의된 파라미터들 : 예를 들면 texture의 경우 metalic, marble 등등) 을 사람이 직접 시뮬레이터에서 매핑해줍니다.
2. Figure5가 말씀하신 것에 대한 정성적인 결과입니다. 좌측에 보이는 다양한 인터넷 이미지들 기반으로 visuomotor policy를 학습한 후 기존 방법론들과 정량적인 평가를 진행했을떄도 우수한 결과를 얻었는데, 해당 실험이 의미하는 것이 “환경이 틀어져도 기존 시뮬레이션 기반 데이터 수집 방법론들보다 우수하다”로 생각하시면 될 것 같습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
뭔가 Grounded-SAM + Wonder3D + inpainting + DepthPro + 정합 + 시뮬 구성까지 파이프라인이 꽤 무거워 보이는데, 이미지 1 장당 처리 시간이나 필요 GPU가 어느정도인지 궁금합니다. 데이터 수집관점에서는 비슷한 연구들은 이런 부분은 아예 고려를 안하는지도 궁금합니다. 감사합니다.
리뷰 잘 읽었습니다 영규님.
Q1의 실험 결과가 꽤나 놀랍긴하네요. multi랑 single 이랑 차이가 크지 않다는게,, 근데 +- 성능은 좀 차이가 나는데, 이는 어떻게 해석하면 될까요?
그리고 간단한 질문이긴한데,, wonder3D 는 입력이미지가 한장이 아니라, 여러 views 의 이미지를 입력으로 받아서 mesh 를 구성하는 방법론인가요?