그래서 AI가 그렇게 좋다는데, 지금 기술로 Video Understanding은 어디까지 가능하지?와 같은 질문에 해답이 될 수 있는 논문을 소개합니다. 본 논문은 Agentic Search를 통한 Longvideo benchmark에서의 성능을 보입니다. 특히, LVBench 벤치마크에서 74.2%로 기존의 모든 방법을 뛰어넘는 성능으로 제시한 agent의 효과를 검증했습니다. 그럼 리뷰를 시작해보겠습니다.
Agentic Search?
가장 먼저 논문에 소개된 Agentic Search란 LLM의 활용 능력을 극대화한 검색 기법입니다. 일반적으로 LLM은 자체에 추론하고 계획을 설계하는 능력이 있다고 알려져 있습니다. x리뷰로도 소개되었던 [CVPR 2025] Video Summarization with Large Language Models 역시 LLM의 이러한 능력을 활용해 비디오 요약테스크를 수행하는 방법을 제안한 것입니다. Agentic Search 또한 LLM의 추론 및 계획 능력을 활용한 검색 기법이라고 볼 수 있습니다.
기존의 검색은 사람이 설계한 파이프라인대로 진행했지만, agentic search를 활용하면 조금 더 상황에 맞는 검색을 수행할 수 있는것이지요. 질문이 모호하더라도 AI를 통해 문제를 재설계하여 검색을 수행하도록 하는게 agentic search의 장점입니다.
Position of this Paper.
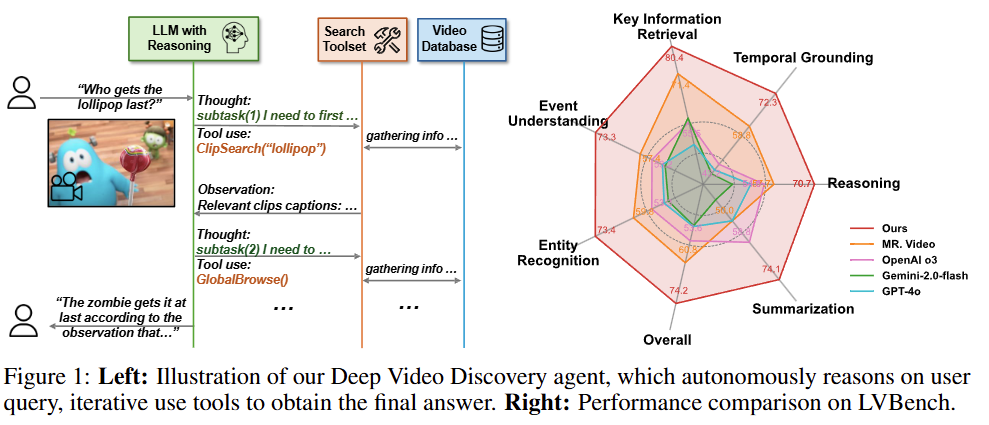
본 논문은 Long video understanding 테스크를 수행한 논문입니다. Figure1의 좌측처럼 질의에 맞는 대응이 가능한 에이전트(Deep Video Discovery agent)를 제안하였으며, 이를 활용할 때 유명 Long-video understanding 벤치마크인 LVBench에서 우측과 같이 우수성을 보인것입니다. Key information Retrieval, Temporal Grounding, Reasoning 등 다양한 지표에서 우수한 성적을 보였으며, 전반적인 성능치가 우수함을 확인할 수 있습니다.
기존에도 LLMs을 통해 검색의 자유도와 정확도를 높인 연구(Deep Search)는 있었으나, Long video에 대한 테스크 수행에 이를 적용한 연구는 없었으며 해당 논문은 Long video 문제를 multi-step information search 문제로 접근하여 agentic search를 통해 해결한 첫 논문(Deep Video Discovery)입니다.
Deep Video Discovery, The methods.
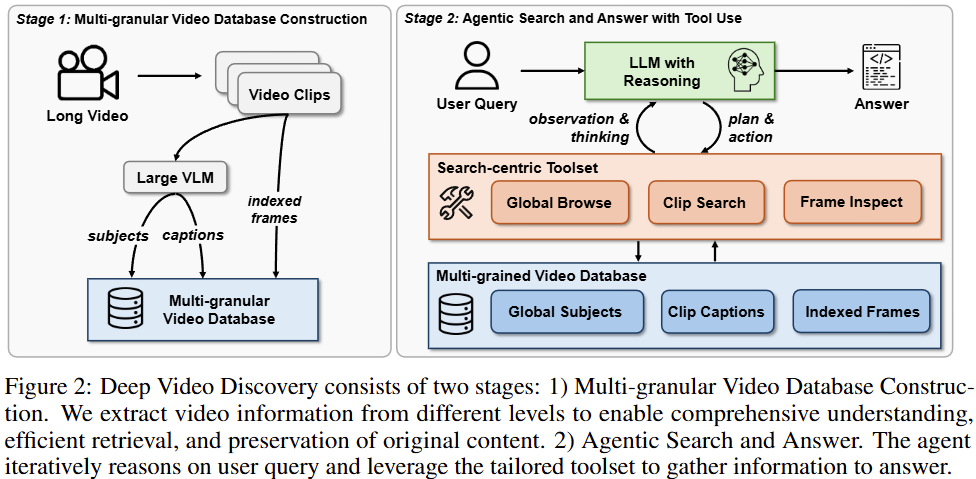
Long video understanding을 위한 에이전트는 데이터베이스, Toolset, 에이전트의 자동화를 관리할 LLM으로 구성되어있습니다. 각 구성요소의 특징을 살펴보겠습니다.
1) 데이터베이스
논문은 여러 단계로 구성된 데이터베이스(multi-grained structed database)를 구축했습니다. 에이전트는 질의의 난이도에 따라 적절한 정보를 탐색해야합니다. 너무 디테일한 정보인 프레임들로만 구성된다면 검색의 효율이 너무낮을것이고, 비디오 전체의 맥락으로만 데이터베이스가 구성된다면 응답의 수준에 제약이 생길 것 입니다. 이것이 multi-grained database가 필요한 이유입니다.
multi-grained 수준은 Figure2의 좌측에서 확인할 수 있듯이 subjects(global video level) / caption(clip level) / frames(frame level) 삼단계로 나뉩니다. frame이 가장 디테일하며 subject가 가장 포괄적입니다. 비디오에서 이러한 요소를 추출하는 방법은 아래와 같습니다. 먼저 5초 단위로 비디오를 나눕니다. 이후 1초당 2개의 프레임을 샘플링해 비디오의 전처리를 수행합니다. 이후 VLM을 통해 frame입력으로 caption을 생성합니다. 또한 caption을 활용하여 subject를 생성합니다. 이렇게 비디오 하나에 대해서 비디오의 주제(S), N개의 클립(1클립당 5초)에 대한 프레임정보(f)/캡션정보(c)/캡션의 임베딩 특징량(e)를 데이터베이스로 구성하게 됩니다.
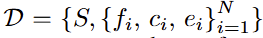
2) Agentic Search and Answer with Tool use
데이터베이스를 구성하고 나서는, 이를 활용해 응답을 생성하는 단계가 필수적입니다. 논문에서는 Agentic Search를 도입한 해당 방법인 Agentic Search and Answer with Tool use(ASA)를 설계했습니다. 먼저 Agent가 사용할 수 있는 Tool인 Action space는 Table1과 같습니다. 즉, Agent는 답변을 생성할 때 데이터베이스에서 아래의 3가지 검색을 수행할 수 있고, 검색이 충분하다고 판단될때 Answer을 호출하여 답변을 생성할 수 있는 것입니다.

각 Tool(=Action)에 대해 보충설명 해보겠습니다. 먼저 Global browse는 Database와 user query를 입력으로 하고 비디오의 global summaries를 출력으로 하는 동작입니다. 이때 두타입의 요약이 제공되는데, 질의에 관계없이 비디오 자체를 요약한 subject-centric 요약과 질의에 적합한 요약인 event-centric 요약입니다. 앞서서 subject-centric 요약이 caption을 입력으로 VLM을 통해 생성된다고 했었는데, event-centric 요약 역시 쿼리와 샘플링된 프레임을 VLM에 입력하여 주제와 유사해보이는 가치있는 이벤트에 대해 LLM에 의존적으로 생성하게 됩니다.
다음으로 Clip Search는 frame보다는 빠르게 세부 정보를 검색하기 위한 Tool입니다. 비디오의 캡션 수준으로 요청된 질의와 유사한 top k개의 비디오 클립을 찾아내는 것입니다. 질의에 대한 정확한 시간영역을 찾기위해 해당 tool을 반복 호출하여 질의를 재구성하며 정밀한 temporal segments를 찾는것이 해당 action(tool)의 목적입니다.
마지막으로 Frame inspect는 반복적인 Clip search를 통해 얻은 답변의 구간인 [t_s, t_e], 비디오 그리고 쿼리를 입력으로 하며 답변을 생성(Answer을 호출)하게 되는 마지막 단계입니다. 구간 내에서 최대 50개의 프레임을 샘플링하며 해당 프레임과 수정된 질의를 VLM에 입력해 답변을 생성하도록 합니다.
위의 Tool을 사용하는 전반적인 agent의 답변생성 과정은 아래의 Algorithm1과 같습니다. 무한반복이 발생하지 않도록 미리 N회의 agent가 action을 수행할 최대 횟수를 지정해놓고 알고리즘을 수행하게 됩니다. O는 관찰로 에이전트가 행동을 수행한 후 얻은 결과, H는 에이전트의 문맥으로 에이전트의 모든 정보인 사용자의 초기질문, 취했던 엑션, 엑션들의 결과를 모두 포함하는 정보입니다. 해당 기록(H)을 통해 LLM을 기반으로 다음에 취해야할 행동(R)을 추론하고, R을 기반으로 에이전트가 실제 수행할 action과 action parameter(top -k의 k등)를 선택합니다. 이후 선택한 action을 수행하고 History(H)를 업데이트하며 answer가 호출되거나 N회의 추론으로 answer가 강제 호출 될 때 까지 반복합니다.

Experiment
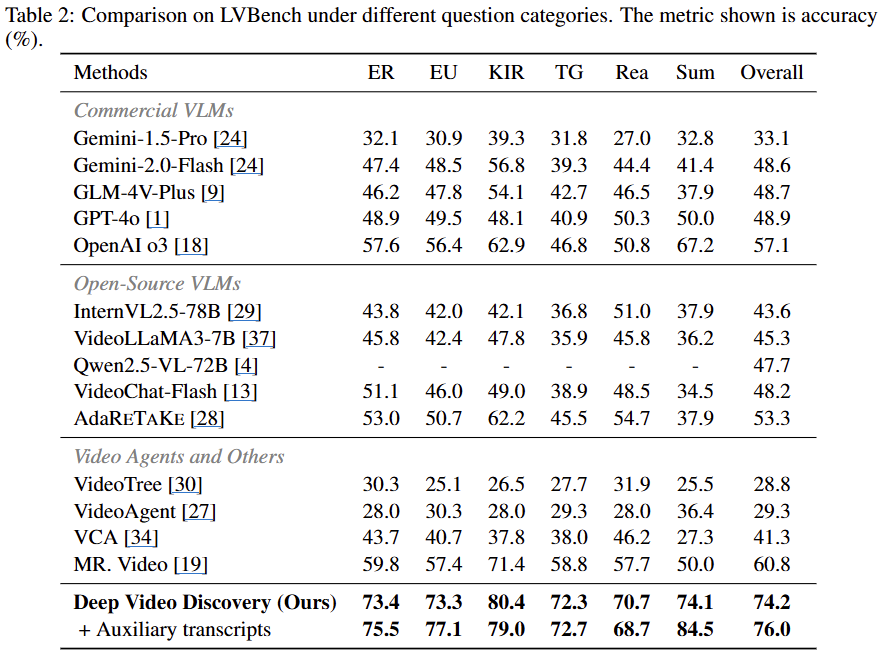
논문은 제안한 알고리즘과 에이전트가 다양한 Long-video understanding benchmark에서 우수성을 보임을 실험을 통해 증명했습니다. 가장 긴 벤치마크인 LVBench를 메인으로 모든 지표에 대해 리포팅한 결과는 Table2와 같습니다. 그 외에도 LongVideoBench, VideoMME, EgoSchema에 대한 벤치마크를 Table3에서 확인할 수 있습니다. VLM기반의 방법론, Agent 기반의 방법론에 대해 모두 수행되었으며 모든 방법론/모든 벤치마크에서 제안한 DVD의 우수성을 확인할 수 있습니다.

다음으로 각 tool에 대한 유용성과 LLM의 영향력을 검토할 수 있는 ablation study입니다. 먼저 Table4는 각 과정에 개입하는 LLM을 정확도가 더 낮은 버전으로 바꾸었을때 성능 등락을, Table4는 각 tool의 부재에 따른 성능 등락을 의미합니다. 실험 결과 agent의 맥락(history)를 기반으로 다음 action을 추론하는 reasoning model이 agentic system에서 가장 중요함을 알 수 있으며, Table5의 실험을 통하 각 단계가 모두 필수적임을 확인했습니다.

이상으로 리뷰를 마치겠습니다. 감사합니다.