안녕하세요. 오늘 X-Review에서 소개해드릴 논문은 24년도 TCSVT 저널에 게재된 <Question-Aware Global-Local Video Understanding Network for Audio-Visual Question Answering>입니다. 저널의 review 기간을 감안한다면 절대적 성능은 그리 높지 않겠지만, question-aware라는 키워드를 어떻게 풀어냈는지 궁금하여 읽게 되었습니다.
결론적으로는 제가 지금까지 리뷰했던 여타 AVQA 논문들과 마찬가지로 Self-attention, Cross-attention의 연속인지라, 빠르게 정리해보겠습니다. 그럼 리뷰 시작하겠습니다.
1. Introduction
22년도 이전에는 질문에 대해 이미지를 보고 답을 만들어내는 Visual Question Answering, 오디오를 듣고 Audio Question Answering이 많이 연구되고 있었습니다. 이후 AVQA, MUSIC-AVQA라는 데이터셋이 등장하며 비디오와 비디오에 포함된 오디오를 함께 활용해 질문에 대한 정확한 답을 만들어내는 AVQA (Audio-Visual Question Answering) task가 활발히 연구되고 있습니다.
AVQA는 모달리티가 하나 추가된만큼 더욱 복합적인 이해 능력을 요구합니다. 그러나 이전 AVQA 방법론들은 비디오와 오디오의 global 정보만을 활용해왔고, 그렇기 때문에 질문에 답하기엔 부족한 장면 이해 능력을 갖추고 있었습니다. 이를 보완하기 위해 입력 질문을 바탕으로 오디오와 비디오의 local한 정보를 추리고 다시 이 정보들을 잘 fusion하는 과정이 필요하다고 주장합니다.

위 그림 1을 보시면 동일한 비디오도 질문이 달라지면 실제로 오디오와 비디오에서 집중해야하는 구간이 달라지고, 심지어는 질문 문장에서도 집중해야하는 단어가 따로 존재하는 것을 볼 수 있습니다. 그래서 저자는 오디오와 비디오 전체 scene 정보를 담는 global feature와 질문을 기반으로 중요하게 추려낸 오디오와 비디오의 local 정보를 적절히 뽑고 fusion해서 써야한다고 주장합니다.
위와 같은 목적을 달성하기 위해, 저자는 말 그대로 오디오와 비디오의 global, local feature를 모두 만들어내고 fusion하는 방법론을 제안합니다. 여기서 한 가지 짚을 점은 local과 global이 저희가 예상했듯 시간축에서 좁은 구간, 넓은 구간을 명시적으로 의미하는 것은 아니고, 질문의 text feature와 한번 interaction 한 오디오, 비디오 feature에 local 정보라는 이름을 붙여주는 것입니다.
방법론은 총 두 단계로 구성됩니다. 첫 번째 단계에서는 모델이 오디오와 비디오에 대한 global, local feature를 만들어냅니다. Global feature는 저자가 설계한 Co-attention 모듈을 거쳐 만들어지며 local feature는 Question-aware attention 모듈을 통해 만들어집니다. 두 번째 단계에서는 앞서 뽑은 이 global, local feature가 서로 정제되고 질문 정보까지 담아내면서 최종 feature를 만들어냅니다. 이 최종 feature는 간단한 분류기에 들어가 질문에 대한 정답을 분류하는 것입니다.
자세한 내용은 아래 방법론에서 알아보고, 기본적으로 Co-attention 모듈과 Question-aware attention 모듈 구조만 아시면 쉽게 이해하실 것입니다.
2. Method
2.1 Workflow of the Framework
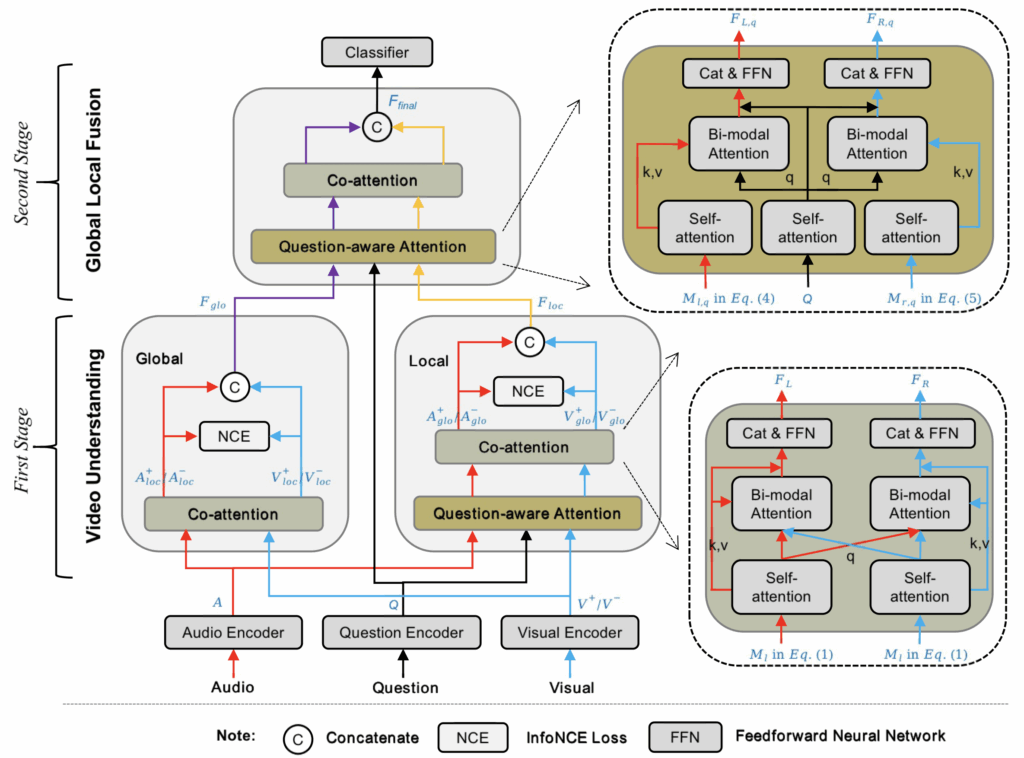
앞서 학습이 두 개 stage로 구성되어있다고 말씀드렸지만, 좀 더 세부적으로는 아래 5단계로 나눠볼 수 있습니다.
- 각각의 모달리티 인코더가 오디오, 비디오, 텍스트 feature 추출
- 1단계의 global, local 브랜치에서 앞서 뽑은 feature들을 정제하고 interact
- 동시에 각 브랜치에서의 contrastive learning을 통해 오디오와 비디오 정보 정합
- 2단계에서는 global, local feature를 질문 기반으로 fusion하여 최종 feature 생성
- 최종 feature는 분류기에 입력되어 예측값 생성
이 과정은 위 그림 2에 나타나있고, 1단계의 global, local 브랜치 흐름과 2단계의 global, local feature fusion 과정을 보실 수 있습니다. 특히 그림 2 우측에는 저자가 설계한 Co-attention, Question-aware attention 모듈의 구조도 확인하실 수 있습니다. 방법론의 설계 의도는 모달리티 특징으로부터 global, local 정보를 추출하고 이 과정에서 지속적으로 질문 정보를 주입하는 것입니다. 또한 InfoNCE loss를 넣어 모달리티 간 정합을 맞춰줍니다.
이제부터는 기본적인 feature 추출 (2.1.1), 방법론의 핵심이 되는 Co-attention 모듈 (2.1.2), Question-aware 모듈 (2.1.3)을 설명드리겠습니다.
2.1.1 Feature Extraction
오디오를 포함하는 비디오가 입력되면, 이를 고정된 T개의 segment로 나눕니다. MUSIC-AVQA는 한 비디오가 60초로 고정되어있고 1초 단위의 segment를 사용하여서, 대략 T=60으로 보시면 좋을 것 같습니다.
같은 비디오로부터 나온 오디오와 비디오 쌍은 \{A_{t}, V_{t}^{+}\}_{t=1}^{T}, 동일 오디오를 기준으로 다른 비디오와의 쌍은 \{A_{t}, V_{t}^{-}\}_{t=1}^{T}로 표현할 수 있습니다. V_{t}^{-}는 추후 대조학습을 위해 정의해둔 notation이라 보시면 됩니다. 마지막으로 질문은 K개 토큰으로 구성된 feature \{Q_{k}\}_{k=1}^{K}로 표현됩니다.
각 모달리티 인코더는 ResNet-18, VGGish, LSTM입니다. 오디오, 비디오, 텍스트 정보는 각 인코더를 통해 feature a_{t}, v_{t}^{+}, v_{t}^{-}, q_{k}로 projection 됩니다.
2.1.2 Co-attention
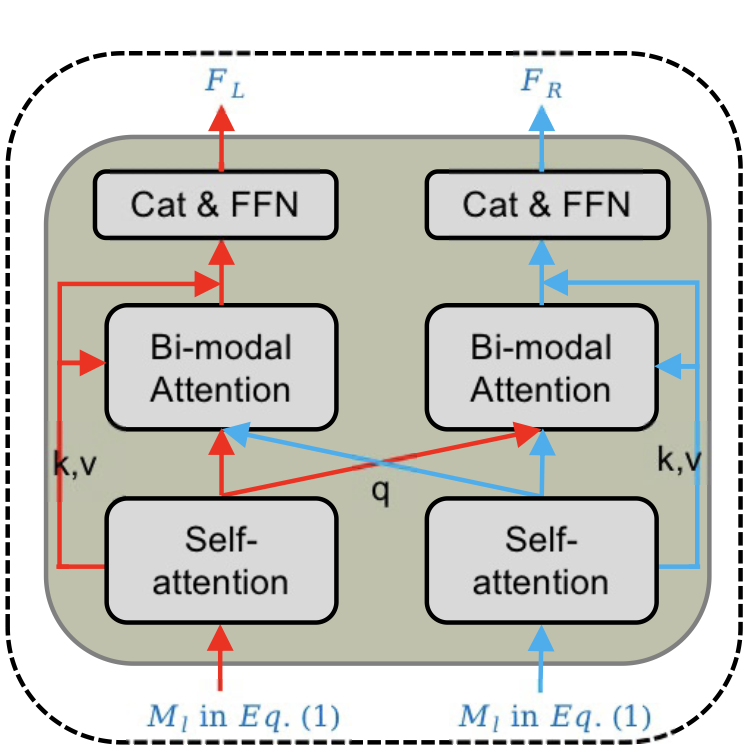
Co-attention 모듈은 위 그림 2-1과 같습니다. 우선 여기서 진짜 model의 forward 과정을 설명드릴 것은 아니고 Co-attention 모듈과 Question-aware attention 모듈의 동작 과정을 설명 드린 다음 forward 과정을 간단히만 말씀드리겠습니다.
본 모듈은 M_{l}, M_{r}을 입력받습니다. 각각은 두 모달리티 중 하나의 feature로 그림 상 left, right을 표현하기 위해 이와 같은 notation이 붙어있습니다. 대충 left를 오디오, right을 비디오로 두고 보시면 편하실것입니다.
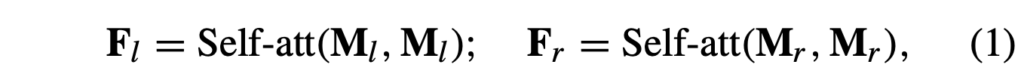
먼저 각 모달리티의 특징 내부적으로 long-range interdependent 정보를 주입해주기 위해 self-attention을 위 수식 (1)과 같이 수행합니다.
다음으로 수식 (1)에서 얻은 feature F_{l}, F_{r}은 서로의 정보를 통해 서로를 정제하는 Bi-modal attention 연산을 포함하여 아래 수식 (2)와 같은 과정을 거칩니다.
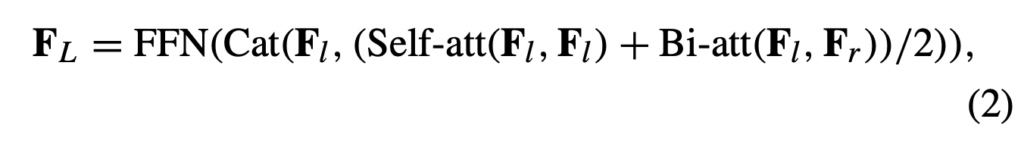
그림 2-1과 위 수식을 비교해보았을 때, 아마 저자가 이야기하는 Bi-modal attention은 스스로에 대한 self-attention + 타 모달리티 특징과의 cross-attention을 평균내는 연산을 칭하는 것 같습니다. 수식 (2)에는 먼저 residual로 들어갈 F_{l}이 존재하고, 자신에 대한 self-attention, l, r의 cross-attention 결과가 평균내어져 concat + FFN 과정을 거치는 것을 볼 수 있습니다. 논문에서는 이러한 설계를 통해 self-modality attentional feature, interactive influence를 알 수 있게 된다고 하는데 크게 와닿지는 않는듯 합니다.
2.1.3 Question-Aware Feature Extraction
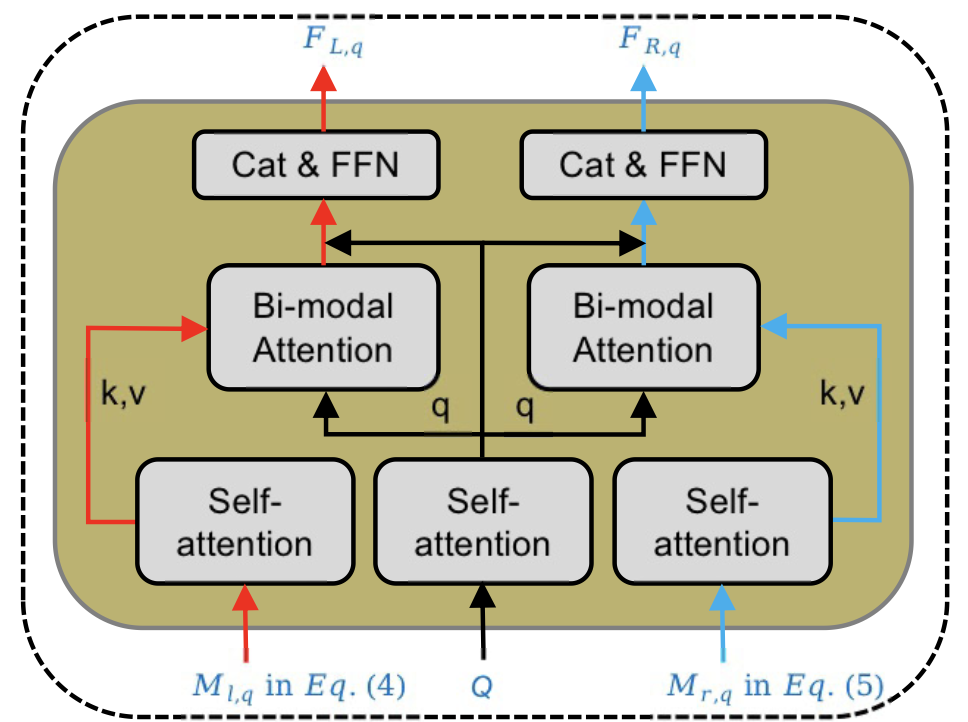
Question-aware attention 모듈은 위 그림 2-2와 같습니다. 이 모듈도 결국은 self-attention과 cross-attention의 연속이네요.
본 모듈은 아래 수식 (4), (5), (6)에서 볼 수 있듯 feature M_{l, q}, M_{r, q}, Q를 입력받습니다. 논문을 쭉 살펴본 결과 질문을 바탕으로 M_{l, q}를 따로 만들어내지 않기 때문에 그냥 M_{l}과 동일한 값이지만 본 모듈의 입력임을 표시하기 위해 q를 붙인 것으로 보입니다. 이전 모듈과 동일한 목적으로 각 입력 feature에 대한 self-attention을 아래 수식과 같이 수행합니다.
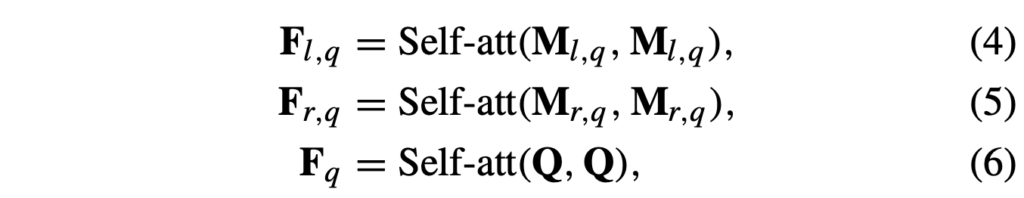
다음으로는 question-aware 성질을 부여하기 위해 질문과의 cross-attention을 아래 수식 (7), (8)과 같이 수행합니다. 별다른 과정은 없고 질문 feature, 질문 feature와 cross-attention한 모달리티 feature를 concat 후 FFN에 태워주는 모습입니다.
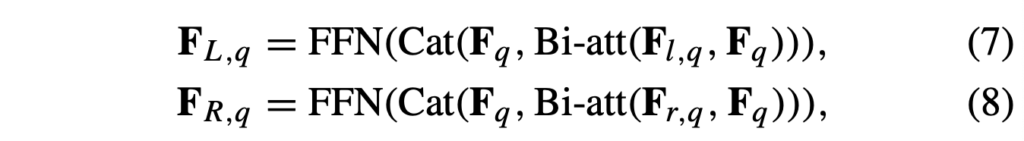
여기까지 두 모듈에 대해 알아보았고, 이젠 본격적으로 그림 2에 나온 forward 과정을 설명드리겠습니다.
2.2 Stage 1: Video Understanding
모델 forward 과정은 1단계(2.2)에 등장하는 Global 브랜치(2.2.1), Local 브랜치(2.2.2), 그리고 2단계(2.3)에 등장하는 Global Local Fusion(2.3.1) 순서대로 간략히 설명드리겠습니다.
2.2.1 Global Branch
앞서도 말씀드렸지만 이 브랜치에서 뽑는 feature가 global인 이유는 질문과의 연관성을 고려하지 않기 때문입니다. 그 과정에서 비디오와 오디오 정보가 서로 합쳐지는 것입니다. 본 브랜치에서는 오디오와 비디오 feature A, V^{+}, V^{-}를 입력받아 수식 (1), (2)의 co-attention 모듈을 거칩니다. 이렇게 A_{glb}^{+}, A_{glb}^{-}, V_{glb}^{+}, V_{glb}^{-} feature를 얻을 수 있습니다.
이 feature들을 활용해 아래 수식 (9)와 같이 단순 concat으로 F_{glb}를 얻습니다. 이 feature는 2단계에서 다시 활용됩니다.
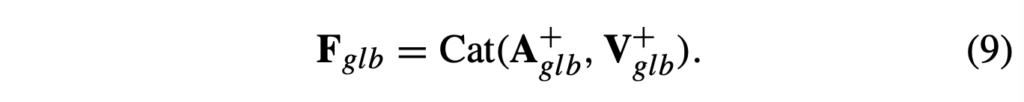
동일한 비디오로부터 온 오디오와 비디오의 정합을 맞춰주기 위해, 다른 비디오 feature를 negative로 두고 대조학습을 진행합니다. 이 때는 InfoNCE(\mathcal{L}_{glb}) loss가 아래 수식 (10)과 같이 적용됩니다. 수식에서 V_{all, glb}^{-}는 배치 내 다른 비디오의 feature를 의미합니다.
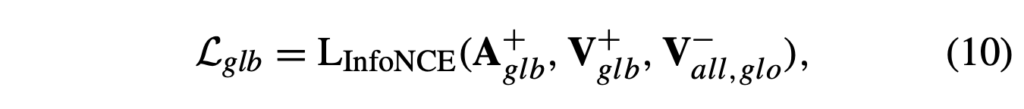
2.2.2 Local Branch
본 브랜치에서는 질문의 정보를 반영한 local 오디오, 비디오 feature를 만들어냅니다. 먼저 A, V^{+}, V^{-}, Q를 Question-aware attention 모듈과 Co-attention 모듈에 순차적으로 입력하여 수식 (4)-(8), (1)-(2)의 과정을 거칩니다. 이렇게 A_{loc}^{+}, A_{loc}^{-}, V_{loc}^{+}, V_{loc}^{-}을 얻을 수 있습니다.
이후 앞선 수식 (9)와 동일하게, 단순 concat으로 F_{loc}을 얻습니다. 이 feature도 2단계에서 다시 활용됩니다.
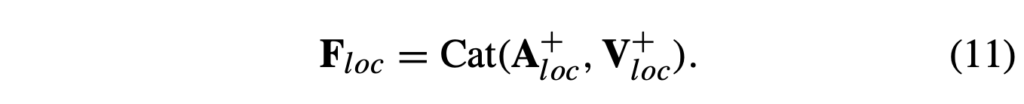
이 브랜치에서도 질문을 고려한 local feature가 배치 내 다른 비디오와는 분리되도록 아래 수식 (12)와 같은 contrastive loss를 적용해줍니다.
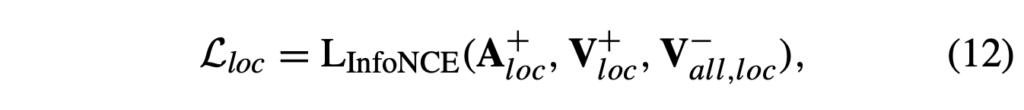
2.3 Global Local Fusion and Answer Prediction
이제 모델의 2단계와 최종 답변 생성 부분만을 남겨두고 있습니다.
2.3.1 Global-Local Fusion
최종 답변 분류에 사용할 최종 feature F_{final}을 만들기 위해, 앞서 global, local 브랜치에서 각각 뽑은 F_{glb}, F_{loc}을 활용합니다. 이 두 feature를 순차적으로 Question-aware attention, Co-attention 모듈에 넣는 것이 전부입니다. 마지막 Co-attention 모듈을 타고 나온 global, local feature를 concat하여 F_{final}이 만들어지는 것입니다. 이 feature를 FC layer에 태워 예측에 대한 확률 분포를 만듭니다.
2.3.2 Objective Function
기본적으로, 분류에 대한 지도학습 loss \mathcal{L}_{qa}는 아래 수식 (13)과 같은 CE loss입니다.
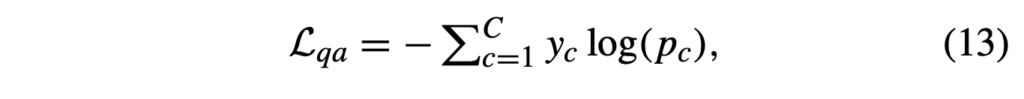
최종 학습 loss는 이 loss와 앞서 나온 각 브랜치에서의 contrastive loss를 합친 아래 수식 (14)입니다.
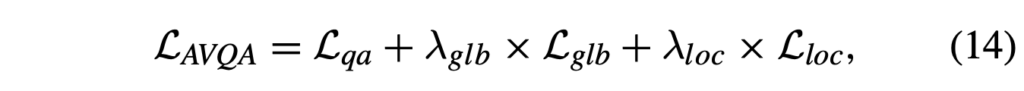
개인적으로 방법론에서 엄청난 고찰과 세심한 설계 의도를 느끼기는 힘들었지만, MUSIC-AVQA 데이터셋이 제안된 직후 나온 초기 방법론임을 감안하면 컨셉 자체는 유의미하다고 생각합니다. 이제 실험 부분으로 넘어가겠습니다.
3. Experimental Result
3.1 Main Results
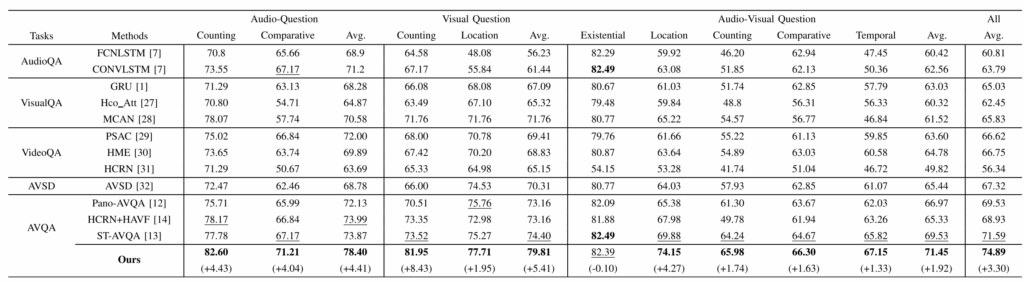
본 논문의 베이스라인이자 직접 비교되는 ST-AVQA가 바로 MUSIC-AVQA 데이터셋과 함께 제안된 초창기 방법론입니다. 전체 평균 정확도를 보았을 때 기존 71.6에서 74.9로 무려 3.3%를 올리며 모달리티 간 interaction과 question-awareness의 중요성을 보여주고 있습니다.
3.2 Ablation Study
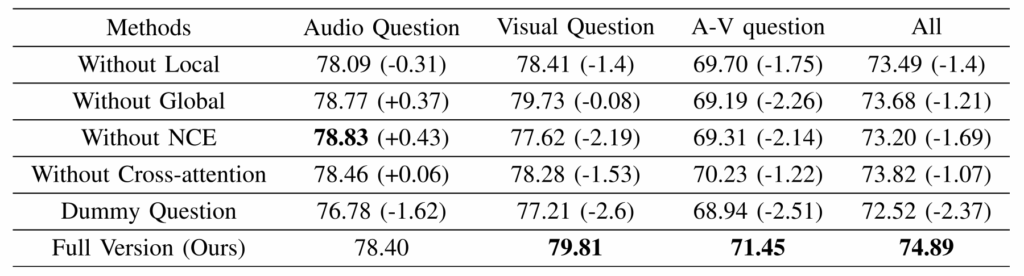
저자가 제안한 여러가지 모듈에 대한 ablation 성능입니다.
먼저 Without Local과 Without Global을 비교해보면 둘 다 성능이 떨어지지만 Local을 뺐을 때 조금 더 많이 떨어지는 것을 볼 수 있습니다. 그 와중에 오디오와 비디오 정보를 모두 잘 알아야하는 A-V question의 경우 오히려 Global을 뺐을 때 더 많이 떨어지는 점을 통해 질문 기반 정보보다 각 모달리티에 대한 정보 해석이 더 요구된다는 점을 알 수 있었습니다.
다음으로 InfoNCE를 빼면 성능이 꽤 많이 떨어지는데, 특이한 점은 Audio 관련 질문은 가장 높은 성능이 나온 것을 볼 수 있습니다. 시각 정보를 안봐도 되는 경우 굳이 두 모달리티를 정렬하는 것이 악수로 작용했다는 점을 알 수 있습니다. 근데 이 결과는 사용하는 백본에 따라, 오디오와 비디오 정합이 또 다른 양상을 보일 수 있을 것 같습니다.
Dummy Question 실험은 모델 내 question-aware attention 모듈에 1벡터를 넣어준 경우를 의미합니다. 결국 질문의 의미를 고려하지 않고 모든 segment를 동일하게 다루는 상황을 의미합니다. 이 때 가장 성능이 크게 떨어졌는데 지금에서는 당연한 이야기이지만 1벡터를 줌으로써 실제 질문 정보의 중요성을 보여주는 유의미한 실험이라고 생각합니다. 다음 스텝으로는 이 질문 feature를 얼마나 잘 정제하여 만들어줄 것이냐가 될 수 있겠네요.
정성적 결과는 중요 구간에 각자 잘 집중하고 있다는 내용이라 생략하도록 하겠습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요 현우님 좋은 리뷰 감사합니다!
co-attention에서 bi-modal attention은 스스로에 대한 self-attention과 타 모달리티와의 cross-attention의 평균을 낸 연산이라고 하였는데요 이 부분이 사용되는 이유가 궁금합니다. co-attention이라는 것이 global한 feature를 뽑기 위함인 것 같은데, 저런 구조를 사용했을 때 얻는 이점이 있을까요?
감사합니다.
안녕하세요, 현우님. 좋은 리뷰 감사드립니다.
리뷰를 읽으면서 궁금한 점이 생겼습니다.
Global–Local fusion 단계에서 두 feature는 attention 기반 정제 이후 단순 concatenation으로 결합되는 것으로 이해했는데, 이때 global feature와 local feature의 상대적 중요도를 조절하는 명시적인 가중치나 gate가 존재하는 건지 궁금합니다.
다시 한번 좋은 리뷰 감사합니다.
안녕하세요 현우님! 좋은 리뷰 감사합니다. 질문 하나 드리고자 합니다.
Local branch는 질문에 따라 필요한 정보를 동적으로 추출해야 하는 곳인데, 여기서 사용된 InfoNCE Loss는 질문 내용과는 상관없이 그저 오디오-비디오 쌍 찾기에만 집중하는 것으로 생각됩니다. 이때 모델은 질문에 대답하기 위한 세부 특징에 집중하기보다 단순히 오디오-비디오 쌍을 잘 찾기 위해 질문과 무관한 정보까지 특징값에 포함하여 local feature가 희석될 여지가 있어 보이는데, 이 정합에 의한 local 정보 희석에 대해 저자가 생각한 해결책이나 의도가 있는지 궁금합니다.