
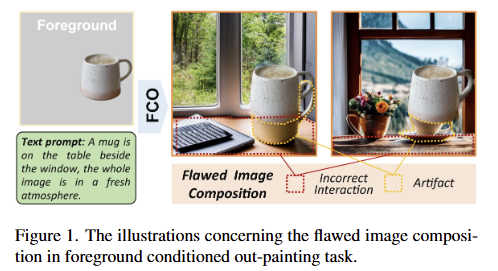
이번 리뷰 논문은 Foreground Conditioned Out-painting (FCO)라는 기법에 대한 논문 입니다. FCO는 fig 3과 같이 전경 (fig 3 – Cond.Image)과 text prompt가 주어졌을 때, 전경은 유지하면서 text prompt를 따르는 영상을 생성하는 연구입니다.
해당 논문을 읽게 된 계기는 최근 로봇 데모 영상을 효과적으로 증강 하기 위한 수단으로 읽게 되었습니다. 최근 트렌드는 조작 대상 객체와 로봇(로봇 궤적도 증강 하거나)을 영상 내에서 분할하여 또 다른 배경에 붙이는 방식으로 증강 하는 방법들이 많이 등장하고 있습니다. 이러한 증강 방법들은 copy-paste 수준이거나, 고수준인 경우에는 전경을 유지하면서 배경을 생성하는 연구(e.g. “Salient Object Aware Background Generation, CVPR 2024”)를 활용하는 것이 트렌드였습니다.
허나, 실제로 결과 값을 뽑아보면 배경과 유연하게 어울리게 생성되는 것이 아니라 어색하거나 artifact가 존재하는 경우가 많았습니다. 이러한 결과물들은 로봇 학습 관점에서 현실과 상이하기 때문에 잘못된 최적화로 인하여 일반화 성능을 저지 시킬 가능성이 있습니다.
이를 해결하고자 하는 최신 기법들을 찾아다니게 되었고, 재밌는 관점으로 문제점을 해결한 해당 논문을 찾게 되었습니다. 해당 기법의 해결책은 FCO 뿐만이 아니라 diffusion model을 활용하는 많은 연구에서도 좋은 통찰을 줄 것이라고 보고 있습니다.
Intro
앞서 밝힌 바와 같이 생성형 AI, 특히 diffusion model은 생성형 모델로 여러 분야에 큰 발전을 가져왔습니다. 특히, 영상 편집 분야 중에서 주어진 전경 객체 (foreground object)를 바탕으로 text prompt에 따라 배경을 자유롭게 생성하는 Foreground Conditioned Out-painting;FCO 기술은 전자상거래, 광고, 콘텐츠 제작 등 다양한 산업에서 그 활용 가능성을 주목 받고 있습니다. 해당 기법을 활용한다면 간단한 텍스트 수정만으로도 동일한 제품을 다채롭게 표현 가능한 배경을 합성 가능하죠.
하지만 기존 FCO 기술들은 Image composition의 퀄리티 측면에서 근본적인 한계에 부딪혀 왔습니다. 즉, 생성된 배경이 주어진 전경과 자연스럽게 어우러지지 못하는 문제입니다. fig 1의 머그컵 예시와 같이 모델이 text prompt “A mug is on the table beside the window, the whole Image is in a fresh atmosphere.”이라는 프롬프트를 이해하고 생성된 fig 1의 오른쪽의 그림과 같이 부자연스러운 결과물을 보이는 경우가 많습니다. 생성된 테이블이 머그컵의 위치나 형태와 맞지 않아 incorrect interaction을 보이거나, 전경과 배경의 경계에 불필요한 artifact이 발생하는 경우가 빈번하다고 합니다.
+ fig 1에서 보이는 문제점을 flawed image composition = image composition 라고 정의하고 있습니다. 해당 리뷰에서는 이를 따릅니다.
저자는 이러한 문제를 해결하기 위한 기존 연구들이 접근한 방식을 크게 두 가지로 나눕니다.
- Learning-free: Blended Latent Diffusion과 같은 방법들은 사전 학습된 모델을 그대로 사용하며, 매 단계에서 생성 중인 배경에 고정된 전경을 ‘붙여 넣는’ 방식으로 작동합니다. 해당 방식은 구현이 간단하지만, 전경과 배경의 통합된 처리가 어려워 둘 사이의 의미 있는 상호작용을 표현하는데에 있어 명백한 한계를 가집니다.
- Learning-based: SD-Inpainting, ControlNet 등은 대규모 데이터셋으로 모델을 미세 조정하여 영상의 그럴싸함을 향상 시키는 방식입니다. 하지만 해당 기법들은 대부분 일반적인 image-inpainting에 초점을 맞추고 있습니다. 따라서 분할된 전경 객체만 단서로 주어지는 FCO의 특수성을 온전히 방영하지 못하기 때문에, 객체 간의 구성 오류를 일으키는 경향이 있습니다.
저자는 이를 해결하기 위한 재밌는 통찰을 제시합니다. FCO의 Image composition 문에 있어 diffusion model의 초기 샘플링 과정에 존재하는 initial noise x_T에서 비롯된다고 주장합니다. 즉, 무작위로 선정된 노이즈로부터 생성을 시작하는 것은 고정된 전경과 충돌하는 구성이 되도록 방치하는 것입니다.
+ 조금 더 쉽게 풀자면 무작위로 선정된 노이즈 initial noise x_T는 생성에 있어 독립된 구성. 그렇기에 지정된 전경과 관련이 없는 구성으로 생성될 가능성이 있습니다. 이럴 경우에 생성 모델은 최대한 전경과 배경을 어떻게든 그럴싸하게 만들기 위해서 artifact를 만들거나, 포기하고 incorrect interaction의 결과를 제시하면서 flawed image composition이 발생한다는 것이 저자의 주장입니다.
저자는 이러한 통찰을 기반으로 Initialization Policy Model;IPM이라는 기법을 제시합니다. IPM은 diffusion process의 초기 단계의 무작위성에 의존하는 것이 아니라 주어진 전경 영상 y와 텍스트 프롬프트 y만을 바탕으로 intermediate state x_{t^s} 를 직접 예측하고 이를 기반으로 Truncated Diffusion Process를 수행합니다.
+ Diffusion process의 중간 단계의 값을 예측하는 모델이 IPM, 중간 단계부터 시작하는 것을 Truncated Diffusion Process라고 보시면 됩니다.
Diffusion model의 diffusion process 초기 상태에서는 low-frequency signals이 생성된다는 점을 활용하여 IPM을 효과적을 학습하기 위한 training process를 제시합니다. 먼저, Inversion-derived Label Supervision은 noised sampling~inversion (역방향) 과정을 통해 얻은 low-frequency signals를 GT로 사용하여 IPM을 학습합니다. Diffusion Reward Supervision은 예측한 x_{t^s} 를 가지고 diffusion process를 수행하고 생성된 영상과 타겟 영상과의 오차를 reward로 사용하여 지도를 수행합니다.
저자는 이를 평가하기 위해서 구축한 OpenImage-FCO 데이터셋을 이용하여 평가를 진행하였으며, 다른 SOTA 모델 대비 크게 향상된 결과를 보여줍니다.
Method
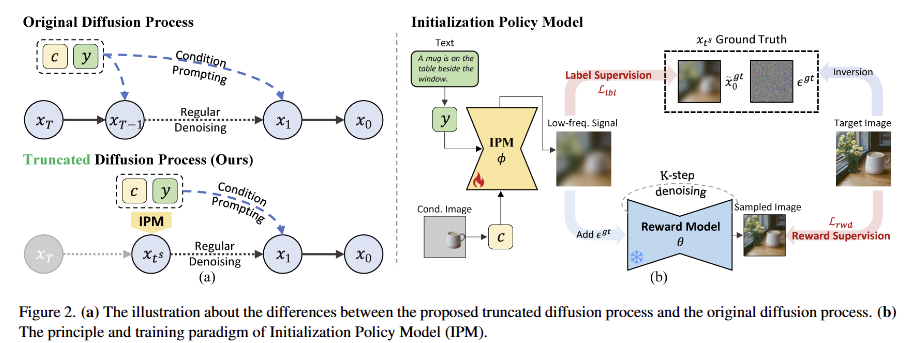
Overview. 해당 기법은 생성된 Image Composition 개선을 목표로 하는 FCO에 초점을 맞춥니다. 특히, diffusion-based method에 집중하며, image generation process는 random noise x_T 에서 시작되는 sequential denoising steps으로 모델링 됩니다. 여기서 T는 timesteps의 수를 의미합니다. 특히, text-driven FCO,의 경우, denoising process에서 목표 영사의 semantics가 설명된 text prompt y와 유지하기 원하는 전경인 condition image c에 의해 제시됩니다. 이는 p_\theta(x_{0:T-1}|x_T, y, c) 로 표현됩니다. 여기서 θ는 denoising model을 나타냅니다.
해당 방법론은 ‘rethinking the influence of x_T’으로부터 비롯됩니다. 기존 연구들에 따르면, 동일한 프롬프트를 주더라도 서로 다른 x_T에 따라 샘플링된 결과(객체의 자세, 크기, 위치 등)가 달라집니다. 이는 x_T가 완전히 독립적이고, x_T가 암시하는 배경 정보가 주어진 전경 객체와 충돌할 가능성이 높아집니다.
저자는 이를 해소하기 위해서 fig 2-(a)에 보이는 바와 같이, 특정 time step t^s 에서 denoising process를 잘라내고 초기 단계를 Initialization Policy Model (IPM) ϕ로 대체하는 것을 제안합니다. 해당 기법은 diffusion process 내의 time-frequency coupling을 활용하며, image composition을 결정하는 low-frequency signals가 주로 초기 단계에서 형성된다는 것을 기반합니다. ϕ는 foreground image c와 text prompt t에만 의존하도록 정의되어, image composition에 대한 x_T의 무작위성에 대해 완전히 분리되도록 합니다. 결과적으로 모델은 p_{\phi}(x_{t^s} | y, c) and p_{\theta}(x_{0:t^s+1} | x_{t^s}, y, c) 로 분해됩니다.
Initialization Policy Model. IPM은 intermediate state x_{t^s} 를 얻기 위한 것을 목적으로 합니다. Diffusion model ~ DDIM에 따르면 x_t는 아래와 같이 정의 됩니다.
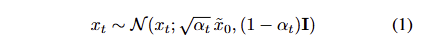
\alpha_t 는 the parameter of the diffusion schedule입니다. \tilde{x_ 0} 는 현재 timestep에서의 target image x_0 의 예측값을 나타내며, 이는 본질적으로 T부터 t − 1까지의 denosing steps 이후의 deterministic signal 역할을 합니다. 이러한 역할을 수식 1을 아래와 같이 수정하여 두드러지게 표현 가능합니다.
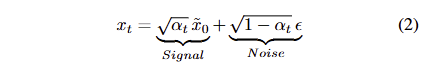
t가 클 때, \tilde{x_ 0} 는 주로 low-frequency signal를 포함하며*, 이는 image composition의 핵심적인 결정 요인으로 작용하는 것을 볼 수 있습니다. ϵ는 random noise를 나타내며, 서로 다른 ϵ는 생성된 이미지에서 구별되는 high-frequency details을 발생 시킵니다. 해당 기법에서 IPM ϕ는 signal component인 \tilde{x_ 0} 를 예측하는 것을 목적으로 합니다. 이를 위해 IPM은 real target images에 대한 low-frequency signals를 학습하며, 샘플링 중에는 IPM의 예측값이 random noise와 결합되어 일관된 구성을 가진 다양한 영상을 만드는 것을 목적으로 합니다.
* Xuan Han, Yihao Zhao, and Mingyu You. Scene diffusion: Text-driven scene image synthesis conditioning on a single 3d model. In ACMMM, pages 7862–7870, 2024. 3
이론적으로는 주어진 c와 y에 대응되는 잠재적인 composition이 존재하며, 이상적인 x_{t^s} 는 복잡한 분포를 따를 겁니다. 아쉽게도 특정 c와 y 쌍에 대응되는 real target image를 얻는 것은 어렵습니다. 따라서 IPM의 역할은 x_{t^s} 의 이상적인 분포 내에서 특정 클러스터를 제공하는 것입니다. 해당 방법에 대해서는 저자는 정량적/정성적인 실험 결과로 해당 모듈이 생성 모델에 미치는 영향과 FCO 모델이 다양성과 일관성 사이의 균형을 달성하도록 어떻게 돕는지 보이는 방식을 택합니다.
해당 모듈의 구조는 Stable Diffusion의 U-Net을 사용합니다. 해당 전략은 해당 가중치에 내장된 풍부한 text-image priors를 계승하는 것을 목표로 합니다. (CLIP에 의해 인코딩된) 텍스트 프롬프트 y는 cross-attention을 통해 통합됩니다. 모듈의 입력 레이어는 (Latent VAE에 의해 인코딩된) condition image c를 수용하기 위한 4개의 추가적인 채널로 확장됩니다. 또한, U-Net이 denoising model로 훈련된 점을 고려하여 fixed-noise 전략을 적용합니다. fixed-noise x^st_T 가 원래 채널에 주입됩니다. low-frequency signal의 최종 예측은 모델의 출력과 x^st_T 로부터 diffusion schedule에 따라 계산됩니다. 이는 아래와 같이 표현됩니다.
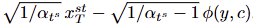
해당 수식은 schedule parameters와 noise는 학습 및 샘플링 전반에 걸쳐 일정하게 유지되므로, 해당 논문에서는 단순화를 위해 ϕ(y, c)를 예측된 low-frequency singal로 지칭합니다.
Inversion-derived Label Supervision. Label data를 활용하는 supervision은 가장 효과적인 학습 기법 중 하나 입니다. IPM의 prediction objectives에 대한 GT data는 diffusion process의 inversion (역변환)을 통해 도출 할 수 있습니다. inversion operation proceeds는 샘플링 과정의 역방향으로 진행되며, target image x_0 에서 initial noise x_T 까지 단계적으로 노이즈를 제거하는 과정을 포함합니다. 동일한 noise schedule을 따라, 역변환을 통해 얻어진 intermediate state x_t 의 trajectory는 유효한 gt로 활용되며, 본문에서는 DDIM Inversion을 활용합니다. 이는 t \in [0, t_s ] 범위 내에서 작동되며, truncation timestep의 intermediate state x_{t^s}^gt 를 활용합니다.
Inversion process의 결과를 기반으로, signal과 random noise에 대한 GT를 다음과 같이 얻을 수 있습니다. \tilde{x}^{gt}_0 = \sqrt{ 1 / \alpha{t^s} } x_{t^s} - \sqrt{ 1 / \alpha_{t^s} - 1 } \theta(x_t, y), \epsilon_{gt} = \theta(x_t, y) . 여기서 θ는 사전학습된 diffusion model을 나타냅니다. \tilde{x}^{gt}_0 는 IPM의 학습을 지도하기 위한 라벨로 사용되며, 이를 위한 loss는 다음과 같습니다.
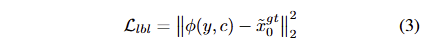
+영상에 노이즈를 가하는 과정을 diffusion process = forward diffusion process =~ inversion process 라고 이해하시면 됩니다.
++ inversion process은 약간 다른 점이 있습니다. 모델이 예측했던 노이즈를 찾아내는 것을 목적으로 합니다.
+++ 즉, real target image x_0^{gt}로부터 t^s까지 forward를 수행해서 x_{t^s}^gt를 찾아내고, 이를 이용해서 noise를 찾아내는 것을 목적으로 합니다.
Diffusion Reward Supervision. IPM은 영상의 low-frequency signal을 예측하는 역할을 합니다. 허나, MSE loss만으로는 결과가 학습 라벨에만 피팅될 수 있습니다. 또한, inversion operation을 통해 얻은 결과는 본질적으로 편차를 가질 수 밖에 없습니다. 따라서 IPM 학습을 지원하기 위한 Diffusion Reward Supervision을 제시합니다. 해당 기법은 fig 2-(b)에서도 볼 수 있습니다. IPM에 의해 샘플리된 x_{t^s} 는 사전 학습된 diffusion model (reward model) θ에 입력되어 여러 번 denosing을 수행하며, 해당 결과와 target image 간의 오차를 학습에 사용될 reward로 사용됩니다.
Diffusion reward는 DDIM과 동일한 denoising schedule을 사용합니다. number of denoising step을 K라고 가정할 때, sampling stpe size는 \lfloor(T - ts)/K \rfloor 이 됩니다. sampling schedule의 다양성을 늘리기 위해서 처음 단계의 step size는 [1, \lfloor(T - ts)/K\rfloor] 내의 난수로 설정합니다. 각 단계는 아래와 같이 정리됩니다.
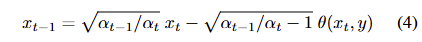
최종 reward로부터 생성된 gradient는 연쇄 법칙에 따라 back-propagation이 될 수 있으며, 이웃된 timestep 간의 gradient는 아래와 같이 표현됩니다.
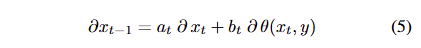
여기서 a_t, b_t 는 각각 schedule parameter를 단순화하는데 표현했으며, 자세히 풀면 다음과 같습니다. a_t = \sqrt{\alpha_{t-1} / \alpha_t} 과 b_t = \sqrt{ \alpha_{t-1} / \alpha_t - 1 }에 해당합니다. 수식 5는 diffusion reward의 단점을 드러낸다고 합니다. 그래디언트의 전달이 reward model를 반복적으로 통과해야만 한다는 겁니다.
저는 이러한 문제점을 해소하기 위해서 Wu et al. ** 연구를 참조하여 stop gradients 기법을 사용합니다. 해당 기법을 활용하면 수식은 아래와 같이 단순화 됩니다.
** Xiaoshi Wu, Yiming Hao, Manyuan Zhang, Keqiang Sun, Zhaoyang Huang, Guanglu Song, Yu Liu, and Hongsheng Li. Deep reward supervisions for tuning text-to-image diffusion models. CoRR, abs/2405.00760, 2024. 4
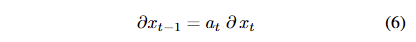
해당 수식은 기울기의 정확도를 감소 시킬 수 있지만, 제한된 메모리로도 어느정도 효과적인 학습이 가능하도록 합니다. 저자는 msd(*)를 multi-step denoising operation로 사용하며, diffusion reward는 다음과 같이 표현됩니다.
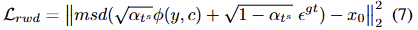
\epsilon^{gt} 는 앞선 inversion prcoess로부터 얻어진 노이즈입니다. 해당 loss는 예측된 low-frequency noise으로부터 최종적으로는 target image 자체로 복원되기를 기대합니다.
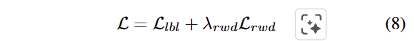
저자는 실험적으로 해당 loss가 예측한 signal의 품질을 효과적으로 향상 시킨다는 것을 보인다고 합니다.최종적인 loss는 아래와 같이 구성됩니다.
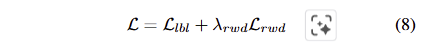
sampling 중에는 IPM ϕ의 출력이 random noise와 결합되어 intermediate state
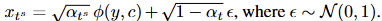
를 얻습니다. 이후, denoising steps는 일반적인 diffusion-based FCO에 의해 수행되어집니다. 제안된 기법에서는 동일한 데이터셋으로 학습된 ControlNet을 활용합니다.
Experiments
Dataset. FCO는 고품질의 task-specific dataset을 요구하지만, 기존 데이터 셋들은 큰 규모를 가지고 있지만, 객체 분할 정보에 대해서는 다양성이 부족한 경우가 많았다고 합니다. 예를 들어서 PowerPaint, OpenImage는 600개의 객체 클래스에 대한 segmentation sub-set만 수행했으며, 영상 내 다수는 주요 대상이 아니었다고 합니다. 저자는 이러한 한계를 극복하기 위해서 OpenImage-v7을 기반으로 OpenImage-FCO를 구축했다고 합니다.
해당 데이터셋은 multi-modal filtering과 semantic reasoning을 통합해서? annotation 품질을 향상했다고 합니다. BLIP2와 RAM을 활용해서 image captioning, tagging을 수행했고, Llama3를 통해 의미론적인 필터링을 걸쳐 focused objects만 채택할 수 있도록 합니다. 또한, GroundingDINO와 HQ-SAM으로 정밀한 객체 마스크를 생성했으며, 이를 통해 580k의 영상과 800k의 마스크, 6k 개의 고유 객체 태그와 이미지 캡션을 가지고 있습니다.
OpenImage-FCO는 멀티모달 필터링과 의미론적 추론을 통합하여 주석 품질을 향상시킵니다. 저희는 BLIP2 [18]와 RAM [45]을 이미지 캡셔닝 및 태깅에 활용하고, Llama3 [34]를 통해 의미론적 필터링을 거쳐 초점 객체만을 유지합니다. GroundingDINO [21]와 HQ-SAM [16]은 정밀한 객체 마스크를 생성하는 데 사용됩니다. 최종 데이터셋에는 580K개의 이미지와 800K개의 마스크, 6K개의 고유 객체 태그, 그리고 이미지 캡션이 포함됩니다. 평가를 위해, 저희는 각각 수동 전경 마스크 주석과 텍스트 프롬프트를 갖춘 250개의 사례로 구성된 테스트 세트를 큐레이션했습니다. 이 규모는 이미지 편집 도메인에서 널리 채택된 벤치마크인 EditBench [36]의 240개 사례와 맞춥니다.
Experimental Settings.
– Implementation Details. Stable Diffusion V2.1을 기반, 512×512을 입력으로 받으며 IPM은 truncation timestep t_s는 800, diffusion reward 파라미터 K는 10, AdamW, 1 x 10-4, batch 8 ~ Nvidia L40s x 8 -> 400k iterations…… 추론에서의 FCO-ControlNet은 AdamW, 1×10−5, batch 8 -> 200k
IPM을 통해 얻은 중간 상태 x_{t^s}를 입력으로 DDIM sampler를 사용하여 10의 스텝 크기와 7의 classifier-free guidance scale로 샘플링하여 이미지를 생성했다고 합니다….
– Metrics. 3가지 측면에서 5 가지 평가지표를 사용함
(1) Image Composition: artifact와 incorrect ineraction을 평가를 담당. GroundingDINO와 HQSAM을 사용하여 전경 객체와 동일한 의미를 가지는 모든 마스크 출력. 출력된 영역 대비 GT 간의 비율을 SAM Score (SAM), 30 명의 참가자가 객체 상호작용과 관련하여 평가를 수행한 (INT)-1~5까지 점수를 매기며 높은 점수가 좋은 결과,
(2) Text-Image Alignment. (CLIP)을 활용하여 text prompt 간의 CLIP Similarity를 측정함
(3) Image Quality. Aesthetic Score (AS), Image Reward (IR) <- 이는 평가 모델은 human preference datasets으로 학습되었으며, 수치가 높을 수록 사람의 선호도가 높다고 간주한다고 합니다.
Comparison with Existing Methods.

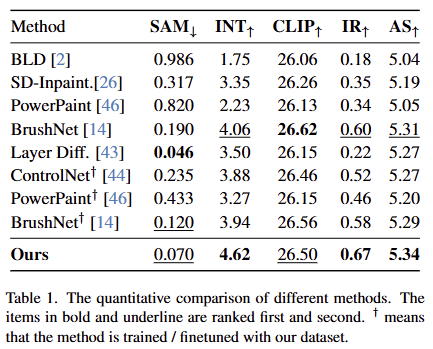
전반적인 실험 결과는 fig 3과 tab 1에서 확인 가능합니다. 실험적인 결과, 대부분의 메트릭에서 가장 좋은 결과를 보여줍니다. SAM 지표에서는 Layer Diff가 더 좋은 결과를 보여주지만, 다른 지표에서는 높은 수치로 우세한 결과를 보여주면서 더 자연스러운 결과를 입증한다고 합니다. CLIP에서는 BrushNet을 이은 2위에 해당합니다. 이는 BrushNet이 120m image를 가진 LAION-Aesthetic로 학습했기 때문에 text-image alginment에 대해서는 우세한 결과를 보인 것이라고 저자는 주장합니다. 정석적인 결과에서는 다른 기법 대비 우세한 결과를 보여줍니다.

또한, IPM의 성능을 IPM의 능력을 더 보여주기 위해, 다양한 특징, 크기, 위치를 가진 전경을 condition images로 선택하고 동일한 text prompt 하에서 결과를 생성한 결과를 fig 4에서 확인 할 수 있습니다. 해당 결과로부터 제안한 기법이 다양한 시나리오에 잘 적응하며 주어진 객체와 배경 간의 합리적인 상호작용을 생성함을 보여줍니다.
The Influence of IPM on Generation Model.

베이스 모델(Control-Net)에서 다양한 텍스트 프롬프트 y에 대한 IPM 적용 유무에 따른 생성 결과는 fig 5-(a)에서 볼 수 있으며, IPM이 model’s controllability에 크게 영향을 미치지 않는다는 것을 보입니다. 즉, 모델은 여전히 요구되는 의미론적 내용을 가진 결과물을 합성한닥 볼 수 있습니다. 저자는 이러한 결과는 tab 1에서 해당 기법과 ControlNet이 모든 접근 방식 중에서 가장 유사한 CLIP 점수을 나타냄을 증거로 볼 수 있다고 합니다.
fig 5-(b)에서는 동일한 c와 y 쌍에 대해 IPM 적용 유무에 따른 기준 모델의 생성 결과입니다. 이 비교에서, IPM는 공유된 저주파 신호로 인해 더 유사한 구성을 보여주는 반면, 베이스 모델은 flawed image composition이 발생되는 것을 확인 할 수 있습니다.
Ablation Study.

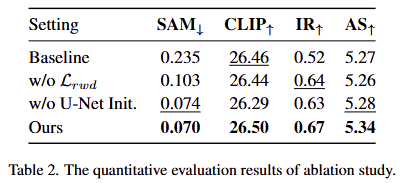
Ablation Study for Lrwd. tab 2에서 보이는 바와 같이 diffusion reward supervision은 artifact 억제에 이점을 보입니다. 해당 기능을 제외하면 AS 같은 영상 품질과 관련된 지표에서 하락하는 경향을 보입니다. 이러한 결과는 IPM이 예측한 저주파 신호의 품질과 상관관계를 가진다고 볼 수 있습니다. 저자는 이를 입증하기 위해서 fig 6을 시각화한 결과를 보여줍니다. 실험적인 결과, 해당 손실 함수를 포함했을 때, 디테일이 향상되는 결과를 보여줍니다.
Ablation Study for U-Net Initialization. tab 2에서 보이는 바와 같이 사전학습된 U-Net으로 IPM를 초기화함으로써, 모델의 텍스트 제어 능력이 강화됨을 보입니다.
The Selection of Truncating Timestep.
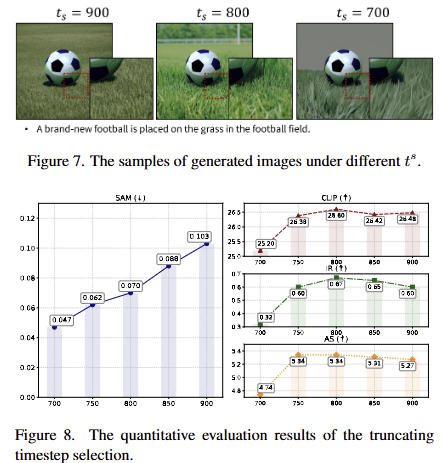
ts 값이 클수록(초기 단계에 가까울수록) IPM이 예측해야 할 주파수 대역은 더 좁아지고, 순수한 노이즈에 가까운 신호를 다루게 됩니다. 이러한 경우에는 IPM의 영향력이 적어져 최적화된 구성이 적어집니다. 이로 인하여 fig 8과 같이 SAM 지표가 향상됨을 볼 수 있습니다.
ts 값이 작을수록(후기 단계에 가까울수록) IPM이 예측해야 할 주파수 대역은 더 넓어지고, 이미 많은 디테일이 포함된 신호를 다루게 됩니다. 이러한 경우에는 그럴싸하게 재구성하는 구간이 적어져 fig 7의 오른쪽과 같이 배경이 비교적 단순화되는 현상이 발생합니다. 이러한 경향은 fig 8에서 CLIP, IR, AS와 같이 의미론적인 영역과 영상 품질 성능이 하락되는 결과를 보여줍니다.
저자는 실험적인 분석을 기반으로 800이 적절했다고 합니다.
Failure case and Future Work

주어진 전경 객체가 극단적인 색상이나 조명 조건을 가지고 있을 때, 배경 생성의 background controllability이 현저하게 떨어지는 문제가 있다고 합니다. fig 9의 왼쪽과 같이 전경과 배경이 동일한 색상을 따라가면서 배경을 생성하는 문제가 있으며, fig 9의 오른쪽과 같이 배경 생성에 실패하는 결과를 보였다고 합니다.
저자는 이러한 원인이 데이터 셋의 한계와 프레임워크 설계의 한계로 본다고 합니다. 먼저, 연구에 사용된 OpenImage-FCO 데이터 셋은 예술적인 사진을 충분히 포함하고 있지 않기 때문에 극단적인 색상이나 조명 조건을 가진 상황에 대해서 충분히 학습하지 못했다고 합니다.
프레임워크 설계에는 합석 과정에서 극단적인 색상을 가진 전경 객체의 특징이 배경 특징을 지배하는 경향이 있다고 합니다. 상호적인 의미 관계를 가지는 것이 전경과 배경에 대한 독립적인 스타일 제어하는 것이 어려워지게 만들었다고 합니다.
해당 기법은 물리적인 특성을 유지하면서 증강을 수행하는 데에 큰 통찰을 줄 것 이라고 기대하고 있습니다. diffusion model은 최근 액션 모델 뿐만이 아니라 월드 모델, 비디오 생성 모델에서도 물리적인 이해를 구하는 생성 모델로 적극적을 활용되고 있습니다. 해당 기법은 기존의 지식을 새롭게 구축하는 것이 아니라 유지하면서 물리적인 특성을 반영 가능한 diffusion을 위한 PTFT 기법으로 해석해도 좋을 것 같네요.