안녕하세요. 이번에 소개할 논문은 명시적 객체 표현이 Video-Language Understanding에서 실제로 도움이 되는지, 그리고 도움이 된다면 어떤 방식으로 통합하는 것이 가장 효율적인지를 다루는 연구입니다. 즉, 모델이 객체의 위치·움직임 같은 구조적 정보를 얼마나 잘 활용할 수 있는지 검증하고, 그 정보를 LLM에 넣는 방법을 비교·분석합니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
이 논문은 Video-Language Understanding에서 좋은 표현(representation)이란 무엇인가? 라는 질문에서 출발합니다. 멀티모달 LLM의 발전과 함께 토큰화할 수 있는 어떤 모달리티든 LLM과 결합하여 활용할 수 있습니다. 이러한 멀티모달 활용 방식은 크게 두 갈래로 나눌 수 있습니다. 하나는 다른 모달리티의 데이터를 전용 인코더로 임베딩하고 MLP나 어텐션 모듈과 같은 작은 신경망을 통해 LLM 임베딩 공간으로 프로젝션하고, 이후 instruction tuning으로 적응시키는 방식입니다. 다른 하나는 객체의 라벨·속성·관계·그래프와 같은 interpretable concepts이나 캡션처럼, 이미 언어 형태로 표현된 정보를 LLM의 입력 토큰으로 직접 입력하는 방식입니다. 하지만 현재까지도 이 두 접근법 중 어느 쪽이 LLM의 추론 능력을 향상시키는 데 더 효과적인지에 대해서는 논쟁의 여지가 있습니다.

그림 1에서 보듯이, 캡션만 사용할 경우 프레임 전반에 대한 장면 설명은 잘하지만, 객체의 위치·움직임·상호작용과 같은 세밀한 시공간 정보는 종종 누락되는 경향이 있습니다. 예를 들어, 그림처럼 “파란 옷을 입은 아이가 공원에서 농구공을 던지고 있다” 라는 캡션과 함께 “이 슛이 들어갈 것인가?” 라는 질문이 주어졌을 때, LLM은 캡션만으로는 공의 궤적이나 위치와 같은 세부 정보를 알 수 없어, 정확한 답변을 내리지 못하는 경우가 생길 수 있습니다. 반대로 비전 정보를 함께 활용하는 MLLM에서는 비주얼 인코더의 공간적 inductive bias를 통해 이러한 질문에 부분적으로 대응할 수 있지만, 객체 자체와 위치 정보를 LLM 내부 표현으로 자연스럽게 통합하는 데에는 여전히 한계가 존재합니다
이 논문은 이러한 문제의식에서 출발해, 객체 중심(object-centric) 인식과 모델링이 여전히 MLLM 성공의 핵심 요소라고 가정합니다. 그리고 “객체 정보가 MLLM 기반의 비디오-언어 이해에 어떻게 기여할 수 있는가?”라는 질문을 두 가지 관점, 표현(representation)과 적응(adaptation) 측면에서 접근합니다.
기존 연구들에서 캡션 기반 표현이 비디오 이해에 효과적이었던 점을 바탕으로, 저자들은 하나의 트레이드오프를 가정합니다. 시각 표현이 표현력이 높을수록, 사전학습된 LLM에 적응시키기 위해서는 더 많은 instruction-tuning 데이터가 필요하다는 것입니다. 예를 들어, 분산 표현은 표현력이 뛰어나지만, LLM과 정렬시키는 데 많은 데이터와 학습 비용이 듭니다. 반면, 객체 좌표를 텍스트로 사용하는 것과 같은 언어 기반(symbolic) 표현은 표현력은 다소 떨어지지만, 이미 LLM이 가진 어휘 체계 안에서 처리할 수 있기 때문에 훨씬 쉽게 활용될 수 있습니다. 특히 비디오에서는, 이런 symbolic 객체 표현이 시간에 따른 객체의 이동 경로나 핵심 포인트(trajectory)를 담을 수 있을 때 더 강력해진다고 저자들은 주장합니다. Figure 1의 농구공 궤적 예시가 시각적으로 보여주는 예시입니다,
이 가설을 검증하기 위해, 저자들은 ObjectMLLM이라는 프레임워크를 제안합니다. ObjectMLLM은 Object Detection 모달과 Tracking 모델을 활용해 구조화된 시각 표현을 멀티모달 LLM에 통합할 수 있도록 설계된 프레임워크입니다.
ObjectMLLM에서는 객체 중심 표현을 설계하는 방식을 두 가지로 비교합니다.
첫 번째는, 객체 bounding box 정보를 벡터 형태로 만든 뒤, 이를 임베딩 프로젝터를 통해 LLM 입력 공간으로 투영하는 방식입니다. 두 번째는, bounding box 좌표 자체를 문자열로 렌더링해서 언어 토큰으로 직접 처리하는 symbolic 방식입니다. 두 방식 모두에서, 사전학습된 LLM을 목표 태스크에 맞게 학습시키기 위해 parameter-efficient fine-tuning을 적용합니다.
2. Method
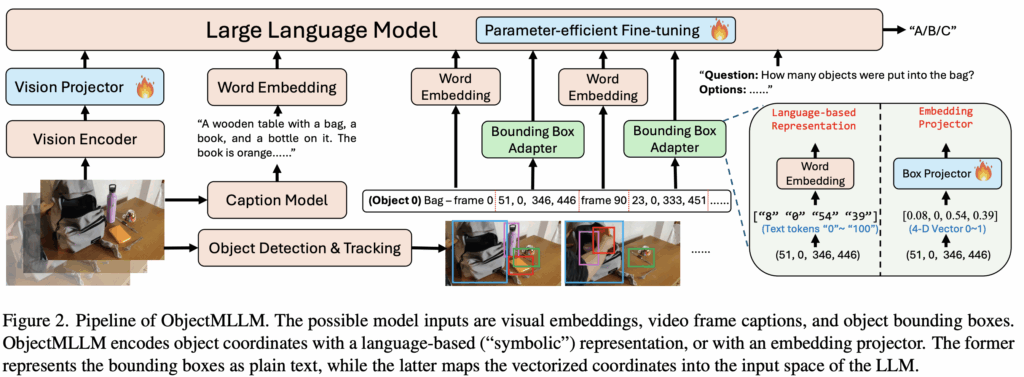
2.1 ObjectMLLM
그림 2에서는 저자들이 제안하는 ObjectMLLM의 전체 파이프라인을 보여줍니다.
먼저 비디오가 입력으로 주어지면, 이를 인코딩해 LLM이 사용할 수 있는 입력 형태로 변환해 주는 비전 인코더와 비전 프로젝터가 있습니다. 동시에 비디오 내용을 요약해 주는 캡션 생성 모델, 비디오 속 객체 정보를 얻기 위해 detection , tracking 모델이 사용됩니다. 마지막으로, 이렇게 추출된 객체 정보를 LLM에 입력하기 위해 bounding box adapter 가 사용됩니다.
여기서 중요한 점은, 저자들이 바운딩 박스 어댑터를 두 가지 방식으로 설계했다는 것입니다. 앞선 Introduction에서 설명했듯이, 멀티모달 정보를 LLM에 결합하는 방식에는 크게 두 가지가 있습니다.
첫 번째는, 별도의 프로젝터를 사용해 bounding box 좌표를 벡터 형태로 표현한 뒤 프로젝터를 거쳐 LLM 입력 공간의 임베딩으로 변환하는 방식이고, 두 번째는, 이런 매핑 없이 LLM이 바로 처리할 수 있도록 bounding box 좌표를 벡터 형태로 표현한 뒤 프로젝터를 거쳐 LLM 입력 공간의 임베딩으로 변환하는 방식입니다. 저자는 이 두 가지 방식을 모두 ObjectMLLM에 구현했습니다. 이후 실험을 통해 이 두 어댑터를 비교·분석하고, 성능과 데이터 효율성 측면에서 더 우수한 어댑터를 선택해 최종 ObjectMLLM 모델에 적용합니다.

위 그림 3에서는 객체 정보가 어떻게 사용되는지 나타나 있습니다. 먼저 각 객체가 어느 시점에 등장하는지(timestamp)를 나열하고, 그 뒤에 해당 시점의 bounding box 정보를 붙이는 형태로 표현됩니다. 객체 라벨과 타임스탬프는 일반 텍스트처럼 토크나이즈되어 LLM에 입력되고, bounding box는 네 개의 연속값으로 표현됩니다.
2.2 Object Detection and Tracking
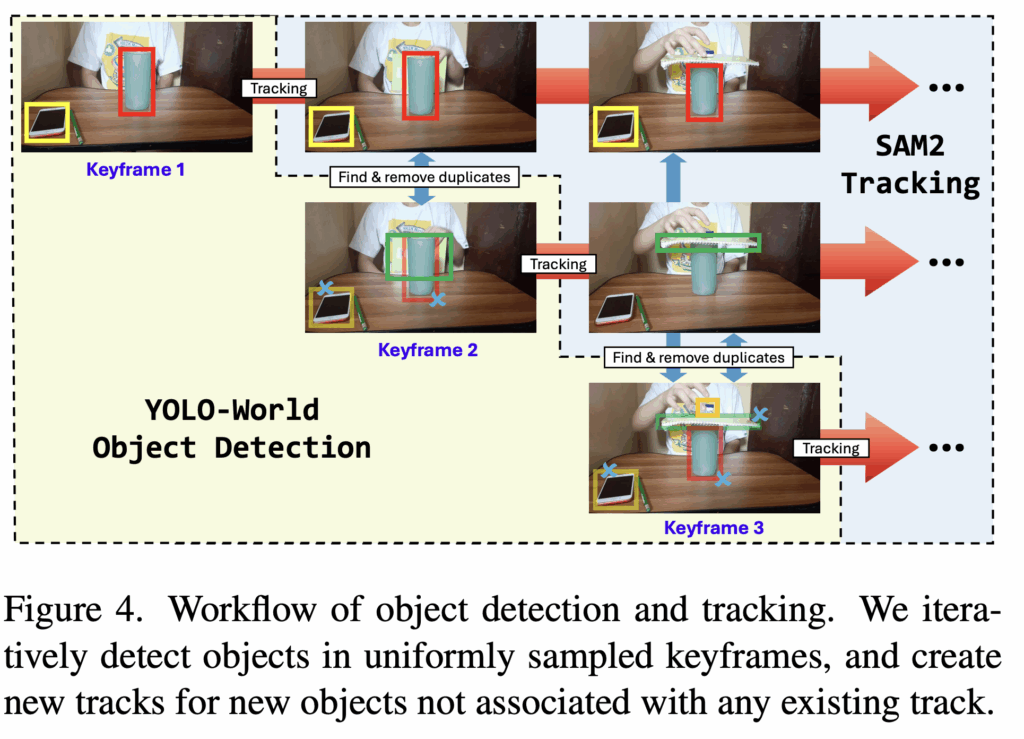
객체 중심 표현을 만들기 위해서 Detection 모델로 YOLO-World를, 그리고 검출된 객체를 비디오 전반에 걸쳐 추적하기 위해 SAM 2를 활용합니다. 먼저 프레임이 주어졌을 때 yolo-world 모델을 사용하여 객체를 탐지합니다. 그리고 이후 프레임에서는 SAM2 트래킹 모델을 사용하여 탐지된 객체를 추척합니다. 동시에 현재 프레임에 존재하는 모든 객체를 다시 YOLO-World로 탐지합니다. 그 다음, 새로 검출된 객체들과 이미 존재하는 객체들 사이의 IoU를 계산하고 IoU가 0.5보다 큰 객체들은 중복되는 것으로 간주하여 제거하고, 나머지 검출 객체들은 새로운 트래킹을 하는데 사용합니다. 이제 이 과정을 반복하여 객체 위치 정보를 추출하게 됩니다.
2.3 Object-centric representation
그림 2에서 보듯이, 저자들은 bounding box 정보를 LLM에 입력하기 위한 어댑터를 두 가지 방식으로 설계합니다. 하나는 언어 기반(language-based) 어댑터이고, 다른 하나는 임베딩 프로젝터(embedding projector) 기반 어댑터입니다. 두 방식의 핵심 차이는, 객체의 공간 정보를 LLM이 이미 잘 다루는 언어 형태로 표현하느냐, 아니면 새로운 벡터 표현을 만들어 LLM 입력 공간으로 매핑하느냐에 있습니다.
먼저 언어 기반 어댑터는, 연속적인 bounding box 좌표를 symbol 기호로 바꿔서 객체의 위치 정보를 표현합니다. 반면, 임베딩 프로젝터 방식은 bounding box 좌표를 벡터로 표현한 뒤, 이를 학습 가능한 프로젝터를 통해 LLM 입력 임베딩 공간으로 투영합니다. 직관적으로 보면, 언어 기반 표현은 사전학습된 LLM이 이미 갖고 있는 토크나이저와 단어 임베딩을 그대로 재사용할 수 있기 때문에, 더 데이터 효율적일 수 있습니다.
언어 기반 표현에서는 먼저 bounding box 좌표를 정규화한 뒤 quantization를 통해 연속값을 이산적인 정수로 변환합니다. 이 과정은 정보 손실이 발생할 수 있지만, 부동소수점 숫자를 그대로 쓰는 것보다 토큰 수를 줄일 수 있다는 장점이 있습니다. 저자들은 좌표 값을 [0,100] 범위의 정수로 변환하고, 각 값을 LLM의 기존 토크나이저를 통해 토큰화하여 임베딩합니다. 다만 하나의 bounding box를 표현하는 데 여러 개의 토큰이 필요하기 때문에, 긴 컨텍스트 길이가 요구되고 계산 비용이 증가한다는 단점도 함께 존재합니다.
반면 임베딩 프로젝터 방식에서는 bounding box를 벡터로 표현하고, 각 차원을 [0,1] 범위로 정규화한 뒤, 선형 레이어를 프로젝터로 학습합니다. 이 프로젝터는 bounding box 정보를 LLM의 단어 임베딩과 동일한 차원으로 변환해, LLM이 다른 토큰들과 함께 처리할 수 있도록 합니다.
2.4 Fine-tuning strategy
ObjectMLLM은 사전학습 LLM에서 시작할 수도 있고, 멀티모달로 확장되어 사전학습 MLLM에서 시작할 수도 있습니다. 학습 시에는 LLM 백본에 대해 parameter-efficient fine-tuning을 적용하고, 동시에 비전 프로젝터와 bounding box 어댑터의 임베딩 프로젝터를 함께 학습합니다.
사전학습된 LLM에서 출발하는 경우, 저자들은 VideoLLaMA2에서 사용된 modality-by-modality 학습 전략을 따릅니다. 즉, 여러 모달리티를 한 번에 넣는 대신, 단계적으로 하나씩 추가하며 모델을 적응시키는 방식입니다. 예를 들어 캡션과 bounding box를 모두 사용하는 모델을 만들고자 할 때, 먼저 캡션만 입력으로 사용하는 설정에서 학습을 진행합니다. 이후 모델이 비디오 프레임 캡션을 어느 정도 활용할 수 있게 되면, 그 다음 단계에서 캡션과 bounding box를 함께 포함한 입력으로 추가 파인튜닝을 수행합니다.
3. Experiment
실험에서는 먼저 ObjectMLLM에서 제안한 두 가지 bounding box 어댑터를 비교합니다. 그다음, 성능이 더 좋은 어댑터를 선택해 입력 모달리티를 어떻게 조합했을 때 효과가 있는지를 분석합니다. 마지막으로, 객체 중심 표현(object-centric representation)이 이미 시각 임베딩을 활용하도록 사전학습된 MLLM의 성능도 추가로 개선할 수 있는지를 살펴봅니다.
3.1 Benchmarks
객체 중심 표현의 효과를 평가하려면, 객체의 위치나 시간에 따른 움직임 정보가 반드시 필요한 질문들을 포함한 벤치마크가 필요합니다. 대표적으로 CLEVRER는 합성 비디오 데이터셋으로, 객체의 움직임과 충돌, 그리고 인과 관계에 대한 질문을 포함하고 있습니다. 다만 CLEVRER는 open-ended 질문이 많아 성능을 정량적으로 평가하기가 어렵습니다. 이를 보완하기 위해 일부 질문을 객관식 형태로 변환해서 사용합니다 . 이 외에도 다른 비디오 벤치마크인 Perception Test, STAR, NExT-QA, IntentQA에서 모델을 평가합니다.
3.2 Comparison of adaptation methods
먼저, 두 가지 bounding box 어댑터 자체의 차이를 비교합니다.
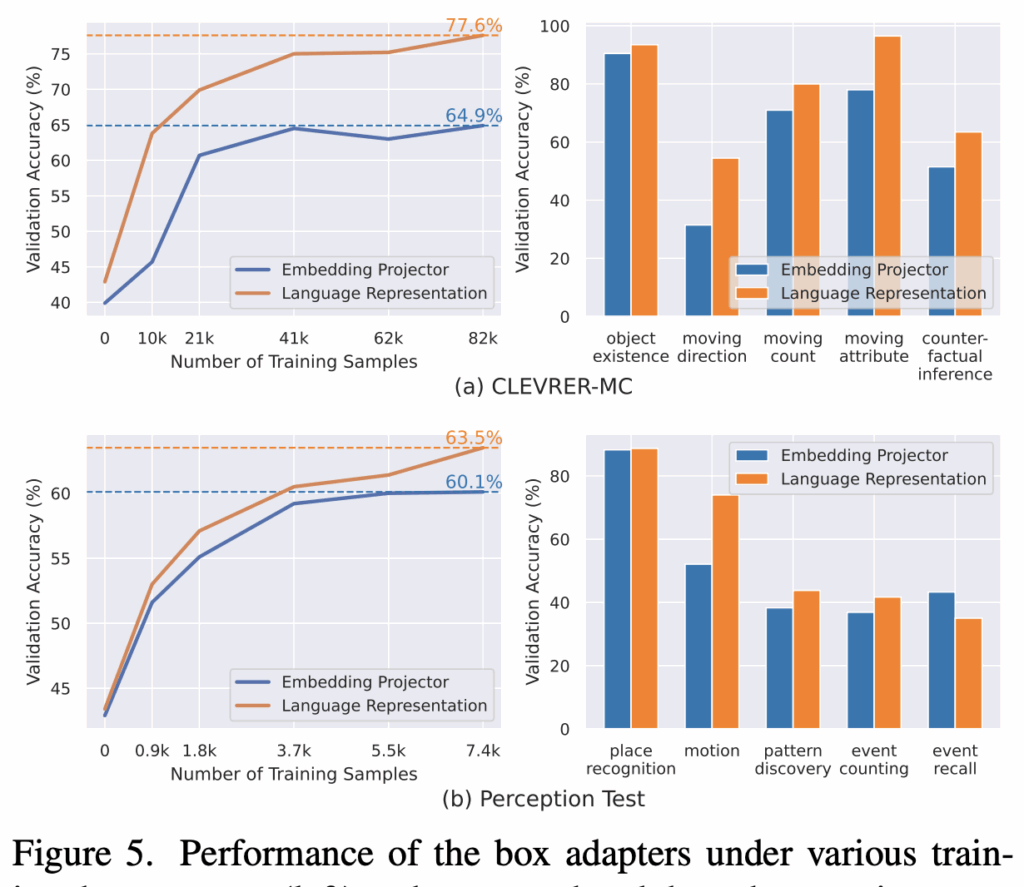
그림 5 왼쪽 그래프에서는 학습 데이터 양을 달리했을 때 두 어댑터의 성능을 비교한 결과입니다. 전체 학습 데이터를 사용할 경우, 언어 기반 표현이 임베딩 프로젝터 방식보다 더 높은 성능을 보입니다. 그리고 학습 데이터가 적을 때 성능 차이는 더 크게 벌이지는데 CLEVRER-MC에서 학습 데이터의 1/8 만 사용했을 때, 언어 기반 표현은 63.8%의 정확도를 달성한 반면, 임베딩 프로젝터 방식은 44.5%에 머뭅니다. 이는 임베딩 프로젝터가 bounding box 좌표의 연속성을 보존하긴 하지만, 적은 데이터 환경에서는 LLM이 이 임베딩을 이해하기 어렵다는 것을 의미합니다. 반대로, 기존 LLM의 어휘 체계를 그대로 재사용하는 언어 기반 표현은 훨씬 데이터 효율적으로 bounding box 정보를 활용할 수 있음을 보여줍니다. 그림 5 오른쪽 그래프는 질문 유형별 성능 비교 결과입니다. 일부 질문 유형에서는 두 방식의 성능이 비슷하지만, 움직임(motion) 관련 질문에서는 언어 기반 표현이 더 좋은 성능을 보입니다.
3.3 Influence of each modality
앞선 실험에서 언어 기반 bounding box 표현이 더 효과적임이 확인되었기 때문에, 이후 실험에서는 이를 기본 어댑터로 사용합니다. 이때 시각 임베딩, 비디오 프레임 캡션, bounding box를 하나의 모델에 통합하고, 각 모달리티 조합을 통한 ablation 실험을 수행합니다. 결과는 Table 1에 제시되어 있습니다.
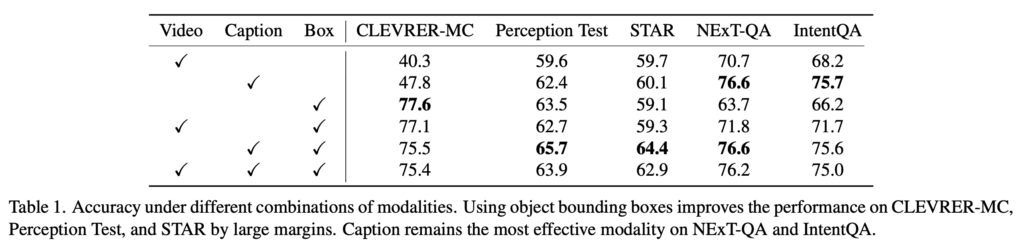
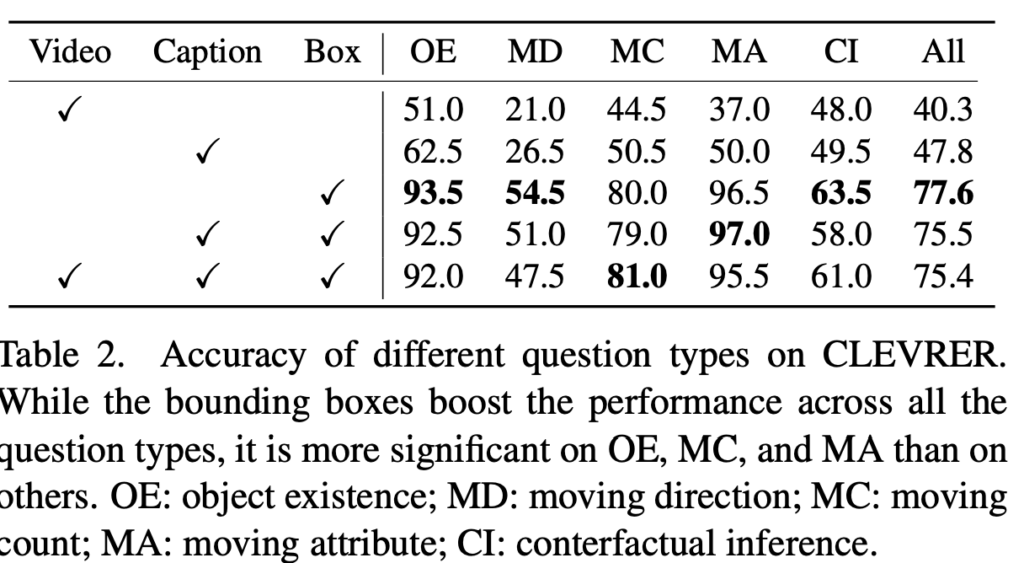
CLEVRER-MC와 Perception Test에서는 bounding box만 사용한 모델이, 비디오 임베딩만 사용하거나 캡션만 사용한 모델보다 더 좋은 성능을 보입니다. 비디오 임베딩만 사용하는 모델에 bounding box를 추가하면 일관된 성능 향상이 나타나며, 이는 비주얼 임베딩만으로는 객체 정보를 충분히 인코딩하기 어렵다는 점을 보여주고 있습니다.
Table 2의 질문 유형별 분석에서는 객체 존재 여부, 이동 개수, 이동 속성에 대한 성능 향상이 크지만, 이동 방향이나 counterfactual 추론에서는 개선 폭이 상대적으로 작습니다. 특히 이동 방향 질문의 경우, bounding box만으로 충분히 추론 가능해 보이지만, 학습 데이터에 이런 유형의 질문이 거의 없어서 일반화가 성능이 저하되었다고 저자는 분석하고 있습니다.
반면 NExT-QA와 IntentQA에서는 bounding box만 사용하는 모델이 캡션 기반이나 비디오 기반 모델보다 더 좋은 성능을 내지 못하는 모습을 보여주고 있습니다. 이는 해당 벤치마크들이 사람의 행동 이해나 사건 간 인과 추론에 초점을 맞추고 있어, 객체 위치 정보만으로는 한계가 있다는 것을 보여주고 있습니다.
마지막으로, 캡션과 bounding box를 함께 사용하는 모델은 항상 캡션 단독이나 box 단독 모델보다 성능이 같거나 더 좋았지만, 여기에 비주얼 임베딩을 추가해도 추가적인 성능 향상은 관찰되지 않았는데 이는 제한된 데이터 환경에서 임베딩 프로젝터를 학습시키는 어려움이 있다는 것을 알 수 있습니다.
3.4 Boosting pre-trained MLLMs with objects
다음으로 저자들은, 이미 사전학습된 MLLM에서도 객체 중심 표현이 추가적인 성능 향상을 줄 수 있는지를 분석합니다. 이를 위해 저자들은 VideoLLaMA2를 백본으로 사용해 ObjectMLLM을 구성하고, 기존의 비디오 입력에 더해 언어 기반으로 표현된 객체 bounding box를 함께 입력합니다.

Table 3의 결과를 보면, 사전학습된 VideoLLaMA2 백본만 사용한 상태에서는, bounding box 정보를 zero-shot으로는 제대로 이해하지 못함을 확인할 수 있습니다. 하지만 이후 LoRA를 이용해, 비디오와 bounding box를 함께 입력으로 사용하는 설정에서 파인튜닝을 수행하면, ObjectMLLM은 비디오 입력만으로 파인튜닝한 VideoLLaMA2보다 CLEVRER-MC, Perception Test, STAR에서 더 높은 성능을 달성합니다.
3.5 Comparison with existing MLLMs
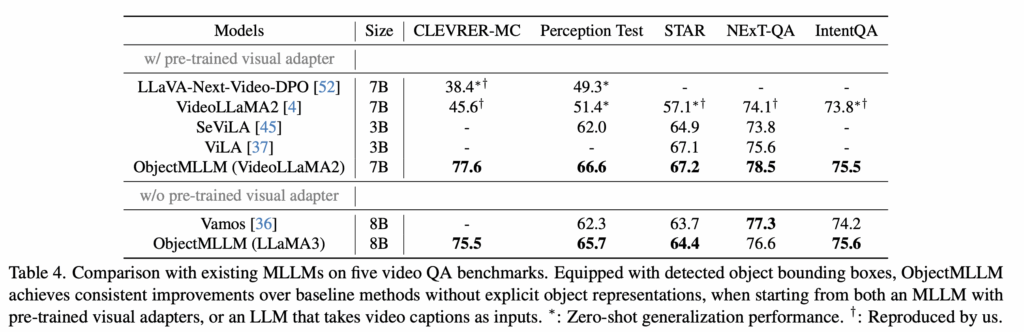
Table 4에서는 ObjectMLLM을 기존의 여러 MLLM들과 비교합니다. 비교 대상에는 대규모로 사전학습된 비주얼 어댑터를 사용하는 모델들과, 그렇지 않은 모델들이 포함됩니다. 객체 bounding box를 함께 사용하는 ObjectMLLM은, 모든 설정에서 기존 MLLM들보다 일관되게 더 높은 성능을 보입니다. 특히 CLEVRER-MC와 Perception Test에서 성능 차이가 크게 나타나는데, 이는 기존 MLLM들이 객체의 시공간적 배치(spatiotemporal configuration)를 이해하는 데 여전히 어려움을 겪는다는 것을 알 수 있습니다.
안녕하세요 의철님 리뷰 잘 읽었습니다!
세미나때 잘 설명해주셔서 이해하기가 훨씬 수월했던 것 같습니다~!
객체에 대한 박스 정보를 넣어주는게 핵심 요소인것 같은데
그럼 혹시 fig3에 객체가 object0, object1 이런 식으로 구분 되어질때 동일 객체(예를 들면 파란보틀, 빨간보틀)가 있을 경우에는 다른 오브젝트로 구분되어 트래킹이 되나요?
안녕하세요 찬미님 좋은 질문 감사합니다.
네 맞습니다. 말씀해주신 것 처럼 동일한 카테고리라도 서로 다른 물체로 인식되어 트래킹됩니다.
감사합니다.
안녕하세요 의철님 좋은 리뷰 감사합니다!
객체 중심 표현을 언어 기반 표현과 임베딩 기반 표현 방식으로 나누어 분석한 지점이 흥미로웠습니다.
2.2 Object Detection and Tracking에서, SAM2가 트래킹을 수행하는 동안 yolo-world가 현재 프레임에서 다시 detection을 수행한다고 하였는데요, detection을 하고 IoU 계산하여 중복 제거하는 과정이 매 프레임마다 반복되는 건가요? 연산 비용 측면에서는 무리가 없는 설계인지 궁금합니다.
감사합니다.
안녕하세요 예은님 좋은 질문 감사합니다.
네 말씀하신대로 매 프레임마다 SAM2로 기존 트랙을 tracking 하는 동시에 YOLO-World로 현재 프레임 전체에서 다시 detection을 수행하고, 그 결과와 기존 트랙 박스 사이의 IoU를 계산해 중복으로 제거한 뒤 남은 detection으로 새 트랙을 생성하는 과정이 반복됩니다. 계산량이 늘기는 하지만 Object-centric reasoning이 목표이기 때문에 효율보다는 일관된 객체 상태의 안정을 택한 것 같습니다.
감사합니다.