안녕하세요
LLM을 사용하여 비디오 요약을 해결한 논문을 살펴보려고 합니다!
리뷰 시작하겠습니다.
<Intro>
기존 기술은 visual features(시각적 단서)와 temporal dynamics(시간적 특징)에 의존하는데 이 비전 정보 중심의 방법들은 시각적인 단서엣만 의존하기 때문에 ‘왜 중요한지’와 같은 장면의 의미를 놓치곤 합니다!
예를들면 웃는장면이라 하더라도 단순한 웃음인지, 슬픈 웃음인지와 같은 차이를 의미적으로 구분해내지 못합니다.
최근 등장한 멀티모달 방법들은 나름 자연어의 문맥성을 활용하려 하지만 여전히 비주얼 정보가 메인이고 텍스트는 이 비주얼 정보에 부가되는 보조 정보(시각특징이 쿼리 / 언어특징이 키,벨류)로 사용됨으로 요약의 초점이 여전히 영상 자체가 됩니다.
저자들은 이것을 해결하기 위해 LLM의 언어적 이해력을 활용하겠다는 접근으로 시작합니다!
그래서 LLM을 사용하면 뭐가 더 좋은건가?를 간단하게 살펴보면 영상 프레임을 캡션으로 변환한 뒤 LLM에게 해당 장면의 중요도를 판단하는 방식으로 LLM의 문맥을 이해하고 추론하는 능력을 사용하여 단순한 중요도 판단을 넘어서 어떤 장면이 왜 중요한지까지의 판단을 할수있게 된다고 합니다.
즉, 영상 프레임을 언어로 표현함으로써 LLM의 인간과 유사한 추론 능력을 요약 과정에 직접 활용하자는 아이디어로 텍스트 정보와 LLM이 보유한 embedded global knowledge를 활용하여 LLM이 중요한 프레임을 선택하는 역할을 수행하도록 하는 LLMVS 프레임워크를 제안하였습니다.
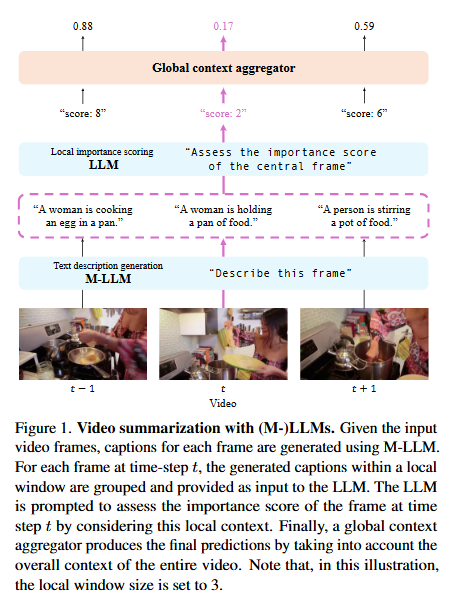
저자들이 제안하는 위의 fig1과 함께 LLMVS프레임워크를 먼저 간략히 살펴보자면!
M-LLM을 사용하여 프레임을 캡션으로 변환하고 LLM이 로컬 문맥 기반으로 프레임 중요도 점수를 산정하는데 앞뒤 w개의 프레임 캡션을 포함한 문맥을 LLM에 함께 입력합니다. 함께 넣어주는 지시문으로 “중앙 프레임이 얼마나 중요한지 1~10점으로 평가하라”는 지시를 통해 각 프레임의 중요도 점수를 예측합니다.
이때 예시(in-context examples)를 함께 제공하여, LLM이 in-context learning을 통해 주어진 예시의 패턴을 따라 추론 규칙을 적용하도록 합니다.
마지막 단계로 글로벌 self-attention을 통해 전체 흐름을 고려하여 점수를 보정하는데 로컬 문맥만으로는 전체 스토리를 놓칠 수 있기 때문에, LLM에서 추출한 출력 임베딩(output embeddings) 을 입력으로 사용하여 self-attention을 적용합니다. 즉 모든 프레임의 임베딩을 전역적으로 통합하고 조정함으로써 영상의 전체 스토리 구조와 앞뒤 장면 간의 상관관계를 반영한 최종 예측을 생성합니다.
<LLMVS>
위에서 간략하게 언급한 LLMVS의 전체 프레임 워크는 다음과 같이 진행됩니다
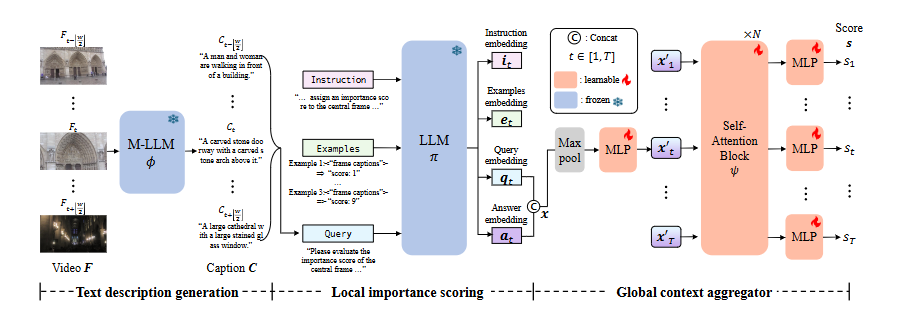
[1단계 : M-LLM이용해서 텍스트 설명 생성(text description generation)]
목적은 비디오 프레임을 언어텍스트 표현으로 변환하는 것으로 C = ϕ(F) : 각 프레임을 ϕ(M-LLM,멀티모달 대형 언어모델, LLaVA썼다고 함)에 넣어 각 프레임(1~T)에 해당하는 캡션시퀀스 C=(C1~CT)를 만든다. 이때 “Provide a detailed one-sentence description”이라는 프롬프트를 ϕ에 함께 입력한다.
[2단계 : LLM을 통한 local 중요 프레임 점수 산출(local importance scoring)]
목적은 각 프레임이 local temporal context내(윈도우기반)에서 얼마나 중요한지를 평가하는 것으로 캡션 시퀀스(C)를 인풋으로 해서 π(LLM,사전 학습된 대형언어모델)에 넣어준다.
비디오프레임에는 중복성이 존재하기 때문에 개별 프레임단위가 아닌 인접 프레임도 다루는 로컬문맥을 기반으로 핵심 프레임을 식별하는 것이 중요하기 때문에 슬라이딩 윈도우 방식으로 시간스텝t의 프레임 Ft에 대해 윈도우w에 포함되는 캡션들을 LLM π에 입력으로 넣어주고 윈도우의 중앙 프레임이 주변 프레임과의 관계에서 얼마나 중요한지 평가한다.
- In-context Learning
- 비디오 요약 task에 특화된 출력을 생성하도록 유도하기 위해 LLM에 인풋할때 프롬프트 내에 예시,지시문(instruction),질의(queries)를 직접 포함시킨다. 이때 지시문,예시는 고정되어 있고, 질의는 입력 비디오에 따라 변경된다. 이 세가지를 직접 포함시킴으로 파인튜닝 없이도 사전학습된 LLM을 VS에 효과적으로 활용할 수 있다.
- 지시문 : 프레임의 중요도 & 기준을 정함
- 예시 : 비디오 요약과 관련된 3개의 질문-답변 쌍 제시
- 질의 : LLM이 실제로 답변해야 할 질문
- LLM의 출력 임베딩 사용하기 (Llama-2)
- 기존의 LLM 기반- 모델처럼 π의 출력(답변 txt)을 직접 사용하는 것이 아닌 내부적으로 더 풍부한 의미적인 정보를 보존하고 있는 내부 임베딩을 추출해서 활용한다.
- 조금 더 자세히 살펴보자면 추론이 끝나기 직전의 Llama-2의 RMSNorm레이어 뒤에서 추출되는데, 각 프레임 t에 대해 instruction i, examples e, query q, answer a 임베딩을 추출해서 사용한다. 최종 텍스트 출력 전 임베딩은 언어적으로 요약되기 전의 의미적 표현을 담고있기 때문에 각 프레임의 의미나 맥락, 중요도 등이 압축된 고품질의 표현이 들어있다고 한다.
- 4가지 임베딩 중 instruction i, examples e 는 프레임들 간에 일정하게 유지되기 때문에 윈도우에 따라 달라지는 query q, answer a를 집중적으로 사용한다.
- 즉, 입력 캡션에 대한 문맥 표현인 쿼리 임베딩과, LLM의 응답표현인 응답 임베딩만 가져간다.
→ 지시문과 예시 임베딩은 모든 프레임에서 동일하다.
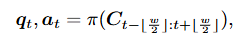
[3단계 : Self-Attention블록을 이용한 global context aggregation]
LLM으로 로컬 context안에서 중요한 프레임을 효과적으로 중요도를 매길수 있지만 비디오 전체에 대한 일관된 요약을 생성하려면 글로벌 context에 대한 이해가 필수적이다. 저자들은 이 부분을 위해 self-attention 블록 ψ를 적용하여 비디오 전체에 걸친 프레임 간의 의존성을 학습하고 최종 중요도 점수를 보정하여 예측할수 있게 한다. 즉, LLM이 로컬에서 만든 의미 판단 결과인 query q, answer a들을 비디오 전체 흐름의 관점에서 다시 조율해주는 단계이다.
해당 단계를 자세히 살펴보자면 먼저 각 시간스텝 t에 대해 직전단계(로컬단계)에서 얻은 query 임베딩qt와 answer 임베딩at을 시퀀스 차원에서 콘캣해주고 해당 벡터를 맥스 풀링과 MLP를 통과시켜 최종적으로 모든 시간스텝인 프레임당 하나의 벡터를 만들어 주어 글로벌 self-attention 블록 ψ에 입력할수 있도록 형태를 맞추어 준다. 이때, 이 q는 로컬 문맥속에서의 맥락을 담고있고 a는 LLM이 내린 판단을 가지고 있기 때문에 이 둘을 합침으로 해당 프레임이 어떤 맥락에서 어떤 판단을 받았는지가 함께 들어가게 되는 것이다.
이 글로벌 self-attention (ψ)만 학습되고 1단계인 M-LLM과 2단계인 LLM은 frozen된다. 즉 의미 추론에 강점을 가진 LLM은 건드리지 않고 self-attention만 최소한으로 학습하는 것으로 LLM이 만들어낸 의미적 판단 겨로가를 전체 비디오 관점에서 어떻게 조합할지만을 학습한다.
[Training Objective]
프레임 중요도 예측을 학습하기 위해 예측된 중요도 점수 s와 정답 중요도 점수 s 간의 손실L은 MSE손실함수를 사용한다. (T:비디오 길이)
MSE를 사용해서 3단계의 결과 보정이 GT와 얼마나 잘 맞는지만을 학습한다.
<Experiment>
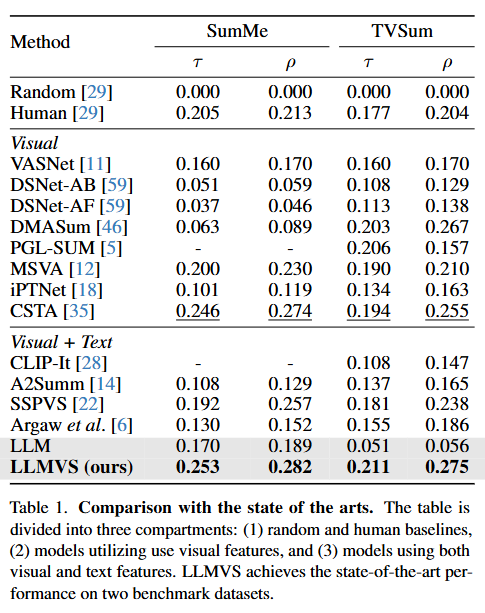
- 먼저 저자들은 비디오 요약에서 가장 널리 쓰이는 벤치마크 데이터셋인 SumMe와 TVSum을 사용하여 다른 SOTA 요약모델들과의 성능을 비교했습니다.
- 위의 실험 결과는 총 3개의 섹션으로 나뉘어져 있고 평가지표는 순위 상관관계를 나타내는 Kendall’s τ(타우) 와 Spearman’s ρ(로우) 를 사용하여 평가를 진행합니다
- 표의 제일 하단에 있는 LLM과 LLMVS는 위의 아키텍처에서 말한 3단계(글로벌 self-attention ψ)를 했느냐 안 했느냐의 차이로 로컬 문맥에서 산출된 중요도 판단 결과를 3단계를 통과한 비디오 전체 흐름의 관점에서의 재조정했을때 그 효과가 성능차이로 나타난다는 것을 보여줍니다.
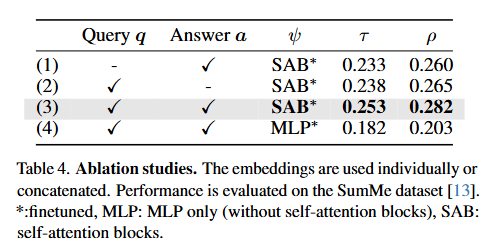
- 다음으로 LLMVS에서 가장 중요한 구성요소가 무엇인지 살펴보는 ablation studies으로 저자들이 제안한 방법에서 출력임베딩인 q,a와 3단계의 self-attention 블록ψ의 효과를 검증했다.
- 1행과 2행은 3단계의 query 임베딩 q또는 answer 임베딩 a만 사용한 경우를 비교한 것으로 쿼리 임베딩을 활용하는게 answer 임베딩만 사용하는 것보다 더 좋은 성능을 보임을 확인함으로 q에 반영된 주변 캡션 정보가 LLM의 의미 처리능력을 더 풍부하게 한다는 것을 알수있다.
- 3행을 통해 두 query 임베딩 q과 answer 임베딩 a을 다 사용한 성능으로 저자들이 제안하는 q(무슨상황인가?) + a(LLM이 어떻게 판단했는가?) + ψ(이 판단이 전체 영상에서 어디쯤인가?)가 모두 결합될때 최적의 성능을 보이는것을 알수 있다.
- 마지막으로 4행은 ψ로 사용된 self-attention 블록(SAB)을 단순한 MLP로 대체했을 때의 성능이다. 3행과 4행을 비교하면 프레임간의 관계를 보지 못하는 MLP를 사용하는 것 보다 프레임 간의 상대적 중요도 관계를 학습하는 글로벌 self-attention 블록을 사용하는것이 더 효과적임을 확인할수 있다.
이상으로 LLM을 사용한 비디오 요약 논문리뷰를 마치도록 하겠습니다.
읽어주셔서 감사합니다!
안녕하세요 찬미님 좋은글 감사합니다.
video summarization task 를 읽어본적이 없어 읽게되었습니다. 우선 해당 방법론이 어떠한 method를 통해 동작되는지는 얼추 이해가 되지만 task에 대한설명이 조금 빠져있는 것 같습니다. 평가방식인 타우와 로우가 순위상관관계에서 어떤걸 알려주는 지표인가요? 혹은 입력과 출력 그리고 어떤걸 맞춰야하는지에 대한 설명이 추가적으로 있으면 좋을 것 같습니다. 감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
논문의 introduction 부분에서 vision 정보만 활용하는 방법론들은 웃는 장면에서 왜 웃는지 이해하기 어렵다는 문제를 지적하였는데, 제안하는 방법론에서 이러한 인과관계 등 비디오의 더욱 복잡한 장면간 관계를 단순 self attention으로 다루는 것으로 이해했습니다.
기존 vision only나 vision+text도 global context를 잡기 위한 self attention layer는 들어가있을 것 같은데, 비디오의 복합적인 장면간 관계를 포착했다는 논문의 실험이나 찬미님의 견해가 있는지 궁금합니다.
안녕하세요 찬미님 좋은 리뷰 감사합니다!
M-LLM으로 ‘장면이 왜 중요한지’ 판단할 수 있고, 두 번째 LLM과 self attention을 통해서 최종 중요도 점수를 구한다고 이해했습니다. 하지만 최종 학습은 정답 중요도 점수와 예측 중요도 점수의 MSELoss만을 사용해서 진행되는데, 이 과정에서 M-LLM이 생성한 reasoning에 대한 텍스트 데이터는 학습에 기여하는 부분이 없는 지(주관식 정답이 존재해서 이것과 비교한다던지), 아니면 단순히 임베딩을 추출하기 위한 용도로만 쓰이는 건지 궁금합니다.
안녕하세요 찬미님 좋은 리뷰 감사합니다.
읽다가 궁금한점이 몇가지 생겨서 질문드립니다
먼저 llama와 같은 llm에 대한 제 지식이 많지 않아서 드는 의문일 수도 있는데
글에서 insturction i, examples e , query q, answer a와 같은 임베딩을 추출한다고 하셨는데
이는 마치 ViT에서 뒤쪽 레이어들을 가져온다고 생각하면 될까요?
그리고 글로벌 self-attention쪽이 이해가 잘 안갔는데,
시간 스텝에 따라 q와 a를 concat해 준것을 전부 모아 self attention 했기에 global한 특징도 챙겼다고 이해하면 될까요?
안녕하세요, 황찬미 연구원님. 리뷰 잘 읽었습니다. 좋은 리뷰 감사합니다. 읽으면서 몇가지 궁금한점과 피드백 있어 댓글 남깁니다.
해당 방법론은 결국 비디오 프레임마다 캡션을 LLM으로 뽑고(모델 보니까 예전 오픈소스 모델들 활용했네요), 인접 프레임들의 캡션을 함께 사용해서 scoring하는 방법이네요. 간단한 아이디어로 LLM을 잘 활용했다고 생각됩니다. 방법론 자체는 굉장히 간단한데, 모든 프레임에서 캡션 뽑고 이 캡션들을 전부 다시 LLM을 써서 scoring하는거 보면 너무 LLM에 의존하여 연산량이 매우 커 보입니다. 연산량 관점에서 저자들의 분석이나 개선사항은 없었는지 궁금합니다.
예를 들어, Local importance Scoring에서는 비전 정보 없이 각 프레임들의 자연어 캡션만 가지고 scoring하는 것 같은데, 굳이 LLM을 사용해야 하나? 라는 의문이 듭니다. Llama2같은 대용량 모델까지 가지 않더라도 비교적 작은 임베딩 모델(발전된 BERT계열이라던지)을 활용해서 충분히 scoring이 가능할 것 같기도 한데, 혹시 해당 모듈에서 LLM을 사용해야만 하는 이유가 있는지 궁금하네요. 답변 주시면 감사하겠습니다.
그리고, 지금까지 작성하신 대부분의 리뷰에 대해 답변을 작성하지 않은 것으로 보입니다. 빠른 시일 내에 밀린 답글 전부 작성하시기 바랍니다.