Intro
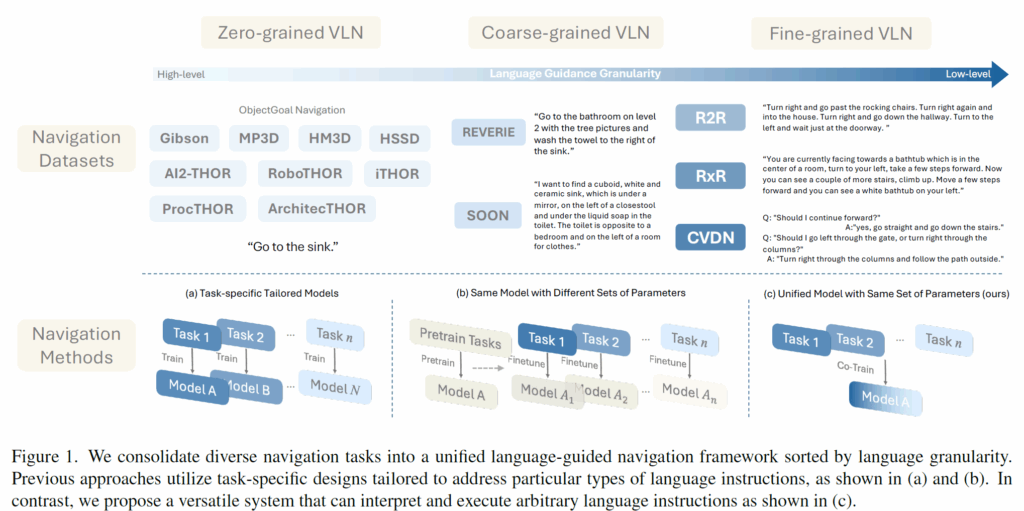
최근 비전-언어 네비게이션(Vision-and-Language Navigation) 분야는 다양한 태스크로 분화되었습니다. 저자들은 이를 언어 지시어의 세밀함(Granularity)에 따라 크게 두 가지로 분류합니다.
- High-level (탐험 중심): “싱크대로 가”와 같이 목표만 제시하는 태스크 (예: ObjectNav dataset).
- Low-level (지시 따르기 중심): “오른쪽으로 돌아서 복도를 따라가다가…”와 같이 구체적인 경로를 알려주는 태스크 (예: R2R dataset).
이들은 겉보기에 다른 목표를 가진 것처럼 보이지만, 본질적으로는 지시어를 해석하고, 주변을 이해하고, 행동을 결정한다는 공통된 목적성을 지니고 있습니다.
하지만 지금까지의 연구들은 이 태스크들을 완전히 별개의 문제로 취급해 왔는데, 가령 특정 태스크에만 최적화된 모델 구조(예: 탐험을 위한 메모리 구조 vs 지시어 해석을 위한 정렬 모듈)를 개발하다 보니, 다른 태스크에는 적용하기 어려운 경우가 많았습니다.
그렇다면 단순히 여러 태스크의 데이터를 모아서 하나의 모델을 학습시키면 어떨까요? 저자들의 연구에 따르면, 단순히 데이터를 섞는 것은 태스크 간의 상충되는 학습 목표 때문에 오히려 성능 저하(Negative Transfer)를 일으키는 것으로 나타났습니다.
저자들은 이러한 문제를 해결하기 위해 SAME이라는 새로운 프레임워크를 제안합니다. 핵심 아이디어는 공통된 지식은 공유하되, 상황에 따라 필요한 기술만 골라서 쓰자는 것입니다. 이를 구현하기 위하여 거대 언어 모델(LLM)에서 쓰이던 Mixture of Experts (MoE) 기법을 도입하여, 에이전트의 현재 상태(시각 정보 + 언어 지시어)에 따라 적절한 전문가 네트워크를 동적으로 선택합니다. 이를 통해 탐험이 필요할 때는 탐험 전문가를, 세밀한 이동이 필요할 때는 이동 전문가를 활용하여 7가지의 다양한 네비게이션 태스크를 아우르는 범용 에이전트를 구축했습니다
Background
우선 VLN task에 대한 문제 정의 및 과정에 대해서 정리하겠습니다.
L개의 단어 임베딩 시퀀스 \mathcal{W}={w_{i}}{i=1}^{L}로 표현되는 지시어가 주어졌을 때, 에이전트는 미리 정의된 무방향 그래프(undirected graph) \mathcal{G}=\langle\mathcal{V},\mathcal{E}\rangle 상에서 네비게이션을 수행합니다. 여기서 \mathcal{V}는 이동 가능한 노드들을, \mathcal{E}는 연결 엣지들을 나타냅니다.
에이전트는 지시어 \mathcal{W}에 명시된 대로 목표 위치 v{T}로 이동하기 위해 일련의 행동 시퀀스 {s_{0},a_{0},s_{1},a_{1},…,s_{T},a_{T}}를 실행해야 합니다. 각 행동 a_{t}는 에이전트를 현재 상태 s_{t}=\langle v_{t},\theta_{t},\phi_{t}\rangle에서 다음 상태 s_{t+1}=\langle v_{t+1},\theta_{t+1},\phi_{t+1}\rangle로 전이시키며, 여기서 상태는 공간적 위치 v_{t}\in\mathcal{V}, 방향각(heading angle) \theta_{t}, 그리고 고도각(elevation angle) \phi_{t}를 포함합니다.
또한 행동에 따라 새로운 시각적 관측 \mathcal{O}{t}가 생성됩니다. 추가적으로, 에이전트는 상태 기록(state history) h{t}를 유지하며, \mathcal{S}{t}=\mathcal{T}(s{t+1}|a_{t},s_{t},h_{t},\mathcal{O},\mathcal{W})로 정의되는 상태 간의 조건부 전이 확률을 조정합니다. 여기서 \mathcal{T}는 조건부 전이 확률 분포를 의미합니다.
저자들은 앞서 intro에서 간략하게 소개드렸다시피 언어 지시어 \mathcal{W}를 세밀함(granularity)에 따라 다음 세 가지 클래스로 분류합니다.
- Fine-grained VLN: \mathcal{W}가 행동 시퀀스 {s_{0},a_{0},s_{1},a_{1},...,s_{T},a_{T}}를 단계별(step-by-step)로 묘사합니다.
- Coarse-grained VLN: \mathcal{W}가 원격 목표 지점 v_{T}를 지칭합니다. 예: “2층 첫 번째 침실에 있는 냉수 수도꼭지”.
- Zero-grained VLN: \mathcal{W}가 목표를 나타내는 단일 용어(예: OBJECTNAV에서의 물체 카테고리)를 지칭합니다.
Multimodal Navigation Policy
매 단계마다, 에이전트는 36개의 뷰 이미지로 구성된 지역적 시각 관측 \mathcal{O}{t}={o{i}}{i=0}^{36}와 언어 지시어 \mathcal{W}를 입력받습니다. 이들은 비전 인코더와 언어 인코더에 의해 각각 시각 특징 \hat{O}{t}와 언어 특징 \hat{\mathcal{W}}로 인코딩됩니다. DUET 모델은 \hat{O}{t}와 에이전트의 상태 s{t}를 통합하여 노드 임베딩 \hat{V}{t}를 얻고, 네비게이션 기록으로서 위상 지도(topological map) \hat{\mathcal{G}}{t}={\hat{V}{i}}{i\le t}를 유지합니다. 이후 crossattention이 구성된 교차 모달 인코더(local cross-modal encoder)를 통해 언어 특징을 시각 특징에 injection합니다.
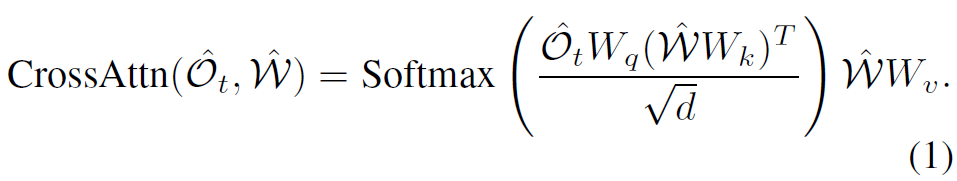
뷰 o_{i}의 마지막 레이어에서 출력된 임베딩을 \hat{o}{i}^{\prime}라고 표기합니다. 마찬가지로, language conditioned map \hat{\mathcal{G}{t}}^{\prime}=\text{CrossAttn}(\hat{\mathcal{G}}{t},\hat{\mathcal{W}})을 인코딩하기 위해 병렬적인 전역 교차 모달 인코더(global cross-modal encoder)가 구현됩니다. 노드 V{i}의 출력 임베딩을 \hat{v}_{i}^{\prime}라고 할 때, 지역 및 전역 교차 모달 인코더가 제공하는 네비게이션 점수는 다음과 같이 계산됩니다:
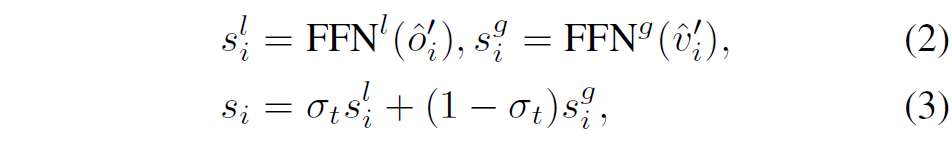
여기서 시그마는 학습되는 파라미터라고 합니다.
Dataset
다음은 저자들이 언어 지시어에 대하여 3가지 기준을 나눴을 때 각 기준에 부합되는 대표 데이터셋에 대한 소개도 잠깐 하고 가겠습니다.
- R2R dataset: 22,000개의 사람이 주석을 단 네비게이션 지시어로 구성된 Fine-grained VLN 태스크입니다. 평균적으로 지시어는 32개의 단어를 포함하며, 정답 경로는 7단계(step), 총 10미터로 구성됩니다.
- REVERIE: R2R의 경로를 상속받지만 목표 물체를 묘사하는 고수준(high-level) 지시어를 제공하는 Coarse-grained VLN 태스크입니다. 평균적으로 지시어는 21개의 단어를 포함하며, 정답 경로의 길이는 4~7단계입니다.
- OBJECTNAV-MP3D : 저자들은 MP3D 내의 Habitat OBJECTNAV 데이터셋 의 표준 validation split에 있는 11개 장면들을 사용하며, 이는 21개의 목표 카테고리로 구성됩니다. 학습 데이터로는 Habitat-Web 의 인간이 시연한 데이터를 활용했다고 하네요.
Data Transformation in Discrete Environment
범용 Navigation agent를 성공적으로 학습시키기 위해서는 다양한 level의 instruction 데이터셋을 통합하여 모델을 학습하였을 때 학습을 방해하는 근본적인 문제점이 무엇인지를 분석할 필요가 있습니다. 따라서 저자들은 이산 환경에서 Habitat-Web dataset의 70k 인간 시연(demonstration) OBJECTNAV 데이터를 변환하여 학습 데이터를 통합하고자 했습니다.
우선 OBJECTNAV의 원래 궤적은 연속적인 시점 위치들의 시퀀스로 구성되어 있으며, 하나의 시연 당 평균 243step이 구성되어있습니다. 저자들은 이전 연구들과 동일하게 Habitat-MP3D 환경을 연결 그래프 \mathcal{G}^{}로 이산화합니다.
구체적으로, Habitat-Web 궤적의 각 시점을 유클리드 거리에 기반하여 \mathcal{G}^{} 상의 가장 가까운 노드에 매칭하고 순차적으로 반복되는 노드의 경우에는 병합합니다. 그리고 연결되지 않은 경로와 원래 종료 지점보다 0.5m 이상 떨어진 종료 위치를 가진 경로는 제거를 하며, 그 결과 평균 step이 20개 정도로 구성되는 58,803개의 궤적을 얻게 됩니다. 이와 동일하게 MP3D 데이터셋에 대한 validation set도 동일한 이산화 과정을 거치게 됩니다.
Fine-grain Language Understanding Benefits Target-oriented Navigation
저자들은 다양한 데이터 혼합을 사용하여 LXMERT(가 무엇인지는 잘 모르겠지만?)로 초기화된 DUET이라는 VLN 모델을 멀티태스크 방식으로 학습하고, 학습에 포함되지 않은 데이터셋에 대한 보류된 추론 결과를 리포팅합니다. 이때, Habitat 렌더링 이미지와 Matterport3D 렌더링 이미지 간의 시각적 격차를 해결하고자 R2R 및 REVERIE 궤적을 \mathcal{G}^{*}에 매핑하고 이 실험에 Habitat 렌더링 이미지를 사용했다고 하며 해당 실험 결과는 아래 표와 같습니다.
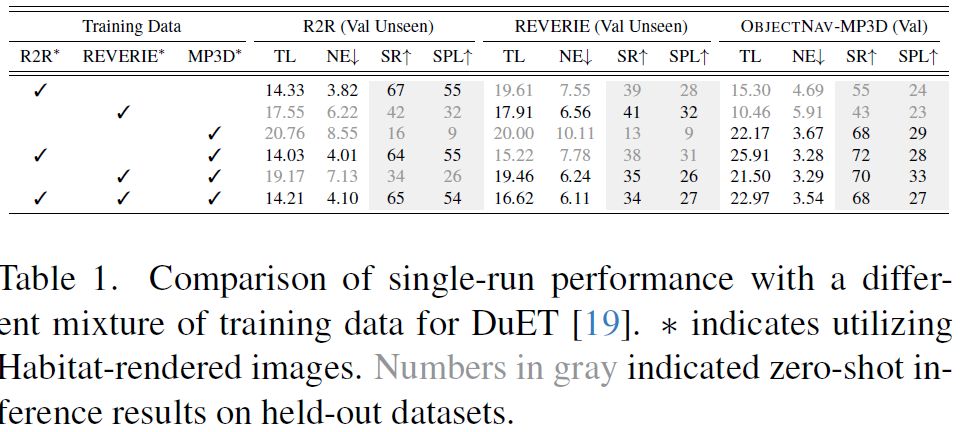
이 표를 통해 저자들은 다음 3가지 흥미로운 결과를 발견했다고 합니다.
- 여러 태스크의 학습 데이터를 섞는 것은 고차원적인 언어 이해 능력이 필요한 개별 태스크에 대해 학습하는 것에 비해 성능을 감소시킵니다. 예를 들어, R2R 태스크에서 추가 데이터를 포함하면 성공률(SR)이 2-3% 하락하며, REVERIE 데이터로 평가할 때 학습 데이터로 OBJECTNAV 데이터를 같이 사용할 경우 상당한 SR 감소(6-7%)가 발생하여 R2R 데이터만으로 학습했을 때 달성한 제로샷 성능보다도 낮아집니다 (39% SR 대 35% SR).
- 두번째는 세밀한 human annotated instruction-trajectory 쌍으로 학습하는 것은 OBJECTNAV에 유리하며, 2-4%의 SR 향상을 가져옵니다.
- 마지막으로, VLN 데이터만으로 학습된 모델(즉 R2R 또는 REVERIE 데이터셋만으로 학습)은 OBJECTNAV에서 강력한 제로샷 성능(40% SR 이상)을 달성합니다. 반면에 OBJECTNAV 데이터만으로 학습된 모델은 정교한 언어 이해가 요구되는 태스크(R2R, REVERIE 평가)에서 저조한 성능(약 15% SR)을 보입니다.
저자들은 위의 3가지 발견을 통해 다음과 같은 결론을 내립니다. 우선 세밀한 언어 이해는 비전-언어 정렬 학습을 통해 시각-의미적 이해가 향상되므로 목표 지향적 네비게이션(OBJECTNAV)의 성능을 개선합니다. 그러나 목표 지향적 데이터만으로 학습된 모델은 복잡한 지시어를 따르는 데 필요한 언어 이해력이 부족합니다.
그리고 단순한 데이터 혼합으로 학습하는 것은 탐험과 상세한 지시어 해석(Coarse-grained VLN)을 모두 요구하는 태스크에서 최적의 성능을 달성하기에 불충분합니다.
Mixture of Experts for Versatile Language-guided Visual Navigation
앞선 실험 결과를 통해 저자들은 서로 다른 깊이의 instruction으로 구성된 데이터셋들의 멀티태스크 학습 중에 발생하는 gradient conflict 문제를 해결해야 한다고 생각하였습니다. 그래서 저자들은 SAME (State-Adaptive Mixture of Experts)라는 VLN framework을 제안하게 되는데, 이름에서도 유추 가능하다시피 MoE 기반으로 동작을 합니다.
즉, SAME은 다수의 전문화된 전문가 네트워크 {f_{1},\cdot\cdot\cdot,f_{N}}를 도입하며, 이들은 네비게이션 에피소드의 각 단계에서 라우팅 메커니즘 \mathcal{R}에 의해 에이전트의 상태를 조건으로 하여 최적의 네트워크로 전환 될 수 있습니다.
MoE Formulation
우선 MoE에 대해서 간략하게 설명하고 넘어가겠습니다. 각 forward pass 동안 희소 게이트(sparsely gated) MoE 레이어에서 전문가들의 하위 집합(subset)이 활성화됩니다. 이때, 라우터는 아래와 같이 각 전문가가 할당될 확률을 예측합니다.
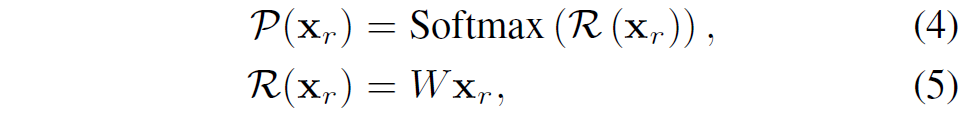
여기서 x_{r}은 입력 x에서 추출된 라우팅 특징(routing feature)이고, W\in\mathbb{R}^{N\times d}는 학습 가능한 레이어, d는 hidden dimension, N은 전문가의 수입니다. 상위-k개(\text{top-}k)의 라우팅 점수를 가진 전문가들(집합 \mathcal{T}로 표기)의 출력에 대한 가중 합이 최종 출력으로 계산됩니다.
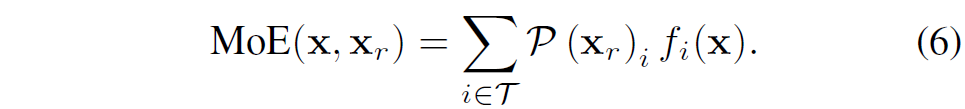
일반적으로, N개의 전문가들에게 입력이 고르게 분포되도록 장려하기 위해 load balancing loss가 구현됩니다.
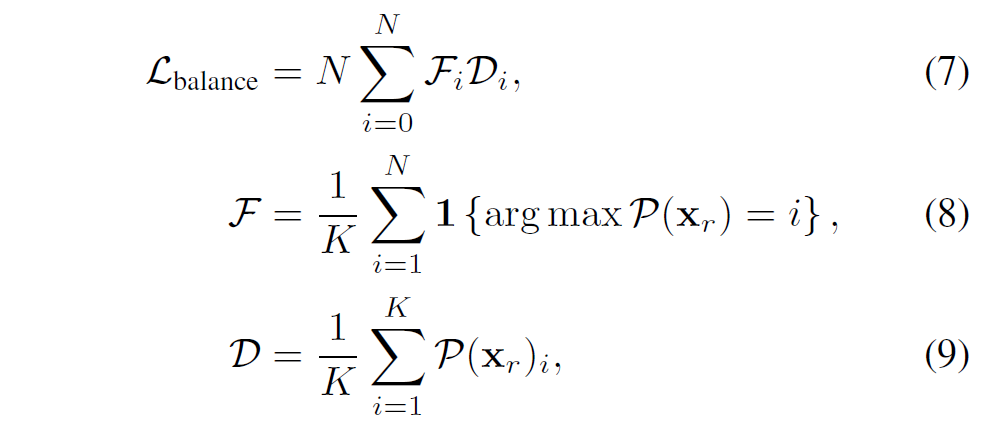
여기서 \mathcal{F}는 각 상위-K 전문가 f_{i}에 의해 처리되는 입력의 비율을 나타내며, \mathcal{D}는 전문가 f_{i}에 할당된 라우터 확률의 비율을 나타냅니다.
Task-wised MoE and Token-wised MoE
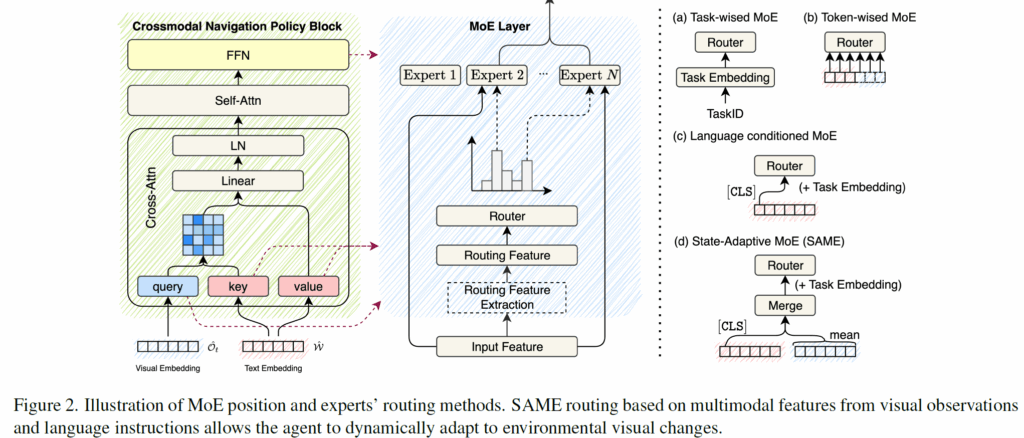
최근 대부분의 MoE에 대한 연구는 LLM에 집중되어 있으며, 해당 방법론들은 그림 2에 묘사된 것처럼 MoE가 토큰 수준에서 작동하여 각 개별 입력 토큰을 처리합니다. 물론 MoE는 컴퓨터 비전 멀티태스크 학습에서도 광범위하게 활용되고 있는데 여기서는 전문가 모듈들이 task 수준에서 라우팅됩니다. 이 두 가지 라우팅 특징은 다음과 같이 정식화됩니다.
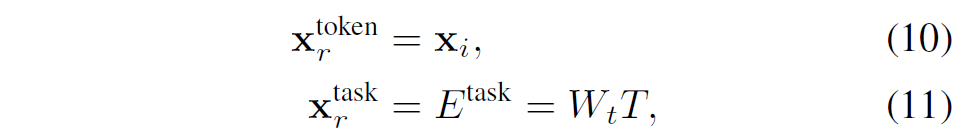
위의 수식에서 x_{i}는 입력 x의 i번째 토큰이며, E^{task}는 인덱스 T를 가진 task에 대한 task embedding을 의미합니다.
저자들은 hard assignment을 통해 각 task T를 특정 전문가에게 할당하는 것을 넘어, 에이전트가 text instruction를 기반으로 적절한 네비게이션 기술? 네트워크?를 선택하는 것이 성능에 긍정적이라고 생각하였습니다. 이를 위해, 저자들은 아래 수식과 같이 language-aware expert selection mechanism을 도입합니다.
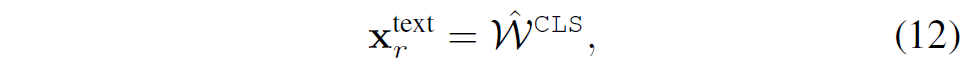
\hat{W}^{CLS}는 텍스트 특징 W에 대한 [\text{CLS}] 토큰을 나타냅니다. 해당 토큰의 쓰임새는 아래에서 설명드리겠습니다.
State-Adaptive Experts Selection
멀티태스크 네비게이션 학습에서 앞서 언급한 토큰별(token-wise) 및 과업별(task-wise) MoE를 사용한 초기 실험은 차선의 결과를 낳았다고 하며, 저자들은 해당 결과를 통해 네비게이션의 순차적 의사결정 과정에 대하여 더욱 실현 가능한 MoE formulation을 만들어야 한다고 판단했습니다.
뭔가 말을 거창하게 했는데 단순히 이야기하면, Expert를 선택하는 알고리즘을 더욱 견고하게 만들필요가 있다는 것 같습니다. 저자들은 에이전트가 행동을 결정하기 위해 시각적 관측과 정렬된 text instruction 정보의 밀도가 서로 다른 task에서 다른 타임스텝(timesteps)에 따라 상당히 달라질 수 있음을 관찰했다고 합니다. 즉, 저자들은 에이전트의 상태 해석(state interpretation)이 별개의 네비게이션 문제들을 해결하기 위해 일반화 가능해야 한다고 주장합니다.
조금 더 부연 설명을 하면 task마다 언어의 밀도도 다르고, time-step에 따른 관측되는 visual observation도 다 다른 상황에서도 최적의 action값을 예측하기 위해서는 현 상태를 해석하고 진단하는 능력이 일반화 가능해야한다?라는 주장 같습니다. 이러한 관점에서 저자들은 State-Adaptive expert selection 메커니즘인 SAME을 제안합니다.
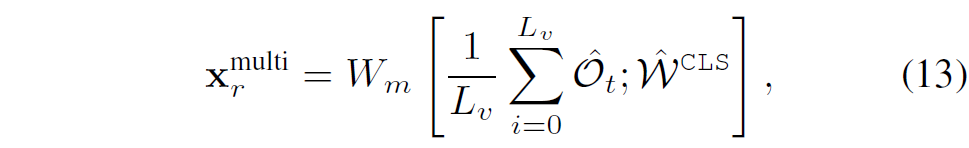
여기서 선형 레이어 W_{m}\in\mathbb{R}^{h\times2h}은 여러 뷰(view)에 대한 평균 시각 특징 \frac{1}{L}\sum_{i=0}^{L}\tilde{\mathcal{O}}_{t}와 텍스트 [\text{CLS}] 토큰 \hat{W}^{CLS}의 concatenation을 병합하기 위해 사용됩니다. 결과적으로 multi-view에 대한 시각정보와 text 정보를 적절히 섞어서 최적의 expert를 selection하겠다는 의미 입니다.
게다가 저자들은 expert selection을 수행할 때 아래 수식들과 같이 task information도 함께 추가한다고 하네요. task information은 수식11에서 정의하고 있으니 참고 바랍니다.
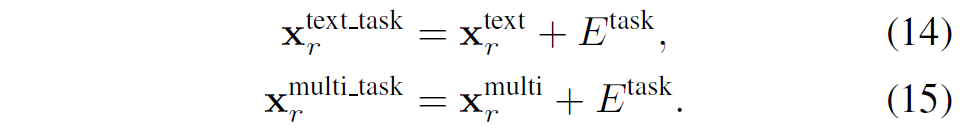
Comparison on MoE Routing
여기서는 저자들이 Expert selection에 대한 다양한 실험을 진행한 것에 대한 결과들을 분석한 내용들입니다.
우선 실험 세팅으로는 R2R과 REVERIE에 대해서는 Matterport3D 렌더링 이미지가 사용되며, 각 MoE 레이어에 대해 8명의 expert를 채택하고 top-2 experts를 선택합니다. MoE expert는 visual queries에 배치된다고 하며, 저자들은 5개 체크포인트에 대한 정량적 결과의 평균을 아래 표에서 리포팅하였다고 합니다.
그리고 저자들은 ScaleVLN으로 모델을 초기화하였으며, ScaleVLN의 경우 합성 데이터를 생성해 VLN 데이터를 14K에서 4.9M으로 확장하여 사전 학습을 수행한 모델이라고 합니다.
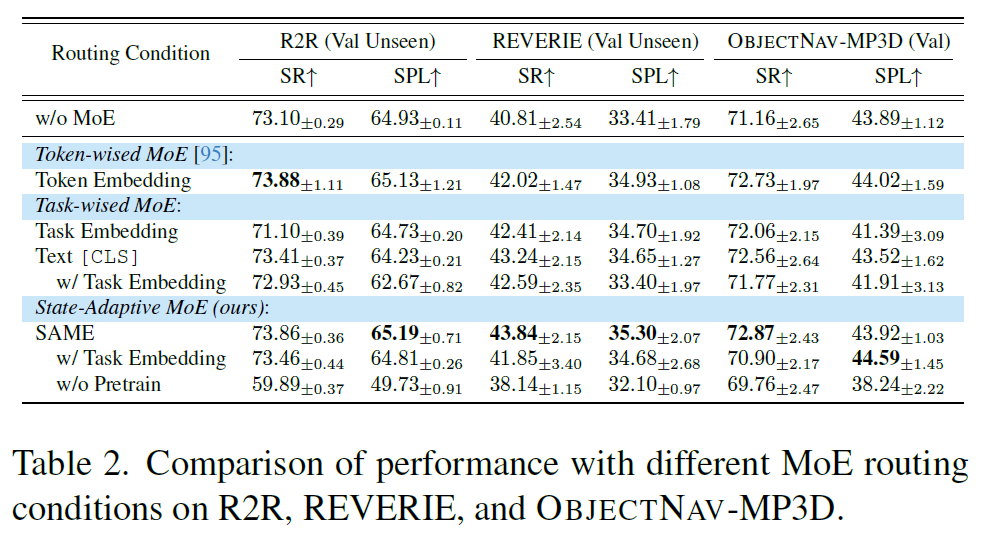
결과를 살펴보면 우선 일반적인 비전-언어 사전 학습 모델인 LXMERT로 초기화하여 SAME에 멀티태스크 튜닝을 수행한 경우(w/o Pretrain)와 비교했을 때, ScaleVLN 사전 학습 가중치로 초기화하면 모든 태스크에서 상당한 성능 향상이 있습니다. 특히 R2R에서 약 14%의 성공률(SR) 향상을 보이고 있네요.
그리고 맨 위의 첫번째 열에 결과인 멀티태스크 튜닝된 DUET(w/o MoE)과 비교했을 때, 모든 MoE 방법들은 다른 태스크에서의 뚜렷한 성능 저하 없이 REVERIE 태스크에서 2-3%(SR) 의 성능 향상을 보여줍니다. 이는 MoE를 쓰지 않은 베이스라인 모델의 coarse-grained instruction 기반 VLN 성능이 다른 수준의 instruction 유형과 함께 학습될 때 부정적인 영향을 받는다는 점을 시사합니다.
그리고 다양한 MoE 라우팅 유형을 비교해 보면, SAME 라우팅이 REVERIE에서 약 2% SR 및 약 1% SPL의 향상을 가져옴을 강조할 수 있습니다. 저자들은 이러한 향상이 Coarse-grained VLN의 특성 때문이라고 가정합니다.
해당 태스크에서 에이전트는 text instruction의 guide가 부족한 경우에 수행하는 탐험(exploration)과, 목표를 정밀하게 위치시켜야 할 때 text instruction을 밀접하게 따르는 행위 사이를 번갈아 수행해야 합니다. 이때, SAME 라우팅은 현재의 관측과 언어 입력에 기초하여 이러한 서로 다른 네비게이션 행동을 관리할 전문가를 유연하게 선택할 수 있다고 하며, 이를 통해 에이전트가 태스크 전반에 걸쳐 전이 가능한 지식을 학습할 수 있도록 합니다. 이러한 유연성 덕분에 SAME 에이전트는 모든 태스크에 걸쳐 가장 높은 평균 SPL 48.13%를 달성했습니다.
그리고 마지막으로 태스크 임베딩을 통해 직접 라우팅함으로써 특정 전문가를 서로 다른 태스크에 전담시키는 hard assignments에 대한 결과를 살펴보면, 해당 방식은 모든 태스크에서 성능 저하를 초래한다고 하네요(w/ Task embedding에 해당하는 행 참고).
또한, 태스크 임베딩을 x_{r}^{text}와 x_{r}^{multi}에 통합하는 것 역시 성능을 감소시킵니다. 즉, 태스크 임베딩을 기반으로 수행한 hard assignment의 경우 라우터가 instruction이나 observation에 기초하여 어떤 전문가를 선택해야 할지 효과적으로 학습하는 것을 방해하고, 태스크 간의 공유된 지식 개발을 저해하는 것 같다고 저자들은 주장합니다.
Which Part of the Navigation Policy Learns Different Navigation Behaviour?
MoE는 주로 트랜스포머 모델 내의 Feed-Forward Network, FFN 모듈을 강화하는 역할을 해왔습니다. 동시에, 일부 연구들은 계산 비용을 관리하면서 성능을 더욱 높이기 위해 멀티 헤드 어텐션 레이어에 MoE를 통합하기도 했습니다.
저자들은 트랜스포머 모델의 서로 다른 구성 요소, 구체적으로 FFN, visual queries W_{q}, textual key W_{k}, 그리고 value W_{v}에 SAME을 적용했을 때의 영향을 표2와 동일한 실험 설정 하에서 분석합니다.
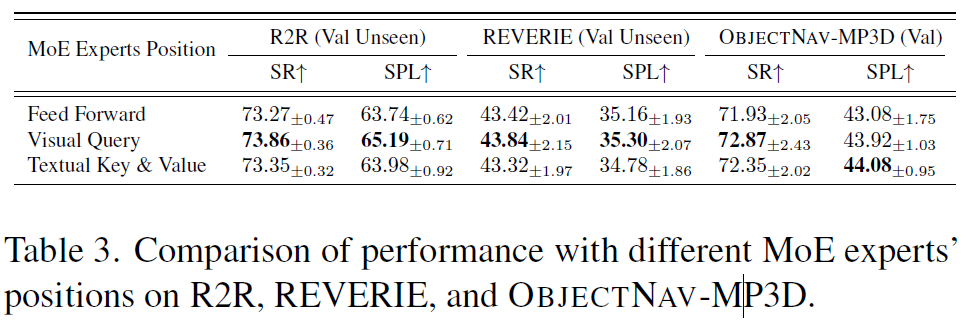
결과를 살펴보면, 시각적 쿼리(visual query)에 MoE를 적용했을 때 전반적으로 가장 우수한 성능이 관찰되었습니다. 이러한 결과는 크로스 어텐션 레이어 내에서 시각적 쿼리 수준에 MoE를 활용하는 것이 특히 효과적임을 시사합니다. 다시 말하면, 멀티모달 정책이 크로스 어텐션 레이어 내에서 다양한 네비게이션 행동을 제어하는 데서 비롯될 가능성이 높다는 것이죠.
Cross-attention에서 전문화된 시각적 쿼리 전문가들은 여러 뷰포인트(viewpoints)로부터 얻은 시각적 임베딩에 대한 어텐션 점수를 조정함으로써 에이전트가 다음 행동을 더 정확하게 결정할 수 있게 합니다 . 반면 FFN 기반의 MoE도 MoE가 없는 모델에 비해 성능을 향상시키지만, 어텐션 레이어와 통합된 MoE 구성에 비해 성능이 떨어집니다. 이는 성공적인 행동 선택에 있어 Cross-modal attention이 조금 더 결정적인 역할을 함을 암시합니다.
정리해보면, 표3의 실험 결과는 visual query experts와 멀티모달 특징(시각적 관측 및 언어 지시어)에 기반한 라우팅(SAME)을 함께 고용하는 것이 에이전트로 하여금 언어 안내와 정렬을 유지하면서도 환경의 시각적 변화에 동적으로 적응할 수 있게 함을 나타낸다고 볼 수 있습니다. 그리고 이는 서로 다른 언어 유도 네비게이션 태스크 전반에 걸쳐 견고한(robust) 성능 향상을 이끌어낸다고 하네요.
Experiments
실험섹션 소개하고 리뷰 마치도록 하겠습니다.
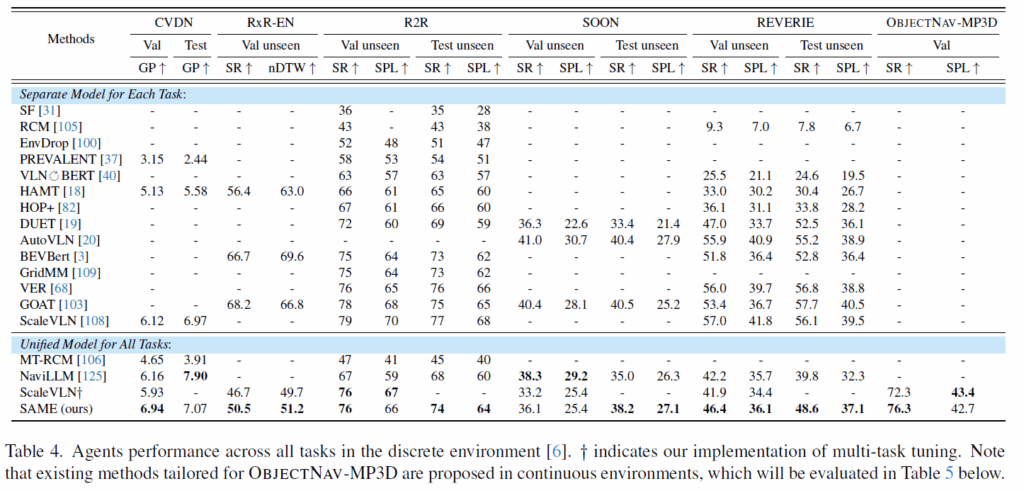
우선 표4는 CVDN부터 ObjectNav 데이터셋까지 총 6개의 데이터셋에서의 평과 결과를 의미합니다. 여기서 좌측에 있는 데이터셋부터 우측에 있는 데이터셋 순으로 지시어의 세밀함이 점점 떨어진다고 보시면 됩니다. Separate Model은 각각의 데이터셋에 대해서 학습 및 평가를 수행하는 모델을 의미하고 unifed Model은 모든 데이터셋을 다 합쳐서 학습 후 평가한 것으로 저자들의 방법론은 unifed model쪽에 속합니다.
결론부터 말씀드리면 SAME 방법론은 각 태스크에 맞춰 따로 튜닝된 모델들과 비교했을 때도 성능이 밀리지 않았습니다. 특히 CVDN 데이터셋에서는 테스트셋 GP(Goal Process) 점수 7.07을 기록하며 기존 SOTA를 경신해주는 모습이고 R2R과 REVERIE에서도 VER이나 GOAT 같은 specific 모델들과 대등한 성능(SPL 기준)을 보여주었습니다.
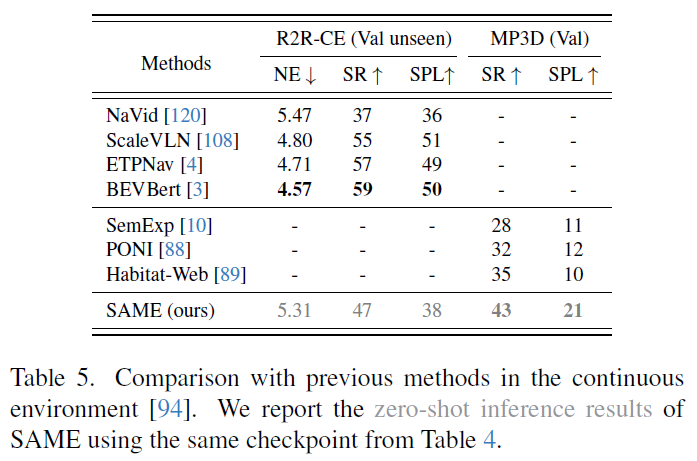
다음 실험은 모델이 학습하지 않은 환경인 Habitat(연속 공간)으로 넘어갔을 때의 제로샷(Zero-shot) 성능을 평가한 것입니다. 참고로 표4는 이산환경에서의 평가 방식으로 미리 정의된 노드와 엣지로 구성된 그래프 상에서 에이전트가 움직인다는 설정이라면, 표5의 경우에는 실제로봇이 움직이는 환경처럼 agent가 연속되어 움직이는 상황을 의미합니다. 정리하면 표4보다 더 사실적이면서 어려운 환경에서의 평가라고 생각하시면 되겠습니다.
아무튼 연속된 환경에서의 네비게이션이기 때문에 이산 환경에서 학습된 모델에 웨이포인트 예측기(waypoint predictor)를 달아서 연속 환경을 테스트했다고 하며, 결과적으로 SAME은 ObjectNav 인간 시연 데이터로 모방 학습을 수행한 Habitat-Web 모델보다 더 뛰어난 제로샷 성능을 보여주었습니다. 이러한 결과를 토대로 저자들은 자신들이 주장했던 “세밀한 언어 이해(Fine-grained understanding) 학습이 목표 지향적 네비게이션(Target-oriented navigation) 실력도 향상시킨다”는 가설을 입증하였다고 이야기합니다.
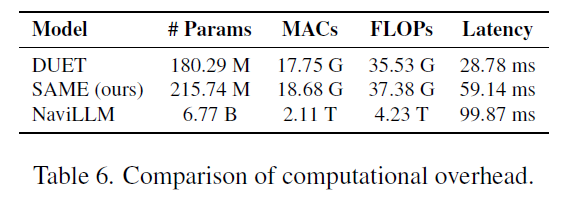
위의 표는 저자들의 방법론의 추론 시 요구되는 파라미터 수나 연산 속도 등을 보여주고 있습니다. DUET이랑 모델의 구조가 비슷?해서 인지 FLOPs가 별 차이가 나지 않는 것을 확인할 수는 있으나 latency는 2배이상 차이가 나는 모습입니다. 저자들도 그것을 의식했는지 상당히 무거운 모델인 NaviLLM과 비교하였을 때 자신들의 모델이 표4에서 대다수의 task/dataset에서 NaviLLM보다 좋은 성능을 보여주지 않았느냐는 식으로 어필을 하는 모습입니다.
결론
이전 VLN 논문들이 R2R 데이터셋을 많이들 가져와 벤치마크로 사용하였었는데 해당 데이터셋이 다른 데이터셋과 비교해서 어떠한 차별점이 있었는지를 이번 기회에 좀 알게 된 것 같습니다. VLN에서 각 데이터셋들 별로 Instruction의 깊이가 다 다름을 이해하고, 이들이 네비게이션 모델에 어떠한 영향을 주는지를 잘 볼 수 있어서 좋았네요.