안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 CVPR 2025에서 Oral presentation으로 선정됐던 논문으로, video data를 활용한 self-supervised object centric learning 기법을 다룹니다. 제 개인 연구에서 어떻게 하면 object query들이 temporal consistency를 갖게 할 수 있을까 고민하면서 읽어보았습니다. 그럼 바로 리뷰 시작하겠습니다.

기존의 딥러닝(CNN/Transformer) 기반 컴퓨터비전 방법론들의 feature에는 다양한 정보들이 얽혀있어(entangled) 특정한 물체의 특징만을 독립적으로 다루기 어려웠습니다. 예를 들어 feature map에서 object 1의 정보를 제외하고 object 2의 정보는 다른 영역에 재배치하고 싶어도, 이들의 정보가 feature map 안에서 다른 object / context 정보들과 복잡하게 얽혀있어 특정 물체만의 정보만을 편집하는 것이 쉽지 않았죠. 이렇게 특정 object나 entity의 정보를 module처럼 표현하고 image나 scene 정보를 이러한 entity/module 정보의 조합으로 다루고자 하는 시도들이 있어왔습니다. object-centric learning도 관련 연구 흐름 중 하나였고, computer vision 분야에서는 최근에 slot attention을 활용한 unsupervised object-centric learning 연구가 많이 진행되었습니다.
Slot Attention은 연산 과정에서 feature map의 특정 영역(pixel / segment)을 어떤 slot이 담당할지 slot 간 경쟁하는 효과가 있습니다. 이 덕분에 적절한 개수의 slot으로 올바르게 학습한다면 별도의 label 없이도 object-centric representation을 학습할 수 있었습니다.
한편, video 분야에서도 unsupervised object-centric learning이 활발하게 연구되었는데, image에서 video로 데이터를 확장하면 temporal 축을 따라 일관된 object-centric representation이 잘 유지되지 않는 문제가 생겼습니다. multiple object tracking이나 dynamic scene modeling에서는 비디오의 frame이 진행될 때 각 object를 일관되게 표현할 수 있어야 하는데 이게 쉽지 않았죠. slot attention 기반 방법론들에서도 t 축에 따라 동일 물체에 동일한 slot들이 일관되게 할당되지 않는 문제가 있었습니다. video sequence에서는 특히 물체가 가려지거나, 재등장하거나, 모션 블러가 생기거나, 여러 물체가 상호작용하는 등 복잡한 시나리오가 포함되어 더욱 쉽지 않았습니다.
이러한 문제 때문에, slot attention 기반 object centric learning에서는 temporal 축에 따라 동일한 object에 동일한 slot이 할당되도록 학습을 유도하여 temporal consistency를 보장하고자 하였습니다. 오늘 리뷰하는 SlotContrast 방법론도 video 데이터의 self-supervised object-centric learning에서 temporal consistency를 보장하기 위한 방법입니다.
본 논문의 큰 그림은 간단합니다. frame 간 slot에 contrastive learning을 도입해서 동일한 object에 대한 slot 할당의 temporal consistency를 개선시키겠다는 컨셉입니다. 학습 과정은 라벨값 없이 Self-Supervised Learning(SSL) 이루어집니다. 기본적인 self-supervised contrastive learning처럼 배치 전체에서 slot representation 간 비교를 통해 임베딩 공간에서 동일 slot은 가깝게, 다른 slot은 멀게 학습시켜서 slot 간 일관성과 구별력을 주게 됩니다. pair를 구성할때는 여러 frame을 한번에 고려하느게 아니라 바로 이전 frame의 slot들을 활용합니다. 이 법을 통해 temporal consistency 개선에 성공했고, unsupervised object tracking이나 latent object dynamics learning과 같은 어려운 downstream task에서 효과적임을 보였습니다.
저자들이 주장하는 contribution을 정리하면 다음과 같습니다 :
- 우리는 새로운 slot-slot contrastive loss를 제안하여 slot기반 비디오 처리 방법론과 통합했을 때 temporal consistency 부문에서 SOTA를 달성했다.
- 우리는 slot-slot contrastive loss와 slot 초기화에 학습을 도입하여(원래 slot attention 제안 당시 slot은 랜덤 초기화 되었었습니다) YouTube 비디오와 같은 실제 데이터로 확장 가능한, 단순하면서도 효과적인 OCL 구조인 SLOT CONTRAST를 개발하였다.
- 우리는 unsupervised online tracking이나 latent object dynamics modeling과 같은 복잡한 다운스트림 태스크에서, 제안하는 learned object-centric learning 기법에 대한 광범위한 연구를 수행하였다.
- 우리는 SlotContrast가 representation의 시간적 일관성을 향상시키는 동시에, object discovery task에서도 SOTA를 달성하여 motion cue를 사용하는 weakly supervised learning 모델들보다 뛰어난 성능을 보임을 입증하였다.
이제 이어서 방법론을 살펴보겠습니다.
Method
기본적으로 제안 방법론은 기존의 reconstruction 기반 object-centric framework(SAVi, VideoSAUR)를 확장해 학습 과정에서 contrastive loss를 추가한 것이라고 합니다. 이쪽에 집중하여 살펴보겠습니다. 전반적인 프레임워크 개요는 아래 그림 2와 같습니다.
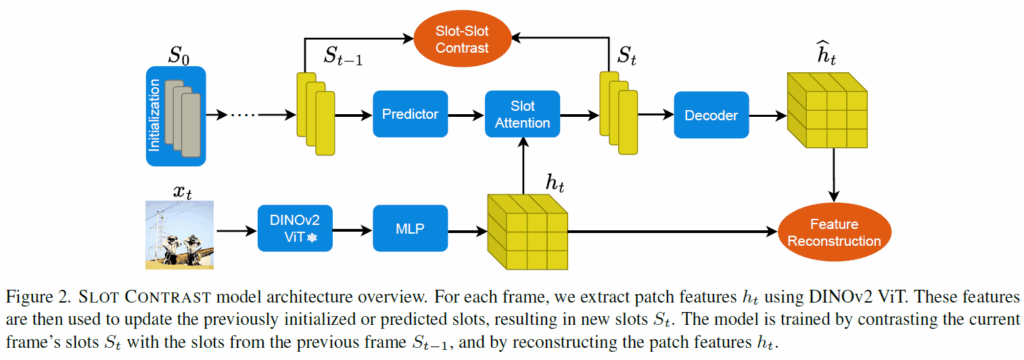
Semantic Recurrent Slot Attention Module
모델은 기본적으로 Slot Attention module을 활용한 인코더-디코더 형태의 object-centric 구조를 가집니다. 크게 3가지 요소로 구성됩니다. 각각 1. feature를 추출하는 백본(DINOv2사용), 2.인코더 피쳐들을 slot으로 grouping하고 temporal slot 업데이트를 모델링하는 Recurrent Slot Attention Module, 3. 각 프레임의 슬롯을 입력값 피쳐(dense SSL feature)으로 reconstruction하는 디코더입니다.
일단, video frames {x}_{t}를 freeze한 백본(DINO) {f}에 통과시켜 N개의 patch feature {g}_{t}를 추출합니다.
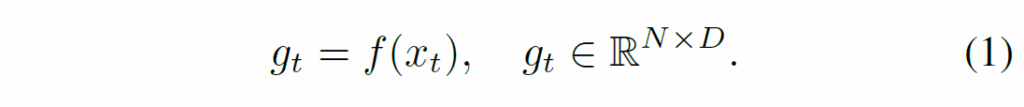
이 때 백본이 학습되지 않고 고정되기에 temporal consistent object discovery task에 알맞게 변환시키기 위해 다음과 같이 한번 MLP({g}_{ψ})를 태워 encoder feature {t}_{t}를 만듭니다.
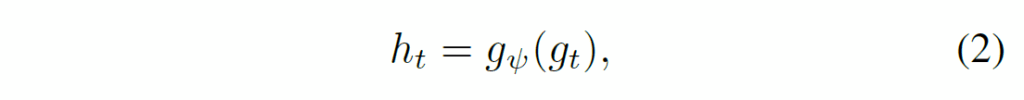
이제 t frame의 slot 집합인 {S}_{t}를 만드는데, 이때 Figure 2와 같이 이전 step의 slot집합인 {S-1}_{t}을 사용합니다. {S}_{t-1}를 predictor에 통과시킨 후, visual feature {h}_{t}와 Slot Attention을 수행하죠. 아래 수식 (3)에서 {P}_{ω}는 predictor module, {C}_{θ}는 grouping module(Slot Attention 수행부)입니다. 논문에서는 이들을 합쳐서 Recurrent Slot Attention Module이라 합니다.
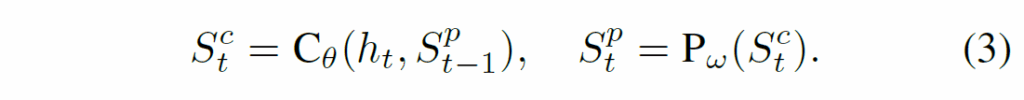
이렇게 생성된 slot representation {S}_{t}^{c}나 {S}_{t}^{p}는 모두 이후 디코딩이나 downstream task에 사용될 수 있습니다. 비유하자면 DETR decoder를 거친 object query와 같은 느낌으로 생각하시면 됩니다. 논문에서는 여기서부터 편의를 위해 {S}_{t}^{c}를 {S}_{t}로 표기합니다. 이후에는 slot이 decoder를 거쳐 reconstruction loss로 넘어갑니다.
보통 본래의 Slot은 가우시안 랜덤 샘플링으로 초기화됩니다. 저자들은 랜덤 초기화 말고, slot을 학습하여 초기화해서 사용했습니다(랜덤 초기화와 비교해 상당한 성능 이점을 보였다고 합니다). 사실 어찌보면 당연한게, 랜덤 샘플링하면 temporal축에 따라 등일 slot이 일관되게 할당되기 어려울 수 있겠죠. 학습을 통해 이런 부분을 완화하였습니다.
Temporal Consistency through Slot Contrast
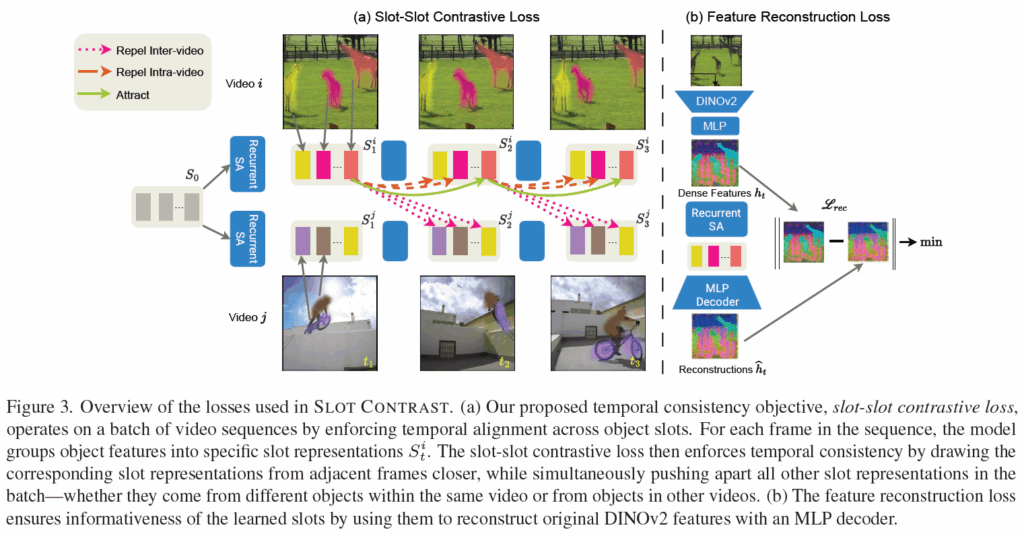
contrastive learning은 워낙 자주 나오는 내용이니 자세한 내용을 여기서 다루지 않겠습니다. 결국 핵심은 positive pair를 잘 구성하고 negative pair를 잘 구성하여 원하는 학습 효과를 강제하는 것입니다. 본 논문에서의 목적인 slot attention의 temporal consistency이니, 프레임 간 동일 slot끼리 contrastive learning을 추가 도입해 동일한 slot간 일관성을 가지고 다른 slot 간 분별력을 가지도록 설계됩니다.
구체적으로는, 한 비디오 내의 두 연속 timestep에서 동일한 slot representation을 positive sample로 정의하고, 해당 timestep들 사이 batch 내 다른 모든 slot들을 negative sample로 정의합니다. 이는 아래 Figure 3에 나타나 있습니다.
Intra-Video Slot-Slot Contrastive Loss
기본적으로 InfoNCE loss를 사용하고, (t-1, t) timestep의 동일 슬롯을 positive로, 나머지는 negative pairs로 사용합니다. 인접 프레임에서 동일한 slot이 동일한 object에 잘 할당되기를 기대하고, negative pair끼리는 멀어지도록 유도하여 분별력을 가지게 하였습니다. 유사도(sim)은 항상 사용되는 cos 유사도입니다. 타우는 temperature parameter입니다.
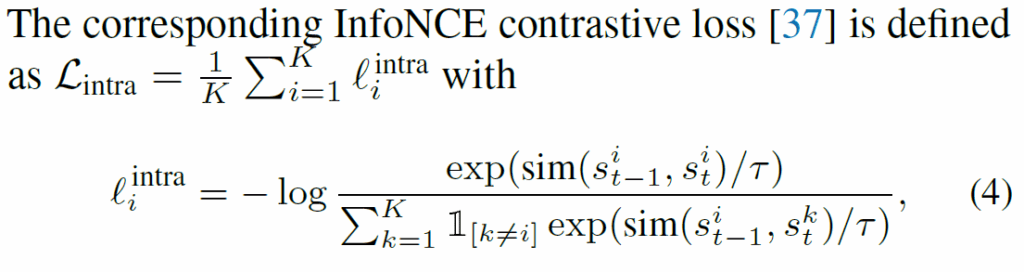
Batch Video Slot-Slot Contrastive Loss
contrastive learning은 비교할 샘플 수가 많으면 많을수록 좋습니다. 당연히 비디오 내 프레임 뿐만 아니라 배치 내 다른 비디오 프레임들을 활용하는게 좋습니다. 다른 video간 slot은 모두 negative로 간주하고 contrastive learning을 확장하면 유의미한 성능 개선이 일어난다고 합니다.
최종적으로는 다음과 같은 slot-slot contrastive loss인 {L}_{scc}를 추가적으로 사용합니다.
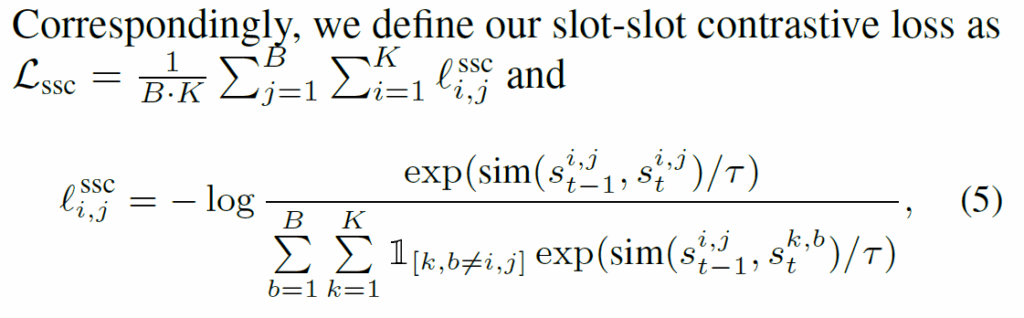
B는 배치 내부 비디오 수이고, {s}^{i,j}_{t}는 t time에서 j번째 비디오의 i번째 슬롯을 의미합니다.
Final Loss
기본적으로 scene decomposition을 위해서 기존 방법론인 DINOSAUR, VideoSAUR와 같이 feature reconstruction loss를 사용합니다. 저자가 제안하는 slot-slot contrastive loss는 reconstruction loss에 추가적으로 적용하여 학습에 활용하는 구조입니다. 최종 loss는 다음과 같습니다.
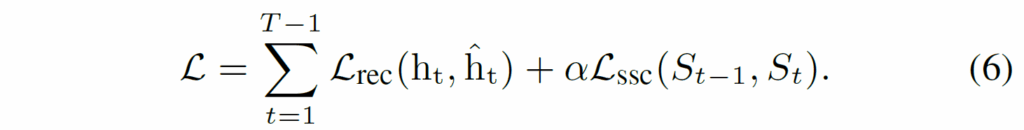
Experiment
실험 데이터셋에는 MOVi-C와 MOVi-E라는 합성 데이터셋을 사용했다고 합니다. MOVi-C는 풍부한 텍스처를 가진 일상 객체들을 포함하고 각 scene 당 최대 11개의 객체가 등장하고, MOVi-E는 이를 23개의 객체로 확장하고 기본적인 linear camera motion을 도입한 데이터라고 합니다. 실제 데이터에 대한 검증을 위해 YouTube-VIS 2021 (YTVIS21) 비디오 데이터셋도 활용했다고 합니다. 처음 보는 task라고 지표도 처음 보는 지표인데, 일관된 object discovery를 평가하기 위해 물체가 얼마나 잘 분리되었는지를 측정하는 (video foreground adjusted rand index(FG-ARI)를 사용했다고 합니다. 보조적으로는 마스크 선명도(sharpness)를 평가하기 위해 mean best overlap, mBO 매칭과 같은 video IoU 지표를 사용했다고 합니다.
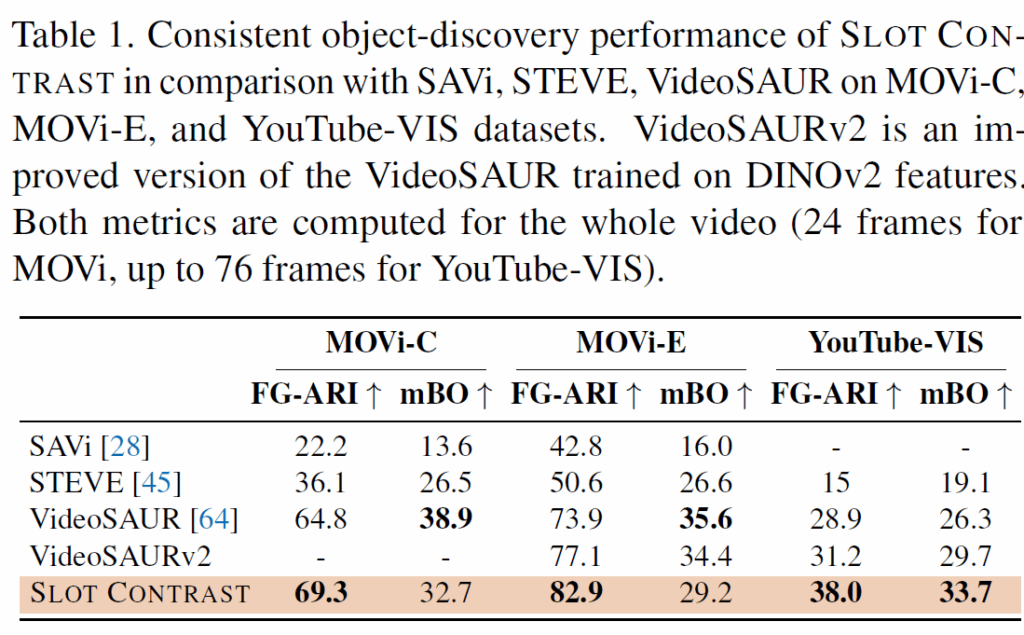
결과적으로, Slot Attention의 consistency object-discovery 성능에서 Slot Contrast가 매우 우수한 성능을 보였습니다.
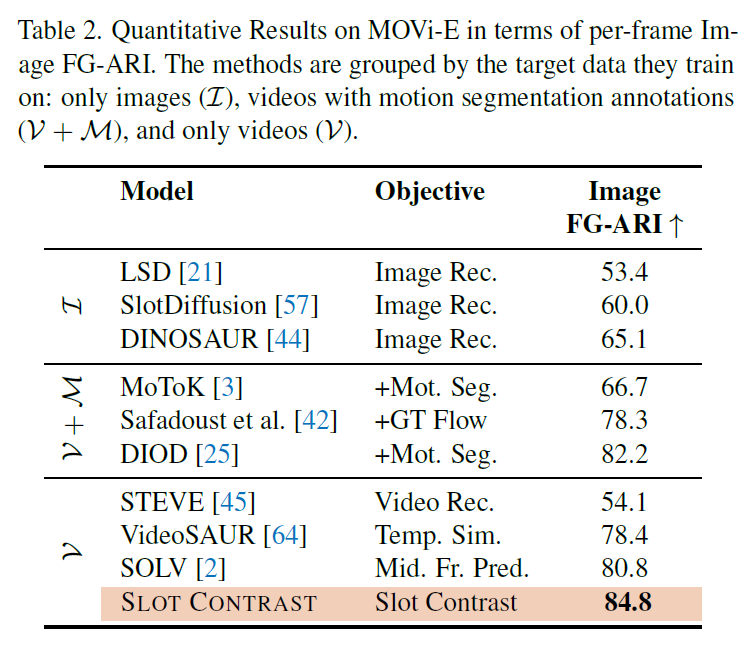
이어서 Table2에는 프레임별 장면 분해를 측정하였습니다. 저자들은 temporal consistency loss에 contrastive learning을 도입이 장면 분해에 도움이 되는 것을 확인하였습니다. 해당 loss가 프레임 전반에 걸쳐 물체에 대해 일관된 feature representation을 학습할 수 있도록 유도하여 개별 frame에서의 object discovery에 큰 도움이 되었다고 합니다.
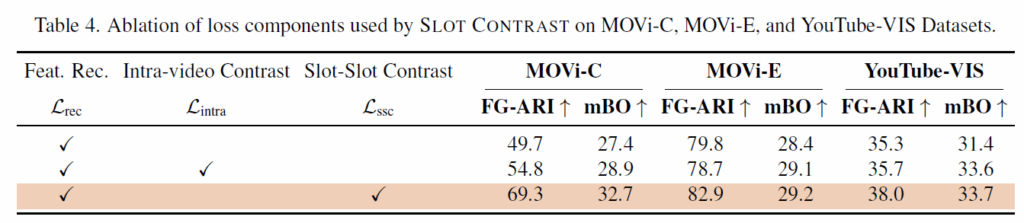
Table 4에서는 loss 구성에 대한 Ablation을 나타내었습니다. 베이스라인 프레임워크인 reconstruction loss에 intra-video contrast, ssc loss로 발전할수록 크게 성능이 개선되는 것을 확인할 수 있습니다.
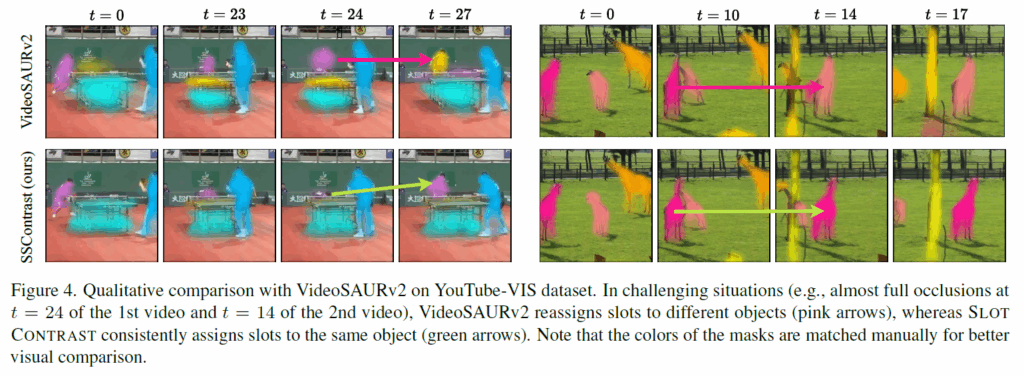
정성적 시각화 결과 하나 보고 리뷰 마무리하도록 하겠습니다. YouTube-VIS dataset에서 제안하는 방법론과 VideoSAURv2를 비교하였습니다. 완전한 occlusion이 발생하는 어려운 상황에서 VideoSAURv2는 다른 물체에 slot을 재할당 하는데(분홍 화살표), SlotContrast는 동일한 물체에 일관적으로 slot을 할당하는 것을 확인할 수 있습니다(초록 화살표).
video task에서 query나 slot의 할당 안정성, 시간적 일관성을 위해 contrastive loss를 도입한 방법론이었습니다. 방법론이 간단한데 강력합니다. 한번 지금 수행 중인 실험에 적용해보고 경향성을 확인해보고자 합니다.
이만, 리뷰 마무리하도록 하겠습니다.
감사합니다.
리뷰 잘 읽었습니다
영상에서 객체가 사라졌다가 다시 등장하거나 (occlusion → reappearance), 두 객체가 붙었다가 다시 분리되는 경우는 object-centric 학습에서 매우 어려울 것 같은데요.
SlotContrast는 객체가 사라졌다가 등장하는 경우에도 동일 slot을 유지할 수 있나요? 아니면 contrastive learning이 가능한 시간적 범위가 사실상 짧은 구간으로 제한되나요?
댓글 감사합니다. 답변 드리도록 하겠습니다.
말씀해주신것처럼 이쪽 task가 unsupervised learning으로 수행되다 보니 물체의 재등장이나 믈체의 분기와 같은 상황을 다루기가 쉽지 않다고 합니다.
학습 시 contrastive loss의 구현 상으로는 인접한 두 프레임 간(t-1, t)에서만 positive pair가 구성되기에, 명시적으로 video sequence 내 temporal 축으로의 long-range object에 대해서 직접적인 supervision이 가해지지는 않습니다. 따라서 모든 challenging한 상황에 강건하게 동작하는 능력이 갑자기 생기지는 않습니다. 하지만, 기존 방법론들과의 비교에서는 유의미하게 개선된 결과를 보인다고 주장합니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
slot attention이 초기에는 랜덤 초기화로 시작했으나, 논문의 contribution에선 이를 learnable vector로 두고 학습했다고 하였습니다. 비디오에서 slot을 learnable vector로 두고 t-1 시점의 slot을 가져오는 것은 굉장히 자연스러워보이는데, 이 방식 자체를 본 논문에서 처음으로 도입한 것인지 궁금합니다.
댓글 감사합니다. 답변 드리도록 하겠습니다.
video 데이터의 object-centric learning에서 slot 초기화를 learnable하게 변경하는 것과 이전 frame을 활용하는 개념 모두 이 논문 이전에도 종종 사용되는 기법이라고 합니다. 대표적으로 2022 ICLR에 제안된 SAVi라는 방법론이 있다고 하네요.
감사합니다.