짧은 논문 소개
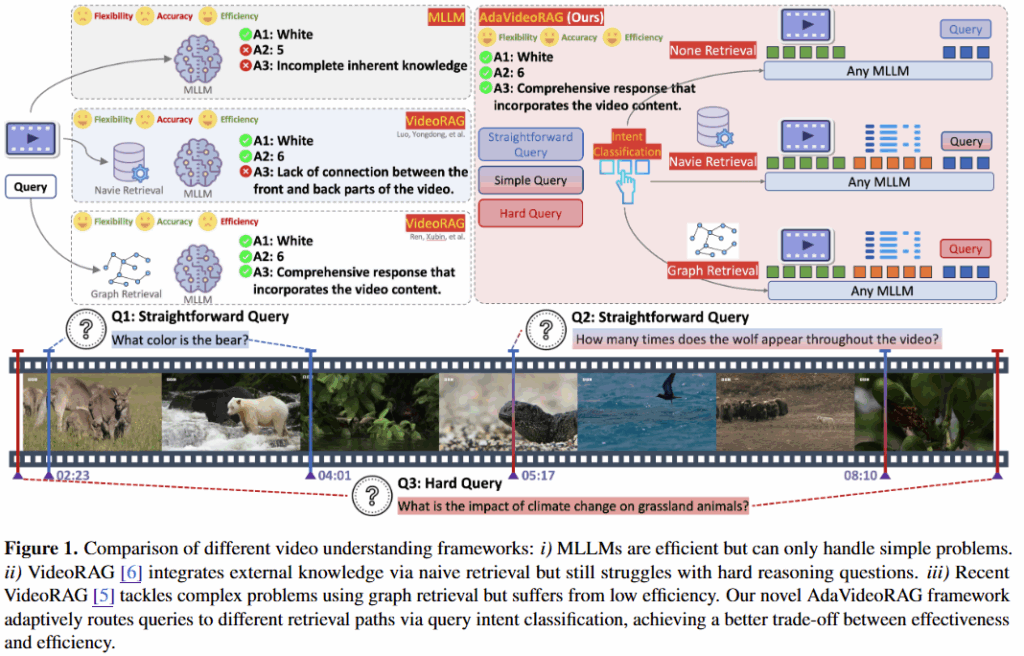
본 연구는 MLLM(Multimodal Large Language Model)을 활용하여 긴 영상에 대한 질의응답 테스크 정확도를 개선하는 RAG 프레임워크를 제시한 것입니다. 연구에서는 기존 RAG 연구가 다양한 모달리티를 적절히 활용하는것이 아닌 텍스트 모달리티를 위주로 설계되었다는 점과, 질의 수준의 다양성을 고려하지 못했다는 한계를 발견하고 이를 개선하는 방법을 제시하였다. 또한 다양한 질문 수준에 대해 동작을 평가할 수 있는 벤치마크 HiVU(Hierarcxhical video understanding)를 공개하여 VideoRAG 분야에 기여한 성과를 내었다.
기존 RAG 연구 현황
RAG란 생성모델의 정확도를 개선하기 위해, 생성에 활용할 적절한 데이터를 이용가능한 외부지식 데이터에서 검색하여 보조적으로 생성모델에 제공하는 기술이다. 해당 기술을 통해 생성모델은 학습하지 않은 데이터에 대해 보조 정보를 통해 비교적 정확하게 동작할 수 있으며, 지식이 부족으로 발생하는 할루시네이션 현상을 완화할 수 있다.
한편, 최근의 RAG 기술은 텍스트 모달리티 기반으로 설계되었는데, 검색을 통해 선별한 외부 데이터를 OCR혹은 GPT와 같은 외부 API를 활용해 텍스트 모달리티로 변환한 후, 이를 생성모델의 보조 입력으로 활용하는 것이다. 그러나 데이터를 텍스트로 변환하는 과정에서 데이터의 손실은 불가피하다. 특히 영상의 경우 이러한 정보 손실이 자주 발생할 수 있다. 예를 들어 붉은 옷을 입은 소녀가 뱀을 안고있는 사진에 대해, 캡셔닝 모델을 통해 “뱀을 안고있는 소녀”로 변환될 수 있다. 이 과정에서 소녀의 옷의 색이나 뱀의 무늬같은 세부정보의 손실이 있다. 이러한 기존 RAG의 한계를 개선하기 위해 최근 VideoRAG[ref]와 같은 연구에서는 영상에서 다양한 메타데이터를 추출하여 활용하였지만, 메타데이터 추출 과정에서 연산량이 크게 증가한다는 한계가 있었다.
본 연구는 영상 데이터에 최적화된 RAG 기술을 개발하고자 하는 기존 연구의 문제점을 계승하나, Long video와 복잡한 질의에도 정확도 높게 동작하는 기술을 위해 비디오의 길이와 질문에 난의도에 맞도록 동작하는 적응적 RAG 기술을 제안한다.
제안 방법론
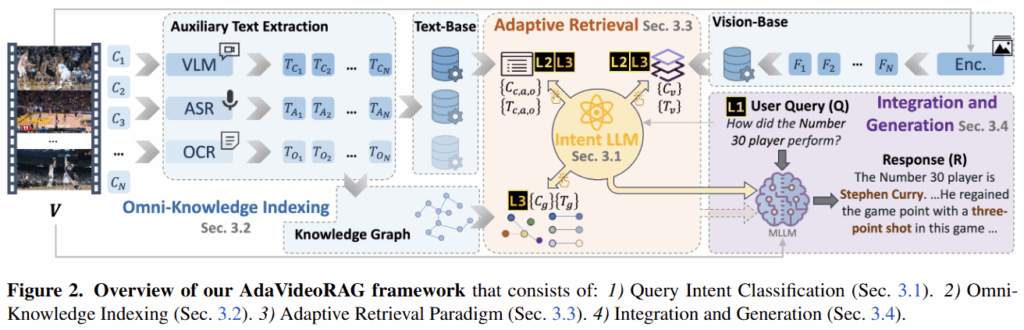
논문에서 제안하는 적응적 RAG 기술은 다음의 4단계를 포함한다.
- 질의 의도 분류, Query Intent Classification
Video RAG에서 영상 데이터에서 생성모델에 입력할 정보를 추출하는데 있어 가장 변수가 되는 요인은 질의의 수준이다. 예를 들어, “5초에 나오는 공의 색깔은 무엇입니까?“와 같은 질의는 영상에 대한 맥락적 이해를 요구하지 않으나, “영상에서 소녀는 왜 공을 던지고자 했습니까?“와 같은 질의는 영상에 등장인물의 행위 의도를 파악해야하는 등 더욱 깊은 수준의 이해를 요구한다. 이처럼, 질의에 대해 올바르게 답변을 생성하기 위하여 질의 의도 분류는 필수적이다. 논문에서는 질의의 수준을 3단계로 나누는데, Level1은 직관적 질의로 video안의 특정 지식에 대한 것이다. Level2는 쉬운 질의로 한단계의 공간/시간적 추론이 필요한 것인데, 예를 들어 “여자가 비오는 시점에 울었나요?”와 같은 질문은 단순히 “여자가 울었다”는 사실이 아닌 “비 온 시점”에 “여자가 울었다”를 확인하기 때문에 시간적 추론이 필요한 질문이다. 마지막으로 Level3는 어려운 질의로 전체 혹은 긴 맥락 파악이 필요한 질문이다. 예를 들어 “영화가 전하는 교훈은 무엇인가요?”와 같은 질문이 이에 속하며, 영화의 내용 전체를 이해해야 답변할 수 있다. - 비디오 지식 인덱싱, Omni-Knowledge Indexing
Video를 통해 생성모델의 입력 프롬프트를 구성하느데 있어 고려해야할 점은, MLLM 모델의 window size 이다. 비디오의 경우 일반적으로 다양하고 많은 정보를 포함하기 때문에 한정된 입력 사이즈를 갖는 생성모델의 입력으로 하기 부적합하다. 효과적인 입력을 구성하기 위해 논문이 제시하는 video 내용을 통한 DB 구축 방법이 Omni-knowledge indexing에 해당한다. 먼저 Text 기반의 DB를 구축하는 방식은 다음과 같다. 비디오 V를 30초 단위의 clip N개로 나누고, clip마다 keyframe을 선별한다. keyframe은 uniform selection 방식으로 5개의 프레임을 선택한다. 이때 frame을 이용해 MiniCPM-V라는 VLM 모델로 캡션을 생성하는 text description DB(Dc), FastWhisper로 추출한 오디오를 텍스트로 변환한 ASR DB(Da), EASYOCR 모델로 추출한 OCR DB(Do)를 구축할 수 있다. 다음으로 어려운 질문(Level3)에 대응하기 위해서는 비디오 전체를 파악할 수 있어야 하는데, 이를 위해 위의 텍스트 기반 데이터를 통해 그래프를 구축한다. 이때 BGE-M3라는 텍스트 임베딩 모델로, 각 OCR, ASR, Captions 데이터간의 관계를 추출하고, 이를 통해 entity간의 연관성을 구조화한 그래프를 생성한다. 예를 들어 entity (철수, 5s-10s, 주방), entiy(철수, 주방)간의 관계( 철수, 잡다, 후라이펜) 다음으로 시각정보를 통한 DB(Vision based DB)는 단순하게 ImageBind라는 이미지 인코더를 통해 추출한 keyframe의 feature합으로 구축한다. - Adaptive Retrieval Paradigm & Integration and Generation
위처럼 질의를 통해 난이도를 나누고,영상을 활용해 DB를 구축했다면, 실질적으로 질문에 대한 답변을 생성해야한다. 논문은 난이도를 기반으로 답변 생성 방법을 달리한다. 먼저 Level 1의 시나리오에서는 DB의 활용 없이 video의 keyframe(Vision based DB)과 질의를 MLLM에 직접 입력하여 답변을 생성한다. 다음으로 Level 2의 질문에 대해서는 구축한 caption, ASR, OCR DB에서 질의와 유사도 검색을 수행한 후 이를 같이 LLM에 입력한다. 이때 적절한 검색을 위해 DB의 특성에 맞게 질의를 재작성한다. 예를 들어 Dc에 대해서는 서술적 질의로, Da는 구어체, Do는 특정한 엔티티로 재구성한다. 구체적 변환 예시로는 “How did the Number 30 player perform?”에 대하여 Caption DB에는 “Performance of number 30 player.” ASR DB에는 “How’s number 30 player doing.” OCR DB에는 “Number 30 player”를 검색 텍스트로 활용한다. 또한 Level2에 대해서는 Vision based DB에 대해서도 검색을 수행하여 frame을 선별하는데, clip caption용의 서술적 질의(Performance of number 30 player)와 코사인 유사도를 통해 일정 역치를 넘는 프레임만을 입력으로 사용한다. 마지막으로 Level 3은 단일 사건(entity)이 아닌 multi-hop reasoning이 필요하기 때문에 graph 정보를 추가로 입력한다. 텍스트 기반 entity-relationship graph에서 검색된 entity와 관련된 정보를 모두 수집해 입력하는 것이다 Level3에서는 이렇게 검색된 그래프 결과와 Level2에서 활용한 결과를 함께 입력하여 답변을 생성한다.
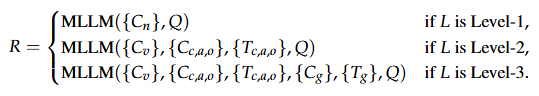
HiVU 벤치마크 제안
논문에서는 계층적 질의응답의 중요성을 언급하고 해결하였다. 이를 검증하기에 기존 데이터셋은 영상이 길이가 짧고 질의가 단순하여 평가가 어렵기 때문에 새로운 벤치마크인 HiVU를 제시하였다. HiVU는 총 60시간에 해당하는 120개의 비디오로 구성되었으며 비디오의 평균 길이는 30분인 Long-video 데이터셋이다. 3가지 다양한 도메인-강의나 다큐멘터리같은 지식-교육, 뉴스와 같은 정보, 엔터테이먼트-에 대한 비디오를 광범위하게 수집하였으며, 제안한것처럼 3단계의 질의응답으로 구성되었다. 뿐 만 아니라 응답의 평가를 위해 5가지로 나누어 평가하도록 구성되었는데 기존에 활용되던 LLM 기반의 평가방식을 구체화한 것으로 평가 지표 5가지: Comprehensiveness (질문을 얼마나 온전히 커버하는가) Empowerment (사용자에게 의미 있는 통찰을 주는가) Trustworthiness (사실성, 신뢰도) Depth (표면적 설명 vs 심층적 분석) Density (불필요한 말 없이 핵심만 담았는가)에 대해 면밀하게 평가하도록 벤치마크를 구성했다. (기존 LLM 기반의 평가방식은 두 모델의 응답을 LLM이 비교 후 승자를 결정하는 Win-Rate 방식으로 LLM-as-a-Judge 등으로 기존 방법에서 다루어지는 지표이다.) 다만 각 평가를 위한 프롬프트는 공개되지 않았다.
실험
실험은 제안한 데이터셋인 HiVU와 대표적인 multi-task benchmark인 Video-MME, MLVU에 대해 진행되었다. 또한, 사용된 MLLMs 모델은 실험의 표에서 확인할 수 있다.
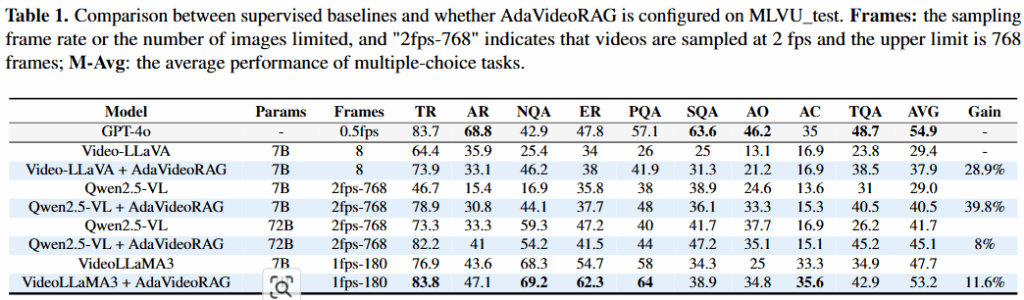
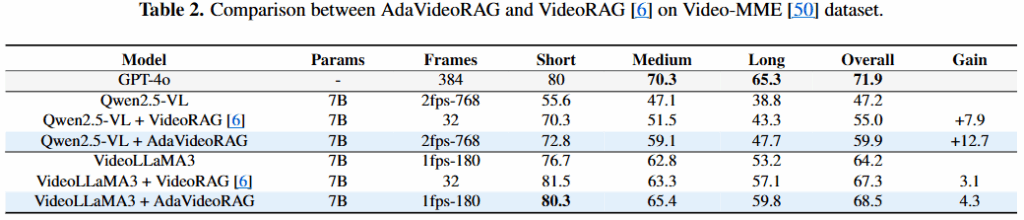
위의 Table1, 2는 기존 벤치마크에 대한 적용실험 결과이다. Video-LLaVA, Qwen2.5-VL, VideoLLaMA3에 대해 실험이 진행되었으며, AdaVideoRAG를 적용했을 때 open source로 상업용 모델인 GPT-4o 성능에 가깝게 도달한 성과를 얻었다. 또한 Video-MME에서는 기존 RAG 기법과 성능을 비교할 수 있었는데, 실험 결과 제안 방법론이 더욱 성능개선이 있었다는 점에서 유의미 하다. 즉, 현재의 RAG 기법 중 open source 모델로 상업용 모델과 가장 가까운 성능을 낼 수 있는 방법이라는 점에서 의미가 있다.
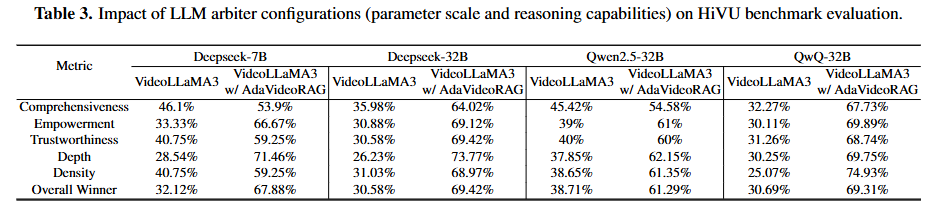
Table3은 HiVU에 대한 평가 결과이다. 제시한 다양한 지표에 대해 평가를 수행했는데, 채점 모델 기준(표의 가장 상단) 7B 모델보다 32B 모델의 개선정도가 우수함을 통해 채점 모델이 우수할수록 명확하게 제안된 AdaVideoRAG가 우수함을 확인할 수 있다.
좋은 리뷰 잘 읽었습니다.
Caption/ASR/OCR/Graph DB에서 검색된 내용이 서로 상충하거나 중복될 경우 우선순위는 어떻게 결정될지 궁그합니다. 중복 정보를 제거하거나 요약하는 모듈이 존재하나요?
안녕하세요 좋은 리뷰 감사합니다.
방법론에서 질의를 난이도에 따라 3단계로 나눈다고 이해하였는데 모델의 학습이나 추론 측면에서 해당 단계가 결정되는 부분이 어디인지 궁금합니다. 단계별로 계층적인 정보를 활용하는 것 같은데, 질문이 입럭되었을때 이게 1, 2, 3단계다라고 이산적으로 분류하는것은 아닌건가요?
안녕하세요 유진님 리뷰 감사합니다~!!
한가지 궁금한게 있는데요!
level3를 위한 retrieval전략으로 level1과 2를 진행하지 않는 이유는 무엇인까요?
더 고난도의 추론이 가능한거면 낮은 레벨의 추론도 가능할것 같다는 생각이 드는데, 이렇게 레벨로 나누어서 하는 이유가 예를 들면 연산량이슈나 낮은 레벨은 오히려 많은 정보가 노이즈가 된다던가 등의 이유가 있어서 그런건가요?