안녕하세요, 이번주는 World Model에 관한 제 나름의 정리글을 작성하려고 합니다. 최근 world model이 급부상 하면서 다양한 연구에 활용되는 경향을 확인할 수 있었는데요, 제가 관심을 가지는 시뮬레이션을 활용한 로봇 데이터 scalining에도 새로운 패러다임이 생긴 것 같은 확신이 들었습니다. 월드 모델 활용을 검토 결과 리소스가 문제였는데, 감사하게도 H100을 사용할 수 있는 기회가 생겼고, 시뮬레이션 데이터를 현실과같이 바꾸는 sim2real transfer에 대한 각종 실험을 진행중입니다. 연구에 활용할거면 어느 정도라도 알고 쓰자!라는 마음으로 서베이 논문과 기타 소스로부터 공부한 내용을 바탕으로 world model은 무엇인지, 제가 사용하려는 cosmos-transfer 2.5 모델은 어떻게 작동하는지 정리해보려 합니다. 사실 시간도 넉넉하지는 않고 학술적인 베이스도 깊지는 않은만큼 큰 그림에서 보는 느낌이 될 것 같습니다,,
World Models
우선은 world model의 정의가 필요할 것 같습니다. 사실 world model에 관심을 가진지 어느새 몇달이 된 것 같은데, 결과물에 감탄만 하고 ‘그래서 world model이 무엇인가요?, input / output이 무엇인가요?’의 질문에 대해 명확하게 답할 수는 없었습니다.
그래서 world model이 무엇이냐? World model은 일단 언어 그대로 실제 세게의 물리 법칙, 공간 구조, 시간적 변화를 내부적으로 학습한 신경망 모델이라고 정의할 수 있을 것 같습니다. 텍스트, 이미지, 비디오, 행동 데이터등 다양한 모달리티를 입력으로 받아 현실적인 물리 환경을 시뮬레이션하는 영상이나 변화된 세계의 상태에 대한 정의를 할 수 있으면 world model로 칭하는 것이 맞을듯 합니다. 로보틱스나 자율주행쪽 같이 Physical AI 분야에서는 world model을 활용해 합성 데이터 생성이나 하위 AI 모델 학습용 데이터 엔진으로 사용하거나 world model 자체의 내제적으로 구축된 지식 자체를 policy에 사용하는데요, 해당 모델들은 실제 세계와 상호작용 한는만큼 물리적인 환경과 dynamics를 이해하는 것이 핵심 목표입니다.
따라서 world model 학습의 핵심은 정말 방대한 양의 현실 데이터라고 합니다. 자율주행의 경우 다양한 지형, 날씨, 로보틱스의 경우에도 정말 다양한 환경에서 다양한 task를 수집한다고 합니다. NVIDIA에서는 페타바이트 규모의 데이터를 필요로 한다고 하니, 규모가 정말 어마어마 한 것 같습니다.
Types of World Models
구체적으로 world model이 어떻게 학습하는지는 world model의 유형에 따라 다른데요, 앞에서도 정의를 하긴 했지만 좀더 세부적으로 input / output이나 세부적인 역할로 구분을 해서 정리하면 더 명확할 것 같습니다. World model은 크게 세가지 유형으로 분류할 수 있습니다. Prediction model, Style transfer model, Reasoning model로 나누어 설명하도록 하겠습니다.
Prediction Models
Prediction model들은 텍스트나 영상을 입력으로 받아 다음 상태를 추론할 수 있습니다. Input modality에 따라 text2world, image2world, video2world로 나눌 수 있는데요, 경우에 따라 출력은 내부적으로, 압축적으로 표현하는 모델들도 있고 실세계의 영상을 직접 표현하는 모델들도 있습니다. 내부적으로 압축된 latent space에서 표현하는 경우는 보통 강화학습의 에이전트에게 state를 전달하기 위해 사용됩니다. Dreamer와 같은 연구들이 잠재공간에서의 상상을 world model을 통해 진행하며 샘플 효율성을 높였다고 합니다.
반대로 최근에 주목받고 있는 모델들(주로 world foundation model로 불리는 모델들)은 텍스트 프롬프트나 영상을 입력받아 새로운 3차원 세계의 영상을 생성합니다. Deepmind의 Genie나 NVIDIA의 Cosmos Predict를 예로 생각하시면 될 것 같습니다. 다만 여기서 좀 의문인게 그럼 video generation 모델들은 다 world model인거냐?인데, 이에 대한 답은 인터넷 검색 결과 아니라고 결론 내렸습니다. Video generation 모델들 중 세계의 상태와 변화를 long term으로 잘 모델링 할 수 있고, 이를 위해 다양한 dynamics를 배울 수 있는 상호작용 데이터로 학습된 경우에만 world model이라고 칭한다고 합니다. 다시 요약하자면, 텍스트나 영상을 받아 실세계에서 일어날 일을 예측해 모델링 하거나 실제로 영상을 생성해 보여줄 수 있는 모델이 prediction 유형의 world model입니다. 그래서 점점 발전하는 비디오 생성 모델들이 이젠 월드모델로 작용할 수 있다는 말이 나오는 것 같습니다.
해당 방식의 모델들의 흥미로운 점은, world model을 실제 시뮬레이터로 활용하려는 목표각 있다고 합니다. 모델의 표현력이 좋아지면 자율주행 자동차나 로봇의 행동을 실세계의 문제를 일으키지 않으며 병렬적으로, control하며 확인할 수 있다고 합니다. 정말 world model 자체를 시뮬레이션으로 활용하고자 하는 움직임이 있구나 정도로 이해하면 될 것 같습니다. 시뮬레이터는 데이터를 보지 않고 물리 엔진을 수학적으로 정의해둔 프레임워크인데, 이를 다양한 동역학적인 요소가 표현된 방대한 양의 데이터를 통해 더 현실적으로 구현하고자 하는 움직임입니다.
Style Transfer Models
Style transfer model들은 주어진 조건에 맞춰 세계의 시각적인 스타일을 변화하는 대상 영상과 다양한 condition 영상들을 입력으로 받아 실세계로 전환된 영상을 출력하는 모델입니다. 주로 시뮬레이션 스타일의 세계를 현실 세계의 스타일로 변화시키며 시뮬레이션 데이터의 현실과의 gap을 줄여준다고 생각하시면 됩니다. (제 최대 관심분야입니다) 시뮬레이션 데이터는 완벽히 현실스럽지 못한 렌더링 (visual gap)도 있지만, 모델의 관점에서 더욱 문제인 물리 엔진의 차이 (dynamics gap)이 존재합니다. Style tansfer의 핵심은 visual gap 뿐만 아니라 dynamics gap까지 해결할 수 있는 photorealistic 영상 생성입니다. Style transfer model들은 주어진 조건에 맞게, 비디오의 style만을 바꾸는것이 목표인 만큼 control 가능한 모델임이 중요합니다. 따라서 ControlNet 기반으로 segmentation map, depth map, canny edge, blur 영상 등 다양한 modality의 영상을 입력으로 받아 대상 영상과 구조를 유지하며 photorealistic 영상을 생성합니다. Cosmos Transfer 2.5 모델은 아래와 같이 시뮬레이션 영상을 변화시킬 수 있습니다. 추가적인 학습이 필요한건지 config 조작 숙련도가 부족한건지 실제로 해봤을땐 아직 아쉬운 부분들이 보입니다,, hallucination을 줄이거나 reality를 얻기 위해서는 많은 파라미터 튜닝이 필요하다고 합니다.
Reasoning Models
Reasoning model들은 multimodal 입력을 받아 영상을 보고 질문에 대해 reasoning을 진행하는 모델입니다. Chain of thought 방식으로 영상의 인과관계를 분석하고, 어떤 행동을 하는지, 행동을 하면 어떻게 될지 등등의 시계열적인 추론을 통해 결정할 수 있는 모델들이 해당됩니다. 해당 모델들을 통해서 시뮬레이션 등의 합성 데이터를 필터링 할 수도 있다고 합니다. 기존 LLM들은 텍스트로만 학습해 world knowledge가 있는것 처럼 보이기는 하지만, 조금이라도 복잡해지거나 물리적인 추론을 하기에는 무리가 있기 때문에 현실과 상호작용이 필요한 레벨에서의 reasoning은 world model들을 통해서만 가능하게 될 것 같습니다.
World Models in Embodied AI
그렇다면 제가 연구중인 embodied AI에서는 어떻게 world model들을 활용하는지 간략하게 정리해봤습니다. Embodied AI는 하나의 시스템으로 실세계에서 자율주행차나 로봇이 환경을 이해한 채로 상호작용 할 수 있도록 하는 AI입니다. 이러한 관점에서 world model은 explicit, 혹은 implicit한 방식으로 사용됩니다. 사실 앞에 말한 내용과 비슷하긴 한데 정리를 해보도록 하겠습니다.
Explicit한 활용은 world model을 시뮬레이터로 직접 사용하는 방식입니다. 현재 상태와 행동을 입력하면 미래를 예측해주는 모델을 통해, 실제 환경에 로봇을 투입하지 않고도 가상 환경 내에서 행동 결과를 관측해 데이터로 활용하거나, 테스트를 진행합니다. 이를 통해 현실에서의 위험한 시행착오 없이도 효율적인 학습이나 평가를 할 수도 있고, 다양한 시나리오의 합성 데이터를 무한히 생성해내는 데이터 엔진으로도 활용되어, 로봇 학습에 필요한 데이터 부족 문제를 해결하는 방법으로도 활용됩니다.
다만 현재는 Sim2Real gap을 해소하는 도구로도 활용됩니다. World model의 현실적인 video generation을 통해 시뮬레이션 데이터의 현실성을 향상 시키고 단일 영상을 다양한 시나리오와 다양한 view에서의 영상으로 변화시키는 등 data engine으로 활용합니다. 뿐만 아니라 시뮬레이션에게 현실적으로 묘사하기 힘든 deformable, liquid, 혹은 칼로 사과를 자르는 상호작용들을 표현할 수 있는 능력을 부여합니다. 이를 통해 시뮬레이션 데이터의 물리적인 정확성이 부족하다는 한계를 해결하고 데이터 scaling을 통해 안정적인 학습도 가능하게 해줍니다.
Implicit한 활용은 world model을 직접적인 출력을 목적으로 하지 않고 에이전트나 VLA의 내부 계획 모듈로 통합하는 방식입니다. 이러한 경우들은 보통 world model의 Latent Representation을 활용합니다. 이를 통해 에이전트나 모델이 단순한 시각 정보보다 더 효율적으로 상황을 인지하고 추론하게 유도합니다. 더 나아가 앞서 소개한 Dreamer 알고리즘과 같이 latent space상에서 미래를 예측하고 보상을 계산하여 최적의 행동을 결정하는 방식으로 학습에 직접적으로 활용되는데, 이를 통해 시각적인 데이터를 생성하지 않고도 에이전트가 내부적으로 더 현실적으로 타당한 의사결정을 내릴 수 있게 합니다. 최근 연구들에서는 두 가지를 결합하여 world model을 통해 생성된 데이터로 train하고 latent representation을 통해 미세조정하는 활용도 나타나고 있다고 합니다. 실세계와 상호작용 해야하는 만큼 세계를 이해하는 모델의 지식을 다양한 방식으로 활용하고 있다고 생각하면 될 것 같습니다.
NVIDIA Cosmos 2.5
저는 월드 모델을 시뮬레이션 데이터를 보강하며 데이터를 증강할 수 있는 data engine으로 활용하려고 하고, 이를 위해 cosmos-transfer 2.5로 제가 직접 수집한 시뮬레이션 데이터를 증강해보았는데요, 해당 모델의 키 컨셉이 무엇인지, 어떤 구조인지, 로봇 데이터 관점에서 어떻게 활용할 수 있는지 살펴보겠습니다.
Cosmos predict 2.5
우선 Cosmos-Transfer 2.5는 Cosmos-predict 2.5가 확장된 버전입니다. 따라서 cosmos-predict 2.5에 대해서 설명하도록 하겠습니다. Cosmos-predict 2.5는 기존의 video diffusion world model인 cosmos-predict 1을 다음과 같이 개선한 모델입니다. 아래 요소들을 하나씩 살펴보도록 하겠습니다.
- Pre-training을 위한 데이터셋 필터링 파이프라인 강화로 인한 고품질 데이터 수집
- 기존 Text2World, Image2World, Video2World로 구분돼있던 모듈들의 아키텍쳐 개선을 통한 통합
- Post-training시에 novel reinforcement learning 알고리즘 도입
Data
우선 가장 큰 개선점은 데이터를 Physical AI에 맞춰 행동이나 기하, 시점변화, 시간축에서의 일관성이 살아있는 데이터만 남겨두었다고 합니다. 이를 통해 long-horizon 안정성을 높이고 hallucination을 감소시켰을 뿐 만 아니라 action consistency를 확보할 수 있었다고 합니다. 무려 2억개에 해당하는 온라인 영상, 데이터셋 영상을 큐레이팅 했다고 하는데, 살펴보도록 하겠습니다.
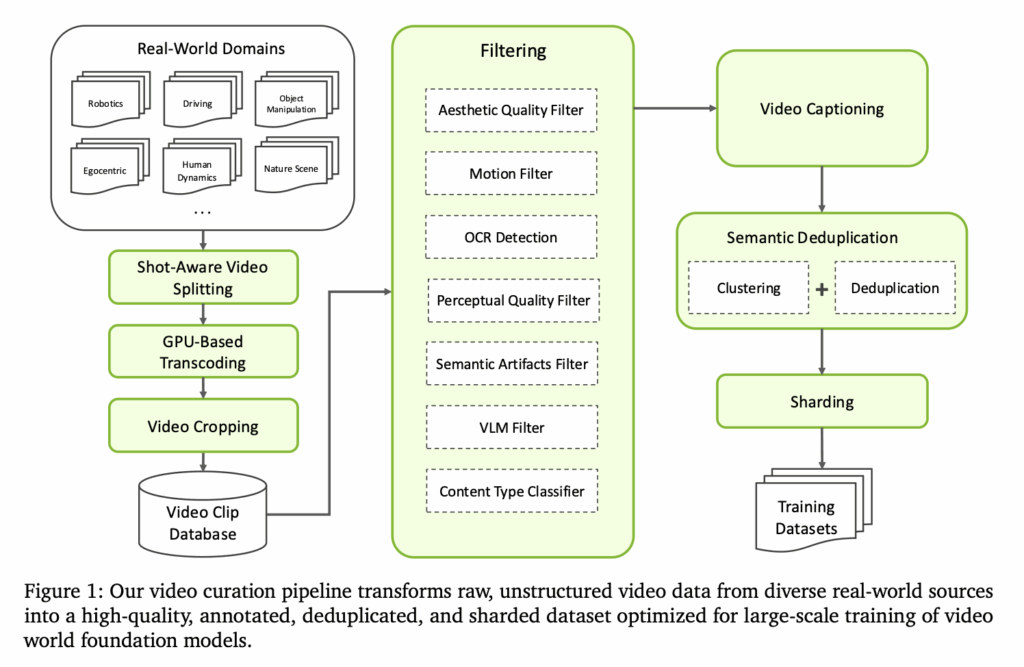
비디오 큐레이션은 다음과 같이 진행됩니다. 우선 다양한 real world의 긴 영상들에서 장면이 전환되는 부분을 shot boundary detection 모델을 통해 감지하여 shot 단위로 분할했다고 합니다. 예를들어 사람이 운전을 하다가 내리는 영상이 있다면 운전하는 영상 / 내리는 영상으로 명확하게 나누어 모델이 하나의 클립을 통해 하나의 semantic한 일관성 있는 동작만 배우도록 했습니다. 이를 통해 시간적인 불연속점을 제거해주었습니다.
이후 대규모 데이터를 파이프라인에 태우기 위해 GPU 기반의 transcoding을 진행했습니다. 기존의 shot 단위로 구분된 데이터들을 학습에 맞게 동일한 코덱과 frame rate로 다시 인코딩 해주었다고 합니다. 2억개의 비디오들은 60억개의 클립으로 나누어졌기 때문에 GPU 기반으로 진행한 frame encoding, decoding 없이는 파이프라인 수행이 불가능했다고 하네요. 기존 ffmpeg와 같은 툴이랑은 다르게 GPU에 올릴 수 있는 텐서 형태의 비디오를 만들었다고 보면 될 것 같습니다. Transcoding 이후에는 시각적인 노이즈가 될 수 있는 black border들을 없애는 video cropping을 진행했습니다.
이렇게 모은 60억개의 클립들을 filtering process를 통해 필터링 해줍니다. 필터링 대상은 모션이 일관되지 않거나 시각적 노이즈가 섞인 비디오들이라고 합니다. 시각적인 품질이 떨어지거나, 과도한 텍스트 오버레이, 왜곡된 영상, VLM을 통한 의미가 모호한 영상들과 추가로 비디오게임이나 애니메이션 영상들도 전부 삭제된다고 합니다.
먼저 Qwen2.5-VL-7B 모델을 통해서 context-aware caption을 진행해줍니다. 이 때 key semantic detail을 잘 담기 위해 프롬프트 엔지니어링도 진행했다고 하는데, 아쉽게도 프롬프트의 예시는 찾아볼 수 없었습니다. Caption은 다양한 용도와 프롬프트에 대응하기 위해 short, medium, long 세 타입으로 진행했다고 합니다.
이제 captioning된 데이터들 중에서 의미적으로 비슷한 영상들끼리 모아서 가장 학습에 강력한 신호를 줄 수 있는 영상들만 남기는 semantic clustering과 deduplication 과정을 거칩니다. 이 때는 embedding 기반의 similarity를 활용해 비슷한 영상들을 모으고, 가장 강력한 학습 신호를 줄 수 있는 고해상도 영상들을 위주로 해당 영상과 pairwise 비교를 통해 중복 영상으로 간주되는 영상들은 제거했다고 합니다. 이를 통해 world model에 풍부한 표현력을 제공할 수 있었다고 합니다. 이런 규칙을 통해 incremental 하게 데이터 풀을 넓혀가며 새로운 영상에 대해서도 의미있는 데이터만 추가하는 식으로 데이터가 아무리 커져도 semantic consistency를 유지할 수 있었다고 합니다.
이렇게 모은 데이터 조차 걸러지고 걸러졌지만 여전히 방대한 양의 데이터기 때문에 학습 가능하고 제어 가능한 구조로 만들기 위해 content type을 26개 taxonomy로 분류했다고 합니다. 분류에는 자체 학습한 classifier를 사용했고, 26개의 semantic label중 어떤 세계인지, 어떤 행동을 하는지, 어떤 상황인지 제일 어울리는 label을 부여했습니다.
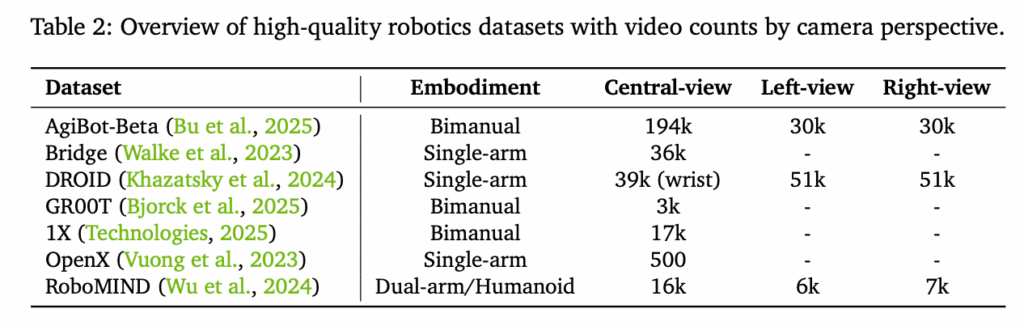
이러한 다단계의 필터를 전부 거치고 살아남은 데이터는 4%정도의 데이터 뿐이라고 하네요.. 역시 모델 학습에는 데이터의 품질이 진짜 중요하다는 것을 느꼈습니다. Cosmos predict 1을 학습할땐 2000만 시간의 비디오 중 30%를 걸러서 사용했는데 이와 비교하면 데이터 자체의 품질이 많이 향상됐을 것 같습니다. VLM 기반의 필터링도 VLM 자체의 발전이 도움을 주었을 것 같습니다. 결론적으로 이러한 데이터 필터링을 통해 더 명확하고 정밀한 supervision이 가능했다고 합니다. 참고로 로보틱스에 특화된 데이터는 아래와 같이 소싱했다고 합니다. VLM 필터링이나 caption을 위한 프롬프팅 시에도 해당 데이터셋들의 메타데이터가 활용되었다고 합니다.
Method
데이터의 변화도 굉장히 중요하지만, cosmos 2.5 모델들은 아키텍쳐도 아예 달라졌습니다. 가장 핵심은 diffusion 모델의 학습 방식을 flow matching으로 바꾼 부분입니다. 최근 생성형 모델들이 flow matching으로 학습하는 이유가 명확한데, cosmos도 해당 방식을 통해 학습했습니다. Flow matching의 장점은 크게 단순함, 학습 안정성, 샘플링 시의 품질향상과 효율 향상으로 볼 수 있습니다.
기존 Cosmos Predict 1은 네트워크의 신호가 안정적으로 설계된 EDM(Elucidated Diffusion Model) 방식을 통해 학습했습니다. 안정적이긴 하지만 결국 학습 대상이 ‘추가된 노이즈가 무엇인가?’ 이기 때문에 매우 고차원인 비디오 생성시에 장기적인 시계열 모델링에서 한계가 명확했다고 합니다. 고해상도 비디오는 애초에 픽셀간 상관성이 매우 강해서 forward 과정에서 노이즈를 약하게 주면 가우시안 노이즈로 구조가 붕괴되지 않고, 그렇다고 너무 강한 노이즈를 주자니 denoising 과정에서의 성능이 나오지 않았다고 합니다. 또한 이런 과정에서 noise schedule과같은 하이퍼파라미터에 매우 민감한 문제도 있고, 결과적으로 간접적으로 denoising을 하는 개념 자체가 학습 안정성 뿐만 아니라 여러 iteration을 거치기 때문에 inference 시의 효율도 떨어트렸습니다.
반면 flow matching 방식은 diffusion과 근본적으로 다르게 노이즈와 데이터간의 분포로 통하는 경로를 직접적으로 설계하고 경로 자체를 학습하도록 설계되었습니다. 간접적으로 매 step마다 노이즈를 확률적으로 추적해가는 것이 아니라 목적 분포로의 방향 자체를 학습해 훨씬더 안정적으로 long horizon과 conditioned modeling이 가능했다고 합니다.
Flow matching에서는 데이터 샘플 x와 표준 정규분포 N(0,I) 에서 샘플링한 노이즈를 가지고 t를 [0,1] 사이에서 샘플링해가며 데이터와 노이즈 사이를 아래와 같은 선형 interpolation 식으로 연결해서 interpolated latent x𝑡 = (1−𝑡)x + 𝑡𝜖 로 정의합니다. 이 부분 자체가 핵심인데, 고차원 상에서 가우시안 노이즈를 확률적으로 한스텝씩 구해서 쫓아가는게 아니라 특정 t에서 어느 방향으로 이동해야 하는지를 바로 예측할 수 있게 됩니다. 그 방향은 Xt를 미분한 v𝑡 = 𝜖−x 가 되고, 모델이 ℒ(𝜃) = Ex,𝜖,c,𝑡 ‖u(x𝑡,𝑡,c; 𝜃)−v𝑡‖2 와 같이 MSE로 여러 conditional input을 기준으로 vt 자체를 학습하도록 설계되었습니다. 이를 통해서 inference 시에도 단순히 condition이 주어졌을 때 주어진 방향으로 적분해나가기만 하면 되는 식이기 때문에 결정적이고, iteration도 훨씬 적게 필요하다고 합니다.
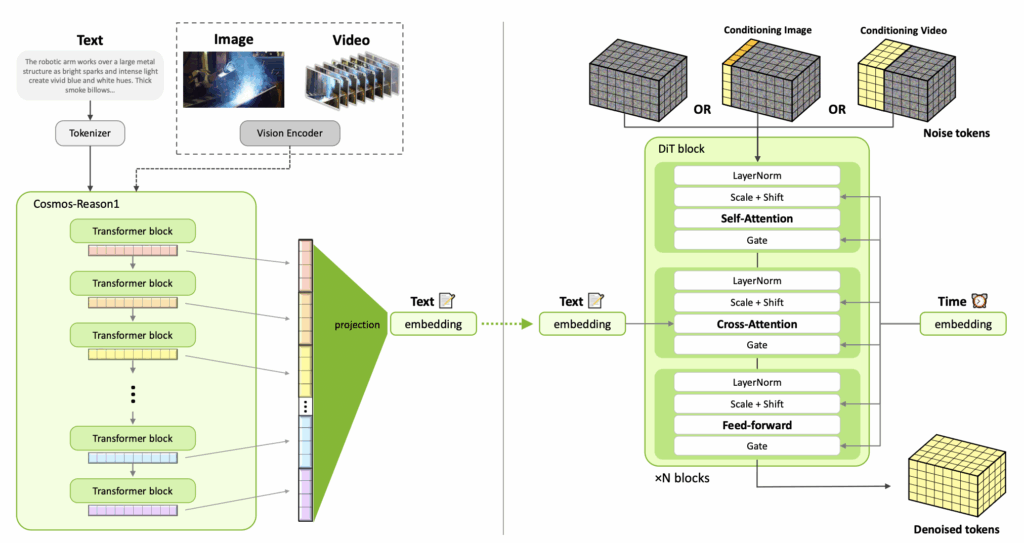
구체적인 모델 구조는 다음과 같습니다. 기존 cosmos-predict 1에서 사용한 DiT 구조들은 유지한채로 velocity prediction을 위해서 재설계되었다고 합니다. 핵심적인 변화점은 positional embedding을 절대 위치에서 상대 위치로 변경했다는 점입니다. 절대 위치 방식은 공간적, 시간적 기준이 고정되어 있어 학습 때 보지 못한 해상도나 길이에 적응하기 어렵다는 한계가 있었으나, 상대 위치 방식은 post-training 단계에서 더 높은 해상도와 긴 영상 시퀀스를 유연하게 처리할 수 있게 되었다고 하네요. 보조적인 모듈들 또한 변경되었는데, 텍스트 인코더를 기존 T5에서 cosmos-reason 1으로 변경해 world model이 요구하는 문맥의 이해를 더 끌어올렸다고 합니다. 그림과 같이 여러 트랜스포머 블록들의 activation 값을 합쳐서 정교함을 추가했다고 하네요. 또한 visual token 생성을 위해 WAN 2.1 VAE를 도입했다고 합니다.
큰 그림을 보면 사용자의 텍스트, 이미지, 또는 비디오를 cosmos reason 1에 태워서 데이터를 뽑아내고 이를 1024차원의 text embedding으로 projection 해줍니다. 이렇게 얻은 text embedding 데이터와 초기 토큰(노이즈 영상)을 가지고 DiT가 영상을 만들어냅니다. Image to video나 video to video를 하는 경우에는 영상의 초반부를 해당 이미지나 비디오로 채워놓고 복원을 진행합니다. 영상 토큰들을 통해 text embedding, 현재 과정이 어떤 시간에 해당하는지를 나타내는 time embedding을 주입시켜 영상을 만듭니다.
Training
Cosmos Predict 2.5는 training 과정을 progressive하게 설계하는 전략을 채택했습니다. 크게 pre-training, post-training (Finetuning + RL), Distillation으로 나눌 수 있스빈다.
먼저 pre-training 단계에서는 해상도를 점점 높여가며 학습을 진행했다고 합니다. 우선 256p 화질의 정지된 이미지를 생성하게 학습시켜서 개별 프레임의 퀄리티를 확보하고, 이후에 480p로 해상도를 높여 Image2World, Video2World (비디오 생성)를 학습시켰습니다. 학습 과정에서는 1장, 또는 5장의 프레임을 condition으로 주고 나머지 93장에서 나머지 프레임을 생성하게 했습니다. 93 프레임인건 WAN 2.1 VAE를 통해 토큰을 생성하기 때문인 것 같습니다. 마지막으로는 720p로 화질을 올려서 text2world까지 학습시켰다고 합니다. 이 때 해상도가 높아질수록 픽셀간의 겹침이 많아져서 모델이 구조를 학습하기 위해서 점차적으로 강한 노이즈가 필요했는데, 해상도가 올라갈수록 노이즈 분포도 고주파로 이동시키는 shifted normal distribution 방식으로 노이즈를 뽑았다고 합니다.

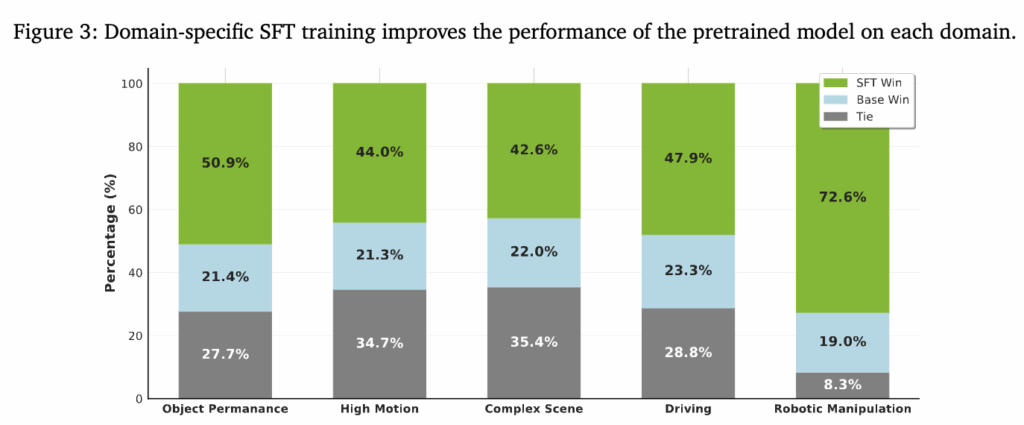
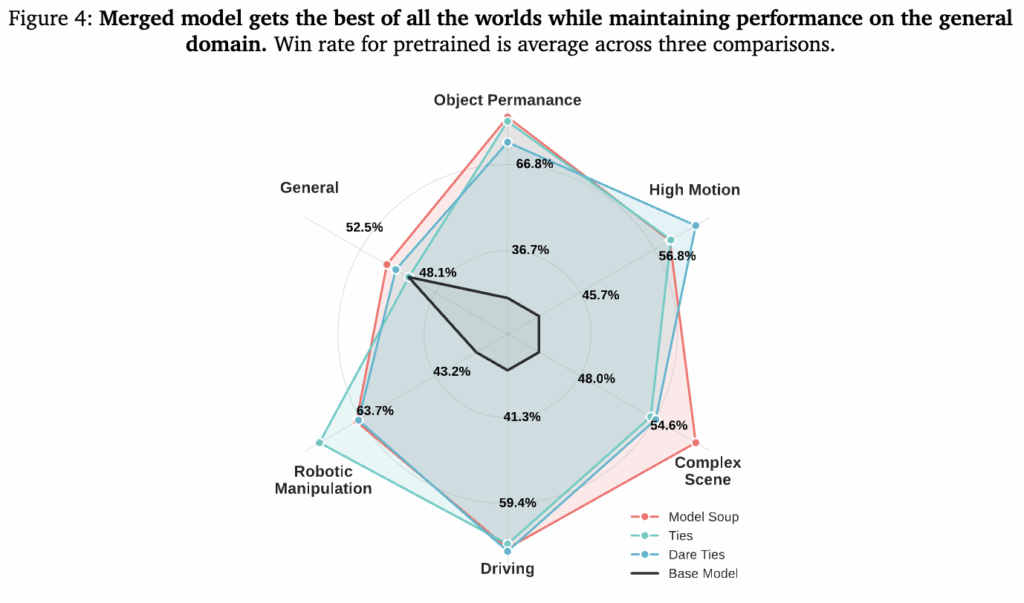
이렇게 기본적인 영상 생성 능력을 갖춘 모델은 table 5의 4K를 제외한 특정 도메인들별로 domain specifit fine-tuning을 거쳤다고 합니다. 하나의 모델이 5가지 도메인을 전부 학습하는것 보다 각 도메인별로 따로 학습시킨 뒤에 파라미터를 하나로 합칠 때 일반화 성능이 좋았다고 합니다. 이렇게 합친 모델을 4k 비디오 데이터셋을 통해 learning rate가 0이 될때까지 계속 finetuning해서 디테일 표현력과 부드러운 움직임을 학습했다고 합니다. (근데 왜 inference 해보면 별로인걸까요..) 아래 figure 3을 보면사람이 봤을 때 각 도메인 별로 finetuning 한 모델들이 base 모델보다 선호도가 높은것을 알 수 있습니다. 연두색이 finetuning 모델이 잘한다, 하늘색이 베이스 모델이 잘한다, 회색은 비슷하다 입니다. 특히 robotic manipulation에서 성능이 두드러지게 개선된 것을 볼 수 있습니다. Figure 4는 finetuning한 모델들을 합친 soup model을 평가한건데 robotic manipulation에서 별 차이가 없다는 평가가 많은 것을 볼 수 있습니다. 진짜 워낙 별난 도메인인거 같습니다,,, 허허
이후에는 사람이 보기에 더 실제 영상같은 느낌을 내기위해 VLM 기반으로 reward를 뽑는 방식으로 VideoAlign을 진행했다고 합니다. 비디오가 텍스트 guide를 잘 따랐는지, 움직임이 자연스러운지, 시각적 품질이 좋은지를 하나의 입력에 대해 8개의 영상을 생성해 GRPO 방식으로 score를 계산해 가장 높은 쪽으로 파라미터를 업데이트 했다고 합니다.
마지막으로는 영상 생성 속도 개선을 위한 Distillation이 진행됐다고 합니다. 내용이 워낙 어려워서,, 큰 틀에서 제가 직관적으로 이해된 부분만 담자면 모델이 정답을 찾아가는 지름길을 타면서도 시간적인 일관성을 유지하도록 학습했고 추가적으로 계산 부분에서도 cosmos predict 2.5만을 위한 flash attention과 병렬 처리 기술을 구현했다고 합니다. 이 결과 아래와 같이 기존의 수십 step과 비교했을 때 4step만으로 끝낸 영상의 퀄리티가 비슷한것을 볼 수 있습니다.

Cosmos-Transfer 2.5
Cosmos-Transfer는 잘 만들어진 cosmos-predict의 응용한 버전으로 생각할 수 있을 것 같습니다. Cosmos-Predict 기반으로 한 world에서 다른 world를 표현 가능한 conditional world2world model이라고 생각함녀 됩니다. Multiple spatial control input들을 조건으로 받아서 world를 생성하는, control 가능한 모델임이 가장 큰 핵심입니다. Condition으로는 edge, blurred video, segmentation map, depth map의 다양한 모달리티를 받을 수 있고, source 영상은 NVIDIA Isaac Sim과 같은 물리 시뮬레이션 엔진의 영상과 현실의 비디오 모두 가능하다고 합니다.
아키텍처는 Cosmos-Transfer 1를 대부분 따르지만, Cosmos-Transfer1에서 메인 브랜치의 시작 부분에만 4개의control block들을 삽입했던 것과 달리 Cosmos-Transfer2.5에서는 메인 브랜치의 매 7번째 블록마다 삽입하여 control block들을 더 고르게 분산시켰다고 합니다. 이를 통해 네트워크 전체에 걸쳐 condition을 더 점진적으로 통합할 수 있게 했다고 합니다. 추가적으로 cosmos-transfer 2.5를 학습할 때 고품질의 control-condition data를 Physical AI에 중점을 맞춰서 큐레이팅 했다고 합니다.
Condition들의 역할을 보자면 Depth information이 기하학적 구조를 포착하고 3D 추론을 강화하는 역할을 합니다. Depth는 Video Depth Anything을 사용한다고 합니다. Semantic segmentation은 로보틱스 task에 필수적인 객체 level에서의 신호를 전달합니다. 실제로 사용할 때 경험해보니 조작 대상과 같은 특정 물체를 자연스럽게 바꾸기 위해서는 segmentation map이 필수적이었습니다. Segment map은 real 데이터의 경우 SAM2를 사용합니다. 저는 시뮬레이터를 활용해 구해주었습니다. 추가로 edge map은 객체들의 경계와 전체적인 video의 structure를 강조하며, blurred video는 모델이 원본의 디테일적인 부분들(원본스러움)을 강제하는 역할을 한다고 합니다.
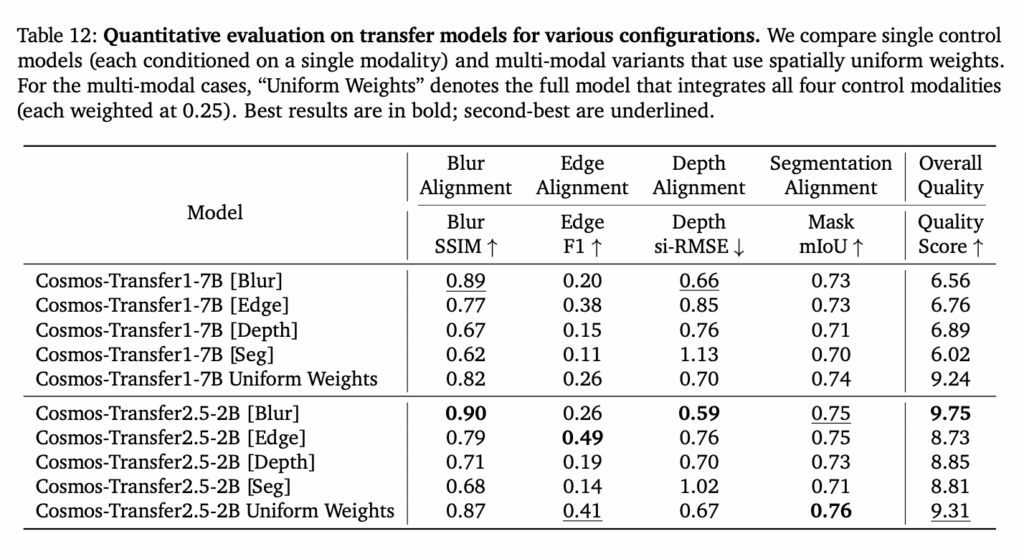
학습은 Cosmos-Trasnfer 2.5 -2B모델을 베이스로 edge, blur, depth, segmentation의 각 modality에 해당하는 control branch를 10만 iteration으로 각각 독립적으로 진행했다고 합니다. 이렇게 따로 학습시켜서 각 전문성을 가지고 통합하는 방식이 많이 쓰이는 것 같습니다. 하이퍼파라미터의 경우, 모델 간의 일관성을 보장하기 위해 Cosmos-Predict2.5-2B에서 사용된 것과 동일한 설정을 채택했습니다.
정리하자면 cosmos predict 2.5를 가져다가 video2video 능력을 베이스로 사용하면서 controlNet 스타일로 control branch만 각 condition modality별로 학습을 돌려서 잘 섞어준 느낌입니다. 그 결과 아래와 같이 기존 cosmos-transfer 7B 모델보다 훨씬 일관성있고 hallucination이 적을 뿐 만 아니라 프롬프트가 잘 반영된 고품질의 영상을 transfer 할 수 있었다고 합니다. 결국 cosmos-predict가 좋아져서 같이 좋아졌다고 볼 수 있을 것 같습니다.

Cosmos-Transfer 2.5 for Robot Policy Learning
Cosmos-Transfer는 robot policy를 위한 데이터 엔진으로 활용할 수 있는데, 이를 노리고 나온만큼 배경과 실제 로봇 데이터 augmentation strategy를 공유했습니다. 핵심은 과연 cosmos transfer 2.5가 policy의 unseen scenario에서의 일반화를 가능하게 하는 data generator로써의 역할을 수행할 수 있는가? 입니다.
실험 세팅은 일반적인 Imitation Learning 파이프라인을 따라서 진행했다고 합니다. Egocentric 카메라로 D455를 사용하는 양팔 로봇을 통해 table top manipulation demo를 수집해 해당 데이터를 바탕으로 학습했습니다. 데이터 수집을 위해서는 Meta Quest 2 controller를 사용했다고 하네요. Task는 아래와 같이랜덤한 위치에 존재하는 bowl 과 appple을 기준으로 각 손으로 apple, bowl을 잡아 사과를 먼저 공중에서 bowl에 담고 사과가 담긴 bowl을 내려놓는 task입니다. 100개의 human teleoperation을 수집해 Diffusion policy policy optimization (DPPO)를 통해서 학습했다고 합니다.

각 데모들에 대해서 아래와 같은 text prompt와 edge map, segmentation map, blurred video를 가지고 데이터를 증강했다고 합니다. 하나의 데모당 5개의 augentation을 진행했다고 합니다.

추가적으로 수집한 데모를 기반으로 같은 task를 다양한 scenario로 확장시킬 수도 있었습니다. Real to Real 에서는 굉장히 control이 잘되는 모습을 볼 수 있습니다.


Agibot real 로봇 데이터셋과 MultiCamVideo라는 synthetic 데이터셋으로 추가 학습해 아래와 같이 하나의 input view에 대한 multivew 영상 생성 또한 가능하다고 합니다.

다만 여기서 아쉬운게 sim2real transfer의 경우 매니퓰레이션에 대한 리포팅은 없었습니다. 예시로도 real2real만 보여준 것을 보면 시뮬레이션 데이터가 부족해서 학습이 덜됐고 잘 안되는게 현실인가..? 싶기도 했습니다. 이 부분은 추가적으로 검토를 해봐야 할 것 같습니다.
Conclusion
월드 모델이 LLM 이후의 대세로 떠오르는 흐름이 확정인 것 같고 AI의 다음 목표인 physical AI를 위해서는 필수적이고, 생성형 AI의 패러다임이 단순하게 그럴싸한 컨텐츠 생성이 아니라 실제로 물리적 세계를 시뮬레이션하는 방으로 나아가는 것 같습니다.
안녕하세요 world model에 대한 소개 감사드립니다.
Table5의 실험 결과에서 5가지 도메인을 따로 학습시킨 후 합친 모델을 Fine tuning 하는것이 가장 효율적이라고 소개해주셨는데, 다른 데이터로 학습한 파라미터들의 위치에 따른 역할이 동일하지 않을 것 같습니다. 혹시 다르게 합한 모델의 파라미터를 단순 합하는 방식인지 궁금합니다.
감사합니다.
안녕하세요 유진님 댓글 감사합니다.
제가 이해한 바로는 모델들을 merge하기 위해 Model Soup 방식을 사용한것으로 알고있고, 이러한 방식은 정말 파라미터를 weighted averaging 하는 방식으로만 알고있습니다. 자세하게는 찾아보지 못했는데, 논문에서도 model soup approach를 적용했다고만 나와있습니다. 같은 pre-trained weight로 각각 학습시킨거라 가능한것 같습니다.
추가적으로 논문에서는 말씀해주신 것과 같은 파라미터 충돌을 해결하는 방식도 몇가지 더 반영해서 비교를 했었는데, 단순히 weighted averaging하는 방식으로 가장 좋은 결과를 얻을 수 있었다고 합니다.
눈팅만 좀 하다가 오랜만에 흥미로운 제목이라 답글 남깁니다. 재밌게 잘 읽었습니다.
저도 모르는 게 많다 보니 질문들을 이것저것 적었는데 적당히 답변할 수 있는 것만 해주셔도 좋을 거 같습니다. (너무 시간 안 쓰셔도 돼요)
Q1. Prediction model, Style transfer model, Reasoning model 는 직접 분류하신건가요??
Q2. 원문) video generation 모델들은 다 world model인거냐?인데, 이에 대한 답은 인터넷 검색 결과 아니라고 결론 내렸습니다. Video generation 모델들 중 세계의 상태와 변화를 long term으로 잘 모델링 할 수 있고, 이를 위해 다양한 dynamics를 배울 수 있는 상호작용 데이터로 학습된 경우에만 world model이라고 칭한다고 합니다.
=> 학습 과정에서 물리적 이해를 위한 inductive bias가 있어야만 World Model라 정의하는건가요? 즉, 단순 pixel matching L1 Loss만 쓰는게 아니라 다른 Objective가 있어야 한다는 의미일까요?
Q3. Reasoning에서 중점적으로 다루는 문제는 물리 기반의 세계 이해인가요?
물리 기반의 세계 이해도 어려움이 많겠지만 (사과가 떨어진다, 물체를 옮긴다, 자른다 등등)
사람 중심 행동에 기반한 세계 이해도 (운동을해서 땀을 많이 흘렸다 -> 몸에 수분이 떨어졌다 -> 목이 마르다 -> 물을 마신다) 활발하게 다루고 있는지 궁금하네요.
Q4. World Model이랑 VLA가 뭐가 다른가요?? VLA는 Action token을 예측하는걸로 알고 있는데 World Model도 다음 state의 action 상태를 예측한다고 하면 비슷한거 아닌가요?? 잘 몰라서 여쭤봅니다…ㅋㅋ
Q5. World Model들은 보통 사이즈가 어떻게 되나요? Million 수준은 아닐거 같고 Billion 수준이라면 통상적으로 논문에서 사용하는 세팅은 몇B 수준인지 (3B, 7B, 등등)
Q6. World Model 학습하는 RL Policy는 보통 GRPO 많이 쓰나요? 그리고 논문에서는 RL Policy를 고도화하는데 (예를 들면 GRPO 한계를 지적하면서 변형된 Objective를 제안하는 등) 집중을 하나요? 아니면 데이터 셋을 구축하는 엔지니어링 과정에 집중을 하나요? 아님 둘다 인가요?
Q7. RL finetune 하면 GPU 얼마나 쓰나요??
안녕하세요 근택님 댓글 감사합니다.
저도 너무 모르는게 많아서 주말에 정리하려다 보니 막상 써둔 내용을 보니 괜한 욕심을 부렸나 싶습니다 허허,,
A1. 해당 분류는 Cosmos 2.5 논문 및 NVIDIA의 World Model 관련 블로그 글에서 분류해둔 것을 사용했습니다. 서베이 논문엔 좀 더 세세한 taxonomy가 있었는데 적지 않았습니다.
A2. 일부 모델에서는 모델이 예측한 latent state와 GT를 인코딩한 latent state의 차이를 최소화 하도록 하는 term도 있었는데 제가 본 Cosmos 논문은 pixel matching loss 만 사용하되 데이터셋이나 인코더 등등을 physical AI 쪽에 특화시켰다고 이해했습니다. 다른 objective가 필수는 아닌 것 같습니다.
=> 이 내용은 시간있을때 좀 더 찾아보고 명확해지면 수정하겠습니다,, inductive bias가 정확히 뭔지 몰라서 원하시는 대답이 아닐수도 있을 것 같습니다
A3. 사람 중심 행동에 기반한 세계 이해도 (의미적인 맥락에 대한 이해가 맞다면) VLM에서 활발히 다루고 있는 것으로 알고있습니다. Cosmos-Reason의 경우는 물리적인 추론 기반의 세계 이해를 우선시 합니다. 예를들어 사과가 땅에서 솟구치는 영상을 주고 해당 영상이 정방향 재생일까 역방향 재생일까?를 물어보는 것과 같이 현실의 물리 법칙을 이해하는지에 대한 reasoning을 주로 평가했습니다.
A4. 사실 저도 이부분이 애매했는데, VLA는 결국 input에 대해서 내가 어떤 행동을 해야할까?의 Action 위주의 추론이라면 World Model은 어떤 일이 벌어질까?의 State나 미래 영상에 대한 추론이라고 생각합니다. 특정 상황을 보고 어떤 행동을 해야할까를 예측하는 제어기 vs 해당 상황에서 어떤 일이 일어날지를 시뮬레이션 해주는 시뮬레이터로 비유할 수 있을 것 같습니다.
A5. 통상적으로 7B, 12B, 20B등등 큰 모델들이 자주 보였고 이번에 공개한 Cosmos Transfer 2.5 같은 경우 2.5B로 7B급 성능을 낼 수 있다 하면서 2.5B가 라이트 하다는 것을 어필하는 정도라고 생각하시면 될 것 같습니다. OpenAI나 Deepmind 쪽 모델들은 훨씬 크게 30B ~ 100B+ 일거라고 하는 글들을 봤었습니다.
A6. 제가 정확히는 모르는데 GRPO 기반으로 발전시켜서 VLA를 RL로 finetuning 하거나 계산한 advantage를 컨디션으로 주는 새로운 아키텍쳐를 제안하는등 후속 연구들이 나오고 있는 것을 보았습니다. 제가 사용한 cosmos 2.5의 경우는 GRPO를 그대로 따랐다고 논문에 명시돼있었습니다.
A7. 요 부분에 대해서는 구체적으로 찾아볼 수 없었습니다.
World model에 대한 정의를 정리하면서 cosmos 2.5의 predict와 transfer에 대해서 정리해주셨네요.
통찰을 얻는 데에 큰 도움이 된 리뷰였습니다.
질문 몇 가지만 하고 가도록 하겠습니다.
Q1. 리뷰 내용이 큰 그림에서 작성되어져 있긴하네요 ㅠㅠ 저희 관심 주제인 robotic 데이터는 어떻게 filtering이 되었는지 아시는 내용이 있다면 공유 부탁합니다.
Q2. Method 첫 그림에 Cosmos-Reason1의 각 블록 별 나온 임베딩 정보를 concat하여 predict 모델에 전달하는 구조를 가져갑니다. 해당 구조를 가져가는 것이 어떤 이점이 있는지 설명이 있을까요?
Q3. 또한, 다른 cosmos 시리즈는 2.5까지 나왔는데 reason 모델은 1에 머물고 있는 이유가 뭐라고 생각하시나요?
안녕하세요, 영규님. 좋은 리뷰 감사드립니다.
리뷰를 읽으며 개인적으로 궁금한 점이 생겨 질문드립니다.
제가 이해하기로는 현재 소개된 월드 모델들은 주로 비디오와 텍스트 정보를 기반으로 세계의 구조와 동역학을 학습하는 것으로 보였습니다. 이러한 접근 외에도, 향후 텍타일 센서로부터 얻어지는 촉각 정보나 힘·토크와 같은 비시각적 센서 정보들이 월드 모델에 함께 통합될 가능성도 있을지 궁금합니다.
다시 한번 좋은 리뷰 공유 감사합니다🌏
안녕하세요 영규님 좋은글 감사합니다.
전체적으로 배운내용을 정리하면서 작성하신 것 같은데, 제가 모르는 분야지만 어느정도 이해가 되게 잘 정리해 주신 것 같습니다. 제가 읽다가 궁금한 내용이 있는데,
“기존 cosmos-predict 1에서 사용한 DiT 구조들은 유지한채로 velocity prediction을 위해서 재설계되었다고 합니다. 핵심적인 변화점은 positional embedding을 절대 위치에서 상대 위치로 변경했다는 점입니다. 절대 위치 방식은 공간적, 시간적 기준이 고정되어 있어 학습 때 보지 못한 해상도나 길이에 적응하기 어렵다는 한계가 있었으나 ” 라는 내용이 있는데 해당 모델에서 이미 엄청 큰 규모의 데이터를 좋은 양질의 데이터로 필터링하여 사용했는데, 이럼에도 보지 못한 해상도나 길이가 남아 있는건지? 그래서 해당 변경이 유의미 했다는건지 궁금합니다.
그리고 diffusion 방식을 flow matching 으로 변경한 내용은 전부 이해가 되는건 아니지만 꽤 흥미로운 것 같습니다.. 완전히 새로운 패러다임을 연 것처럼 보이는데 해당 방식이 diffusion 을 완전히 뒤엎는, 앞으로 해당 방식만 쓰이는 방향으로 연구가 된건지, 혹은 diffusion 의 노이즈 생성과 제거 방식의 목적만 간단하게 바꾼 것인지 궁금합니다.
제가 아는게 적어서 질문의 수준이 좀 낮지만 답변해주시면 감사하겠습니다.