
- Conference: NIPS 2025
- Authors: Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, Xiangyu Yue
- Affiliation: CUHK MMLab, CUHK (SZ), Tsinghua University, UCAS, CUHK HCCL
- Title: Video-R1: Reinforcing Video Reasoning in MLLMs
- Code: GitHub
0. Background (RL & GRPO)
언어모델에서의 강화학습(RL)은 정답만 맞히는 모델이 아니라 “풀이 과정이 논리적으로 타당한지”까지 고려하도록 설계하는 학습 방식이라고 합니다. 단순히 정답 여부로 평가받는 것이 아니라 추론 과정 전체가 보상과 연결되기 때문에, 모델이 더 깊게 생각하고 단계적으로 reasoning을 수행하도록 유도할 수 있죠. 특히 최근 LLM이 길고 구조적인 Chain-of-Thought을 생성할 수 있게 된 것도 이러한 RL 기반 학습 덕분이라고 합니다.
하지만 언어모델의 추론을 RL로 학습시키는 것은 여전히 까다로운 문제였고, 이를 해결하기 위해 등장한 방식 중 하나가 *GRPO(Group Relative Policy Optimization) 입니다. GRPO는 모델이 여러 개의 답변 후보를 생성하도록 한 뒤, 그룹 내부에서 상대적으로 더 나은 답변을 선택해 강화학습을 적용하는 방식이라고 합니다. 즉, 어떤 답변이 절대적으로 좋은지 판별하는 대신, 한 배치 안에서 가장 합리적인 추론 경로를 가진 답변에게 보상을 주는 구조라고 이해하면 됩니다.
*DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
이 방식의 장점은 RL에서 흔히 발생하는 reward 설계 문제를 크게 완화한다는 점이라고 하는데요, 사람이 세밀한 보상 함수를 설계할 필요 없이, 모델이 생성한 여러 후보를 서로 비교하는 것만으로도 자연스럽게 더 논리적인 추론 전략을 선택하도록 학습이 진행됩니다. 이러한 강점 덕분에 GRPO는 텍스트 기반 reasoning 능력을 빠르게 향상시키는 데 큰 역할을 해왔습니다.
다만 GRPO에는 한 가지 핵심적인 한계가 존재한다고 합니다. GRPO는 ‘답변이 논리적인지’는 평가할 수 있어도, 그 답변이 시간적 단서를 제대로 활용했는지까지 판단할 보상 체계는 갖추지 못했다는 점입니다. 그래서 영상과 같이 temporal reasoning이 필수적인 데이터에 그대로 적용하면, 한계가 있고 이게 바로 본 논문에서 집중한 문제점이었습니다.
1. Introduction
앞서 살펴본 것처럼 최근 강화학습을 통해 언어모델이 스스로 추론 과정을 형성하도록 유도하는 연구가 성공하면서, 이를 영상 기반 멀티모달 모델에도 확장하려는 시도가 이어지고 있습니다. 그러나 기존 방식은 영상 전체를 이해하기보다 마지막 한두 프레임만 보고 정답을 찍는 shortcut (편법) 전략을 학습하는 경향이 강해, 실제로 시간적 변화를 따라가며 논리적으로 판단하는 능력은 거의 향상되지 않았습니다.

이 문제는 Figure 1에서 확인할 수 있는데요, 기존 GRPO 방식으로 학습된 모델은 청록색 큐브가 ‘언제’ 등장했는지 확인하지 않고, 마지막 장면에 존재한다는 이유만으로 원래부터 있었다는 결론을 내립니다. 반면 T-GRPO는 큐브가 처음에는 없다가 이후에 등장하는 순서를 추적하며 답을 도출하여, 겉보기에는 비슷한 문장을 생성하더라도 실제 reasoning을 수행하는지 여부가 완전히 달라질 수 있음을 보여줬습니다.
이러한 현상이 반복되는 근본 원인은 두 가지라고 합니다. 첫째, 기존 RL 보상 체계에는 모델이 시간 정보를 활용했는지를 구분할 기준이 없어, ‘편법’을 선택해도 페널티를 거의 받지 않는다는 것. 둘째, 난도가 높은 비디오 reasoning 데이터가 부족해, RL이 다양한 문제 유형을 경험하며 능력을 확장하기 어려웠다는 것이죠.
따라서 저자들은 Video-R1를 통해, 시간 순서를 반영한 답변에만 보상을 부여하는 T-GRPO를 설계해 모델을 실제 temporal reasoning으로 유도하였습니다. 또한, 비디오 reasoning에 필요한 데이터가 충분하지 않다는 점을 고려해 대규모 이미지 기반 reasoning 데이터를 함께 사용해 추론 전략을 먼저 학습시킨 다음, 비디오로 확장하는 방식으로 데이터 문제를 해소하였다고 하네요. 지금부터 구체적으로 어떤 방법론인지 알아보겠습니다.
2. Method
2.1 Dataset Construction
Video-R1의 핵심 아이디어는 모델이 처음부터 영상 추론을 잘하도록 학습시키는 것이 아니라, 논리적 사고 기반을 “이미지 Reasoning → 비디오 Reasoning” 순서로 점진적으로 쌓는 커리큘럼 형태로 학습하도록 설계했다는 점입니다. 즉, 시간 정보를 다루는 능력을 길러주기 전에 먼저 “어떤 문제든 단계적으로 사고하는 법”을 익히게 한 뒤, 이를 비디오에 확장시키는 구조입니다.
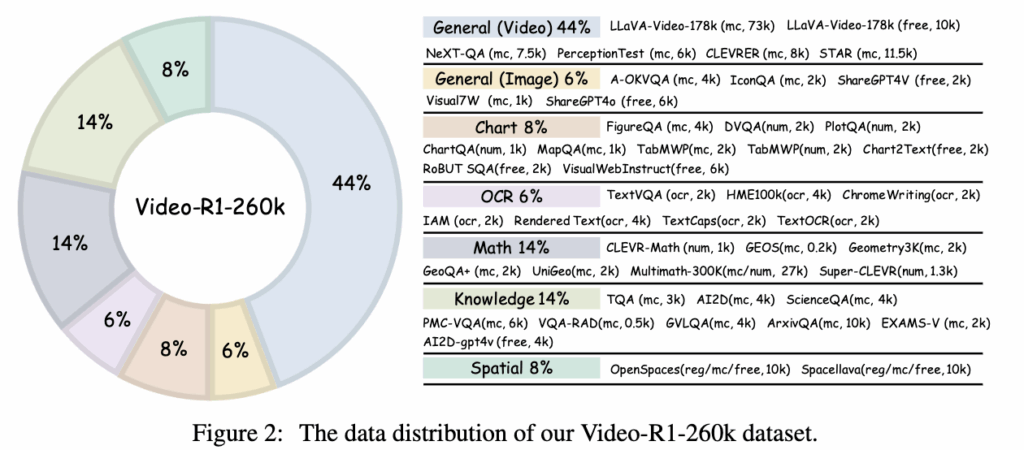
상단 Figure 2를 보면 Video-R1-260k의 데이터 구성 비율을 알 수 있는데요. 전체의 약 44%만이 비디오 기반 reasoning이고, 나머지 56%는 수학, 도표 해석, 상식, OCR, 공간 추론 등 다양한 유형의 이미지 reasoning으로 구성되어 있습니다. 단순히 데이터를 많이 모은 것이 아니라, 서로 다른 reasoning 능력을 균형 있게 포함시켜 특정 유형으로 편향되지 않도록 설계한 것이라고 합니다.
이미지 데이터는 수학적 추론(Math), 도표 해석(Chart), 상식 기반 판단(Knowledge), OCR, 공간적 이해(Spatial) 등 서로 다른 사고 축을 담당하고 있습니다. 이 덕분에 모델은 비디오를 보기 전부터 ‘문제 상황을 쪼개고, 선택지를 비교하고, 근거를 찾아 결론에 이르는 사고 과정’을 먼저 익힐 수 있는 거죠. 이후에 비디오 데이터가 투입되면, 모델은 단순 장면 인식이 아니라 사건의 전개와 인과관계를 따라 reasoning을 확장할 수 있는 준비가 된 상태가 됩니다.

Video-R1-CoT-165k는 사람이 직접 reasoning을 작성한 데이터가 아니라, 대규모 비전언어모델(Qwen2.5-VL-72B-Instruct)에 Figure 11의 템플릿을 적용해 생성된 CoT 데이터를 규칙 기반 필터링으로 정제한 결과물입니다. 이 과정을 거쳐 SFT(supervised fine-tuning) 단계에서부터 모델이 reasoning 문장을 사고하는 과정으로 학습할 수 있도록 설계한 것입니다.
이렇게 SFT 단계에서 reasoning 습관을 먼저 만들고, 이후 RL(T-GRPO) 단계에서 시간 정보를 반영한 reasoning이 선택되도록 보상이 설계되면서, 사고 방식과 시간 정보 활용 능력이 서로 연결되도록 구성된 데이터라고 볼 수 있습니다.

상단 Figure 12의 평가 템플릿을 보면, Video-R1이 단순히 정답을 맞히는지보다 응답이 시간 흐름을 이해하고 있는지를 평가하도록 설계되어 있음을 확인할 수 있습니다. 즉, 사건이 발생한 순서, 특정 행동이 이전/이후에 일어났는지, 지속시간이나 속도·방향 변화를 추적했는지 같은 시간적 단서가 reasoning 안에 나타나야 올바른 응답으로 간주됩니다.
정리하자면 Video-R1의 데이터셋은 단순히 비디오 데이터를 많이 모은 것이 아니라, ① CoT 기반 SFT로 reasoning 언어를 먼저 학습 → ② 다양한 이미지 reasoning으로 사고력을 확장 → ③ 비디오 데이터로 temporal reasoning을 강화라는 3단계 커리큘럼이 데이터 설계에 그대로 반영되어 있습니다.

데이터셋의 구조가 모델의 추론 능력으로 이어진다는 점은 아래 예시에서 잘 드러납니다. Figure 10은 Video-R1-7B가 비디오 콘텐츠를 보고 답을 도출하는 과정을 그대로 출력한 사례인데, 단순히 최종 장면만 보고 정답을 맞추는 것이 아니라, 각 장면에서 일어난 사건을 순차적으로 해석하고 선택지와 대응시키며 결론에 도달하는 것을 확인할 수 있습니다.
(Ross가 왜 대화를 끝내고 자리를 떠났는지를 묻습니다. 모델은 처음에 등장인물의 관계를 파악하고, 각 선택지가 실제 상황과 얼마나 연관되는지를 하나씩 검토합니다. 이후 감정적 요인과 사건의 맥락을 연결해 가장 개연성 높은 선택지를 도출하며, 마지막에는 자신이 선택한 이유가 논리적으로 일관되는지 다시 한 번 검토해 확신을 기반으로 정답을 출력)
2.2 Temporal Group Relative Policy Optimization (T-GRPO)
앞서 살펴본 바와 같이 Video-R1의 핵심 목표는 모델이 실제로 시간 정보를 사용해 추론하도록 만드는 것이었습니다. 이를 위해 저자들은 기존 GRPO가 가진 보상 설계의 한계를 보완한 T-GRPO(Temporal Group Relative Policy Optimization)를 새롭게 제안합니다.
핵심 아이디어는 간단하다고 하는데요: 정상 순서의 프레임을 보고 풀었을 때 더 잘 맞히는가?
=> 이 단 한 가지 기준을 보상 함수에 직접 반영한다.
즉, 모델이 시간 순서를 신경 쓰지 않아도 맞힐 수 있는 문제라면 보상이 크게 주어지지 않고, 프레임 순서가 뒤섞였을 때 성능이 떨어지고 올바른 시간 순서일 때 더 높은 정확도를 보이는 경우에만 추가 보상을 주는 구조입니다. 이렇게 하면 모델은 자연스럽게 편법(shortcut)보다는 temporal pattern을 활용한 reasoning 전략을 선택하도록 학습할 수 있다고 합니다.
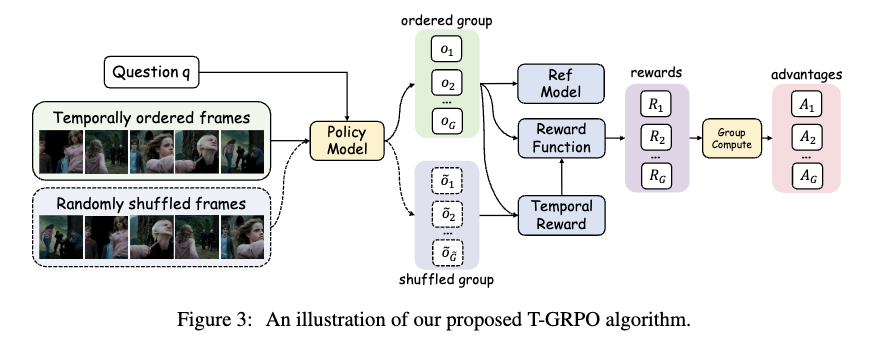
이를 시각적으로 이해하기 쉽도록 Figure 3이 T-GRPO의 전체 과정을 보여줍니다.
모델은 하나의 질문에 대해 두 버전의 입력으로 답변을 생성합니다:
(1) 시간 순서가 유지된 프레임,
(2) 무작위로 뒤섞인 프레임.
그리고 두 그룹 각각에 대해 생성된 여러 개의 답변들에 대해 정답 여부를 계산한 뒤, 정상 순서 그룹의 정확도가 shuffled 그룹보다 높을 때에만 temporal 보상이 추가됩니다. 즉, 정답을 맞히는 것 자체가 아니라 정답을 시간추론 기반으로 맞히는지가 RL에서의 핵심 판단 기준이 되는 것입니다.
이때 중요한 설계 포인트는 보상이 정답을 맞힌 경우에만 증가한다는 점입니다. 만약 정답을 틀렸다면, 오히려 temporal 보상이 잘못된 학습을 강화해버릴 수 있기 때문에, 모델이 temporal reasoning을 효과적으로 활용했을 때만 보상이 주어지도록 설계되어 있습니다.
또한 Figure 3 오른쪽 부분에서는, temporal 보상이 기존 correctness reward와 합쳐져 최종 reward가 계산되고, 각 답변의 advantage가 그룹 내부에서 상대적으로 산출되는 과정이 표현되어 있습니다. 이 구조 덕분에 모델은 단순히 정답을 맞히는 전략보다는 시간적 변화와 사건 순서를 고려해야만 높은 advantage를 얻는 학습 과정을 경험하게 됩니다.
2.3 Training Strategies
Video-R1의 학습은 SFT → RL(T-GRPO) 두 단계로 진행되었습니다.
- SFT 단계에서는 Video-R1-CoT-165k로 지도학습을 진행해, 모델이 다양한 추론 형식과 멀티모달 입력에 익숙해지도록 했습니다. 이 단계는 “기본 추론 능력 세팅” 역할이며, 여기까지 학습된 모델이 Qwen2.5-VL-7B-SFT입니다.
- RL 단계에서는 Video-R1-260k 전체 데이터로 강화학습을 진행하며, 시간 순서를 활용한 reasoning을 했을 때만 보상을 주도록 T-GRPO를 적용했습니다. 이 과정에서 비디오 기반 temporal reasoning 능력이 본격적으로 강화되었고, 최종 모델이 Video-R1-7B가 되었습니다.
또한 RL 단계에서 답변이 지나치게 길어지는 경향을 막기 위해, 정답이면서도 길이가 적정 범위에 있을 때만 추가 보상을 제공해 균형을 유지하였다고 합니다.
2.4 Aha Moment in Video Reasoning
Video-R1은 단순히 시간 순서를 따라가는 수준을 넘어, 중간 reasoning 내용을 스스로 재검토하고 결론을 수정하는 패턴을 보였습니다. 논문에서는 이런 순간을 “Aha moment” 라고 부르며, 모델이 외워서 답하는 것이 아니라 실제로 사고 과정을 따라가고 있다는 증거라고 설명했습니다.

시간 흐름을 잘못 해석했다가 다시 프레임 순서를 따라가며 답을 고치는 사례가 보여져, Aha moment 개념을 가장 직관적으로 이해할 수 있습니다.
3. Experiment
3.1 Setup
Video-R1의 성능은 총 6개의 비디오 벤치마크에서 평가되었습니다.
이 중 VSI-Bench / VideoMMMU / MMVU는 추론 중심 평가,
MVBench / TempCompass / VideoMME는 지각 + 추론을 함께 평가
Training Details
학습은 A100 80GB × 8대 환경에서 진행되었으며, 효율을 위해 학습 시 비디오 프레임은 최대 16개로 제한했습니다(추론 시 16~64 프레임 확대). 먼저 Video-R1-CoT-165k로 1 epoch SFT, 이후 Video-R1-260k로 RL을 진행해 최종 모델을 얻었습니다. 흥미로운 점은 RL을 단 1,000 step만 진행했음에도 비디오 추론 성능이 크게 향상되었다는 것입니다. 이는 데이터 구성 + T-GRPO 보상 설계가 상당히 효과적이었다는 근거로 해석할 수 있습니다.
3.2 Main Table
Video-R1은 6개의 벤치마크 전반에서 기존 모델들의 성능을 넘겼는데요. 특히 VSI-Bench, VideoMMMU, MMVU와 같은 비디오 추론 특화 벤치마크에서 큰 폭의 향상이 관찰되는데, 이는 단순 인식 능력만으로는 해결할 수 없는 문제에서 RL 기반의 temporal reasoning이 실질적으로 효과가 있음을 뒷받침한다고 합니다.
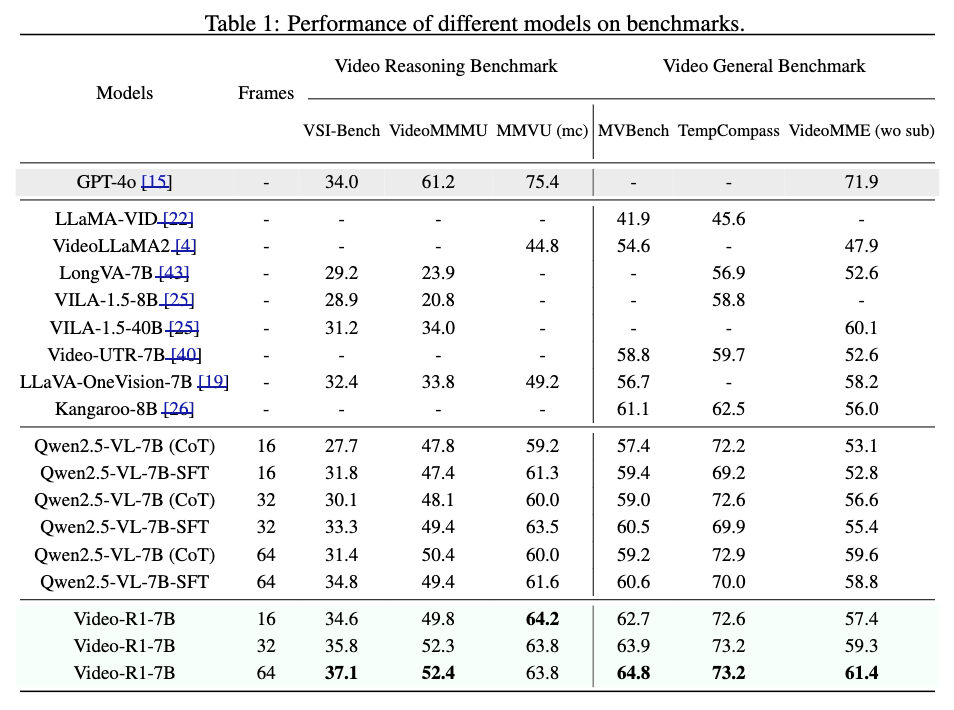
재밌는 부분은 동일한 기반 모델(Qwen2.5-VL-7B)일지라도 SFT만 한 모델(Qwen-SFT)은 성능이 정체되거나 하락한 반면, 단 1k 단계의 RL만 추가해도 Video-R1이 크게 개선된다는 점인데요. 즉, 이 모델의 경쟁력은 아키텍처 변경보다 학습 방식 (특히 T-GRPO 중심의 RL) 이 성능을 이끈 핵심 요인임을 의미한다고 합니다.
또한 Table 1 하단의 세 변형(16 / 32 / 64 프레임)을 비교하면 더 많은 프레임을 입력으로 사용할수록 성능이 상승하는 경향이 있었습니다. 이는 단순히 프레임 수를 늘렸다고 해서 성능이 나빠지지 않는다는 것을 넘어, Video-R1이 실제로 장기 맥락과 시간적 흐름을 활용하는 방향으로 학습되었다는 간접적 증거라고도 합니다. 연구적으로는 “더 긴 비디오를 처리할 수 있는 모델 구조/훈련 전략”이 앞으로의 핵심 경쟁 지점이 될 가능성을 시사하는 부분이라고 하네요
3.3 Ablation study
추가 실험에서는 Video-R1 성능 향상에 기여한 요소가 무엇인지 확인하기 위해 세 가지 변형 모델을 비교했다고 합니다:
(1) 이미지 기반 데이터를 제거한 모델(Video-R1-7B-wo-image)
(2) T-GRPO 대신 기존 GRPO를 사용한 모델(Video-R1-7B-wo-temporal)
(3) SFT 없이 RL만 수행한 모델(Video-R1-7B-zero)
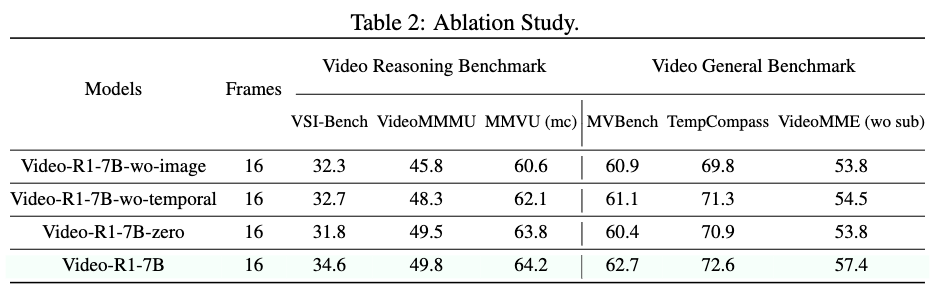
그 결과는 모두 완전한 Video-R1-7B 대비 성능이 떨어졌습니다. 특히 이미지 기반 데이터를 제거한 경우 성능 하락이 가장 컸다고 합니다. 반대로 시간 정보를 고려하지 않는 GRPO를 사용한 모델은 영상 속 temporal cue를 제대로 활용하지 못해 추론 성능이 크게 저하되었습니다. 마지막으로 SFT 없이 RL만 수행한 경우에도 일반화 성능이 감소해, RL이 효과적이기 위해서는 사전 reasoning 능력을 갖춘 상태에서 시작하는 SFT 단계가 필수라는 점을 보여주었습니다.
3.4 Effect of Temporal Reward Analysis
마지막으로 저자들은 T-GRPO의 temporal 보상이 실제로 reasoning 방식에 어떤 영향을 주는지를 따로 분석했습니다. 단순히 점수가 올라간 것이 아니라, 모델이 정말 시간적 단서를 사용해서 추론하고 있는지 확인한 것이 핵심입니다.
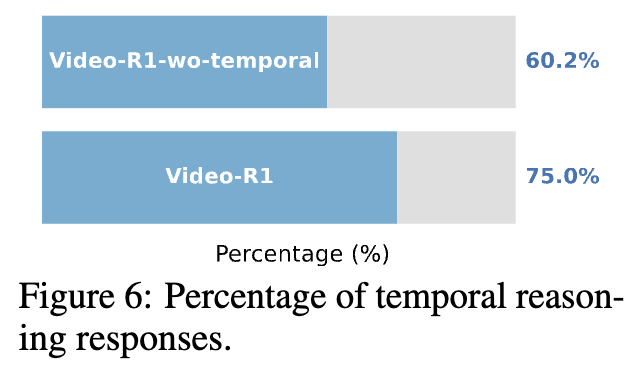
그 결과, Figure 6에서처럼 Video-R1의 답변 중 75%가 시간 정보를 반영한 reasoning을 포함한 반면, temporal 보상이 없는 Video-R1-wo-temporal은 60.2%에 그쳤습니다. 즉, T-GRPO가 단순 성능 향상을 넘어 “shortcut을 방지하고, 시간 추적을 핵심 근거로 삼는 추론 전략을 학습시킨다” 는 점을 정량적으로 확인한 것이라고 합니다.
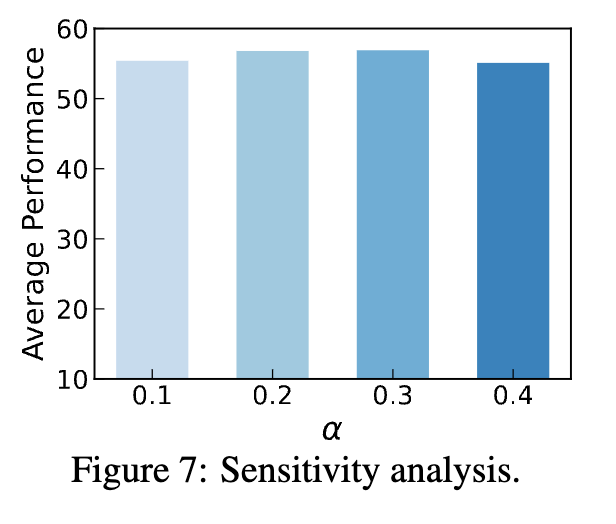
또한 Figure 7에서는 temporal 보상 계수 α에 대한 민감도 분석을 수행했는데, α를 0.2~0.3 범위로 두었을 때 가장 안정적인 성능을 보였고, 값이 너무 작거나(0.1) 너무 크더라도(0.4) 소폭 성능이 떨어졌습니다. 즉, Video-R1은 temporal 보상을 필요로 하지만, 적절한 범위 내에서는 과한 튜닝 없이도 안정적으로 작동하는 메커니즘임을 보여주는 결과라고 볼 수 있습니다.
안녕하세요 좋은 리뷰 감사합니다.
학습 과정은 아래와 같다고 이해하였는데, 이에 두 가지 질문이 있습니다.
(1) SFT 단계: Video-R1-CoT-165k (Qwen2.5-VL이 만든 reasoning 데이터)로 지도학습
(2) RL 단계: Video-R1-260k(단순 학계 데이터셋) 전체 데이터로 강화학습
1. 1단계에서 Qwen이 만든 reasoning 결과 문장(CoT-165k 셋)이 단순 A, B, Yes 등의 단답이 아니라 굉장히 길 것 같은데, 이 reasoning 결과를 next token prediction으로 학습한다는 것인가요?
2. 그리고 2단계에서 본 방식이 제안한 T-GRPO가 적용되는 것으로 이해하였는데, 단순 학계 데이터셋으로 구성된 이 260k 셋에서 모델이 temporal 정보를 보았는지 안보았는지는 어떻게 평가되는지 (즉 여러 답변 중 보상을 줄 답변을 어떻게 결정하는지) 궁금합니다.
3. 앞선 두 과정이 잘 이해되지 않다보니, 오히려 1단계에서 260k 셋으로 next token prediction 기반 SFT를 하고, 2단계에서 qwen이 만든 reasoning 답변으로 T-GRPO를 해야하는 것이 아닌지 헷갈립니다.